Presto: Distributed Machine Learning and Graph Processing with Sparse Matrices
Download as PPTX, PDF3 likes2,712 views

Presto is a large-scale array-based framework that extends R to enable distributed machine learning and graph processing on sparse matrices. It addresses challenges with sparse matrices through techniques like dynamic repartitioning to balance workloads, and allowing shared reading of data through zero-copy transfers while maintaining correctness. Evaluation shows Presto can process problems faster than Spark and Hadoop on in-memory datasets by leveraging these techniques.











![MadLINQ [EuroSys’12]
Linear algebra platform on Dryad
Not efficient for sparse matrix comp.](https://image.slidesharecdn.com/presto-130523031143-phpapp02/85/Presto-Distributed-Machine-Learning-and-Graph-Processing-with-Sparse-Matrices-12-320.jpg)
![Ricardo [SIGMOD’10]
But ends up inheriting the
inefficiencies of the MapReduce
interface
R Hadoop
aggregation-processing queries
aggregated data](https://image.slidesharecdn.com/presto-130523031143-phpapp02/85/Presto-Distributed-Machine-Learning-and-Graph-Processing-with-Sparse-Matrices-13-320.jpg)





























Presto: Distributed Machine Learning and Graph Processing with Sparse Matrices
- 1. Distributed Machine Learning and Graph Processing with Sparse Matrices Speaker: LIN Qian http://www.comp.nus.edu.sg/~linqian/
- 2. Big Data, Complex Algorithms PageRank (Dominant eigenvector) Recommendations (Matrix factorization) Anomaly detection (Top-K eigenvalues) User Importance (Vertex Centrality) Machine learning + Graph algorithms
- 3. Large-Scale Processing Frameworks Data-parallel frameworks – MapReduce/Dryad (2004) – Process each record in parallel – Use case: Computing sufficient statistics, analytics queries Graph-centric frameworks – Pregel/GraphLab (2010) – Process each vertex in parallel – Use case: Graphical models Array-based frameworks – MadLINQ (2012) – Process blocks of array in parallel – Use case: Linear Algebra Operations
- 4. PageRank using Matrices Power Method Dominant eigenvector Mp M = web graph matrix p = PageRank vector Simplified algorithm repeat { p = M*p } Linear Algebra Operations on Sparse Matrices p
- 5. Statistical software moderately-sized datasets single server, entirely in memory
- 6. Work-around for massive dataset Vertical scalability Sampling
- 7. MapReduce Limited to aggregation processing
- 8. Data analytics Deep vs. Scalable Statistical software (R, MATLAB, SPASS, SAS) MapReduce
- 9. Improvement ways 1. Statistical sw. += large-scale data mgnt 2. MapReduce += statistical functionality 3. Combining both existing technologies
- 11. HAMA, SciHadoop
- 12. MadLINQ [EuroSys’12] Linear algebra platform on Dryad Not efficient for sparse matrix comp.
- 13. Ricardo [SIGMOD’10] But ends up inheriting the inefficiencies of the MapReduce interface R Hadoop aggregation-processing queries aggregated data
- 14. Array-based Single-threaded Limited support for scaling
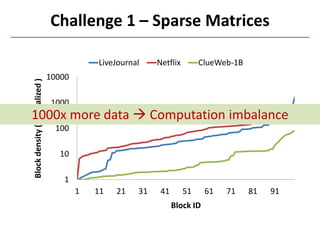
- 15. Challenge 1: Sparse Matrices
- 16. Challenge 1 – Sparse Matrices 1 10 100 1000 10000 1 11 21 31 41 51 61 71 81 91 Blockdensity(normalized) Block ID LiveJournal Netflix ClueWeb-1B 1000x more data Computation imbalance
- 17. Challenge 2 – Data Sharing Sharing data through pipes/network Time-inefficient (sending copies) Space-inefficient (extra copies) Process copy of data local copy Process data Process copy of data Process copy of data Server 1 network copy network copy Server 2 Sparse matrices Communication overhead
- 18. Extend R – make it scalable, distributed Large-scale machine learning and graph processing on sparse matrices
- 20. Presto architecture WorkerWorker Master R instanceR instance DRAM R instance R instanceR instance DRAM R instance
- 22. foreach Parallel execution of the loop body f (x ) Barrier Call Update to publish changes
- 23. PageRank Using Presto M darray(dim=c(N,N),blocks=(s,N)) P darray(dim=c(N,1),blocks=(s,1)) while(..){ foreach(i,1:len, calculate(m=splits(M,i), x=splits(P), p=splits(P,i)) { p m*x } )} Create Distributed Array M p P1 P2 PN/s
- 24. PageRank Using Presto M darray(dim=c(N,N),blocks=(s,N)) P darray(dim=c(N,1),blocks=(s,1)) while(..){ foreach(i,1:len, calculate(m=splits(M,i), x=splits(P), p=splits(P,i)) { p m*x } )} Execute function in a cluster Pass array partitions p P1 P2 PN/s M
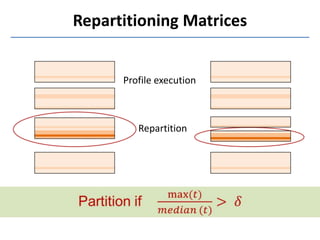
- 25. Dynamic repartitioning To address load imbalance Correctness
- 27. Invariants compatibility in array sizes
- 28. Maintaining Size Invariants invariant(mat, vec, type=ROW)
- 29. Data sharing for multi-core Zero-copy sharing across cores
- 30. Data sharing challenges 1. Garbage collection 2. Header conflict R object data part R object header R instance R instance
- 31. Overriding R’s allocator Allocate process-local headers Map data in shared memory page Shared R object data part Local R object header page boundary page boundary
- 32. Immutable partitions Safe sharing Only share read-only data
- 33. Versioning arrays To ensure correctness when arrays are shared across machines
- 34. Fault tolerance Master: primary-backup replication Worker: heartbeat-based failure detection
- 35. Presto applications Presto doubles LOC w.r.t. purely programming in R.
- 36. Evaluation Faster than Spark and Hadoop using in-memory data
- 39. Data sharing benefits 4.45 2.49 1.63 0.71 0.7 0.72 10 20 40 CORES 4.38 2.21 1.22 1.22 2.12 4.16 10 20 40 CORES Compute TransferNo sharing Sharing
- 40. Repartitioning benefits 0 20 40 60 80 100 120 140 160 Workers Transfer Compute 0 20 40 60 80 100 120 140 160 WorkersNo Repartition Repartition
- 41. Repartitioning benefits 0 50 100 150 200 250 300 350 400 2000 3000 4000 5000 6000 7000 8000 0 5 10 15 20 Cumulativepartitioningtime(s) Timetoconvergence(s) Number of Repartitions Convergence Time Time spent partitioning
- 42. Limitations 1. In-memory computation 2. One writer per partition 3. Array-based programming
- 43. • Presto: Large scale array-based framework extends R • Challenges with Sparse matrices • Repartitioning, sharing versioned arrays Conclusion
- 44. IMDb Rating: 8.5 Release Date: 27 June 2008 Director: Doug Sweetland Studio: Pixar Runtime: 5 min Brief: A stage magician’s rabbit gets into a magical onstage brawl against his neglectful guardian with two magic hats.
Editor's Notes
- #2: MapReduce excels in massively parallel processing, scalability, and fault tolerance.In terms of analytics, however, such systems have been limited primarily to aggregation processing, i.e., computation of simple aggregates such as SUM, COUNT, and AVERAGE, after using filtering, joining, and grouping operations to prepare the data for the aggregation step. Although most DMSs provide hooks for user-defined functions and procedures, they do not deliver the rich analytic functionality found in statistical packages.
- #3: Virtually all prior work attempts to get along with only one type of system, either adding large-scale data management capability to statistical packages or adding statistical functionality to DMSs. This approach leads to solutions that are often cumbersome, unfriendly to analysts, or wasteful in that a great deal of well established technology is needlessly re-invented or re-implemented.
- #4: Convert matrix operations to MapReduce functions.
- #5: R sending aggregation-processing queries to Hadoop (written in the high-level Jaql query language), and Hadoop sending aggregated data to R for advanced statistical processing or visualization.
- #6: R has serious limitations when applied to very large datasets: limited support for distributed processing, no strategy for load balancing, no fault tolerance, and is constrained by a server’s DRAM capacity.
- #8: Large-scale machine learning and graph processing on sparse matrices
- #9: Distributed array (darray) provides a shared, in-memory view of multi-dimensional data stored across multiple servers.
- #10: Repartitioning can be used to subdivide an array into a specified number of parts. Repartitioning is an optional performance optimization which helps when there is load imbalance in the system.
- #11: Note that for programs with general data structures (e.g., trees) writing invariants is difficult. However, for matrix computation, arrays are the only data structure and the relevant invariant is the compatibility in array sizes.
- #12: Qian’s comment: same concept as the snapshot isolation.