Hadoop Jungle
6 likes1,298 views

The document is a comprehensive overview of Hadoop and its components, focusing on big data processing techniques and tools such as MapReduce, HDFS, and YARN. It discusses various concepts including parallel computing, fault tolerance, and the architecture of Hadoop, as well as practical code examples for MapReduce tasks. Additionally, the document emphasizes performance tuning, testing strategies, and infrastructure improvements for effective big data management.





































































![70Hadoop Jungle
Minimal
Runner
public class MinimalMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf());
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduce(), args);
System.exit(exitCode);
}
}](https://image.slidesharecdn.com/hadoop2016-160321073736/85/Hadoop-Jungle-70-320.jpg)
![71Hadoop Jungle
Minimal
Runner
public class MinimalMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf());
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduce(), args);
System.exit(exitCode);
}
}](https://image.slidesharecdn.com/hadoop2016-160321073736/85/Hadoop-Jungle-71-320.jpg)
![72Hadoop Jungle
Minimal
Runner
public class MinimalMapReduce extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = new Job(getConf());
job.setJarByClass(getClass());
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MinimalMapReduce(), args);
System.exit(exitCode);
}
}](https://image.slidesharecdn.com/hadoop2016-160321073736/85/Hadoop-Jungle-72-320.jpg)



























![100Hadoop Jungle
How to get data from Cache?
To list the content of Distributed Cache:
Path[] pathes = JobContext.getLocalCacheFiles();
Then you have to check this URI to pick up your file
for(Path u : pathes) {
if(u.getName().toUpperCase.contains(“TARGET”)) {
….
}
}](https://image.slidesharecdn.com/hadoop2016-160321073736/85/Hadoop-Jungle-100-320.jpg)





![106Hadoop Jungle
• You want to send by other rule (hash to value)
• Need know more about secondary sort
• Extend Partitioner abstract class
• getPartition(key, value, number of Reducers)
• Return int [0, number of Reducers – 1]
• Don’t forget job.setPartitionerClass(MyPartitioner.class);
How to customize?](https://image.slidesharecdn.com/hadoop2016-160321073736/85/Hadoop-Jungle-106-320.jpg)




























Hadoop Jungle
- 1. Hadoop Jungle Alexey Zinovyev, Java/BigData Trainer in EPAM
- 2. 2Hadoop Jungle About I am a <graph theory, machine learning, traffic jams prediction, BigData algorithms> scientist But I'm a <Java, Scala, NoSQL, Hadoop, Spark> programmer and trainer
- 3. 3Hadoop Jungle Contacts E-mail : Alexey_Zinovyev@epam.com Twitter : @zaleslaw @BigDataRussia vk.com/big_data_russia Big Data Russia vk.com/java_jvm Java & JVM langs
- 4. 4Hadoop Jungle Are you a Hadoop developer?
- 5. 5Hadoop Jungle Let’s do THIS!
- 6. 6Hadoop Jungle WHAT IS BIG DATA?
- 7. 7Hadoop Jungle Joke about Excel
- 8. 8Hadoop Jungle Every 60 seconds…
- 9. 9Hadoop Jungle From Mobile Devices
- 10. 10Hadoop Jungle We started to keep and handle stupid new things!
- 11. 11Hadoop Jungle 10^6 rows in MySQL
- 13. 13Hadoop Jungle Is BigData about PBs?
- 14. 14Hadoop Jungle Is BigData about PBs?
- 15. 15Hadoop Jungle It’s hard to … • .. store • .. handle • .. search in • .. visualize • .. send in network
- 16. 16Hadoop Jungle Just do it … in parallel
- 17. 17Hadoop Jungle Scale-up vs scale-out Scale - Up16 CPUs 16 CPUs Scale - Out 48 CPUs 16 CPUs 16 CPUs 16 CPUs
- 18. 18Hadoop Jungle Motivation: Fault tolerance
- 19. 19Hadoop Jungle Motivation: Fault tolerance
- 20. 20Hadoop Jungle You need to write • .. distributed on-disk storage
- 21. 21Hadoop Jungle You need to write • .. distributed on-disk storage • .. in-memory storage (or shared memory buffer)
- 22. 22Hadoop Jungle You need to write • .. distributed on-disk storage • .. in-memory storage (or shared memory buffer) • .. thread pool to run hundreds of threads
- 23. 23Hadoop Jungle You need to write • .. distributed on-disk storage • .. in-memory storage (or shared memory buffer) • .. thread pool to run hundreds of threads • .. synchronize all components
- 24. 24Hadoop Jungle You need to write • .. distributed on-disk storage • .. in-memory storage (or shared memory buffer) • .. thread pool to run hundreds of threads • .. synchronize all components • .. provide API for reusing by other developers
- 25. 25Hadoop Jungle All we love reinvent bicycles, but…
- 29. 29Hadoop Jungle The main concept Let’s read data in parallel
- 31. 31Hadoop Jungle The main concept Let’s read data in parallel
- 32. 32Hadoop Jungle It must survive
- 33. 33Hadoop Jungle Parallel Computing vs Distributed Computing
- 34. 34Hadoop Jungle Hadoop and its workers: send me your little code
- 36. 36Hadoop Jungle • Hadoop Commons • Hadoop Clients • HDFS • YARN • MapReduce Main components
- 37. 37Hadoop Jungle Hadoop frameworks • Universal MapReduce, Tez, Kudu, RDD in Spark) • Abstract (Pig, Pipeline Spark) • SQL - like (Hive, Impala, Spark SQL) • Processing graph (Giraph, GraphX) • Machine Learning (Mahout, MLib) • Stream processing (Spark Streaming, Storm)
- 39. 39Hadoop Jungle • Automatic parallelization and distribution • Fault-tolerance • Data Locality • Writing the Map and Reduce functions only • Single-threaded model Key features
- 41. 41Hadoop Jungle The main idea 'Time to transfer' > 'Time to seek'
- 43. 43Hadoop Jungle Files in HDFS
- 44. 44Hadoop Jungle • NameNode HDFS node types
- 45. 45Hadoop Jungle • NameNode • DataNode HDFS node types
- 46. 46Hadoop Jungle • NameNode • DataNode • SecondaryNode (not for HA) HDFS node types
- 47. 47Hadoop Jungle • NameNode • DataNode • SecondaryNode • StandbyNode HDFS node types
- 48. 48Hadoop Jungle • NameNode • DataNode • SecondaryNode • StandbyNode • Checkpoint Node HDFS node types
- 49. 49Hadoop Jungle • NameNode • DataNode • SecondaryNode • StandbyNode • Checkpoint Node • Backup Node HDFS node types
- 50. 50Hadoop Jungle The main thought about HDFS HDFS node is JVM daemon
- 51. 51Hadoop Jungle • monitor with JMX • use jmap, jps and so on.. • configure NameNode Heap Size • use power of JVM flags You can do it with HDFS node
- 53. 53Hadoop Jungle MapReduce in different languages
- 54. 54Hadoop Jungle • WordCount • Log handling • Filtering • Reporting Preparation MR Typical Tasks
- 55. 55Hadoop Jungle Why should we use MapReduce?
- 56. 56Hadoop Jungle We try to reduce ‘time to act’ but keep BigData
- 58. 58Hadoop Jungle Do you like batches?
- 60. 60Hadoop Jungle Filter all elements
- 61. 61Hadoop Jungle Yet One YARN’s lover
- 62. 62Hadoop Jungle Pay attention! Hadoop != MapReduce
- 63. 63Hadoop Jungle Think in Key-Value style map (k1, v1) → list(k2, v2) reduce (k2, list(v2*) )→ list(k3, v3)
- 64. 64Hadoop Jungle • Map Main steps
- 65. 65Hadoop Jungle • Map • Shuffle Main steps
- 66. 66Hadoop Jungle • Map • Shuffle • Reduce Main steps
- 67. 67Hadoop Jungle
- 68. 68Hadoop Jungle
- 69. 69Hadoop Jungle The main performance idea Reduce shuffle time & resources
- 70. 70Hadoop Jungle Minimal Runner public class MinimalMapReduce extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Job job = new Job(getConf()); job.setJarByClass(getClass()); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new MinimalMapReduce(), args); System.exit(exitCode); } }
- 71. 71Hadoop Jungle Minimal Runner public class MinimalMapReduce extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Job job = new Job(getConf()); job.setJarByClass(getClass()); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new MinimalMapReduce(), args); System.exit(exitCode); } }
- 72. 72Hadoop Jungle Minimal Runner public class MinimalMapReduce extends Configured implements Tool { @Override public int run(String[] args) throws Exception { Job job = new Job(getConf()); job.setJarByClass(getClass()); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new MinimalMapReduce(), args); System.exit(exitCode); } }
- 75. 75Hadoop Jungle Hadoop club rules
- 77. 77Hadoop Jungle MapReduce for WordCount
- 80. 80Hadoop Jungle Combiner as a Local Reducer
- 81. 81Hadoop Jungle Can we make something around map(), reduce() calls?
- 82. 82Hadoop Jungle Setup /** * Called once at the start of the task. */ protected void setup(Context context ) throws IOException, InterruptedException { // Prepare something for each Mapper or Reducer // Validate external sources }
- 83. 83Hadoop Jungle Setup /** * Called once at the end of the task. */ protected void cleanup(Context context ) throws IOException, InterruptedException { // Finish something after each Mapper or Reducer // Handle specific exceptions }
- 85. 85Hadoop Jungle Run Mapper /** * Expert users can override this method for more complete control over the * execution of the Mapper. * @param context * @throws IOException */ public void run(Context context) throws IOException, InterruptedException { setup(context); try { while (context.nextKeyValue()) { map(context.getCurrentKey(), context.getCurrentValue(), context); } } finally { cleanup(context); } }
- 86. 86Hadoop Jungle Run Reducer /** * Advanced application writers can use the * {@link #run(*.Reducer.Context)} method to * control how the reduce task works. */ public void run(Context context) throws IOException, InterruptedException { setup(context); try { while (context.nextKey()) { reduce(context.getCurrentKey(), context.getValues(), context); // If a back up store is used, reset it Iterator<VALUEIN> iter = context.getValues().iterator(); if(iter instanceof ReduceContext.ValueIterator) { ((ReduceContext.ValueIterator<VALUEIN>)iter).resetBackupStore(); } } } finally { cleanup(context); } }
- 88. 88Hadoop Jungle How many Reducers do we need?
- 89. 89Hadoop Jungle Data Flow with single Reducer
- 90. 90Hadoop Jungle • receives all keys in sorted order • the output will be completely in sorted order • take a long time to run • can throw OutOfMemory One Reducer
- 91. 91Hadoop Jungle Data Flow with multiple Reducers
- 92. 92Hadoop Jungle How many Reducers should we do?
- 93. 93Hadoop Jungle • Key will be the weekday • Seven Reducers will be specified • A Partitioner will be written which sends one key to each Reducer Ideal Case: data grouped by day of week
- 94. 94Hadoop Jungle Could we skip shuffle step?
- 95. 95Hadoop Jungle Map-Only ‘MapReduce’ Jobs
- 97. 97Hadoop Jungle
- 98. 98Hadoop Jungle The main concept of Distributed Cache Share common data
- 99. 99Hadoop Jungle • For ToolRunner in command line with –files option • - archives • - libjars • In code Job.addCacheFile(URI uriToFileInHdfs); • Job.addCacheArchive(URI uriToArchiveFileInHdfs); • Job.addArchiveToClassPath(Path pathToJarInHdfs); How to implement?
- 100. 100Hadoop Jungle How to get data from Cache? To list the content of Distributed Cache: Path[] pathes = JobContext.getLocalCacheFiles(); Then you have to check this URI to pick up your file for(Path u : pathes) { if(u.getName().toUpperCase.contains(“TARGET”)) { …. } }
- 103. 103Hadoop Jungle May I customize DataFlow before shuffling?
- 104. 104Hadoop Jungle Hash Partitioner just do it.. public class HashPartitioner<K2, V2> extends Partitioner<K2, V2> { public int getPartition(K2 key, V2 value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
- 105. 105Hadoop Jungle Partitioner’s Role in Shuffle and Sort
- 106. 106Hadoop Jungle • You want to send by other rule (hash to value) • Need know more about secondary sort • Extend Partitioner abstract class • getPartition(key, value, number of Reducers) • Return int [0, number of Reducers – 1] • Don’t forget job.setPartitionerClass(MyPartitioner.class); How to customize?
- 110. 110Hadoop Jungle The main concept of JOIN Let’s skip Reduce + Shuffle
- 112. 112Hadoop Jungle Map-side join for large datasets
- 113. 113Hadoop Jungle What about Really Large Tables? SELECT Employees.Name, Employees.Age, Department.Name FROM Employees INNER JOIN Department ON Employees.Dept_Id=Department.Dept_Id
- 114. 114Hadoop Jungle The main JOIN idea fro large tables Redis or Memcache cluster as Distributed Cache
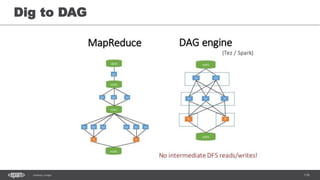
- 116. 116Hadoop Jungle Dig to DAG
- 117. 117Hadoop Jungle The main concept of DAG Decompose you problem, build DAG, skip HDFS
- 118. Let’s run on JVM!
- 120. 120Hadoop Jungle Typical mistakes • Collections in memory • Sorting all data in memory • Logging each input key-value pairs • Many JARs • JVM issues
- 121. 121Hadoop Jungle Performance tips • Correct data storage (on JVM ) • Don’t forget about combiner • Use appropriate Writable type • Min required replication factor • Tune your JVM • Think in terms Big-O
- 122. 122Hadoop Jungle JVM tuning • mapred.child.java.opts • -XX:+PrintGCDetails -XX:+PrintGCTimeStamps • Low-latence GC collector –XX: + UseConcMarkSweepGC, -XX:ParallelGCThreads • Xmx == Xms (max and starting heap size)
- 123. 123Hadoop Jungle JVM Reusing: Uber Task
- 124. 124Hadoop Jungle TESTING & DEVELOPMENT
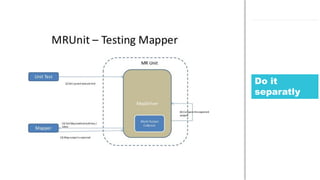
- 125. 125Hadoop Jungle MR Unit idea
- 127. 127Hadoop Jungle Simple Test public class MRUnitHelloWorld { MapDriver<LongWritable, Text, Text, IntWritable> mapDriver; @Before public void setUp() { WordMapper mapper = new WordMapper(); mapDriver = new MapDriver<LongWritable, Text, Text, IntWritable>(); mapDriver.setMapper(mapper); } @Test public void testMapper() { mapDriver.withInput(new LongWritable(1), new Text("cat dog")); mapDriver.withOutput(new Text("cat"), new IntWritable(1)); mapDriver.withOutput(new Text("dog"), new IntWritable(1)); mapDriver.runTest(); } }
- 128. 128Hadoop Jungle • First develop/test in local mode using small amount of data Testing strategies
- 129. 129Hadoop Jungle • First develop/test in local mode using small amount of data • Test in pseudo-distributed mode and more data Testing strategies
- 130. 130Hadoop Jungle • First develop/test in local mode using small amount of data • Test in pseudo-distributed mode and more data • Test on fully distributed mode and even more data Testing strategies
- 131. 131Hadoop Jungle • First develop/test in local mode using small amount of data • Test in pseudo-distributed mode and more data • Test on fully distributed mode and even more data • Final execution: fully distributed mode & all data Testing strategies
- 132. 132Hadoop Jungle And we can DO IT! Real-Time Data-Marts Batch Data-Marts Relations Graph Ontology Metadata Search Index Events & Alarms Real-time Dashboarding Events & Alarms All Raw Data backup is stored here Real-time Data Ingestion Batch Data Ingestion Real-Time ETL & CEP Batch ETL & Raw Area Scheduler Internal External Social HDFS → CFS as an option Time-Series Data Titan & KairosDB store data in Cassandra Push Events & Alarms (Email, SNMP etc.)
- 133. 133Hadoop Jungle It reminds me …
- 134. 134Hadoop Jungle Infrastructure issues are waiting YOU!
- 135. 135Hadoop Jungle • Move to Java 8 • Support more than 2 NameNodes (multiple standby NameNodes) • Derive heap size or mapreduce.*.memory.mb automatically • Work with SSD, RAM, HDD, CPU as resources for YARN • Support Docker containers Hadoop 3: Roadmap
- 136. 136Hadoop Jungle MapReduce is not a ideal approach! But it works!