DOD 2016 - Rafał Kuć - Building a Resilient Log Aggregation Pipeline Using Elasticsearch and Kafka
1 like248 views

The document discusses building a resilient log aggregation pipeline using Elasticsearch and Kafka. It recommends using Kafka as a centralized buffer due to its scalability, fault tolerance, and streaming capabilities. Daily or size-based indices in Elasticsearch are preferable to a single large index. The document also provides optimization strategies for Elasticsearch, Kafka, and log shipping, including maintaining separate hot and cold tiers and properly configuring resources for data, master and ingest nodes.



















































DOD 2016 - Rafał Kuć - Building a Resilient Log Aggregation Pipeline Using Elasticsearch and Kafka
- 1. Building Resilient Log Aggregation Pipeline Using Elasticsearch and Kafka Rafał Kuć @ Sematext Group, Inc.
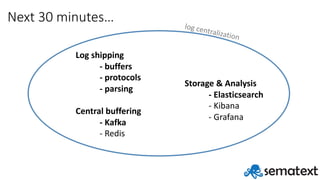
- 3. Next 30 minutes… Log shipping - buffers - protocols - parsing Central buffering - Kafka - Redis Storage & Analysis - Elasticsearch - Kibana - Grafana
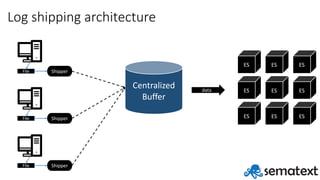
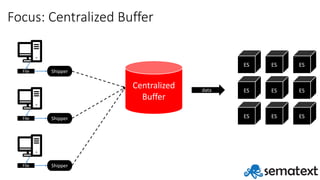
- 4. Log shipping architecture File Shipper File Shipper File Shipper Centralized Buffer ES ES ES ES ES ES ES ES ES data
- 5. Focus: Elasticsearch File Shipper File Shipper File Shipper Centralized Buffer ES ES ES ES ES ES ES ES ES data
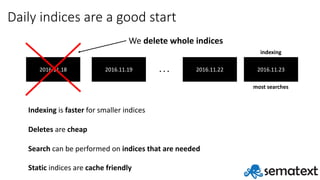
- 13. Daily indices are a good start 2016.11.18 2016.11.19 2016.11.22 2016.11.23. . . Indexing is faster for smaller indices Deletes are cheap Search can be performed on indices that are needed Static indices are cache friendly indexing most searches
- 14. Daily indices are a good start 2016.11.18 2016.11.19 2016.11.22 2016.11.23. . . Indexing is faster for smaller indices Deletes are cheap Search can be performed on indices that are needed Static indices are cache friendly indexing most searches We delete whole indices
- 21. Slice using size Predictable searching and indexing performance Better indices balancing Fewer shards Easier handling of spiky loads Less costs because of better hardware utilization
- 22. Proper Elasticsearch configuration Keep index.refresh_interval at maximum possible value 1 sec -> 100%, 5 sec -> 125%, 30 sec -> 175% You can loosen up merges - possible because of heavy aggregation use - segments_per_tier -> higher - max_merge_at_once-> higher - max_merged_segment -> lower All prefixed with index.merge.policy } higher indexing throughput
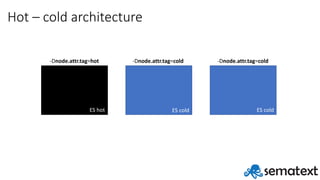
- 25. Hot – cold architecture ES hot ES cold ES cold -Dnode.attr.tag=hot -Dnode.attr.tag=cold -Dnode.attr.tag=cold
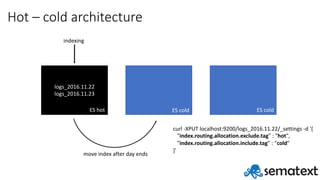
- 26. Hot – cold architecture logs_2016.11.22 ES hot ES cold ES cold -Dnode.attr.tag=hot -Dnode.attr.tag=cold -Dnode.attr.tag=cold curl -XPUT localhost:9200/logs_2016.11.22 -d '{ "settings" : { "index.routing.allocation.exclude.tag" : "cold", "index.routing.allocation.include.tag" : "hot" } }'
- 27. Hot – cold architecture logs_2016.11.22 ES hot ES cold ES cold indexing
- 28. Hot – cold architecture logs_2016.11.22 logs_2016.11.23 ES hot ES cold ES cold indexing
- 29. Hot – cold architecture logs_2016.11.22 logs_2016.11.23 ES hot ES cold ES cold indexing move index after day ends curl -XPUT localhost:9200/logs_2016.11.22/_settings -d '{ "index.routing.allocation.exclude.tag" : "hot", "index.routing.allocation.include.tag” : "cold" }'
- 30. Hot – cold architecture logs_2016.11.23 logs_2016.11.22 ES hot ES cold ES cold indexing
- 31. Hot – cold architecture logs_2016.11.23 logs_2016.11.24 logs_2016.11.22 ES hot ES cold ES cold indexing
- 32. Hot – cold architecture logs_2016.11.23 logs_2016.11.24 logs_2016.11.22 ES hot ES cold ES cold indexing move index after day ends
- 33. Hot – cold architecture logs_2016.11.24 logs_2016.11.22 logs_2016.11.23 ES hot ES cold ES cold indexing
- 35. Hot – cold architecture summary ES cold Optimize costs – different hardware for different tier Performance – use case optimized hardware Isolation – long running searches don’t affect indexing
- 42. Focus: Centralized Buffer File Shipper File Shipper File Shipper Centralized Buffer ES ES ES ES ES ES ES ES ES data
- 45. Kafka & topics security_logs access_logs app1_logs app2_logs Kafka stores data in topics written on disk
- 50. Things to remember when using Kafka Scales by adding more partitions not threads The more IOPS the better Keep the # of consumers equal to # of partitions Replicas used for HA and FT only Offsets stored per consumer – multiple destinations easily possible
- 51. Focus: Shipper File Shipper File Shipper File Shipper Centralized Buffer ES ES ES ES ES ES ES ES ES data
- 53. Buffers performance & availability batches & threads when central buffer is gone
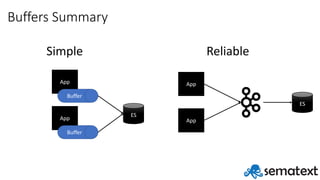
- 54. Buffer types Disk || memory || combined hybrid approach On source || centralized App Buffer App Buffer file or local log shipper easy scaling – fewer moving parts often with the use of lightweight shipper App App Kafka / Redis / Logstash / etc… one place for all changes extra features made easy (like TTL) ES ES
- 56. Protocols UDP – fast, cool for the application, not reliable TCP – reliable (almost) application gets ACK when written to buffer Application level ACKs may be needed HTTP RELP Beats Kafka Logstash, rsyslog, Fluentd Logstash, rsyslog Logstash, Filebeat Logstash, rsyslog, Filebeat, Fluentd
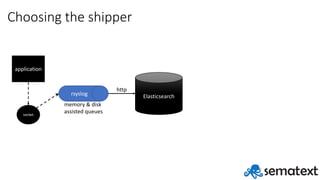
- 57. Choosing the shipper application rsyslog Elasticsearch http socket memory & disk assisted queues
- 59. What about OS? Say NO to swap Set the right disk scheduler CFQ for spinning disks deadline for SSD Use proper mount options for ext4 noatime nodirtime data=writeback, nobarier For bare metal check CPU governor disable transparent huge pages /proc/sys/vm/nr_hugepages=0