Distributed and Fault Tolerant Realtime Computation with Apache Storm, Apache Kafka and Apache Zookeeper
Download as PPT, PDF1 like1,304 views

Folio3 is a software development company that focuses on building mobile, social, cloud-based, and gamified applications. They have over 200 employees across offices in the US, Canada, Bulgaria, and Pakistan. Folio3 works with enterprise and consumer clients to develop custom applications for areas like mobile, web, social media, and more. They also have expertise in distributed and fault-tolerant real-time computation using Apache Storm.

































Distributed and Fault Tolerant Realtime Computation with Apache Storm, Apache Kafka and Apache Zookeeper
- 1. Distributed and Fault-TolerantDistributed and Fault-Tolerant Realtime ComputationRealtime Computation www.folio3.com@folio_3
- 2. Folio3 – OverviewFolio3 – Overview www.folio3.com @folio_3
- 3. Who We Are We are a Development Partner for our customers Design software solutions, not just implement them Focus on the solution – Platform and technology agnostic Expertise in building applications that are: Mobile Social Cloud-based Gamified
- 4. What We Do Areas of Focus Enterprise Custom enterprise applications Product development targeting the enterprise Mobile Custom mobile apps for iOS, Android, Windows Phone, BB OS Mobile platform (server-to-server) development Social Media CMS based websites for consumers and enterprise (corporate, consumer, community & social networking) Social media platform development (enterprise & consumer)
- 5. Folio3 At a Glance Founded in 2005 Over 200 full time employees Offices in the US, Canada, Bulgaria & Pakistan Palo Alto, CA. Sofia, Bulgaria Karachi, Pakistan Toronto, Canada
- 6. Areas of Focus: Enterprise Automating workflows Cloud based solutions Application integration Platform development Healthcare Mobile Enterprise Digital Media Supply Chain
- 7. Some of Our Enterprise Clients
- 8. Areas of Focus: Mobile Serious enterprise applications for Banks, Businesses Fun consumer apps for app discovery, interaction, exercise gamification and play Educational apps Augmented Reality apps Mobile Platforms
- 9. Some of Our Mobile Clients
- 10. Areas of Focus: Web & Social Media Community Sites based on Content Management Systems Enterprise Social Networking Social Games for Facebook & Mobile Companion Apps for games
- 11. Some of Our Web Clients
- 12. www.folio3.com @folio_3 Distributed and Fault-TolerantDistributed and Fault-Tolerant Realtime ComputationRealtime Computation
- 13. Agenda Big Data Hadoop Vs Storm Lambda Architecture Storm Architecture And Concepts
- 14. Big Data To understand “Big Data”, it has four dimensions : Volume : Scale of Data (terabytes, petabytes, exabytes) Velocity : Need to be analyzed quickly (milliseconds to seconds to respond) Variety : Different forms of Data (& Data Sources) Veracity : Uncertainty of Data (due to data inconsistency, ambiguities, latency, data incompleteness)
- 15. Example Query Total Number of Page Views To A Website URL over a range of time
- 16. Example Query function pageViewsOverTime(bigData, url, startTime, endTime) { int count = 0; for (data : bigData) { if ( data.url == url && data.timestamp >= startTime && data.timestamp <= endTime ) { count ++; } } return count; }
- 17. Example Query TOO SLOW : Big Data is in petabytes (Volume)
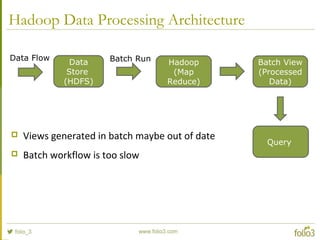
- 18. Hadoop Data Processing Architecture Data Store (HDFS) Hadoop (Map Reduce) Batch View (Processed Data) Query Views generated in batch maybe out of date Batch workflow is too slow Data Flow Batch Run
- 20. Immutable Master Dataset ( stored in HDFS)
- 21. What is Apache Storm ? Storm is a real-time distributed computing framework for reliably processing large volumes of high velocity unbounded data streams. It was created by Nathan Marz and his team at BackType, and released as open source in 2011(after BackType was acquired by Twitter)
- 22. Five characteristics make Storm ideal for real-time data processing workloads. Fast – benchmarked at processing one million+ 100 byte messages per second per node Scalable – with parallel calculations that run across a cluster of machines Fault-tolerant – when workers die, Storm will automatically restart them. If a node dies, the work will be restarted on another node. Reliable – Storm guarantees that each unit of data (tuple) will be processed at least once or exactly once. Messages are only replayed when there are failures. Easy to operate – standard configurations are suitable for production on day one. Once deployed, Storm is easy to operate.
- 23. Tweet from Nathan Marz (31 May 2012)
- 24. Storm Topology The input stream of a Storm cluster is handled by a component called a Spout. The spout passes the to a component called a Bolt, which transforms it in some way. A Bolt either persists the data in storage, or passes it to some other bolt.
- 26. Sample Problem … Thus the heavens and the earth were finished, and all the host of them. And on the seventh day God ended his work which he had made and he rested on the seventh day from all his work which he had made… File : Bible.txt (“thus”, “the”, “heavens”, “and”, “the”, “earth”, “were”, “finished” “and”, “all”, “the”, “host”, “of”, “them”) {“Thus the heavens and the earth were finished, and all the host of them.”} {“And on the seventh day God ended his work which he had made”} ( (“testaments”, 10), (“holy”, 12), (“faith”, 34) ) f g h
- 27. Relationship of Storm Topology with Functional Programming BoltBolt BoltBoltSpoutSpoutData f g h Line-reader Word-Splitter Word-Counter
- 28. Data Source Reliability A data source is considered “unreliable”, if there is no means to replay a message. A data source is considered “reliable” if it can somehow replay a message if processing fails at any point. A data source is considered “durable” if it can replay any message or set of messages given the necessary selection criteria.
- 29. Reliability Limitations: Integrating Kafka with Apache Storm Exactly once processing requires a “durable” data source. At least once processing requires a “reliable” data source. An “unreliable” data source can be wrapped to provide additional guarantees. For Apache Storm (demo), I’ve backed up unreliable data source with Apache Kafka (minor latency overhead to ensure 100% durability).
- 30. Relationship of Storm Topology with Functional Programming BoltBolt BoltBoltSpoutSpout Data f g h Storm Spout subscribed to topic bible of kafka messaging queue Word-Splitter Word-CounterTopic: bible …5|4|3|2|1 Line-reader
- 31. Scenarios / Use cases where Storm can be effectively used Predictive Analysis Social Graph Analysis Network Monitoring Recommendation Engine Realtime Analytics Online Machine Learning Continuous Computation Distributed Remote Procedure Call Website Activity Tracking Log Aggregation
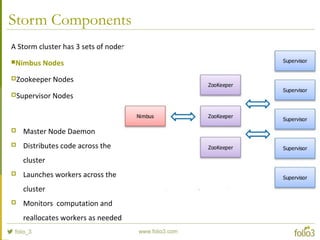
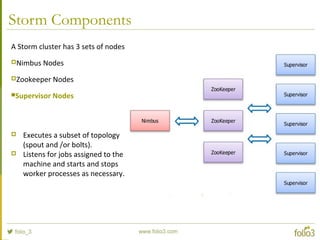
- 32. Storm Components A Storm cluster has 3 sets of nodes Nimbus Nodes Zookeeper Nodes Supervisor Nodes
- 33. Storm Components A Storm cluster has 3 sets of nodes Nimbus Nodes Zookeeper Nodes Supervisor Nodes Master Node Daemon Distributes code across the cluster Launches workers across the cluster Monitors computation and reallocates workers as needed
- 34. Storm Components A Storm cluster has 3 sets of nodes Nimbus Nodes Zookeeper Nodes Supervisor Nodes Manages all the coordination between Nimbus and the supervisors.
- 35. Storm Components A Storm cluster has 3 sets of nodes Nimbus Nodes Zookeeper Nodes Supervisor Nodes Executes a subset of topology (spout and /or bolts). Listens for jobs assigned to the machine and starts and stops worker processes as necessary.
- 36. Known Limitations: Nimbus : A single point of failure When Nimbus is down : Topologies continue to work Tasks from failing nodes (Spouts/Bolts) aren’t replayed Can’t upload a new topology or rebalance an old one It is recommended to run Nimbus under daemon tool or monit so that it could be restarted automatically when it is down. (In contrast to Hadoop, if the Job Tracker dies, all the running jobs are lost)
- 37. Contact For more details about our services, please get in touch with us. contact@folio3.com US Office: (408) 365-4638 www.folio3.com