







![9 | P a g e
Adding a dedicated Hadoop system user
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop phool
Configure the sudo permissions for 'hduser'
$ sudo visudo
[Since by default ubuntu text editor is nano we will need to use CTRL + O to edit]
[Add the permissions to sudoers i.e. add this line]
hduser ALL=(ALL) ALL
[Use CTRL + X keyboard shortcut to exit out. Enter Y to save the file.]
Install ssh
$ sudo apt-get install ssh
$ sudo apt-get install rsync
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
Generate an SSH key for the phool user
$ su - phool
$ ssh-keygen -t rsa -P ""
Enter file in which to save the key (/home/phool/.ssh/id_rsa):
Created directory '/home/phool/.ssh'.
Your identification has been saved in /home/phool/.ssh/id_rsa.
Your public key has been saved in /home/phool/.ssh/id_rsa.pub.
Second, you have to enable SSH access to your local machine with this newly
created key
$ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
$ ssh localhost](https://image.slidesharecdn.com/miniproject2rrtsir-190722052750/85/Sentiment-Analysis-using-Big-Data-9-320.jpg)



![13 | P a g e
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
Make the directory for namenode and datanode and change the ownership of
hadoop
$ cd
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
$ sudo chown phool:phool -R /usr/local/hadoop
Format the namenode
$ hdfs namenode -format[first time when start the single node cluster]
[if there is some error, check bashrc file and command: source ~/.bashrc]
Start the daemon process and check them
$ start-all.sh](https://image.slidesharecdn.com/miniproject2rrtsir-190722052750/85/Sentiment-Analysis-using-Big-Data-13-320.jpg)













Sentiment Analysis using Big Data
- 1. 1 | P a g e Mini Project Report “Sentiment Analysis on Twitter of Demonetization using Big Data Apache Hadoop ” A Project report submitted to:- Prof. Rajiv Ranjan tewari Submitted By: Rajat Mittal Roll Number :- 13 Enrollment Number :- 16AU/665 In partial fulfillment of the requirements for the award of the degree of Bachelor of Technology
- 2. 2 | P a g e CERTIFICATE This is to certify that the project report entitled “Sentiment Analysis on Twitter of Demonetization using Big Data Apache Hadoop” prepared under my supervision by RAJAT MITTAL of B. Tech 6TH Semester, Computer Science & Engineering, having enrolment no. 16AU/665 has been done according to the regulations of the Degree of Bachelor of Technology in Computer Science & Engineering. The candidates have fulfilled the requirements for the submission of the project report. DATE:15th July 2019 ------------------------ PLACE: Prayagraj Prof. R. R. Tewari
- 3. 3 | P a g e INDEX 1. Acknowledgement…………………………………………...4 2. Abstract………………………………………………………5 3. About…………………………………………………………6 I. Introduction II. Purpose III. Scope IV. System Requirement 4. Feasibility Study……………………………………………...7 I. Economic II. Technical III. Behavioral 5. Experimental Setup…………………………………..............8 6. User Interface……………………………………………….15 7. Hadoop File System…………………………………………16 8. Sentiment Analysis………………………………………….18 9. Conclusion…………………………………………………..27 10. Future works……………………………………………….27 11. References…………………………………………………27
- 4. 4 | P a g e ACKNOWLEDGEMENT I would like to express our sincere gratitude to Prof. R. R. Tewari of the department of Computer Science and Engineering, J.K Institute of Applied Physics & Technology, whose role as project guide was invaluable for the project. I am extremely thankful for the keen interest he took in advising us, for the reference materials provided for the moral support extended to me. Last but not the least I convey my gratitude to all the teachers for providing me the technical skill that will always remain as my asset and to all non-teaching staff for the gracious hospitality they offered me. Finally, yet importantly, I would like to express my heartfelt thanks to my beloved parents for their blessings, my friends and classmates for their help and wishes for the successful completion of this project. Rajat Mittal
- 5. 5 | P a g e Abstract Due to the advent of new technologies, devices, and communication means like social networking sites, the amount of data produced by mankind is growing rapidly every year. The amount of data produced by us from the beginning of time till 2003 was 5 billion gigabytes. If you pile up the data in the form of disks it may fill an entire football field. The same amount was created in every two days in 2011, and in every ten minutes in 2013. This rate is still growing enormously. Though all this information produced is meaningful and can be useful when processed, it is being neglected. Hadoop is an Apache open source framework written in java that allows distributed processing of large datasets across clusters of computers using simple programming models. A Hadoop frame-worked application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage. MapReduce is a framework using which we can write applications to process huge amounts of data, in parallel, on large clusters of commodity hardware in a reliable manner. The major advantage of MapReduce is that it is easy to scale data processing over multiple computing nodes. Under the MapReduce model, the data processing primitives are called mappers and reducers. Decomposing a data processing application into mappers and reducers is sometimes nontrivial. But, once we write an application in the MapReduce form, scaling the application to run over hundreds, thousands, or even tens of thousands of machines in a cluster is merely a configuration change. This simple scalability is what has attracted many programmers to use the MapReduce model. So, by using this model we have easily done word count program for large data sets. Word count program tells how many times given words are repeated.
- 6. 6 | P a g e ABOUT 1.1 Introduction: India’s Prime Minister Mr. Narendra Modi declared the demonetizing of Notes on 8th November 2016. To see the reactions of normal people on demonetization, sentiment analysis is a good project. Government can launch new policies just by knowing the reactions of people. 1.2 Purpose: This project comprehensively describes how we can analyze the sentiments of different people using social media platform ‘Twitter’ which is widely popular all over the world by using Hadoop. 1.3 Scope: The project aims to produce real time sentiment analysis associated with a range of brands, products and topics. The project's scope is not only to have static sentiment analysis for past data, but also sentiment classification and reporting in real time. 1.4 System Requirement: • Operating system: Linux (Ubuntu 18.04) • Disk: minimum 30 GB • Network:1 GB Ethernet • RAM: 4 GB or above • Software: Pig, Hadoop .
- 7. 7 | P a g e FEASIBLITY STUDY 2.1 Economic Feasibility: Nothing can beat the scalability function of Hadoop because you can easily scale to thousands of inexpensive servers with just a single Hadoop cluster. You can keep on adding as many clusters as you want. The most attractive feature of Hadoop is that it is free. If at all any expense is incurred, then it probably would be commodity hardware for storing huge amounts of data. But that still makes Hadoop inexpensive. 2.2 Technical Feasibility: The technical requirement for the system is very basic economic and it does not use any other additional hardware and software. All the software used are free of cost for pseudo distributed mode. 2.3 Behavioural Feasibility: The system working is quite easy to use and learn due to its simple but attractive interface. User requires basic knowledge of Linux operating system.
- 8. 8 | P a g e Experimental Setup Single Node Cluster Installing JDK Download JDK-11tar.gz file from official website. →Go to link https://www.oracle.com/technetwork/java/javase/downloads/index.html →click on Downloads button After downloading $ cd Desktop/ $ sudo tar -xvf jdk-11_linux-x64_bin.tar.gz $ sudo mv jdk-11_linux-x64_bin /usr/lib/java Check version after installation. $ java –version
- 9. 9 | P a g e Adding a dedicated Hadoop system user $ sudo addgroup hadoop $ sudo adduser --ingroup hadoop phool Configure the sudo permissions for 'hduser' $ sudo visudo [Since by default ubuntu text editor is nano we will need to use CTRL + O to edit] [Add the permissions to sudoers i.e. add this line] hduser ALL=(ALL) ALL [Use CTRL + X keyboard shortcut to exit out. Enter Y to save the file.] Install ssh $ sudo apt-get install ssh $ sudo apt-get install rsync $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys Generate an SSH key for the phool user $ su - phool $ ssh-keygen -t rsa -P "" Enter file in which to save the key (/home/phool/.ssh/id_rsa): Created directory '/home/phool/.ssh'. Your identification has been saved in /home/phool/.ssh/id_rsa. Your public key has been saved in /home/phool/.ssh/id_rsa.pub. Second, you have to enable SSH access to your local machine with this newly created key $ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys $ ssh localhost
- 10. 10 | P a g e Download and Install Hadoop-2.6.0 $ cd Desktop/ $ sudo tar -xzvf hadoop-2.7.7.tar.gz $ sudo mv hadoop-2.7.7 /usr/local/hadoop $ sudo chown -R phool:hadoop hadoop Edit bashrc file $ sudo gedit ~/.bashrc Add the following lines at last in file #Hadoop Variables export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$JAVA_HOME/bin export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" Source the variables using the source command $ source ~/.bashrc Edit hadoop-env.sh file $ cd /usr/local/hadoop/etc/hadoop/ $ sudo gedit hadoop-env.sh Add path for JAVA_HOME # the java implementation to use. export JAVA_HOME="/usr/lib/jvm/jdk1.8.0_191" Add some more from other sites at last in file # To set the Hadoop installation directory export HADOOP_HOME=/usr/local/hadoop export HADOOP_PREFIX=/usr/local/hadoop # To set Hadoop native library directory
- 11. 11 | P a g e export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native # To disable IPv6 only for Hadoop export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # To set the library directory export HADOOP_OPTS="$HADOOP_OPTS - Djava.library.path=$HADOOP_HOME/lib" Edit yarn-env.sh file $ cd /usr/local/hadoop/etc/hadoop/ $ sudo gedit yarn-env.sh Add path for JAVA_HOME export JAVA_HOME="/usr/lib/java/jvm/jdk1.8.0_191" Create Temporary Directory Hadoop default configuration uses hadoop.tmp.dir as the default base temporary directory both for the local file system and HDFS. To use other directory, create the directory and set required ownership and permission. If we do this then we must have add it in core-site.xml. $ sudo mkdir -p /usr/local/hadoop/etc/hadoop/hadooptmp $ sudo chown -R phool:phool /usr/local/hadoop/etc/hadoop/hadooptmp If you want to tighten up security, chmod from 755 to 750 #$ sudo chmod 0750 /usr/local/hadoop/etc/hadoop/hadooptmp $ sudo chmod -R 755 /usr/local/hadoop/etc/hadoop/hadooptmp Edit core-site.xml, yarn-site.xml, mapred-site.xml, hdfs-site.xml $ cd /usr/local/hadoop/etc/hadoop/ core-site.xml $ sudo gedit core-site.xml Add the following configuration <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>
- 12. 12 | P a g e <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/etc/hadoop/hadooptmp</value> </property> </configuration> yarn-site.xml $ sudo gedit yarn-site.xml Add the following configurations <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux- services.mapreduce.shuffle.class</name> <value> org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration> mapred-site.xml $ sudo cp mapred-site.xml.template mapred-site.xml $ sudo gedit mapred-site.xml Add the following configuration <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> hdfs-site.xml Add the following configurations. For default 128 MB (value written in bytes) for 64 MB (change it to 67108864) <configuration> <property>
- 13. 13 | P a g e <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value> </property> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> </configuration> Make the directory for namenode and datanode and change the ownership of hadoop $ cd $ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode $ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode $ sudo chown phool:phool -R /usr/local/hadoop Format the namenode $ hdfs namenode -format[first time when start the single node cluster] [if there is some error, check bashrc file and command: source ~/.bashrc] Start the daemon process and check them $ start-all.sh
- 14. 14 | P a g e $ jps User Interface Access the Web UIs Verify Hadoop installation With Web Interfaces. Open the browser with the following URL’s HDFS-UI: http://localhost:50070 HDFS-UI
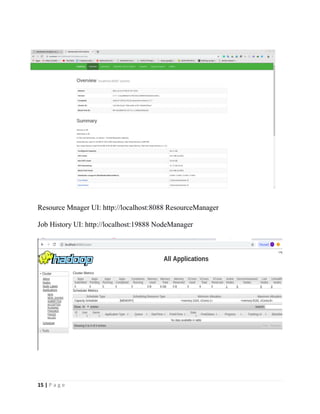
- 15. 15 | P a g e Resource Mnager UI: http://localhost:8088 ResourceManager Job History UI: http://localhost:19888 NodeManager
- 16. 16 | P a g e Hadoop File System StartingHDFS Initially you have to format the configured HDFS file system, open namenode (HDFS server), and execute the following command. $ hadoop namenode -format After formatting the HDFS, start the distributed file system. The following command will start the namenode as well as the data nodes as cluster. $ start-dfs.sh ListingFilesinHDFS After loading the information in the server, we can find the list of files in a directory, status of a file, using ‘ls’. Given below is the syntax of ls that you can pass to a directory or a filename as an argument. $ $HADOOP_HOME/bin/hadoop fs -ls <args> InsertingDataintoHDFS Assume we have data in the file called file.txt in the local system which is ought to be saved in the hdfs file system. Follow the steps given below to insert the required file in the Hadoop file system. Step 1 You have to create an input directory. $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input Step 2 Transfer and store a data file from local systems to the Hadoop file system using the put command. $ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input Step 3 You can verify the file using ls command. $ $HADOOP_HOME/bin/hadoop fs -ls /user/input
- 17. 17 | P a g e RetrievingDatafromHDFS Assume we have a file in HDFS called outfile. Given below is a simple demonstration for retrieving the required file from the Hadoop file system. Step 1 Initially, view the data from HDFS using cat command. $ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile Step 2 Get the file from HDFS to the local file system using get command. $ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/ ShuttingDowntheHDFS You can shut down the HDFS by using the following command. $ stop-dfs.sh
- 18. 18 | P a g e Sentiment Analysis Introduction :- 2016 Indian banknote demonetization On 8 November 2016, the Government of India announced the demonetization of all ₹500 and ₹1,000 banknotes of the Mahatma Gandhi Series. It also announced the issuance of new ₹500 and ₹2,000 banknotes in exchange for the demonetized banknotes. The Prime minister of India Narendra Modi claimed that the action would curtail the shadow economy and reduce the use of illicit and counterfeit cash to fund illegal activity and terrorism. The announcement of demonetization was followed by prolonged cash shortages in the weeks that followed, which created significant disruption throughout the
- 19. 19 | P a g e economy. People seeking to exchange their banknotes had to stand in lengthy queues, and several deaths were linked to the rush to exchange cash. According to a 2018 report from the Reserve Bank of India, approximately 99.3% of the demonetized banknotes, or ₹15.30 lakh crore (15.3 trillion) of the ₹15.41 lakh crore that had been demonetized, were deposited with the banking system. The banknotes that were not deposited were only worth ₹10,720 crore (107.2 billion), leading analysts to state that the effort had failed to remove black money from the economy. The BSE SENSEX and NIFTY 50 stock indices fell over 6 percent on the day after the announcement. The move reduced the country's industrial production and its GDP growth rate. Initially, the move received support from several bankers as well as from some international commentators. The move was also criticized as poorly planned and unfair, and was met with protests, litigation, and strikes against the government in several places across India. Debates also took place concerning the move in both houses of the parliament. ➢ Let us find out the views of different people on the demonetization by analyzing the tweets from twitter. Here is the dataset where twitter tweets are gathered in CSV format. You can download the dataset from the below link :- https://drive.google.com/open?id=0ByJLBTmJojjzNkRsZWJiY1VGc28 File name-: demonetization-tweets.csv • Now we will load the data into pig using PigStorage as follows:
- 20. 20 | P a g e load_tweets = LOAD '/twitter/demonetization-tweets.csv' USING PigStorage(','); Now after loading successfully, you can see the tweets loaded successfully into pig by using the dump command. Here is the sample tweet :- ("1","RT @rssurjewala: Critical question: Was PayTM informed about #Demonetization edict by PM? It's clearly fishy and requires full disclosure &�",FALSE,0,NA,"2016-11-23 18:40:30",FALSE,NA,"801495656976318464",NA,"<a href=""http://twitter.com/download/android"" rel=""nofollow"">Twitter for Android</a>","HASHTAGFARZIWAL",331,TRUE,FALSE) Metadata of the tweets are as follows: • id • Text (Tweets) • favorited • favoriteCount • replyToSN • created • truncated • replyToSID • id • replyToUID • statusSource • screenName • retweetCount • isRetweet • retweeted
- 21. 21 | P a g e • Now from this columns, we will extract the id and the tweet_text as follows extract_details = FOREACH load_tweets GENERATE $0 as id,$1 as text; Now if you dump the extracted columns, you will get the id and the tweet_text as follows: ("1","RT @rssurjewala: Critical question: Was PayTM informed about #Demonetization edict by PM? It's clearly fishy and requires full disclosure &�") Now we will divide the tweet_text into words to calculate the sentiment of the whole tweet. tokens = foreach extract_details generate id,text, FLATTEN(TOKENIZE(text)) As word; For every word in the tweet_text, each word will be taken and created as a new row You can use the dump command to check the same. Here is the sample. ("1","RT @rssurjewala: Critical question: Was PayTM informed about #Demonetization edict by PM? It's clearly fishy and requires full disclosure &�",RT) In the above sample record, you can see that at the last RT word has been taken and created a new record for that.
- 22. 22 | P a g e You can use the describe tokens command to check the schema of that relation and is as follows: tokens: {id: bytearray,text: bytearray,word: chararray} Now, we have to analyse the Sentiment for the tweet by using the words in the text. We will rate the word as per its meaning from +5 to -5 using the dictionary AFINN. The AFINN is a dictionary which consists of 2500 words which are rated from +5 to -5 depending on their meaning. You can download the dictionary from the following link: AFINN dictionary - https://drive.google.com/open?id=0ByJLBTmJojjzZ0d1RVdBTDVjT28 We will load the dictionary into pig by using the below statement: dictionary = load '/twitter/AFINN.txt' using PigStorage('t') AS(word:chararray,rating:int); We can see the contents of the AFINN dictionary in the below screen shot.
- 23. 23 | P a g e Now, let’s perform a map side join by joining the tokens statement and the dictionary contents using this relation: word_rating = join tokens by word left outer, dictionary by word using 'replicated'; We can see the schema of the statement after performing join operation by using the below command: describe word_rating; word_rating: {tokens::id: bytearray,tokens::text: bytearray,tokens::word: chararray,dictionary::word: chararray,dictionary::rating: int} In the above statement describe word_rating, we can see that the word_rating has joined the tokens (consists of id, tweet text, word) statement and the dictionary(consists of word, rating). Now we will extract the id,tweet text and word rating(from the dictionary) by using the below relation. rating = foreach word_rating generate tokens::id as id,tokens::text as text, dictionary::rating as rate; We can now see the schema of the relation rating by using the command describe rating. rating: {id: bytearray,text: bytearray,rate: int} In the above statement describe rating we can see that our relation now consists of id,tweet text and rate(for each word). Now, we will group the rating of all the words in a tweet by using the below relation:
- 24. 24 | P a g e word_group = group rating by (id,text); Here we have grouped by two constraints, id and tweet text. Now, let’s perform the Average operation on the rating of the words per each tweet. avg_rate = foreach word_group generate group, AVG(rating.rate) as tweet_rating; Now we have calculated the Average rating of the tweet using the rating of each word. From the above relation, we will get all the tweets i.e., both positive and negative. Here, we can classify the positive tweets by taking the rating of the tweet which can be from 0-5. We can classify the negative tweets by taking the rating of the tweet from -5 to -1. We have now successfully performed the Sentiment Analysis on Twitter data using Pig. We now have the tweets and its rating, so let’s perform an operation to filter out the positive tweets. Now we will filter the positive tweets using the below statement: positive_tweets = filter avg_rate by tweet_rating>=0 Here are the sample tweets with positive ratings.
- 25. 25 | P a g e (("7989","RT @rssurjewala: Critical question: Was PayTM informed about #Demonetization edict by PM? It's clearly fishy and requires full disclosure &�"),1.0) (("7990","All weddings now need to be approved by RBI... Amazing times #demonetization isn't that what we are understanding"),2.0) (("7993","RT @jackerhack: Indore's collector would like you to shut up about #demonetization. At @internetfreedom we think that is a problem. https:/�"),2.0) (("7994","@quizderek Post #Dmonetization the result will be totally different.The win is not because of #demonetization an all knows about it"),4.0) (("7995","@baliramsingh2 So many restrictions. Not easy to avail the facility by anyone. Multiple U-turns by GOI on the issue. #DeMonetization #RBI"),1.0) ((How long, successful and sustainable will be this strategic game of #DeMonetization against Demons?"),3.0) ((No there r many, we cal them by many names like C#%),2.0) ((Akhilesh=not good,black money is good),3.0) ((And respect their decision,but support oppositio�"),2.0) ((And respect their decision,but support opposition just b'coz of party"),2.0) (( the avg indian wants corruptn free india.. So in d name of black money, everybody agrees),1.0)
- 26. 26 | P a g e Like this we will also filter the negative tweets as follows: negative_tweets = filter avg_rate by tweet_rating<0; Here are the sample tweets with negative rating (("7969","OK � now don’t complain that modi ji promised 2 Crore jobs a year but did only 1.35 Lakh. He is making up for thru� https://t.co/RiON3cqAlH"),-0.5) (("7997","RT @sukanyaiyer2: #DeMonetization AAP protests by marching Against Govts move over DeMonetization & he is also detained as he Tried 2 March�"),-2.0) (("7998","#demonetization will help combat terror because Pak won't be able to print new notes! And now),-0.6666666666666666) (("8000","RT @UnSubtleDesi: Kejriwal posts pic of dead robber and claims it's #demonetization related death? How shameless has this man become? https�"),- 2.5) ((Only noise, chaos & disruptions by obstructionist #�"),-2.0) ((Only noise, chaos & disruptions by obstructi� https://t.co/zVE7MYt04G"),-2.0) ((5% bad idea, poor implementation"),-2.0) ((25% good idea, poor implementation),-2.0) ((If not for Aam Aadmi, listen to them no PM Modi?"),-1.0) ((Aim of #demonetization laudable, but Govt has no road map2create... https://t.co/A4Geu9chOv"),-1.0)
- 27. 27 | P a g e ((Enough jokes on #Demonetization, also no more posts on politics or social affairs...),-1.0) ((RT @kanimozhi: Everyone seems to hate the rich, even the rich hates richer and the richer hates the richest. #Demonetization"),-1.3333333333333333) In this we can find the type of tweets on Twitter whether it is Positive, Negative or Neutral. Conclusion :- As we can divide the tweets in three different categories- Positive, Negative & Neutral. It is very useful to know the reactions of people on every product, policy etc. As we can able to do this using this product, we can update the policies or launch a new product. This is very helpful to increase the business or conduct a good government in a best way. Thus, Sentiment Analysis plays a very important role for an government of a country. Here I analyzed sentiments on demonetization, anyone can do these kinds of sentiment analysis on anything. Future Works :- Sentiments analysis can be done on real time tweets also. i.e. a very adorable way. If we are able to know the thinking of a common people on real-time that is a best thing for an government. For good conduct of government, leader should know everything about his/her community. References:- https://www.tutorialspoint.com/hadoop/ https://acadgild.com/blog/pig-use-case-sentiment-analysis-on-demonetization