Machine learning clustering
Download as PPTX, PDF6 likes6,902 views

This document discusses machine learning concepts including supervised vs. unsupervised learning, clustering algorithms, and specific clustering methods like k-means and k-nearest neighbors. It provides examples of how clustering can be used for applications such as market segmentation and astronomical data analysis. Key clustering algorithms covered are hierarchy methods, partitioning methods, k-means which groups data by assigning objects to the closest cluster center, and k-nearest neighbors which classifies new data based on its closest training examples.














Machine learning clustering
- 1. Mauritius JEDI Machine Learning & Big Data Clustering Algorithms Nadeem Oozeer
- 2. Machine learning: • Supervised vs Unsupervised. – Supervised learning - the presence of the outcome variable is available to guide the learning process. • there must be a training data set in which the solution is already known. – Unsupervised learning - the outcomes are unknown. • cluster the data to reveal meaningful partitions and hierarchies
- 3. Clustering: • Clustering is the task of gathering samples into groups of similar samples according to some predefined similarity or dissimilarity measure sample Cluster/group
- 4. • In this case clustering is carried out using the Euclidean distance as a measure.
- 5. Clustering: • What is clustering good for – Market segmentation - group customers into different market segments – Social network analysis - Facebook "smartlists" – Organizing computer clusters and data centers for network layout and location – Astronomical data analysis - Understanding galaxy formation
- 6. Galaxy Clustering: • Multi-wavelength data obtained for galaxy clusters – Aim: determine robust criteria for the inclusion of a galaxy into a cluster galaxy – Note: physical parameters of the galaxy cluster can be heavily influenced by wrong candidate Credit: HST
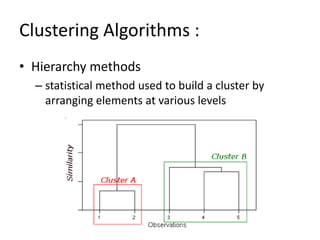
- 7. Clustering Algorithms : • Hierarchy methods – statistical method used to build a cluster by arranging elements at various levels
- 8. Dendogram: • Each level will then represent a possible cluster. • The height of the dendrogram shows the level of similarity that any two clusters are joined • The closer to the bottom they are the more similar the clusters are • Finding of groups from a dendrogram is not simple and is very often subjective
- 9. • Partitioning methods – make an initial division of the database and then use an iterative strategy to further divide it into sections – here each object belongs to exactly one cluster Credit: Legodi, 2014
- 10. K-means:
- 11. K-means algorithm: 1. Given n objects, initialize k cluster centers 2. Assign each object to its closest cluster centre 3. Update the center for each cluster 4. Repeat 2 and 3 until no change in each cluster center • Experiment: Pack of cards, dominoes • Apply the K-means algorithm to the Shapley data – Change the number of potential cluster and find how the clustering differ
- 12. K Nearest Neighbors (k-NN): • One of the simplest of all machine learning classifiers • Differs from other machine learning techniques, in that it doesn't produce a model. • It does however require a distance measure and the selection of K. • First the K nearest training data points to the new observation are investigated. • These K points determine the class of the new observation.
- 13. 1-NN • Simple idea: label a new point the same as the closest known point Label it red.
- 14. 1-NN Aspects of an Instance-Based Learner 1. A distance metric – Euclidian 2. How many nearby neighbors to look at? – One 3. A weighting function (optional) – Unused 4. How to fit with the local points? – Just predict the same output as the nearest neighbor.
- 15. k-NN • Generalizes 1-NN to smooth away noise in the labels • A new point is now assigned the most frequent label of its k nearest neighbors Label it red, when k = 3 Label it blue, when k = 7
Editor's Notes
- #7: In order to make use of all the multi-wavelength data obtained for galaxy clusters we need to determine robust criteria for the inclusion of a galaxy into a galaxy cluster. The physical parameters can be heavily influenced by the inclusion of galaxies which do not belong and this may lead to false conclusions. Clustering algorithms can be divided into two main groups – hierarchy methods and partitioning methods.
- #9: Dendogram: .... We choose a set level of similarity of about 50% of the height and then all lines which cross this level indicate a cluster. This method is combined into the partitioning methods to get starting points for the mixture modeling algorithms.
- #11: It is a clustering algorithm that tries to partition a set of points into K sets (clusters) such that the points in each cluster tend to near each other. It is unsupervised because the points have no external classification.