Big Data/Hadoop Infrastructure Considerations
5 likes2,358 views

1) Big data is growing exponentially and new frameworks like Hadoop are needed to analyze large, unstructured datasets. 2) Hadoop uses distributed computing and storage across commodity servers to provide scalable and cost-effective analytics. It leverages local disks on each node for temporary data to improve performance. 3) Virtualizing Hadoop simplifies operations, enables mixed workloads, and provides high availability through features like vMotion and HA. It also allows for elastic scaling of compute and storage resources.

















































Big Data/Hadoop Infrastructure Considerations
- 1. Big Data in a Software-Defined Datacenter Richard McDougall Chief Architect, Storage and Application Services VMware, Inc @richardmcdougll © 2009 VMware Inc. All rights reserved
- 2. Trend: New Data Growing at 60% Y/Y Exabytes of information stored 20 Zetta by 2015 1 Yotta by 2030 Yes, you are part of the yotta audio( generation… digital(tv( digital(photos( camera(phones,(rfid( medical(imaging,(sensors( satellite(images,(logs,(scanners,(twi7er( cad/cam,(appliances,(machine(data,(digital(movies( Source: The Information Explosion, 2009 2
- 3. Trend: Big Data – Driven by Real-World Benefit 3
- 4. Big Data Family of Frameworks Hadoop Other NoSQL Spark, batch analysis Shark, Cassandra, Big SQL Mongo, etc Solr, Compute HBase Impala, Platfora, Etc,… layer real-time queries Pivotal HawQ File System/Data Store Distributed Resource Management Host Host Host Host Host Host Host 4
- 5. Big (Data) problems: making management easier 5
- 6. Broad Application of Hadoop technology Horizontal Use Cases Vertical Use Cases Log Processing / Click Financial Services Stream Analytics Machine Learning / Internet Retailer sophisticated data mining Web crawling / text Pharmaceutical / Drug processing Discovery Extract Transform Load Mobile / Telecom (ETL) replacement Image / XML message Scientific Research processing General archiving / Social Media compliance Hadoop’s ability to handle large unstructured data affordably and efficiently makes it a valuable tool kit for enterprises across a number of applications and fields. 6
- 7. How does Hadoop enable parallel processing? ! A framework for distributed processing of large data sets across clusters of computers using a simple programming model. Source: http://architects.dzone.com/articles/how-hadoop-mapreduce-works 7
- 8. Hadoop System Architecture ! MapReduce: Programming framework for highly parallel data processing ! Hadoop Distributed File System (HDFS): Distributed data storage ! Other Distributed Storage Options: • Alternatives to HDFS • MAPR (SW), Isilon (HW) 8
- 9. Job Tracker Schedules Tasks Where the Data Resides Job Tracker Job Input%File Host%1 Host%2 Host%3 Split%1%–%64MB Task%% Task%% Task%% Split%2%–%64MB Tracker Tracker Tracker Split%3%–%64MB Task%<%1 Task%<%2 Task%<%3 DataNode DataNode DataNode %Input%File Block%1%–%64MB Block%2%–%64MB Block%3%–%64MB 9
- 10. Hadoop Data Locality and Replication 10
- 12. Rules of Thumb: Sizing for Hadoop ! Disk: • Provide about 50Mbytes/sec of disk bandwidth per core • If using SATA, that’s about one disk per core ! Network • Provide about 200mbits of aggregate network bandwidth per core ! Memory • Use a memory:core ratio of about 4Gbytes:core ! Example: 100 node cluster • 100 x 16 cores = 1600 cores • 1600 x 50Mbytes/sec = 80Gbytes/sec(!) • 1600 x 200mbits = 320gbits of network traffic 12
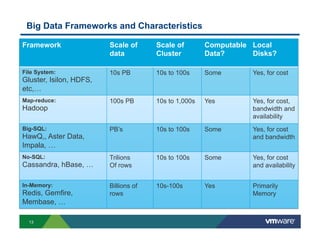
- 13. Big Data Frameworks and Characteristics Framework Scale of Scale of Computable Local data Cluster Data? Disks? File System: 10s PB 10s to 100s Some Yes, for cost Gluster, Isilon, HDFS, etc,… Map-reduce: 100s PB 10s to 1,000s Yes Yes, for cost, Hadoop bandwidth and availability Big-SQL: PB’s 10s to 100s Some Yes, for cost HawQ,, Aster Data, and bandwidth Impala, … No-SQL: Trilions 10s to 100s Some Yes, for cost Cassandra, hBase, … Of rows and availability In-Memory: Billions of 10s-100s Yes Primarily Redis, Gemfire, rows Memory Membase, … 13
- 14. Big Data Virtual Infrastructure 14
- 15. Virtualization enables a Common Infrastructure for Big Data MPP DB HBase Hadoop Virtualization Platform Virtualization Platform Hadoop HBase Cluster Consolidation Scaleout SQL ! Simplify • Single Hardware Infrastructure Cluster Sprawling • Unified operations Single purpose clusters for various business applications lead to cluster ! Optimize sprawl. • Shared Resources = higher utilization • Elastic resources = faster on-demand access 15
- 16. Native versus Virtual Platforms, 24 hosts, 12 disks/host 450 Elapsed time, seconds (lower is better) 400 350 Native 1 VM 300 2 VMs 4 VMs 250 200 Native versus Virtual Platforms, 24 hosts, 12 150 disks/host 100 50 0 TeraGen TeraSort TeraValidate 16
- 17. Why Virtualize Hadoop? Simple to Operate Highly Available Mixed Workloads ! Rapid deployment ! No more single point of ! Shrink and expand failure cluster on demand ! Unified operations across enterprise ! One click to setup ! Resource Guarantee ! Easy Clone of Cluster ! High availability for MR ! Independent scaling of Jobs Compute and data 17
- 18. In-house Hadoop as a Service “Enterprise EMR” – (Hadoop + Hadoop) Production Ad hoc ETL of log files data mining Compute Production layer recommendation engine Data HDFS HDFS layer Virtualization platform Host Host Host Host Host Host 18
- 19. Integrated Hadoop and Webapps – (Hadoop + Other Workloads) Short-lived Hadoop compute cluster Compute Hadoop layer compute cluster Web servers for ecommerce site Data HDFS layer Virtualization platform Host Host Host Host Host Host 19
- 20. Integrated Big Data Production – (Hadoop + other big data) Hadoop batch analysis Compute HBase Big SQL – Other layer real-time queries Impala NoSQL – Spark, Shark, Cassandra, Solr, Mongo, etc Platfora, Etc,… Data HDFS layer Virtualization Host Host Host Host Host Host Host 20
- 21. Serengeti: Deploy a Hadoop Cluster in under 30 Minutes Step 1: Deploy Serengeti virtual appliance on vSphere. Deploy vHelperOVF to vSphere Step 2: A few simple commands to stand up Hadoop Cluster. Select Compute, memory, storage and network Select configuration template Automate deployment Done 21
- 22. Why Virtualize Hadoop? Simple to Operate Highly Available Mixed Workloads ! Rapid deployment ! No more single point of ! Shrink and expand failure cluster on demand ! Unified operations across enterprise ! One click to setup ! Resource Guarantee ! Easy Clone of Cluster ! High availability for MR ! Independent scaling of Jobs Compute and data 22
- 23. vMotion, HA, FT enables High Availability for the Hadoop Stack ETL Tools BI Reporting RDBMS Pig (Data Flow) Hive (SQL) HCatalog Zookeepr (Coordination) Hive Hcatalog MDB MetaDB Management Server MapReduce (Job Scheduling/Execution System) HBase (Key-Value store) Jobtracker Namenode HDFS (Hadoop Distributed File System) Server 23
- 24. Why Virtualize Hadoop? Simple to Operate Highly Available Mixed Workloads ! Rapid deployment ! No more single point of ! Shrink and expand failure cluster on demand ! Unified operations across enterprise ! One click to setup ! Resource Guarantee ! Easy Clone of Cluster ! High availability for MR ! Independent scaling of Jobs Compute and data 24
- 25. Containers with Isolation are a Tried and Tested Approach Reckless Workload 2 Hungry Workload 1 Nosy Workload 3 vSphere, DRS Host Host Host Host Host Host Host 25
- 26. Mixing Workloads: Three big types of Isolation are Required ! Resource Isolation • Control the greedy noisy neighbor • Reserve resources to meet needs ! Version Isolation • Allow concurrent OS, App, Distro versions ! Security Isolation • Provide privacy between users/groups • Runtime and data privacy required vSphere, DRS Host Host Host Host Host Host Host 26
- 27. Elasticity Enables Sharing of Resources 27
- 28. “Time Share” Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop vHelper VMware vSphere Host Host Host HDFS HDFS HDFS While existing apps run during the day to support business operations, Hadoop batch jobs kicks off at night to conduct deep analysis of data. 28
- 29. Big Data Impact to Storage 29
- 30. Traditional Storage – VMDK’s on SAN/NAS App VM DB VM • VMs have just a few self-contained VMDKs • Data is not shared between VMs • VMs have limited individual bandwidth needs Boot Boot Data VMDK VMDK VMDK (block) (block) (block) VMFS VMCB (SAN or NFS) VM Level Archive EMC NTAP Archive 30
- 31. Rapid Growth of Big Data Capacity Necessitates New storage Exabytes of information stored 20 Zetta by 2015 1 Yotta by 2030 Yes, you are part of the yotta audio( generation… digital(tv( digital(photos( camera(phones,(rfid( medical(imaging,(sensors( satellite(images,(logs,(scanners,(twi7er( cad/cam,(appliances,(machine(data,(digital(movies( Source: The Information Explosion, 2009 31
- 32. Use Local Disk where it’s Needed SAN Storage NAS Filers Local Storage $2 - $10/Gigabyte $1 - $5/Gigabyte $0.05/Gigabyte $1M gets: $1M gets: $1M gets: 0.5Petabytes 1 Petabyte 10 Petabytes 200,000 Disk IOPS 200,000 Disk IOPS 400,000 Disk IOPS 8Gbyte/sec 10Gbyte/sec 250 Gbytes/sec 32
- 33. Storage Economics $5.50 $5.00 Traditional $4.50 SAN/NAS $4.00 $3.50 VMware $3.00 vSAN $2.50 Cost per GB $2.00 $1.50 $1.00 Distributed $0.50 Object $- Storage 0.5 1 2 4 8 16 32 64 128 Petabytes Deployed HDFS MAPR Scale-out NAS CEPH Isilon, NTAP 33
- 34. Scalable Storage Architecture: Hadoop Demands Compute Compute Compute Compute Compute Compute Compute Compute Compute Compute Compute Compute Data Node Data Node Data Node Data Node ! Each node needs approximately ~1 disk of bandwidth per core • 16 core node needs ~1GByte/sec of bandwidth ! A 1,000 node Hadoop cluster needs 1Terabyte/sec of bandwidth • Local disks: $800 of local disks per node • Traditional SAN: Would require an est. $50k of SAN storage per node 34
- 35. Storage-Servers: Configurations and Capabilities 16-24 core server 12-24 SATA 2-4TB Disks 10 GbE adapter Typical Storage Server Throughput: 2.5Gbytes/sec Capacity: 96TB 16-24 core server 80 SATA 2-4TB Disks 10 GbE adapter Throughput: 2.5Gbytes/sec High Capacity Server Capacity: 320TB 35
- 36. Scalable Storage Bandwidth is Important for Big Data 120 100 80 GBytes/sec 60 Scalable Storage Single SAN/NAS 40 20 0 1 10 20 30 40 50 # Hosts 36
- 37. Hadoop has Significant Ephemeral Data Map%Task% Reduce% Map%Task% Job% Map% Reduce% Sort% Map%Task% Output% file.out* Spills% Map%Task% DFS% Spills% &%Logs% % Shuffle% Map_*.out* Input% Data% spill*.out* 75%%of% Combine% DFS% Intermediate.out* Output% % Disk%Bandwidth% % Data% 12%%of% 12%%of% Bandwidth% Bandwidth% HDFS% 37
- 38. Impact of Temporary Data ! Leverage local-disks when shared-storage is used • As much as 75% of the bandwidth will be transient • No-need for reliable, replicated storage • Just use unprotected local-disk Temporary Data (Local Disks) Shared Data (Shared, Network Storage) HDFS% 38
- 39. Extend Virtual Storage Architecture to Include Local Disk ! Shared Storage: SAN or NAS ! Hybrid Storage • Easy to provision • SAN for boot images, VMs, other • Automated cluster rebalancing workloads • Local disk for Hadoop & HDFS • Scalable Bandwidth, Lower Cost/GB Other VM Other VM Other VM Other VM Other VM Other VM Other VM Other VM Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop Hadoop Host Host Host Host Host Host 39
- 40. Scale-out Storage for Big Data: Local Disk or Scale-out-NAS Servers with Big-Data using Scale-out NAS Local Disks Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Host% Host% Host% Host% Host% Temp Host% Data Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Scale<out% Scale<out% Shared NAS% NAS% Data 40
- 41. Big-Data using Local Disks Servers with Local Disks High Performance 10GBE Top%of%Rack%Switch% Switch per Rack Host% Host% Host% 16-24 core server Host% 12-24 SATA 2-4TB Disks 10 GbE adapter Host% iSCSI/NFS for Shared Storage for vMotion etc,… Host% Host% 41
- 42. Big Data with Scale-out-NAS Big-Data using Scale-out NAS Top%of%Rack%Switch% Top%of%Rack%Switch% Local Host% Host% Disk or SSD Temp In each Host Host% Host% Data For Transient Data Host% Host% Host% Host% Host% Host% Host% Host% Isilon Shared Scale<out% Scale<out% Scale-out NAS% NAS% Data NAS 42
- 43. Big Data Impact to Networking 43
- 44. Hadoop has Specific Network Demands that must be Considered ! A framework for distributed processing of large data sets across clusters of computers using a simple programming model. Source: http://architects.dzone.com/articles/how-hadoop-mapreduce-works 44
- 45. A Typical Network Architecture AggregaQng% AggregaQng% Switch% Switch% L2%Switch% L2%Switch% L2%Switch% L2%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% Host% 45
- 46. A Typical Network Architecture ! Hadoop Requirements AggregaQng% AggregaQng% Switch% Switch% • Hadoop can generate up to 200mbits per core of network traffic • Bursts of bandwidth during remote data read and shuffle phases L2%Switch% L2%Switch% L2%Switch% L2%Switch% • Data locality can help minimize net reads, but shuffle and reduce are global ! Inside Rack Network • Today’s core-counts require 10GBe to hostsTop%of%Rack%Switch% inside Rack Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% • High throughput switches required to meet aggregate bandwidth • Switch Network Buffers sizing is important due to coordinated burstsHost% Host% Host% Host% ! Rack-to-rack Network Host% Host% Host% Host% • Two level switch aggregation can be a bottleneck Host% Host% Host% Host% • Easy to saturate, especially during shuffle phases ! Link-Speed Sizing • Hadoop originally designedHost% Host% around 4 cores, 1Gbit uplink Host% Host% • Now, 16-24 cores per box means 10Gbe is required for uplink 46
- 47. Two Level Aggregated Network Characteristics AggregaQng% AggregaQng% Switch% Switch% L2%Switch% L2%Switch% L2%Switch% L2%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Top%of%Rack%Switch% Between Racks: Top of Rack: Host% Host% Bandwidth can be saturated Host% Host% Overprovisioning Possible Host% Host% 10Gbe High End Switch Host% Host% >500Gbits/sec Host% Host% Host% Host% Host% Host% Host% Host% 47
- 48. Future Network Designs, optimized for Big-Data Traditional Tree-structured Clos network between Aggregation and networks Intermediate (core) switches LA – (physical) Locator address AA – (flat, virtual) Application address Cons: High oversubscription Pros: full-bisection bandwidth, of upper-level (Aggregation) non-blocking switching fabric, and core switches. Hard to path diversity! Formalized in 1953 get full-bisection bandwidth Images courtesy Greenberg et al.:http://research.microsoft.com/pubs/80693/vl2-sigcomm09-final.pdf and http://www.stanford.edu/class/ee384y/Handouts/clos_networks.pdf 48
- 49. In Conclusion ! Software Defined Datacenter enables Unified Big Data Platform ! Plan to build a Software Defined “Big Data”, Datacenter • Enable Hadoop and other Big-Data ecosystem components ! Values • Consolidated Hardware, reduced SKU • Higher Utilization: Can leverage a shared cluster for bursty workloads • Rapid Deployment: Use APIs to deploy software-defined clusters rapidly • Flexible Cluster Use: Share the same infrastructure for different workload types ! References www.projectserengeti.org vmware.com/hadoop VMware Hadoop Performance Whitepaper VMware Hadoop HA/FT Paper 49
- 50. Big Data in a Software-Defined Datacenter Richard McDougall Chief Architect, Storage and Application Services VMware, Inc @richardmcdougll © 2009 VMware Inc. All rights reserved