







































































Java one2011 brisk-and_high_order_bits_from_cassandra_and_hadoop
- 1. Brisk: Truly peer-to-peer Hadoop High-order bits from Cassandra & Hadoop srisatish ambati @srisatish
- 2. How many in audience…
- 3. NoSQL - Know your queries.
- 4. points • Usecases • Why cassandra? • Usecase: Hadoop, Brisk • FUD: Consistency – Why facebook is not using Cassandra? • Anti-patterns • Community, Code, Tools • Q&A
- 5. Users. Netflix. Key by Customer, read-heavy Key by Customer:Movie, write-heavy
- 6. TimeSeries: (several customers) periodic readings: dev0, dev1…deviceID:metric:timestamp ->value Metrics typically way larger dataset than users.
- 9. write Operational simplicity read peer-to-peer
- 11. reads local dc1 dc2 Replication: Multi-datacenter Multi-region ec2, aws Multi-availability zones
- 12. 4.21.2011, Amazon Web Services outage: “Movie marathons on Netflix awaiting AWS to come back up.” #ec2disabled
- 13. 4.21.2011, Amazon Web Services outage: Netflix was running on AWS.
- 14. fast durable writes. fast reads.
- 16. Writes Sequential, append-only. ~1-5ms On cloud: ephemeral disks rock!
- 17. Reads Local Key & row caches, (also, jna-based 0xffheap) indexes, materialized
- 18. Reads Local Key & row caches, (also, jna-based 0xffheap) indexes, materialized ssds: improved read performance!
- 19. amortize Replication over writes Repair over reads
- 20. Distribution between nodes Gossip Anti-entropy Failure-detector L ig h t w e i g h t
- 21. Clients: cql, thrift pycassa, phpcassa hector, pelops (scala, ruby, clojure)
- 22. Usecase #3: h a d o o p Hdfs cassandra hive Logs stats analytics
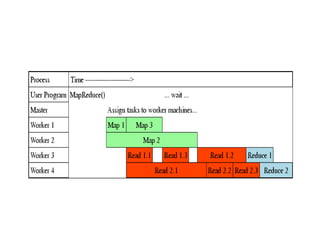
- 26. map(String key, String value): // key: document name // value: document contents for each word w in value: EmitIntermediate(w, "1"); reduce(String key, Iterator values): // key: a word // values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result)); word count in MapReduce
- 30. immutable data write-once-read-many! Files once created, written & closed.. not changing!
- 31. jobtracker, tasktracker hdfs: namenode, datanode
- 32. cloudera amazon: elastic map reduce hortonworks mapR brisk
- 33. Tools & Analytics Hive, Pig, R Karmasphere Datameer … dozens of stealth startups!
- 35. “However, given that there is only a single master, it’s failure is unlikely;” The MapReduce paper, 2004. Sanjay et,al, Google.
- 38. NameNode: Single Master node Single Machine Address space Single Point of failure
- 40. Use column families (tables) inode sblock
- 41. One kind of node no master node, no spof peer-to-peer
- 43. near-real time hadoop Low latency: cassandra_dc nodes Batch Analytics: brisk_dc nodes
- 44. BriskSimpleSnitch.java if(TrackerInitializer.isTrackerNode) { myDC = BRISK_DC; logger.info("Detected Hadoop trackers are enabled, setting my DC to " + myDC); } else { myDC = CASSANDRA_DC; logger.info("Looks like Vanilla Cassandra nodes, setting my DC to " + myDC); }
- 45. Hive: SQL-like access cli, hwi, jdbc, metastore Pushdown predicates (v beta2)
- 46. hive> CREATE TABLE invites (foo INT, bar STRING)PARTITIONED BY (ds STRING); hive> LOAD DATA LOCAL INPATH '$BRISK_HOME/resources/hive/examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008- 08-15'); hive> SELECT count(*), ds FROM invites GROUP BY ds; http://www.datastax.com/docs/0.8/brisk/about_hive
- 47. ETL Real-time Cassandra CFs DataCenters Scale @srisatish
- 48. @srisatish
- 49. No me in team! Ben Coverston Michael Allen Ben Werther Mike Bulman Brandon Williams Nate McCall Cathy Daw Nick M Bailey Jackson Chung Patricio Echague Jake Luciani Tyler Hobbs Joaquin Casares SriSatish Ambati Jonathan Ellis Yewei Zhang
- 50. 100-node Brisk Cluster on Opscenter @srisatish
- 51. FUD, acronym: fear, uncertainty, doubt.
- 52. Consistency: R + W > N ORACLE, 2-node: R=1, W=2, N=2,(T=2) DNS * N is replication factor. Not to be confused with T=total #of nodes
- 53. Tune-able, flexibility. For High Consistency: read:quorum, write:quorum For High Availability: high W, low R.
- 54. Consistency: R + W > N ORACLE, 2-node: R=1, W=2, N=2,(T=2) DNS "brisk.consistencylevel.read", "QUORUM"; "brisk.consistencylevel.write", "QUORUM"; * N is replication factor. Not to be confused with T=total #of nodes
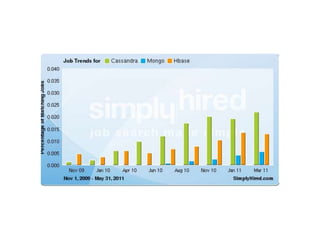
- 56. Inbox Search: 600+cores.120+TB (2008) Went from 100-500m users. Average NoSQL deployment size: ~6-12 nodes.
- 57. Usecase #5: search Apache Solr + Cassandra = Solandra Other inbox/file Searches: xobni, c3 github.com/tjake/solandra
- 58. “Eventual consistency is harder to program.” mostly immutable data. complex systems at scale.
- 59. Miscellaneous, Myth: data-loss, partial rows. writes are durable.
- 61. Anti-Patterns for cloud ebs jvm, virtualized single region
- 62. A few more good reasons for Cassandra...
- 63. Tools AMIs, OpsCenter, DataStax AppDynamics Getting Started with brisk ami Netflix just builds AMIs for deployment!
- 64. Beautiful C 0 d e = new code(); //less is more ~90k.java.concurrent.@annotate. bloomfilters, merkletrees. non-blocking, staged-event-driven. bigtable, dynamo.
- 65. Current & Future Focus: Distributed Counters, CQL. Simple client. operational smoothening. compaction.
- 66. Community Robust. Rapid. Brisk # Professional support from DataStax. git clone git@github.com:riptano/brisk.git engineers: independent,startups, large companies, Rackspace, Twitter, Netflix.. Come join the efforts!
- 67. Usecase #4: first NoSQL, then scale! simpledb Cassandra mongodb Cassandra
- 70. Copyright: xkcd
- 71. Copyright: plantoys … more than one way to do it!
- 72. Summary - high scale peer-to-peer datastore best friend for multi-region, multi-zone availability. Hadoop – HDFS engulfing the DataWorld Brisk – best of both worlds!
- 73. @srisatish Q&A
- 74. Dynamo, 2007 Bigtable, 2006 + OSS, 2008 Incubator 2009 TLP, 2010 Cassandra + + Brisk
- 75. NoSQL - Know your queries.