GDPR Community Showcase for Apache Ranger and Apache Atlas
Download as PPTX, PDF1 like1,910 views

The document outlines the evolution and features of Apache Ranger and Apache Atlas, highlighting their integration with partner technologies like Privacera and Attunity for data management and compliance. It covers the journey of both projects, significant milestones in their development, and enhancements for security and data governance. The discussions also emphasize metadata management and the importance of user consent in GDPR compliance as part of modern data architectures.














































![Notices and disclaimers
continued
© 2018 IBM Corporation
Information concerning non-IBM products was obtained from the suppliers of
those products, their published announcements or other publicly available
sources. IBM has not tested those products about this publication and cannot
confirm the accuracy of performance, compatibility or any other claims related
to non-IBM products. Questions on the capabilities of non-IBM products
should be addressed to the suppliers of those products. IBM does not warrant
the quality of any third-party products, or the ability of any such third-party
products to interoperate with IBM’s products. IBM expressly disclaims all
warranties, expressed or implied, including but not limited to, the implied
warranties of merchantability and fitness for a purpose.
The provision of the information contained herein is not intended to, and does
not, grant any right or license under any IBM patents, copyrights, trademarks
or other intellectual property right.
IBM, the IBM logo, ibm.com and [names of other referenced IBM products and
services used in the presentation] are trademarks of International Business
Machines Corporation, registered in many jurisdictions worldwide. Other
product and service names might be trademarks of IBM or other companies. A
current list of IBM trademarks is available on the Web at "Copyright and
trademark information" at: www.ibm.com/legal/copytrade.shtml.
48](https://image.slidesharecdn.com/gdprcommunityshowcase-180626215253/85/GDPR-Community-Showcase-for-Apache-Ranger-and-Apache-Atlas-48-320.jpg)




GDPR Community Showcase for Apache Ranger and Apache Atlas
- 1. 1 © Hortonworks Inc. 2011 – 2017. All Rights Reserved Hortonworks Inc. Privacera Attunity IBM Ali Bajwa, Partner Solutions Balaji Ganesan, CEO Jordan Martz, Director Somil Kulkarni, Director Srikanth Venkat, Product Mgmt Bosco Durai, Chief Architect Greg Goldsmith, Director DataWorks Summit – San Jose June 2018 Partner Ecosystem Showcase For Apache Ranger And Apache Atlas
- 2. 2 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Agenda Apache Ranger & Apache Atlas Journey, Ecosystem & Partners Hortonworks Partner Certification Program SEC Ready & GOV Ready program Partner Technology Showcase
- 3. 3 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Community Snapshot May 2014 XASecure Acquisition July 2014 Enters Apache Incubation Nov 2014 Ranger 0.4.0 Release July 2015 Ranger 0.5/ HDP2.3 Aug 2016 Ranger 0.6/ HDP2.5 Nov 2016 Ranger 0.6.2/ HDP2.5.3 Jan 2017 Ranger TLP graduation! Jun 2017 Ranger 0.7.1 /HDP2.6.1 1.0.0 March 2018 • Committers: 27 • Contributors from: Ebay, MSFT, Huawei, Pandora, Accenture, ING, Talend, ZTE Ranger 1.0/HDP3.0 Ranger 0.7.x/HDP2.6.x • User Sync Nested LDAP Support • Tag based Masking • Tag Attribute Based Policy • Export/import of Policies • $User and macros • Plugin status tab • “Show columns” and “describe extended support” • Incremental LDAP Sync • SmartSense Metrics • Time based policies • Ranger ON by default (HDP3) • Audit only (compliance) role • Metadata security • Hive UDF usage authorization • Show Hive query in Access Audits UX • Policy labels • User Sync Audits • Hive 3 Support (Information Schema, Workload AuthZ, Default Authorizer for Hive) Apr 2017 Ranger 0.7 /HDP2.6 Oct 2017 Ranger 0.7.1++ /HDP2.6.3 Aug 2017 Ranger 0.7.1+ /HDP2.6.2
- 4. 4 © Hortonworks Inc. 2011 – 2017. All Rights Reserved Apache Ranger: Ecosystem PartnerPartner Integrations Apache Ranger Apache Kafka Native Hadoop Service Authorizers Azure Data Lake Store (ADLS)* (Future) Authorizer Extensions for Non- Hadoop Filesystems & Stores
- 5. 5 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Community Snapshot May 2015 Apache Atlas Incubation DGI group Kickoff Dec 2014 Apr 2017 Apache 0.8 Release Global Financial Company Aug 2016 Apache 0.7 Foundation Release Apache Atlas 1.0.0/HDP 3.0 • Business Catalog • Classification Propagation • Hbase hook (GA)/Spark hook (TP) • Kafka Bridge • Time based classifications • Janus Graph (TP3) & Solr 7 Apache Atlas 0.8/HDP2.6.0-2.6.5 • Search UX Improvements • Tag based masking • Classification-based security for HDFS, Kafka, HBase • Knox SSO • Column level lineage • Nifi support • Committers – 38 • Code contributors: Hortonworks, IBM, Comcast, ING, Aetna, Merck, Target Jun 2017 Atlas Becomes TLP! Q4 2017 Apache 0.8.1 Release Apache 1.0 Release June 2018
- 6. 6 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Apache Atlas: Current Connectors and Ecosystem Custom Integration PartnerPartner Apache Atlas RDBMS Apache Kafka Pending: (preview)
- 9. SOLUTIONS FOR MANAGING SENSITIVE DATA DISCOVERY AND CLASSIFICATION ACCESS CONTRO L ANONYMIZATION MONITORING Where is sensitive data? Protect sensitive data at rest and in motion Who has access to data? What are users doing with data?
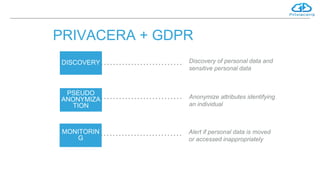
- 10. PRIVACERA + GDPR DISCOVERY Discovery of personal data and sensitive personal data PSEUDO ANONYMIZA TION Anonymize attributes identifying an individual MONITORIN G Alert if personal data is moved or accessed inappropriately
- 11. ETL END TO END SCENARIO WITH PRIVACERA LANDING ZONE HIVE BEELI NE BI 1 Discover sensitive data 2 Encrypt sensitive data, push tags to Atlas 3 Classify anonymized data, push tags to Atlas 4 4 Control access based on data classification 5 Deanonymize data for certain users 6 Monitor user actions DATA LAKE RANG ER ATLAS
- 12. INTRODUCTION - DATA DISCOVERY AND CLASSIFICATION customer.csv Resource Tags customer.csv SSN NA ME EMA IL ZIPC ODE
- 13. SCALABLE AND SEARCHABLE METADATA
- 14. ANONYMIZATION SUPPORT FOR GDPR Method Scheme Original Value Anonymized Value Pseudo- anonymization FPE (Format Preserving Encryption) 747-44-9484 872-23-8023 Pseudo- anonymization Alphanumeric Jane Doe 1nhg 89d Redaction Masking/Hashing 747-44-9484 XXX-XX-XXXX Partial Redaction Last 4 747-44-9484 XXX-XX-9484
- 15. ENCRYPTION POLICIES - DRIVEN BY CLASSIFICATION
- 16. Classification Prohibition Time Location Policies PDP Resource Cache Ranger Manage Access Policies and Audit Logs Track Metadata and Lineage Atlas Client Subscribers to Topic Gets Metadata Updates Atlas Metastore Tags Assets Entitles Streams Pipelines Feeds Hive Tables HDFS Files HBase Tables Entities in Data Lake Dynamic Tag-based Security Policies INTRO - ACCESS TO DATA BASED ON CLASSIFICATION
- 17. INTRO - ACCESS TO DATA BASED ON CLASSIFICATION
- 18. DEMO
- 19. DEMO FLOW ▸Ingest data into landing zone ▸Tag sensitive data ▸Encrypt sensitive data fields (Name, Email Address) ▸Push tags into Privacera and then Atlas ▸Show lineage of Atlas ▸Show tag based policies in Ranger ▸De-anonymize data based on a Ranger policy ▸“Forget user” - No longer able to deanonymize data
- 23. RANGER TAG BASED POLICIES
- 24. RANGER – TAG BASED ANONYMIZATION
- 25. PRIVACERA - USER CONSENT
- 26. PRIVACERA - GDPR TAKEAWAY DEEP PERSONAL DATA DISCOVERY Privacera discovers and classifies personal data, and uses data classification for control decisions PSEUDONYMIZATION Privacera provides pseudonymization capabilities to remove personal data identifiers. Privacera solution can easily address consent and RTBF requirements BUILT FOR MODERN DATA ARCHITECTURE Privacera provides native integration for Apache Kafka, HBase, Hadoop, Hive, Spark, Ranger, Knox and many other open source big data projects
- 28. Greg Goldsmith, Director of Product Management Jordan Martz, Director of Technology Solutions Attunity for Data Lakes DATAWORKS JUNE 2018
- 29. 29© 2018 Attunity 29© 2017 Attunity Changing Analytics Needs Driving Data Lake Adoption “Capture only what is needed” “Capture everything” “I don’t know what I need!” “I know what I need” Business determines what questions to ask IT delivers platform to store, refine & analyze all data sources IT structures data to answer those questions Business explores data for questions worth answering REPORTING • Structured • Repeatable DISCOVERY • Multi-Structured • Iterative
- 30. 30© 2018 Attunity Source: Metadata Is the Fish Finder in Data Lakes, 2017 Through 2018, 90% of deployed data lakes will be useless as they are overwhelmed with information assets captured for uncertain use cases. Data lakes store raw data and their business value is entirely determined by the skills of data lake users. Many technologies used to implement data lakes are new and lack the necessary information capabilities that organizations normally take for granted. Without data lineage within data lakes, data must be collected, assembled and refined by each user separately and independently to drive meaningful business insights. Key Challenges 1st Generation Data Lakes Not Showing Value
- 31. 31© 2018 Attunity Source: Metadata Is the Fish Finder in Data Lakes, 2017 Through 2018, 90% of deployed data lakes will be useless as they are overwhelmed with information assets captured for uncertain use cases. Skills Tools Trust Key Challenges 1st Generation Data Lakes Not Showing Value
- 32. Continuous Transactional Data Streaming SAP RDBMS DATA WAREHOUSE FILES MAINFRAME Land Assemble Provision Consume CAPTURE PARTITION ENRICH SUBSET STANDARDIZE MERGE FORMAT ANALYZE PREPARE CLEANSE JOIN Full Change History HDS ODS Snapshot Views Source Making Transactional Data Available for Analytics at the Speed of Change Raw Deltas FOR DATA LAKES Continuous CDC and refresh of data and metadata into data lake Data continuously updated and merged into historic data store Subsets created to meet analytic requirements
- 33. 33© 2018 Attunity Attunity Replicate Assists GDPR Compliance Securely moves customer data into GDPR-compliant data lake for anonymization, deletion, analytics, etc. Reduces risk of PII breach User authentication and role-based access controls Secure client-server connections Encrypted WAN transfer Test and development system almost never have consent! Removes PII with row and column filtering or obfuscation during replication process Helps demonstrate compliance via audit log of all replication tasks • Audit log • User authentication and authorization • Data filtering Hadoop File s RDBM S Mainframe Hadoop Files RDBMS Kafka EDW EDW
- 34. 34© 2018 Attunity • Metadata management must be automated • Metadata management must become ubiquitous • Metadata must become open and remotely accessible • Metadata should be used to drive the governance of data The discovery, maintenance and use of metadata has to be an integral part of all tools that access, change and move information. ODPi: A New Manifesto for Metadata and Governance 34
- 35. 35© 2018 Attunity 35© 2017 Attunity Today’s Reality
- 36. Continuous Transactional Data Streaming SAP RDBMS DATA WAREHOUSE FILES MAINFRAME Land Assemble Provision Consume Metadata Management Operations Management CAPTURE PARTITION ENRICH SUBSET STANDARDIZE MERGE FORMAT ANALYZE PREPARE CLEANSE JOIN Full Change History HDS ODS Snapshot Views Source Making Transactional Data Available for Analytics at the Speed of Change Raw Deltas DESIGN Dataflows MANAGE Platform MONITOR Tasks ANALYZE Trends TRACE Lineage CATALOG Data VALIDATE Transfers ANALYZE Data Usage SYNC Catalog
- 37. 37© 2018 Attunity Marketing Demographics Electronic medical records CRM POS (Structured)(Structured) (Structured) (Structured) (Structured) Cluster 1: Dublin Cluster 2: San Francisco (Unstructured)(Unstructured)(Unstructured) Cluster 3: Prague (Structured) On Premise Data Lakes (Unstructured)(Structured) (Unstructured) (Structured) Cloud Data Lakes Social Weblogs & Feeds Transactional Mobile IoT Personal Data Demo: Attunity & HortoniaBank Data Landscape
- 39. © 2018 IBM Corporation Integration of Information Server with ApacheAtlas Kunju Kashalikar Program Director, Unified Governance & Integration Somil Kulkarni Program Director, UnifiedGovernance & Integration
- 40. Please note IBM’s statements regarding its plans, directions, and intent are subject to change or withdrawal without notice and at IBM’s sole discretion. Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision. The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract. The development, release, and timing of any future features or functionality described for our products remains at our sole discretion. Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here. 40© 2018 IBM Corporation
- 41. IBM InfoSphere Information Server Information Empowerment forYour Data Ecosystem 41© 2018 IBM Corporation Integrating and transforming data and content to deliver accurate, consistent, timely and complete information through a unified platform with a common metadata foundation InfoSphere Information Server Data Quality Information Governance Catalog Data Integration Information Governance Catalog Understand & Collaborate − Catalog technical metadata & align w/ business language − Manage (big) data lineage − BCBS compliance reporting Data Discovey & Quality Cleanse & Monitor − Analyze, validate, classify − Cleanse & standardize − Define, manage & monitor data rules + exceptions Data Integration Transform & Deliver − Massive scalability − Power for any complexity − Deliver in batch and/or real-time with change capture Common Connectivity / Shared Metadata / Security / Common Execution EngineWith Flexible Deployments (Hadoop, Grid, Cloud)
- 42. HDP 2.6.x IIS Integration withApacheAtlas .8 release 42 © 2018 IBM Corporation Knowledge Graph Enterprise Data Catalog Apache Atlas Repository Atlas – IGC Connector Atlas kafka IIS Rest API IIS kafka Listens to Atlas API IIS 11.7.x Listens to
- 43. IIS – Atlas .8 43 Capabilities & Deployment • Deployment • Download Apache “Atlas Information Governance Catalog Connector” from IBM Fix Central • Copy binaries in HDP • Configure The Connector to connect to HDP and IIS • Run the Connector on schedule or continuously • Capabilities • Support for ingestion of Hive Tables, represented as Database Table in IGC • Support for ingestion of IGC Terms represented as Atlas Terms
- 44. Demo Scenario 44 Demo • A new table , Account Info with column customer id is created in a new Database , NECust , Schema – CustInfo. • In igc, user is able to view the asset. • User assigns a term Customer ID ( existing) to the table/column. • User Creates a new term , “North East Territory” and assigns to the database. • That term is reflected back in Atlas • A user is able to search for Customer ID and finds assets in DB2 as well as Hive.
- 45. Apache Atlas Integration 1.0 45 Roadmap • Support for additional Asset Types will be delivered on Atlas 1.0 • Initial Delivery targeted for Q4 2017
- 46. Thank you 46© 2018 IBM Corporation Kunju Kashalikar Program Director, IBM Unified Governance & Integration Somil Kulkarni Program Director, IBM Unified Governance & Integration —
- 47. Notices and disclaimers © 2018 International Business Machines Corporation. No part of this document may be reproduced or transmitted in any form without written permission from IBM. U.S. Government Users Restricted Rights — use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM. Information in these presentations (including information relating to products that have not yet been announced by IBM) has been reviewed for accuracy as of the date of initial publication and could include unintentional technical or typographical errors. IBM shall have no responsibility to update this information. This document is distributed “as is” without any warranty, either express or implied. In no event, shall IBM be liable for any damage arising from the use of this information, including but not limited to, loss of data, business interruption, loss of profit or loss of opportunity. IBM products and services are warranted per the terms and conditions of the agreements under which they are provided. IBM products are manufactured from new parts or new and used parts. In some cases, a product may not be new and may have been previously installed. Regardless, our warranty terms apply.” Any statements regarding IBM's future direction, intent or product plans are subject to change or withdrawal without notice. Performance data contained herein was generally obtained in a controlled, isolated environments. Customer examples are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual performance, cost, savings or other results in other operating environments may vary. References in this document to IBM products, programs, or services does not imply that IBM intends to make such products, programs or services available in all countries in which IBM operates or does business. Workshops, sessions and associated materials may have been prepared by independent session speakers, and do not necessarily reflect the views of IBM. All materials and discussions are provided for informational purposes only, and are neither intended to, nor shall constitute legal or other guidance or advice to any individual participant or their specific situation. It is the customer’s responsibility to insure its own compliance with legal requirements and to obtain advice of competent legal counsel as to the identification and interpretation of any relevant laws and regulatory requirements that may affect the customer’s business and any actions the customer may need to take to comply with such laws. IBM does not provide legal advice or represent or warrant that its services or products will ensure that the customer follows any law. 47© 2018 IBM Corporation
- 48. Notices and disclaimers continued © 2018 IBM Corporation Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products about this publication and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. IBM does not warrant the quality of any third-party products, or the ability of any such third-party products to interoperate with IBM’s products. IBM expressly disclaims all warranties, expressed or implied, including but not limited to, the implied warranties of merchantability and fitness for a purpose. The provision of the information contained herein is not intended to, and does not, grant any right or license under any IBM patents, copyrights, trademarks or other intellectual property right. IBM, the IBM logo, ibm.com and [names of other referenced IBM products and services used in the presentation] are trademarks of International Business Machines Corporation, registered in many jurisdictions worldwide. Other product and service names might be trademarks of IBM or other companies. A current list of IBM trademarks is available on the Web at "Copyright and trademark information" at: www.ibm.com/legal/copytrade.shtml. 48
- 49. © 2018 IBM Corporation 49
- 50. 50 © Hortonworks Inc. 2011 – 2017. All Rights Reserved HDP SEC READY & GOV READY Programs ✔ Choice: Customers choose features that they want to deploy—a la carte ✔ Curated & Fast: Partners to provide rich, complimentary and complete features ready to deploy ✔ Agile: Faster deployment and accelerate innovation ✔ Centralized : Open metadata/governance and security infrastructure ✔ Flexibility: Portfolio of partner reference architectures and integration patterns ✔ Safe: HDP at core to provide stability and interoperability
- 51. 51 © Hortonworks Inc. 2011 – 2017. All Rights Reserved Hortonworks Certified Technology Program HDP YARN Ready Integrates with YARN (native, Tez, Slider) or uses/runs on a YARN Ready engine HDP Operations Ready Integrates with Ambari APIs, Stacks, Blueprints, or Views HDP Governance Ready Integrates with Atlas HDP Security Ready Integrates with Ranger, Knox, or other security features Sign up to be a partner and request certification kit! http://hortonworks.com/partners/product-integration-certification/
- 52. 52 © Hortonworks Inc. 2011 – 2016. All Rights Reserved Questions
Editor's Notes
- #6: How fast ? 7 months !
- #7: What does ecosystem look like? Connectors for Sqoop, Hive, Storm, Kafka as well as custom integration method to build your own connector via highly scalable REST API. For ex, although there is no first class connector for Spark, you can hook a snippet of code at end of your Spark job to report lineage/metadata info into Atlas. More native connectors being worked for future releases: NiFi and Hbase We also have partner program for ‘Gov ready’ certification and you can see a list of partners who have already built integration Some interesting ones: Talend: data pipelining done in their canvas gets faithfully converted into Atlas lineage graph so we’re able to capture all the steps/transformations/metadata for each of the processes/entities in that chain Dataguise/Waterline do data discovery and are able to publish classification in bulk into Atlas. Same can be done for lineage IGC is special…its joined at the hip with Atlas: they will have one to one model equivalency in terms of backend and will be able to query each other for metadata/lineage etc
- #35: The maintenance of metadata must be automated to scale to the sheer volumes and variety of data involved in modern business. Metadata management must become ubiquitous in cloud platforms and large data platforms, such as Apache Hadoop so that the processing engines on these platforms can rely on its availability and build capability around it. Metadata access must become open and remotely accessible so that tools from different vendors can work with metadata located on different platforms. This implies unique identifiers for metadata elements, some level of standardization in the types and formats for metadata and standard interfaces for manipulating metadata. Metadata should be used to drive the governance of data and create a business friendly logical interface to the data landscape. Wherever possible, discovery and maintenance of metadata has to an integral part of all tools that access, change and move information.
- #38: So how does this work in a real life context. HortoniaBank is a multinational bank and insurer with offices in EU and US (Dublin, Prague, SF) and 2 clusters in AWS/Azure - all types of data from multiple sources - IoT, social, mobile etc. and applications/systems CRM, EMR, etc.