[INSIGHT OUT 2011] B26 optimising a two table join(jonathan lewis)
5 likes652 views

The document discusses optimizing a query that performs a join between an orders table and a products table. It describes the initial plan which does a full table scan of the orders table before probing the products table, examining ways to reduce the number of visits to the products table by leveraging partitioning or indexes on the orders table. It also considers creating a composite index on the orders table to further filter rows before accessing the products table.


















[INSIGHT OUT 2011] B26 optimising a two table join(jonathan lewis)
- 1. How to optimize a … two-table join Jonathan Lewis jonathanlewis.wordpress.com www.jlcomp.demon.co.uk Who am I ? Independent Consultant. 27+ years in IT 23+ using Oracle Strategy, Design, Review, Briefings, Educational, Trouble-shooting jonathanlewis.wordpress.com www.jlcomp.demon.co.uk Member of the Oak Table Network Oracle ACE Director Oracle author of the year 2006 Select Editor’s choice 2007 O1 visa for USA Jonathan Lewis Most slides have a foot-note. This is a brief summary of the comments that I Two Tables © 2011 should have made whilst displaying the slide, and is there for later reference. 2 / 38 1
- 2. Basic Query select ord.* from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ; http://jonathanlewis.wordpress.com/2011/06/23/video/ Jonathan Lewis This is a version of a production query: "Find recent sales of classical CD." Two Tables © 2011 The URL leads to a video of a similar presentation I did in Turkey. 3 / 38 Products create table products ( id number(8,0) not null, product_group varchar2(20) not null, description varchar2(64) not null, constraint prd_pk primary key (id) ); Products: 1,000,000 "CLASSICAL CD" 1,000 Jonathan Lewis The products table was about 1M rows, of which about 1,000 were classical Two Tables © 2011 CDs - we can build a model of this very quickly 4 / 38 2
- 3. Orders create table orders( id number(10,0) not null, date_placed date not null, id_product number(8,0) not null, padding varchar2(64) not null, constraint ord_pk primary key (id), constraint ord_fk_prd foreign key (id_product) references products (id) ); create index ord_fk_prd on orders(id_product) compress; 250,000 per day - 250M in production (ca. 3 years), 6.5M in demo. Jonathan Lewis The orders table was quite large, and referenced products. The system Two Tables © 2011 allowed only one item per order - no "order lines" table. 5 / 38 Initial Plan (11g) | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | | | 2 | NESTED LOOPS | | 1113 | |* 3 | TABLE ACCESS FULL | ORDERS | 255K| |* 4 | INDEX UNIQUE SCAN | PRD_PK | 1 | |* 5 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | Predicate Information (identified by operation id): 3 - filter("ORD"."DATE_PLACED">SYSDATE@!-1) 4 - access("ORD"."ID_PRODUCT"="PRD"."ID") 5 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis This is the basic plan from my first model. Two Tables © 2011 The full tablescan is an obvious threat - but might not be. 6 / 38 3
- 4. Partitioned Plan | Id | Operation | Name | Rows | Pstart| Pstop | | 0 | SELECT STATEMENT | | 1113 | | | | 1 | NESTED LOOPS | | | | | | 2 | NESTED LOOPS | | 1113 | | | | 3 | PARTITION RANGE ITERATOR | | 255K| KEY | 997 | |* 4 | TABLE ACCESS FULL | ORDER2 | 255K| KEY | 997 | |* 5 | INDEX UNIQUE SCAN | PRD_PK | 1 | | | |* 6 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | | | Predicate Information (identified by operation id): 4 - filter("ORD"."DATE_PLACED">SYSDATE@!-1) 5 - access("PRD"."ID"="ORD"."ID_PRODUCT") 6 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis If the order table had been partitioned by day the a tablescan of the last two Two Tables © 2011 partitions would have been a reasonable starting strategy 7 / 38 Indexed access path create index ord_dat_prd on orders (date_placed); | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | | | 2 | NESTED LOOPS | | 1113 | | 3 | TABLE ACCESS BY INDEX ROWID| ORDERS | 255K| |* 4 | INDEX RANGE SCAN | ORD_DAT | 255K| |* 5 | INDEX UNIQUE SCAN | PRD_PK | 1 | |* 6 | TABLE ACCESS BY INDEX ROWID | PRODUCTS | 1 | Predicate Information (identified by operation id): 4 - access("ORD"."DATE_PLACED">SYSDATE@!-1) 5 - access("ORD"."ID_PRODUCT"="PRD"."ID") 6 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD')! Jonathan Lewis The live system had an index on orders(date_placed), and was using it for Two Tables © 2011 this query. It's a good idea since the data for a day is well clustered. 8 / 38 4
- 5. Excess Visits - a 250,000 index entries 250,000 rows (orders) 250,000 PK probes 250,000 Rows (products) 249,750 discards Jonathan Lewis This is an approximate picture of the query and the work it did. There are Two Tables © 2011 only a few orders for the date range - but we visit a lot of irrelevant orders. 9 / 38 Excess Visits - a' 250,000 index entries 250,000 rows (orders) 250,000 PK probes 250,000 Rows (products) 249,750 discards Jonathan Lewis Because recent orders are at the end of the table, this is a slightly better Two Tables © 2011 picture. Recent orders will mostly be cached. 10 / 38 5
- 6. Excess Visits - b 250,000 Index entries (orders) 250,000 PK Probes (products) 250,000 Rows 249,750 discards (products) 250 Rows by rowid (orders) Can we make this happen ? Jonathan Lewis It would be nice if we worked out which orders were for classical CDS Two Tables © 2011 before we visited the orders table - but is that possible. 11 / 38 Indexed access path - 2 create index ord_dat_prd on orders (date_placed, id_product); Execution plan (still visiting orders table early) . | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | | | 2 | NESTED LOOPS | | 1113 | | 3 | TABLE ACCESS BY INDEX ROWID| ORDERS | 255K| |* 4 | INDEX RANGE SCAN | ORD_DAT_PRD | 255K| |* 5 | INDEX UNIQUE SCAN | PRD_PK | 1 | |* 6 | TABLE ACCESS BY INDEX ROWID | PRODUCTS | 1 | Predicate Information (identified by operation id): 4 - access("ORD"."DATE_PLACED">SYSDATE@!-1) 5 - access("ORD"."ID_PRODUCT"="PRD"."ID") 6 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis A first step would be to change the index on orders to include the product id. Two Tables © 2011 But we still visit the orders table before checking the product table. 12 / 38 6
- 7. Basic Query select ord.* -- Oracle MUST visit the table from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ; Jonathan Lewis If we have columns in the select list for the orders table, we MUST visit that Two Tables © 2011 table before we do the join. 13 / 38 Rowids only select ord.rowid from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ; Jonathan Lewis So let's write a query that doesn't select any other columns from the table and Two Tables © 2011 see what happens. 14 / 38 7
- 8. Rowid plan | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1114 | | 1 | NESTED LOOPS | | | | 2 | NESTED LOOPS | | 1114 | |* 3 | INDEX RANGE SCAN | ORD_DAT_PRD | 256K| |* 4 | INDEX UNIQUE SCAN | PRD_PK | 1 | |* 5 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | Predicate Information (identified by operation id): 3 - access("ORD"."DATE_PLACED">SYSDATE@!-1) 4 - access("PRD"."ID"="ORD"."ID_PRODUCT") 5 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis We get the plan we want - but we're not picking up order data. Two Tables © 2011 15 / 38 Rewrite select ord2.* from ( select ord.rowid from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ) ordv, orders ord2 where ord2.rowid = ordv.rowid; Jonathan Lewis So let's run that query to get rowids, then go to the orders table. Two Tables © 2011 16 / 38 8
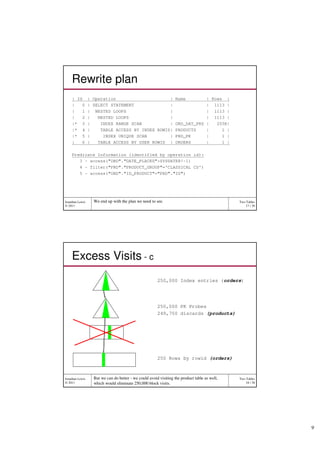
- 9. Rewrite plan | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | 1113 | | 2 | NESTED LOOPS | | 1113 | |* 3 | INDEX RANGE SCAN | ORD_DAT_PRD | 255K| |* 4 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | |* 5 | INDEX UNIQUE SCAN | PRD_PK | 1 | | 6 | TABLE ACCESS BY USER ROWID | ORDERS | 1 | Predicate Information (identified by operation id): 3 - access("ORD"."DATE_PLACED">SYSDATE@!-1) 4 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') 5 - access("ORD"."ID_PRODUCT"="PRD"."ID") Jonathan Lewis We end up with the plan we need to see. Two Tables © 2011 17 / 38 Excess Visits - c 250,000 Index entries (orders) 250,000 PK Probes 249,750 discards (products) 250 Rows by rowid (orders) Jonathan Lewis But we can do better - we could avoid visiting the product table as well, Two Tables © 2011 which would eliminate 250,000 block visits. 18 / 38 9
- 10. Rewrite and Reindex alter table orders drop constraint ord_fk_prd; alter table products drop primary key; drop index prd_pk; alter table products add constraint prd_pk primary key(id) using index( create index prd_pk on products(id, product_group) ) ; alter table orders add constraint ord_fk_prd foreign key (id_product) references products(id) ; Jonathan Lewis Again we extend an index definition. This is a little harder because it's a Two Tables © 2011 primary key index, so we have to drop and recreate the PK. 19 / 38 Rewrite & Reindex Plan | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | 1113 | | 2 | NESTED LOOPS | | 1113 | |* 3 | INDEX RANGE SCAN | ORD_DAT_PRD | 255K| |* 4 | INDEX RANGE SCAN | PRD_PK | 1 | | 5 | TABLE ACCESS BY USER ROWID| ORDERS | 1 | Predicate Information (identified by operation id): 3 - access("ORD"."DATE_PLACED">SYSDATE@!-1) 4 - access("ORD"."ID_PRODUCT"="PRD"."ID" AND "PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis With the change in place, we get the plan we wanted. But we are still doing Two Tables © 2011 250,000 probes of the product index - can we reduce that? 20 / 38 10
- 11. Excess Visits - d 250,000 Index entries (orders) 1,000 index entries(products) 249,750 discards on hash probe 250 Rows by rowid (orders) create index prd_grp_id on products( product_group, id ) compress 1; Jonathan Lewis If we copy the right part of the product index into private memory we can Two Tables © 2011 probe it in private and reduce the CPU due to latching. 21 / 38 Rewrite/Reindex/Hash Plan | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | | 1 | NESTED LOOPS | | 1113 | |* 2 | HASH JOIN | | 1113 | |* 3 | INDEX RANGE SCAN | PRD_GRP_ID | 1000 | |* 4 | INDEX RANGE SCAN ** | ORD_DAT_PRD | 255K| | 5 | TABLE ACCESS BY USER ROWID| ORDERS | 1 | Predicate Information (identified by operation id): 2 - access("ORD"."ID_PRODUCT"="PRD"."ID") 3 - access("PRD"."PRODUCT_GROUP"='CLASSICAL CD') 4 - filter("ORD"."DATE_PLACED">SYSDATE@!-1) ** My little data set used an index fast full scan. Jonathan Lewis With the hash join in place this is the final plan. Two Tables © 2011 22 / 38 11
- 12. Rewritten SQL - reprise select ord2.* from ( select ord.rowid from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ) ordv, orders ord2 where ord2.rowid = ordv.rowid; Jonathan Lewis Two Tables © 2011 23 / 38 Basic Query select ord.* from orders ord, products prd where ord.date_placed > sysdate - 1 and prd.id = ord.id_product and prd.product_group = 'CLASSICAL CD' ; Jonathan Lewis Two Tables © 2011 24 / 38 12
- 13. Subquery Style select ord.* Common Guideline from orders ord If a table isn't in the where select list it shouldn't ord.date_placed > sysdate - 1 be in the from list and id_product in ( select Warning /*+ no_unnest */ The suggestion may be illegal, incorrect or id idiotic, in some cases. from products prd where prd.product_group = 'CLASSICAL CD' ) ; -- with just the pk, fk, and (date, product) indexes Jonathan Lewis We could take a different approach. We were only selecting columns from Two Tables © 2011 the orders table, and we have a PK on products. A subquery rewrite is valid. 25 / 38 Subquery plan (unhinted) | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1113 | |* 1 | HASH JOIN | | 1113 | |* 2 | TABLE ACCESS FULL | PRODUCTS | 1000 | | 3 | TABLE ACCESS BY INDEX ROWID| ORDERS | 255K| |* 4 | INDEX RANGE SCAN | ORD_DAT_PRD | 255K| Predicate Information (identified by operation id): 1 - access("ID_PRODUCT"="ID") 2 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') 4 - access("ORD"."DATE_PLACED">SYSDATE@!-1) On my data set the optimizer unnested the subquery and turned it into a hash join Note: in the absence of the product PK, this would have been a hash semi-join. Jonathan Lewis This is nearly the execution plan from last join plan - doing a tablescan Two Tables © 2011 instead of an index range scan (that the effect of the small dataset) 26 / 38 13
- 14. Subquery plan (hinted) | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1 | | 1 | TABLE ACCESS BY INDEX ROWID | ORDERS | 12758 | |* 2 | INDEX RANGE SCAN | ORD_DAT_PRD | 12758 | |* 3 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | |* 4 | INDEX UNIQUE SCAN | PRD_PK | 1 | Predicate Information (identified by operation id): 2 - access("ORD"."DATE_PLACED">SYSDATE@!-1) filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "PRODUCTS" "PRD" WHERE "ID"=:B1 AND "PRD"."PRODUCT_GROUP"='CLASSICAL CD')) 3 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') 4 - access("ID"=:B1) Note: the in subquery has been transformed into an exists subquery. Jonathan Lewis To prove a point, I can hint the code into a subquery. Two Tables © 2011 27 / 38 Subquery plan (with my visual hack) | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1 | | 1 | TABLE ACCESS BY INDEX ROWID | ORDERS | 12758 | |* 2a| FILTER | | 12758 | |* 2b| INDEX RANGE SCAN | ORD_DAT_PRD | 255K | |* 3 | TABLE ACCESS BY INDEX ROWID| PRODUCTS | 1 | |* 4 | INDEX UNIQUE SCAN | PRD_PK | 1 | Predicate Information (identified by operation id): 2a - filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "PRODUCTS" "PRD" WHERE "ID"=:B1 AND "PRD"."PRODUCT_GROUP"='CLASSICAL CD')) 2b - access("ORD"."DATE_PLACED">SYSDATE@!-1) 3 - filter("PRD"."PRODUCT_GROUP"='CLASSICAL CD') 4 - access("ID"=:B1) Jonathan Lewis Oracle used to produce plans showing the FILTER operation of subquery, Two Tables © 2011 but since 9i the FILTER sometime "disappears". 28 / 38 14
- 15. Subquery 250,000 Index entries (orders) 250,000 PK Probes (products) 250,000 Rows 249,750 discards (products) 250 Rows by rowid (orders) Jonathan Lewis A visual impression of the subquery approach. The query is simple, the work Two Tables © 2011 is similar to my rewritten approach. Why not do it this way ? 29 / 38 Subquery/Reindex plan create index prd_pk on products(id, product_group); | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 1 | | 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | 12741 | |* 2 | INDEX RANGE SCAN | ORD_DAT_PRD | 12741 | |* 3 | INDEX RANGE SCAN | PRD_PK | 1 | Predicate Information (identified by operation id): 2 - access("ORD"."DATE_PLACED">SYSDATE@!-1) filter( EXISTS (SELECT /*+ NO_UNNEST */ 0 FROM "PRODUCTS" "PRD" WHERE "PRD"."PRODUCT_GROUP"='CLASSICAL CD' AND "ID"=:B1)) 3 - access("ID"=:B1 AND "PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis And we can still do a little better if the indexing is correct, and avoid visiting Two Tables © 2011 the table. 30 / 38 15
- 16. Subquery/Reindex 250,000 Index entries (orders) 250,000 PK Probes (products) 249,750 discards 250 Rows by rowid (orders) Jonathan Lewis The work is then comparable with my last join plan. Two Tables © 2011 31 / 38 Join rewrite vs. Subquery Orders index 250,000 entries Products index 250,000 Probes 249,750 discards Orders table 250 Rows by rowid Jonathan Lewis How much difference is there between these two plans ? Two Tables © 2011 Are there any differences in the internal code. 32 / 38 16
- 17. Join rewrite or Subquery Orders index 250,000 entries Join must happen every row Root block is pinned on join So 2 buffer gets per probe Jonathan Lewis Two Tables © 2011 33 / 38 Join rewrite or Subquery Orders index 250,000 entries Root block not pinned on subquery So 3 gets per probe Subquery may run once per product, rather than once per row. Depends on pattern of product ids Jonathan Lewis Two Tables © 2011 34 / 38 17
- 18. Subquery with sort select ord2.* from ( select ord1.rid from ( select /*+ no_merge no_eliminate_oby */ ord.rowid rid, ord.id_product from orders ord where ord.date_placed > sysdate - 1 order by ord.id_product ) ord1 where exists ( select /*+ no_unnest push_subq */ null from products prd where prd.product_group = 'CLASSICAL CD' and prd.id = ord1.id_product ) ) ordv, orders ord2 where ord2.rowid = ordv.rid Jonathan Lewis If we sort the order index entries by product ID before running the subquery Two Tables © 2011 we guarantee that the subquery runs only once per product (at present). 35 / 38 Subquery with sort - plan | Id | Operation | Name | Rows | | 0 | SELECT STATEMENT | | 254K | | 1 | NESTED LOOPS | | 254K | |* 2 | VIEW | | 254K | | 3 | SORT ORDER BY | | 254K | |* 4 | INDEX RANGE SCAN | ORD_DAT_PRD | 254K | |* 5 | INDEX RANGE SCAN | PRD_PK | 1 | | 6 | TABLE ACCESS BY USER ROWID| ORDERS | 1 | Predicate Information (identified by operation id): 2 - filter( EXISTS (SELECT /*+ PUSH_SUBQ NO_UNNEST */ 0 FROM "PRODUCTS" "PRD" WHERE "PRD"."PRODUCT_GROUP"= 'CLASSICAL CD' AND "PRD"."ID"=:B1)) 4 - access("ORD1"."DATE_PLACED">SYSDATE@!-1) 5 - access("PRD"."ID"=:B1 AND "PRD"."PRODUCT_GROUP"='CLASSICAL CD') Jonathan Lewis Two Tables © 2011 36 / 38 18
- 19. Other Possibilities • Function-based indexes – To minimise the size of the second data set – (could do it with virtual columns in 11g) • Materialized views – On commit refresh, with primary key – Maintain a small data set for the reference • Result cache - 11g – Visit memory rather than data blocks • Deterministic PL/SQL function Jonathan Lewis There are many other ways in which we can reduce work by reducing data Two Tables © 2011 set sizes, or doing the checks more cheaply or less frequently. 37 / 38 Summary • Avoid visiting blocks you don't need • Change indexes to avoid block visits • There are things the optimizer can't do – We can engineer SQL to do things the optimizer can't – Should we take advantage of knowledge of internals ? • There are many possibilities Jonathan Lewis Two Tables © 2011 38 / 38 19