Elasticsearch 5.2とJava Clientで戯れる #elasticsearchjp
Download as PPTX, PDF1 like5,426 views

第18回Elastcisearch勉強会 https://www.meetup.com/ja-JP/Tokyo-Elastic-Fantastics/events/237511494/ LT資料




![Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved.
Elasticsearch 5.2 セットアップ
• DLページの簡単3step通りなのだけど・・・
• https://www.elastic.co/jp/downloads/elasticsearch
• 初期設定だとlocalhostからしかアクセスできないのでnetwork.hostを0.0.0.0にして立ち上げようと
するとファイルディスクリプタとメモリマップの警告でエラー
• 5系からプロダクション設定での起動チェックが厳しくなっているらしい
5
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]](https://image.slidesharecdn.com/elasticsearchjavaclient-170221035940/85/Elasticsearch-5-2-Java-Client-elasticsearchjp-5-320.jpg)









Elasticsearch 5.2とJava Clientで戯れる #elasticsearchjp
- 1. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. 2017年2月20日 1 ヤフー株式会社 データ&サイエンスソリューション統括本部 データプラットフォーム本部 開発1部 パイプライン 森谷 大輔 Elasticsearch 5.2 と Java Clientで戯れる Elasticsearch勉強会#18 LT
- 2. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. 自己紹介 • 森谷 大輔(@kokumutyoukan) • 仕事 • 次世代データパイプラインの開発 • 1,000,000 msgs/sec • Kafka, Storm, Cassandra, Elasticsearch • Elasticsearch (+Kibana)はログの可視化用途 • Java Clientは初めて触ったので5.2でどう進化したかなどは今回触れない 2
- 3. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. LTの内容 • Elasticsearch 5.2 のJava Client(Bulk Processor)でログ投入して みた • 試した流れの要約と詰まったところ • Elasticsearch 5.2 と Java Clientについて複合した内容 • Elasticsearch 5.2 セットアップ • Java Client - Elasticsearchクラスタ接続設定 • 1ログを投入 • Bulk Processorで投入 3
- 4. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. なんでJava Clientでログ投入? • Logstash や Beats は? • 前提:自分が今回想定したユースケースはログを発するところではなく、 Kafka→Elasticsearchを中継するようなところ • 使ったことがなかったのでこれはこれで覚える必要 • 前処理で好き勝手やりたい • id上書きしたりタイムスタンプ補正したりKVSデータとJoinしたり • ↑でもできるかもだけどJavaならとりあえず何でもできるでしょという感覚 4 Data Source Data Source Mirror Maker こ こ
- 5. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Elasticsearch 5.2 セットアップ • DLページの簡単3step通りなのだけど・・・ • https://www.elastic.co/jp/downloads/elasticsearch • 初期設定だとlocalhostからしかアクセスできないのでnetwork.hostを0.0.0.0にして立ち上げようと するとファイルディスクリプタとメモリマップの警告でエラー • 5系からプロダクション設定での起動チェックが厳しくなっているらしい 5 max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
- 6. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Elasticsearch 5.2 セットアップ • tar ballからセットアップしようとしたからあたったが、RPMからインストールすればこの辺 の設定はsystemd経由で最初から入っている • ファイルディスクリプタの制御面倒なのでRPMからのインストールが無難 • 【一言メモ】セットアップ前にこのQiita記事を見ておくのオススメ • http://qiita.com/uzresk/items/e0b10c14875b79c450f2 6
- 7. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. 脱線:モニター • elasticsearch-headが好きだった • しかし5系からsite pluginが使えなくなった • スタンドアロンで起動するしかないが • headの場合は別にWebサーバを立てなければ使えないので面倒になった • Cerebro(旧Kopf)に鞍替えした • tar ball展開して bin/cerebro 実行するだけでWebサーバも一緒に立ち上げて くれるのですごく楽 • headからの乗換感想:headでよく使ってた機能は持っているみたいだしいい 感じ、直感的ですぐ慣れた 7
- 8. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Java Client - Elasticsearchクラスタ 接続設定 • Java API説明ページを見ながら進めていく • https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html • まずはここから 8 <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>transport</artifactId> <version>5.2.0</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-api</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.7</version> </dependency>
- 9. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. client オブジェクトを作る 9 private TransportClient cli; /** * elasticsearch clientを、つくってゆきます * @param esHost 例:es01.example.com * @param esCliPort client受付ポートのデフォルトは9200じゃなくて9300 * @param clusterName デフォルトのelasticsearchのままになんてしないよね・・・? */ private void createCli(String esHost, int esCliPort, String clusterName) throws UnknownHostException { InetSocketTransportAddress address = new InetSocketTransportAddress( InetAddress.getByName(esHost), esCliPort); Settings settings = Settings.builder().put("cluster.name", clusterName).build(); cli = new PreBuiltTransportClient(settings) .addTransportAddress(address); //.addTransportAddresses(addresses); // 複数のホストを指定する場合ここに配列 }
- 10. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. index template • 5系では elasticsearch.yml でインデックス設定ができなくなった • index.number_of_shards, index.number_of_replicas • 僕「えっ?!デフォルトのシャード数とレプリカ数どうやって指定する の?!」 • → こうする • index templateを使う、もちろんJava Clientじゃなくてもよい 10 cli.admin().indices() .preparePutTemplate("hogehoge-template") // 任意のテンプレート名 .setTemplate(indexPrefix + "-*") // テンプレートを有効にしたい対象のインデックス .setSettings(Settings.builder() .put("number_of_shards", 10) .put("number_of_replicas", 1)) .get();
- 11. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. 1ログを投入する • client便利だと思った • 入力に以下のどれでも選べる • JSON文字列 • Map • beansクラスの Jacksonバイナリ • Elasticsearch専用ヘルパー • 特にMapがお手軽 11 // index名やidの準備 DateTime eventTime = new DateTime(eventTimestamp); String indexName = indexPrefix + “-” + eventTime.toString(“yyyy.MM.dd”); String id = UUID.randomUUID().toString(); // 書き込むログの準備 Map<String, Object> json = new HashMap<>(); json.put(“user”, “kokumutyoukan”); json.put(“postDate”, new Date(eventTime.getMillis())); json.put(“message”, "eat rice."); // 書き込みリクエスト IndexResponse response = cli.prepareIndex( indexName, type, id).setSource(json).get();
- 12. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Bulk Processor • それなりの流量でドキュメントをインデックスするならBulk API一択 • Bulk Processorはすごく直感的で良かった 12
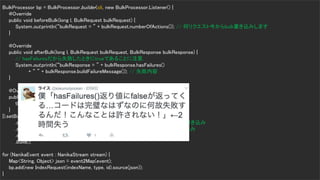
- 13. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Bulk Processor 13 BulkProcessor bp = BulkProcessor.builder(cli, new BulkProcessor.Listener() { @Override public void beforeBulk(long l, BulkRequest bulkRequest) { System.out.println(“bulkRequest = ” + bulkRequest.numberOfActions()); // 何リクエスト今からbulk書き込みします } @Override public void afterBulk(long l, BulkRequest bulkRequest, BulkResponse bulkResponse) { // hasFailuresだから失敗したときにtrueであることに注意. System.out.println(“bulkResponse = ” + bulkResponse.hasFailures() + “ ” + bulkResponse.buildFailureMessage()); // 失敗内容 } @Override public void afterBulk(long l, BulkRequest bulkRequest, Throwable throwable) { throwable.printStackTrace(); } }).setBulkActions(10000) // 1万リクエストたまったらbulk書き込み .setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)) // 5MBたまったらbulk書き込み .setFlushInterval(TimeValue.timeValueSeconds(5)) // 5秒たまったらbluk書き込み .setConcurrentRequests(1) // bulk書き込みの並列度、1なら2並列 .build(); for (NanikaEvent event : NanikaStream stream) { Map<String, Object> json = event2Map(event); bp.add(new IndexRequest(indexName, type, id).source(json)); }
- 14. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. Bulk Processor 14 BulkProcessor bp = BulkProcessor.builder(cli, new BulkProcessor.Listener() { @Override public void beforeBulk(long l, BulkRequest bulkRequest) { System.out.println(“bulkRequest = ” + bulkRequest.numberOfActions()); // 何リクエスト今からbulk書き込みします } @Override public void afterBulk(long l, BulkRequest bulkRequest, BulkResponse bulkResponse) { // hasFailuresだから失敗したときにtrueであることに注意. System.out.println(“bulkResponse = ” + bulkResponse.hasFailures() + “ ” + bulkResponse.buildFailureMessage()); // 失敗内容 } @Override public void afterBulk(long l, BulkRequest bulkRequest, Throwable throwable) { throwable.printStackTrace(); } }).setBulkActions(10000) // 1万リクエストたまったらbulk書き込み .setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)) // 5MBたまったらbulk書き込み .setFlushInterval(TimeValue.timeValueSeconds(5)) // 5秒たまったらbluk書き込み .setConcurrentRequests(1) // bulk書き込みの並列度、1なら2並列 .build(); for (NanikaEvent event : NanikaStream stream) { Map<String, Object> json = event2Map(event); bp.add(new IndexRequest(indexName, type, id).source(json)); }
- 15. Copyrig ht © 2017 Yahoo Japan Corporation. All Rig hts Reserved. まとめ • Elasticsearch 5.2 いくつか引っかかるところもあった • Java Client初めて使ったけど使い勝手が良かった • 自力でBulkのHTTPリクエスト生成するよりはずっといい • Bulk Processorは特に良かった 15