2. 曖昧性推定
2
機械学習システムは様々な分野での社会実装が期待されている
Autonomous Driving[1]
[1] Levinson et al., “Towards Fully Autonomous Driving: Systems and Algorithms”, iEEE, 2011
[2] Miotto et al., “Deep patient: an unsupervised representation to predict the future of patients from the electronic health records”
, 2016
Medical Diagnosis[2]
ミス
重要な意思決定における機械学習のミスは甚大な被害につながる
→ 判定結果に対する曖昧性を推定する研究
4. DNNの抱える課題
4
Out of Distribution / Adversarial Attacks
OODやノイズ画像に対する識別でも高スコアで誤識別する
(Nguyen et al., 2015[3])
Perturbationを加えると誤識別する
(Goodfellow et al., 2015[4])
score>99.6% の誤分類データ[3] Adversarial Example[4]
[3] Nguyen et al., “Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images”, IEEE, 2015
[4] Goodfellow et al., “Explaining and Harnessing Adversarial Examples”, ICLR, 2015
5. DNNの抱える課題
5
Over Confidence [Guo + , 2017][5]
モデルが正しく予測できないにも関わらず、
高いスコアを出力してしまう
[5] Guo et al., “On Calibration of Modern Neural Networks”, ICML, 2017
医療画像診断や自動運転など,DNNを社会実装していくには
これらの課題の解決し,
判定結果に対して曖昧性を算出することが不可欠となる
モデルの出力事後確率の値が
正解率(Accuracy)を上回ってしまう現象
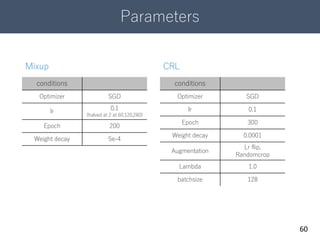
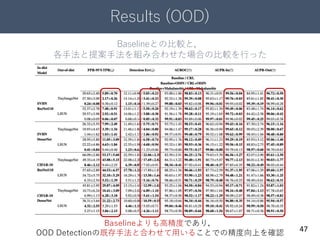
14. 紹介論文
15
① On Mixup Training:
Improved Calibration and Predictive Uncertainty
for Deep Neural Networks
② Confidence – Aware Learning For Deep Neural Networks
データ拡張のMixupがOverconfidence解消に貢献することを示す
DNNの学習過程における傾向を加味したCorrect Ranking Lossを提案
学習過程でOverConfidenceを解消した紹介
15. 紹介論文
16
① On Mixup Training:
Improved Calibration and Predictive Uncertainty
for Deep Neural Networks
② Confidence – Aware Learning For Deep Neural Networks
データ拡張のMixupがOverconfidence解消に貢献することを示す
DNNの学習過程における傾向を加味したCorrect Ranking Lossを提案
学習過程でOverConfidenceを解消した紹介
16. 17
On Mixup Training:
Improved Calibration and Predictive Uncertainty
for Deep Neural Networks
NeurIPS 2019
Sunil Thulasidasan , Gopinath Chennupati ,
Jeff Bilmes , Tanmoy Bhattacharya , Sarah Michalak
50. 参考
51
[1] Levinson et al., “Towards Fully Autonomous Driving: Systems and Algorithms”, iEEE, 2011
[2] Miotto et al., “Deep patient: an unsupervised representation to predict
the future of patients from the electronic health records”, 2016
[3] Nguyen et al., “Deep Neural Networks are Easily Fooled: High Confidence Predictions
for Unrecognizable Images”, IEEE, 2015
[4] Goodfellow et al., “Explaining and Harnessing Adversarial Examples”, ICLR, 2015
[5] Guo et al., “On Calibration of Modern Neural Networks”, ICML, 2017
[6] Yarin Gal, Zoubin Ghahramani, “Dropout as a Bayesian Approximation:
Representing Model Uncertainty in Deep Learning”, 2016
[7] Lakshminarayanan et al., “Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles ”, NIPS, 2017
[8] Chapelle et al., “Vicinal risk minimization” , NeurIPS, 2001
[9] Szegedy et al., “Rethinking the inception architecture for computer vision” , IEEE, 2016
[10] Pereyra et al., “Regularizing neural networks by penalizing confident output distributions”, ICLR, 2017
[11] Verma et al., “Manifold Mixup: Better Representations by Interpolating Hidden States”, ICML, 2019
[12] Toneva et al., “AN EMPIRICAL STUDY OF EXAMPLE FORGETTING
DURING DEEP NEURAL NETWORK LEARNING”, ICLR, 2019
[13] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
[14] Kendall et al., “What uncertainties do we need in bayesian deep learning for computer vision?”, NIPS, 2017
[15] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
[16] Liang et al., “Verified uncertainty calibration”,, 2019
[17] Lee et al., “A simple unified framework for detecting out-of-distribution samples and adversarial attacks” , 2018
[18] Sener & Savarese ., “Active learning for convolutional neural networks: A core-set approach”, NIPS, 2018

![曖昧性推定
2
機械学習システムは様々な分野での社会実装が期待されている
Autonomous Driving[1]
[1] Levinson et al., “Towards Fully Autonomous Driving: Systems and Algorithms”, iEEE, 2011
[2] Miotto et al., “Deep patient: an unsupervised representation to predict the future of patients from the electronic health records”
, 2016
Medical Diagnosis[2]
ミス
重要な意思決定における機械学習のミスは甚大な被害につながる
→ 判定結果に対する曖昧性を推定する研究](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-2-320.jpg)

![DNNの抱える課題
4
Out of Distribution / Adversarial Attacks
OODやノイズ画像に対する識別でも高スコアで誤識別する
(Nguyen et al., 2015[3])
Perturbationを加えると誤識別する
(Goodfellow et al., 2015[4])
score>99.6% の誤分類データ[3] Adversarial Example[4]
[3] Nguyen et al., “Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images”, IEEE, 2015
[4] Goodfellow et al., “Explaining and Harnessing Adversarial Examples”, ICLR, 2015](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-4-320.jpg)
![DNNの抱える課題
5
Over Confidence [Guo + , 2017][5]
モデルが正しく予測できないにも関わらず、
高いスコアを出力してしまう
[5] Guo et al., “On Calibration of Modern Neural Networks”, ICML, 2017
医療画像診断や自動運転など,DNNを社会実装していくには
これらの課題の解決し,
判定結果に対して曖昧性を算出することが不可欠となる
モデルの出力事後確率の値が
正解率(Accuracy)を上回ってしまう現象](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-5-320.jpg)


![Monte Carlo Dropout[6]
9[6] Yarin Gal, Zoubin Ghahramani, “Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning”, 2016
ベルヌーイ分布はDropoutと同義とみなせる
ベルヌーイ分布に従うDropoutを近似的な事後分布として予測分布を算出
𝑊𝑖 = 𝑀𝑖. 𝑑𝑖𝑎𝑔([𝑧𝑖,𝑗] 𝑗=1
𝐾 𝑖
)
𝑧𝑖,𝑗 ∼ 𝐵𝑒𝑟𝑛𝑜𝑢𝑙𝑙𝑖 𝑝𝑖 𝑓𝑜𝑟 𝑖 = 1, … 𝐿, 𝑗 = 1, … , 𝐾𝑖−1
𝑝 𝑦∗ 𝑥∗, 𝑋, 𝑌 = 𝑝 𝑦∗ 𝑥∗, 𝑤 𝑞 𝑤 𝑑𝑤 ≈
1
𝑇
𝑡=1
𝑇
𝑝(𝑦∗|𝑥∗, 𝑤𝑡)
𝑤𝑡 ∼ 𝑞 𝑤 (𝑡 = 1, … 𝑇)
未知データ(𝑥∗
, 𝑦∗
)の入力に対して予測分布を求める際に周辺化は困難
→モンテカルロ法でサンプリング
推論時にも複数のモデルで推論を行うため計算量が課題](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-8-320.jpg)

![Deep Ensemble[7]
11
ランダムに初期化されたネットワークを用いて訓練データ全体を学習し,
出力の平均をとって曖昧性を推定する
高い精度を示すが訓練 / 推論時ともに,高い計算コストがかかる
[7] Lakshminarayanan et al., “Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles ”, NIPS, 2017](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-10-320.jpg)

![Post Process (Temperature Scaling[5])
13
Softmax への入力 Logits を適切なTで除算し OverConfidence を解消する
Original Temp Scale Histogram binning Isotonic regression
Noisy Image や OODに対して高い Confidenceを示してしまうことがある](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-12-320.jpg)





![OverConfidence
19
Epoch
[縦軸: Accuracy, 横軸:Confidence (Mean of Winning Softmax) ]
一般的なクラス分類では,
Epochを経るごとに事後確率の値が先行して高い値をとる
→学習中に,Over Confidenceを防ぐ工夫が必要
事後確率の値が正解率(Accuracy)を上回ってしまうこと](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-18-320.jpg)
![Mixup Training
20
訓練データのみでなく,その近傍も用いて学習をする
[8] Chapelle et al., “Vicinal risk minimization” , NeurIPS, 2001
𝑥 = 𝜆𝑥𝑖 + 1 − 𝜆 𝑥𝑗
𝑦 = 𝜆𝑦𝑖 + 1 − 𝜆 𝑦𝑗
𝜆 ∈ 0,1 , 𝜆~𝐵𝑒𝑡𝑎(𝛼, 𝛼)
入力データ (𝑥𝑖, 𝑦𝑖), (𝑥𝑗, 𝑦𝑗)に対して,
Beta分布に従う𝜆を用いて近傍データ( 𝑥, 𝑦)を生成する.
Vicinal Risk Minimization (VRM) [8]
生成された 𝑥と,ソフトラベル 𝑦を用いて学習を行う](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-19-320.jpg)

![実験条件 (Image)
22
データセット
1, STL-10
2, CIFAR-10/100
3, Fashion-MNIST
モデル
・VGG-16(1,2)
・ResNet-34(2)
・ResNet-18(3)
比較手法
・ε-label smoothing [9]
・ERL(Entropy-regularized loss)[10]
[9] Szegedy et al., “Rethinking the inception architecture for computer vision” , IEEE, 2016
[10] Pereyra et al., “Regularizing neural networks by penalizing confident output distributions”, ICLR, 2017](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-21-320.jpg)
![評価指標
23
(nはデータ数)
𝑂𝐸 =
𝑚=1
𝑀
|𝐵 𝑚|
𝑛
[𝑐𝑜𝑛𝑓 𝐵 𝑚 × max 𝑐𝑜𝑛𝑓 𝐵 𝑚 − 𝑎𝑐𝑐 𝐵 𝑚 , 0 ]
( 𝑝𝑖は,推定クラスの事後確率)
Expected Calibration Error(ECE)𝐵 𝑚
M個のbinに分割
Overconfidence Error (OE)
Over Confidenceを
起こしている𝐵 𝑚にのみ加算](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-22-320.jpg)




![実験条件 (OOD / Noisy Data)
28
データセット
・In : STL-10
・Out : ImageNet
・Noisy : Gaussian Random Noise
モデル
・VGG-16
比較手法
・Temperature Scaling[5]
・Monte Carlo Dropout[6]](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-27-320.jpg)



![(追加実験) Manifold Mixup[11]
32
Mixupの派生系で,中間層の特徴をMixupする手法
・同様条件では,提案 Mixup が高精度
× Hyper Parameterが多い
× 訓練が複雑で,要する時間が長い
・Epochを増やすと,Manifold Mixup が高いAccuracyを示す
→ 本論文では,Mixupを採用
[11] Verma et al., “Manifold Mixup: Better Representations by Interpolating Hidden States”, ICML, 2019](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-31-320.jpg)




![提案の元となるアイデア
37
Forgetting Sample [Toneva+, ICLR 2019[12]]
訓練中に一度正解したが訓練の進行に伴い誤分類されてしまうデータには
判定困難(Noisy Label / 不明瞭)なサンプルが多い
Easy-to-classify Sample [Geifman+, ICLR 2019[13]]
[12] Toneva et al., “AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING”, ICLR, 2019
[13] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
識別困難なデータに比べて,識別が容易なサンプルは,
訓練の初期段階で識別可能になる](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-36-320.jpg)
![サンプルの正解確率の仮定
38
Forgetting Sample [Toneva+, ICLR 2019[12]]
訓練中に一度正解したが訓練の進行に伴い誤分類されてしまうデータには
判定困難(Noisy Label / 不明瞭)なサンプルが多い
Easy-to-classify Sample [Geifman+, ICLR 2019[13]]
[12] Toneva et al., “AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING”, ICLR, 2019
[13] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
識別困難なデータに比べて,識別が容易なサンプルは,
訓練の初期段階で識別可能になる
→正解確率𝑃は,学習中に正しく推論された頻度に基づくと仮定](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-37-320.jpg)

![Correctness Ranking Loss (CRL)
40
推論結果(正解/不正解)
Epoch 𝑥𝑖 𝑥𝑗
1 × ×
2 × ○
n ○ ○
正解率 𝑐 ∈ [0,1]
Loss計算時のepochまでの正解率
信頼度𝜅
・Maximum Class Probability
・Margin
・Negative Entropy
などの事後確率Baseの曖昧性指標から選択 𝑐 ∈ [0,1]
𝑐と𝜅の大小関係が一致していないと加算
特に,正解率𝑐に大きな乖離が
見られるペアに関してLossを強める](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-39-320.jpg)


![実験条件 (Image)
43
データセット
・SVHN, CIFAR10/100
モデル
・VGG-16
・PreAct-ResNet110
・DenseNet-BC
比較手法
・Baseline(Cross Entropy)
・MCDropout[6]
・Aleatoric + MCDropout[14]
・AES[15]
[14] Kendall et al., “What uncertainties do we need in bayesian deep learning for computer vision?”, NIPS, 2017
[15] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-42-320.jpg)


![実験条件 (OOD)
46
データセット
・In : SVHN , CIFAR-10
・Out : Tiny-ImageNet, LSUN
モデル
・PreAct-ResNet110
・DenseNet
比較手法
・Baseline(Cross Entropy)
・ODIN [16]
・Mahalanobis Detector[17]
[16] Liang et al., “Verified uncertainty calibration”,, 2019
[17] Lee et al., “A simple unified framework for detecting out-of-distribution samples and adversarial attacks” , 2018](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-45-320.jpg)
![実験条件 (Active Learning)
48
データセット
・CIFAR-10/100
モデル
・ResNet18
比較手法
・Baseline(Entropy , Random Sampling)
・MCDropout[6]
・Core-set Sampling[18]
[18] Sener & Savarese ., “Active learning for convolutional neural networks: A core-set approach”, NIPS, 2018
クエリ
・2000(初期データは各手法共通) *10 (5回試行)
・不確かなものから優先的にクエリとして抽出し,学習](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-47-320.jpg)


![参考
51
[1] Levinson et al., “Towards Fully Autonomous Driving: Systems and Algorithms”, iEEE, 2011
[2] Miotto et al., “Deep patient: an unsupervised representation to predict
the future of patients from the electronic health records”, 2016
[3] Nguyen et al., “Deep Neural Networks are Easily Fooled: High Confidence Predictions
for Unrecognizable Images”, IEEE, 2015
[4] Goodfellow et al., “Explaining and Harnessing Adversarial Examples”, ICLR, 2015
[5] Guo et al., “On Calibration of Modern Neural Networks”, ICML, 2017
[6] Yarin Gal, Zoubin Ghahramani, “Dropout as a Bayesian Approximation:
Representing Model Uncertainty in Deep Learning”, 2016
[7] Lakshminarayanan et al., “Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles ”, NIPS, 2017
[8] Chapelle et al., “Vicinal risk minimization” , NeurIPS, 2001
[9] Szegedy et al., “Rethinking the inception architecture for computer vision” , IEEE, 2016
[10] Pereyra et al., “Regularizing neural networks by penalizing confident output distributions”, ICLR, 2017
[11] Verma et al., “Manifold Mixup: Better Representations by Interpolating Hidden States”, ICML, 2019
[12] Toneva et al., “AN EMPIRICAL STUDY OF EXAMPLE FORGETTING
DURING DEEP NEURAL NETWORK LEARNING”, ICLR, 2019
[13] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
[14] Kendall et al., “What uncertainties do we need in bayesian deep learning for computer vision?”, NIPS, 2017
[15] Geifman et al., “BIAS-REDUCED UNCERTAINTY ESTIMATION FOR DEEP NEURAL CLASSIFIERS”, ICLR, 2019
[16] Liang et al., “Verified uncertainty calibration”,, 2019
[17] Lee et al., “A simple unified framework for detecting out-of-distribution samples and adversarial attacks” , 2018
[18] Sener & Savarese ., “Active learning for convolutional neural networks: A core-set approach”, NIPS, 2018](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-50-320.jpg)


![Result (α-Error)
54
実験から適切なαは,[0.1, 0.4]と結論づけていた](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-53-320.jpg)
![AES[15]
55
データ群によって一番最適化されているEpochが異なることから
推論時のデータに対して適切なEpochのパラメタから得られる信頼度を用いる手法](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-54-320.jpg)
![ERL[10]
56
NLL (Negative Log Likelihood) Lossに対して
予測結果のNegative Entropy を加える正則化を行う手法
・誤ったクラスに対する事後確率が高い
・予測分布の曖昧性(Entropy)が低い
サンプルに対して大きな損失が加算されるように正則化を行う](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-55-320.jpg)
![Calibration methods
57
Histogram binning
Isotonic regression
[0] Guo et al., “On Calibration of Modern Neural Networks”, ICML, 2017
各bin 𝑎 𝑚, 𝑎 𝑚+1 において下式を最適化する信頼度𝜃 𝑚を定義
(binary setting)](https://image.slidesharecdn.com/20201109-matsunaga-slide-201226145002/85/DNN-56-320.jpg)