








![Job definition
10
<hdp:job id=“hadoopJob"
input-path="${wordcount.input.path}"
output-path="${wordcount.output.path}"
libs="file:${app.repo}/supporting-lib-*.jar"
mapper="org.company.Mapper"
reducer="org.company.Reducer"/>
Configuration conf = new Configuration();
Job job = new Job(conf, “hadoopJob");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Maper.class);
job.setReducerClass(Reducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new
Path(args[1]));
job.waitForCompletion(true);](https://image.slidesharecdn.com/springforapachehadoop-130528055951-phpapp02/85/Spring-for-Apache-Hadoop-10-320.jpg)






















Spring for Apache Hadoop
- 1. Spring for Apache Hadoop By Zenyk Matchyshyn
- 2. Agenda • Goals of the project • Hadoop Map/Reduce • Scripting • HBase • Hive • Pig • Other • Alternatives 2
- 3. Big Data – Why? Because of Terabytes and Petabytes: • Smart meter analysis • Genome processing • Sentiment & social media analysis • Network capacity trending & management • Ad targeting • Fraud detection 3
- 4. Goals • Provide programmatic model to work with Hadoop ecosystem • Simplify client libraries usage • Provide Spring friendly wrappers • Enable real-world usage as a part of Spring Batch & Spring Integration • Leverage Spring features 4
- 5. Supported distros • Apache Hadoop • Cloudera CDH • Greenplum HD 5
- 6. HADOOP 6
- 8. Hadoop basics Split Map Shuffle Reduce 8 Dog ate the bone Cat ate the fish Dog, 1 Ate, 1 The, 1 Bone, 1 Cat, 1 Ate, 1 The, 1 Fish,1 Dog, 1 Ate, {1, 1} The, {1, 1} Bone, 1 Cat, 1 Fish,1 Dog, 1 Ate, 2 The, 2 Bone, 1 Cat, 1 Fish,1
- 9. Configuration 9 <?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns="http://www.springframework.org/schema/hadoop" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:beans="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/hadoop http://www.springframework.org/schema/hadoop/spring-hadoop.xsd"> <context:property-placeholder location="hadoop.properties"/> <configuration> fs.default.name=${hd.fs} mapred.job.tracker=${hd.jt} </configuration> …………………. </beans:beans
- 10. Job definition 10 <hdp:job id=“hadoopJob" input-path="${wordcount.input.path}" output-path="${wordcount.output.path}" libs="file:${app.repo}/supporting-lib-*.jar" mapper="org.company.Mapper" reducer="org.company.Reducer"/> Configuration conf = new Configuration(); Job job = new Job(conf, “hadoopJob"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(Maper.class); job.setReducerClass(Reducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
- 11. Job Execution 11 <hdp:job-runner id="runner" run-at-startup="true" pre-action=“someScript“ post-action=“someOtherScript“ job-ref=“hadoopJob" />
- 12. • Hadoop Streaming: • Hadoop Tool Executor: Other approaches 12 <hdp:streaming id="streaming" input-path="/input/" output-path="/ouput/" mapper="${path.cat}" reducer="${path.wc}"/> <hdp:tool-runner id="someTool" tool-class="org.foo.SomeTool" run-at-startup="true"> <hdp:arg value="data/in.txt"/> <hdp:arg value="data/out.txt"/> property=value </hdp:tool-runner>
- 13. SCRIPTING 13
- 14. Details • Supports JVM languages from JSR-223 (Groovy, JRuby, Jython, Rhino) • Exposes SimplerFileSystem • Provides implicit variables • Exposes FsShell to mimic HDFS shell • Exposes DistCp to mimic distcp from Hadoop 14
- 15. Example 15 <hdp:script-tasklet id="script-tasklet"> <hdp:script language="groovy"> inputPath = "/user/gutenberg/input/word/" outputPath = "/user/gutenberg/output/word/" if (fsh.test(inputPath)) { fsh.rmr(inputPath) } if (fsh.test(outputPath)) { fsh.rmr(outputPath) } inputFile = "src/main/resources/data/nietzsche-chapter-1.txt" fsh.put(inputFile, inputPath) </hdp:script> </hdp:script-tasklet>
- 16. HBASE 16
- 18. HBase basics • Distributed, column oriented store • Independent of Hadoop • No translation into Map/Reduce • Stores data in MapFiles (indexed SequenceFiles) 18 Create ‘sometable’, ‘clmnfamily1’ Put ‘sometable’, ‘row_id1’, ‘clmnfamily1:c1’, ‘some values’ Scan ‘sometable’
- 19. Features • Easy connection interface • Thread safe • DAO friendly support and wrappers: • HbaseTemplate • TableCallback • RowMapper • ResultsExtractor • Binding table to current thread 19
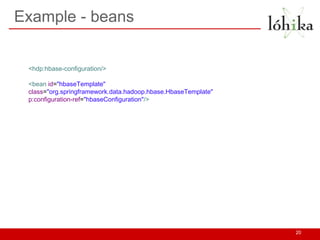
- 20. Example - beans 20 <hdp:hbase-configuration/> <bean id="hbaseTemplate" class="org.springframework.data.hadoop.hbase.HbaseTemplate" p:configuration-ref="hbaseConfiguration"/>
- 21. Example - code 21 template.execute("MyTable", new TableCallback<Object>() { @Override public Object doInTable(HTable table) throws Throwable { Put p = new Put(Bytes.toBytes("SomeRow")); p.add(Bytes.toBytes("SomeColumn"), Bytes.toBytes("SomeQualifier"), Bytes.toBytes("AValue")); table.put(p); return null; } }); List<String> rows = template.find("MyTable", "SomeColumn", new RowMapper<String>() { @Override public String mapRow(Result result, int rowNum) throws Exception { return result.toString(); } }));
- 22. HIVE 22
- 24. Hive basics • SQL-like interface - HiveQL • Has its own structure • Not a pipeline like Pig • Basically a distributed data warehouse • Has execution optimization 24
- 25. Features • Hive server • DAO friendly Hive Thrift Client simplification • Hive JDBC driver within Spring DAO ecosystem • Hive scripting • Thread safe 25
- 26. Example - beans 26 <hdp:hive-server host=“hivehost" port="10001" /> <hdp:hive-template /> <hdp:hive-client-factory host="some-host" port="some-port" > <hdp:script location="classpath:org/company/hive/script.q"> <arguments>ignore-case=true</arguments> </hdp:script> </hdp:hive-client-factory> <hdp:hive-runner id="hiveRunner" run-at-startup="true"> <hdp:script> DROP TABLE IF EXITS testHiveBatchTable; CREATE TABLE testHiveBatchTable (key int, value string); </hdp:script> <hdp:script location="hive-scripts/script.q"/> </hdp:hive-runner>
- 27. Example - template 27 return hiveTemplate.execute(new HiveClientCallback<List<String>>() { @Override public List<String> doInHive(HiveClient hiveClient) throws Exception { return hiveClient.get_all_databases(); } }));
- 28. PIG 28
- 30. Pig • High level language for data analysis • Uses PigLatin to describe data flows (translates into MapReduce) • Filters, Joins, Projections, Groupings, Counts, etc. • Example: 30 A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float); B = FOREACH A GENERATE name; DUMP B;
- 31. Features • Scripts execution • DAO friendly template • Thread safe 31
- 32. Example - beans 32 <hdp:pig-factory exec-type="LOCAL" job-name="pig-script" configuration-ref="hadoopConfiguration" properties-location="pig-dev.properties”"> source=${pig.script.src} <script location="org/company/pig/script.pig“/> </hdp:pig-factory> <hdp:pig-runner id="pigRunner" run-at-startup="true"> <hdp:script> A = LOAD 'src/test/resources/logs/apache_access.log' USING PigStorage() AS (name:chararray, age:int); B = FOREACH A GENERATE name; DUMP B; </hdp:script> <hdp:script location="pig-scripts/script.pig"> <arguments>electric=sea</arguments> </hdp:script> </hdp:pig-runner> <hdp:pig-template/>
- 33. Example - template 33 return pigTemplate.execute(new PigCallback<Set<String>() { @Override public Set<String> doInPig(PigServer pig) throws ExecException, IOException { return pig.getAliasKeySet(); } }));
- 34. Other features • Cascading support • Works well with Hadoop security • Spring Batch tasklets • Spring Integration support 34
- 35. Alternatives & related • Apache Flume – distributed data collection • Apache Oozie – workflow scheduler • Apache Sqoop – SQL bulk import/export 35
- 36. Q/A ? 36