BigDataCloud meetup - July 8th - Cost effective big-data processing using Amazon EMR- Presentation by Sujee
2 likes796 views

This document discusses using Amazon Elastic MapReduce (EMR) for cost-effective big data processing. It describes the author's experience using EMR to process 1TB of log data per week for a startup. Key advantages of EMR include only paying for usage, no hardware to maintain, and ability to customize cluster resources for different jobs. The author outlines best practices learned, such as splitting logs by type and processing in smaller windows, as well as next steps like using spot instances and NoSQL for improved performance and cost savings.



















































![Lessons learned : Logfile formatCSV JSONStarted with CSVCSV: "2","26","3","07807606-7637-41c0-9bc0-8d392ac73b42","MTY4Mjk2NDk0eDAuNDk4IDEyODQwMTkyMDB4LTM0MTk3OTg2Ng","2010-09-09 03:59:56:000 EDT","70.68.3.116","908105","http://housemdvideos.com/seasons/video.php?s=01&e=07","908105","160x600","performance","25","ca","housemdvideos.com","1","1.2840192E9","0","221","0.60000","NULL","NULL20-40 fields… fragile, position dependant, hard to code url = csv[18]…counting position numbers gets old after 100th time around)If (csv.length == 29) url = csv[28] else url = csv[26]JSON: { exchange_id: 2, url : “http://housemdvideos.com/seasons/video.php?s=01&e=07”….}Self-describing, easy to add new fields, easy to processurl = map.get(‘url’)](https://image.slidesharecdn.com/bigdatacloudmeetup-july8th-costeffectivebig-dataprocessingusingamazonelasticmapreduce-presentationbysujee-110710125617-phpapp01/85/BigDataCloud-meetup-July-8th-Cost-effective-big-data-processing-using-Amazon-EMR-Presentation-by-Sujee-57-320.jpg)












BigDataCloud meetup - July 8th - Cost effective big-data processing using Amazon EMR- Presentation by Sujee
- 1. ‘Amazon EMR’ coming up…by Sujee Maniyam
- 2. Big Data Cloud MeetupCost Effective Big-Data Processing using Amazon Elastic Map ReduceSujee Maniyamhello@sujee.net | www.sujee.netJuly 08, 2011
- 3. Cost Effective Big-Data Processing using Amazon Elastic Map ReduceSujee Maniyamhttp://sujee.nethello@sujee.net
- 4. QuizPRIZE!Where was this picture taken?
- 5. Quiz : Where was this picture taken?
- 6. Answer : Montara Light House
- 7. Hi, I’m Sujee10+ years of software developmententerprise apps web apps iphone apps HadoopHands on experience with Hadoop / Hbase/ Amazon ‘cloud’More : http://sujee.net/tech
- 8. I am an ‘expert’
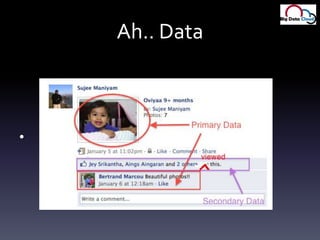
- 9. Ah.. Data
- 10. Nature of Data…Primary DataEmail, blogs, pictures, tweetsCritical for operation (Gmail can’t loose emails)Secondary dataWikipedia access logs, Google search logsNot ‘critical’, but used to ‘enhance’ user experienceSearch logs help predict ‘trends’Yelp can figure out you like Chinese food
- 11. Data ExplosionPrimary data has grown phenomenallyBut secondary data has exploded in recent years“log every thing and ask questions later”Used forRecommendations (books, restaurants ..etc)Predict trends (job skills in demand)Show ADS ($$$)..etc‘Big Data’ is no longer just a problem for BigGuys (Google / Facebook)Startups are struggling to get on top of ‘big data’
- 12. Hadoop to RescueHadoop can help with BigDataHadoop has been proven in the fieldUnder active developmentThrow hardware at the problemGetting cheaper by the yearBleeding edge technologyHire good people!
- 13. Hadoop: It is a CAREER
- 14. Data Spectrum
- 15. Who is Using Hadoop?
- 16. Big Guys
- 17. Startups
- 19. About This PresentationBased on my experience with a startup5 people (3 Engineers)Ad-Serving SpaceAmazon EC2 is our ‘data center’Technologies:Web stack : Python, Tornado, PHP, mysql , LAMPAmazon EMR to crunch dataData size : 1 TB / week
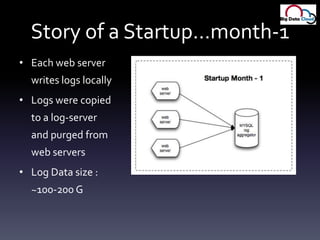
- 20. Story of a Startup…month-1Each web serverwrites logs locallyLogs were copiedto a log-serverand purged from web serversLog Data size : ~100-200 G
- 21. Story of a Startup…month-6More web servers comeonlineAggregate log serverfalls behind
- 22. Data @ 6 months2 TB of data already50-100 G new data / day And we were operating on 20% of our capacity!
- 23. Future…
- 24. Solution?Scalable database (NOSQL)HbaseCassandraHadoop log processing / Map Reduce
- 25. What We Evaluated1) Hbase cluster2) Hadoop cluster3) Amazon EMR
- 26. Hadoop on Amazon EC21) Permanent Cluster2) On demand cluster (elastic map reduce)
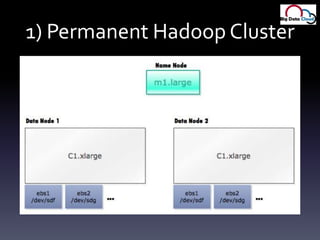
- 27. 1) Permanent Hadoop Cluster
- 28. Architecture 1
- 29. Hadoop Cluster7 C1.xlarge machines15 TB EBS volumesSqoop exports mysql log tables into HDFSLogs are compressed (gz) to minimize disk usage (data locality trade-off)All is working well…
- 30. Lessons LearnedC1.xlarge is pretty stable (8 core / 8G memory)EBS volumesmax size 1TB, so string few for higher density / nodeDON’T RAID them; let hadoop handle them as individual disks?? : Skip EBS. Use instance store disks, and store data in S3
- 32. 2 months laterCouple of EBS volumes DIECouple of EC2 instances DIEMaintaining the hadoop cluster is mechanical job less appealingCOST!Our jobs utilization is about 50%But still paying for machines running 24x7
- 33. Amazon EC2 Cost
- 34. Hadoop cluster on EC2 cost$3,500 = 7 c1.xlarge @ $500 / month$1,500 = 15 TB EBS storage @ $0.10 per GB$ 500 = EBS I/O requests @ $0.10 per 1 million I/O requests $5,500 / month$60,000 / year !
- 35. Buy / Rent ?Typical hadoop machine cost : $10k10 node cluster = $100k Plus data center costsPlus IT-ops costsAmazon Ec2 10 node cluster:$500 * 10 = $5,000 / month = $60k / year
- 36. Buy / RentAmazon EC2 is great, forQuickly getting startedStartupsScaling on demand / rapidly adding more serverspopular social gamesNetflix storyStreaming is powered by EC2Encoding movies ..etcUse 1000s of instancesNot so economical for running clusters 24x7
- 37. Next : Amazon EMR
- 38. Where was this picture taken?
- 39. Answer : Pacifica Pier
- 40. Amazon’s solution : Elastic Map ReduceStore data on Amazon S3Kick off a hadoop cluster to process dataShutdown when donePay for the HOURS used
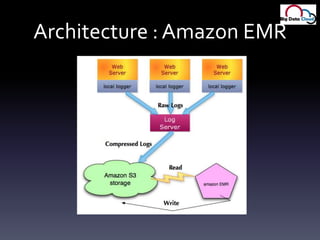
- 41. Architecture : Amazon EMR
- 42. Moving partsLogs go into ScribeScribe master ships logs into S3, gzippedSpin EMR cluster, run job, doneUsing same old Java MR jobs for EMRSummary data gets directly updated to a mysql
- 43. EMR Launch Scriptsscripts to launch jar EMR jobsCustom parameters depending on job needs (instance types, size of cluster ..etc)monitor job progressSave logs for later inspectionJob status (finished / cancelled)https://github.com/sujee/amazon-emr-beyond-basics
- 44. Sample Launch Script#!/bin/bash## run-sitestats4.sh# configMASTER_INSTANCE_TYPE="m1.large"SLAVE_INSTANCE_TYPE="c1.xlarge"INSTANCES=5export JOBNAME="SiteStats4"export TIMESTAMP=$(date +%Y%m%d-%H%M%S)# end configecho "==========================================="echo $(date +%Y%m%d.%H%M%S) " > $0 : starting...."export t1=$(date +%s)export JOBID=$(elastic-mapreduce --plain-output --create --name "${JOBNAME}__${TIMESTAMP}" --num-instances "$INSTANCES" --master-instance-type "$MASTER_INSTANCE_TYPE" --slave-instance-type "$SLAVE_INSTANCE_TYPE" --jar s3://my_bucket/jars/adp.jar --main-class com.adpredictive.hadoop.mr.SiteStats4 --arg s3://my_bucket/jars/sitestats4-prod.config --log-uri s3://my_bucket/emr-logs/ --bootstrap-action s3://elasticmapreduce/bootstrap-actions/configure-hadoop --args "--core-config-file,s3://my_bucket/jars/core-site.xml,--mapred-config-file,s3://my_bucket/jars/mapred-site.xml”)sh ./emr-wait-for-completion.sh
- 45. Mapred-config-m1-xl.xml <?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx1024M</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx3000M</value> </property> <property> <name>mapred.tasktracker.reduce.tasks.maximum</name> <value>3</value> <decription>4 is running out of memory</description> </property><property> <name>mapred.output.compress</name> <value>true</value></property> <property> <name>mapred.output.compression.type</name> <value>BLOCK</value> </property></configuration>
- 46. emr-wait-for-completion.shPolls for job status periodicallySaves the logs Calculates job run time
- 47. Saved Logs
- 48. Sample Saved Log
- 49. Data joining (x-ref)Data is split across log files, need to x-ref during Map phaseUsed to load the data in mapper’s memory (data was small and in mysql)Now we use Membase (Memcached)Two MR jobs are chainedFirst one processes logfile_type_A and populates Membase (very quick, takes minutes)Second one, processes logfile_type_B, cross-references values from Membase
- 50. X-ref
- 51. EMR WinsCost only pay for usehttp://aws.amazon.com/elasticmapreduce/pricing/Example: EMR ran on 5 C1.xlarge for 3hrsEC2 instances for 3 hrs = $0.68 per hr x 5 inst x 3 hrs = $10.20http://aws.amazon.com/elasticmapreduce/faqs/#billing-4(1 hour of c1.xlarge = 8 hours normalized compute time)EMR cost = 5 instances x 3 hrs x 8 normalized hrs x 0.12 emr = $14.40Plus S3 storage cost : 1TB / month = $150Data bandwidth from S3 to EC2 is FREE! $25 bucks
- 52. EMR WinsNo hadoop cluster to maintainno failed nodes / disksBonus : Can tailor cluster for various jobssmaller jobs fewer number of machinesmemory hungry tasks m1.xlargecpu hungry tasks c1.xlarge
- 53. Design WinsBidders now write logs to Scribe directly No mysql at web server machinesWrites much faster!S3 has been a reliable storage and cheap
- 54. Next : Lessons Learned
- 55. Where was this pic taken?
- 56. Answer : Foster City
- 57. Lessons learned : Logfile formatCSV JSONStarted with CSVCSV: "2","26","3","07807606-7637-41c0-9bc0-8d392ac73b42","MTY4Mjk2NDk0eDAuNDk4IDEyODQwMTkyMDB4LTM0MTk3OTg2Ng","2010-09-09 03:59:56:000 EDT","70.68.3.116","908105","http://housemdvideos.com/seasons/video.php?s=01&e=07","908105","160x600","performance","25","ca","housemdvideos.com","1","1.2840192E9","0","221","0.60000","NULL","NULL20-40 fields… fragile, position dependant, hard to code url = csv[18]…counting position numbers gets old after 100th time around)If (csv.length == 29) url = csv[28] else url = csv[26]JSON: { exchange_id: 2, url : “http://housemdvideos.com/seasons/video.php?s=01&e=07”….}Self-describing, easy to add new fields, easy to processurl = map.get(‘url’)
- 58. Lessons Learned : Control the amount of InputWe get different type of eventsevent A (freq: 10,000) >>> event B (100) >> event C (1)Initially we put them all into a single log fileAAAABAABC
- 59. Control Input…So have to process the entire file, even if we are interested only in ‘event C’ too much wasted processingSo we split the logslog_A….gzlog_B….gzlog_C…gzNow only processing fraction of our logsInput : s3://my_bucket/logs/log_B*x-ref using memcache if needed
- 60. Lessons learned : Incremental Log ProcessingRecent data (today / yesterday / this week) is more relevant than older data (6 months +)Adding ‘time window’ to our statsonly process newer logs faster
- 61. EMR trade-offsLower performance on MR jobs compared to a clusterReduced data throughput (S3 isn’t the same as local disk)Streaming data from S3, for each jobEMR Hadoop is not the latest versionMissing tools : OozieRight now, trading performance for convenience and cost
- 62. Next steps : faster processingStreaming S3 data for each MR job is not optimalSpin clusterCopy data from S3 to HDFSRun all MR jobs (make use of data locality)terminate
- 63. Next Steps : More ProcessingMore MR jobsMore frequent data processingFrequent log rollsSmaller delta window
- 64. Next steps : new software New SoftwarePython, mrJOB(from Yelp)Scribe Cloudera flume?Use work flow tools like OozieHive?Adhoc SQL like queries
- 65. Next Steps : SPOT instancesSPOT instances : name your price (ebay style)Been available on EC2 for a whileJust became available for Elastic map reduce!New cluster setup:10 normal instances + 10 spot instancesSpots may go away anytimeThat is fine! Hadoop will handle node failuresBigger cluster : cheaper & faster
- 67. Next Steps : nosqlSummary data goes into mysqlpotential weak-link ( some tables have ~100 million rows and growing)Evaluating nosql solutionsusing Membase in limited capacityWatch out for Amazon’s Hbase offering
- 68. Take a test driveJust bring your credit-card http://aws.amazon.com/elasticmapreduce/Forum : https://forums.aws.amazon.com/forum.jspa?forumID=52