Optimizing, profiling and deploying high performance Spark ML and TensorFlow AI models in production with GPUs
5 likes1,355 views

The document outlines a workshop led by Chris Fregly on utilizing TensorFlow with GPU optimization, focusing on both training and deployment of models. Attendees will learn advanced techniques for optimizing TensorFlow model training and inference, as well as handling distributed training across clusters. The session includes hands-on exercises using Jupyter notebooks and introduces key components of TensorFlow serving for model deployment.











































![BATCH NORMALIZATION
§ Each Mini-Batch May Have Wildly Different Distributions
§ Normalize per batch (and layer)
§ Speeds up Training!!
§ Weights are Learned Quicker
§ Final Model is More Accurate
§ Final mean and variance will be folded into Graph later
-- Always Use Batch Normalization! --
z = tf.matmul(a_prev, W)
a = tf.nn.relu(z)
a_mean, a_var = tf.nn.moments(a, [0])
scale = tf.Variable(tf.ones([depth/channels]))
beta = tf.Variable(tf.zeros ([depth/channels]))
bn = tf.nn.batch_normalizaton(a, a_mean, a_var,
beta, scale, 0.001)](https://image.slidesharecdn.com/219freglyoptimizingprofilinganddeployinghighperformancesparkmlandtensorflowaimodelsinproductionwithg-170626215442/85/Optimizing-profiling-and-deploying-high-performance-Spark-ML-and-TensorFlow-AI-models-in-production-with-GPUs-44-320.jpg)























































Optimizing, profiling and deploying high performance Spark ML and TensorFlow AI models in production with GPUs
- 1. TENSORFLOW + GPU WORKSHOP CHRIS FREGLY, RESEARCH ENGINEER @ PIPELINE.IO
- 3. INTRODUCTIONS: ME § Chris Fregly, Research Engineer @ § Formerly Netflix and Databricks § Advanced Spark and TensorFlow Meetup Please Join Our 18,000+ Members Globally!! * San Francisco * Chicago * Washington DC * London Please Join!!
- 4. INTRODUCTIONS: YOU § Software Engineer or Data Scientist interested in optimizing and deploying TensorFlow models to production § Assume you have a working knowledge of TensorFlow
- 5. NOTES ABOUT THIS MATERIAL
- 6. CONTENT BREAKDOWN § 50% Training Optimizations (TensorFlow, XLA, Tools) § 50% Deployment and Inference Optimizations (Serving) § Why Heavy Focus on Inference? § Training: boring batch, O(num_data_scientists) § Inference: exciting realtime, O(num_users_of_app) § We Use Simple Models to Highlight Optimizations § Warning: This is not introductory TensorFlow material!
- 7. 100% OPEN SOURCE CODE § https://github.com/fluxcapacitor/pipeline/ § Please Star this Repo! J § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml
- 8. HANDS-ON EXERCISES § Combo of Jupyter Notebooks and Command Line § Command Line through Jupyter Terminal § Some Exercises Based on Experimental Features In Other Words, You Will See Errors. We’ll be OK!!
- 9. YOU WILL LEARN… § TensorFlow Best Practices § To Inspect and Debug Models § To Distribute Training Across a Cluster § To Optimize Training with Queue Feeders § To Optimize Training with XLA JIT Compiler § To Optimize Inference with AOT and Graph Transform Tool (GTT) § Key Components of TensorFlow Serving § To Deploy Models with TensorFlow Serving § To Optimize Inference by Tuning TensorFlow Serving
- 10. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 11. EVERYBODY GETS A GPU!
- 12. SETUP ENVIRONMENT § Step 1: Browse to the following: http://allocator.demo.pipeline.io/allocate § Step 2: Browse to the following: http://<ip-address> Need Help? Use the Chat!
- 13. VERIFY SETUP http://<ip-address> Any username, Any password!
- 14. HOUSEKEEPING § Navigate to the following notebook: 01_Explore_Environment § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 15. PULSE CHECK
- 17. GPU HALF-PRECISION SUPPORT § FP16, INT8 are “Half Precision” § Supported by Pascal P100 (2016) and Volta V100 (2017) § Flexible FP32 GPU Cores Can Fit 2 FP16’s for 2x Throughput! § Half-Precision is OK for Approximate Deep Learning Use Cases
- 18. VOLTA V100 RECENTLY ANNOUNCED § 84 Streaming Multiprocessors (SM’s) § 5,376 GPU Cores § 672 Tensor Cores (ie. Google TPU) § Mixed FP16/FP32 Precision § More Shared Memory § New L0 Instruction Cache § Faster L1 Data Cache § V100 vs. P100 Performance § 12x TFLOPS @ Peak Training § 6x Inference Throughput
- 19. V100 AND CUDA 9 § Independent Thread Scheduling - Finally!! § Similar to CPU fine-grained thread synchronization semantics § Allows GPU to yield execution of any thread § Still Optimized for SIMT (Same Instruction Multiple Thread) § SIMT units automatically scheduled together § Explicit Synchronization P100 V100
- 20. GPU CUDA PROGRAMMING § Barbaric, But Fun Barbaric! § Must Know Underlying Hardware Very Well § Many Great Debuggers/Profilers § Hardware Changes are Painful! § Newer CUDA compiler automatically JIT-compilesold CUDA code to new NVPTX § Not optimal, of course
- 21. CUDA STREAMS § Asynchronous I/O Transfer § Overlap Compute and I/O § Keeps GPUs Saturated § Fundamental to Queue Framework in TensorFlow
- 22. LET’S SEE WHAT THIS THING CAN DO! § Navigate to the following notebook: 01a_Explore_GPU 01b_Explore_Numba § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 23. PULSE CHECK
- 24. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 25. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 26. TRAINING TERMINOLOGY § Tensors: N-Dimensional Arrays § ie. Scalar, Vector, Matrix § Operations: MatMul, Add, SummaryLog,… § Graph: Graph of Operations (DAG) § Session: ContainsGraph(s) § Feeds: Feed inputs into Operation § Fetches: Fetch output from Operation § Variables: What we learn through training § aka “weights”, “parameters” § Devices: Hardware device on which we train -TensorFlow- Trains Variables -User- Fetches Outputs -User- Feeds Inputs -TensorFlow- Performs Operations -TensorFlow- Flows Tensors with tf.device(“worker:0/device/gpu:0,worker:1/device/gpu:0”)
- 27. TRAINING DEVICES § cpu:0 § By default, all CPUs § Requires extra config to target a CPU § gpu:0..n § Each GPU has a unique id § TF usually prefers a single GPU § xla_cpu:0, xla_gpu:0..n § “JIT Compiler Device” § Hints TensorFlow to attempt JIT Compile with tf.device(“/cpu:0”): with tf.device(“/gpu:0”): with tf.device(“/gpu:1”):
- 28. TRAINING METRICS: TENSORBOARD § Summary Ops § Event Files /root/tensorboard/linear/<version>/events… § Tags § Organize data within Tensorboard UI loss_summary_op = tf.summary.scalar('loss', loss) merge_all_summary_op = tf.summary.merge_all() summary_writer = tf.summary.FileWriter( '/root/tensorboard/linear/<version>', graph=sess.graph)
- 29. TRAINING ON EXISTING INFRASTRUCTURE § Data Processing § HDFS/Hadoop § Spark § Containers § Docker § Schedulers § Kubernetes § Mesos <dependency> <groupId>org.tensorflow</groupId> <artifactId>tensorflow-hadoop</artifactId> <version>1.0-SNAPSHOT</version> </dependency> https://github.com/tensorflow/ecosystem
- 30. TRAINING PIPELINES § Don’t Use feed_dict for Production Workloads!! § feed_dict Requires Python <-> C++ Serialization § Retrieval is Single-threaded, Synchronous, SLOW! § Can’t Retrieve Until Current Batch is Complete § CPUs/GPUs Not Fully Utilized! § Use Queue or Dataset API
- 31. QUEUES § More than Just a Traditional Queue § Perform I/O, pre-processing, cropping, shuffling § Pulls from HDFS, S3, Google Storage, Kafka, ... § Combine many small files into large TFRecord files § Typically use CPUs to focus GPUs on compute § Uses CUDA Streams
- 32. DATA MOVEMENT WITH QUEUES § GPU Pulls Batch from Queue (CUDA Streams) § GPU pulls next batch while processing current batch GPUs Stay Fully Utilized!
- 33. QUEUE CAPACITY PLANNING § batch_size § # examples / batch (ie. 64 jpg) § Limited by GPU RAM § num_processing_threads § CPU threads pull and pre-process batches of data § Limited by CPU Cores § queue_capacity § Limited by CPU RAM (ie. 5 * batch_size)
- 34. DETECT UNDERUTILIZED CPUS, GPUS § Instrument training code to generate “timelines” § Analyze with Google Web Tracing Framework (WTF) § Monitor CPU with `top`, GPU with `nvidia-smi` http://google.github.io/tracing-framework/ from tensorflow.python.client import timeline trace = timeline.Timeline(step_stats=run_metadata.step_stats) with open('timeline.json', 'w') as trace_file: trace_file.write( trace.generate_chrome_trace_format(show_memory=True))
- 35. LET’S FEED A QUEUE FROM HDFS § Navigate to the following notebook: 02_Feed_Queue_HDFS § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 36. PULSE CHECK
- 37. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 38. TENSORFLOW MODEL § MetaGraph § Combines GraphDef and Metadata § GraphDef § Architecture of your model (nodes, edges) § Metadata § Asset: Accompanying assets to your model § SignatureDef: Maps external : internal tensors § Variables § Stored separately during training (checkpoint) § Allows training to continue from any checkpoint § Variables are “frozen” into Constants when deployed for inference GraphDef x W mul add b MetaGraph Metadata Assets SignatureDef Tags Version Variables: “W” : 0.328 “b” : -1.407
- 39. TENSORFLOW SESSION Session graph: GraphDef Variables: “W” : 0.328 “b” : -1.407 Variablesare Periodically Checkpointed GraphDef is Static
- 40. LET’S TRAIN A MODEL (CPU) § Navigate to the following notebook: 03_Train_Model_CPU § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 41. LET’S TRAIN A MODEL (GPU) § Navigate to the following notebook: 03a_Train_Model_GPU § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 42. TENSORFLOW DEBUGGER § Step through Operations § Inspect Inputs and Outputs § Wrap Session in Debug Session sess = tf.Session(config=config) sess = tf_debug.LocalCLIDebugWrapperSession(sess)
- 43. LET’S DEBUG A MODEL § Navigate to the following notebook: 04_Debug_Model § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 44. BATCH NORMALIZATION § Each Mini-Batch May Have Wildly Different Distributions § Normalize per batch (and layer) § Speeds up Training!! § Weights are Learned Quicker § Final Model is More Accurate § Final mean and variance will be folded into Graph later -- Always Use Batch Normalization! -- z = tf.matmul(a_prev, W) a = tf.nn.relu(z) a_mean, a_var = tf.nn.moments(a, [0]) scale = tf.Variable(tf.ones([depth/channels])) beta = tf.Variable(tf.zeros ([depth/channels])) bn = tf.nn.batch_normalizaton(a, a_mean, a_var, beta, scale, 0.001)
- 45. PULSE CHECK
- 46. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 47. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 48. MULTI-GPU TRAINING (SINGLE NODE) § Variables stored on CPU (cpu:0) § Model graph (aka “replica”, “tower”) is copied to each GPU(gpu:0, gpu:1, …) Multi-GPU Training Steps: 1. CPU transfersmodel to each GPU 2. CPU waitson all GPUs to finish batch 3. CPU copiesall gradientsback from all GPUs 4. CPU synchronizesand averagesall gradientsfrom GPUs 5. CPU updatesGPUs with new variables/weights 6. Repeat Step 1 until reaching stop condition (ie. max_epochs)
- 49. DISTRIBUTED, MULTI-NODE TRAINING § TensorFlow Automatically Inserts Send and Receive Ops into Graph § Parameter Server Synchronously AggregatesUpdates to Variables § Nodes with Multiple GPUs will Pre-Aggregate Before Sending to PS Worker0 Worker0 Worker1 Worker0 Worker1 Worker2 gpu0 gpu1 gpu2 gpu3 gpu0 gpu1 gpu2 gpu3 gpu0 gpu1 gpu2 gpu3 gpu0 gpu1 gpu0 gpu0
- 50. SYNCHRONOUS VS. ASYNCHRONOUS § Synchronous § Nodes compute gradients § Nodes update Parameter Server (PS) § Nodes sync on PS for latest gradients § Asynchronous § Some nodes delay in computing gradients § Nodes don’t update PS § Nodes get stale gradients from PS § May not converge due to stale reads!
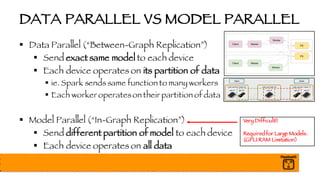
- 51. DATA PARALLEL VS MODEL PARALLEL § Data Parallel (“Between-Graph Replication”) § Send exact same model to each device § Each device operates on its partition of data § ie. Spark sends same function to many workers § Each worker operateson their partition of data § Model Parallel (“In-Graph Replication”) § Send different partition of model to each device § Each device operates on all data Very Difficult!! Requiredfor Large Models. (GPU RAM Limitation)
- 52. DISTRIBUTED TENSORFLOW CONCEPTS § Client § Program that builds a TF Graph, constructs a session,interacts with the cluster § Written in Python, C++ § Cluster § Set of distributed nodes executing a graph § Nodes can play any role § Jobs (“Roles”) § Parameter Server (“ps”)stores andupdates variables § Worker (“worker”) performs compute-intensive tasks (stateless) § Assigned 0..* tasks § Task (“Server Process”) “ps” and “worker” are conventional names
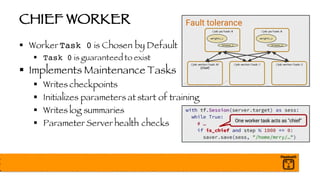
- 53. CHIEF WORKER § Worker Task 0 is Chosen by Default § Task 0 is guaranteed to exist § Implements Maintenance Tasks § Writes checkpoints § Initializes parameters at start of training § Writes log summaries § Parameter Server health checks
- 54. NODE AND PROCESS FAILURES § Checkpoint to Persistent Storage (HDFS, S3) § Use MonitoredTrainingSession and Hooks § Use a Good Cluster Orchestrator (ie. Kubernetes,Mesos) § Understand Failure Modes and Recovery States Stateless, Not Bad: Training Continues Stateful, Bad: TrainingMustStop Dios Mio! Long NightAhead…
- 55. VALIDATING DISTRIBUTED MODEL § Separate Training and Validation Clusters § Validate using Saved Checkpoints from Parameter Servers § Avoids Resource Contention Training Cluster Validation Cluster Parameter Server Cluster
- 56. EXPERIMENT AND ESTIMATOR API § Higher-Level APIs Simplify Distributed Training § Picks Up Configuration from Environment § Supports Custom Models (ie. Keras) § Used for Training, Validation, and Prediction § API is Changing, but Patterns Remain the Same § Works Well with Google Cloud ML (Surprised?!)
- 57. LET’S TRAIN A DISTRIBUTED MODEL § Navigate to the following notebook: 05_Train_Model_Distributed § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 58. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 59. XLA FRAMEWORK § Accelerated Linear Algebra (XLA) § Goals: § Reduce reliance on custom operators § Improve execution speed § Improve memory usage § Reduce mobile footprint § Improve portability § Helps TF Stay Flexible and Performant
- 60. XLA HIGH LEVEL OPTIMIZER (HLO) § Compiler Intermediate Representation (IR) § Independent of source and target language § Define Graphs using HLO Language § XLA Step 1 Emits Target-IndependentHLO § XLA Step 2 Emits Target-DependentLLVM § LLVM Emits Native Code Specific to Target § Supports x86-64, ARM64 (CPU), and NVPTX (GPU)
- 61. JIT COMPILER § Just-In-Time Compiler § Built on XLA Framework § Goals: § Reduce memory movement – especiallyuseful on GPUs § Reduce overhead of multiple function calls § Similar to Spark Operator Fusing in Spark 2.0 § Unroll Loops, Fuse Operators, Fold Constants, … § Scope to session, device, or `with jit_scope():`
- 62. VISUALIZING JIT COMPILER IN ACTION Before After Google Web Tracing Framework: http://google.github.io/tracing-framework/ from tensorflow.python.client import timeline trace = timeline.Timeline(step_stats=run_metadata.step_stats) with open('timeline.json', 'w') as trace_file: trace_file.write( trace.generate_chrome_trace_format(show_memory=True))
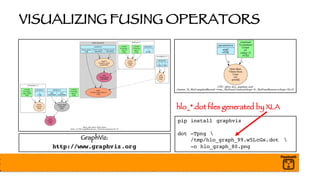
- 63. VISUALIZING FUSING OPERATORS pip install graphviz dot -Tpng /tmp/hlo_graph_99.w5LcGs.dot -o hlo_graph_80.png GraphViz: http://www.graphviz.org hlo_*.dot files generated by XLA
- 64. LET’S TRAIN A MODEL (XLA + JIT) § Navigate to the following notebook: 06_Train_Model_XLA_CPU § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 65. LET’S TRAIN A MODEL (XLA + JIT) § Navigate to the following notebook: 06a_Train_Model_XLA_GPU § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 66. IT’S WORTH HIGHLIGHTING… § From Now On, We Optimize Trained Models For Inference § In Other Words, We’re Done with Training! Yeah!!
- 67. PULSE CHECK
- 68. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 69. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 70. AOT COMPILER § Standalone, Ahead-Of-Time (AOT) Compiler § Built on XLA framework § tfcompile § Creates executable with minimal TensorFlow Runtime needed § Includes only dependenciesneeded by subgraph computation § Creates functions with feeds (inputs) and fetches (outputs) § Packaged ascc_libary header and object filesto link into your app § Commonly used for mobile device inference graph § Currently, only CPU x86-64 and ARM are supported - no GPU
- 71. GRAPH TRANSFORM TOOL (GTT) § Optimize Trained Models for Inference § Remove training-only Ops (checkpoint, drop out, logs) § Remove unreachable nodes between given feed -> fetch § Fuse adjacent operators to improve memory bandwidth § Fold final batch norm mean and variance into variables § Round weights/variables improves compression (ie. 70%) § Quantize weights and activations simplifies model § FP32 down to INT8
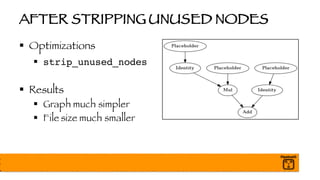
- 73. AFTER STRIPPING UNUSED NODES § Optimizations § strip_unused_nodes § Results § Graph much simpler § File size much smaller
- 74. AFTER REMOVING UNUSED NODES § Optimizations § strip_unused_nodes § remove_nodes § Results § Pesky nodes removed § File size a bit smaller
- 75. AFTER FOLDING CONSTANTS § Optimizations § strip_unused_nodes § remove_nodes § fold_constants § Results § Placeholders (feeds) -> Variables
- 76. AFTER FOLDING BATCH NORMS § Optimizations § strip_unused_nodes § remove_nodes § fold_constants § fold_batch_norms § Results § Graph remains the same § File size approximatelythe same
- 77. WEIGHT QUANTIZATION § FP16 and INT8 Are Smaller and Computationally Simpler § Weights/Variables are Constants § Easy to Linearly Quantize
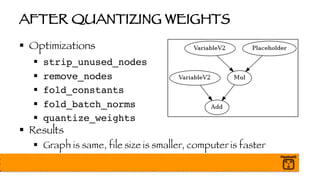
- 78. AFTER QUANTIZING WEIGHTS § Optimizations § strip_unused_nodes § remove_nodes § fold_constants § fold_batch_norms § quantize_weights § Results § Graph is same, file size is smaller, computer is faster
- 79. LET’S OPTIMIZE MODEL WITH GTT § Navigate to the following notebook: 07_Optimize_Model § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 80. BUT WAIT, THERE’S MORE!
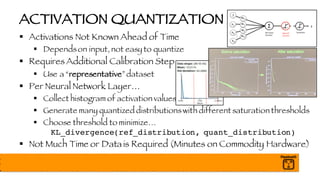
- 81. ACTIVATION QUANTIZATION § Activations Not Known Ahead of Time § Dependson input, not easy to quantize § Requires Additional Calibration Step § Use a “representative”dataset § Per Neural Network Layer… § Collect histogram of activation values § Generate many quantized distributionswith different saturation thresholds § Choose threshold to minimize… KL_divergence(ref_distribution, quant_distribution) § Not Much Time or Data is Required (Minutes on Commodity Hardware)
- 82. ACTIVATION QUANTIZATION GRAPH OPS Create Conversion Subgraph Produces QuantizedMatMul, QuantizedRelu EliminateAdjacent Dequantize + Quantize
- 83. AFTER ACTIVATION QUANTIZATION § Optimizations § strip_unused_nodes § remove_nodes § fold_constants § fold_batch_norms § quantize_weights § quantize_nodes (activations) § Results § Larger graph, needs calibration! Requires additional freeze_requantization_ranges
- 84. LET’S OPTIMIZE MODEL WITH GTT § Navigate to the following notebook: 08_Optimize_Model_Quantize_Activations § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 85. PULSE CHECK
- 86. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 87. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 88. MODEL SERVING TERMINOLOGY § Inference § Only Forward Propagation through Network § Predict, Classify, Regress, … § Bundle § GraphDef, Variables, Metadata, … § Assets § ie. Map of ClassificationID -> String § {9283: “penguin”, 9284: “bridge”, …} § Version § Every Model Has a Version Number (Integers Only?!) § Version Policy § ie. Serve Only Latest (Highest), Serve both Latest and Previous, …
- 89. TENSORFLOW SERVING FEATURES § Low-latency or High-throughput Tuning § Supports Auto-Scaling § DifferentModels/Versions Served in Same Process § Custom Loaders beyond File-based § Custom Serving Models beyond HashMap and TensorFlow § Custom Version Policies for A/B and Bandit Tests § Drain Requests for Graceful Model Shutdown / Update § Extensible Request Batching Strategies for Diff Use Cases and HW § Uses Highly-Efficient GRPC and Protocol Buffers
- 90. PREDICTION SERVICE § Predict (Original, Generic) § Input: List of Tensors § Output: List of Tensors § Classify § Input: List of `tf.Example` (key, value) pairs § Output: List of (class_label: String, score: float) § Regress § Input: List of `tf.Example` (key, value) pairs § Output: List of (label: String, score: float)
- 91. PREDICTION INPUTS + OUTPUTS § SignatureDef § Defines inputs and outputs § Maps external (logical) to internal (physical) tensor names § Allows internal (physical) tensor names to change tensor_info_x_observed = utils.build_tensor_info(x_observed) tensor_info_y_pred = utils.build_tensor_info(y_pred) prediction_signature = signature_def_utils.build_signature_def( inputs = {'x_observed': tensor_info_x_observed}, outputs = {'y_pred': tensor_info_y_pred}, method_name = signature_constants.PREDICT_METHOD_NAME )
- 92. MULTI-HEADED INFERENCE § Multiple “Heads” of Model § Return class and scores to be fed into another model § Inputs Propagated Forward Only Once § Optimizes Bandwidth, CPU, Latency, Memory, Coolness
- 93. BUILD YOUR OWN MODEL SERVER (?!) § Adapt GRPC(Google) <-> HTTP (REST of the World) § Perform Batch Inference vs. Request/Response § Handle Requests Asynchronously § Support Mobile, Embedded Inference § Customize Request Batching § Add Circuit Breakers, Fallbacks § Control Latency Requirements § Reduce Number of Moving Parts #include “tensorflow_serving/model_servers/server_core.h” … class MyTensorFlowModelServer { ServerCore::Options options; // set options (model name, path, etc) std::unique_ptr<ServerCore> core; TF_CHECK_OK( ServerCore::Create(std::move(options), &core) ); } Compile and Link with libtensorflow.so
- 94. FREEZING MODEL FOR DEPLOYMENT § Optimizations § freeze_graph § Results § Variables -> Constants Finally!! We’re Ready to Deploy…
- 95. LET’S DEPLOY UNOPTIMIZED MODEL § Navigate to the following notebook: 08_Deploy_Unoptimized_Model § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 96. LET’S DEPLOY OPTIMIZED MODEL § Navigate to the following notebook: 09_Deploy_Optimized_Model § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 97. PULSE CHECK
- 98. BREAK § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Need Help? Use the Chat!
- 99. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 100. REQUEST BATCH TUNING § max_batch_size § Enables throughput/latency tradeoff § Bounded by RAM § batch_timeout_micros § Defines batch time window, latency upper-bound § Bounded by RAM § num_batch_threads § Defines parallelism § Bounded by CPU cores § max_enqueued_batches § Defines queue upper bound, throttling § Bounded by RAM Reaching either threshold will trigger a batch
- 101. BATCH SCHEDULER STRATEGIES § BasicBatchScheduler § Best for homogeneous request types (ie. always classify or always regress) § Async callback upon max_batch_size or batch_timeout_micros § BatchTask encapsulates unit of work to be batched § SharedBatchScheduler § Best for heterogeneous request types, multi-step inference, ensembles, … § Groups BatchTasks into separate queues to form homogenous batches § Processes batches fairly through interleaving § StreamingBatchScheduler § Mixed CPU/GPU/IO-bound workloads § Provides fine-grained control for complex, multi-phase inference logic Must Experiment to Find the Best Strategy for You!!
- 102. LET’S TUNE THE MODEL SERVER § Navigate to the following notebook: 10_Tune_Model_Server § https://github.com/fluxcapacitor/pipeline/gpu.ml/ notebooks/
- 103. PULSE CHECK
- 104. AGENDA § Setup Environment § Train and Debug TensorFlow Model § Train with Distributed TensorFlow Cluster § Optimize Model with XLA JIT Compiler § Optimize Model with XLA AOT and Graph Transforms § Deploy Model to TensorFlow Serving Runtime § Optimize TensorFlow Serving Runtime § Wrap-up and Q&A
- 105. YOU JUST LEARNED… § TensorFlow Best Practices § To Inspect and Debug Models § To Distribute Training Across a Cluster § To Optimize Training with Queue Feeders § To Optimize Training with XLA JIT Compiler § To Optimize Inference with AOT and Graph Transform Tool (GTT) § Key Components of TensorFlow Serving § To Deploy Models with TensorFlow Serving § To Optimize Inference by Tuning TensorFlow Serving
- 106. Q&A § Thank you!! § https://github.com/fluxcapacitor/pipeline/ § Slides, code, notebooks, Docker images available here: https://github.com/fluxcapacitor/pipeline/ gpu.ml Contact Me @ Email: chris@pipeline.io Twitter: @cfregly