【メタサーベイ】Video Transformer
3 likes3,585 views

cvpaper.challenge の メタサーベイ発表スライドです。 cvpaper.challengeはコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ作成・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。 http://xpaperchallenge.org/cv/


































![High-Performance Discriminative Tracking with Transformers
● [問題点]・・・背景情報を有効に利用した最新の追
跡方式でも,回帰モデルの識別性やロバストな追跡
,追跡パイプラインの分離の改善には限界がある
● [貢献点]・・・ロバストな追跡のための背景情報の
利用・従来の識別追跡パイプラインの簡略化を実現
● [提案手法]・・・Transfomerの関係モデル化に基
づく特徴埋め込みを行うことで,学習画像の強力な
識別表現を含むことができ,ロバストな追跡が可能
● [結果]・・・GOT10k、LaSOT、NfS、
TrackingNetの4つのベンチマークにおいて、
50FPS以上で動作し、評価指標「AUC」において
は従来手法より有効的かつ効率的であることを確認
36
著者:Bin Yu, Ming Tang, Linyu Zheng, Guibo Zhu, Jinqiao Wang, Hao Feng, Xuetao Feng,
Hanqing Lu
会議名:ICCV 2021
視覚的な追跡(Visual Tracking)に対してTransformerを導入
スライド作成者:近藤](https://image.slidesharecdn.com/videotransformer-220830002056-535f98d8/85/Video-Transformer-36-320.jpg)
![Transformer Tracking
37
著者:Xin Chen, Bin Yan, Jiawen Zhu , Dong Wang, Xiaoyun Yang and Huchuan Lu
会議名:CVPR 2021
スライド作成者:
● [問題点]・・・追跡分野における相関演算は,線形マッチング処理による特徴量の損失に繋がるため,追跡のボトルネック
となっている
● [貢献点]・・・テンプレートと探索領域の特徴を相関関係なしに結合することで特徴量の損失を防ぐ
● [提案手法]・・・注意メカニズムのみを考慮したテンプレートと探索領域の特徴を,ECA・CFAモジュールで結合しより多
くの特徴量を取得
● [結果]・・・LaSOT、TrackingNet、GOT-10kベンチマークにおいて、約50FPSで動作し,評価指標「AUC」においては
従来手法より有効的かつ効率的であることを確認
追跡分野における特徴量融合手法にTransformerを導入](https://image.slidesharecdn.com/videotransformer-220830002056-535f98d8/85/Video-Transformer-37-320.jpg)





【メタサーベイ】Video Transformer
- 1. Video × Transformer 原 健翔,橋口 凌大,篠田 理沙,斎藤 巧真,近藤 拓未
- 2. はじめに ● cvpaper.challengeにおける2022年のメタサーベイとして videorecogグループをはじめとしたメンバーにより作成 ● 動画を対象としてTransformerを用いた論文40本(予定)を調査し まとめたサーベイ資料 ○ 対象領域のすべての論文を網羅できているわけではありません ● Transformerについての基本的な話や画像認識への応用については 別の資料をご参照ください ○ Transformerメタサーベイ https://www.slideshare.net/cvpaperchallenge/transformer-247407256 2
- 3. 動画へのTransformerの適用 ● 2021年ごろから動画の各種タスクにTransformerを導入した研究が 次々と登場 ○ 基本的な動画認識タスクから始まり 時空間シーングラフ生成など複雑なタスクへの応用も急速に進展 ○ 動画だけでなく画像や言語,音声などと合わせてマルチモーダルな手法も多数登場 ○ 1年半で40本以上もの論文が登場 3
- 4. 動画認識へのTransformer導入のモチベーション ● 時系列の長期的な依存関係を捉えられる認識モデルとして Transformerが有望視 ○ 元々Transformerは動画と同様に系列データを扱う自然言語で提案されたモデル ○ 局所的な畳み込み計算を用いるCNNとは異なり Transformerは系列全体での自己注意を計算することで 動画中の時系列の長期的な相関などを考慮することが可能 ○ 新たに動画タスクにTransformerを導入した論文は 大体このお決まりの理由を挙げて手法を提案 4
- 5. Transformerの導入方法|入力 動画をフレーム毎のベクトル列に してからTransformerに入力 5 D. Neimark+, “Video Transformer Network”, ICCVW 2021. A. Arnab+, “ViViT: A Video Vision Transformer”, ICCV 2021. 動画をパッチの系列に してからTransformerに入力
- 6. Transformerの導入方法|マルチモーダル入力 各モダリティをトークンの系列に変換してしまえば モダリティの差を吸収して同様に利用可能 6 R. Girdhar+, “OMNIVORE: A Single Model for Many Visual Modalities”, CVPR 2022. A. Botach+, “End-to-End Referring Video Object Segmentation with Multimodal Transformers”, CVPR 2022.
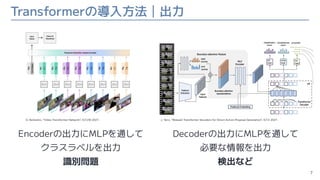
- 7. Transformerの導入方法|出力 Encoderの出力にMLPを通して クラスラベルを出力 識別問題 7 D. Neimark+, “Video Transformer Network”, ICCVW 2021. Decoderの出力にMLPを通して 必要な情報を出力 検出など J. Tan+, “Relaxed Transformer Decoders for Direct Action Proposal Generation”, ICCV 2021.
- 8. Transformerが導入された動画系タスクの例 ● Action/Video Recognition ● Action Localization, Proposal Generation, Detection ● Video Instance Segmentation ● Object Tracking ● Video Super Resolution ● Video Frame Interpolation 8
- 9. 識別問題用のモデルが矢継ぎ早に登場 ● 2021年ごろから次々に論文が(主に企業から)投稿されるように ○ TimeSformer (FAIR), 2021/2/9, ICML2021 ○ STAM (Alibaba), 2021/3/25 ○ ViViT (Google), 2021/3/29, ICCV2021 ○ X-ViT (Samsung), 2021/6/10, NeurIPS2021 ○ Video Swin Transformer (Microsoft), 2021/6/24 ○ PolyViT (Google), 2021/11/25 ○ BEVT (Microsoft), 2021/12/2, CVPR2022 ○ VideoMAE (Tencent), 2022/3/23 ○ MAE (FAIR), 2022/5/18 9 インターン,大学との共同研究も含む
- 10. 基本的な動画認識用のTransformer|ViViT 10 ● 動画をトークンの系列に変換 ● Encoderに入力 ○ Self-AttentionとMLPの繰り返し ● Classification Tokenを MLPに通して識別 A. Arnab+, “ViViT: A Video Vision Transformer”, ICCV 2021.
- 11. 基本的な動画認識用のTransformer|ViViT 11 ● トークンへの変換方法 ○ フレーム毎に パッチに分割して埋め込み ○ 複数フレーム (T=2) をまとめて パッチに分割して埋め込み Uniform Frame Sampling Tubelet Embedding A. Arnab+, “ViViT: A Video Vision Transformer”, ICCV 2021.
- 12. 基本的な動画認識用のTransformer|ViViT 12 ● Encoderの実装 ○ フレーム毎にEncoderに通した後に 時間方向を処理するEncoderに 再度入力 ○ 空間方向と時間方向それぞれでの Self-Attentionを交互に計算 Factorised Encoder Factorised Self-Attention A. Arnab+, “ViViT: A Video Vision Transformer”, ICCV 2021.
- 13. 基本的な動画認識用のTransformer|ViViT 13 ● 既にCNNベースの手法を 上回る認識精度を達成 ○ 少ない計算量で高い精度 ○ CNNベースのSlowFastやX3Dは スクラッチ学習なのに対して ViViTはImageNetでPretrain しているのでその点には注意 A. Arnab+, “ViViT: A Video Vision Transformer”, ICCV 2021.
- 14. 動画認識へのTransformer導入の利点と欠点 ● 利点 ○ 高精度(モデルの規模やデータ量による) ○ 画像認識のモデルを流用しやすい ○ マルチモーダルなデータを扱いやすい ● 欠点 ○ 必要なメモリが大きい 14
- 17. Is Space-Time Attention All You Need for Video Understanding? ● 画像認識で成功したViTを 動画に適用するように拡張した TimeSformerを提案 ● 時間方向と空間方向を分けて 自己注意を計算するDivided Space-Time Attentionが 最も良い性能を達成 ● 3D CNNよりも速く学習可能で 推論時の計算効率も良いという結果 17 著者:Gedas Bertasius, Heng Wang, Lorenzo Torresani 会議名:ICML 2021 動画認識に時空間の自己注意を用いるTransformerを導入 スライド作成者:原
- 18. ViViT: A Video Vision Transformer ● ViTを動画に適用するためにパッチの切り方や自己注意の計算方法を検討 ● パッチは複数フレームにまたがるTubelet Embeddingが有効 ● 各フレームで空間方向の自己注意を計算しきってから後で時間方向の自己注意を 計算するFactorised Encoderが性能と効率のバランスが良い 18 著者:Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid 会議名:ICCV 2021 動画認識に時空間の自己注意を用いるTransformerを導入 スライド作成者:原
- 19. BEVT: BERT Pretraining of Video Transformers ● 自然言語でのBERTのようにランダム なパッチにマスクをかけてマスク内 の画素を推定することでViTを学習 ● 画像・動画それぞれで空間的・ 時間的な特徴を獲得するという戦略 ● 静止的な特徴が重要なKinetics-400 でSOTAに匹敵,時間的な情報が重要 なSomething-Something, Diving48 ではSOTAを超える性能を達成 19 著者:Rui Wang, Dongdong Chen, Zuxuan Wu, Yinpeng Chen, Xiyang Dai, Mengchen Liu, Yu-Gang Jiang, Luowei Zhou, Lu Yuan 会議名:CVPR 2022 画像と動画を用いたマスク領域の復元タスクを学習することで高い性能を達成 スライド作成者:原
- 20. VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training ● 画像のMAEを動画で行うためにマスク方法などを検討した研究 ● 動画では複数フレームで冗長な情報があるため画像よりも高いマスク割合の方 が良い性能を達成可能,数千動画という小規模データでもVideoMAEでの学習に より高い性能を達成可能,などの結果が得られた 20 著者:Zhan Tong, Yibing Song, Jue Wang, Limin Wang 会議名:arXiv, 2022 画像認識で提案されたMAEを動画認識に応用 スライド作成者:原
- 21. Video Transformer Network ● 任意の2Dモデルの空間特徴量に時間 方向にTransformerにかけるVTNを 提案 ● Longformerを用いることによりク リップのフレーム数が増えても効率 的な推論が可能 ● ビデオ全体をまとめて推論できるた め、従来の手法と同等の性能のまま 計算量削減 21 著者:Daniel Neimark, Omri Bar, Maya Zohar, Dotan Asselmann 会議名:ICCV Workshop 2021 動画認識に時空間の自己注意を用いるTransformerを導入 スライド作成者:橋口
- 22. An Image is Worth 16×16 Words, What is a Video Worth? ● ViTを動画に適用するためにViTで抽出 した特徴量を時間方向のTransformerに かけることで動画認識に拡張する ● すべてのフレームでAttentionを取るこ とから大域的な時間でまとめて処理 ● 疎にサンプリングしたクリップで学習推 論を行うことで高精度かつ計算コストの 削減に貢献 22 著者:Gilad Sharir, Asaf Noy, Lihi Zelnik-Manor 会議名:arXiv 2021 動画認識に時空間の自己注意を用いるTransformerを導入 スライド作成者:橋口
- 23. Token Shift Transformer for Video Classification ● ViTで付与するCLS Tokenを時間方向にシフトすることでViTを動画認識に拡張 ● ViTにシフト操作のみを追加するため追加のパラメータを必要とせず計算量不変 ● フレーム間の時間相互作用はTokenを介して行い、3D CNNと同等の精度を達成 23 著者:Hao Zhang, Yanbin Hao, Chong-Wah Ngo 会議名:ACMMM 2021 特徴量シフトによりTransformerを動画認識に拡張 スライド作成者:橋口
- 24. Space-time Mixing Attention for Video Transformer ● 3D CNNのように隣接フレーム間でAttentionをとるモデル構造をTransformerに導入 ● そのまま拡張するとViTの学習済みモデルが使えないためシフト操作を導入することにより 隣接フレーム間の情報を混ぜた特徴でAttentionをとる構造を提案 24 著者:Adrian Bulat, Juan Manuel Perez Rua, Swathikiran Sudhakaran, Brais Martinez, Georgios Tzimiropoulos 会議名:NeurIPS 2021 特徴量シフトによりTransformerを動画認識に拡張 スライド作成者:橋口
- 25. PolyViT: Co-training Vision Transformers on Images, Videos and Audio ● パラメータを共有しつつ、異なるタスクをまとめて学習するアーキテクチャを提案 ● データの組み合わせごとにパタメータを調整する必要はなく、シングルタスク学習 で得られたパラメータを適用するだけでよい ● 動画と音声の分類でSOTAを達成 25 著者:Valerii Likhosherstov, Anurag Arnab, Krzysztof Choromanski, Mario Lucic, Yi Tay, Adrian Weller, Mostafa Dehghani 会議名:arXiv, 2021 画像、動画、音声をまとめてTransformerで学習 スライド作成者:篠田
- 26. Action Localization, Action Proposal Generation, Action Detection 26
- 27. Relaxed Transformer Decoders for Direct Action Proposal Generation ● 行動の境界が曖昧なことを考慮して出力と正解とのマッチングを取る際に 厳密な1対1の対応ではなく緩和したマッチングを行うRelaxed Matcherを提案 ● 各フレームの特徴表現に境界の情報(開始,終了のスコア)を追加する Boundary-attentive Moduleの追加なども行いDETRから改善 27 著者:Jing Tan, Jiaqi Tang, Limin Wang, Gangshan Wu 会議名:ICCV 2021 物体検出用TransformerのDETRを行動候補領域生成に応用 スライド作成者:原
- 28. Temporal Alignment Networks for Long-term Video ● HowTo100M(インストラクション動画に話者の字幕が付与されたデータセット)を利用 ● 字幕に含まれるノイズ(動画の内容とは無関係,時間的にずれているなど)を 除去しながら学習する手法を提案 ● 動画とテキストをマルチモーダルにTransformerで処理するJoint Encoderと 独立に扱い動画のみTransformerで処理するDual Encoderを同時に学習しながら 両者の出力の整合性を取るような形で学習 28 著者:Tengda Han, Weidi Xie, Andrew Zisserman 会議名:arXiv, 2022 動画とテキストの対応付けをTransformerにより実現 スライド作成者:原
- 29. TubeDETR: Spatio-Temporal Video Grounding with Transformers ● テキストのクエリから画像中の物体を検出するMDETRを動画に拡張し 事前に物体候補領域抽出などが不要なシンプルな構造で本タスクを実現 ● Video-Text Encoderでは間引いた動画フレームとテキストを合わせて マルチモーダルな表現を効率的に獲得するSlow multi-modal branchと 軽量なFast visual-only branchを合わせることで効率的に計算できるように工夫 29 著者:Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, Cordelia Schmid 会議名:CVPR 2022 テキストクエリから動画中のTubeを出力するタスクにTransformerを導入 スライド作成者:原
- 31. ● Tranceformerを動画内の領域分割に導入し、既存手法を上回る精度、速度を達成 ● 1. CNNで特徴量を抽出し、2. ピクセル、インスタンス単位での特徴量の関連度をTransformerエ ンコーダで計算し、3. フレームごとにインスタンスの特徴量をTransformerデコーダで計算す る。その後、4.フレーム間でのインスタンスの相対的な位置情報を予測しつつ、インスタンス毎 のマスクも予測する。 31 著者:Yuqing Wang, Zhaoliang Xu, Xinlong Wang, Chunhua Shen, Baoshan Cheng, Hao Shen, Huaxia Xia 会議名:CVPR 2021 インスタンスセグメンテーションにTransformerを導入 スライド作成者:篠田 End-to-End Video Instance Segmentation With Tranceformers
- 32. End-to-End Referring Video Object Segmentation with Multimodal Transformers ● Multi-modalなTransformerを 用いることで従来よりもシンプルな パイプラインで従来手法を上回る 性能を達成 ● 提案手法はテキストと動画から それぞれ特徴抽出した後に Multimodal Transformer (DETR) を通して各物体インスタンスを推定, 最後にFPN-likeなDecoderで 最終的な出力を獲得 32 著者:Adam Botach, Evgenii Zheltonozhskii, Chaim Baskin 会議名:CVPR 2022 テキストクエリを入力とした動画中の物体領域分割をTransformerで実現 スライド作成者:原
- 34. TransMOT: Spatial-Temporal Graph Transformer for Multiple Object Tracking ● MOTのための新たな時空間グラフTransformer(TransMOT)を提案。 ● Transformerの計算の前に動画内の追跡対象の物体を重み付きグラフ構造で入手。 その後に動画の時空間情報をエンコーダで計算。重み付きグラフ構造をデコーダで 計算。その結果、複数の物体間の相互作用をモデル化。また、低スコア検出や長期 間のオクルージョンを扱うためにcascade association frameworkを利用。 ● 従来手法よりも計算効率と追跡精度が向上。 34 著者:Peng Chu,Jiang Wang,Quanzeng You,Haibin Ling,Zicheng Liu 会議名:arXiv, 2022 複数物体の追跡(MOT)タスクにTransformerを導入。 スライド作成者:齊藤
- 35. MeMOT: Multi-Object Tracking with Memory ● メモリエンコーディングで追跡物体のコア情報を抽出し、メモリデコードで物体検出とデータ 関連付けタスクを同時に行う。 ● 追跡された物体全ての時空間情報を長期に保持することができ、物体間のリンクに必要な情報 を効率的に取得する。 35 著者:Jiarui Cai, Mingze Xu, Wei Li, Yuanjun Xiong, Wei Xia, Zhuowen Tu, Stefano Soatto 会議名:CVPR2022 Tranceformerを導入し、長期の物体追跡を実現 スライド作成者:篠田
- 36. High-Performance Discriminative Tracking with Transformers ● [問題点]・・・背景情報を有効に利用した最新の追 跡方式でも,回帰モデルの識別性やロバストな追跡 ,追跡パイプラインの分離の改善には限界がある ● [貢献点]・・・ロバストな追跡のための背景情報の 利用・従来の識別追跡パイプラインの簡略化を実現 ● [提案手法]・・・Transfomerの関係モデル化に基 づく特徴埋め込みを行うことで,学習画像の強力な 識別表現を含むことができ,ロバストな追跡が可能 ● [結果]・・・GOT10k、LaSOT、NfS、 TrackingNetの4つのベンチマークにおいて、 50FPS以上で動作し、評価指標「AUC」において は従来手法より有効的かつ効率的であることを確認 36 著者:Bin Yu, Ming Tang, Linyu Zheng, Guibo Zhu, Jinqiao Wang, Hao Feng, Xuetao Feng, Hanqing Lu 会議名:ICCV 2021 視覚的な追跡(Visual Tracking)に対してTransformerを導入 スライド作成者:近藤
- 37. Transformer Tracking 37 著者:Xin Chen, Bin Yan, Jiawen Zhu , Dong Wang, Xiaoyun Yang and Huchuan Lu 会議名:CVPR 2021 スライド作成者: ● [問題点]・・・追跡分野における相関演算は,線形マッチング処理による特徴量の損失に繋がるため,追跡のボトルネック となっている ● [貢献点]・・・テンプレートと探索領域の特徴を相関関係なしに結合することで特徴量の損失を防ぐ ● [提案手法]・・・注意メカニズムのみを考慮したテンプレートと探索領域の特徴を,ECA・CFAモジュールで結合しより多 くの特徴量を取得 ● [結果]・・・LaSOT、TrackingNet、GOT-10kベンチマークにおいて、約50FPSで動作し,評価指標「AUC」においては 従来手法より有効的かつ効率的であることを確認 追跡分野における特徴量融合手法にTransformerを導入
- 39. Learning Trajectory-Aware Transformer for Video Super-Resolution ● 長い時系列の情報を扱うことが重要な動画の超解像に対してTransformerを導入 ● 事前に物体のモーションを推定して各トークンを軌跡に基づいて整列し 軌跡内のトークンでのみ自己注意を計算することで計算コストを削減し 長期間の時系列の扱いを可能とした手法を提案 39 著者:Chengxu Liu, Huan Yang, Jianlong Fu, Xueming Qian 会議名:CVPR 2022 計算コストを削減しつつ動画超解像にTransformerを導入 スライド作成者:原
- 41. Video Frame Interpolation Transformer ● CNNはConvの重みが入力に依存せず一定であることや長期間の依存関係を 表現できないことがフレーム補間では問題としてTransformerの導入を提案 ● メモリや計算の効率を良くするために 局所的な自己注意 (Swin Transformer)や時間と空間を分けた自己注意を提案 41 著者:Zhihao Shi, Xiangyu Xu, Xiaohong Liu, Jun Chen, Ming-Hsuan Yang 会議名:CVPR 2022 Transformerを動画フレーム補間に応用 スライド作成者:原
- 42. まとめ ● 様々な動画認識タスクでTransformerの導入が活発に研究 ○ 導入初期ということもあってか多くの研究で類似した動画タスクへの拡張方法が提案 ○ 今後タスクごとに細分化された手法になっていくのか それとも多くのタスクが類似した手法で解かれるようになるのかが注目ポイント? ● 動画系タスクでTransformerがCNNを置き換えるのかに今後注目 ○ 性能面では既にCNNよりも良くなっている手法・タスクが多い ○ 要求するメモリの大きさがネックになるかどうか 42