【DL輪読会】Replacing Labeled Real-Image Datasets With Auto-Generated Contours
Download as PPTX, PDF0 likes235 views

2022/06/17 Deep Learning JP: http://deeplearning.jp/seminar-2/
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Replacing Labeled Real-Image Datasets With Auto-
Generated Contours
Shunsuke Chiba(the university of Tokyo B3)](https://image.slidesharecdn.com/dlp220617chibashunsukev0-220617030537-f76841ee/95/DL-Replacing-Labeled-Real-Image-Datasets-With-Auto-Generated-Contours-1-638.jpg)














【DL輪読会】Replacing Labeled Real-Image Datasets With Auto-Generated Contours
- 1. 1 DEEP LEARNING JP [DL Papers] http://deeplearning.jp/ Replacing Labeled Real-Image Datasets With Auto- Generated Contours Shunsuke Chiba(the university of Tokyo B3)
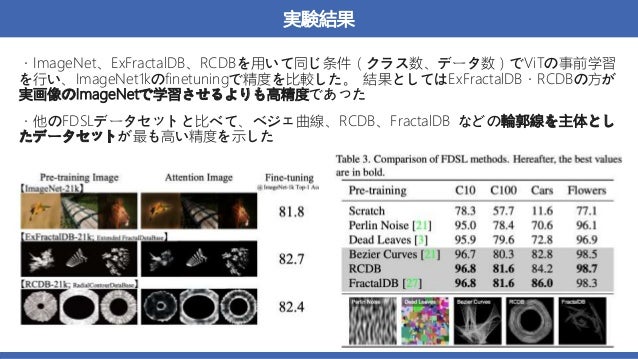
- 2. 書誌情報 著者:Hirokatsu Kataoka, Ryo Hayamizu, Ryosuke Yamada, Kodai Nakashima, Sora Takashima, Xinyu Zhang, Edgar Josafat Martinez-Noriega, Nakamasa Inoue, Rio Yokota,Tsinghua University 2 タ イ ト ル : Replacing Labeled Real-Image Datasets With Auto-Generated Contours カンファレンス:CVPR 2022 ※本資料で使用されている図や画像は特に言及がない限り、本論文または公式サイトからの引用です。 概要:数式から生成された画像を用いた、VisionTransformer(ViT)の事前学習 →実画像を用いて事前学習させた時と同等かそれ以上の精度を達成した
- 6. 先行研究 formula-driven supervised learning(FDSL) Pre-training without Natural Images(2020)では、数式から生成されたフラクタル図形のデー タセットFractalDBを使ってCNNを学習させたところ、実画像に近い精度が観測された 6 出典: https://openaccess.thecvf.com/content/ACCV2020/papers/Kataoka_Pre- training_without_Natural_Images_ACCV_2020_paper.pdf
- 11. 画像データセット
- 14. 実験結果 ViTとFDSLの相性 ResNet ・ gMLP ・ ViT で そ れ ぞ れ FDSLを行ったところ、ViTが最も高 精度であった。 → ViTがFDSLと相性が良いと考えら れる
- 15. まとめ • 数式から生成された画像を用いて学習する 手法FDSLを用いて、ViTを事前学習したと ころ、実画像と同等かそれ以上の精度が観 測された • FDSLデータセットでは、オブジェクトの輪 郭が重要である • FDSLパラメータの数を変化させることで事 前学習の難易度を制御したところ、事前学 習の難易度が高いほどファインチューニン グの精度が高くなった 15
- 16. 個人的な感想・疑問 • 大量の実画像を集められる団体が、一部の企業に偏ってきている現状を踏まえると、本手 法のように誰でも利用できる手法はとても有意義であると感じた • RCDBのデータ数をどこまで増やすことができるのかが、今後この手法が発展するかに影 響してきそう。パラメータを増やして複雑にしていくと事前学習に失敗する例もあったの で、どこかで頭打ちがきてもおかしくない • 結局なぜこの方法で、ドメインが明らかに違うImage Net等に対しても汎化が進むのかが 分からなかった 16