![CloudFundoo 2012
Distributed Hash Tables and Consistent
Hashing
DHT(Distributed Hash Table) is one of the fundamental algorithms
used in distributed scalable systems; it is used in web caching, P2P
systems, distributed file systems etc.
First step in understanding DHT is Hash Tables. Hash tables need
key, value and a hash function, where hash function maps the key to a
location where the value is stored.
Keys Hash Function Stored Values
Key1 Value3
Key2 Value4
Key3 Value1
Value2
Key4
value = hashfunc(key)
Python’s dictionary data type is implemented using hashing, see the
example below.
1. #!/usr/bin/python
2.
3. dict = {'Name': 'Zara', 'Age': 11, 'Class': 'First'};
1
4.
5. dict['Age'] = 12;
6. dict['School'] = "State School";
7.
Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/](https://image.slidesharecdn.com/distributedhashtableandconsistenthashing-120526081412-phpapp02/85/Distributed-Hash-Table-and-Consistent-Hashing-1-320.jpg)
![CloudFundoo 2012
8.
9. print "dict['Age']: ", dict['Age'];
10. print "dict['School']: ", dict['School'];
If we have a perfect hash function we will get an O (1) performance
i.e. constant time performance out of hash table while searching for a
(key, value) pair, this is because hash function distributes the keys
evenly across the table. One of the problem with hashing is it requires
lot of memory (or space) to accommodate the entire table, even if
most of the table is empty we need to allocate memory for entire
table, so there is waste of memory most of the time. This is called as
time-space tradeoff, hashing gives best time for search at the expense
of memory.
When we want to accommodate large number of keys (millions and
millions, say for the case of a cloud storage system), we will have to
divide keys in to subsets, and map those subsets of keys to a bucket,
each bucket can reside in a separate machine/node. You can assume
bucket as a separate hash table.
Distributed Hash Table
Using buckets to distribute the (key, value) pair is called DHT.
A simple scheme to implement DHT is by using modulus operation
on key i.e. your hash function is key mod n, where n is the number of
buckets you have.
Key Space
K1 Kn/3 K2n/3 Kn
2
Bucket 1 Bucket 2 Bucket 3
Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/](https://image.slidesharecdn.com/distributedhashtableandconsistenthashing-120526081412-phpapp02/85/Distributed-Hash-Table-and-Consistent-Hashing-2-320.jpg)




Distributed Hash Table and Consistent Hashing
- 1. CloudFundoo 2012 Distributed Hash Tables and Consistent Hashing DHT(Distributed Hash Table) is one of the fundamental algorithms used in distributed scalable systems; it is used in web caching, P2P systems, distributed file systems etc. First step in understanding DHT is Hash Tables. Hash tables need key, value and a hash function, where hash function maps the key to a location where the value is stored. Keys Hash Function Stored Values Key1 Value3 Key2 Value4 Key3 Value1 Value2 Key4 value = hashfunc(key) Python’s dictionary data type is implemented using hashing, see the example below. 1. #!/usr/bin/python 2. 3. dict = {'Name': 'Zara', 'Age': 11, 'Class': 'First'}; 1 4. 5. dict['Age'] = 12; 6. dict['School'] = "State School"; 7. Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
- 2. CloudFundoo 2012 8. 9. print "dict['Age']: ", dict['Age']; 10. print "dict['School']: ", dict['School']; If we have a perfect hash function we will get an O (1) performance i.e. constant time performance out of hash table while searching for a (key, value) pair, this is because hash function distributes the keys evenly across the table. One of the problem with hashing is it requires lot of memory (or space) to accommodate the entire table, even if most of the table is empty we need to allocate memory for entire table, so there is waste of memory most of the time. This is called as time-space tradeoff, hashing gives best time for search at the expense of memory. When we want to accommodate large number of keys (millions and millions, say for the case of a cloud storage system), we will have to divide keys in to subsets, and map those subsets of keys to a bucket, each bucket can reside in a separate machine/node. You can assume bucket as a separate hash table. Distributed Hash Table Using buckets to distribute the (key, value) pair is called DHT. A simple scheme to implement DHT is by using modulus operation on key i.e. your hash function is key mod n, where n is the number of buckets you have. Key Space K1 Kn/3 K2n/3 Kn 2 Bucket 1 Bucket 2 Bucket 3 Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
- 3. CloudFundoo 2012 If you have 6 buckets then, key = 1 will go to bucket 1 since key % 6 = 1, key=2 will go to bucket 2 since key % 6 = 2 and so on. We will need a second hashing to find the actual (key, value) pair inside a particular bucket. We can use two dictionaries to visualize DHT; here each row in Client/Proxy dictionary is equivalent to a bucket in DHT. Bucket 1 Client/Proxy Bucket 3 Bucket 0 3 This scheme will work perfectly fine as long as we don’t change the number of buckets. This scheme starts to fail when we add/remove Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
- 4. CloudFundoo 2012 buckets to/from the system. Lets add one more bucket to the system, the number of buckets is now equal to seven, i.e. n=7. The key = 7 which was previously mapped to bucket 1 now map to bucket 0 since key % 7 is equal to 0. In order to make it still work we need to move the data between buckets, which is going to be expensive in this hashing scheme. Let’s do some calculation, consider modulo hash function, h(key) = key mod n Where n is the number of buckets, when we increase the number of buckets by one, the hash function becomes h(key) = key mod (n+1) Because of the addition of a new bucket, most of keys will hash to a different bucket, let’s calculate the ratio of keys moving to different bucket, K–n keys will move to a different bucket if keys are in the range 0 to K, only the first n keys will remain in the same buckets. So ratio of keys moving to a different bucket is (K – n)/K = 1- n/K If there are 10 buckets and 1000 keys, then 99% of keys will move to a different bucket when we add another bucket. If we are using python’s hash() or hashlib.md5 hashing functions, then the fraction of keys moving to another bucket is 4 n/(n +1) Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
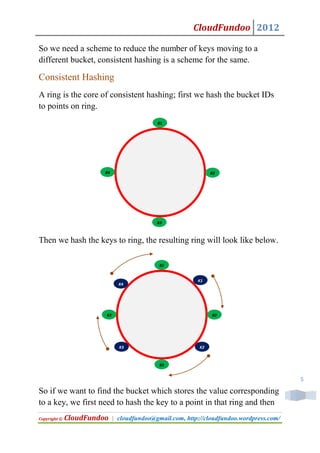
- 5. CloudFundoo 2012 So we need a scheme to reduce the number of keys moving to a different bucket, consistent hashing is a scheme for the same. Consistent Hashing A ring is the core of consistent hashing; first we hash the bucket IDs to points on ring. B1 B4 B2 B3 Then we hash the keys to ring, the resulting ring will look like below. B1 K1 K4 B3 B2 K3 K2 B3 5 So if we want to find the bucket which stores the value corresponding to a key, we first need to hash the key to a point in that ring and then Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
- 6. CloudFundoo 2012 we need to search in the clockwise direction in the ring to find the first bucket in that ring, that bucket will be the one storing the value corresponding to the key. For key K1 value will be stored in bucket B2, for key K2 value will be stored in bucket B3 and so on. Hashing is working fine with this scheme, but we introduced this scheme to handle addition/removal of buckets, let see how it handles this, this is explained in below picture. B1 K4 K1 B3 B2 K3 K2 B3 So if we are removing bucket B3, key K2 seems to have a problem, let’s see how consistent hashing solves this problem, key K2 still hash to the same point in circle, while searching in the clockwise direction it sees no bucket called B3, so searches past B3 in clockwise direction and it will find bucket B4, where value corresponding to key K2 is stored. For other keys there is no problem, all remains same, key K4 in bucket B1, key K1 in bucket B2 etc. So we need to move only the contents of removed bucket to the clockwise adjacent bucket. 6 Let’s see what will happen if we add a bucket, see a slightly modified diagram below. Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
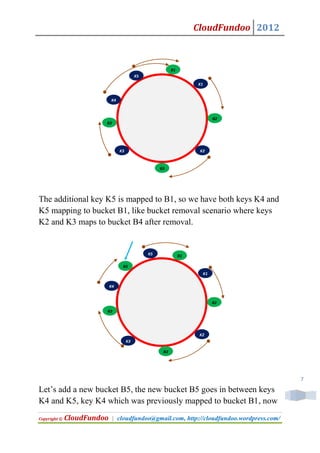
- 7. CloudFundoo 2012 B1 K5 K1 K4 B2 B3 K3 K2 B3 The additional key K5 is mapped to B1, so we have both keys K4 and K5 mapping to bucket B1, like bucket removal scenario where keys K2 and K3 maps to bucket B4 after removal. K5 B1 B5 K1 K4 B2 B3 K2 K3 B3 7 Let’s add a new bucket B5, the new bucket B5 goes in between keys K4 and K5, key K4 which was previously mapped to bucket B1, now Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/
- 8. CloudFundoo 2012 goes to bucket B5 and Key K5 still maps to bucket B1. So only the keys which lie between B4 and B5 should be moved from B1 to B5. On an average the fraction of keys which we need to move between buckets when one bucket is added to the system is given as 1/(n +1) So by introducing consistent hashing we reduced the fraction of keys which we need to move, from n/(n+1) to 1/(n+1), which is significant. There is lot of details to consistent hashing, which is not covered in this. Consistent hashing has a great role in distributed systems like DNS, P2P, distributed storage, and web caching systems etc, OpenStack Swift Storage and Memcached are open source projects which use this to achieve scalability and Availability. <EOF> 8 Copyright © CloudFundoo | cloudfundoo@gmail.com, http://cloudfundoo.wordpress.com/