Hadoop Cluster Configuration and Data Loading - Module 2
Download as PPTX, PDF1 like841 views

The document outlines the configuration and architecture of a Hadoop cluster, including specifications for hardware, configuration files, and operating modes. It provides details on different cluster types and the necessary Hadoop shell commands for managing files within HDFS. Additionally, it includes references for further reading on Hadoop hardware recommendations and configurations.









![Hadoop Shell commands contd..
• See contents of a file
Usage: hadoop fs -cat <path[filename]>
Example: hadoop fs -cat /user/saurzcode/dir1/abc.txt
• Move file from source to destination.
Usage: hadoop fs -mv <src> <dest>
Example: hadoop fs -mv /user/saurzcode/dir1/abc.txt /user/saurzcode/dir2
• Remove a file or directory in HDFS.
Usage : hadoop fs -rm <arg>
Example: hadoop fs -rm /user/saurzcode/dir1/abc.txt
Usage : hadoop fs -rmr <arg>
Example: hadoop fs -rmr /user/saurzcode/](https://image.slidesharecdn.com/module2-161021183215/85/Hadoop-Cluster-Configuration-and-Data-Loading-Module-2-11-320.jpg)
![Hadoop Shell commands contd..
• Display last few lines of a file.
Usage : hadoop fs -tail <path[filename]>
Example: hadoop fs -tail /user/saurzcode/dir1/abc.txt
• Display the aggregate length of a file.
Usage : hadoop fs -du <path>
Example: hadoop fs -du /user/saurzcode/dir1/abc.txt](https://image.slidesharecdn.com/module2-161021183215/85/Hadoop-Cluster-Configuration-and-Data-Loading-Module-2-12-320.jpg)



Hadoop Cluster Configuration and Data Loading - Module 2
- 1. Hadoop Cluster Configuration and Data Loading
- 2. Hadoop Cluster Specification • Hadoop is designed to run on commodity hardware • “Commodity” does not mean “low-end.” • Processor • 2 quad-core 2-2.5GHz CPUs • Memory • 16-24 GB ECC RAM1 • Storage • 4 × 1TB SATA disks • Network • Gigabit Ethernet
- 4. Hadoop Cluster Configuration files Filename Format Description hadoop-env.sh Bash script Environment variables that are used in the scripts to run Hadoop. core-site.xml Hadoop configuration XML Configuration settings for Hadoop Core, such as I/O settings that are common to HDFS and MapReduce. hdfs-site.xml Hadoop configuration XML Configuration settings for HDFS daemons: the namenode, the secondary namenode, and the datanodes. mapred-site.xml Hadoop configuration XML Configuration settings for MapReduce daemons: the jobtracker, and the tasktrackers. masters Plain text A list of machines (one per line) that each run a secondary namenode. slaves Plain text A list of machines (one per line) that each run a datanode and a tasktracker.
- 5. Hadoop Cluster Modes • Standalone (or local) mode There are no daemons running and everything runs in a single JVM. Standalone mode is suitable for running MapReduce programs during development, since it is easy to test and debug them. • Pseudo-distributed mode The Hadoop daemons run on the local machine, thus simulating a cluster on a small scale. • Fully distributed mode The Hadoop daemons run on a cluster of machines.
- 6. Multi-Node Hadoop Cluster Reference: http://www.michael- noll.com/tutorials/running-hadoop-on-ubuntu-linux- multi-node-cluster/
- 7. A Typical Production Hadoop Cluster Machine Type Workload Pattern/ Cluster Type Storage Processor (# of Cores) Memory (GB) Network Slaves Balanced workload Four to six 1 TB disks Dual Quad 24 Dual 1 GB links for all nodes in a 20 node rack and 2 x 10 GB intercon- nect links per rack going to a pair of central switches. Compute intensive workload Four to six 1 TB or 2 TB disks Dual Hexa Quad 24-48 I/O intensive workload Twelve 1 TB disks Dual Quad 24-48 HBase clusters Twelve 1 TB disks Dual Hexa Quad 48-96 Masters All workload pat- terns/HBase clusters Four to six 2 TB disks Dual Quad Depends on number of file system objects to be created by NameNode. References : http://docs.hortonworks.com/HDP2Alpha/index.htm#Hardware_Recommendations_for_Hadoop.htm
- 8. MapReduce Job execution (Map Task)
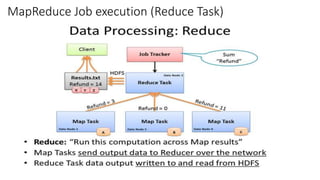
- 9. MapReduce Job execution (Reduce Task)
- 10. Hadoop Shell commands • Create a directory in HDFS at given path(s) Usage: hadoop fs -mkdir <paths> Example: hadoop fs -mkdir /user/saurzcode/dir1 /user/saurzcode/dir2 • List the contents of a directory Usage: hadoop fs -ls <args> Example: hadoop fs -ls /user/saurzcode • Upload and download a file in HDFS. Usage: hadoop fs -put <localsrc> ... <HDFS_dest_Path> Example: hadoop fs -put /home/saurzcode/Samplefile.txt /user/saurzcode/dir3/ Usage: hadoop fs -get <hdfs_src> <localdst> Example: hadoop fs -get /user/saurzcode/dir3/Samplefile.txt /home/
- 11. Hadoop Shell commands contd.. • See contents of a file Usage: hadoop fs -cat <path[filename]> Example: hadoop fs -cat /user/saurzcode/dir1/abc.txt • Move file from source to destination. Usage: hadoop fs -mv <src> <dest> Example: hadoop fs -mv /user/saurzcode/dir1/abc.txt /user/saurzcode/dir2 • Remove a file or directory in HDFS. Usage : hadoop fs -rm <arg> Example: hadoop fs -rm /user/saurzcode/dir1/abc.txt Usage : hadoop fs -rmr <arg> Example: hadoop fs -rmr /user/saurzcode/
- 12. Hadoop Shell commands contd.. • Display last few lines of a file. Usage : hadoop fs -tail <path[filename]> Example: hadoop fs -tail /user/saurzcode/dir1/abc.txt • Display the aggregate length of a file. Usage : hadoop fs -du <path> Example: hadoop fs -du /user/saurzcode/dir1/abc.txt
- 13. Hadoop Copy Commands • Copy a file from source to destination Usage: hadoop fs -cp <source> <dest> Example: hadoop fs -cp /user/saurzcode/dir1/abc.txt /user/saurzcode/dir2 • Copy a file from/To Local file system to HDFS Usage: hadoop fs -copyFromLocal <localsrc> URI Example: hadoop fs -copyFromLocal /home/saurzcode/abc.txt /user/saurzcode/abc.txt Usage: hadoop fs -copyToLocal URI <localdst> Example: hadoop fs -copyFromLocal /user/saurzcode/abc.txt /home/saurzcode/abc.txt