







![Association rule mining
● Attempts to identify rules like people “who bought X also bought Y”
● Based on the items bought together in a transaction or a time window
● Rules of the form X → Y are discovered/mined from the data
● Where X is called antecedent and Y is called the consequent
● Metrics associated with the rules,
○ Support = N(X U Y) / |T| ( P(X AND Y) Ratio of transactions in which X and Y are bought
together)
○ Confidence = Support(X U Y) / Support(X) ( P(Y|X) Percentage of buyers of X, who also
bought Y)
○ Lift = Support(X U Y) / [Support(X) * Support(Y)] ( P(X AND Y) / [P(X) * P(Y)] )
● Some popular product tend to be appearing part of the consequent of all rules
● Lift is the metric that can help to get away with the issue](https://image.slidesharecdn.com/recommendersystems-170922143006/85/Recommender-systems-10-320.jpg)








Recommender systems
- 1. Recommender Systems Vivek Murugesan 10th Jun 2017
- 2. Agenda ● Recommendations… ● Advantages ● Recommender systems ● Anatomy of recommender systems ● Type of recommender systems or algorithms ● Requirements for scaling ● Learning to rank model ● Where to start…? ● Questions
- 3. Recommendations... ● It is estimated that close to 30% of Amazon’s revenue comes from the way they integrated recommendations ● About 75% of Netflix’s business is driven through recommendations ● Posts, groups, people and jobs recommended through Linkedin ● Posts, friends suggested in Facebook ● Google search results, autocomplete suggestions, google news, etc,. ● Stories recommended through Quora ● ...
- 4. Advantages... ● Increase customer engagement ● Increase customer satisfaction by delivering relevant contents ● Increase sales with cross sell options ● Drive more traffic Bought Similar Recommend
- 5. Recommender systems ● Attempts to predict the preference of a given user for an item ● Based on the prediction recommends set of items for the user ● By using, ○ Data: User history, Social profile, etc,. ○ Algorithms: Like Collaborative filtering, content based filtering etc,. ● Delivers the recommendations and let the users interact with them ● Attempts to learn more about the users
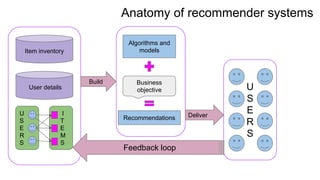
- 6. Anatomy of recommender systems Item inventory User details U S E R S I T E M S Algorithms and models Business objective Recommendations U S E R S Deliver Build Feedback loop
- 7. User preference data ● Data that the recommender system rely on to know/learn about the users ● The same being used for personalizing recommendations for the users ● Explicit, ○ Rating ○ Voting ○ Opinion ● Implicit, ○ Click ○ Purchase ○ Follow ● Binary ○ Like/Dislike ○ Click/Ignore ● Rating ○ Scale ● Unary ○ Purchase ○ Views ● Normalize rating ○ Handling scales ○ User biases ● Unary data ○ Special processing
- 8. Type of recommender systems or algorithms ● Non-personalized ○ Popular and trending product ○ Based on simple summary statistics ○ To handle cold start scenario in some cases ● Semi personalized ○ Association rule mining ○ Market basket recommendation ○ Ephemeral (contextual) ● Personalized ○ Persistent (long term interests) ○ Content based ○ Collaborative filtering ■ User-user similarity ■ Item-item similarity ■ Latent attributes through SVD ● Advanced ○ Hybrid (contextual + interest and content + collaborative) ○ Learning to rank
- 9. Content based filtering 1. Associate each item with certain keywords or attributes 2. Build a vector of keyword preference for user, by inferring based on their item preferences 3. Use TFIDF or similar mechanism to accumulate preferences on keywords across items 4. Score each item based on the cosine similarity (i.e. a dot product between two vectors) of its keyword vector with the user’s keyword vector
- 10. Association rule mining ● Attempts to identify rules like people “who bought X also bought Y” ● Based on the items bought together in a transaction or a time window ● Rules of the form X → Y are discovered/mined from the data ● Where X is called antecedent and Y is called the consequent ● Metrics associated with the rules, ○ Support = N(X U Y) / |T| ( P(X AND Y) Ratio of transactions in which X and Y are bought together) ○ Confidence = Support(X U Y) / Support(X) ( P(Y|X) Percentage of buyers of X, who also bought Y) ○ Lift = Support(X U Y) / [Support(X) * Support(Y)] ( P(X AND Y) / [P(X) * P(Y)] ) ● Some popular product tend to be appearing part of the consequent of all rules ● Lift is the metric that can help to get away with the issue
- 11. Collaborative filtering ● Unlike content based filtering collaborative filtering doesn’t assume the presence of attributes or keywords about the items ● Makes use of the User x Item matrix computed based on the history ● Generates recommendations entirely based on this this matrix ● Doesn’t rely on any additional details about the items or users (like demography)
- 12. User-user similarity 1. Build neighbourhood for each user based on the User x Item matrix (by using the correlation or cosine similarity of each user with others) 2. Use the likes/interactions of the top k users to build a potential set of items to recommend for the user a. 3. Score each item in the potential set based on the preference of the user u and their similarity with user a.
- 13. Item-item similarity 1. Build an item neighbourhood based on the preferences expressed by different users (i.e. based on the rating vectors of two different items) 2. Use set of items that the user has expressed preferences on up front to generate potential items as recommendations for them 3. Score each item in the potential set based on their similarity with the item that the user has liked (expressed preference) earlier
- 14. Requirements for scaling ● Volume of item base:- Depending on the item inventory, it can sometimes turn out to be huge number ● Volume of user base:- Similar to item base, users can also be very large in number ● Delivery channel/mode:- Depending on the mode of choice delivery, either turn around time or response time needs to be focused ● User feedback/interactions:- It is an opportunity to learn more about the users, handling the streaming data of interactions may pose some challenges ● Incremental update of models/algorithms:- Interactions means models need to be updated in near real time. Capability of incremental update is critical to avoid whole bunch of recomputation.
- 15. Scaling... With n items and m users calculating similarities of a given user with all other m-1 users take O(mn) time. When we are talking about performing this across all users it takes O(m2 n) time, as there will be np 2 pairs or nc 2 combinations. Similarly for calculating similarities across all items it takes O(n2 m) time. But we need only top k neighbourhood for each user or item. When n>>k then it results in lot of unnecessary computations. Is there a way to avoid these…? The item similarity API from Spark ML provides an answer to this. Clustering:- Let’s say we are trying the compute the user similarities among m users, where is really a large number. User neighbourhood can then be computed only within the cluster of users. Dimensionality reduction:- A User x Item matrix of dimension mxn, can be reduced to mxk by generating top k principal components from the matrix. Similarity computation on top of this reduced matrix will be faster than using the original matrix.
- 16. Learning to rank ● Several algorithms and models, ○ Can generate predicted rating items by user ○ Can also generated rank ordered list of recommendations ○ By consuming user history ● Various indicators of items like trend, seasonality, etc,. ● User’s preference, context, etc,. ● Business promotional objectives ● Item catalog/inventory coverage ● Eventual rank ordering by combining all of these ○ To satisfy user’s preference ○ And business objectives
- 17. Where to start…? ● Open source datasets ○ Movie lens ○ Million song ● Open source framework and API ○ Spark ML ○ Movie lens ● References ○ Recommender systems survey ○ Applying SVD/PCA on recommender systems ○ Learning to rank model ○ Coursera:- Recommender system ● Github ○ https://github.com/vivekmurugesan/recommender-systems