




































THE SOLUTION FOR BIG DATA
- 1. THE SOLUTION FOR BIG DATA NAME:SIVAKOTI TARAKA SATYA PHANINDRA ROLL NO:15K81D5824 COURSE: CSE M.TECH/SEM-1
- 2. CONTENT: Data – Trends in storing data. BigData – Problems in IT industry Why BigData ? Introduction to HADOOP HDFS (Hadoop Distributed File System) MapReduce Prominent users of Hadoop. Conclusion
- 3. Data – Trends in storing data What is data--- Any real world symbol (character, numeric, special character) or a of group of them is said to be data it may be of the visual or audio or scriptural , images, etc., File system Databases Cloud (internet)
- 4. BIG DATA: What is big data—In IT, it is a collection of data sets so large and complex data that it becomes difficult to process using on-hand database management tools or traditional data processing applications. As of 2016, limits on the size of data sets that are feasible to process in reasonable time were on the order of Exabyte of data.(KBs MBs GBs TBs PB ZB )
- 6. BIGDATA and problems with it. Daily about 0.8 Petabytes of updates are being made into FACEBOOK including 50 millions photos. Daily, YOUTUBE is loaded with videos that can be watched for one year continuously Limitations are encountered due to large data sets in many areas, including meteorology, genomics, complex physics simulations, and biological and environmental research. Also affect Internet search, finance and business informatics. The challenges include in capture, retrieval, storage, search, sharing, analysis, and visualization.
- 7. Why BIG DATA ?
- 9. THEN WHAT COULD BE THE SOLUTION FOR BIGDATA ?
- 10. Hadoop’s Developers: 2005: Doug Cutting and Michael J. Cafarella developed Hadoop to support distribution for the Nutch search engine project. The project was funded by Yahoo. 2006: Yahoo gave the project to Apache Software Foundation. Doug Cutting
- 11. What is Hadoop? It is a open source software written in java Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage.
- 12. • Apache top level project, open-source implementation of frameworks for reliable, scalable, distributed computing and data storage. • It is a flexible and highly- available architecture for large scale computation and data processing on a network of commodity hardware.
- 14. The project includes these modules: Hadoop Common Hadoop Distributed File System(HDFS) Hadoop MapReduce
- 15. 1.Hadoop Commons It provides access to the filesystems supported by Hadoop. The Hadoop Common package contains the necessary JAR files and scripts needed to start Hadoop. The package also provides source code, documentation, and a contribution section which includes projects from the Hadoop Community (Avro, Cassandra, Chukwa, Hbase, Hive, Mahout, Pig, ZooKeeper)
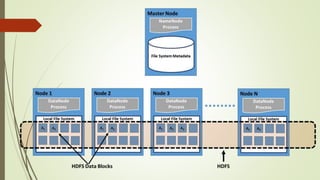
- 16. 2. Hadoop Distributed File System (HDFS): Hadoop uses HDFS, a distributed file system based on GFS (Google File System), as its shared filesystem. HDFS architecture divides files into large chunks (~64MB) distributed across data servers (this is configurable). It has a namenode and datanodes
- 17. What does a HDFS contain HDFS consists of a global namenodes or namespaces and they are federated. The datanodes are used as common storage for blocks by all the Namenodes. Each datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports and handles commands from the Namenodes
- 18. Structure of Hadoop system: Master Node : Name Node Secondary Name Node Job Tracker Slaves : Data Node Task Tracker
- 19. MASTER NODE: Master node Keeps track of namespace and metadata about items Keeps track of MapReduce jobs in the system Hadoop currently configured with centurion064 as the master node Hadoop is locally installed in each system. Installed location is in /localtmp/hadoop/hadoop-0.15.3
- 20. SLAVE NODES: Slave nodes Manage blocks of data sent from master node In common, these are the chunkservers Currently centurion060, centurion064 are the two slave nodes being used. Slave nodes store their data in /localtmp/hadoop/hadoop-dfs (this is automatically created by the DFS) Once you use the DFS, relative paths are from /usr/{your usr id}
- 22. Advantages and Limitations of HDFS : Reduce traffic on job scheduling. File access can be achieved through the native Java or language of the users' choice (C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk, and OCaml), It cannot be directly mounted by an existing operating system. It should be provided with UNIX or LUNIX system.
- 23. 3.Hadoop MAPREDUCE SYSTEM: The Hadoop MapReduce framework harnesses a cluster of machines and executes user defined MapReduce jobs across the nodes in the cluster. A MapReduce computation has two phases a map phase and a reduce phase.
- 24. MAP AND REDUCE METHODS USAGE… Map function Reduce function Run this program as a MapReduce job
- 25. WORD COUNT OVER A GIVEN SET OF STRINGS We 1 love 1 India 1 We 1 Play 1 Tennis 1 Love 1 India 1 We 2 Tennis 1 Play 1 Map Reduce
- 26. MAPREDUCE IN WITH NO REDUCE TASKS
- 27. MAPREDUCE WITH TWO REDUCE TASKS - AUTOMATIC PARALLEL EXECUTION IN MAPREDUCE
- 28. Shuffle and sort in MapReduce with multiple reduce tasks
- 32. Prominent users of HADOOP Amazon – 100 nodes Facebook – two clusters of 8000 and 3000 nodes Adobe – 80 node system EBay – 532 node cluster yahoo – cluster of about 4500 nodes IIIT Hyderabad – 30 node cluster
- 34. Salaries Tend in Hadoop:
- 35. Achievements : 2008 - Hadoop Wins Terabyte Sort Benchmark (sorted 1 terabyte of data in 209 seconds, compared to previous record of 297 seconds) 2009 - Avro and Chukwa became new members of Hadoop Framework family 2010 - Hadoop's Hbase, Hive and Pig subprojects completed, adding more computational power to Hadoop framework 2011 - ZooKeeper Completed March 2011 - Apache Hadoop takes top prize at Media Guardian Innovation Award 2013 - Hadoop 1.1.2 and Hadoop 2.0.3 alpha. - Ambari, Cassandra, Mahout have been added
- 36. Conclusion: It reduce traffic on capture, storage, search, sharing, analysis, and visualization. A huge amount of data could be stored and large computations could be done in a single compound with full safety and security at cheap cost. BIGDATA and BIGDATA-SOLUTIONS is one of the burning issues in the present IT industry so, work on those will surely make you more useful to that.