
























Leveraging Feature Selection Within TreeNet
- 1. Leveraging Feature Selection Within TreeNet
- 2. OverviewIntroductionThe Case For Feature SelectionMethodologiesCase Study – DMA Analytics Challenge 2007Comparison of ApproachesAdvanced AlgorithmsConclusion – Questions & Answers
- 6. Analytical FrameworkWhen more is not necessarily betterTreeNet Models are naturally more robust than more traditional algorithms.
- 7. Without any limitations a TreeNet Model in a typical DM environment can incorporate hundreds of independent variables.
- 8. How many of these variables actually provide true informational gain?Not all variables are created equalCertain types of variables can degrade TN model performance.
- 9. High order categorical (e.g. State, cluster)
- 10. Composite variables(e.g. risk score, cluster, family composition)Why Not Specialize?Lower number of variables can allow for tighter parameters
- 11. Increased number of terminal nodes
- 12. Decreased number of observations in minchild
- 13. Allowance for more variable interactions (ICL)You want me to build how many models?Brute Force = 2N-1
- 14. 60 Variables = 1,152,921,504,606,846,975 Models
- 15. Processing Time = 730,693,161,740 years
- 16. Age of the Universe ≈ 13,730,000,000 years
- 17. 1/2 will include top variable
- 18. 1/4 will include top two variables
- 19. 1/1024 will include top ten variablesFeature SelectionFeature Selection Goal – Efficiently identify the subset of independent variables that maximize model discrimination.
- 20. Basic Feature Selection = N x (N+1)/2
- 21. 60 Variables = 60 + 59 + 58 + … + 1 = 1,830 ModelsFeature Selection - FrameworkThe programmatic development and evaluation of TN batches is a necessity
- 22. Performance of initial models dictate the composition of later models.
- 23. Too many decision points to require human interaction.
- 24. SAS/C#Variable ShavingStepwise removal of variables from model based on variable importance.
- 25. Typically starts with an unrestricted model and removes variables until stop condition is met or there are no more variables to remove.
- 26. At each step variable with lowest importance is removed.
- 27. Very low cost – only requires N total models since only one model per step.Forward SelectionStepwise addition of variables to model based on performance criteria.
- 28. Typically starts with 0 variables and grows until available variables are exhausted or a stop condition is met.
- 29. Each step has the following substeps that are repeated up to N iterations:Model TestingEvaluationVariable Selection
- 30. Forward Selection – Process
- 31. Forward Selection – Process
- 32. Forward Selection – Process
- 33. Forward Selection – ProcessSample Scenario – 7 available independent variablesBackward SelectionStepwise removal of variables from model based on decision criteria.
- 34. Typically starts with an unrestricted model and restricts variables until stop condition is met or there are no more variables to remove.
- 35. Substeps are similar to forward selection:Model Testing – candidate variables are removed from models.Evaluation - identify model with highest performanceVariable Removal – remove variable from model
- 36. Backward Selection – Process
- 37. Backward Selection – Process
- 38. Backward Selection – Process
- 39. Backward Selection – Process
- 40. Case Study – Overview2007 DMA Analytics Challenge
- 42. Independent Variables: 228 variables in total
- 44. Area/household level lifestyles and interests
- 45. Geo demographics
- 47. Domain: 40k random mailpieces generating 20k respondersCase Study – OverviewModel Parameters – TN 2.0
- 48. Type: Logistic Binary – ROC stopping condition
- 49. Nodes: 6
- 50. Trees: 200
- 51. Minchild: 200
- 52. LR: 0.1
- 53. SubSample: .5
- 54. Validation Type: 50% internal test
- 55. Performance (No Variable Restrictions):
- 57. KS (Learn/Test): .392/.351Case Study – Variable ShavingDecision Metric: Importance (TN 2.0)
- 58. Resample: Changing of seed values
- 59. Peak performance attained after 72 variables.
- 60. 157 models required to identify best 72 out of 228 variables.
- 61. ROC (Learn/Test): .763/.741Case Study – Variable Shaving
- 62. Case Study – Forward SelectionDecision Metric: ROC (Test)
- 63. Resample: Rows of input file are physically shuffled after each batch.
- 64. Peak performance attained after 25 variables.
- 65. 6,400 models required to identify 25 out of 228 variables.
- 66. ROC (Learn/Test): .768/.758Case Study – Forward Selection
- 67. Case Study – Backward SelectionDecision Metric: ROC (Test)
- 68. Resample: Rows of input file are physically shuffled after each batch.
- 69. Peak performance attained after 71 variables.
- 70. 23,600 models required to identify best 71 out of 228 variables.
- 71. ROC (Learn/Test): .761/.760Case Study – Backward Selection
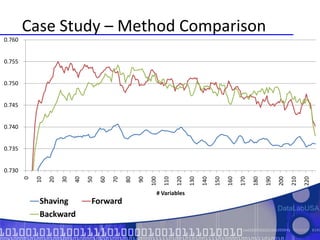
- 72. Case Study – Method Comparison
- 73. Comparison
- 74. Devising more advanced algorithmsCombination of the two procedures
- 75. Controlling for differences in parameters over variable space.
- 78. Internal re-sampling of learn vs. test
- 79. ICLConclusionsKey component of TN model optimizationPerformanceInterpretabilityBackward/Forward selection important building blocks for more sophisticated methodsQuestions?