No sql 이해 및 활용 공개용
Download as PPTX, PDF0 likes994 views

NoSQL이 탄생하기 전까지 배경과 RDBMS와 NOSQL 차이점도 기술 되어 있습니다. 많이 NOSQL 중에 CASSANDRA에 대해서 집중적으로 다룹니다.









































No sql 이해 및 활용 공개용
- 1. NoSQL 이해 및 활용 전영규
- 2. HISTORY
- 5. 1980 1990 2000 2010 Relational Database Object Database 20년 동안 Relational Database 지배
- 6. 많은 트래픽
- 7. 높은 비용, 성능 한계 이런 방법은 한계가 있다
- 8. Sharding id 1-2 id 3-4 id 5-6 APPLICATION id 7-8 id 9-0 slave Slave slave Slave. . . Master Master
- 10. RDBMS VS NoSQL RDBMS relational table row column schema join transaction stored Procedure trigger index focus on consistency centralized NoSQL non-relational open-source cluster schema less decentralized distributed systems no transaction no join focus on availability simpler and faster VERSUS
- 11. Relational DBMS ACID Atomicity 부분적으로 실행되다가 중단되지 않음 예) 은행 계좌 예제 에서 송금시 금액 감소, 금액 증가 동시에 성공 해야 Consistency 트랜잭션이 성공적으로 완료 하면 언제나 일관성 있는 데이터 유지 Isolation 특정 트랜잭션 수행 시 다른 트랜잭션의 연산 작업을 볼 수도 끼어 들수도 없음 Durability 성공적으로 수행된 트랜잭션은 영원히 반영 되어야 함.
- 12. NoSQL BASE Basic availability 클러스터 덕분에 기본적으로 Available Soft-state 입력 데이터가 없는 상황 에서도 시스템의 상태는 항상 변경 될 수 있음 Eventual consistency 잠시동안 데이터가 inconsistency 할 수 있으나 결국에는 consistency 상태
- 13. ACID versus BASE
- 14. Consistency VS Availability Consistency - 항상 같은 데이터가 응답 되어야 한다. - 예) 하나 주문만 되어야 한다. 중복 예약은 발생 할 수 없음 - RDBMS 에서는 transaction 하여 데이터 consistency 보장 Availability - 언제나 응답할 수 있음 - 예) 서버중에 장애가 발생해도 서비스 할 수 있음. 그렇지 않은 경우는 장애 페이 지
- 15. CAP VS PACELC theorem - CAP대한 논란이 많음. - Partition Tolerance 정의가 일관성이 없다는 의견 - CAP 장애 상황 일 경우는 성립이 됨 - CAP 보다 명확함 - 정상 상황 일때 와 장애 상황 일때 의 특성을 파악 - 네트워크 장애 상황 일 때는 A/C 둘 중 선택 장애 상황일 아닐때는 L(Latency)/C 중 선택 if there is a partition (P) how does the system tradeoff between availability and consistency (A and C); else (E) when the system is running as normal in the absence of partitions, how does the system tradeoff between latency (L) and consistency (C)?
- 16. NoSQL 종류 Key-value store - Memcached, Redis, Riak, DynamoDB, Berkeley DB Graph store - Neo4j, InfiniteGraph, AllegroGraph, S2Graph(카카오) Column family store - Apache Cassandra, HBase, Accumulo Document store - MongoDB, CouchDB, CouchBase, RavenDB, MarkLogic
- 18. Key-value store 활용 - 대표적인 key-value store memcached/Redis - Memcached는 논리적으로 메모리를 combine 함으로써 낭비되는 메모리가 적음 - memcached web cache로 사용
- 20. Document Store 활용 뉴스 사이트 Blog 회원 가입 복잡한 상품 정보 JSON 포맷 으로 저장
- 21. Column-Family Stores - Inspired by Google Bigtable paper - Rows 에 많은 컬럼이 있음 - 각각의 컬럼은 key-value 형태 name -> key - 하나의 Row는 여러 key-value 조합 - 각각의 row에는 timestamp 함께 저장(write conflicts, TTL 등등)
- 22. Column-Family Stores 활용 - Event Logging(application 마다 고유의 컬럼을 가짐) application state, error log - E-Commerce 상품 추천, 장바구니 등등
- 23. Graph Databases - entities와 entities 사이의 relationship 을 저장 - entities -> “Node” 속성(박지성, 기성용)을 가짐 - relation -> “edge” 방향과, 속성(like, friend)을 가짐 - relationship 데이터에 특화 되어 있음
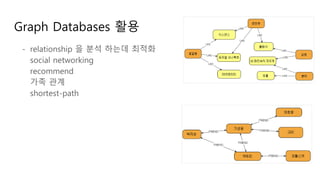
- 24. Graph Databases 활용 - relationship 을 분석 하는데 최적화 social networking recommend 가족 관계 shortest-path
- 25. 왜 NoSQL을 쓰는가? 개발하기 쉽다 big data 처리 가능
- 26. Cassandra 파헤치기
- 27. - Big Table & Dynamo 장점만 - PA/EL
- 29. Cassandra Ring - Cassandra cluster is called a ring. - cassandra 1.1 이전 버전에서는 각각의 노드는 token range를 가지고 있었음. - 노드를 추가 하거나 제거할 때 token range를 수동으로 계산. - 또한 특정 노드를 새로운 노드로
- 30. Cassandra 1.1 이후 Virtual nodes - 기존의 cassandra ring 문제점을 해결하기 위해 고안 - 각각의 노드는 small range 를 가짐 range 는 자동으로 계산된다. - 빠른 복구 가능 1.1 version 이하 -> 큰 범위를 가진 노드에서 복구 1.1 이상 -> small range를 가진 여러 노드로 부터 받기 때문에 복구 속도 빠름
- 31. Cassandra Write - client cassandra 어느 노드들 중에 하나에 write 요청을 함. 이 노드를 coordinator 라고 함 - coordinator는 해당 데이터의 Row key를 hashing 하여 어느 노드에 저장할지 결정 - Consistency Level에 따라 몇 개의 노드에 write 할지 참 고 함. - 특정 노드 상태가 정상이 아니라면 hint hand off 라는 공 간에 write 데이터 저장 노드가 정상으로 돌아올 때 데이터를 write 하기 위함
- 32. Cassandra write - 데이터 write 요청이 들어 오면 MemTable 메모리에 저장 장애에 대비 하기 위해 Commit log 로컬 디스크에 저장 - MemTable에 데이터가 쌓이면 SSTable 에 데이터를 flush - SSTable은 immutable 하고 sequential 특징이 있어 다수의 SSTable을 관리
- 33. Cassandra Read - client 가 read시 cassandra 노드들중 하나만 coordinator로 지정. 해당 요청의 row key를 hashing 하 여 접근해야할 노드위 위치 파악 - Consistency Level을 체크하여 몇 개의 Replication 을 확인 할지 결정 후 가장 가까운 노드에 read 요청을 함. - 다른 가까운 노드들에는 Data Digest Request 를 함. - Data와 Data Digest Request를 비교하여 일치 하지 않 으면 모든 노드들로부터 full date를 가지고 와 그중 가 장 최신 데이터 리턴 - 이후에 conflicting 노드 들은 최신 데이터로 업데이트.
- 34. 1) 데이터 read 요청이 들어오면 먼저 MemTable을 확인함. 2) 데이터가 없다면 Multiple SSTable에 바로 접근 하는게 아니라 Bloom Filter, Index를 먼저 확인 3) 각각의 SSTable은 메모리에 저장되는 bloom filter를 확인하여 해당 데이터가 있는지 빠르게 확인 4) 데이터가 없으면 여러 다른 bloom filter 확인 하면서 데이터를 확인 5) 데이터가 확인되면 index를 뒤져 해당 데이터의 offset 정보 취득 후 빠르게 SSTable 에서 해당 데이터 retrieve Cassandra Read within a node
- 35. Delete Data - 데이터 삭제 요청이 있을 때 데이터를 바로 삭제 하는 것이 아님 - 해당 데이터에 tombstone marker를 표시하고 SSTables compaction시 데이터 삭제함 - 데이터가 삭제 되더라도 Tombstone이 marked 되어 있는 것일 뿐 여전히 Disk에 존재 함. - 따라서 SSTable 의 데이터를 Sequential 하게 읽어야 하는 Cassandra 특징 때문에 Tombstone 데이터는 무조건 읽 힘. - 이러한 이유 때문에 Queue 방식으로 Cassandra를 사용하면 안된다.
- 36. Cassandra Query Language (CQL) KEYSPACE CREATE KEYSPACE RECOMMEND WITH REPLICATION = {‘CLASS’ : ‘NetworkTopologyStrategy’, ‘DC1’ : 3} TABLE CREATE TABLE RECOMMEND.ITEMBASE( ITEM_ID TEXT, RECOMMEND_ID TEXT, PRIMARY KEY(ITEM_ID) ); SELECT SELECT ITEM_ID FROM RECOMMEND.ITEMBASE; DELETE DELETE FROM RECOMMEND.ITEMBASE WHERE ITEM_ID = ‘1’; UPDATE UPDATE RECOMMEND.ITEMBASE SET RECOMMEND_ID = ‘2’ WHERE ITEM_ID = ‘1’;
- 37. Cassandra 활용 - 추천
- 38. 1980 1990 2000 2010 Relational Database Object Database 20년 동안 Relational Database 지배 Polyglot persistence
- 40. SUMMARY - NoSQL는 항상 좋은 툴이 될 수 없다. Domain, Business rule에 따라 신중한 결정이 필요하다 - 잘만 사용하면 이보다 좋을 수 없다 - NoSQL은 계속 진화 하고 있다. ACID 지원 하는 NoSQL 있음(예 : RAVEN DB)
- 41. 참고 서적
- 42. 참고 사이트 https://www.youtube.com/watch?v=qI_g07C_Q5I&t=142s (강추 Martin Fowler NoSQL) http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/ (CAP Theorem, 오해와 진실) http://meetup.toast.com/posts/58 Apache Cassandra 톺아보기 - 1편 http://meetup.toast.com/posts/60 Apache Cassandra 톺아보기 - 2편 http://meetup.toast.com/posts/65 Apache Cassandra 톺아보기 - 3편
Editor's Notes
- #3: NoSQL을 본격적으로 얘기 하기 전에 약간의 히스토리를 얘기 하겠다. 약간 지겨울수도 있겠지만
- #5: 하지만 몇가지 문제 들이 있었죠. 메모리에 저장 되어 있는 변수들.. Relational database 에 맞게 변환을 해야 했습니다. 특정 테이블에 row, column 에 맞게 데이터를 변환을 해야 했습니다. 참 귀찮은 일이죠.
- #6: 1980 년 중반에 나온 Relational Database 우리에게 굉장히 익숙한 DB Oracle, Mysql, Mssql 등등이 여기에 속함. Transaction 처리, SQL , Join, Procedure 등 다양한 기능들이 있죠 많은 기업들이 RDBMS 를 적극적으로 사용 했습니다. RDBMS는 정말 좋은 툴이죠 20년 동안 DBMS 에 시장에서 Relational Database 가 독보적으로 사용이 되었죠. 여러분 학교에서도 프로젝트를 한다고 한다면 보통은 Relational Database 를 많이 사용 했을거 같습니다. 1990 년 중반에 Object Database 가 나왔습니다. RDBMS 처럼 테이블에 저장하기 위해 변환을 할 필요가 없었습니다. 메모리에 있는 그대로 넣었으면 되었으니까요. 하지만.. 우리는 Object Database 를 지금까지 써본적도 없을 것이고 제품이 무엇인지 들어 본적도 없을 것입니다.
- #8: 많은 트래픽을 감당하기 위해 많은 시도 첫번 째로는 scale-up 을 시도 하게 되죠. CPU 코어수를 늘린다거나, 많은 디스크를 사용하거나 기타 등등 많은 비용이 들어가게 되고 또한 성능을 업그 레이드 할 수 있는 한계가 있음. 그래서 다음 대안으로 sclae-out 비싸지 않은 장비로 확장을 하게 되는 거죠. 대표적인 예는 데이터를 replicate 하거나 sharding 을 하는 것입니다. 물론 Oracle RAC, Microsoft SQL 이 cluster 구성을 할 수 있도록 되어 있긴 하죠.. 엄청나게 비쌉니다. 또한 하나의 디스크 만을 공유 하기 때문에 a single point of failure 이 발생 할 수 있죠,
- #9: 각각 다른 데이터 set 를 담당하게 되는 거죠. sharding 이라고 불립니다. 서버의 로드가 id 로 분리 되기 때문에 고르게 받을 수 있음. 장애에 대비하기 위해 master-slave replication Master는 write, update만 처리 하고 slave는 보통은 reads만 처리 순간적으로read 장애가 많아 진다고 하면 slave를 더 늘리면 되지만.. 갑자기 write 와 read 가 많아 지는 상황에서 순간적으로 master, slave 간데 데이터가 inconsistency 발생 가능성 있음. consistency의 의미는 commit 한 이후로는 항상 같은 데이터가 조회가 되어야 한다는 의미 인데.. 업데이트가 지연이 될 수 있다. RDBMS의 consistency 는 아주 중요한 요소 입니다. 이거에 대해서는 뒤에서 자세하게 설명 또한 Application 에서 어디로 데이터를 저장할지 써야 할지 알아야 합니다. 일반적으로 modular 연산으로 하게 되죠. 우리한테 이런 구조는 익숙 하지만.. 굉장히 많은 복합적인 문제들을 포함 하고 있습니다.
- #10: 뭐 이렇든.. 굉장히 문제 들이 복잡해 지면서 이러한 Google, Amazon 에서는 paper 발간 하게 됩니다. 구글의 BigTable, Amazon DynamoDB 들이 NoSQL이 탄생 에 많은 영향을 미칩니다.
- #11: 이제 부터 본격적으로 NoSQL에 대해서 얘기를 해보려고 합니다 high-level view 로 RDBMS 와 NoSQL 차이점을 설명해 보도록 하겠습니다. .
- #12: 정보처리 기사 공부 하거나 DBMS 대학교 수업 시간에 처음으로 배우는 거죠. 다시 복습 한다는 차원에서 얘기를 다시 해보겠습니다. RDBMS가 오랫동안 사용될 수 있었던 이유는 ACID 때문이죠.
- #13: RDBMS는 consistency, transaction에 집중을 한다면 NoSQL은 availability에 좀더 집중하고 있다고 생각. NOSQL 은 반대로 BASE 라는 개념을 사용. Basic availability : 많은 NoSQL 이라는 건 클러스터를 사용을 하기 때문에 어느 한 장비가 장애가 발생 하더라도 다른 노드 그 일을 대신 할 수 있게 됨 soft-state : 내가 데이터를 수정 하거나 입력하지 않았는데 데이터는 변경 될 수 있다는 의미에서 soft 라는 단어를 사용 했고요 Eventual consistency 는.. 우리가 RDBMS 가 사용 했다면 사실 이해하기가 쉽지 않을 것 같습니다. update, insert 를 하게 되면 우리는 당연히 데이터는 바로 반영이 될 것이고 어느때나 똑같은 데이터를 조회를 할 수 있다고 생각을 하게 되죠.. 하지만 NoSQL은 클러스터로 묶여 있고 데이터가 분산 되어서 저장이 되기 때문에 잠시동안은 데이터가 inconsistency 할 수 있습니다. 하지만 결국에는 데이터는 일치 하게 되겠죠. 쓸만한 DB 인거냐 생각을 해보면. Join, lock, transaction 이 없기 때문에 굉장히 빨라요. 당연 하겠죠 그 만큼 체크를 해야 되는 것들이 줄어 드니깐요. facebook like, twitter retweet에 적합하다.. Like가 안보인다고, retweet이 안보인다고 문제가 생기지 않는다. 이런 상황은 like 처리 되었다고 빨리 처리 해주고 뒤에서 데이터를 빨리 consistency 하게 만들어 주는 작업이 좋습니다.
- #14: 지금 까지 얘기 했던 ACID, BASE 에 대해서 비교를 해보자.. 영어를 볼건 없고 그림만 보아도 쉽게 이해 할 수 있다. ACID에 있는 그림은 굉장히 깐깐하게 보이는 사람이 있죠. 이와 같이 트랜잭션을 사용하고, 데이터는 항상 consistency 해야 하고 이 때문에 테이블을 lock, unlock 을 하는 이런 메커니즘을 사용 하고 있죠. 반면에 Base 는 어느 바다에 해먹 그림 인데요. 굉장히 편안해 보이죠. 트랜잭션을 사용하지 않고 데이터가 일시적으로 inconsistency 해도 허용 하고 lock 을 사용하지 않죠. 하지만 availability 에 중점을 두고 있습니다.
- #16: http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/ CAP는 분산 시스템을 선택할때 도움을 주는 가이드 역할을 한다. 즉 우리 비스지스에 맞게 올바른 database를 선택할 수 있는 가이드 역할을 해준다. CAP가 주장 하는 바로는 CAP 중에 2개만을 만족할 수 있다. Consistency 데이터 일관성을 중요하게 여길 것인가. Availability 장애 상황에서 read/update를 할 수 있는가. Partition Tolerance 이 부분 때문에 논란이 많은데.. 한 노드에서 다른 노드로 메시지가 유실 되어도 용인을 할 것인지에 대한 것이다. 사실 이 상황은 네트워크가 장애인 상황인데.. 이 세상에 네트워크가 장애가 발생하지 않은 네트워크는 없기 때문에.. P는 기본적으로 무조건 들어 가기 때문에 P가 빠진 분산 시스템이 있을 수 없다. 근래에는 PACELC가 맞다고 얘기가 되어 지고 있는데.. 이 것은 장애 상황 일때, 장애 상황이 아닐때를 모드 파악 할 수 있다. Partition 상황일때 Availability/Consistency 상충 되므로 둘 중에 하나만 선택이 되어야 하고, 장애 상황이 아닐 때는 latency/Consistency가 선택 되어야 한다. 뒤에서 설명할 Cassandra는 PA/EL 이다. 장애 상황 일때는 서비스를 최대한 할 수 있도록 초점을 맞추도록 하고 정상 상황 일때는 latency를 위해 consistency를 포기 한다. 모든 노드에 consistency를 위해 업데이트를 하게 되면 latency가 떨어 지게 된다.
- #17: 종류 4가지 RDBMS는 종류가 1가지다.
- #18: key, value의 단순한 형태. java 에서 hashMap 자료 구조와 동일함. value 이미지, 문서, PDF, HTML 어떤 것이든 가능 key 는 상품 아이디 value 는 상품의 정보가 될 수 있다.
- #20: document db 는 documents 저장 하거나 가지고 올 수 있다. 도큐먼트 형태는 JSON, XML, HTML 어떤 문서이든 가능하다. document는 self-describing 이면서 tree 형태의 자료구조를 가지고 있는 형태 이고, maps, collection 자료 구조를 가질 수 있다. RDBMS 처럼 schema가 있기 때문에 데이터를 empty 혹은 null로 표시를 해야 되지만 document db는 no schema 이기 때문에 그럴 필요도 없고 각 row 마다 데이터가 동일할 필요가 없다. 어떻게 보면 key-value store와 document store를 비슷하게 생각 할 수 있지만 document db는 document 안에 내용을 query를 할 수 있다. key-value는 반대로 불가능 하고 value를 파싱을 해야 함.
- #21: RDBMS 를 사용 한다면.. 상품 정보의 경우 여러 테이블에 나누어서 저장을 하게 되는데 document store 를 사용하게 되면 json, xml 형태로 편하게 저장 할 수 있죠
- #23: 테이블은 만들지만 스키마를 깐깐하게 fix 하지 않기 때문에 다양한 형태의 데이터를 저장 할 수 있다. 어플리케이션에서 만들어 내는 로그를 저장할 수 있는데.. 각 어플리케이션 마다 컬럼 정보가 틀리기 때문에 유연하게 저장 하는데.. 사용이 될 수 있고요.
- #26: 그러면 왜 우리가 NoSQL 쓰는가 의문을 가질 수 있을거 같습니다. 일반 첫번째 로는 개발하기 쉽다. 예를 들어 guardian, 기사를 통채로 저장한다. rdbms에 저장 하는걸 생각해봐.. 짜증난다. 친구 추천을 생각 한다고 해보자 rdmbs 엄청 복잡하다. graph 를 이용한다고 생각해봐라. 엄청 쉬움. 클러스터로 구성이 되어 있어 single point of failure 에 대비 할 수 있다. 빅데이터 처리가 가능하면서 처리 속도는 굉장히 빠르다. 라는 장점 때문에 NoSQL을 쓰는거 같습니다.
- #28: Cassandra는 Google Big Table, Dynamo 장점만 취했음. PACELC 에서 PA/EL 임 partition 일때 availability에 중점을 두고 장애 상황인 아니면 Latency에 중점을 둔다는 의미 화면에 내용을 엄청 좋아 보임. 몇가지 특징만 얘기 하면
- #29: 논리적인 Data 저장소 keyspace - rdbms 에서 database와 동일한 컨셉 keyspace는 table을 포함하고 있다. table을 여러개의 Row 들로 구성 되어 있고 Row는 key-value로 구성된 column 들로 구성. rdbms table-column 구조와 동일
- #39: 미래에는 NoSQL이 모든 것을 지배 하게 될까? 그건 아닐 것이다.. 아마도 다양한 polyglot persistence가 생기게 될 것이다. 다시 말해 다양한 DBMS가 서비스에 맞게 사용이 될 것이라는 의미 이다.
- #40: 요즘 많이 대두가 되고 있는 microservice, 간단하게 말하면 monolith 싱글 데이터 베이스에 한 프로젝트에 모든 코드를 다 집어 넣는 거죠.. 굉장히 무겁죠. 그 대신에 서비스를 짤개 쪼개서 배포를 빠르게 하고 고객의 요구에 빠르게 대응할 수 있도록 하는 거죠. 각각의 microservice는 각각의 요구사항에 맞게 다양한 NoSQL을 쓰게 되는 거죠.