Introduction to oracle DB data structure and data access (persian)
Download as PPTX, PDF1 like1,019 views

data structure and data access Oracle DB Concept






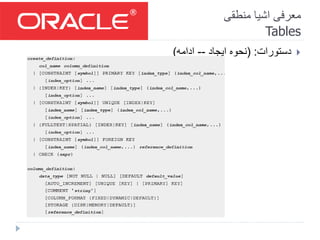








![منطقی اشیا معرفی
Tables
جداول مورد در اطالعات کسب:
دستور از استفادهDesc[ribe]جدول ساختار بررسی برای
جداول بررسی و کردن پیدا برای مدیریتی جداول از استفاده:
خاص جدول:Dual](https://image.slidesharecdn.com/introductiontooracle-datastructureanddataaccess-161218182340/85/Introduction-to-oracle-DB-data-structure-and-data-access-persian-16-320.jpg)













![منطقی اشیا معرفی
Partitions
ها پارتیشن ادغام و سازی فشرده ،حذف:
پارتیشن حذف:می باشد نداشته ای داده پارتیشنی که صورتی دربه توان
دستور با سادگی
ALTER TABLE <T-NAME> DROP PARTITION <P-
NAME> [UPDATE GLOBAL INDEXES];
عبارت جای به باال دستور درPARTITIONعبارت از اگر
SUBPARTITIONپارتیش در پارتیشن زیر حذف به ،شود استفادهن
پردازد می سطحی دو بندی.](https://image.slidesharecdn.com/introductiontooracle-datastructureanddataaccess-161218182340/85/Introduction-to-oracle-DB-data-structure-and-data-access-persian-34-320.jpg)





![منطقی اشیا معرفی
Indexes
B*Tree:می ایجاد مربوطه ستون اساس بر که است متوازن درخت یک
شود.
درخت این نودهای سطح ترین پایین(ها برگ)سم به هایی گر اشارهت
دارند داده محل(ROWID)
مقادیرNULLشوند نمی ذخیره اندکس در
های پرسش برای هم اندکس این از استفاده امکان(برابری)=ب هم ورای
ای بازه های پرسش(< >)است استفاده قابل.
ایجاد نحوه:
CREATE INDEX <I-NAME> ON <T-
NAME>(C1[,C2,…]) TABLESPACE <TBS-NAME>](https://image.slidesharecdn.com/introductiontooracle-datastructureanddataaccess-161218182340/85/Introduction-to-oracle-DB-data-structure-and-data-access-persian-40-320.jpg)






























Introduction to oracle DB data structure and data access (persian)
- 1. Introduction to Oracle Database Data Structure ئی حمزه احسان
- 2. اوراکل در منطقی داده ساختار! Oracle Schema: شود می کاربر به مربوط منطقی اشیا تمامی شامل م ایجاد کاربری نام با نام هم جدید اسکیمایی یک جدید کاربر ایجاد هنگامشود ی عنوان به کاربر که ای منطقی اشیاء تمامیownerهستند شما این در ،دارد. اسکی درون منطقی اشیای به تواند می کاربر دسترسی داشتن صورت درمای کند پیدا دسترسی کاربران سایر. امکانswitchصو در کاربران سایر اسکیمای به کاربر اسکیمای از کردنرت دارد وجود دسترسی وجود(دستورalter session set current schema=?) منطقی اشیا از منظور:،کالسترها ،ها اندکس ،ها پارتیشن ،جداولStored Procedure،هاviewو ها!... همانند را نقشی اسکیماnamespaceکند می ایفا!در حتی اشیا این از برخی باشند نام هم توانند می هم اسکیما یک!
- 3. اوراکل در ای داده انواع ای داده انواع: کاراکتری: Char Nchar Vchar Nvchar عددی Number(p,s) Integer زمان و تاریخ Date Timestamp بزرگ اشیا(LOB) CLOB BLOB BFile
- 4. منطقی اشیا معرفی Tables جداول: دائمی موقت Transaction-Specific Session-Specific جداول: Relational Tables Heap organized Index organized External Object Tables
- 5. منطقی اشیا معرفی Tables نیست ستون و سطر جز به چیزی جدول یک( !بزرگان سخنان)! ها ستون: عادی Invisible ROWID>>Special Case>>Type: ROWID Virtual
- 6. منطقی اشیا معرفی Tables دستورات( :ایجاد نحوه)
- 7. منطقی اشیا معرفی Tables دستورات( :ایجاد نحوه--ادامه)
- 8. منطقی اشیا معرفی Tables دستورات( :ایجاد نحوه--مثال)
- 9. منطقی اشیا معرفی Tables دستورات( :تغییرات ایجاد) ستون کردن اضافه: ستون نام تغییر: ستون حذف: ستون مشخصات تغییر: جدول محتویات تمام حذف:با اطالعات حذفTruncateناپذیر برگشت است( !!دستور ازdeleteشود استفاده)
- 10. منطقی اشیا معرفی Tables دستورات( :تغییرات ایجاد-ادامه) سطح تغییر نحوه(RW/RO:) سطح درReadOnly:
- 11. منطقی اشیا معرفی Tables دستورات( :تغییرات ایجاد-ادامه) جدول حذف: جدول نام تغیر: Alter Table tbl_name Rename To new_tbl_name
- 12. منطقی اشیا معرفی Tables سازی ذخیره: یک جدول هرData Segment سازی ذخیره نوع به بسته(Index Organized, Heap Organized)قالب در سطرها اوراکل کلی حالت در اما ،است متفاوت Row Pieceاست این بر سعی امکان حد در که کند می داری نگه هایی هر ازای به کهRowیکRow Pieceباشد داشته وجود. Null،سطر انتهای هایSkipشوند می. سازی ذخیره بحث برای سازی فشرده امکان: جدول ساده سازی فشرده: سطر پیشرفته سازی فشرده: هیبریدی سازی فشرده(سطری/ستونی:)
- 13. منطقی اشیا معرفی Tables Temporary Tables: مثال:اینترنتی سایت یک در خرید سبد به مربوط جدول
- 14. منطقی اشیا معرفی Tables External Tables: ب یا باشند شده ذخیره قبل از فایل یک درون است ممکن جداول این های دادهه مربو فراداده جدول نوع این تعریف با باشند؛ داده پایگاه از خارج نحوی هربه ط بخش در ها آنData Dictionaryامکان اوراکل به و ،شود می ذخیره دهد می را ها داده پردازش.
- 15. منطقی اشیا معرفی Tables External Tables( :ادامه)
- 16. منطقی اشیا معرفی Tables جداول مورد در اطالعات کسب: دستور از استفادهDesc[ribe]جدول ساختار بررسی برای جداول بررسی و کردن پیدا برای مدیریتی جداول از استفاده: خاص جدول:Dual
- 17. منطقی اشیا معرفی Constraints محدودیت تعریف نحوه: ستون سطح در: جدول سطح در محدودیت انواع: NOT NULL(ستون سطح در فقط) UNIQUE(روش هردو) PRIMARY KEY(روش دو هر) FOREIGN KEY(روش هردو) CHECK(روش هردو)
- 18. منطقی اشیا معرفی Constraints ایجادConstraintایجاد از بعدTableدستور از استفاده باAlTER است پذیر امکان. ر این به ،جدول ایجاد از بعد یکتایی یا اصلی کلید قید که صورتی درایجاد وش سازد نمی ها ستون این روی اتوماتیک صورت به را اندکس اوراکل ،شوند! محدودیت تغییر: حذف: ALTER TABLE table_name DROP CONSTRAINT constraint_name; مربو های اندکس اتوماتیک صورت به یکتایی یا اصلی کلید به مربوط قیود حذف باها آن به ط از دستور انتهای در اینکه مگر ،شود می حذف اوراکل توسطKEEP INDEXشود استفاده.
- 19. منطقی اشیا معرفی Constraints کردن فعال غیر و فعال: دهیم انجام را تنظیمات این بخواهیم ایجاد هنگام در و نباشد موجود اگر: ALTER TABLE table_name ADD CONSTRAINT constraint_name … {ENABLE, DISABLE} {VALIDATE, NOVALIDATE}; باشد موجود اگر: ALTER TABLE table_name {ENABLE, DISABLE} {VALIDATE, NOVALIDATE} CONSTRAINT constraint_name; تعویق با محدودیت کنترل( :ت را ویژگی این بخواهیم و باشد موجود اگرغییر کنیم ایجاد جدید تعویق ویژگی با مجدد و کرده حذف را قید باید دهیم) ALTER TABLE table_name ADD CONSTRAINT constraints_name … DEFEREABLE {INITIALLY IMMEDIATE, INITIALLY DEFERRED}
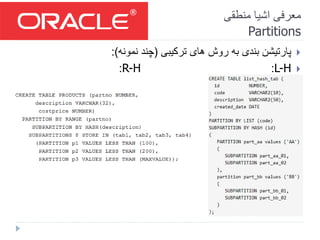
- 20. منطقی اشیا معرفی Partitions بندی؟ پارتیشن مفهوم بندی پارتیشن کلید... مزایا: و بازیابی زمان کاهش ،آسان مدیریت ،کارائی افزایش... کرد؟ بندی پارتیشن باید را جدول یک مواردی چه در جدول اطالعات باالی حجم شده بایگانی اطالعات
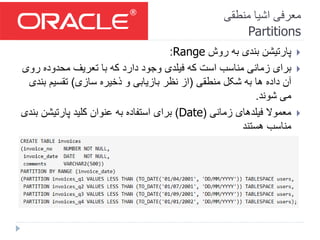
- 21. منطقی اشیا معرفی Partitions بندی پارتیشن روشهای انواع: Range List Hash Interval System Reference Virtual Column-Based سطحی دو بندی پارتیشن(ترکیبی:) R-R, R-L, R-H, L-R, L-L, L-H, I-R, I-L, I-H, H-H
- 22. منطقی اشیا معرفی Partitions روش به بندی پارتیشنRange: ر محدوده تعریف با که دارد وجود فیلدی که است مناسب زمانی برایوی منطقی شکل به ها داده آن(سازی ذخیره و بازیابی نظر از)ب تقسیمندی شوند می. زمانی فیلدهای معموال(Date)پارتیشن کلید عنوان به استفاده برایبندی هستند مناسب
- 23. منطقی اشیا معرفی Partitions روش به بندی پارتیشنList: دارای که دارد وجود فیلدی که حالتی در بندی پارتیشن روش این از ف منطقی شکل به را جدول بندی تقسیم امکان و است محدودی مقادیرراهم شود می استفاده ،آورد می.
- 24. منطقی اشیا معرفی Partitions روش به بندی پارتیشنHash: استف نتوان قبلی روش دو از که است مناسب حالتی برای روش ایناده مانند کلید یک اساس بر و کردidتابع یکHashکه شود می استفاده خروجی مشخصی تعداد به را ستون این در موجود مقادیرMapکند می.
- 25. منطقی اشیا معرفی Partitions روش به بندی پارتیشنInterval: یک روش اینextendروش رویRangeاست حالتی برای و است جدید های داده ورود با کهRangeاین در شود می مطرح جدیدی های روش از که صورتی در حالتRangeخطای پیغام با باشد شده استفادهی شویم می رو روبه زیر شکل به.
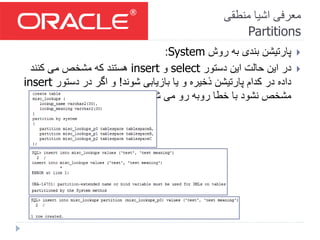
- 26. منطقی اشیا معرفی Partitions روش به بندی پارتیشنSystem: دستور این حالت این درselectوinsertکنند می مشخص که هستند شوند بازیابی یا و ذخیره پارتیشن کدام در داده!دستور در اگر وinsert شود می رو روبه خطا با نشود مشخص!
- 27. منطقی اشیا معرفی Partitions ترکیبی های روش به بندی پارتیشن(نمونه چند:) L-H:R-H:
- 31. منطقی اشیا معرفی Partitions ها پارتیشن روی رایج های فعالیت: 1-بندی پارتیشن به جدید پارتیشن یک کردن اضافهRange 2-بندی پارتیشن به جدید پارتیشن یک کردن اضافهHash 3-بندی پارتیشن به جدید پارتیشن یک کردن اضافهList 4-سطحی دو بندی پارتیشن به جدید پارتیشن یک کردن اضافه 5-پارتیشن سازی فشردهHash 6-پارتیشن حذف 7-پارتیشن ادغام 8-پارتیشن مکان تغییر 9-هرکدام وضعیت و ها پارتیشن از آماری اطالعات آوردن دست به!
- 32. منطقی اشیا معرفی Partitions جدید پارتیشن یک کردن اضافه: ALTER TABLE <T-Name> ADD PARTITION <P- Name> VALUES LESS THAN … TABLESPACE <TBS- Name>; (Range) ALTER TABLE <T-Name> ADD PARTITION <P- NAME> TABLESPACE <TBS-NAME>; (Hash) ALTER TABLE <T-Name> ADD PARTITION <P- NAME> VALUES (…) TABLESPACE <TBS-NAME>
- 33. منطقی اشیا معرفی Partitions جدید پارتیشن یک کردن اضافه(دوسطحی:) ALTER TABLE <T-Name> ADD PARTITION <P- Name> VALUES LESS THAN … TABLESPACE <TBS- Name>; (Range) ALTER TABLE <T-Name> ADD PARTITION <P- NAME> TABLESPACE <TBS-NAME>; (Hash) ALTER TABLE <T-Name> ADD PARTITION <P- NAME> VALUES (…) TABLESPACE <TBS-NAME>
- 34. منطقی اشیا معرفی Partitions ها پارتیشن ادغام و سازی فشرده ،حذف: پارتیشن حذف:می باشد نداشته ای داده پارتیشنی که صورتی دربه توان دستور با سادگی ALTER TABLE <T-NAME> DROP PARTITION <P- NAME> [UPDATE GLOBAL INDEXES]; عبارت جای به باال دستور درPARTITIONعبارت از اگر SUBPARTITIONپارتیش در پارتیشن زیر حذف به ،شود استفادهن پردازد می سطحی دو بندی.
- 35. منطقی اشیا معرفی Partitions پارتیشن جایی جابه: آماری اطالعات آوردن بدست:
- 36. منطقی اشیا معرفی Indexes س آنها از استفاده بعضا که هستند اختیاری ساختار یک ها ایندکسرعت دهد می افزایش جدول یک های پرسش برای را پاسخگویی. ی عنوان به خود و هستند جدول از مستقل صورت به کامال ها ایندکسک کنند می فعالیت مجزا شی. از جلوگیری برای ها ایندکسFull-Scanمی قرار استفاده مورد و ایجاد فیل را جدول از چندانی مقادیر ها آن خروجی که صورتی در اما گیرندتر اض سرباری بلکه کنند نمی کمک کارایی بهبود به تنها نه نکندبه افه آیند می حساب.
- 37. منطقی اشیا معرفی Indexes شود؟ استفاده ایندکس از زمانی چه 1-ناچی درصد به ستون یک حسب بر که دارند وجود رایجی های کوئری که زمانیزی شوند می منتج جدول اطالعات از. 2-از جلوگیری منظور به دهند می دیگری جدول به ارجاع که هایی ستون مورد در full table lockاست منطقی ها ایندکس از استفاده. 3-از اطالعات دریافت دستورات درون که زمانیORDER BY, GROUP BY, UNION, DISTINCTشود می استفاده( .است با و است سازی مرتب به نیاز زیرافاده است شده انجام سازی مرتب خود به خود اندکس از) ک طوری به ،دارد ایندکس از استفاده عدم یا استفاده برای معیاری اوراکلپیش ه نه یا کند می کمک کارائی بهبود به ایندکس از استفاده کند می بینیدر و کند می استفاده ایندکس از نیاز صورت(ص به میتوان کوئری در البتهورت داد را ایندکس از استفاده دستور صریح)!>>Index Clustering Factor
- 38. منطقی اشیا معرفی Indexes رنگ پر نقش ،ایندکس ساختار درROWIDبه شود می احساس کامال از استفاده با مربوطه اندکس روی در داده محل آمدن دست با که طوری ROWIDپی سطر به مربوط های داده سازی ذخیره محل به توان می برد. نشود؟ استفاده ها ایندکس از بهتر زمانی چه مقادیر دارای که هایی ستون مورد درNULLهستند زیاد تکرار با. ها آن داده نوع که هایی ستونDateاست)*( . کوچک جداول باالست آن تغییرات سرعت و میزان که جداولی
- 39. منطقی اشیا معرفی Indexes ها ایندکس وضعیت: Visibility Usability ها ایندکس انواع: B* Tree Bitmap اوراک اندکسها برای شده انجام های فعالیت در فرض پیش صورت بهل نوعB*Treeاز بخواهیم که صورتی در و گیرد می نظر در را Bitmapب انجام را کار این صریح صورت به باید کنیم استفاده هادهیم.
- 40. منطقی اشیا معرفی Indexes B*Tree:می ایجاد مربوطه ستون اساس بر که است متوازن درخت یک شود. درخت این نودهای سطح ترین پایین(ها برگ)سم به هایی گر اشارهت دارند داده محل(ROWID) مقادیرNULLشوند نمی ذخیره اندکس در های پرسش برای هم اندکس این از استفاده امکان(برابری)=ب هم ورای ای بازه های پرسش(< >)است استفاده قابل. ایجاد نحوه: CREATE INDEX <I-NAME> ON <T- NAME>(C1[,C2,…]) TABLESPACE <TBS-NAME>
- 41. منطقی اشیا معرفی Indexes ایندکس از زمانی چهB*Treeکنیم؟ استفاده باشد قبلی شرایط که زمانی+باشد زیاد نظر مورد ستون متمایز مقادیر های ایندکس انواعB*Treeایجاد نوع نظر از یکتا غیر و یکتا معکوس و عادی معمولی و فشرده ساده و مرکب تابع بر مبتنی شده سازی مرتب(صعودی/نزولی) م و فشرده غیر ،غیریکتا صورت به پیشفرض طور به ایندکسهاشده رتب شوند می ایجاد صعودی صورت به!
- 43. منطقی اشیا معرفی Indexes ایندکسBitmap: ست محدودی مقادیر دارای نظر مورد ستون که زمانی باهم منطقی اپراتورهای حسب بر محدود مقادیر با ستون چندین که زمانی شوند می ترکیب(where a=… & b=… | …) دارد وجود پرسش در داده بندی گروه که زمانی. ب آرایه یک است ستون در که مختلفی مقدار هر ازای به حالت این دریتی شود می ایجاد.با جدول یک ازای به پسmآن مشخص ستون که سطر n،دارد متمایز مقدارnآرایهmمقادیر با تایی0یا1که شود می ایجاد 0و نیست مشخص سطر در نظر مورد داده که است این معنی به1 ...
- 44. منطقی اشیا معرفی Indexes ایندکسBitmap: تر شرط با هایی کوئری در کاربرد و ایندکس نوع این از استفادهکیبی
- 45. منطقی اشیا معرفی Indexes ایندکسBitmap: تر شرط با هایی کوئری در کاربرد و ایندکس نوع این از استفادهکیبی
- 46. منطقی اشیا معرفی Indexes BITMAP JOIN INDEX: آورد می فراهم را مختلف جدول دو روی از ایندکس یک تعریف امکان. مبنای اما شود می اعمال اول جدول روی اندکس که طوری به0.1است دوم جدول ها.
- 47. منطقی اشیا معرفی Indexes مقایسهBtree, Bitmap: نکات بخش!!؟ Bitmap Btree کاردینالیتی با هایی ستون برایپایین ب کاردینالیتی با هایی ستون برایاال مناسببرایOLAP مناسببرایOLTP رسانی روز بهمشکل رسانی روز بهساده NULL (OK) NULL (!)
- 48. منطقی اشیا معرفی Indexes Partition Indexes:خود که جداولی برای ها اندکس این کلی طور به شود می استفاده اند شده بندی پارتیشن.عمومی ی دسته دو به و GLOBALمحلی وLOCALشوند می بندی تقسیم. معمولی های ایندکس:نشون یا شوند بندی پارتیشن خود توانند میدر اما د بندی پارتیشن مربوطه جدول از مجزا و مستقل صورت به حالت اینمی جدول در تغییری که درصورتی و گردند(DDL)حالت در دهد رخ دستور انتهای در آنکه مگر شوند می نامعتبر عادیDDLاعالم صراحتا گردد:UPDATE GLOBAL INDEXES
- 49. منطقی اشیا معرفی Indexes GLOBAL INDEX: ی همه یا یک به توانند می ایندکس پارتیشن یک به مربوط عناصر باشند مربوط جدول های پارتیشن. کاربردهای برای مناسبOLTP اطالعات به دسترسی مبنای مجزا صورت به ستون چندین که هایی سناریو هستند. نوع از فقط ها ایندکس نوع اینB*Treeهستند! مستقل صورت به پارتیشن کردن اضافه و حذف
- 50. منطقی اشیا معرفی Indexes GLOBAL INDEX:
- 51. منطقی اشیا معرفی Indexes Local INDEX: مربوطه جدول روی شده انجام بندی پارتیشن مطابق دقیقا(مبنا برهمان ی شرایط همان با و بندی پارتیشن استراتژی همان از ،ستون)! ایندکس و جدول پارتیشن هر یک به یک تناظر! نوع دو هر ازB*Tree, Bitmapباشند توانند می. کاربردهای برای مناسبOLAP مزایا: Availabilityباالتر تر ساده مدیریت ایجاد نحوه: CREATE INDEX <I-Name> ON <T-Name>(<C-Name>) LOCAL;
- 52. منطقی اشیا معرفی Indexes Local INDEX: ها محدودیت: پارتیشن؟ کردن اضافه پارتیشن؟ یک حذف
- 53. منطقی اشیا معرفی Indexes Local INDEX: Prefixed: ایندکس تعریف درLocalاست بندی پارتیشن کلید ستون اولین ها ستون تعریف بخش در و مربوطه! Non-Prefixed: ایندکس تعریف درLocalو نیست بندی پارتیشن کلید ستون اولین ها ستون تعریف بخش در و مربوطهحتی باشد نداشته وجود لیست در کال تواند می. سناریو: جدول(2در پارتیشن2TBS( )ستون کلیدa)کردن فعال غیرTBSدوم! ایجاد2به اندکس2روش(کلیدa,b( + )کلیدb,a) مبنای بر کوئریa,b>>planاز استفاده اوراکل توسطprefixed(با ایندکس انتخاب CBO) مبنای بر کوئریb>>توسط خطاlocal-prefixed(با ایندکس انتخابCBO) شود نمی منتج پارتیشن حذف به اوقات گاهی( !انتخاب زمان در یا کال)شرا در امایط کنند می رفتار شکل یک به نوع دو هر عادی. اندکس یک کند می تعیین که هاست کوئری ماهیت این واقع درlocalشکل کدام به باشد( !در باید طراحی در آنها تکرار فرکانس و مختلف ی ها کوئری به توجه بااین شود گیری تصمیم باره)!
- 54. منطقی اشیا معرفی Indexes مقایسهLocal , Global indexes:
- 55. منطقی اشیا معرفی Indexes Partial Partition Index: پارتیشن سطح در اندکس کردن فعال امکان!!
- 56. منطقی اشیا معرفی Index Organized Table درختی ایندکس ساختار در را خود های داده جداول نوع این(B*Tree)نگه کنند می داری! حتما باید البته است جداول این مزایای از اطالعات بازیابی باالی سرعت گیرد قرار نظر مد نیز آن از استفاده معایب و جداول این های محدودیت. نیست؟ مناسب زمان چه اساس بر دسترسیPKنباشد. باالست اصلی کلید تغییرات یا است زیاد درج عملیات! ها محدودیت: کلیدPKجداول خالف برheapاست اجباری اینجا در است اختیاری که جنس از های ستونLONGباشد داشته تواند نمی. صورت به تواند نمیCLUSTERشود استفاده(شود بازیابی و ذخیره) روش سه به جداول این بندی پارتیشن امکان است ذکر به الزمH,R,Lوجود جدول اصلی کلید از ای مجموعه زیر بندی پارتیشن کلید باید ولی داردباشد!
- 57. منطقی اشیا معرفی Index Organized Table بخش جداول این برای توان می(Segment)داده ذخیره برای مجزایی سرریز های(overflow)گرفت نظر در.اندکس همانند حالت این در اس سرریز بخش در نظر مورد بالک به گری اشاره ی ذخیره به نیازت. ش می که جایی تا چون ،حالت این در است مهم بسیار ها ستون ترتیبود روند می سرریز بخش به مابقی و شوند می ذخیره بخش همان در. اندکس بر مبتنی جدول ایجاد پارامترهای: 1-OVERFLOW TABLESPACE <TBS-NAME> 2-PCTTHRESHOLD <TH> 3-INCLUDING <C-NAME>
- 58. منطقی اشیا معرفی Index Organized Table تعریف از مثالیIOT:
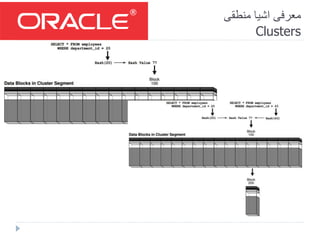
- 59. منطقی اشیا معرفی Clusters سازی ذخیره(فیزیکی)کنار صورت به جدول چند یا دو بازیابی ورا هم نامند می جداول کالستر. در داده پایگاه کارایی بهبود منظور به شی اینJOINپر سنگین های است شده ایجاد تکرار.ب که جداولی های داده داری نگه با که طوری بها همJOINکند کمک بازیابی سرعت بهبود به تواند می شوند می( .زیرا های فرآیند تعدادIOای تکنیک این با و برانگیزند چالش که هستندن یابند می کاهش فرآیندها) فرآیند در کارایی کاهش سبب تکنیک این از استفاده البتهINSERTION بود خواهد. از زمانی چهCLUSTERINGنکنیم استفاده: 1-کررات به جداول که زمانیUPDATEشوند می. 2-به نیاز که زمانیFULL-SCANاست رایج عملی جدول.
- 60. منطقی اشیا معرفی Clusters INDEX CLUSTER: دسترسی برای ایندکس از و کند می استفاده داده به همین مبنای بر شکل مطابق های داده ایندکس مقادیر هم کنار را مختلف جداول کند می بازیابی و ذخیره.
- 61. منطقی اشیا معرفی Clusters INDEX CLUSTER: ایندکس مبنای بر کالستر تعریف ی نحوه: اول گام:کالستر تعریف دوم گام:ایندکس تعریف سوم گام:جداول کردن اضافه
- 62. منطقی اشیا معرفی Clusters HASH CLUSTER: مفهوم همان روش اینINDEX CLUSTERاین با کند می دنبال را تابع از که تفاوتHASHجای بهINDEXکند می استفاده. تابع های خروجی تعداد اگرHASHکلی متمایز عناصر تعداد با متناسبد فرآیند یک با باشد کالسترIOدسترسی نظر مورد های داده به توان می تابع خروجی هم سازی ذخیره هنگام در زیرا کرد؛ پیداHASHمشخص خرو توان می هم بازیابی هنگام در پس ،بوده سازی ذخیره محل کنندهجی داد قرار استفاده مورد مستقیم صورت به را آن. تعریف نحوه:مث دقیقا سوم گام ،شود می حذف قبل روش در دوم گامل رو به رو شکل به اول گام و قبل روش:
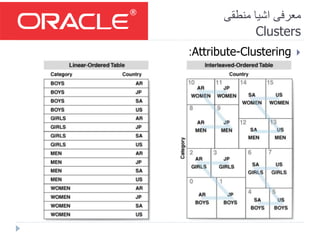
- 64. منطقی اشیا معرفی Clusters Attribute-Clustering: جدول یکheapش می تعیین کاربر توسط آن سازی ذخیره قاعده که استود! چند یا یک درون محتوای روی واقع در قواعد این(حداکثر10)هستند ستون کنند می عمل ،بگیرند قرار مختلفی جداول در توانند می که. سازی ذخیره قواعد: Linear Order Interleaved Order انواعAttribute-Clustering: عادی:فیزیک ی حافظه در جدول همان ستون چند یا یک مبنای بر جدول یک عناصری حاف در ،باشد نزدیک هم به ها ستون این مقادیر جا هر که نحوی به شوند می ذخیرهظه باشد نزدیک به ها آن مکان هم فیزیکی. Join:در دیگر جدوال ستون چند یا یک مبنای بر جدول یک عناصر حالت این در که نحوی به ،شوند می ذخیره فیزیکی ی حافظه...
- 69. منطقی اشیا معرفی Views موجو ویوهای یا جداول اساس بر که است منطقی جدول یک دید یا ویود باشد می. می تغذیه جداول از بلکه کند نمی ذخیره خود درون ای داده هیچ ویو شود. ویو مزایای: کند می مخفی را اصلی های داده های پیچیدگی. آورد می فراهم کاربران مستقیم دسترسی از جلوگیری با را جداول امنیت. کند می مستقل پایه جداول در تغییرات از را کاربردی های برنامه.
- 70. منطقی اشیا معرفی Views ویو ایجاد:
- 71. منطقی اشیا معرفی Views دستوراتDMLبرViewها: Check Option! ایجاد امکانViewمحدودیت باRead-Only(With Read Only Constraint) جداول از توان می ویوها مورد در اطالعات کسب و مدیریت منظور به کرد استفاده زیر:DBA_VIEWS, ALL_VIEWS, USER_VIEWS
- 72. تشکر با-اول بخش اتمام
Editor's Notes
- #3: نکات: ---- تفاوت بین کاربر و شمای کاربر! لینک زیر توضیحات کامل را داده است: http://radiofreetooting.blogspot.com/2007/02/user-schema.html رابطه کاربر و اسکیما : 1 به 1 --- به طور کلی اشیایی از جنس Table، View، Sequence، Private Synonym، Procedure، Function، Materialized View و User-Defined Data Type ها باید در یک schema نام متفاوتی داشته باشند اما نسبت به سایر اشیا مانند Index، Constraint، Cluster، Trigger، Dimension و ... می توانند نام یکسانی حتی در یک Schema داشته باشند!
- #4: نکات: ---- V در فرمت های کاراکتر نقش اندازه متناسب با ورودی را دارد (البته حداکثر اندازه را به صورت فیکس می گیرد ولی برخلاف موارد بدون V، به اندازه ورودی فضا اشغال می کند) N در فرمت های کاراکتری به معنی استفاده از Unicode برای تفسیر داده و ذخیره سازی آن است. سایر انواع داده ای: ROWID, LONG سایر نوع داده های عددی: Binary_Float, Binary_Double سایر نوع داده های زمان: Timestamp with time zone, Timestamp with local time zone (تفاوت آن ها مربوط به ذخیره سازی زمان گرینویچ با اختلاف زمان، یا ذخیره سازی زمان محلی است) سایر داده های LOB: NLOB همان CLOB است اما با national Language character LONG نوع داده ای قدیمی و با عملکرد ضعیف است و اوراکل صرفا جهت پشتیبانی از ورژن های قبلی این نوع داده را deprecate نکرده است (پیشنهاد می شود به جای این نوع داده از LOB استفاده شود!) جهت مطالعه دلایل به بخش جواب در لینک روبه رو: http://stackoverflow.com/questions/12722636/what-is-the-difference-between-long-and-long-raw-data-types-in-oracle مراجعه شود.
- #5: نکات: ---- دسته بندی های مختلف جداول دسته بندی جداول Relational به سه مورد از نظر نحوه ذخیره سازی است. دسته بندی جداول موقت بیانگر زمانی است که اطلاعات درون جدول حذف خواهند شد. Heap Organized: جداول به صورت معمولی از این دسته هستند و در این نوع جداول داده ها بر مبنای وجود فضای خالی مناسب روی دیسک ذخیره می شوند، بنابراین در فرآیند Insertion بسیار مناسب هستند، حال آن که ممکن است در فرآیندهای مربوط به Retrieval در صورتی که از روش های بهبود دسترسی استفاده نشود، عملکرد ضعیفی داشته باشند. Index Organized Table: این نوع tableها در ذخیره سازی داده و retrieval ساختار درختیِ اندکس های B*Tree را رعایت کرده اند. (توضیحات بیشتر در بخش اندکسها) External Table: در این table ها دادهی مربوط در پایگاه داده اوراکل نیست و ممکن است حتی در قالب یک فایل مجزا باشد. (توضیحات در بخش مربوطه)
- #6: نکات: ---- Invisible Column: این ستون ها به تا به صورت صریح در کوئری نام برده نشوند در خروجی ظاهر نخواهند شد! به عنوان مثال select * …. این نوع ستون ها را بر نمی گرداند و اگر بخواهیم آنها را در خروجی مشاهده کنیم باید کوئری را این گونه بنویسیم: select *, <I.C.Name> ….! ROWID یک ستون نامرئی خاص است که اوراکل همواره در هر جدولی آن را ایجاد می کند. نوع این ستون ROWID است و اوراکل با استفاده از آن می تواند مکان یابی محل ذخیره رکورد را انجام دهد. اوراکل از این ROWID ها برای ساخت اندکس و دسترسی سریع به مقادیر یک رکورد در دیسک استفاده می کند. به طور کلی ROWID ها به سه دسته: 1- فیزیکی 2- منطقی (برای Index Organized Tableها) 3- خارجی (برای رکورد های خارج پایگاه داده اوراکل) تقسیم می شود و هر سه بخشی از مفهوم کلیِ ROWID یا Universal ROWID هستند. کاربردهای ROWID: ایجاد اندکس، سریع ترین روش دسترسی به سطر، معرف نحوه ساختار ذخیره سازی جدول ---- ستون های مجازی ، ستون هایی هستند که مقدار درون آنها از روی سایر ستون ها با استفاده از اعمال روابطی مشخص به دست می آید. به عنوان مثال ستونِ مالیات که با درصدی از درآمد به دست می آید.
- #7: نکات: ---- دستورات >> سه روش رایج برای تعریف یک جدول! روش دوم داده و ساختار با هم تعریف می شوند!
- #8: نکات: ---- برای سایر جزئیات مراجعه شود به : https://docs.oracle.com/cd/E17952_01/refman-5.1-en/create-table.html
- #9: نکات: ---- مطالب مهم درون مثال: ستون ssn، به صورت کد گذاری ذخیره شده است. مقدار پیش فرض برای ستون hiredate تعریف ستون virtual، hrly_rate تعریف ستون نامرئی status محل تعریف table، table space مربوط به آن و مقدار اولیه برای ذخیره سازی + کامنت در مورد جدول
- #10: نکات: --- تنها در صورتی می توان طول یک ستون را کاهش داد که یا جدول خالی باشد، یا تمامی مقادیر آن ستون NULL باشند. در غیر این صورت نمی توان فرآیند کاهش طول ستون را انجام داد ولی می توان آن را افزایش داد. با تغییر مقدار پیش فرض برای یک ستون، رکورد های قبلی که برای این ستون مقدار پیش فرض گرفته تغییر نخواهند کرد. در استفاده از دستور Truncate حتما باید توجه داشت با توجه به اینکه با جاجرای این دستور هیچ گونه داده برگشتی تولید نمی شود پس داده ها به هیچ روشی (به جز داده های بک آپ) امکان بازیابی نخواهند داشت. به همین منظور استفاده از دستور delete به جای دستور truncate توصیه می شود.
- #11: نکات: ---- برخی دستورات صرفا در حالت Read Write امکان انجام دارند ولی برخی دیگر در هر دو حالت Read Only و Read Write قابلیت اجرا دارند. در شکل مربوطه، لیست مربوط به این دستورات را در این صفحه مشاهده میکنید.
- #12: نکات: ---- PURGE این امکان را فراهم می کند تا حافظه اختصاصی به جدول به صورت آنی به پایگاه داده بازگردد. در صورتی که این پارامتر نباشد، حذف جدول از نظر اوراکل به تغییر نام جدول و انتقال آن به Recycle Bin خلاصه می شود، این امکان سبب می شود تا اوراکل بتواند Flash Recovery انجام بدهد اما در صورتی که از پارامتر Purge استفاده شود دیگر این امکان فراهم نیست. تغییر نام جدول سبب می شود تا View ها، Stored Procedure هایی که روی این جدول کار می کردند در وضعیت Invalid قرار گیرند و باید دوباره Rebuild شوند، اما Indexها و Constraintهای مربوطه به صورت اتوماتیک توسط اوراکل Rebuild می شوند.
- #13: نکات: ---- (بحث فشرده سازی نیازمند مطالعه بیشتر است!) + در صورت یافتن رفرنس مناسب ضمیمه می شود!
- #14: نکات: ---- با توجه به آپشن ON COMMIT می توان مشخص کرد که جدول مربوطه از نوع Session-Specific است یا Transaction-Specific در حالت session-specific تا زمانی که session برقرار است داده های موجود در جدول موقتی حذف نمی شوند اما در حالت transaction-specific به محض commit شدن داده ها از جدول موقت پاک می شوند. محدودیت های استفاده از جدوال موقت: 1- جدول موقت نمی تواند Index organized باشد، یا partition بندی و یا cluster شود. 2- جدول موقت نمی تواند foreign key داشته باشد. 3- برای این جداول نمی توان مشخص کرد که در کدام table space قرار بگیرند زیرا به صورت عادی درون table space مربوط به temp قرار می گیرند. 4- امکان export یا recovery برای این جداول وجود ندارد. 5- در این جداول نمی توان از Varray و با Nested Table استفاده کرد.
- #15: نکات: ---- همانطور که مشاهده می شود دو فایل با ساختار یکسان وجود دارند در صفحه بعد با ایجاد جدولِ خارجی این دو فایل را به آن لینک می کنیم.
- #16: نکات: ---- به منظور کسب اطلاعات بیشتر مراجعه شود به سند Oracle DB 12c Administration Guide مراجعه شود. (صفحه 759( حذف یک جدول خارجی سبب می شود تا فرداده ذخیره شده در دیتا دیکشنری حذف شود و روی فایل خارجی مربوطه فعالیتی را انجام نمی دهد.
- #17: نکات: ---- برای مشاهده لیست کامل این جداول مراجعه شود به سند Oracle DB 12c Administration Guide صفحه ی 764 --- جدول Dual یک جدول با یک سطر و یک ستون است، که در آن مقدار X قرار دارد. اوراکل این جدول را برای استفاده جهت تست function ها، stored procedure ها و عملیات گذاشته است. به طوری که دستور select روی این جدول اعمال می شود ولی هیچ خواندنی و عملیاتی روی این جدول سبک انجام نخواهد شد.
- #18: نکات: ----
- #19: نکات: ----
- #20: نکات: ---- (تست میدانی در 8 حالت گرفته شود!!) 4 حالت ممکن: ENABLE-VALIDATE: (حالت پیش فرض) اطلاعات قبلی از نظر قید بررسی می شوند. اطلاعات جدید نیز با توجه به ENABLE بودن قید چک خواهند شد. ENABLE-NOVALIDATE: اطلاعات جدید با توجه به فعال بودن قید چک خواهند شد اما اطلاعات قدیمی نیازی به VALIDATE کردن ندارد. DISABLE-VALIDATE: در این حالت برای داده های جدید با توجه به غیر فعال بودن قید چکی انجام نمی شود اما داده های قبلی از نظر برقرار بودن قید بررسی می شوند. DISABLE-NOVALIDATE: در این حالت نه داده های قدیمی نه داده های جدید هیچکدام مورد بررسی قید قرار نمی گیرند. --- تعویق: حالت INITIALLY IMMEDIATE به ازای هر دستور قیود چک می شود، اما INITIALLY DEFFERED تا زمان کامیت شدن تراکنش صبر می کند و سپس همه را با هم بررسی می کند (مثال قید کلید خارجی که شی مربوط به جدول اصلی دیرتر از خود کلید خارجی ایجاد می شود) --- برای بدست آوردن اطلاعات در مورد قیود مختلف می توان از ویو های DBA_CONSTRAINTS و DBA_CONS_COLUMNS استفاده کرد. این امکان وجود دارد که یک SESSION درخواست بررسی قیود را به صورت تعویقی داشته باشد. در این صورت حتی اگر روش آنی در تعریف قید باشد، اوراکل به صورت تعویقی این کار را انجام می دهد. ALTER SESSION SET CONSTRAINT = DEFFERED;
- #21: نکات: ---- پارتیشن در دو سطح ایندکس و جدول قابل انجام است. منظور از پارتیشن کردن، تقسیم بندی و ذخیره سازی داده های یک شی (جدول یا ایندکس) بر اساس یک Policy در قسمت های مختلف است. (حتی در سطح TBSهای مختلف) با استفاده از این تکنیک کارایی در پرسش و پاسخ برای جداول بسیار بزرگ VLDB بسیار بهتر می شود. همچنین می توان مدیریتی بهتری روی جداول داشت چون اطلاعات درون آن ها شکسته شده است و هرکدام از این اجزا قابل مدیریت هستند. یکی از شرایط کلید پارتیشن بندی این است که معمولا در قسمت WHERE کوئری ها ظاهر می شود! یا خود کوئری مشخص می کند که روی کدام پارتیشن کار می کند! کتاب مدیریت پایگاه داده اوراکل 11، مقدار 2 گیگا بایت را به عنوان ترشهولدی مناسب برای پارتیشن بندی در نظر گرفته است. همچنین جداولی که مشخصا برخی به صورت اطلاعات بایگانی و برخی اطلاعات به صورت current در حال استفاده هستند پتانسیل بالایی برای استفاده از این تکنیک را دارند.
- #22: نکات: ---- روش های مختلف در اسلاید های بعدی توضیح داده شده اند. در پارتیشن بندی دو سطحی منظور از R – Range, I- Index, L- List, H-Hash می باشد.
- #23: نکات: ---- منظور از به شکل منطقی این است که محدوده های تعریف شده، اولا از نظر حجم اطلاعاتی (همین موضوع سبب می شود تا در ذخیره سازی روند پارتیشن بندی منطقی باشد و هم در پرسش و پاسخ داده های مورد بررسی به شدت کاهش یابند) و در ثانی از نظر پرسش و پاسخ روی بخش های مختلف به شکلی منطقی و قابل دفاع تعیین شده باشند. همانطور که در مثال مشاهده می شود می توان بخش های مختلف را در TBS های مختلف ذخیره کرد!!
- #24: نکات: ----
- #25: نکات: ---- تعداد پارتیشن ها در این حالت باید توانی از 2 باشد (2، 4، 8، 16، ...) امکان تعریف محل ذخیره سازی هر پارتیشن نیز با استفاده از دستور STORE In فراهم می آید. که به ترتیب مشخص می کند پارتیشن اول تا پارتیشن n در کدام TBS ذخیره شوند.
- #26: نکات: ---- نام پارتیشن های جدید به صورت دیفالت از SYS_Pn تبعیت می کند که n یک شمارشگر افزایشی است!! امکان تغییر اینتروال پس از تعریف وجود دارد! alter table pos_data set INTERVAL(NUMTOYMINTERVAL(3, 'MONTH')); امکان لغو بخش اینتروال پارتیشن بندی پس از تعریف وجود دارد! alter table pos_data_range set INTERVAL(); امکان تعریف اینتروال روی یک پارتیشن بندی Range بعد از تعریف با دستور رو به رو وجود دارد: alter table pos_data_range set INTERVAL(NUMTOYMINTERVAL(1, 'MONTH'));
- #27: نکات: ----
- #28: نکات: ----
- #29: نکات: ---- http://www.morganslibrary.org/reference/partitions.html تمامی حالت های پارتیشن با مثال در این صفحه موجودند!!!
- #30: نکات: ---- در این اسلاید مثال مربوط به Business case جالبه
- #31: نکات: ---- در این اسلاید مثال مربوط به Business case جالبه
- #32: نکات: ----
- #33: نکات: ----
- #34: نکات: ---- در حالت دو سطحی دستور ADD PARTITION به ADD SUBPARTITION تغییر پیدا می کند. فرم کلی دستور به شکل ALTER TABLE MODIFY PARTITION <P-NAME> ADD SUBPARTITION <SP-NAME> …. خواهد بود!
- #35: نکات: ---- برای این دستور نیازی به آپدیت کردن اندکس های محلی وجود ندارد ولی برای آپدیت کردن اندکس های گلوبال باید از بخش اختیاری دستور (UPDATE GLOBAL INDEXES) استفاده شود.
- #36: نکات: ----
- #37: نکات: ---- ایندکس ها با توجه به نیاز به نگه داری و به روز رسانی اتوماتیک با دستورات DML از کارایی این دستورات در پایگاه داده میکاهند.
- #38: نکات: ---- Index Clustering Factor یک معیار عددی است که بیانگر شباهت ساختار ایندکس با ذخیره سازی داده اصلی (جدول) در دیسک است و بر همین اساس اوراکل یک تعداد IO به صورت تقریبی دارد و همین اساس می تواند قبل از انجام کوئری تصمیم بگیرد که به سراغ ایندکس برود یا نه! لازم به ذکر است که اندکس ها سبب مرتب سازی داده در هنگام ذخیره سازی نمی شوند! (خود به صورت ساختاری مجزا ذخیره می شوند) مسئولیت تصمیم گیری برای استفاده از ایندکس با بخشی است به نام CBO- Cost-Based Optimizer!
- #39: نکات: ---- به طور کلی تا کوئری هایی که میخام روی جدول بزنیم مشخص نشوند نمی توان اندکس منطقی ای ایجاد کرد. فاکتور هایی مانند سرعت تغییرات جدول و اندازه آن نیز در تصمیم گیری برای این کار بسیار تاثیر گذار است.
- #40: نکات: ---- به طور کلی تا کوئری هایی که میخام روی جدول بزنیم مشخص نشوند نمی توان اندکس منطقی ای ایجاد کرد. فاکتور هایی مانند سرعت تغییرات جدول و اندازه آن نیز در تصمیم گیری برای این کار بسیار تاثیر گذار است. به صورت پیش فرض ایندکسهای ایجاد شده در وضعیت Usable , Visible قرار می گیرند. اما با تغییر وضعیت آن ها به حالت Unusable دیگر نه به صورت اتوماتیک بعد از دستورات DML، نگه داری و به روز می شوند و نه در هنگام پرسش به عنوان گزینه ای (روی میز ) مورد استفاده قرار می گیرند. در حالت Invisible با اعمال دستورات DML به روز می شوند اما در هنگام پرسش مورد استفاده قرار نمی گیرند.
- #41: نکات: ---- منظور از عدم ذخیره مقادیر NULL ایندکس این است که در این درخت سطرهایی که مقدار NULL دارند به عنوان برگ ظاهر نمی شوند (چون مشخص نیست کجای درخت هستند!) پس زمانی که کوئری ما در قسمت where با شرط <c-name> = null رو به رو می شود اوراکل ناگزیر به استفاده از full scan می باشد. در زمان ایجاد یک composite index یعنی ایندکسی که روی چندین ستون اعمال می شود، حتما به ترتیب وارد شدن ستون ها توجه شود و هر کدام که بیشتر به شرایط گفته شده می خورند در مکان بهتری قرار بگیرند
- #42: نکات: ---- به طور کلی تا کوئری هایی که میخام روی جدول بزنیم مشخص نشوند نمی توان اندکس منطقی ای ایجاد کرد. فاکتور هایی مانند سرعت تغییرات جدول و اندازه آن نیز در تصمیم گیری برای این کار بسیار تاثیر گذار است. به صورت پیش فرض ایندکسهای ایجاد شده در وضعیت Usable , Visible قرار می گیرند. اما با تغییر وضعیت آن ها به حالت Unusable دیگر نه به صورت اتوماتیک بعد از دستورات DML، نگه داری و به روز می شوند و نه در هنگام پرسش به عنوان گزینه ای (روی میز ) مورد استفاده قرار می گیرند. در حالت Invisible با اعمال دستورات DML به روز می شوند اما در هنگام پرسش مورد استفاده قرار نمی گیرند. اگر ستونی که روی آن ایندکس می زنیم Unique است حتما باید ذکر شود چون زمانی که CBO می خواهد در مورد استفاده یا عدم استفاده از ایندکس تصمیم بگیرد ممکن است به علت عدم معرفی صحیح ایندکس از این کار صرف نظر کند. Reverse زمانی مناسب است که insertهای همزمان روی جدول وجود دارد و میخواهیم کارایی این insertionها را تا حد امکان بهبود ببخشیم (البته زمانی این کارایی بهبود می یابد که ترتیب insert شدن داده ها برای ستون مورد نظر روند خاصی داشته باشد (مثلا افزایشی یا کاهشی) باشد در این صورت بدون استفاده از reverse برخی کاربران نیازمند منتظر بودن برای اتمام کار مابقی هستند و از آنجا که اوراکل به صورت دیفالت روی حافظه اصلی کار می کند و با یک ترند 3 ثانیه ای در دیسک می نویسد.... اما با استفاده از reverse کاربران مختلف می توانند بخش های مختلف درخت را آپدیت کنند و داده کسی و توسط فرد دیگر lock نشده است. نحوه استفاده به شکل زیر است: … ON <T-Name> (C1[,C2,…]) REVERSE [TABLESPACE <TBS-Name>]; در ایندکس های فشرده مفهوم اصلی فشرده سازی یعنی قرار دادن یک بار داده های duplicate مطرح می شود. نحوه استفاده از آن به شکل زیر است: … ON <T-Name> (C1[,C2,…]) [TABLESPACE <TBS-Name>] COMPRESS <level-number> در اینجا سطح 1 برگ ها هستند. (مطالب مربوط به compression ناقص هستند) ایندکس مبتنی بر تابع: در هنگام ایجاد یک تابع روی ورودی اعمال می شود و درخت بر همان اساس ساخته می شود و اگر شرط این تابع اعمال شده باشد اوراکل از این ایندکس استفاده می کند … ON <T-Name> (F(C1[,C2,…]) در ایندکس مرتب شده هم صعودی و نزولی بودن را مشخص می کنیم... می توان یک ایندکس ترکیبی تعریف کرد که برخی ستون ها صعودی و برخی دیگر نزولی باشند.! لازم به ذکر است همه ترکیبات امکان پذیر نیستند و نمی توان یک ایندکس یکتای فشرده ایجاد کرد
- #43: نکات: ---- ساختار مربوط به ایندکس B*Tree
- #44: نکات: ----
- #45: نکات: ----
- #46: نکات: ----
- #47: نکات: ---- مثال بیانگر این است که اندکسی بر مبنای نوع شغل (که در جدول JOB مشخص شده است) به شکل Bitmapروی جدول EMPLOYEE که فاقد ستون نوع شغل است ایجاد می شود. لازمه اصلی ارتباط دو جدول است که از طریق ستون FK بر قرار شده است. نکات اضافی: Bitmap نیز علاوه بر حالت معمولی می توان به صورت function-based مورد استفاده قرار گیرد.
- #48: نکات: ---- Conventional wisdom holds that bitmap indexes are most appropriate for columns having low distinct values--such as GENDER, MARITAL_STATUS, and RELATION. This assumption is not completely accurate, however. In reality, a bitmap index is always advisable for systems in which data is not frequently updated by many concurrent systems! Conventional wisdom holds that bitmap indexes are most appropriate for columns having low distinct values--such as GENDER, MARITAL_STATUS, and RELATION. This assumption is not completely accurate, however. In reality, a bitmap index is always advisable for systems in which data is not frequently updated by many concurrent systems (http://www.oracle.com/technetwork/articles/sharma-indexes-093638.html) In summary, bitmap indexes are best suited for DSS regardless of cardinality for these reasons: With bitmap indexes, the optimizer can efficiently answer queries that include AND, OR, or XOR. (Oracle supports dynamic B-tree-to-bitmap conversion, but it can be inefficient.) With bitmaps, the optimizer can answer queries when searching or counting for nulls. Null values are also indexed in bitmap indexes (unlike B-tree indexes). Most important, bitmap indexes in DSS systems support ad hoc queries, whereas B-tree indexes do not. More specifically, if you have a table with 50 columns and users frequently query on 10 of them either the combination of all 10 columns or sometimes a single column creating a B-tree index will be very difficult. If you create 10 bitmap indexes on all these columns, all the queries can be answered by these indexes, whether they are queries on all 10 columns, on 4 or 6 columns out of the 10, or on a single column. The AND_EQUAL hint provides this functionality for B-tree indexes, but no more than five indexes can be used by a query. This limit is not imposed with bitmap indexes. In summary, bitmap indexes are best suited for DSS regardless of cardinality for these reasons: With bitmap indexes, the optimizer can efficiently answer queries that include AND, OR, or XOR. (Oracle supports dynamic B-tree-to-bitmap conversion, but it can be inefficient.) With bitmaps, the optimizer can answer queries when searching or counting for nulls. Null values are also indexed in bitmap indexes (unlike B-tree indexes). Most important, bitmap indexes in DSS systems support ad hoc queries, whereas B-tree indexes do not. More specifically, if you have a table with 50 columns and users frequently query on 10 of themeither the combination of all 10 columns or sometimes a single columncreating a B-tree index will be very difficult. If you create 10 bitmap indexes on all these columns, all the queries can be answered by these indexes, whether they are queries on all 10 columns, on 4 or 6 columns out of the 10, or on a single column. The AND_EQUAL hint provides this functionality for B-tree indexes, but no more than five indexes can be used by a query. This limit is not imposed with bitmap indexes.
- #49: نکات: ---- شکل دسته بندی کلی ایندکس ها را نشان می دهد.
- #50: نکات: ----
- #51: نکات: ----
- #52: نکات: ----
- #53: نکات: ----
- #54: نکات: ---- به طور کلی prefixed همواره به حذف پارتیشن منتج می شود! (البته باید در قسمت where روی کلید پارتیشن شرط باشد!) اما ایندکس به سایر ستون های غیر از کلید پارتیشن بندی کمک چندانی نمی کند. Non prefixed ها برای زمانی است که علاوه بر کلید پارتیشن بندی سایر ستون ها هم در کوئری ها به صورت مجزا هستند، اما ممکن است چون در گام اول به حذف پارتیشن منتج نمی شود به خطا بخورد در حالی که امکان پاسخگویی به جواب را دارد!! توجه شود که پارتیشن بندی اندکس و خود ساختار اندکس درون هر بخش متفاوتند و مطلب گفته شده با مفهوم local بودن تناقضی ندارد!! https://asktom.oracle.com/pls/apex/f?p=100:11:::NO:RP:P11_QUESTION_ID:6144022300346417212
- #55: نکات: ----
- #56: نکات: ---- این امکان سبب می شود تا داده هایی که به شدت به روز می شوند و بار اضافی ایندکس در آن ها نه تنها کمکی به بازیابی نمی کند بلکه سبب ایجاد مشکل در کارایی کلیت سیستم می شود توسط مدیر پایگاه داده غیر فعال شود. علاوه بر این سرویس CBO که تصمیم گیرنده استفاده و عدم استفاده از ایندکس است در سطح پارتیشن این کار را می کند (که سبب می شود در برخی موارد که امکان استفاده از ایندکس سبب افزایش سرعت می شود از ایندکس استفاده شود و در غیر این صورت نه! لینک زیر تست کیس فوق العاده ای را فراهم آورده است: https://richardfoote.wordpress.com/2013/07/08/12c-partial-indexes-for-partitioned-tables-part-i-ignoreland/ https://richardfoote.wordpress.com/2013/07/12/12c-partial-indexes-for-partitioned-tables-part-ii-vanishing-act/ **) تصاویر به سمت چپ و راست جدا هستند!!! (صرفا جهت اطلاع این ها از دو سورس مختلف آمده اند و ربطی به هم ندارند. تصویر سمت چپ کلیت Partial Partition Index را معرفی می کند و تصویر سمت راست نحوه ایجاد آن توضیح می دهد!) (نیاز به مطالعه بیشتر!!)
- #57: نکات: ---- اگر شرایط و محدودیت ها مشکلی ایجاد نکند استفاده از این روش سرعت بازیابی را به شدت افزایش می دهد.
- #58: نکات: ---- *) پارامتر اول مشخص کننده tbs ذخیره سازی سگمت سرریز است. *) پارامتر دوم درصدی از یک بلاک را مشخص می کند که در صورتی که یک سطر اندازه ش از آن بیشتر شد مابقی اطلاعات را به بخش سرریز ببرد. *) پارامتر سوم تعیین کننده ستون هایی است که نمیخواهیم مقادیر آن ها به بخش سرریز بروند.
- #59: نکات: ---- *) با بیان ORGANIZATION INDEX کار تمام است و جدول به صورت IOT ایجاد می شود. سایر پارامتر ها اختیاری هستند و در صورتی که مشخص نشوند بخش overflow در نظر گرفته نمی شود و تمام داده ها در همان بخش اصلی ذخیره می شوند.
- #60: نکات: ---- مبنای کلاستر شدن هم کلید خارجی است. به آن کلید کلاستر می گویند. کلید کلاستر به ازای هر چند جدول هم باشد فقط یک بار ذخیره می شود. *) حذف کلاستر DROP Cluster در صورتی که شامل جدولی باشد که حذف نشده باشد با پیغام خطا رو به رو می شود. اما اگر آپشن INCLUDING TABLES را به دستور مربوطه اضافه کنیم کلاستر و جداولش با هم حذف می شوند.
- #61: نکات: ----
- #62: نکات: ---- در هنگام بازیابی داده ها به این روش نیاز به حداقل دو فرآیند IO است. یکی برای ایندکس و یکی هم برای رسیدن به اطلاعات در بلاک مورد نظر.
- #63: نکات: ---- در مثال بالا برای ایجاد یک کلاستر به روش HASH، 100 بیانگر حداکثر تعداد خروجی های مجاز تابع HASH است. (مقدار پارامتر HASHKEYS)
- #64: نکات: ---- تصویر سمت چپ حالت عادی استفاده از این روش را نشان می دهد که هم اندازه بلوک برای ذخیره سازی داده کافی بوده است و هم اینکه تعداد خروجی تعریف شده برای تابع HASH متناسب با مقادیر متمایز کلید کلاسترینگ بوده !!! تصویر سمت راست هر دو مورد نقض شده اند( دو ورودی 43و 77 یک خروجی HASH دارند چون تعداد UNDERESTIMATE شده بوده و علاوه براین با پر شدن بلاک مربوطه تعداد فرآیندهای IO به دو مورد افزایش یافته است.) اگر مقادیر مربوط به HASHKEY و اندازه بلاک درست تعیین نشود تعداد فرآیند های IO ممکن است از دو هم بیشتر بشود!!
- #65: نکات: ---- در روش Linear Order: ترتیب ستون ها بسیار مهم است! و اگر ستون اول در بخش where کوئری نباشد این نوع کلاسترینگ به هیچ دردی نمی خورد زیرا اول بر مبنای ستون اول بعد درون آن بر مبنای ستون دوم و ... (Linear!) در روش Interleaved Order: از تکنیکی استفاده می شود که عناصر چند بعدی را با حفظ محلیت به عناصر یک بعدی تبدیل می کند تکنیک استفاده شده در اوراکل بر مبنای Z-Ordering Curve می باشد. یعنی مستقل از تعداد ورودی و ترتیب آن ها سعی می کند نزدیک های هر کدام در کل به هم نزدیک باشند و بعد از N به 1 تقلیل پیدا کند.
- #66: نکات: ---- برای کسب اطلاعات بیشتر به جای کتاب Concept به سند Data Warehousing اوراکل مراجعه شود! لینک های زیر هم کمک شایانی می توانند بکنند! https://richardfoote.wordpress.com/2014/08/26/12-1-0-2-introduction-to-attribute-clustering-the-division-bell/ ---- https://richardfoote.wordpress.com/2014/09/03/12-1-0-2-introduction-to-zone-maps-part-i-map-of-the-problematique/ https://richardfoote.wordpress.com/2014/10/30/12-1-0-2-introduction-to-zone-maps-part-ii-changes/ https://richardfoote.wordpress.com/2014/11/24/12-1-0-2-introduction-to-zone-maps-part-iii-little-by-little/
- #67: نکات: ---- در این اسلاید به سوال پرسش داده شده است که چه زمان می توان از Attribute Clustering استفاده شود و چگونه از Attribute Clustering استفاده شود؟!!!! کلا GuideLine ها رو گفته! این بخش از کتاب DataWarehousing اوراکل آورده شده است.
- #68: نکات: ---- نحوه ایجاد با دو استراتژی Linear و Interleaved! (در حالت اول)
- #69: نکات: ---- نحوه ایجاد با دو استراتژی Linear و Interleaved! (در حالت دوم Join Attribute Cluster) در حالت دوم به پرانتز ها توجه شود! مناسب برای کوئری هایی است که بر اساس Time_id Prod_Category Prod_Category, Prod_SubCategory Time_id, Prod_Category Time_id, Prod_Category, Prod_SubCategory اما اگه Prod_SubCategory تنها باشه خوب نیست دلیلش همون پرانتزه س!
- #70: نکات: ----
- #71: نکات: ---- بررسی شماتیک نحوه ایجاد ویو و ارتباط بین ویو و جدول اصلی
- #72: نکات: ---- اعمال دستورات DML بر ویو ها ممکن است شرایطی را که View با آن ساخته شده است را تحت تاثیر قرار دارند به همین خاطر همانطور که شکل مشاهده می شود با استفاده از Check Option این موضوع بررسی خواهد شد!!!!