[PYCON Korea 2018] Python Application Server for Recommender System
8 likes2,116 views

(한글 fixed) 추천 시스템을 위한 어플리케이션 서버 개발 후기 @ PYCON Korea 2018 link: https://www.pycon.kr/2018/program/33






































![복잡한 필터링
빌트인 프로시져로 처리할 수 없는 필터링의 경우를 위해
룰에 파이썬 코드를 심고 런타임 컴파일을 사용
brunch/similar
{
“bucket_A”: {
“$filter”: “{"$match": {"$and": [{"is_black_user": {"$eq": 0}}, {"status": {"$eq": “normal”}}]}}”,
},
“bucket_B”: {
“@filter”: “lambda x: “,
}](https://image.slidesharecdn.com/20180818pyconapplicationserverforrecommendersystematkakaorev3-180820011512/85/PYCON-Korea-2018-Python-Application-Server-for-Recommender-System-45-320.jpg)












[PYCON Korea 2018] Python Application Server for Recommender System
- 1. 추천 시스템을 위한 어플리케이션 서버 개발 후기 김광섭
- 2. 김광섭 mrkwangsub@gmail.com C++/Python 개발자 Pattern Recognition 전공 추천 시스템 / 머신러닝에 관심있습니다
- 3. 추천 시스템
- 5. 음악 블로그 뉴스 영화
- 6. 추천 시스템은 복잡한 문제입니다. https://leankit.com/blog/2016/01/managing-complex-workflows-in-leankit/
- 7. 추천 시스템은 복잡한 문제입니다. 하지만, 우리가 해야할 일을 아주 간단히 축소하면, 다음 두가지 맥락으로 해석할 수 있습니다 https://leankit.com/blog/2016/01/managing-complex-workflows-in-leankit/
- 8. 아이템 추천 개인화 추천 아이템 개인 Thanks a lot to http://xkcd.com
- 9. 설계
- 10. 쿼리 유사도 정렬 메타데이터/선호도 조회 필터링 다이어트 바나나... 품절 사과혐오 아이템 추천 시나리오 어떤 게 적합할까? 여기서 원하는 게 뭘까?
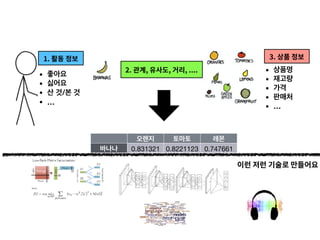
- 11. 2. 관계, 유사도, 거리, .... • 상품명 • 재고량 • 가격 • 판매처 • … 3. 상품 정보1. 활동 정보 • 좋아요 • 싫어요 • 산 것/본 것 • …
- 12. 이런 저런 기술로 만들어요 2. 관계, 유사도, 거리, .... 오렌지 토마토 레몬 바나나 0.831321 0.8221123 0.747661 • 상품명 • 재고량 • 가격 • 판매처 • … 3. 상품 정보1. 활동 정보 • 좋아요 • 싫어요 • 산 것/본 것 • …
- 13. 2. 관계, 유사도, 거리, .... 3. 상품 정보 1. 활동 정보 데이터베이스 데이터 수집 데이터 분석 어플리케이션 서버 장보기/과일추천 { type: “similar”, database: “장보기”, filter: {“kind”: “disliked”, “n”: 5}, where: {“status”: “okay”}, limit: 20 } 과일추천 Rule(Schema)
- 14. 이제 만들어 보자!
- 15. 이제 만들어 보자! vs 그냥 있는거 쓰면 안되요? (이런 사람 꼭 있다)
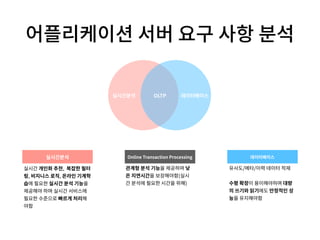
- 16. 유사도/메타/이력 데이터 적재 수평 확장이 용이해야하며 대량 의 쓰기와 읽기에도 안정적인 성 능을 유지해야함 실시간 개인화 추천, 복잡한 필터 링, 비지니스 로직, 온라인 기계학 습에 필요한 실시간 분석 기능을 제공해야 하며 실시간 서비스에 필요한 수준으로 빠르게 처리해 야함 실시간분석 데이터베이스 관계형 분석 기능을 제공하며 낮 은 지연시간을 보장해야함(실시 간 분석에 필요한 시간을 위해) OLTP 실시간분석 Online Transaction Processing 데이터베이스 어플리케이션 서버 요구 사항 분석
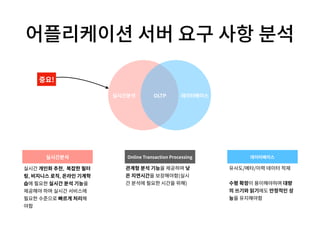
- 17. 유사도/메타/이력 데이터 적재 수평 확장이 용이해야하며 대량 의 쓰기와 읽기에도 안정적인 성 능을 유지해야함 실시간 개인화 추천, 복잡한 필터 링, 비지니스 로직, 온라인 기계학 습에 필요한 실시간 분석 기능을 제공해야 하며 실시간 서비스에 필요한 수준으로 빠르게 처리해 야함 실시간분석 데이터베이스 관계형 분석 기능을 제공하며 낮 은 지연시간을 보장해야함(실시 간 분석에 필요한 시간을 위해) OLTP 실시간분석 Online Transaction Processing 데이터베이스 어플리케이션 서버 요구 사항 분석 중요!
- 18. 실시간 개인화 추천, 복잡한 필터 링, 비지니스 로직, 온라인 기계학 습에 필요한 실시간 분석 기능을 제공해야 하며 실시간 서비스에 필요한 수준으로 빠르게 처리해 야함 실시간분석 실시간분석 어플리케이션 서버 요구 사항 분석 개인화 추천을 미리 계산하는 것은 매우 비효율적. 실시간 분석이 적합.
- 19. 벤치마킹 실시간분석 OLTP 데이터베이스 기타 실시간분석이 거의 제공 되지 않음 스케일 아웃이 쉽지 않음(확장성) 실시간분석이 거의 제공 되지 않음 OLTP성 작업에 제약이 있음 일부 실시간분석이 가능하지만 처리 속도가 느림 안정성이 충분히 검증되지 않음 일부 실시간분석을 만족할만한 시간 내에 처리 하지만 안정성이 낮음(버전 1.0이하 테스트) 실시간분석 기능을 가장 많이 제공하나, 여전히 불충분 하고, 유료임
- 20. 그냥 있는거 쓰면 안되요? 네. 1. 실시간분석 • “결과가 없으면 같은 카테고리내 다른 상품을 보여줬으면 좋겠어요.” • “본 거는 빼주세요. 그런데 3번 정도 봐야 빠졌으면 좋겠어요.” • 대용량 개인화 추천, 온라인 기계학습 2. 속도/성능 • 데이터베이스 작업을 단순화하고, 복잡한 로직을 더 효과적으로 구현하자. (혹은 써드파티 라이브러리의 활용) 3. 확장성/안정성 • 대용량 데이터베이스의 특성과 실시간 분석 두가지를 하나의 플랫폼으로 만족시키기 어렵다. 4. 완결성 • API를 사용하는 입장에서 추가 작업 없이 바로 사용 가능하도록 하자.
- 21. 이제 만들어 보자! 실시간분석 데이터베이스OLTP 실시간분석과 OLTP 연산을 처리하는 것에 집중하고 데이터베이스는 외부 솔루션에 의존 만드려는 것은 여기에 집중
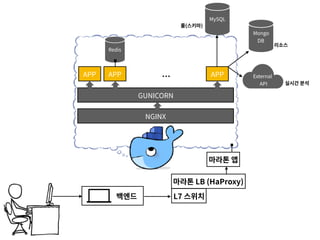
- 22. L7 스위치백엔드 마라톤 LB (HaProxy) 마라톤 앱 NGINX GUNICORN APP APP Redis Mongo DB External API APP MySQL 룰(스키마) 리소스 실시간 분석
- 23. APP MySQL 정의된 룰(스키마) 로드 brunch/similar { “bucket_A”: { }, “bucket_B”: { } } brunch/similar (200 OK) dinner/similar (404) Mongo DB External API Redis
- 24. 개발 후기 만들면서 겪었던 문제들
- 25. • python2 vs python3: tornado vs sanic • asyncio.Future • 데이터베이스 프로파일링 • 꼼꼼한 캐싱 • 복잡한 필터링 • 설정 배포 • 퍼포먼스
- 27. python2 v.s. python3 v.s. Flask-like Python 3.5+ web server
- 28. 서비스에 사용중이던 파이썬2 + 토네이도 기반의 비슷한 구현체가 있었습니다 가능하면 재활용을 하고 싶었지만, 몇가지 장점으로 파이썬3 + Sanic 조합으로 변경했습니다 python2 v.s. python3
- 29. 코드 가독성 증가 및 LOC 감소 Sanic의 문법이 tornado보다 간결하기도 하지만 파이썬3와 써드 파티 라이브러리 전반적으로 코드 사용이 더 쉬웠습니다 python2 v.s. python3
- 30. 성능 uvloop 덕택인지 tornado 구현체 대비해 동일 환경에서 약 2.1배 가량 빠른 응답 속도를 보였습니다 https://magic.io/blog/uvloop-blazing-fast-python-networking/ python2 v.s. python3
- 31. asyncio.Future
- 33. asyncio.Future VS RUN/WAIT RUN/WAIT RUN RUN/WAIT WAIT 네트워크 I/O 대기를 최소화해서 CPU를 최대한 뽑아먹자
- 34. 데이터베이스 프로파일링
- 35. 코드를 최적화 하다 보니 결국에는 쿼리를 처리하는데 소요되는 대 부분의 시간은 데이터베이스 조회에(혹은 다른 RPC) 사용됐습니다 데이터베이스는 MongoDB를 사용했습니다 sanic-motor를 사용 하면 쉽게 비동기 호출 방식으로 사용할 수 있습니다 고민이 되는 지점은 데이터베이스의 기능을 어디까지 사용할지 입 니다 데이터베이스 프로파일링 ELSE 32% DB 68% ELSE 1% DB 99% Rule A Rule B
- 36. 데이터베이스 프로파일링 품절 APP Mongo DB 품절 APP Mongo DB MongoDB에 aggregate라는 기능으로 여러 연산을 중복해서 실행 할 수 있습니다. 그 중에 $filter 연산은 사용하는 것이 더 좋았습니다. 앱서버 CPU 사용량 감소 데이터 전송량 감소 데이터베이스 부하는 비슷
- 37. 데이터베이스 프로파일링 Mongo DB Mongo DB 반면 $group는 어플리케이션 서버에서 처리하는 것이 수배 빨랐습 니다. 3개 3개 3개 3개 APP APP
- 38. 데이터베이스 프로파일링 데이터베이스에서 제공하는 기능을 그대로 사용할지 어플리케이션 서버에서 구현할지 테스트 해보자!
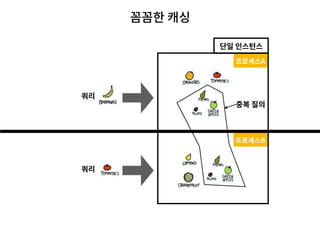
- 39. 꼼꼼한 캐싱
- 40. 꼼꼼한 캐싱 데이터베이스 조회 비용이 비싸기 때문에 최대한 캐싱을 꼼꼼히 할 필요가 있습니다 인스턴스내 여러 프로세스로 앱 프로세스가 생성되기 때문에 프로 세스간 중복되는 연산을 줄이기 위해 임베디드 캐시 대신 Redis를 사용했습니다 APP Redis APPAPP
- 42. 꼼꼼한 캐싱 슈퍼 노드를 해결을 위해서도 인스턴스 내의 캐시는 필요했습니다 Mongo DB Shard1 Shard2 ShardN 적절한 키로 샤드를 구성하더라도 공통되어 사용되는 리소스가 존재하는 경우 특정 샤드에 부하가 집중됩니다 핫 포도
- 43. 복잡한 필터링
- 44. 복잡한 필터링 바나나 싫다 바나나 싫다 제거하기 뒤로 밀어내기 최근에 봤거나, 결과 수를 일정하게 유지 하기 위해서는 커스텀 필터 구현
- 45. 복잡한 필터링 빌트인 프로시져로 처리할 수 없는 필터링의 경우를 위해 룰에 파이썬 코드를 심고 런타임 컴파일을 사용 brunch/similar { “bucket_A”: { “$filter”: “{"$match": {"$and": [{"is_black_user": {"$eq": 0}}, {"status": {"$eq": “normal”}}]}}”, }, “bucket_B”: { “@filter”: “lambda x: “, }
- 46. 설정 배포
- 47. 설정 배포 마라톤 앱 NGINX GUNICORN APP APP Redis External API APP MySQL 룰(스키마) brunch/similar { “bucket_A”: { }, “bucket_B”: { } }
- 48. 설정 배포 마라톤 앱 NGINX GUNICORN APP APP Redis External API APP MySQL 룰(스키마) brunch/similar { “bucket_A”: { } } 테스트를 포함해 룰을 바꾸는 일은 잦음
- 49. 설정 배포 마라톤 앱 NGINX GUNICORN APP APP Redis External API APP MySQL 룰(스키마) 순차적 재시작 이럴 경우 요청이 유실 될 수 있습니다.
- 50. 설정 배포 마라톤 앱 NGINX GUNICORN APP APP Redis External API APP MySQL 룰(스키마) KILL SIGTERM 안전하게 앱을 재시작 할 수 있습니다.
- 51. 설정 배포 마라톤 앱 NGINX GUNICORN APP APP Redis External API APP MySQL 룰(스키마) KILL SIGTERM 안전하게 앱을 재시작 할 수 있습니다.
- 52. 퍼포먼스
- 53. 퍼포먼스 API API 요청 350M+ 평균 응답 속도 17ms 100ms 이하 응답 비율 99.7% / day 데이터베이스 INSERT 1B+ UPDATE 1.5B+ SELECT 1.2B+ / day 인스턴스(1Thread) 294.98 TPS 20 가상 유저, 60초 버스트 평균 전송 데이터 43KB linear scalability
- 54. 그 밖의 코멘트
- 55. 파이썬으로 그런거 만드는 거 아니에요 (그만 좀 들었으면... 실제로 이런 경우가 적지 않습니다) 실시간 어플리케이션 서버의 병목 대부분 네트워크 IO (왜 우리 파이썬한태 그래요!!?!) CPU 연산의 경우 수치 연산에 최적화된 라이브러리를 잘 활용하자 (그래도 느리다면 내 코드가 문ㅈ...)
- 56. FAQ
- 57. kakao > 추천팀 영입 공고 • 추천 시스템 연구/개발: https://careers.kakao.com/jobs/P-9883 • 추천 시스템 소프트웨어 엔지니어: https://careers.kakao.com/jobs/P-10200