[PythonPH] Transforming the call center with Text mining and Deep learning (Case study@Uber)
3 likes394 views

The document outlines a presentation by Paul Lo, a data analytics manager at Uber, on utilizing text mining and deep learning to enhance user experience in call centers. It discusses two main projects: a text mining tool to unlock user insights through natural language processing and a deep learning-based assistant for customer service representatives to improve operational efficiency. The presentation emphasizes the importance of data analysis and machine learning in addressing user feedback and optimizing support processes across the Asia-Pacific region.























![Speed up data processing
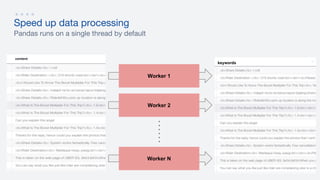
Pandas runs on a single thread by default
A pandas DataFrame with 50k+ rows
Data Preparation
text_processing() is a heavy function
contains many things:
● Tokenization
● Removal of numbers, html tags, and
other invalid words
● Stemming and lemmatization
● TFIDF
df['content'].apply(text_processing)
→ single thread by default](https://image.slidesharecdn.com/pythonphtransformingthecallcenterwithtextmininganddeeplearningcasestudyuber-180929062748/85/PythonPH-Transforming-the-call-center-with-Text-mining-and-Deep-learning-Case-study-Uber-30-320.jpg)



























![Python tips: be cautious about the underlying “copy implementation”
np.random.shuffle
What’s the value of
my_list2?
A. [1, 2, 3, 4, 5]
B. [2, 5, 1, 4, 3]](https://image.slidesharecdn.com/pythonphtransformingthecallcenterwithtextmininganddeeplearningcasestudyuber-180929062748/85/PythonPH-Transforming-the-call-center-with-Text-mining-and-Deep-learning-Case-study-Uber-63-320.jpg)
![np.random.shuffle
What’s the value of
my_list2?
A. [1, 2, 3, 4, 5]
B. [2, 5, 1, 4, 3]
Python tips: be cautious about the underlying “copy implementation”](https://image.slidesharecdn.com/pythonphtransformingthecallcenterwithtextmininganddeeplearningcasestudyuber-180929062748/85/PythonPH-Transforming-the-call-center-with-Text-mining-and-Deep-learning-Case-study-Uber-64-320.jpg)







[PythonPH] Transforming the call center with Text mining and Deep learning (Case study@Uber)
- 1. Paul Lo Data Analytics Manager @ Uber, Asia-Pacific Community Operation Central team paullo0106@gmail.com | paul.lo@uber.com | http://paullo.myvnc.com/blog/ Transforming the Call Center with Text Mining and Deep Learning for Better User Experience PythonPH Sep. 2018 (https://www.meetup.com/pythonph/events/254444065/)
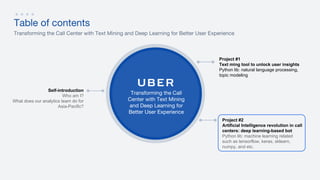
- 2. Project #1 Text ming tool to unlock user insights Python lib: natural language processing, topic modeling Self-introduction Who am I? What does our analytics team do for Asia-Pacific? Project #2 Artificial Intelligence revolution in call centers: deep learning-based bot Python lib: machine learning related such as tensorflow, keras, sklearn, numpy, and etc. Transforming the Call Center with Text Mining and Deep Learning for Better User Experience Table of contents Transforming the Call Center with Text Mining and Deep Learning for Better User Experience
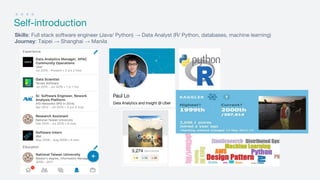
- 3. Self-introduction Skills: Full stack software engineer (Java/ Python) → Data Analyst (R/ Python, databases, machine learning) Journey: Taipei → Shanghai → Manila
- 4. Self-introduction Uber Shanghai → Uber Manila (APAC Community Operation Central Analytics team)
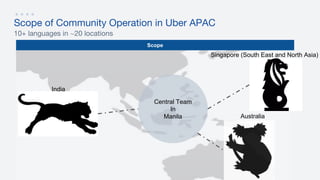
- 5. Scope of Community Operation in Uber APAC Scope 10+ languages in ~20 locations Central Team In Manila India Singapore (South East and North Asia) Australia
- 6. APAC A&I 2017 Year-end Analytics & Insights is the team responsible for building the analyses, models, and tools to aid operational and strategic decision making for the APAC Region. We are also dedicated to furthering Uber’s collective analytical capability.
- 7. Self-introduction Uber still has awesome team (Analytics, S&P, PM, and etc) based in Manila!!
- 8. Improving user experience is one of our core mission Improve user experience Drive down defect rate Optimize operational efficiency Manage the cost of business operation
- 9. Project #1: Text mining and NLP for use experience enhancement Acknowledgement: Troy James Palanca, Lorenzo Ampil
- 10. Value proposition Speed up the workflow on user experience enhancement Defect rate and issue type Leaderboard Community Operation Product, Engineering, and etc. User feedback database Root cause analysis and recommended feature or policy changes Review customer feedback in tickets User experience enhancement
- 11. Value proposition Speed up the workflow on user experience enhancement Defect rate and issue type Leaderboard Community Operation Product, Engineering, and etc. User feedback database Root cause analysis and recommended feature or policy changes Review customer feedback in tickets User experience enhancement Making this process more efficient
- 12. Issue type dashboard as a high-level data source Mockup Dashboard
- 13. Problem How can we quickly get the insights from users’ feedback? Problem Reviewing tickets manually to diagnose the root cause is not scalable and unsystematic Ticket dataset Driver > Trips > Fare … > … > Technical issue ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket ticket
- 14. Problem How can we quickly get the insights from users’ feedback? Solution Use topic modeling techniques to efficiently group tickets and assign them to reasonably named topics. Ticket dataset Driver > Trips > Fare … > … > Technical issue App stuck/ crash (35%) Fare calculation Dispute (15%) GPS issue (55%)
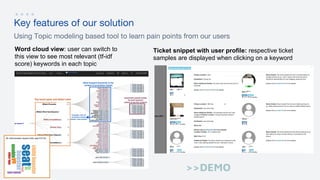
- 15. Key features of our solution Using Topic modeling based tool to learn pain points from our users Ticket snippet with user profile: respective ticket samples are displayed when clicking on a keyword Word cloud view: user can switch to this view to see most relevant (tf-idf score) keywords in each topic >>DEMO
- 16. Sample results “Fare Disputes” in one of the city we operate are mainly about payments, airport issues, and wrong riders: ● Credit cards and other modes of payment (18%) ● Overcharging (28.8%) ● Wrong profiles being billed (12.8%) ● Airport terminal issues (12.9%) ● Someone else taking the trip (12.5%)
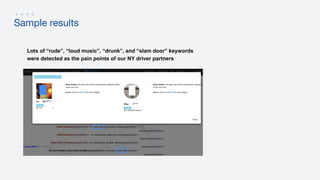
- 17. Sample results Lots of “rude”, “loud music”, “drunk”, and “slam door” keywords were detected as the pain points of our NY driver partners
- 18. Sample results More than 10% of driver cancellation tickets in Singapore are related to car seat rules for child safety: many sample tickets show that drivers want to reimburse their cancellation fee due to their riders bringing children without prior notice.
- 19. Tool architecture Computing node (any Uber servers) Data collection Data preparation LDA model training Web server (AWS node) Html and json files from training results User Interface (d3js) Train the model for each country with top issues monthly Web 1.0 design with the focus on computing node
- 20. Workflow overview Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category
- 21. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Text processing library: nltk, BeautifulSoup, re, TextBlob LDA library: gensim.ldamodel.LdaModel and pyLDAvis
- 22. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Remove invalid words: ● Numbers ● Html tags ● Custom dictionary Stemming and lemmatization Tokenization TFIDF (Term Frequency Inverse Document Frequency)
- 23. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Remove invalid words: ● Numbers re.sub(r'd+', '', text) ● Html tags BeautifulSoup(document).get_text() BeautifulSoup(document).find_all(‘b’) ● Custom dictionary Stemming and lemmatization Tokenization TFIDF (Term Frequency Inverse Document Frequency)
- 24. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Remove invalid words Stemming and lemmatization: Reduce inflectional forms and sometimes derivationally related forms of a word to a common base form. For instance: ○ cancel, cancels, cancelled -> cancel ○ riders, rider -> rider Tokenization TFIDF (Term Frequency Inverse Document Frequency)
- 25. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Remove invalid words Stemming and lemmatization Tokenization: Part-of-speech based word detection TFIDF (Term Frequency Inverse Document Frequency)
- 26. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content Sample ~50,000 tickets for each training in each issue category Remove invalid words Stemming and lemmatization Tokenization: Part-of-speech based word detection TFIDF (Term Frequency Inverse Document Frequency) Common practice to score each term with weighted frequency and relevance
- 27. Data Preparation (Natural Language Processing) Using TFIDF to filter the most important keywords Machine Learning Model
- 28. Data Preparation (Natural Language Processing) Using TFIDF to filter the most important keywords Machine Learning Model Term frequency Inverse Document Frequency
- 29. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Data preparation for text processing can be very time-consuming Sample ~50,000 tickets for each training in each issue category Remove invalid words: Stemming and lemmatization Tokenization TFIDF (Term Frequency Inverse Document Frequency)
- 30. Speed up data processing Pandas runs on a single thread by default A pandas DataFrame with 50k+ rows Data Preparation text_processing() is a heavy function contains many things: ● Tokenization ● Removal of numbers, html tags, and other invalid words ● Stemming and lemmatization ● TFIDF df['content'].apply(text_processing) → single thread by default
- 31. Speed up data processing Pandas runs on a single thread by default Worker 1 Worker 2 Worker N keywords
- 32. Data processing speedup trick in Pandas Pandas runs on a single thread by default 1 2 3 4 5 6 7 8 9 10
- 33. Many handy text processing libraries TextBlob and spaCy Tokenization Sentence correction .correct() Part of speech .tags Sentiment analysis .sentiment.polarity NLP Library (TextBlob) (spaCy)
- 34. Workflow overview Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Unlocking support insights from textual content - but how? Sample ~50,000 tickets for each training in each issue category LDA: - Unsupervised learning - Bag of words - “topic distribution” Usage: lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, random_state=some_number) lda.show_topics()
- 35. Latent Dirichlet Allocation model General concept of this model Unsupervised learning method - does not require any class labels; similar to clustering ‘Bag of words’ model - uses word counts in messages without regard for its order (Peter owe Alice money = Alice owe Peter money) Estimated iteratively - Starts with random initialization then adjusts probabilities to reduce perplexity / increase fit Doc 1 Doc 2 Doc 3 Doc n... (topic) FruitsFruits document-topic probabilities 30% health (topic 1) 60% fruits (topic 2) 10% disease (topic 3)
- 36. Latent Dirichlet Allocation model Model implementation and visualization Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Data input: ticket text as raw data Output: topic model clusters Sample ~50,000 tickets for each training in each issue category Usage: lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, random_state=some_number) lda.show_topics() from pyLDAvis.gensim import prepare, save_html from gensim.models import LdaModel
- 37. Future work and learnings Data Preparation (text processing) Extract useful information and transform corpus to a sparse matrix Data Modeling (Latent Dirichlet Allocation) Main computation to perform topic modeling Customization is needed ● Not suited for specific issue category ● Build own dictionary for the removal of irrelevant words Data input: ticket text as raw data Output: topic model clusters How to make the results more “actionable”? ● # of topic for convergence ● Time and performance tradeoff ● Other ”Deep NLP” model ? Bad result examples
- 38. Project #1 Text ming tool to unlock user insights Python lib: natural language processing, topic modeling Self-introduction Who am I? What does our analytics team do for Asia-Pacific? Project #2 Artificial Intelligence revolution in call centers: deep learning-based bot Python lib: machine learning related such as tensorflow, keras, sklearn, numpy, and etc. Transforming the Call Center with Text Mining and Deep Learning for Better User Experience Table of contents Transforming the Call Center with Text Mining and Deep Learning for Better User Experience
- 39. Product owner: Huaixiu Zheng and Yichia Wang in Uber’s Applied Machine Learning team Project #2: Artificial Intelligence revolution in call centers
- 40. CSR’s sample workflow for user in a call center How does our users submit an issue?
- 41. CSR’s sample workflow for user in a call center Online support via in-app-help User CSRContact Ticket Response Select Issue Category Write Message Confirm Issue Category Lookup info. & Knowledge Base Select Action Write response using a Reply Template
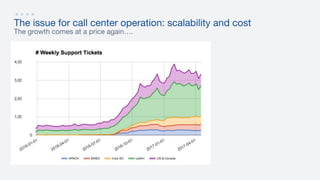
- 42. The issue for call center operation: scalability and cost The growth comes at a price again….
- 43. Solution? Let’s start from a basic sample “I want to change my rating for a rider”
- 44. API-less solution to the basic sample We can ‘program’ the pre-defined logic for certain tickets with Selenium or Chrome Script element mapping element mapping
- 45. End-to-end solution Web interaction Read and Write (click and input text) Knowledge base ● Keyword recognition ● Web element id dictionary ● (Natural Language Processing) Policy engine Program the flow aligning with policy/ SOP Monitoring and logging ● Real-time gsheet API logging ● Monitoring and alert trigger Ticket answering bot
- 46. The business impact of a simple bot-solving solution 3k+ weekly solves A team of 18 CSR 28k USD monthly
- 47. What’s the problem with this solution?
- 48. What’s the problem with this solution? “Scalability”
- 49. The difference between Programming and Machine Learning Outputs = Agents’ responses Inputs = Contact Ticket
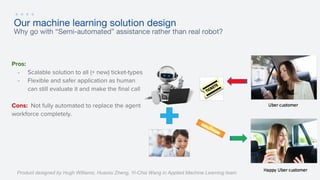
- 50. Our machine learning solution design Why go with “Semi-automated” assistance rather than real robot? Pros: - Scalable solution to all (+ new) ticket-types - Flexible and safer application as human can still evaluate it and make the final call Cons: Not fully automated to replace the agent workforce completely. Product designed by Hugh Williams, Huaixiu Zheng, Yi-Chia Wang in Applied Machine Learning team
- 51. Our machine learning solution design ‘Assistant to CSR’ - Provide suggestions for reply and actions Issue category suggestion Action suggestion 10M+ tickets Correct response from agents to these 10M+ tickets Technical model training Product design
- 52. Typical Machine Learning process Note: picture from “Mark Peng’s “General Tips for participating Kaggle Competitions” on Slideshare
- 53. Typical Machine Learning process Model selection ML 101: Start with simple model first Data source: https://eng.uber.com/cota-v2/
- 54. Deep Learning Architecture Reference: Uber AML Lab: http://eng.uber.com/cota Sample code with Keras for a simple CNN
- 55. Deep Learning Architecture Reference: Uber AML Lab: http://eng.uber.com/cota Essay: COTA: Improving the Speed and Accuracy of Customer Support through Ranking and Deep Networks
- 56. Development environment for Deep learning model training How does model training look like? >> DEMO Main codebase + data set
- 57. Feature engineering and feature importance Trade off between capacity and interpretability “Capacity” “Interpretability”
- 58. Feature engineering and feature importance What are the important features? Very easy to learn that in simpler model
- 59. Feature engineering and feature importance What are the important features? Very easy to get explanation in simpler models
- 60. Feature engineering and feature importance What are the important features? NN model is like our brain’s intuition … blackbox
- 61. Feature engineering and feature importance What are the important features? Sklearn: Recursive feature elimination (sklearn.feature_selection.RFE) Mockup dataset
- 62. Feature engineering and feature importance What are the important features? Time on model training >>> prediction Shuffle each feature to create noise…. on the testing set Mockup dataset
- 63. Python tips: be cautious about the underlying “copy implementation” np.random.shuffle What’s the value of my_list2? A. [1, 2, 3, 4, 5] B. [2, 5, 1, 4, 3]
- 64. np.random.shuffle What’s the value of my_list2? A. [1, 2, 3, 4, 5] B. [2, 5, 1, 4, 3] Python tips: be cautious about the underlying “copy implementation”
- 65. np.random.permutation Python tips: be cautious about the underlying “copy implementation”
- 66. np.random.permutation from copy import deepcopy mylist2 = deepcopy(my_list) Python tips: be cautious about the underlying “copy implementation”
- 67. Feature engineering and feature importance What are the important features? Shuffle each feature to create noise…. on the testing set Mockup example
- 68. Issue category suggestion Action suggestion Product design Last stop: making business Impact Ensure KPI measurement is well-planned in the beginning User CSRContact Ticket Response Select Issue Category Write Message Confirm Issue Category Lookup info. & Knowledge Base Select Action Write response using a Reply Template
- 69. Last stop: making business Impact Identify key business metrics, and cautiously conduct and monitor A/A and A/B testing Source: https://eng.uber.com/cota-v2/
- 70. Look forward to collaborating! http://careers.uber.com
- 71. Paul Lo Data Analytics Manager @ Uber paul.lo@uber.com | paullo0106@gmail.com | | http://paullo.myvnc.com/blog/ Q&A