










![ساده مثال“Hello World”درOpenMPدر
زبانC++
Directiveصورت به مختلف زبانهای های
زیراست
- C/C++: #pragma omp
- Fortran free form: !$omp
برایهای سویچ از کردن کامپایل
کنید استفاده زیر
- GNU: -fopenmp
- Intel: -qopenmp
- Cray: -h omp
- PGI: -mp[=nonuma,align,allcorembind]
#include <omp.h>
#include <cstdio>
int main(){
// This code is executed by 1 thread
const int nt=omp_get_max_threads();
printf("OpenMP with %d threadsn", nt);
#pragma omp parallel
{ // This code is executed in parallel
// by multiple threads
printf("Hello World from thread %dn",
omp_get_thread_num());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-12-320.jpg)



![در سازی موازی مختلف روشهای
OpenMP
1-از استفادهDirectiveهای
کامپایلری
2-کامپایلری شرایط از استفاده
باماکروهاC/C++Fortran
#pragma omp parallel [clause]!$omp parallel [clause]Compiler Directive
#ifdef _OPENMP
OpenMP specific code
#else
Code without OpenMP
#endif
!$
*$
c$
Conditional Macro](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-16-320.jpg)


![پیش ذخیره فضای
فرض
int A[5]; /* File scope */
int main(void) {
int B[2];
#pragma omp parallel
do_things(B);
return 0;
}
extern int A [5];
void do_things(int *var){
double wrk [10];
static int status;
...
}](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-19-320.jpg)





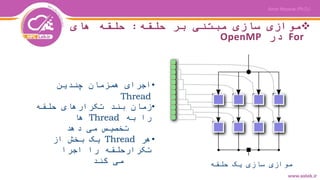


![حلقه بندی زمان مختلف حالتهای
درOpenMP
برایتقسیمبندیدادههابینthreadهایحلقهایروشهایمختلفی
میتواناستفادهکرد:
•schedule(static[,chunk])
بههرthreadبالکیازداده(تکرارهایحلقه)بهاندازهchunk
اختصاصدادهمیشود
•schedule(dynamic[,chunk])
صفیازدادههاتشکیلمیشودکهبههرthreadبهصورتپویابه
اندازهchunkدادهتخصیصمیدهد
•schedule(guided[,chunk])
تقسیمدادهازابتداباسایزبزرگبینthreadهاانجاممیشود
وبهمروربهسمتسایزchunkکاهشمییابد](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-28-320.jpg)
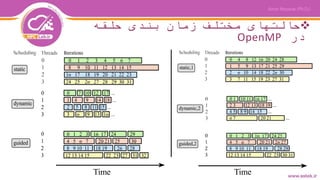
![مختلف حالتهای از مثالهایی
حلقه بندی زمان
!$omp parallel shared(x,y,z) private(i)
!$omp do schedule(dynamic,chunk)
do i = 1, n
z(i) = x(i) + y(i) end do
!$omp end do
!$omp end parallel
#pragma omp parallel shared(x,y,z) private(i)
{
#pragma omp for schedule(dynamic,chunk)
for (i = 0; i < n; i++)
z[i] = x[i] + y[i]
}
Fortran
C/C++](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-30-320.jpg)













![چندThreadی
amin@astek% icpc -c -qopenmp -xMIC-AVX2 stencil.cc
1 #pragma omp parallel for
2 for (int i = 1; i < height-1; i++)
3 #pragma omp simd
4 for (int j = 1; j < width-1; j++) out[i*width + j] =
5 -in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1]
6 -in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1]
7 -in[(i+1)*width + j-1] - in[(i+1)*width + j] - in[(i+1)*width + j+1];](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-46-320.jpg)












![کنترلی ساختارهای سایر
critical[(name)]
•از یکی توسط فقط بار هر که کد از بخشیthreadمی ها
شود اجرا تواند
•توان می بحرانی بخش یک برایnameکرد انتخاب دلخواه
flush[(var1,…)]
•همه حافظهthreadکند می همگام را ها
•شود می نیاز خاصی موارد در فقط
•شود می انجام زیر مواقع در ضمنی صورت به عمل این:
oهمه درbarrierها
oورود/به خروج/بحرانی مناطق ازکد](https://image.slidesharecdn.com/03openmpfundamentalsofparallelismandcodeoptimization-www-200426101252/85/03-open-mp_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-60-320.jpg)








03 open mp_fundamentals_of_parallelism_and_code_optimization-www.astek.ir
- 1. درس3-نوی برنامه در موازیOpenMP Fundamentals of Parallelism & Code Optimization (C/C++,Fortran) در کدها سازی بهینه و سازی موازی مبانی زبانهایC/C++,Fortran Amin Nezarat (Ph.D.) Assistant Professor at Payame Noor University aminnezarat@gmail.com www.astek.ir - www.hpclab.ir
- 2. عناوین دوره 1.های پردازنده معماری با آشنایی اینتل 2.Vectorizationمعماری در اینتل کامپایلرهای 3.نویسی برنامه با کار و آشنایی درOpenMP 4.با داده تبادل قواعد و اصول حافظه(Memory Traffic)
- 4. سلایر کد ،سلایر پردازنده
- 6. سلایر کد ،موازی پردازنده
- 8. Threadمقابل در ها Processها اول گزینه:بین داده تقسیمT/P Examples: computational fluid dynamics (CFD), image processing.
- 9. Threadمقابل در ها Processها دوم گزینه:بین داده گذاری اشتراک بهT/P Examples: particle transport simulation, machine learning (inference).
- 11. های کتابخانه و ها چارچوب ساختThreadها FunctionalityFramework Asynchronous functions; only C++C++11 Threads Fork/join; C/C++/Fortran; LinuxPOSIX Threads Async tasks, loops, reducers, load balance; C/C++Cilk Plus Trees of tasks, complex patterns; only C++TBB Tasks, loops, reduction, load balancing, affinity, nesting, C/C++/Fortran (+SIMD, offload) OpenMP
- 12. ساده مثال“Hello World”درOpenMPدر زبانC++ Directiveصورت به مختلف زبانهای های زیراست - C/C++: #pragma omp - Fortran free form: !$omp برایهای سویچ از کردن کامپایل کنید استفاده زیر - GNU: -fopenmp - Intel: -qopenmp - Cray: -h omp - PGI: -mp[=nonuma,align,allcorembind] #include <omp.h> #include <cstdio> int main(){ // This code is executed by 1 thread const int nt=omp_get_max_threads(); printf("OpenMP with %d threadsn", nt); #pragma omp parallel { // This code is executed in parallel // by multiple threads printf("Hello World from thread %dn", omp_get_thread_num()); } } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
- 13. برنامه کامپایلHello Worldدر OpenMP amin@astek% icpc -qopenmp hello_omp.cc amin@astek% export OMP_NUM_THREADS=5 amin@astek% ./a.out OpenMPwith 5 threads Hello World from thread 0 Hello World from thread 3 Hello World from thread 1 Hello World from thread 2 Hello World from thread 4 OMP_NUM_THREADS controls number of OpenMP threads (default: logical CPU count)
- 14. ساده مثال“Hello World”درOpenMPزبان در Fortran
- 15. ساختار از ای خالصه OpenMP
- 16. در سازی موازی مختلف روشهای OpenMP 1-از استفادهDirectiveهای کامپایلری 2-کامپایلری شرایط از استفاده باماکروهاC/C++Fortran #pragma omp parallel [clause]!$omp parallel [clause]Compiler Directive #ifdef _OPENMP OpenMP specific code #else Code without OpenMP #endif !$ *$ c$ Conditional Macro
- 18. پیش ذخیره فضای فرض -صورت به متغیرها اغلبshareشوند می تعریف -متغیرهایglobalبینthreadگذاشته اشتراک به ها شوند می •C:متغیرهایstaticفایل محدوده درshareهستند •Fortran:متغیرهایSAVEوMODULEمحدوده در بالکهایCOMMON •پویا صورت به متغیرها آنها دوی هر در شوند می داده تخصیص -فرض پیش صورت به متغیرهاprivateهستند
- 19. پیش ذخیره فضای فرض int A[5]; /* File scope */ int main(void) { int B[2]; #pragma omp parallel do_things(B); return 0; } extern int A [5]; void do_things(int *var){ double wrk [10]; static int status; ... }
- 20. omp parallel:اشتراک قواعد داده گذاری private(list) -متغیرهایprivateاز یک هر در اختصاصی پشته یک درthreadها شوند می ذخیره -است نشده تعریف آنها اولیه مقدار -تعریف کد موازی بخش از خروج از پس نیز آنها نهایی مقدار است نشده firstprivate(list) -و گیرد می اولیه مقدار که تفاوت این با است قبلی همانند است استفاده قابل موازی بخش در مقدار این
- 21. omp parallel:اشتراک قواعد داده گذاری lastprivate(list) -همانندprivateو استthreadانجام را موازی بخش تکرار آخرین که دارد را اصلی متغیر به خود مقدار کردن کپی وظیفه دهد می shared(list) -همهthreadآن از یا و بنویسند متغیر نوع این در توانند می ها بخوانند -هستند نوع این از فرض پیش صورت به متغیرها تمامی dafault(private,shared,none) -نوع کدام از فرض پیش صورت به متغیرها که کرد تعیین توان می باشند -درc/c++تعریفdefault(private)نیست مجاز -default(none)کدنویسی زمان در نویس برنامه که است حالت بهترین
- 22. Method 1: using clauses in pragma omp parallel (C, C++, Fortran): int A, B; // Variables declared at the beginning of a function #pragma omp parallel private(A) shared(B) { // Each thread has its own copy of A, but B is shared } int B; // Variable declared outside of parallel scope - shared by default #pragma omp parallel { int A; // Variable declared inside the parallel scope - always private // Each thread has its own copy of A, but B is shared } Method 2: using scoping (only C and C++): 1 2 3 4 5 1 2 3 4 5 6
- 23. سازی موازی روشهای انواع درOpenMP در سازی موازی مدلompبر مبتنیSIMDبرای و است بین داده تقسیمthreadمختلفی روشهای از موازی های کرد استفاده توان می: حلقه ساختار ساختارWorkshare(در فقطFortran) ساختارSingle/Master ساختارSections
- 25. حلقه بر مبتنی سازی موازی:های حلقه ForدرOpenMP •چندین همزمان اجرای Thread •حلقه تکرارهای بند زمان به راThreadها دهد می تخصیص •هرThreadاز بخش یک اجرا را تکرارحلقه کند می حلقه یک سازی موازی
- 26. حلقه بر مبتنی سازی موازی:های حلقه ForدرOpenMP کتابخانهOpenMPاز ها نخ بین حلقه تکرارهای توزیع برای #pragma omp parallel forزبان درc/c++و!$omp parallel doدر Fortranکند می استفاده !$omp parallel shared(x,y,z) private(i) !$omp do do i = 1, n z(i) = x(i) + y(i) end do !$omp end do !$omp end parallel #pragma omp parallel for for (int i = 0; i < n; i++) { printf("Iteration %dis processed by thread %dn", i, omp_get_thread_num()); // ... iterations will be distributed across available threads... } !$omp parallel shared(x,y,z) private(i) !$omp do do i = 1, n z(i) = x(i) + y(i) end do !$omp end do !$omp end parallel 1 2 3 4 5 6
- 27. حلقه بر مبتنی سازی موازی:های حلقه ForدرOpenMP #pragma omp parallel { // Code placed here will be executed by all threads. // Alternative way to specify private variables: // declare them in the scope of pragma omp parallel int private_number=0; #pragma omp for for (int i = 0; i < n; i++) { // ... iterations will be distributed across available threads... } // ... code placed here will be executed by all threads } 1 2 3 4 5 6 7 8 9 10 11 12 13 14
- 28. حلقه بندی زمان مختلف حالتهای درOpenMP برایتقسیمبندیدادههابینthreadهایحلقهایروشهایمختلفی میتواناستفادهکرد: •schedule(static[,chunk]) بههرthreadبالکیازداده(تکرارهایحلقه)بهاندازهchunk اختصاصدادهمیشود •schedule(dynamic[,chunk]) صفیازدادههاتشکیلمیشودکهبههرthreadبهصورتپویابه اندازهchunkدادهتخصیصمیدهد •schedule(guided[,chunk]) تقسیمدادهازابتداباسایزبزرگبینthreadهاانجاممیشود وبهمروربهسمتسایزchunkکاهشمییابد
- 29. حلقه بندی زمان مختلف حالتهای درOpenMP
- 30. مختلف حالتهای از مثالهایی حلقه بندی زمان !$omp parallel shared(x,y,z) private(i) !$omp do schedule(dynamic,chunk) do i = 1, n z(i) = x(i) + y(i) end do !$omp end do !$omp end parallel #pragma omp parallel shared(x,y,z) private(i) { #pragma omp for schedule(dynamic,chunk) for (i = 0; i < n; i++) z[i] = x[i] + y[i] } Fortran C/C++
- 32. Workshare directiveبالکهایی به را کد اجرایی های قسمت ها اجرا بار یک فقط کد تکه هر که کنند می تقسیم مجزایی شود می. real :: a(n,n), b(n,n), c(n,n) d(n,n) ... !$omp parallel shared(a,b,c,d) !$omp workshare c=a*b d=a+b !$omp end workshare nowait !$omp end parallel
- 34. Race Conditionsپیش قابل غیر رفتارهای و برنامه بینی int total = 0; #pragma omp parallel for for (int i = 0; i < n; i++) { // Race condition total = total + i; } زمانیرخمیدهدکه2یابیشتراز Threadهابخواهدبهیکآدرس یکسانازحافظهدسترسییابندو
- 35. Mutex Mutual Exclusion (Mutex)از کد سازی سریالی باData Race کند می جلوگیری
- 36. MutexدرOpenMP #pragma omp parallel { // parallel code #pragma omp critical { // protected code // multiple lines // many variables } } #pragma omp parallel { // parallel code #pragma omp atomic // protected code // one line // specific operations // on scalars total += i; } Good parallel codes minimize the use of mutexes. 1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
- 37. مسئلهrace conditionروشهای و آن حل مسئلهrace conditionچندین که دهد می رخ زمانیthreadزمان یک در اتفاق این از نمونه یک ،باشند داشته را نوشتن و خواندن قصد است مالحظه قابل زیر مثال در asum = 0.0d0 !$omp parallel do shared(x,y,n,asum) private(i) do i = 1, n asum = asum + x(i)* y(i) end do !$omp end parallel do •ترتیب به بستگی که است تصادفی جوابهای شامل کد این نتایج دسترسیthreadمتغیر به هاasumدارد. •روشهایی به نیاز حافظه به دسترسی مکانیزم بر کننترل برای
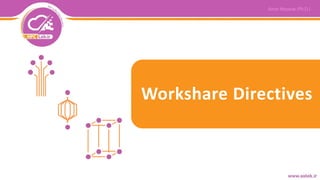
- 38. Reductionمقابله برای بهRC کاربردهای از یکی آرایه یک مقادیر کردن جمعreductionاست Computed by thread 0 Computed by thread 1 Combined result •درopenMPتوسط که محاسباتی نتایج کردن جمعthreadمختلف های توسط شود می انجامreductionانجام قابلاست
- 39. Reductionمقابله برای بهRC reduction(operator:list) •از یک هر ازای به threadجمع عملیات ها می انجام جداگانه زدن شود •بخش پایان از بعد مقادیر تمامی موازی در و شده آوری جمع
- 40. Reductionمقابله برای بهRC مشکل رفع برای کد نمونهRCفرترن در !$omp parallel do shared(x,y,n) private(i) reduction(+:asum) do i = 1, n asum = asum + x(i)*y(i) end do !$omp end parallel
- 41. Built-In Reduction مشکل رفع برای کد نمونهRCدرC/C++ int total = 0; #pragma omp parallel for reduction(+: total) for (int i = 0; i < n; i++) { total += i
- 42. Reductionاختصاصی فضای با Thread int total = 0; #pragma omp parallel { int total_thr = 0; #pragma omp for for (int i=0; i<n; i++) total_thr += i; #pragma omp atomic total += total_thr; } 1 2 3 4 5 6 7 8 9 10 11
- 44. های عملگر Stencil •خطی معادالت •دیفرانسیل جزئی Fluid dynamics, heat transfer, image processing (convolution matrix), cellular automata.
- 45. لبه تشخیص
- 46. چندThreadی amin@astek% icpc -c -qopenmp -xMIC-AVX2 stencil.cc 1 #pragma omp parallel for 2 for (int i = 1; i < height-1; i++) 3 #pragma omp simd 4 for (int j = 1; j < width-1; j++) out[i*width + j] = 5 -in[(i-1)*width + j-1] - in[(i-1)*width + j] - in[(i-1)*width + j+1] 6 -in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1] 7 -in[(i+1)*width + j-1] - in[(i+1)*width + j] - in[(i+1)*width + j+1];
- 48. عددی انتگرال
- 50. سلایر سازی پیاده const double dx = a/(double)n; double integral = 0.0; for (int i = 0; i < n; i++) { const double xip12 = dx*((double)i + 0.5); const double dI = BlackBoxFunction(xip12)*dx; integral += dI; } 1 2 3 4 5 6 7 8 9
- 51. Race Conditionمحافظت نشده const double dx = a/(double)n; double integral = 0.0; #pragma omp parallel for for (int i = 0; i < n; i++) { const double xip12 = dx*((double)i + 0.5); const double dI = BlackBoxFunction(xip12)*dx; integral += dI; } 1 2 3 4 5 6 7 8 9
- 52. از استفادهMutex const double dx = a/(double)n; double integral = 0.0; #pragma omp parallel for for (int i = 0; i < n; i++) { const double xip12 = dx*((double)i + 0.5); const double dI = BlackBoxFunction(xip12)*dx; #pragma omp atomic integral += dI; } 1 2 3 4 5 6 7 8 9
- 53. Built-in Reduction const double dx = a/(double)n; double integral = 0.0; #pragma omp parallel for reduction(+: integral) for (int i = 0; i < n; i++) { const double xip12 = dx*((double)i + 0.5); const double dI = BlackBoxFunction(xip12)*dx; integral += dI; } 1 2 3 4 5 6 7 8 9
- 54. Reductionاختصاصی فضای با Thread const double dx = a/(double)n; double integral = 0.0; #pragma omp parallel { double integral_th = 0.0; #pragma omp for for (int i = 0; i < n; i++) { const double xip12 = dx*((double)i + 0.5); const double dI = BlackBoxFunction(xip12)*dx; integral_th += dI; } #pragma omp atomic integral += integral_th; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14
- 56. Single/Master
- 57. اجرا زمان کنترلهای دربرخیمواردبخشیازکدبایدتوسطmasterاجراشودو بخشدیگرتوسطیکsingle thread •I/O،مقداردهی،اولیهبهروزرسانیمقادیرغیرمحلی مثالهاییازایندستهستند. •OpenMPروشهاییبرایاینمدلازاجراارائهکردهاست
- 58. کنترلی ساختارbarrier master •توسط فقط باید که کند می مشخص را کد از ای ناحیه masterشود اجرا •که باشید داشته دقتbarrierاین انتهای در ضمنی ندارد قرار کد از بخش single •یک توسط باید که کند می مشخص را کد از ای ناحیه threadشود اجرا و دلخواه
- 59. کنترلی ساختار master/single barrier •یک که زمانیthreadیک بهbarrierکه زمانی تا رسد می سایرthreadمنتظر برسند نقطه آن به وی تیمی هم های ماند می. •همهthreadیک به باید تیم یک هایbarrierیا برسند نرسند هیچیک •دستورات این پایان درbarrierدارد وجود ضمنی:do, parallel, sections, single, workshare
- 60. کنترلی ساختارهای سایر critical[(name)] •از یکی توسط فقط بار هر که کد از بخشیthreadمی ها شود اجرا تواند •توان می بحرانی بخش یک برایnameکرد انتخاب دلخواه flush[(var1,…)] •همه حافظهthreadکند می همگام را ها •شود می نیاز خاصی موارد در فقط •شود می انجام زیر مواقع در ضمنی صورت به عمل این: oهمه درbarrierها oورود/به خروج/بحرانی مناطق ازکد
- 61. مثال:reduction using critical section فرترن !$OMP PARALLEL SHARED(x,y,n,asum) PRIVATE(i, psum) psum = 0.0d !$OMP DO do i = 1, n psum = psum + x(i)*y(i) end do !$OMP END DO !$OMP CRITICAL(dosum) asum = asum + psum !$OMP END CRITICAL(dosum) !$OMP END PARALLEL DO
- 62. مثال:initialization and output C/C++ #pragma omp parallel while (err > tolerance) { #pragma omp master { err = 0.0; } #pragma omp barrier // Compute err … #pragma omp single printf(“Error is now: %5.2fn”, err); }
- 64. OpenMP Directive #pragma omp parallel – create threads #pragma omp for – process loop with threads #pragma omp task/taskyield – asynchronous tasks #pragma omp critical/atomic – mutexes #pragma omp barrier/taskwait – synchronization points #pragma omp sections/single – blocks of code for individual threads #pragma omp flush – enforce memory consistency #pragma omp ordered – partial loop serialization OMP_* – environment variables, omp_*() – functions Click construct names for links to the OpenMP reference from the LLNL
- 65. List of environment variables (OpenMP 4.5) OMP_SCHEDULE OMP_NUM_THREADS OMP_DYNAMIC OMP_PROC_BIND OMP_PLACES OMP_NESTED OMP_STACKSIZE OMP_MAX_ACTIVE_LEVELS OMP_THREAD_LIMIT OMP_CANCELLATION OMP_DISPLAY_ENV OMP_DEFAULT_DEVICE OMP_WAIT_POLICY OMP_MAX_TASK_PRIORITY
- 66. Runtime functions •یا تنظیمات مقادیر خواندن برای اجرای زمان توابع شوند می استفاده اجرا زمان متغییرهای به مقداردهی –C/C++ header file omp.h –omp_lib Fortran module (omp_lib.h header in some implementations) •کاری بار توزیع برای مهم تابع دو –omp_get_num_threads() –omp_get_thread_num()
- 67. توابع با حلقه یک سازی موازی ای کتابخانه #ifdef _OPENMP #include “omp.h” #else #define omp_get_thread_num() 0 #define omp_get_num_threads() 1 #endif … #pragma omp parallel private(i,nthrds,thr_id) { nthrds = omp_get_num_threads(); thrd_id = omp_get_thrd_num(); for (i=thrd_id; i<n; i+=nthrds) { … } }