








![Object Storage characteristics
• Highly reliable and durable
– 99.9 % availability for AWS S3
– 99.999999999 % durability
• Massive scale
– 1.3 trillion objects stored across 7 AWS regions [Nov 2012 figures]
– Throughput: 830,000 requests per second
• Immutable objects
– Objects cannot be modified, only deleted
• Simple API
– PUT/POST objects, GET objects, DELETE objects
– No seek / no mutation / no POSIX API
• Flat namespace
– Everything stored in buckets.
– Bucket names are unique
– Buckets can only contain objects, not other buckets
• Cheap and getting cheaper](https://image.slidesharecdn.com/2-s3hdfsapachecon-130502175136-phpapp01/85/Scalable-Object-Storage-with-Apache-CloudStack-and-Apache-Hadoop-15-320.jpg)





![Why HDFS
• ASF Project (Apache Hadoop)
• Immutable objects, replication
• Reliability, scale and performance
– 200 million objects in 1 cluster [Facebook]
– 100 PB in 1 cluster [Facebook]
• Simple operation
– Just add data nodes](https://image.slidesharecdn.com/2-s3hdfsapachecon-130502175136-phpapp01/85/Scalable-Object-Storage-with-Apache-CloudStack-and-Apache-Hadoop-22-320.jpg)










Scalable Object Storage with Apache CloudStack and Apache Hadoop
- 1. Scalable Object Storage with Apache CloudStack and Apache Hadoop April 30 2013 Chiradeep Vittal @chiradeep
- 2. Agenda • What is CloudStack • Object Storage for IAAS • Current Architecture and Limitations • Requirements for Object Storage • Object Storage integrations in CloudStack • HDFS for Object Storage • Future directions
- 3. • History • Incubating in the Apache Software Foundation since April 2012 • Open Source since May 2010 • In production since 2009 – Turnkey platform for delivering IaaS clouds – Full featured GUI, end-user API and admin API Apache CloudStack Build your cloud the way the world’s most successful clouds are built
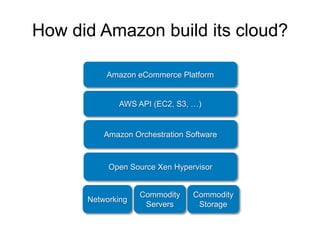
- 4. How did Amazon build its cloud? Commodity Servers Commodity Storage Networking Open Source Xen Hypervisor Amazon Orchestration Software AWS API (EC2, S3, …) Amazon eCommerce Platform
- 5. How can YOU build a cloud? Servers StorageNetworking Open Source Xen Hypervisor Amazon Orchestration Software AWS API (EC2, S3, …) Amazon eCommerce Platform Hypervisor (Xen/KVM/VMW/) CloudStack Orchestration Software Optional Portal CloudStack or AWS API
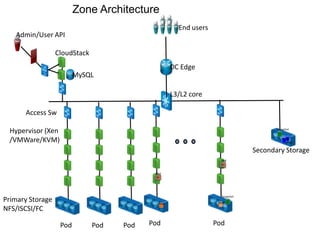
- 6. Secondary Storage Image L3/L2 core DC Edge End users Pod Pod Pod Pod Zone Architecture Pod Access Sw MySQL CloudStack Admin/User API Primary Storage NFS/ISCSI/FC Hypervisor (Xen /VMWare/KVM) VM VM Snapshot Snapshot Image Disk Disk VM
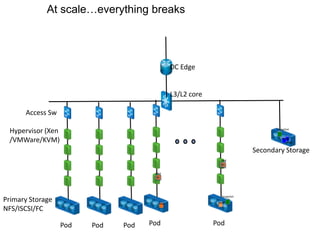
- 7. Cloud-Style Workloads • Low cost – Standardized, cookie cutter infrastructure – Highly automated and efficient • Application owns availability – At scale everything breaks – Focus on MTTR instead of MTBF
- 8. Secondary Storage Image L3/L2 core DC Edge Pod Pod Pod Pod At scale…everything breaks Pod Access Sw Primary Storage NFS/ISCSI/FC Hypervisor (Xen /VMWare/KVM) VM VM Snapshot Snapshot Image Disk Disk VM
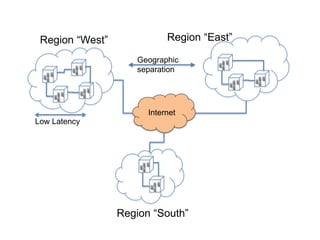
- 9. Region “West” Zone “West-Alpha” Zone “West-Beta” Zone “West-Gamma” Zone “West-Delta” Low Latency Backbone (e.g., SONET ring) Regions and zones
- 10. Region “East” Region “South” Internet Geographic separation Region “West” Low Latency
- 11. Secondary Storage in CloudStack 4.0 • NFS server default – can be mounted by hypervisor – Easy to obtain, set up and operate • Problems with NFS: – Scale: max limits of file systems • Solution: CloudStack can manage multiple NFS stores (+ complexity) – Performance • N hypervisors : 1 storage CPU / 1 network link – Wide area suitability for cross-region storage • Chatty protocol – Lack of replication
- 12. Object Storage Technology Region “West” Zone “West-Alpha” Zone “West-Beta” Zone “West-Gamma” Zone “West-Delta” Object Storage in a region • Replication • Audit • Repair • Maintenance
- 13. Region “West” Object Storage enables reliability
- 14. Object Storage Technology Region “West” Object Storage also enables other applications Object Store API Servers • DropBox • Static Content • Archival
- 15. Object Storage characteristics • Highly reliable and durable – 99.9 % availability for AWS S3 – 99.999999999 % durability • Massive scale – 1.3 trillion objects stored across 7 AWS regions [Nov 2012 figures] – Throughput: 830,000 requests per second • Immutable objects – Objects cannot be modified, only deleted • Simple API – PUT/POST objects, GET objects, DELETE objects – No seek / no mutation / no POSIX API • Flat namespace – Everything stored in buckets. – Bucket names are unique – Buckets can only contain objects, not other buckets • Cheap and getting cheaper
- 16. CloudStack S3 API Server Object Storage Technology S3 API Servers MySQL
- 17. CloudStack S3 API Server • Understands AWS S3 REST-style and SOAP API • Pluggable backend – Backend storage needs to map simple calls to their API • E.g., createContainer, saveObject, loadObject – Default backend is a POSIX filesystem – Backend with Caringo Object Store (commercial vendor) available – HDFS backend also available • MySQL storage – Bucket -> object mapping – ACLs, bucket policies
- 18. Object Store Integration into CloudStack • For images and snapshots • Replacement for NFS secondary storage Or Augmentation for NFS secondary storage • Integrations available with – Riak CS – Openstack Swift • New in 4.2 (upcoming): – Framework for integrating storage providers
- 19. What do we want to build ? • Open source, ASL licensed object storage • Scales to at least 1 billion objects • Reliability and durability on par with S3 • S3 API (or similar, e.g., Google Storage) • Tooling around maintenance and operation, specific to object storage
- 20. The following slides are a design discussion
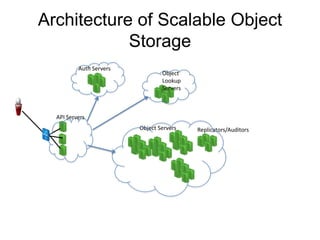
- 21. Architecture of Scalable Object Storage API Servers Auth Servers Object Servers Replicators/Auditors Object Lookup Servers
- 22. Why HDFS • ASF Project (Apache Hadoop) • Immutable objects, replication • Reliability, scale and performance – 200 million objects in 1 cluster [Facebook] – 100 PB in 1 cluster [Facebook] • Simple operation – Just add data nodes
- 23. HDFS-based Object Storage S3 API Servers S3 Auth Servers Data nodes Namenode pair HDFS API
- 24. BUT • Name Node Scalability – 150 bytes RAM / block – GC issues • Name Node SPOF – Being addressed in the community✔ • Cross-zone replication – Rack-awareness placement ✔ – What if the zones are spread a little further apart? • Storage for object metadata – ACLs, policies, timers
- 25. Name Node scalability • 1 billion objects = 3 billion blocks (chunks) – Average of 5 MB/object = 5 PB (actual), 15 PB (raw) – 450 GB of RAM per Name Node • 150b x 3 x 10^9 – 16 TB / node => 1000 Data nodes • Requires Name Node federation ? • Or an approach like HAR files
- 26. Name Node Federation Extension: Federated NameNodes are HA pairs
- 27. Federation issues • HA for name nodes • Namespace shards – Map object -> name node • Requires another scalable key-value store – HBase? • Rebalancing between name nodes
- 28. Replication over lossy/slower links A. Asynchronous replication – Use distcp to replicate between clusters – 6 copies vs. 3 – Master/Slave relationship • Possibility of loss of data during failover • Need coordination logic outside of HDFS B. Synchronous replication – API server writes to 2 clusters and acks only when both writes are successful – Availability compromised when one zone is down
- 29. CAP Theorem Consistency or Availability during partition Many nuances
- 30. Storage for object metadata A. Store it in HDFS along with the object – Reads are expensive (e.g., to check ACL) – Mutable data, needs layer over HDFS B. Use another storage system (e.g. HBase) – Name node federation also requires this. C. Modify Name Node to store metadata – High performance – Not extensible
- 31. Object store on HDFS Future • Viable for small-sized deployments – Up to 100-200 million objects – Datacenters close together • Larger deployments needs development – No effort ongoing at this time
- 32. Conclusion • CloudStack needs object storage for “cloud-style” workloads • Object Storage is not easy • HDFS comes close but not close enough • Join the community!
Editor's Notes
- #4: Need a better slide than this
- #5: Frequently require CCNA , Vmwareceritification, EMC training, etc etc. But they chose commondity systems. And simple networking.Can also sell cheaply since they use their own commerce platform.
- #6: The key here is the API on top of the infrastructure. This is the disruptive piece for the industry. Forget about CCNA, Vmware cert, now people can programmatically control their infrastructure as well as the VMs on top of it.