Parallel SPAM Clustering with Hadoop
Download as ODP, PDF0 likes1,048 views

The document discusses parallelizing spam clustering using Apache Hadoop. It presents an implementation of k-means clustering on a dataset of 1 million spam emails distributed across Apache Hadoop. The implementation abstracts the k-means algorithm and defines mappers and reducers to run the algorithm in parallel. Benchmark results show the Hadoop implementation is faster than a sequential approach and scales well with additional nodes. Analysis of overhead shows sorting to be the largest contributor. The document concludes there is room for further optimization of the system.




































Parallel SPAM Clustering with Hadoop
- 1. Parallel Spam Clustering with Apache Hadoop Thibault Debatty
- 2. Spam ● 70% of total email volume ● Estimated cost : $20.5 billion/year ● To fight better, need better strategic knowledge ● Examples : ● “Guaranteed Results” ● “Make YourPenis 3-inches longer & thicker, girl will love you 1k” Thibault Debatty Parallel Spam Clustering with Apache Hadoop 2
- 3. Spam ● 70% of total email volume ● Estimated cost : $20.5 billion/year ● To fight better, need better strategic knowledge ● Examples : ● “Guaranteed Results” Close IP ● “Make YourPenis 3-inches longer & thicker, girl will Same domain love you 1k” Thibault Debatty Parallel Spam Clustering with Apache Hadoop 3
- 4. Problem statement ● Cluster spams in parallel : ● To get useful insights ● Fast! ● Dataset : 1 million spams (231MB) Thibault Debatty Parallel Spam Clustering with Apache Hadoop 4
- 5. Problem statement ● Subject Your Special Order #253650 ● Charset windows-1250 ● Geo GB ● Day 2010-10-01 ● Host virginmedia.com ● ip 82.4.229.158 ● Lang english ● Size 1482 ● From berry_wagnertl@migrosbank.ch ● Rcpt brady@domain0140.com Thibault Debatty Parallel Spam Clustering with Apache Hadoop 5
- 6. What's next... 1. MapReduce and Apache Hadoop 2. Parallel K-means 3. Implementation 4. Benchmarks and speedup analysis 5. Clusters vizualisation Thibault Debatty Parallel Spam Clustering with Apache Hadoop 6
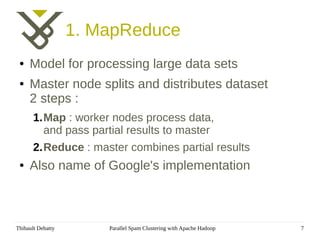
- 7. 1. MapReduce ● Model for processing large data sets ● Master node splits and distributes dataset 2 steps : 1.Map : worker nodes process data, and pass partial results to master 2.Reduce : master combines partial results ● Also name of Google's implementation Thibault Debatty Parallel Spam Clustering with Apache Hadoop 7
- 8. 1. Apache Hadoop ● Free implementation of MapReduce ● Written in Java ● Process large amounts of data (PB) ● Used by : ● Yahoo : + 10.000 cores ● Facebook : 30 PB of data ● Distributed filesystem (HDFS) + data locality Thibault Debatty Parallel Spam Clustering with Apache Hadoop 8
- 9. 1. Apache Hadoop ● Job Tracker ● ≃ Master ● Divides input data into “splits” ● Schedules map tasks (with data locality) ● Schedules reduce tasks on nodes ● Checks tasks health Thibault Debatty Parallel Spam Clustering with Apache Hadoop 9
- 10. 1. Apache Hadoop <key, value> <key, list of values> Thibault Debatty Parallel Spam Clustering with Apache Hadoop 10
- 11. 2. KMeans ● Select initial centers ● Until stop criterion is reached : ● Assign each point to closest center ● Compute new center ● Advantages : ● Suited to large datasets ● Can be implemented in parallel ● Computation O(nki) Thibault Debatty Parallel Spam Clustering with Apache Hadoop 11
- 12. 2. Parallel KMeans ● “Parallel K-Means Clustering Based on MapReduce” Weizhong Zhao, Huifang Ma and Qing He ● Map (point) : ● Compute distance to each center ● Output <id closest center, point> ● Reduce (list of points) : ● Compute center ● Output <center> Thibault Debatty Parallel Spam Clustering with Apache Hadoop 12
- 13. 3. Implementation : KMeans ● Abstract KMeans ● Abstract KMeansMapper ● Abstract KmeansReducer ● Interface IPoint ● Interface ICenter ● 2 concrete implementations : ● Spam ● Simple 2D points Thibault Debatty Parallel Spam Clustering with Apache Hadoop 13
- 14. 3. Implementation : Abstract KMeans // Write to "/it_0/part00000" this.writeInitialCentroids(); for (…) { conf.setMapperClass(this.mapper); conf.setReducerClass(this.reducer); conf.setInt("iteration", iteration); SetOutputPath(... "/it_" + (iteration + 1)); ... } Thibault Debatty Parallel Spam Clustering with Apache Hadoop 14
- 15. 3. Implementation : Abstract KMeansMapper public void configure(JobConf job) { // reads from // "/it_" + job.get("iteration") + "/partxxxxx" this.fetchCenters(job); } public void map(key, value,...) { IPoint point = this.createPointInstance(); point.parse(value); ... } public abstract IPoint createPointInstance(); public abstract ICenter createCenterInstance(); Thibault Debatty Parallel Spam Clustering with Apache Hadoop 15
- 16. 3. Implementation : Abstract KMeansReducer public void reduce(key, values, …) { new_center = this.createCenterInstance(); new_center.setOldCenter(old_center); while (values.hasNext()) { new_center.addPoint(point); } new_center.compute(); output.collect(new_center); } public abstract IPoint createPointInstance(); public abstract ICenter createCenterInstance(); Thibault Debatty Parallel Spam Clustering with Apache Hadoop 16
- 17. 3. Implementation : Spam Clustering ● Distance between spams : Weighted Average of feature distances ● Text features : Jaro distance Thibault Debatty Parallel Spam Clustering with Apache Hadoop 17
- 18. 3. Implementation : Spam Clustering Jaro similarity = Where : ● m = number of matching characters; ● t = number matching characters not located at the same position / 2. Matching = not farther than => Takes misspelling into account Thibault Debatty Parallel Spam Clustering with Apache Hadoop 18
- 19. 3. Implementation : Spam Clustering Distance between spams : Weighted Average of feature distances ● Text features : Jaro distance ● IP : Number of different bits / 32 ● Size : max 10% difference ● Day : arctangent-shaped function Thibault Debatty Parallel Spam Clustering with Apache Hadoop 19
- 20. 3. Implementation : Spam Clustering Thibault Debatty Parallel Spam Clustering with Apache Hadoop 20
- 21. 3. Implementation : Spam Clustering ● Center of cluster : ● Text features : Longest Common Subsequence; ● Charset, Geo (country code), Lang, Day : most often occurring value; ● Size : average value. Thibault Debatty Parallel Spam Clustering with Apache Hadoop 21
- 22. 4. Benchmarks ● Small Cluster : 3 nodes ● Single core ● 2GB RAM ● Gigabit Ethernet network ● Data replication : 3 Thibault Debatty Parallel Spam Clustering with Apache Hadoop 22
- 23. 4. Benchmarks ● n = 1M spams ● k = 30 ● i = 10 => 1131 sec Thibault Debatty Parallel Spam Clustering with Apache Hadoop 23
- 24. 4. Benchmarks : scalability 3500 3000 2500 Execution time (sec) 2000 1500 1000 500 0 1 node 2 nodes 3 nodes Thibault Debatty Parallel Spam Clustering with Apache Hadoop 24
- 25. 4. Benchmarks : scalability Thibault Debatty Parallel Spam Clustering with Apache Hadoop 25
- 26. 4. Benchmarks : Hadoop Overhead Sequential : 2424 sec 3 servers (theoretic) : 808 sec 3 servers (real) : 1131 sec Overhead : 323 sec (40%) Thibault Debatty Parallel Spam Clustering with Apache Hadoop 26
- 27. 4. Benchmarks : Hadoop Overhead Sequential : 2424 sec 3 servers (theoretic) : 808 sec 3 servers (real) : 1131 sec Overhead : 323 sec (40%) MPI Jumpshot Thibault Debatty Parallel Spam Clustering with Apache Hadoop 27
- 28. 4. Benchmarks : Hadoop Overhead Sequential : 2424 sec 3 servers (theoretic) : 808 sec 3 servers (real) : 1131 sec Overhead : 323 sec (40%) No data (setup) : 76 sec (9.5%) Trivial distance (setup + sort) : 242 sec Sort : 166 sec (20.5%) Remaining : 81 sec (10%) Thibault Debatty Parallel Spam Clustering with Apache Hadoop 28
- 29. 4. Benchmarks : Weka and Mahout ● 10 million 2D points ● Weka (sequential) 5355 sec ● Hadoop: 1841 sec (2.9x faster) ● Mahout + 4h ? Thibault Debatty Parallel Spam Clustering with Apache Hadoop 29
- 30. 4. Benchmarks ● Bigger cluster : ● 27 nodes ● 2 x 4 cores ● 16 GB ● Deployment: ● Shared home dir (NFS) ● Custom setup script ● Executed on all nodes through SSH Thibault Debatty Parallel Spam Clustering with Apache Hadoop 30
- 31. 4. Benchmarks : Cluster 1M spams Small cluster : Bigger cluster : ● 3 cores ● 216 cores ● k = 30 ● k = 4000 ● 1131 sec ● 2484 sec Thibault Debatty Parallel Spam Clustering with Apache Hadoop 31
- 32. 4. Benchmarks : Comparison Small cluster : Bigger cluster : x 72 ● 3 cores ● 216 cores x 133 ● k = 30 ● k = 4000 ● 1131 sec ● 2484 sec Expected : 2089 sec Difference : 19% Thibault Debatty Parallel Spam Clustering with Apache Hadoop 32
- 33. 4. Benchmarks : Profiling and optimization With String dates : With timestamps : - 32% ● 1131 sec ● 770 sec Thibault Debatty Parallel Spam Clustering with Apache Hadoop 33
- 34. 5. Results ● "Your receipt #" ● From: "" ● To: "@domain4.com" ● “LinkedIn Messages, /0/2010" ● From: "adjustsc5837@rodneymoore.com" ● To: "@domain0140.com" ● "" ● From: "LiliKepp5219@telemar.net.br" ● To: "@domain4.c" Thibault Debatty Parallel Spam Clustering with Apache Hadoop 34
- 35. 5. Results Visualization ● "eil rder #" ● From: "hilton_ns@datares.com.my" Thibault Debatty Parallel Spam Clustering with Apache Hadoop 35
- 36. Conclusion ● Hadoop allows faster clustering ● But: ● Limitations ● Lacks graphical performance analysis tool (MPI Jumpshot) ● Programmer needs to understand inner working! ● Lot of room for improvement: ● Memcached to store intermediate centers? ● MPI to intercept method calls between JVMs? ● Selection of initial centers (canopy?), stop criterion? ● Distance computation (WOWA) ● Clustering algorithm (online clustering) ● Influence of data locality and data size? Thibault Debatty Parallel Spam Clustering with Apache Hadoop 36
- 37. Questions ? Thibault Debatty Parallel Spam Clustering with Apache Hadoop 37