






























![pred= predict(output.forest, readingSkills)
library(e1071)
library(caret)
# Create Confusion Matrix
confusionMatrix(data=pred, reference=readingSkills$nativeSpeaker, positive='yes')
Confusion Matrix and Statistics
Reference
Prediction no yes
no 100 0
yes 0 100
Accuracy : 1
95% CI : (0.9817, 1)
No Information Rate : 0.5
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 1
Mcnemar's Test P-Value : NA
Sensitivity : 1.0
Specificity : 1.0
Pos Pred Value : 1.0
Neg Pred Value : 1.0
Prevalence : 0.5
Detection Rate : 0.5
Detection Prevalence : 0.5
Balanced Accuracy : 1.0
'Positive' Class : yes 33](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-33-320.jpg)


![We are going to use variable ′medv′ as the Response variable, which is
the Median Housing Value. We will fit 500 Trees.
dim(Boston)
[1] 506 14
#training Sample with 300 observations
train=sample(1:nrow(Boston),300)
• Fitting the Random Forest
We will use all the Predictors in the dataset.
Boston.rf=randomForest(medv ~ . , data = Boston , subset = train)
Boston.rf
Number of trees: 500
No. of variables tried at each split: 4
Mean of squared residuals: 12.07361
% Var explained: 85.91
36](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-36-320.jpg)

![• Now we can compare the Out of Bag Sample Errors and Error on Test set
• The above Random Forest model chose Randomly 4 variables to be considered at each split. We
could now try all possible 13 predictors which can be found at each split.
oob.err=double(13)
test.err=double(13)
#mtry is no of Variables randomly chosen at each split
for(mtry in 1:13)
{ rf=randomForest(medv ~ . , data = Boston , subset =
train,mtry=mtry,ntree=400)
oob.err[mtry] = rf$mse[400] #Error of all Trees fitted
pred<-predict(rf,Boston[-train,]) #Predictions on Test Set for each
Tree
test.err[mtry]= with(Boston[-train,], mean( (medv - pred)^2)) #Mean
Squared Test Error
cat(mtry," ") #printing the output to the console }
38](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-38-320.jpg)
![> test.err
[1] 20.89175 14.95446 13.03060 12.78799 12.03247 11.73759 11.50418 11.59229
[9] 12.23918 11.89928 11.91245 12.36971 12.41598
> oob.err # Out of Bag Error Estimation
[1] 21.17376 13.68955 12.59845 11.83516 11.72935 11.07857 11.77836 11.61401
[9] 12.39642 12.78779 12.10131 12.82391 12.44966
• What happens is that we are growing 400 trees for 13 times i.e for all 13
predictors.
• Plotting both Test Error and Out of Bag Error
matplot(1:mtry , cbind(oob.err,test.err), pch=19 ,
col=c("red","blue"),type="b",ylab="Mean Squared Error",xlab="Number of Predictors
Considered at each Split")
legend("topright",legend=c("Out of Bag Error","Test Error"),pch=19,
col=c("red","blue"))
39](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-39-320.jpg)

![Parameter Tuning with an Algorithm
> bestmtry <- tuneRF(Boston[,-13], Boston[,13],
stepFactor=1.5, improve=1e-5, ntree=500)
mtry = 4 OOB error = 10.15204
Searching left ...
mtry = 3 OOB error = 10.58809
-0.04295218 1e-05
Searching right ...
mtry = 6 OOB error = 10.47271
-0.0315876 1e-05
> print(bestmtry)
mtry OOBError
3 3 10.58809
4 4 10.15204
6 6 10.47271
41](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-41-320.jpg)

![Boston.lm=lm(medv ~ . , data = Boston)
summary(Boston.lm)
error <- Boston.lm$residuals
lm_error <- mean(error^2)
lm_error
[1] 21.89483
43](https://image.slidesharecdn.com/randomforests-240713121440-8f53d211/85/RANDOM-FORESTS-Ensemble-technique-Introduction-43-320.jpg)
RANDOM FORESTS Ensemble technique Introduction
- 2. Ensemble methods • A single decision tree does not perform well • But, it is super fast • What if we learn multiple trees? • We need to make sure they do not all just learn the same 2
- 3. Bagging • If we split the data in random different ways, decision trees give different results, high variance. • Bagging: Bootstrap aggregating is a method that result in low variance. • If we had multiple realizations of the data (or multiple samples), we could calculate the predictions multiple times and take the average of the fact that averaging multiple onerous estimations produce less uncertain results 3
- 5. Bootstrap • Construct B (hundreds) of trees (no pruning) • Learn a classifier for each bootstrap sample and average them • Very effective 5
- 6. Bagging for classification: Majority vote 6
- 8. Out‐of‐Bag Error Estimation • No cross validation? • Remember, in bootstrapping we sample with replacement, and therefore not all observations are used for each bootstrap sample. On average 1/3 of them are not used! • We call them out‐of‐bag samples (OOB) • We can predict the response for the i-th observation using each of the trees in which that observation was OOB and do this for n observations • Calculate overall OOB MSE or classification error 8
- 9. Bagging • Reduces overfitting (variance) • Normally uses one type of classifier • Decision trees are popular • Easy to parallelize 9
- 10. Variable Importance Measures • Bagging results in improved accuracy over prediction using a single tree • Unfortunately, difficult to interpret the resulting model. Bagging improves prediction accuracy at the expense of interpretability. • Calculate the total amount that the RSS or Gini index is decreased due to splits over a given predictor, averaged over all B trees. 10
- 11. Bagging • Each tree is identically distributed (i.d.) the expectation of the average of B such trees is the same as the expectation of any one of them the bias of bagged trees is the same as that of the individual trees • i.d. and not i.i.d 11
- 12. Bagging 12
- 13. Why does bagging generate correlated trees? • Suppose that there is one very strong predictor in the data set, along with a number of other moderately strong predictors. • Then all bagged trees will select the strong predictor at the top of the tree and therefore all trees will look similar. • How do we avoid this? • What if we consider only a subset of the predictors at each split? • We will still get correlated trees unless …. we randomly select the subset ! 13
- 14. Random Forest, Ensemble Model • The random forest (Breiman, 2001) is an ensemble approach that can also be thought of as a form of nearest neighbor predictor. • Ensembles are a divide-and-conquer approach used to improve performance. The main principle behind ensemble methods is that a group of “weak learners” can come together to form a “strong learner”. 14
- 15. Trees and Forests • The random forest starts with a standard machine learning technique called a “decision tree” which, in ensemble terms, corresponds to our weak learner. In a decision tree, an input is entered at the top and as it traverses down the tree the data gets bucketed into smaller and smaller sets. 15
- 16. Random Forest • As in bagging, we build a number of decision trees on bootstrapped training samples each time a split in a tree is considered, a random sample of m predictors is chosen as split candidates from the full set of p predictors. • Note that if m = p, then this is bagging. 16
- 17. Trees and Forests • In this example, the tree advises us, based upon weather conditions, whether to play ball. For example, if the outlook is sunny and the humidity is less than or equal to 70, then it’s probably OK to play. 17
- 18. Trees and Forests • The random forest takes this notion to the next level by combining trees with the notion of an ensemble. Thus, in ensemble terms, the trees are weak learners and the random forest is a strong learner. 18
- 19. Random Forest Algorithm • For b = 1 to B: (a) Draw a bootstrap sample Z∗ of size N from the training data. (b) Grow a random-forest tree to the bootstrapped data, by recursively repeating the following steps for each terminal node of the tree, until the minimum node size nmin is reached. i. Select m variables at random from the p variables. ii. Pick the best variable/split-point among the m. iii. Split the node into two daughter nodes. Output the ensemble of trees. 19
- 20. Random Forest Algorithm • To make a prediction at a new point x we do: For regression: average the results For classification: majority vote 20
- 21. 21
- 22. Training the algorithm • For some number of trees T: • Sample N cases at random with replacement to create a subset of the data. The subset should be about 66% of the total set. • At each node: • For some number m (see below), m predictor variables are selected at random from all the predictor variables. • The predictor variable that provides the best split, according to some objective function, is used to do a binary split on that node. • At the next node, choose another m variables at random from all predictor variables and do the same. • Depending upon the value of m, there are three slightly different systems: • Random splitter selection: m =1 • Breiman’s bagger: m = total number of predictor variables • Random forest: m << number of predictor variables. Breiman suggests three possible values for m: ½√m, √m, and 2√m 22
- 23. Running a Random Forest • When a new input is entered into the system, it is run down all of the trees. The result may either be an average or weighted average of all of the terminal nodes that are reached, or, in the case of categorical variables, a voting majority. Note that: • With a large number of predictors, the eligible predictor set will be quite different from node to node. • The greater the inter-tree correlation, the greater the random forest error rate, so one pressure on the model is to have the trees as uncorrelated as possible. • As m goes down, both inter-tree correlation and the strength of individual trees go down. So some optimal value of m must be discovered. 23
- 24. Differences to standard tree • Train each tree on Bootstrap Resample of data (Bootstrap resample of data set with N samples: Make new data set by drawing with Replacement N samples; i.e., some samples will probably occur multiple times in new data set) • For each split, consider only m randomly selected variables • Don’t prune • Fit B trees in such a way and use average or majority voting to aggregate results 24
- 25. Random Forests Tuning • The inventors make the following recommendations: For classification, the default value for m is √p and the minimum node size is one. For regression, the default value for m is p/3 and the minimum node size is five. • In practice the best values for these parameters will depend on the problem, and they should be treated as tuning parameters. • Like with Bagging, we can use OOB and therefore RF can be fit in one sequence, with cross-validation being performed along the way. Once the OOB error stabilizes, the training can be terminated. 25
- 26. Why Random Forests works: 26
- 27. Advantages of Random Forest • No need for pruning trees • Accuracy and variable importance generated automatically • Overfitting is not a problem • Not very sensitive to outliers in training data • Easy to set parameters • Good performance 27
- 28. Example • 4,718 genes measured on tissue samples from 349 patients. • Each gene has different expression • Each of the patient samples has a qualitative label with 15 different levels: either normal or 1 of 14 different types of cancer. • Use random forests to predict cancer type based on the 500 genes that have the largest variance in the training set. 28
- 29. 29
- 30. R Example • We will use the R in-built data set named readingSkills to create a decision tree. It describes the score of someone's readingSkills if we know the variables "age","shoesize","score" and whether the person is a native speaker. • Here is the sample data. > library(randomForest) randomForest 4.6-14 Type rfNews() to see new features/changes/bug fixes. > # Print some records from data set readingSkills. > print(head(readingSkills)) nativeSpeaker age shoeSize score 1 yes 5 24.83189 32.29385 2 yes 6 25.95238 36.63105 3 no 11 30.42170 49.60593 4 yes 7 28.66450 40.28456 5 yes 11 31.88207 55.46085 6 yes 10 30.07843 52.83124 30
- 31. # Create the forest. output.forest <- randomForest(nativeSpeaker ~ age + shoeSize + score, data = readingSkills) # View the forest results. print(output.forest) Number of trees: 500 No. of variables tried at each split: 1 OOB estimate of error rate: 1% Confusion matrix: no yes class.error no 99 1 0.01 yes 1 99 0.01 31
- 32. # Importance of each predictor. print(importance(output.forest,type = 2)) MeanDecreaseGini age 14.13397 shoeSize 18.48703 score 57.52747 plot(output.forest, type="l") varImpPlot(output.forest) • Gini Impurity measures how often a randomly chosen record from the data set used to train the model will be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset. Gini Impurity reaches zero when all records in a group fall into a single category. This measure is essentially the probability of a new record being incorrectly classified at a given node in a Decision Tree, based on the training data. • Because Random Forests are an ensemble of individual Decision Trees, Gini Importance can be leveraged to calculate Mean Decrease in Gini, which is a measure of variable importance for estimating a target variable. • Mean Decrease in Gini is the average of a variable’s total decrease in node impurity, weighted by the proportion of samples reaching that node in each individual decision tree in the random forest. • This is a measure of how important a variable is for estimating the value of the target variable across all of the trees that make up the forest. A higher Mean Decrease in Gini indicates higher variable importance. • Variables are sorted and displayed in the Variable Importance Plot created for the Random Forest by this measure. The most important variables to the model will be highest in the plot and have the largest Mean Decrease in Gini Values, conversely, the least important variable will be lowest in the plot, and have the smallest Mean Decrease in Gini values. 32
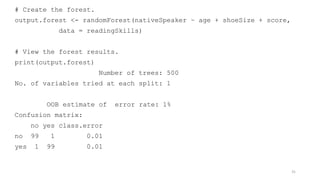
- 33. pred= predict(output.forest, readingSkills) library(e1071) library(caret) # Create Confusion Matrix confusionMatrix(data=pred, reference=readingSkills$nativeSpeaker, positive='yes') Confusion Matrix and Statistics Reference Prediction no yes no 100 0 yes 0 100 Accuracy : 1 95% CI : (0.9817, 1) No Information Rate : 0.5 P-Value [Acc > NIR] : < 2.2e-16 Kappa : 1 Mcnemar's Test P-Value : NA Sensitivity : 1.0 Specificity : 1.0 Pos Pred Value : 1.0 Neg Pred Value : 1.0 Prevalence : 0.5 Detection Rate : 0.5 Detection Prevalence : 0.5 Balanced Accuracy : 1.0 'Positive' Class : yes 33
- 34. Random Forest Implementation in R (prediction) • Let’s use Boston dataset require(randomForest) require(MASS)#Package which contains the Boston housing dataset attach(Boston) set.seed(101) ?Boston #to search on the dataset 34
- 35. crim: per capita crime rate by town. zn: proportion of residential land zoned for lots over 25,000 sq.ft. indus: proportion of non-retail business acres per town. chas: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise). nox: nitrogen oxides concentration (parts per 10 million). rm: average number of rooms per dwelling. age: proportion of owner-occupied units built prior to 1940. dis: weighted mean of distances to five Boston employment centres. rad: index of accessibility to radial highways. tax: full-value property-tax rate per $10,000. ptratio: pupil-teacher ratio by town. black: 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town. lstat: lower status of the population (percent). medv: median value of owner-occupied homes in $1000s. 35
- 36. We are going to use variable ′medv′ as the Response variable, which is the Median Housing Value. We will fit 500 Trees. dim(Boston) [1] 506 14 #training Sample with 300 observations train=sample(1:nrow(Boston),300) • Fitting the Random Forest We will use all the Predictors in the dataset. Boston.rf=randomForest(medv ~ . , data = Boston , subset = train) Boston.rf Number of trees: 500 No. of variables tried at each split: 4 Mean of squared residuals: 12.07361 % Var explained: 85.91 36
- 37. • The above Mean Squared Error and Variance explained are calculated using Out of Bag Error Estimation. In this 2/3 of Training data is used for training and the remaining 1/3 is used to Validate the Trees. Also, the number of variables randomly selected at each split is 4. • Plotting the Error vs Number of Trees Graph. plot(Boston.rf) This plot shows the Error and the Number of Trees. We can easily notice that how the Error is dropping as we keep on adding more and more trees and average them. 37
- 38. • Now we can compare the Out of Bag Sample Errors and Error on Test set • The above Random Forest model chose Randomly 4 variables to be considered at each split. We could now try all possible 13 predictors which can be found at each split. oob.err=double(13) test.err=double(13) #mtry is no of Variables randomly chosen at each split for(mtry in 1:13) { rf=randomForest(medv ~ . , data = Boston , subset = train,mtry=mtry,ntree=400) oob.err[mtry] = rf$mse[400] #Error of all Trees fitted pred<-predict(rf,Boston[-train,]) #Predictions on Test Set for each Tree test.err[mtry]= with(Boston[-train,], mean( (medv - pred)^2)) #Mean Squared Test Error cat(mtry," ") #printing the output to the console } 38
- 39. > test.err [1] 20.89175 14.95446 13.03060 12.78799 12.03247 11.73759 11.50418 11.59229 [9] 12.23918 11.89928 11.91245 12.36971 12.41598 > oob.err # Out of Bag Error Estimation [1] 21.17376 13.68955 12.59845 11.83516 11.72935 11.07857 11.77836 11.61401 [9] 12.39642 12.78779 12.10131 12.82391 12.44966 • What happens is that we are growing 400 trees for 13 times i.e for all 13 predictors. • Plotting both Test Error and Out of Bag Error matplot(1:mtry , cbind(oob.err,test.err), pch=19 , col=c("red","blue"),type="b",ylab="Mean Squared Error",xlab="Number of Predictors Considered at each Split") legend("topright",legend=c("Out of Bag Error","Test Error"),pch=19, col=c("red","blue")) 39
- 40. Now what we observe is that the Red line is the Out of Bag Error Estimates and the Blue Line is the Error calculated on Test Set. Both curves are quite smooth and the error estimates are somewhat correlated too. The Error Tends to be minimized at around mtry=4. 40
- 41. Parameter Tuning with an Algorithm > bestmtry <- tuneRF(Boston[,-13], Boston[,13], stepFactor=1.5, improve=1e-5, ntree=500) mtry = 4 OOB error = 10.15204 Searching left ... mtry = 3 OOB error = 10.58809 -0.04295218 1e-05 Searching right ... mtry = 6 OOB error = 10.47271 -0.0315876 1e-05 > print(bestmtry) mtry OOBError 3 3 10.58809 4 4 10.15204 6 6 10.47271 41
- 42. > Boston.rf2=randomForest(medv ~ . , data = Boston , subset = train, mtry=4) > Boston.rf2 Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 4 Mean of squared residuals: 11.68897 % Var explained: 86.36 42
- 43. Boston.lm=lm(medv ~ . , data = Boston) summary(Boston.lm) error <- Boston.lm$residuals lm_error <- mean(error^2) lm_error [1] 21.89483 43