










![Target Tasks
● TechQA-RC
○ Predict start and end position of the answer span with two separate classifiers
● TechQA-DR, AskUbuntu-DQD
○ Classify the [CLS] token at the final layer with a binary classifier
○ During inference, rank according to classification score
● Data Augmentation for TechQA
○ Data perturbation (random deletion, duplication, dropping title, removing stop words, etc)
○ Training size increased by 10 times
12](https://image.slidesharecdn.com/transferlearninglowresourcelanguagesdomains-210608195319/85/Transfer-Learning-for-Low-Resource-Languages-and-Domains-12-320.jpg)





































Transfer Learning for Low Resource Languages and Domains
- 1. Transfer Learning for Low-resource Languages and Domains Efsun Sarioglu Kayi 1
- 2. Transfer Learning Source task/domain /language Target task/domain /language Source Model Transfer Learning Target Model Domain Adaptation Cross-lingual Embeddings Knowledge Distillation 2 Diagram adapted from ruder.io ● Scarce or no labeled data ● Lack of computational resources/data to train large models
- 3. Roadmap ● Domain Adaptation ○ Adapting pre-trained language model to a new domain via vocabulary extension and auxiliary tasks ● Knowledge Distillation ○ Synthetic data generation for multilingual dependency parsers ● Cross-lingual Embeddings ○ Zero-shot transfer of urgency detection for low-resource languages 3
- 4. Multi-Stage Pre-training for Low-Resource Domain Adaptation In collaboration with Rong Zhang, Revanth Gangi Reddy, Md Arafat Sultan, Vittorio Castelli, Anthony Ferritto, Radu Florian, Salim Roukos, Avirup Sil and Todd Ward Work done at IBM Research 4 Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)
- 5. Domain Adaptation of Language Models ● Fine-tuning pre-trained LMs shown to be successful across many tasks ○ LMs trained on open domain corpora e.g. Wikipedia, Books, News etc ● Specialized pre-trained LMs ○ Fine-tune LM on in-domain corpora e.g. BioBERT , SciBERT ● Problems still exist ○ OOV: missing terms in LM’s vocabulary ○ Over-segmentation of unknown words by the LM tokenizer (e.g. WordPiece, BPE) ○ Similar problems going from English to other languages 5
- 6. IT Domain Datasets ● TechQA ○ Real world questions from IBM developer forums, with 50 support documents provided per question ○ Includes both answerable and unanswerable questions ○ 801K unlabeled TechNotes provided to support LM training ● AskUbuntu ○ Contains user-marked pairs of similar questions from Stack Exchange, developed for a duplicate question detection task ○ A dump of forum posts is provided for LM training 6
- 7. Tech Domain Adaptation ● Extending vocabulary of LM with domain-specific terms while fine-tuning on in-domain data ● Utilize structure in unlabeled data to create auxiliary synthetic tasks that helps LM transfer to downstream tasks ● Improvements on three tasks ○ Extractive Reading Comprehension (TechQA-RC) ○ Document Ranking (TechQA-DR) ○ Duplicate Question Detection (AskUbuntu-DQD) 7
- 8. Vocabulary Extension ● Augment the LM vocabulary using frequent in-domain words ○ For 95% coverage ■ TechNotes: 10K new items ■ AskUbuntu: 5K new items ● LM In-Domain training ○ Embeddings of the new vocabulary: randomly initialized and learned during MLM training ○ Existing vocabulary: fine-tuned on domain-specific corpus RoBERTa Vocabulary OOV rate (%) BPE per Token TechQA TechNotes 19.8 1.32 1M Wikipedia Sentences 8.1 1.12 8
- 9. Adaptive Fine-Tuning Open domain unlabeled data In-domain unlabeled data Pre-training (MLM) Adaptive Fine-tuning (MLM) Specialized to the target data RoBERTa Domain-specific vocabulary ● TechNotes ● AskUbuntu web dump ● Wikipedia ● Books ● News ● ... 9
- 10. Task Specific Synthetic Pre-training ● TechQA ○ TechNotes’ sections to generate QA examples ■ Abstract, Error Description, Question → Question ■ Cause, Resolving the Problem → Answer ■ Document → Context ○ 10 unanswerable examples sampled randomly ○ Long answer examples: 115K ● AskUbuntu ○ Accepted answer as positive class and randomly selected answer as negative class: Answer selection as a classification task with a positive:negative ratio of 1:1 ○ 210K synthetic corpus 10
- 11. Behavioral Fine-tuning Open domain unlabeled data In-domain unlabeled data In-domain relevant labeled data Pre-training (MLM) Adaptive Fine-tuning (MLM) Behavioral Fine-tuning Specialized to the target data Specialized to the target task RoBERTa Synthetic Datasets for Auxiliary Tasks ● TechQA: RC-long Answers ● AskUbuntu: Answer Classification 11 Domain-specific vocabulary
- 12. Target Tasks ● TechQA-RC ○ Predict start and end position of the answer span with two separate classifiers ● TechQA-DR, AskUbuntu-DQD ○ Classify the [CLS] token at the final layer with a binary classifier ○ During inference, rank according to classification score ● Data Augmentation for TechQA ○ Data perturbation (random deletion, duplication, dropping title, removing stop words, etc) ○ Training size increased by 10 times 12
- 13. Tech Domain Adaptation Open domain unlabeled data In-domain unlabeled data In-domain relevant labeled data In-domain labeled data Pre-training (MLM) Adaptive Fine-tuning (MLM) Behavioral Fine-tuning Target Task Fine-tuning Specialized to the target data Specialized to the target task RoBERTa ● TechQA-RC ● TechQA-DR ● AskUbuntu-DQD 13 Domain-specific vocabulary
- 14. Results on TechQA-RC Task 14
- 15. TechQA Leaderboard - First Place 15
- 16. Results on TechQA-DR Task 16
- 17. Results on AskUbuntu-DQD Task 17
- 18. Recap: Tech Domain Adaptation ● Beneficial to extend the vocabulary of the LM for target domain in addition to fine-tuning on domain-specific corpora ● Structure in unlabeled in-domain data can be utilized as synthetic data for auxiliary tasks ● Extending pre-training with auxiliary tasks trained on synthetic data results in effective domain adaptation 18
- 19. Roadmap ● Domain Adaptation ○ Adapting pre-trained language model to a new domain via vocabulary extension and auxiliary tasks ● Knowledge Distillation ○ Synthetic data generation for multilingual dependency parsers ● Cross-lingual Embeddings ○ Zero-shot transfer of urgency detection for low-resource languages 19
- 20. Scalable Cross-lingual Treebank Synthesis for Improved Production Dependency Parsers In collaboration with Yousef El-Kurdi, Hiroshi Kanayama, Todd Ward, Vittorio Castelli, and Hans Florian Work done at IBM Research 20 Proceedings of the 28th International Conference on Computational Linguistics: Industry Track. 2020
- 21. Multilingual Dependency Parsing ● Dependency parsers captures syntactic structure of sentences ○ Universal Dependencies (UD) treebanks available in many languages ○ Limited amount for some languages, can be topical or can contain errors ● Our Approach: Biaffine-attention parser trained with monolingual and multilingual pre-trained language models 21
- 22. Production Parser ● Production requirements ○ Accuracy, response time, hardware constraints e.g. GPU ● Knowledge Distillation ○ Compact student trained to recover predictions of a highly accurate but large model that does not meet the resource constraints ○ Teacher transfers knowledge to the student by exposing its label predictions → producing pseudo-labels for unlabeled data 22
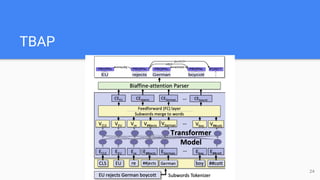
- 23. Transformer Enhanced Biaffine-Attention Parser (TBAP) ● Transformer LM provides contextualized representation for the sentences to the biaffine parser ○ Last four layers of the encoder ○ Merge word-pieces back into words by either averaging, max-pooling or taking the first subword representation ● Stanford NLP (SNLP) for biaffine parser implementation ● UD Treebanks v2.6 ● Evaluation metric: Labeled Attachment Score (LAS) 23
- 24. TBAP 24
- 25. Monolingual & Multilingual Transformer Models 25
- 26. Knowledge Distillation 26 Pre-trained Multilingual LM Neural-Net Parser TBAP Model TBAP Multilingual UD Treebanks Multilingual Unlabeled Text Synthetic UD Treebanks Production Parser Train
- 27. Results of the Production Parser 27 +2.7 +3.0 +2.8 +4.3 +1.6 +5.0 +4.3
- 28. LAS against the size of Synthetic Training Corpora 28
- 29. Recap: Multilingual Dependency Parsing ● Transformer enhanced biaffine parser (TBAP) captures monolingual and multilingual contextual representations via pretrained LMs ● Knowledge distillation from highly accurate teacher (TBAP) to resource-constrained student (production parser) by generating synthetic data 29
- 30. Roadmap ● Domain Adaptation ○ Adapting pre-trained language model to a new domain via vocabulary extension and auxiliary tasks ● Knowledge Distillation ○ Synthetic data generation for multilingual dependency parsers ● Cross-lingual Embeddings ○ Zero-shot transfer of urgency detection for low-resource languages 30
- 31. Detecting Urgency Status of Crisis Tweets: A Transfer Learning Approach for Low Resource Languages In collaboration with Linyong Nan, Bohan Qu, Mona Diab and Kathleen McKeown Work done at Columbia University 31 Proceedings of the 28th International Conference on Computational Linguistics. 2020
- 32. Urgency Detection for Low-resource Languages ● Provide situational awareness for low-resource languages by predicting urgency status of emergent incidents ● Many corpora exists for sentiment and emotion but not for urgency ● Crisis tweets from past natural and human-induced disasters available for high-resource languages1 1: https://crisisnlp.qcri.org/ 32 ● Our Approach: Annotate a small subset of crisis tweets in English, train an English urgency classifier and then transfer it to low-resource languages
- 33. English Urgency Labels ● Figure-Eight (Appen) crowdsourcing platform ● 4 levels of urgency to capture intensity ● From multiple categories to binary ○ {Extremely Urgent, Definitely Urgent} → True ○ {Somewhat Urgent, Not Urgent} → False ○ Binary urgency ratio: 26.7% Labels Total True % IAA Extremely Urgent 134 6.98 69.88 Definitely Urgent 378 19.7 72.63 Somewhat Urgent 589 30.79 53.69 Not Urgent 818 42.61 78.02 1,919 33 Dataset available at https://github.com/niless/urgency Extremely Urgent: “my uncle is in kathmandu, trapped, suffers from jaundice, chest infection,diabetes, his number #NepalQuake”
- 35. English Urgency Classifier ● Embeddings ○ In-domain & non-contextual: CrisisNLP ○ Out-of-domain ■ Non-contextual: fastText ■ Contextual: BERT, RoBERTa, XLM-R ● Architectures ○ Support Vector Machines (SVM), Random Forests1 ○ Multi Layer Perceptron (MLP), Convolutional Neural Network (CNN)2 ○ Sequence classification with contextual language models using transformers library3 1: https://scikit-learn.org/ 2: https://github.com/CrisisNLP/deep-learning-for-big-crisis-data 3.https://huggingface.co/transformers/ Figure: MLP Architecture 35
- 36. Data Augmentation and Ensembling ● Self-training ○ Add a classifier’s predictions on unlabeled data to the original data if there is agreement over three classifiers ○ Repeat several times and test the performance at various sizes {3K, 10K, 16K, 20K} ■ The best performance is at ~16K ● Ensembling ○ Ensemble various classifiers by vote ○ Predict positive if any of the models predict positive Dataset Size % of Urgent Samples Original 1,919 26.7% Original+Synthetic 16,243 18.5% 36
- 37. English Urgency Classification Results 37 Embeddings Embedding Type Classifier F1 Score In Domain Contextual Original Data Augmented Data CrisisNLP x - RF 55.9 66.8 x - SVM 41.9 61.9 x - MLP 70.5±1.3 64.6±1.0 x - CNN 69.0±1.4 63.2±0.6 fastText - - MLP 65.8±1.4 61.6±0.9 - - CNN 59.8±1.7 63.2±3.6 BERT-base - x FT 71.9 71 BERT-large - x FT 75.2 75.6 RoBERTa-large - x FT 75.7 75.6 XLM-mlm-en - x FT 71.3 74.6 Ensemble F1 Score: 76.5
- 38. Cross-lingual Urgency Classifiers for Low Resource Languages: Sinhala and Odia 38
- 39. Low Resource Languages: Sinhala and Odia ● Sinhala: spoken primarily in Sri Lanka ○ “ඇසින් දුටූූවන් උපුටා දක්වමින් විෙදස් ප්රවෘත්ති ෙස්වා සඳහන් කෙළේ ඇතැම් ස්ථානවල දැනටමත් ලාවා ගලා යාමට පටන් ෙගන ඇති අතර , එහි සල්ෆර් සහ දැෙවන ශාක වල ගන්ධය අඝ්රාණය වන බවයි .” ○ “Foreign news agencies quoted eyewitnesses as saying that lava had already begun to flow in some places, smelling the sulfur and burning plants.” ● Odia(Oria): spoken in the Indian state of Odisha ○ “ଫଳେର ଘଣ୍ଟା ଘଣ୍ଟା େରାଗୀମାେନ ହନ୍ତସନ୍ତ େହବାର େଦଖିବାକୁ ମିଳିଥିଲା । ○ As a result, patients were seen dying for hours.” Language Native Informant Parallel Corpora Total True % # of Sentences Sinhala 181 7.7% 415,042 Odia 510 16.1% 454,540 39
- 40. English Monolingual Embedding IL Monolingual Embedding Parallel Corpora English Training Data with Labels Align Words & Extract Dictionary Bilingual Dictionary Train Cross-lingual Embedding Cross-lingual Embedding Train Urgency Classifier Cross-lingual Classifier INPUT CROSS-LINGUAL LEARNING CROSS-LINGUAL OUTPUT Transfer Learning in Zero-Shot Setting 40 fastText LORELEI fast align CrisisNLP + Figure-Eight VecMap ProcB CNN MLP 72K vocabulary 300 dimension Urgency Classifiers ● English-Sinhala ● English-Odia
- 41. Cross-lingual Urgency Classification Results 41 Embeddings Contextual Classifier F1 Score Sinhala Odia Original Data Augmented Data Original Data Augmented Data ProcB - MLP 54.6±5.1 57.3±3.8 53.3±3.4 54.7±4.3 - CNN 48.7±2.3 51.9±3.6 53.1±2.2 51.1±1.9 VecMap - MLP 52.3±4.7 54.2±3.9 53.0±3.4 56.4±2.1 - CNN 48.9±2.1 51.1±3.0 53.4±2.3 54.0±1.2 LASER x FT 62.1 58.9 - - XLM-R (base) x FT 54.2 54.6 47.9 61.3 XLM-R (large) x FT 54.8 59.2 49.2 54.7 Ensemble F1 score for Sinhala: 63.5 Ensemble F1 score and for Odia: 62.6
- 42. Recap: Zero-Shot Urgency Classification ● Limited amount of annotated data in source language English and no training data for target low resource languages ● Pre-trained multilingual contextual embeddings perform the best ● In the absence of pre-trained model for a low resource language, similar performance is achieved by training cross-lingual embeddings from parallel corpora 42
- 43. MultiSeg: Parallel Data and Subword Information for Learning Bilingual Embeddings in Low Resource Scenarios In collaboration with Vishal Anand and Smaranda Muresan Work done at Columbia University 43 Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL). 2020
- 44. Representing Subwords in Cross-lingual Space ● fastText: monolingual word embeddings that take into account subword information-->words as bag of character n-grams ● Bilingual SkipGram (BiSkip) ○ Trains 4 SkipGram models jointly between two languages l1 and l2 based on word and sentence alignments: 44
- 45. MultiSeg: Cross-lingual Embeddings Learned with Subword Information ● Train BiSkip like model using various subword representations ● MultiSegCN : Character n-grams ● Morphemes obtained by unsupervised morphological segmentation ○ MultiSegM : Three segments: prefix + stem + suffix ○ MultiSegMall : stem + afixes ● MultiSegBPE : Byte Pair Encoding (BPE) ● MultiSegAll : Char n-grams, morphological segments, BPE 45 Code available at https://github.com/vishalanand/MultiSeg
- 46. Dataset for Low Resource Languages ● Three morphologically rich low resource languages: Swahili (SW), Tagalog(TL), Somali (SO) ○ IARPA Machine Translation for English Retrieval of Information in Any Language (MATERIAL) project’s parallel corpora ● German, a high resource morphologically rich language ○ EuroParl (1,908,920) subsampled to 100K to simulate low resource scenario 46
- 48. t-SNE Visualization for English-Tagalog Vectors 48
- 49. Cross-Language Document Classification (CLDC) ● A document classifier trained on language {en,de} tested on documents from language {de,en} ○ Train on 1,000 documents and test on 5,000 documents 49 BiSkip MultiSegCN MultiSegM MultiSegMall MultiSegBPE MultiSegAll Dimension 40 300 40 300 40 300 40 300 40 300 40 300 eng-->deu 0.828 0.839 0.814 0.812 0.841 0.861 0.836 0.864 0.812 0.846 0.822 0.828 deu-->eng 0.666 0.667 0.662 0.69 0.71 0.734 0.724 0.652 0.72 0.723 0.631 0.713
- 50. Recap: MultiSeg ● Learning subwords during training of cross-lingual embeddings ● Better-quality cross-lingual embeddings particularly for morphological variants in both languages ● Successful zero-shot transfer learning between German and English in Cross Language Document Classification task 50