[OracleCode SF] In memory analytics with apache spark and hazelcast
2 likes625 views

The document discusses the integration of Apache Spark with Hazelcast's in-memory data grid, highlighting the speed advantages of Spark and its fault-tolerance with resilient distributed datasets (RDDs). It provides code examples for configuration and uses cases, emphasizing parallel processing and operational benefits. Additionally, it mentions limitations regarding data updates while reading from Spark, suggesting potential issues like cursor inaccuracies.






































[OracleCode SF] In memory analytics with apache spark and hazelcast
- 1. @gamussa @hazelcast #oraclecode IN-MEMORY ANALYTICS with APACHE SPARK and HAZELCAST
- 2. @gamussa @hazelcast #oraclecode Solutions Architect Developer Advocate @gamussa in internetz Please, follow me on Twitter I’m very interesting © Who am I?
- 3. @gamussa @hazelcast #oraclecode What’s Apache Spark? Lightning-Fast Cluster Computing
- 4. @gamussa @hazelcast #oraclecode Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
- 5. @gamussa @hazelcast #oraclecode When to use Spark? Data Science Tasks when questions are unknown Data Processing Tasks when you have to much data You’re tired of Hadoop
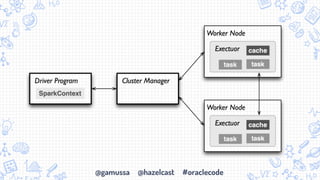
- 6. @gamussa @hazelcast #oraclecode Spark Architecture
- 9. @gamussa @hazelcast #oraclecode Resilient Distributed Datasets (RDD) are the primary abstraction in Spark – a fault-tolerant collection of elements that can be operated on in parallel
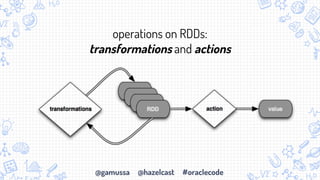
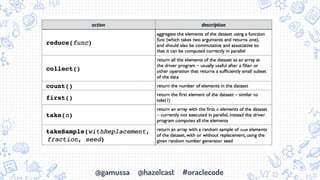
- 11. @gamussa @hazelcast #oraclecode RDD Operations
- 12. @gamussa @hazelcast #oraclecode operations on RDDs: transformations and actions
- 13. @gamussa @hazelcast #oraclecode transformations are lazy (not computed immediately) the transformed RDD gets recomputed when an action is run on it (default)
- 20. @gamussa @hazelcast #oraclecode RDD Fault Tolerance
- 23. @gamussa @hazelcast #oraclecode parallelized collections take an existing Scala collection and run functions on it in parallel
- 24. @gamussa @hazelcast #oraclecode Hadoop datasets run functions on each record of a file in Hadoop distributed file system or any other storage system supported by Hadoop
- 25. @gamussa @hazelcast #oraclecode What’s Hazelcast IMDG? The Fastest In-memory Data Grid
- 26. @gamussa @hazelcast #oraclecode Hazelcast IMDG is an operational, in-memory, distributed computing platform that manages data using in-memory storage, and performs parallel execution for breakthrough application speed and scale
- 27. @gamussa @hazelcast #oraclecode High-Density Caching In-Memory Data Grid Web Session Clustering Microservices Infrastructure
- 28. @gamussa @hazelcast #oraclecode What’s Hazelcast IMDG? In-memory Data Grid Apache v2 Licensed Distributed Caches (IMap, JCache) Java Collections (IList, ISet, IQueue) Messaging (Topic, RingBuffer) Computation (ExecutorService, M-R)
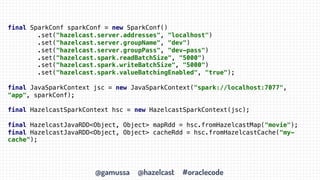
- 31. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 32. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 33. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 34. @gamussa @hazelcast #oraclecode final SparkConf sparkConf = new SparkConf() .set("hazelcast.server.addresses", "localhost") .set("hazelcast.server.groupName", "dev") .set("hazelcast.server.groupPass", "dev-pass") .set("hazelcast.spark.readBatchSize", "5000") .set("hazelcast.spark.writeBatchSize", "5000") .set("hazelcast.spark.valueBatchingEnabled", "true"); final JavaSparkContext jsc = new JavaSparkContext("spark://localhost:7077", "app", sparkConf); final HazelcastSparkContext hsc = new HazelcastSparkContext(jsc); final HazelcastJavaRDD<Object, Object> mapRdd = hsc.fromHazelcastMap("movie"); final HazelcastJavaRDD<Object, Object> cacheRdd = hsc.fromHazelcastCache("my- cache");
- 37. @gamussa @hazelcast #oraclecode DATA SHOULD NOT BE UPDATED WHILE READING FROM SPARK
- 39. @gamussa @hazelcast #oraclecode MAP EXPANSION SHUFFLES THE DATA INSIDE THE BUCKET
- 40. @gamussa @hazelcast #oraclecode CURSOR DOESN’T POINT TO CORRECT ENTRY ANYMORE, DUPLICATE OR MISSING ENTRIES COULD OCCUR
- 42. @gamussa @hazelcast #oraclecode THANKS! Any questions? You can find me at @gamussa viktor@hazelcast.com