Db2s1z80
0 recomendaciones871 vistas

Este documento proporciona información sobre la versión 8 de IBM DB2 Universal Database SQL Reference Volume 1. Cubre conceptos clave de bases de datos relacionales y SQL, incluyendo tablas, vistas, índices, autorización, tipos de datos y expresiones.



























































































































![archivo. (La opción es
SQL-FILE-APPEND en
COBOL, sql_file_append en
FORTRAN y APPEND en
REXX.)
Longitud de datos
No se utiliza en la entrada. En la
salida, la implantación establece la
longitud de datos en la longitud de
los nuevos datos grabados en el
archivo. La longitud se mide en bytes.
Como sucede con el resto de variables del lenguaje principal, una variable de
referencia a archivos puede tener asociada una variable de indicador.
Ejemplo de una variable de referencia a archivos de salida (en C): Suponga
una sección de declaración codificada como:
EXEC SQL BEGIN DECLARE SECTION
SQL TYPE IS CLOB_FILE hv_text_file;
char hv_patent_title[64];
EXEC SQL END DECLARE SECTION
Una vez procesada:
EXEC SQL BEGIN DECLARE SECTION
/* SQL TYPE IS CLOB_FILE hv_text_file; */
struct {
unsigned long name_length; // Longitud del nombre del archivo
unsigned long data_length; // Longitud de datos
unsigned long file_options; // Opciones de archivo
char name[255]; // Nombre del archivo
} hv_text_file;
char hv_patent_title[64];
EXEC SQL END DECLARE SECTION
El código siguiente puede utilizarse para seleccionar en una columna CLOB
de la base de datos para un nuevo archivo al que :hv_text_file hace referencia.
strcpy(hv_text_file.name, "/u/gainer/papers/sigmod.94");
hv_text_file.name_length = strlen("/u/gainer/papers/sigmod.94");
hv_text_file.file_options = SQL_FILE_CREATE;
EXEC SQL SELECT content INTO :hv_text_file from papers
WHERE TITLE = ’The Relational Theory behind Juggling’;
Ejemplo de una variable de referencia a archivos de entrada (en C):
Tomando la misma sección de declaración que antes, se puede utilizar el
siguiente código para insertar datos de un archivo normal al que :hv_text_file
hace referencia en una columna CLOB.
98 Consulta de SQL, Volumen 1](https://image.slidesharecdn.com/db2s1z80-120211134635-phpapp02/85/Db2s1z80-124-320.jpg)










































































































































































































































































































































































































































































































































































































































































































































































































































































































































Db2s1z80
- 1. ® ™ IBM DB2 Universal Database Consulta de SQL Volumen 1 Versión 8 SC10-3730-00
- 3. ® ™ IBM DB2 Universal Database Consulta de SQL Volumen 1 Versión 8 SC10-3730-00
- 4. Antes de utilizar esta información y el producto al que da soporte, asegúrese de leer la información general incluida en el apartado Avisos. ® ™ Esta publicación es la traducción del original inglés IBM DB2 Universal Database SQL Reference, Volume 1, SC09-4844-00. Este documento contiene información sobre productos patentados de IBM. Se proporciona según un acuerdo de licencia y está protegido por la ley de la propiedad intelectual. La presente publicación no incluye garantías del producto y las declaraciones que contiene no deben interpretarse como tales. Puede realizar pedidos de publicaciones en línea o a través del representante de IBM de su localidad. v Para realizar pedidos de publicaciones en línea, vaya a IBM Publications Center en www.ibm.com/shop/publications/order v Para encontrar el representante de IBM correspondiente a su localidad, vaya a IBM Directory of Worldwide Contacts en www.ibm.com/planetwide Para realizar pedidos de publicaciones en márketing y ventas de DB2 de los EE.UU. o de Canadá, llame al número 1-800-IBM-4YOU (426-4968). Cuando envía información a IBM, otorga a IBM un derecho no exclusivo para utilizar o distribuir dicha información en la forma en que IBM considere adecuada, sin contraer por ello ninguna obligación con el remitente. © Copyright International Business Machines Corporation 1993, 2002. Reservados todos los derechos.
- 5. Contenido Acerca de este manual . . . . . . . . xi Particionamiento de datos entre múltiples A quién va dirigido este manual . . . . . xi particiones . . . . . . . . . . . . 32 Estructura de este manual . . . . . . . xi Bases de datos relacionales distribuidas . . . 33 Una breve visión general del volumen 2 xiii Unidad de trabajo remota . . . . . . 34 Lectura de los diagramas de sintaxis . . . xiii Unidad de trabajo distribuida dirigida por Elementos de sintaxis comunes . . . . . xv aplicación . . . . . . . . . . . . 38 Designador de función . . . . . . . xv Consideraciones sobre la representación de Designador de método . . . . . . . xvii los datos . . . . . . . . . . . . 44 Designador de procedimiento . . . . . xix Sistemas federados de DB2 . . . . . . . 44 Convenios utilizados en este manual . . . xxi Sistemas federados . . . . . . . . . 44 Condiciones de error . . . . . . . . xxi Fuentes de datos . . . . . . . . . 46 Convenios de resaltado . . . . . . . xxi La base de datos federada . . . . . . 48 Documentación relacionada . . . . . . xxi El compilador de SQL y el optimizador de consultas . . . . . . . . . . . . 50 Capítulo 1. Conceptos . . . . . . . . 1 Compensación . . . . . . . . . . 51 Bases de datos relacionales . . . . . . . 1 Sesiones de paso a través . . . . . . 52 Lenguaje de consulta estructurada (SQL) . . . 1 Reiniciadores y módulos de reiniciador . . 53 Autorización y privilegios . . . . . . . . 2 Definiciones de servidor y opciones de Esquemas . . . . . . . . . . . . . 4 servidor . . . . . . . . . . . . 56 Tablas . . . . . . . . . . . . . . 6 Correlaciones del usuario y opciones del Vistas . . . . . . . . . . . . . . 7 usuario. . . . . . . . . . . . . 57 Seudónimos . . . . . . . . . . . . 8 Apodos y objetos de la fuente de datos . . 58 Índices . . . . . . . . . . . . . . 8 Opciones de columna . . . . . . . . 59 Claves . . . . . . . . . . . . . . 9 Correlaciones de tipos de datos . . . . 60 Restricciones . . . . . . . . . . . . 9 Correlaciones de funciones y plantillas de Restricciones de unicidad . . . . . . 10 funciones . . . . . . . . . . . . 63 Restricciones de referencia . . . . . . 11 Opciones de correlación de funciones . . 64 Restricciones de comprobación de tabla . . 14 Especificaciones de índice . . . . . . 65 Niveles de aislamiento . . . . . . . . 15 Consultas . . . . . . . . . . . . . 18 Capítulo 2. Elementos del lenguaje . . . 67 Expresiones de tabla . . . . . . . . . 18 Caracteres. . . . . . . . . . . . . 67 Procesos, simultaneidad y recuperación de Símbolos . . . . . . . . . . . . . 69 aplicaciones . . . . . . . . . . . . 19 Identificadores . . . . . . . . . . . 71 Interfaz de nivel de llamada de DB2 (CLI) y Convenios de denominación y Open Database Connectivity (ODBC) . . . 21 calificaciones de nombre de objeto Programas Conectividad de bases de datos explícitas . . . . . . . . . . . . 71 Java (JDBC) y SQL incorporado para Java Seudónimos . . . . . . . . . . . 77 (SQLJ) . . . . . . . . . . . . . . 22 ID de autorización y nombres de Paquetes . . . . . . . . . . . . . 23 autorización . . . . . . . . . . . 78 Vistas de catálogo . . . . . . . . . . 23 Nombres de columna . . . . . . . . 84 conversión de caracteres . . . . . . . . 23 Referencias a variables del lenguaje Supervisores de sucesos . . . . . . . . 26 principal . . . . . . . . . . . . 91 Activadores . . . . . . . . . . . . 28 Tipos de datos . . . . . . . . . . . 101 Espacios de tablas y otras estructuras de Tipos de datos . . . . . . . . . . 101 almacenamiento. . . . . . . . . . . 30 Números. . . . . . . . . . . . 103 © Copyright IBM Corp. 1993, 2002 iii
- 6. Series de caracteres . . . . . . . . 104 Funciones definidas por el usuario Series gráficas . . . . . . . . . . 106 escalares, de columna, de fila y de tabla . 181 Series binarias . . . . . . . . . . 107 Signaturas de función . . . . . . . 182 Gran objeto (LOB) . . . . . . . . 108 Resolución de función . . . . . . . 183 Valores de fecha y hora . . . . . . . 110 invocación de funciones. . . . . . . 188 Valores DATALINK . . . . . . . . 114 Semántica de vinculación conservadora 189 Valores XML . . . . . . . . . . 116 Métodos . . . . . . . . . . . . . 192 Tipos definidos por el usuario . . . . 117 Métodos definidos por el usuario Promoción de tipos de datos . . . . . 120 externos y SQL . . . . . . . . . 192 Conversiones entre tipos de datos . . . 122 Signaturas de método . . . . . . . 193 Asignaciones y comparaciones . . . . 126 Resolución de métodos . . . . . . . 194 Reglas para los tipos de datos del Invocación de métodos . . . . . . . 198 resultado. . . . . . . . . . . . 145 Asignación dinámica de métodos . . . 199 Reglas para la conversión de series . . . 150 Expresiones . . . . . . . . . . . . 202 Tipos de datos compatibles entre Expresiones son operadores . . . . . 203 particiones . . . . . . . . . . . 153 Expresiones con el operador de Constantes . . . . . . . . . . . . 155 concatenación . . . . . . . . . . 203 Constantes enteras . . . . . . . . 155 Expresiones con operadores aritméticos 206 Constantes de coma flotante . . . . . 156 Dos operandos enteros . . . . . . . 208 Constantes decimales . . . . . . . 156 Operandos enteros y decimales . . . . 208 Constantes de series de caracteres . . . 156 Dos operandos decimales . . . . . . 208 Constantes hexadecimales . . . . . . 157 Aritmética decimal en SQL. . . . . . 208 Constantes de series gráficas . . . . . 157 Operandos de coma flotante . . . . . 209 Registros especiales . . . . . . . . . 158 Tipos definidos por el usuarios como Registros especiales . . . . . . . . 158 operandos . . . . . . . . . . . 209 CLIENT ACCTNG . . . . . . . . 160 Selección completa escalar . . . . . . 210 CLIENT APPLNAME . . . . . . . 161 Operaciones de fecha y hora y duraciones 210 CLIENT USERID . . . . . . . . . 162 Aritmética de fecha y hora en SQL . . . 211 CLIENT WRKSTNNAME . . . . . . 163 Prioridad de las operaciones . . . . . 216 CURRENT DATE . . . . . . . . . 164 Expresiones CASE . . . . . . . . 216 CURRENT DBPARTITIONNUM . . . . 165 Especificaciones CAST . . . . . . . 219 CURRENT DEFAULT TRANSFORM Operaciones de desreferencia . . . . . 222 GROUP . . . . . . . . . . . . 166 Funciones OLAP . . . . . . . . . 223 CURRENT DEGREE . . . . . . . . 167 Funciones XML . . . . . . . . . 230 CURRENT EXPLAIN MODE . . . . . 168 Invocación de métodos . . . . . . . 235 CURRENT EXPLAIN SNAPSHOT . . . 170 Tratamiento de los subtipos . . . . . 236 CURRENT MAINTAINED TABLE TYPES Referencia de secuencia . . . . . . . 237 FOR OPTIMIZATION . . . . . . . 171 Predicados . . . . . . . . . . . . 242 CURRENT PATH . . . . . . . . . 172 Predicados . . . . . . . . . . . 242 CURRENT QUERY OPTIMIZATION . . 173 Condiciones de búsqueda . . . . . . 243 CURRENT REFRESH AGE. . . . . . 174 Predicado básico . . . . . . . . . 246 CURRENT SCHEMA . . . . . . . 175 Predicado cuantificado . . . . . . . 247 CURRENT SERVER . . . . . . . . 176 Predicado BETWEEN . . . . . . . 250 CURRENT TIME . . . . . . . . . 177 Predicado EXISTS . . . . . . . . . 251 CURRENT TIMESTAMP . . . . . . 178 Predicado IN . . . . . . . . . . 252 CURRENT TIMEZONE . . . . . . . 179 Predicado LIKE . . . . . . . . . 255 USER . . . . . . . . . . . . . 180 Predicado NULL . . . . . . . . . 261 Funciones . . . . . . . . . . . . 181 Predicado TYPE . . . . . . . . . 262 Funciones definidas por el usuario externas, de SQL y derivadas . . . . . 181 Capítulo 3. Funciones . . . . . . . . 265 iv Consulta de SQL, Volumen 1
- 7. Resumen de las funciones . . . . . . . 265 DLNEWCOPY . . . . . . . . . . . 361 Funciones agregadas . . . . . . . . . 289 DLPREVIOUSCOPY . . . . . . . . . 364 AVG . . . . . . . . . . . . . . 290 DLREPLACECONTENT . . . . . . . 366 CORRELATION . . . . . . . . . . 292 DLURLCOMPLETE . . . . . . . . . 368 COUNT . . . . . . . . . . . . . 293 DLURLCOMPLETEONLY . . . . . . . 369 COUNT_BIG . . . . . . . . . . . 295 DLURLCOMPLETEWRITE. . . . . . . 370 COVARIANCE. . . . . . . . . . . 297 DLURLPATH . . . . . . . . . . . 372 GROUPING . . . . . . . . . . . 298 DLURLPATHONLY . . . . . . . . . 373 MAX . . . . . . . . . . . . . . 300 DLURLPATHWRITE . . . . . . . . . 374 MIN . . . . . . . . . . . . . . 302 DLURLSCHEME . . . . . . . . . . 376 Funciones de regresión . . . . . . . . 304 DLURLSERVER . . . . . . . . . . 377 STDDEV . . . . . . . . . . . . . 308 DLVALUE . . . . . . . . . . . . 378 380 SUM . . . . . . . . . . . . . . 309 ENCRYPT . . . . . . . . . . . . 382 VARIANCE . . . . . . . . . . . . 310 EVENT_MON_STATE . . . . . . . . 385 Funciones escalares . . . . . . . . . 311 EXP . . . . . . . . . . . . . . 386 ABS o ABSVAL . . . . . . . . . . 312 FLOAT . . . . . . . . . . . . . 387 ACOS. . . . . . . . . . . . . . 313 FLOOR . . . . . . . . . . . . . 388 ASCII . . . . . . . . . . . . . . 314 GETHINT . . . . . . . . . . . . 389 ASIN . . . . . . . . . . . . . . 315 GENERATE_UNIQUE . . . . . . . . 390 ATAN. . . . . . . . . . . . . . 316 GRAPHIC . . . . . . . . . . . . 392 ATAN2 . . . . . . . . . . . . . 317 HASHEDVALUE . . . . . . . . . . 394 ATANH ATANH . . . . . . . . . . 318 HEX . . . . . . . . . . . . . . 396 BIGINT . . . . . . . . . . . . . 319 HOUR . . . . . . . . . . . . . 398 BLOB . . . . . . . . . . . . . . 321 IDENTITY_VAL_LOCAL . . . . . . . 399 CEILING o CEIL . . . . . . . . . . 322 INSERT . . . . . . . . . . . . . 405 CHAR . . . . . . . . . . . . . 323 INTEGER . . . . . . . . . . . . 407 CHR . . . . . . . . . . . . . . 329 JULIAN_DAY . . . . . . . . . . . 409 CLOB . . . . . . . . . . . . . . 330 LCASE o LOWER. . . . . . . . . . 410 COALESCE . . . . . . . . . . . . 331 Función escalar . . . . . . . . . . 411 CONCAT . . . . . . . . . . . . 332 LEFT . . . . . . . . . . . . . . 412 COS . . . . . . . . . . . . . . 333 LENGTH . . . . . . . . . . . . 413 COSH. . . . . . . . . . . . . . 334 LN. . . . . . . . . . . . . . . 415 COT . . . . . . . . . . . . . . 335 LOCATE . . . . . . . . . . . . . 416 DATE . . . . . . . . . . . . . . 336 LOG . . . . . . . . . . . . . . 417 DAY . . . . . . . . . . . . . . 338 LOG10 . . . . . . . . . . . . . 418 DAYNAME . . . . . . . . . . . . 340 LONG_VARCHAR . . . . . . . . . 419 DAYOFWEEK . . . . . . . . . . . 341 LONG_VARGRAPHIC . . . . . . . . 420 DAYOFWEEK_ISO . . . . . . . . . 342 LTRIM . . . . . . . . . . . . . 421 DAYOFYEAR . . . . . . . . . . . 343 Función escalar . . . . . . . . . . 423 >DAYS . . . . . . . . . . . . . 344 MICROSECOND . . . . . . . . . . 424 DBCLOB. . . . . . . . . . . . . 345 MIDNIGHT_SECONDS . . . . . . . . 425 DBPARTITIONNUM . . . . . . . . . 346 MINUTE. . . . . . . . . . . . . 426 DECIMAL . . . . . . . . . . . . 348 MOD . . . . . . . . . . . . . . 427 DECRYPT_BIN y DECRYPT_CHAR . . . 353 MONTH . . . . . . . . . . . . . 428 DEGREES . . . . . . . . . . . . 355 MONTHNAME . . . . . . . . . . 429 DEREF . . . . . . . . . . . . . 356 MQPUBLISH . . . . . . . . . . . 430 DIFFERENCE . . . . . . . . . . . 357 MQREAD . . . . . . . . . . . . 433 DIGITS . . . . . . . . . . . . . 358 MQREADCLOB . . . . . . . . . . 435 DLCOMMENT. . . . . . . . . . . 359 MQRECEIVE . . . . . . . . . . . 437 DLLINKTYPE . . . . . . . . . . . 360 MQRECEIVECLOB . . . . . . . . . 439 Contenido v
- 8. MQSEND . . . . . . . . . . . . 441 WEEK_ISO . . . . . . . . . . . . 518 MQSUBSCRIBE . . . . . . . . . . 443 YEAR . . . . . . . . . . . . . . 519 MQUNSUBSCRIBE . . . . . . . . . 445 Funciones de tabla . . . . . . . . . 520 MULTIPLY_ALT . . . . . . . . . . 447 MQREADALL . . . . . . . . . . . 521 NULLIF . . . . . . . . . . . . . 449 MQREADALLCLOB . . . . . . . . . 523 POSSTR . . . . . . . . . . . . . 450 MQRECEIVEALL . . . . . . . . . . 525 POWER . . . . . . . . . . . . . 452 >MQRECEIVEALLCLOB . . . . . . . 528 QUARTER . . . . . . . . . . . . 453 SNAPSHOT_AGENT . . . . . . . . 531 RADIANS . . . . . . . . . . . . 454 SNAPSHOT_APPL . . . . . . . . . 532 RAISE_ERROR. . . . . . . . . . . 455 SNAPSHOT_APPL_INFO . . . . . . . 536 RAND . . . . . . . . . . . . . 457 SNAPSHOT_BP . . . . . . . . . . 538 REAL . . . . . . . . . . . . . . 458 SNAPSHOT_CONTAINER . . . . . . . 540 REC2XML . . . . . . . . . . . . 459 SNAPSHOT_DATABASE . . . . . . . 542 REPEAT . . . . . . . . . . . . . 465 SNAPSHOT_DBM . . . . . . . . . 547 REPLACE . . . . . . . . . . . . 466 SNAPSHOT_DYN_SQL . . . . . . . . 549 RIGHT . . . . . . . . . . . . . 467 SNAPSHOT_FCM . . . . . . . . . 551 ROUND . . . . . . . . . . . . . 468 SNAPSHOT_FCMPARTITION . . . . . 552 RTRIM . . . . . . . . . . . . . 470 SNAPSHOT_LOCK . . . . . . . . . 553 Función escalar . . . . . . . . . . 471 SNAPSHOT_LOCKWAIT . . . . . . . 555 SECOND . . . . . . . . . . . . 472 SNAPSHOT_QUIESCERS . . . . . . . 557 SIGN . . . . . . . . . . . . . . 473 SNAPSHOT_RANGES . . . . . . . . 558 SIN . . . . . . . . . . . . . . 474 SNAPSHOT_STATEMENT . . . . . . . 560 SINH SINH . . . . . . . . . . . . 475 SNAPSHOT_SUBSECT . . . . . . . . 562 SMALLINT . . . . . . . . . . . . 476 SNAPSHOT_SWITCHES . . . . . . . 564 SOUNDEX . . . . . . . . . . . . 477 SNAPSHOT_TABLE . . . . . . . . . 565 SPACE . . . . . . . . . . . . . 478 SNAPSHOT_TBS . . . . . . . . . . 567 SQRT . . . . . . . . . . . . . . 479 SNAPSHOT_TBS_CFG . . . . . . . . 569 SUBSTR . . . . . . . . . . . . . 480 SQLCACHE_SNAPSHOT . . . . . . . 571 TABLE_NAME. . . . . . . . . . . 484 Procedimientos . . . . . . . . . . 572 TABLE_SCHEMA . . . . . . . . . . 486 GET_ROUTINE_SAR . . . . . . . . 573 TAN . . . . . . . . . . . . . . 489 PUT_ROUTINE_SAR . . . . . . . . 575 TANH . . . . . . . . . . . . . 490 Funciones definidas por el usuario . . . . 577 TIME . . . . . . . . . . . . . . 491 TIMESTAMP . . . . . . . . . . . 492 Capítulo 4. Consultas . . . . . . . . 579 TIMESTAMP_FORMAT . . . . . . . . 494 Consultas de SQL . . . . . . . . . . 579 TIMESTAMP_ISO . . . . . . . . . . 496 Subselección . . . . . . . . . . . 580 TIMESTAMPDIFF. . . . . . . . . . 497 cláusula-select . . . . . . . . . . 581 TO_CHAR . . . . . . . . . . . . 499 cláusula-from . . . . . . . . . . 586 TO_DATE . . . . . . . . . . . . 500 referencia-tabla. . . . . . . . . . 587 TRANSLATE . . . . . . . . . . . 501 tabla-unida . . . . . . . . . . . 591 TRUNCATE o TRUNC . . . . . . . . 504 cláusula-where . . . . . . . . . . 594 TYPE_ID. . . . . . . . . . . . . 506 Cláusula group-by . . . . . . . . 595 TYPE_NAME . . . . . . . . . . . 507 cláusula-having . . . . . . . . . 602 TYPE_SCHEMA . . . . . . . . . . 508 cláusula-order-by . . . . . . . . . 603 UCASE o UPPER . . . . . . . . . . 509 cláusula-fetch-first . . . . . . . . 607 VALUE . . . . . . . . . . . . . 510 Ejemplos de subselecciones . . . . . 607 VARCHAR . . . . . . . . . . . . 511 Ejemplos de uniones . . . . . . . . 610 VARCHAR_FORMAT . . . . . . . . 513 Ejemplos de conjuntos de agrupaciones, VARGRAPHIC . . . . . . . . . . . 515 cube y rollup . . . . . . . . . . 614 WEEK . . . . . . . . . . . . . 517 Selección completa . . . . . . . . . 623 vi Consulta de SQL, Volumen 1
- 9. Ejemplos de una selección completa . . 626 SYSCAT.COLUMNS . . . . . . . . . 685 Sentencia select . . . . . . . . . . 629 SYSCAT.COLUSE . . . . . . . . . . 692 expresión-común-tabla . . . . . . . 629 SYSCAT.CONSTDEP . . . . . . . . . 693 cláusula-update . . . . . . . . . 632 SYSCAT.DATATYPES . . . . . . . . 694 cláusula-read-only . . . . . . . . 632 SYSCAT.DBAUTH . . . . . . . . . 696 cláusula-optimize-for. . . . . . . . 633 SYSCAT.DBPARTITIONGROUPDEF . . . 698 Ejemplos de una sentencia-select . . . . 634 SYSCAT.DBPARTITIONGROUPS . . . . 699 SYSCAT.EVENTMONITORS . . . . . . 700 Apéndice A. Límites de SQL . . . . . 637 SYSCAT.EVENTS . . . . . . . . . . 702 SYSCAT.EVENTS . . . . . . . . . . 703 Apéndice B. SQLCA (área de SYSCAT.FULLHIERARCHIES . . . . . . 704 comunicaciones SQL). . . . . . . . 645 SYSCAT.FUNCMAPOPTIONS . . . . . 705 Descripción de los campos de la SQLCA . . 645 SYSCAT.FUNCMAPPARMOPTIONS . . . 706 Informe de errores . . . . . . . . . 650 SYSCAT.FUNCMAPPINGS. . . . . . . 707 Utilización de SQLCA en sistemas de bases SYSCAT.HIERARCHIES. . . . . . . . 708 de datos particionadas . . . . . . . . 650 SYSCAT.INDEXAUTH . . . . . . . . 709 SYSCAT.INDEXCOLUSE . . . . . . . 710 Apéndice C. SQLDA (área de descriptores SYSCAT.INDEXDEP . . . . . . . . . 711 de SQL). . . . . . . . . . . . . 651 SYSCAT.INDEXES . . . . . . . . . 712 Descripción de los campos de la SQLDA . . 651 SYSCAT.INDEXEXPLOITRULES . . . . . 718 Campos en la cabecera SQLDA . . . . 652 SYSCAT.INDEXEXTENSIONDEP . . . . 719 Campos de una ocurrencia de una SYSCAT.INDEXEXTENSIONMETHODS . . 720 SQLVAR base . . . . . . . . . . 653 SYSCAT.INDEXEXTENSIONPARMS . . . 721 Campos de una ocurrencia de una SYSCAT.INDEXEXTENSIONS. . . . . . 722 SQLVAR secundaria . . . . . . . . 655 SYSCAT.INDEXOPTIONS . . . . . . . 723 Efecto de DESCRIBE en la SQLDA . . . . 657 SYSCAT.KEYCOLUSE . . . . . . . . 724 SQLTYPE y SQLLEN . . . . . . . . 659 SYSCAT.NAMEMAPPINGS . . . . . . 725 SQLTYPE no reconocidos y no soportados 662 SYSCAT.PACKAGEAUTH . . . . . . . 726 Números decimales empaquetados . . . 662 SYSCAT.PACKAGEDEP. . . . . . . . 727 Campo SQLLEN para decimales . . . . 663 SYSCAT.PACKAGES . . . . . . . . . 729 SYSCAT.PARTITIONMAPS . . . . . . 735 Apéndice D. Vistas de catálogo . . . . 665 SYSCAT.PASSTHRUAUTH. . . . . . . 736 ‘Mapa de carreteras’ para las vistas de SYSCAT.PREDICATESPECS . . . . . . 737 catálogo . . . . . . . . . . . . . 665 SYSCAT.PROCOPTIONS . . . . . . . 738 ‘Mapa de carreteras’ para vistas de catálogo SYSCAT.PROCPARMOPTIONS . . . . . 739 actualizables . . . . . . . . . . . 668 SYSCAT.REFERENCES . . . . . . . . 740 Vistas de catálogo del sistema. . . . . . 668 SYSCAT.REVTYPEMAPPINGS . . . . . 741 SYSIBM.SYSDUMMY1 . . . . . . . . 671 SYSCAT.ROUTINEAUTH . . . . . . . 743 SYSCAT.ATTRIBUTES . . . . . . . . 672 SYSCAT.ROUTINEDEP . . . . . . . . 745 SYSCAT.BUFFERPOOLDBPARTITIONS . . 674 SYSCAT.ROUTINEPARMS . . . . . . . 746 SYSCAT.BUFFERPOOLS . . . . . . . 675 SYSCAT.ROUTINES . . . . . . . . . 748 SYSCAT.CASTFUNCTIONS . . . . . . 676 SYSCAT.SCHEMAAUTH . . . . . . . 756 SYSCAT.CHECKS . . . . . . . . . . 677 SYSCAT.SCHEMATA . . . . . . . . 757 SYSCAT.COLAUTH . . . . . . . . . 678 SYSCAT.SEQUENCEAUTH . . . . . . 758 SYSCAT.COLCHECKS . . . . . . . . 679 SYSCAT.SEQUENCES . . . . . . . . 759 SYSCAT.COLDIST . . . . . . . . . 680 SYSCAT.SERVEROPTIONS. . . . . . . 761 SYSCAT.COLGROUPDIST . . . . . . . 681 SYSCAT.SERVERS. . . . . . . . . . 762 SYSCAT.COLGROUPDISTCOUNTS. . . . 682 SYSCAT.STATEMENTS . . . . . . . . 763 SYSCAT.COLGROUPS . . . . . . . . 683 SYSCAT.TABAUTH . . . . . . . . . 764 SYSCAT.COLOPTIONS . . . . . . . . 684 SYSCAT.TABCONST . . . . . . . . . 766 Contenido vii
- 10. SYSCAT.TABDEP . . . . . . . . . . 767 Fuentes de datos DB2 para UNIX y SYSCAT.TABLES . . . . . . . . . . 768 Windows . . . . . . . . . . . 823 SYSCAT.TABLESPACES . . . . . . . . 774 Fuentes de datos Informix . . . . . . 824 SYSCAT.TABOPTIONS . . . . . . . . 776 Fuentes de datos SQLNET de Oracle . . 825 SYSCAT.TBSPACEAUTH . . . . . . . 777 Fuentes de datos NET8 de Oracle . . . 827 SYSCAT.TRANSFORMS. . . . . . . . 778 Fuentes de datos Microsoft SQL Server 828 SYSCAT.TRIGDEP . . . . . . . . . 779 Fuentes de datos ODBC. . . . . . . 831 SYSCAT.TRIGGERS . . . . . . . . . 780 Fuentes de datos Sybase . . . . . . 833 SYSCAT.TYPEMAPPINGS . . . . . . . 782 Correlaciones de tipos de datos invertidas SYSCAT.USEROPTIONS . . . . . . . 784 por omisión. . . . . . . . . . . . 834 SYSCAT.VIEWS . . . . . . . . . . 785 Fuentes de datos DB2 para z/OS y SYSCAT.WRAPOPTIONS . . . . . . . 786 OS/390 . . . . . . . . . . . . 836 SYSCAT.WRAPPERS . . . . . . . . . 787 Fuentes de datos DB2 para iSeries . . . 837 SYSSTAT.COLDIST . . . . . . . . . 788 Fuentes de datos DB2 Server para VM y SYSSTAT.COLUMNS. . . . . . . . . 790 VSE . . . . . . . . . . . . . 838 SYSSTAT.INDEXES . . . . . . . . . 792 Fuentes de datos DB2 para UNIX y SYSSTAT.ROUTINES . . . . . . . . . 797 Windows . . . . . . . . . . . 839 SYSSTAT.TABLES . . . . . . . . . . 799 Fuentes de datos Informix . . . . . . 840 Fuentes de datos SQLNET de Oracle . . 841 Apéndice E. Sistemas federados . . . . 801 Fuentes de datos NET8 de Oracle . . . 842 Tipos de servidores válidos en sentencias de Fuentes de datos de Microsoft SQL Server 844 SQL . . . . . . . . . . . . . . 801 Fuentes de datos Sybase . . . . . . 844 Reiniciador CTLIB . . . . . . . . 801 Reiniciador DBLIB . . . . . . . . 801 Apéndice F. La base de datos SAMPLE 847 Reiniciador DJXMSSQL3 . . . . . . 801 Creación de la base de datos SAMPLE . . . 847 Reiniciador DRDA . . . . . . . . 801 Eliminación de la base de datos SAMPLE 847 Reiniciador Informix . . . . . . . . 803 Tabla CL_SCHED . . . . . . . . . . 847 Reiniciador MSSQLODBC3 . . . . . 803 Tabla DEPARTMENT . . . . . . . . 848 Reiniciador NET8 . . . . . . . . . 803 Tabla EMPLOYEE. . . . . . . . . . 848 Reiniciador ODBC . . . . . . . . 803 Tabla EMP_ACT . . . . . . . . . . 852 Reiniciador OLE DB . . . . . . . . 803 Tabla EMP_PHOTO . . . . . . . . . 854 Reiniciador SQLNET . . . . . . . . 803 Tabla EMP_RESUME. . . . . . . . . 854 Opciones de columna para sistemas Tabla IN_TRAY . . . . . . . . . . 855 federados . . . . . . . . . . . . 804 Tabla ORG . . . . . . . . . . . . 855 Opciones de correlación de funciones para Tabla PROJECT . . . . . . . . . . 855 sistemas federados . . . . . . . . . 805 Tabla SALES . . . . . . . . . . . 856 Opciones de servidor para sistemas Tabla STAFF . . . . . . . . . . . 858 federados . . . . . . . . . . . . 806 Tabla STAFFG (sólo para páginas de códigos Opciones del usuario para sistemas de doble byte) . . . . . . . . . . . 859 federados . . . . . . . . . . . . 816 Archivos de muestra con tipos de datos Opciones de reiniciador para sistemas BLOB y CLOB . . . . . . . . . . . 860 federados . . . . . . . . . . . . 817 Foto de Quintana . . . . . . . . . 860 Correlaciones de tipos de datos en avance Currículum vitae de Quintana . . . . 860 por omisión. . . . . . . . . . . . 818 Foto de Nicholls . . . . . . . . . 862 Fuentes de datos DB2 para z/OS y Currículum vitae de Nicholls . . . . . 862 OS/390 . . . . . . . . . . . . 819 Foto de Adamson . . . . . . . . . 863 Fuentes de datos DB2 para iSeries . . . 820 Currículum vitae de Adamson . . . . 863 Fuentes de datos DB2 Server para VM y Foto de Walker. . . . . . . . . . 865 VSE . . . . . . . . . . . . . 822 Currículum vitae de Walker . . . . . 865 viii Consulta de SQL, Volumen 1
- 11. Apéndice G. Nombres de esquema Tipos de datos . . . . . . . . . . 936 reservados y palabras reservadas . . . 867 Constantes . . . . . . . . . . . 939 Funciones . . . . . . . . . . . 939 Apéndice H. Comparación de niveles de Expresiones . . . . . . . . . . . 939 aislamiento . . . . . . . . . . . 871 Predicados . . . . . . . . . . . 940 Funciones . . . . . . . . . . . . 941 Apéndice I. Interacción de los activadores LENGTH . . . . . . . . . . . 941 con las restricciones . . . . . . . . 873 SUBSTR . . . . . . . . . . . . 941 TRANSLATE . . . . . . . . . . 941 Apéndice J. Tablas de Explain . . . . . 877 VARGRAPHIC . . . . . . . . . . 941 Tablas de Explain . . . . . . . . . . 877 Sentencias . . . . . . . . . . . . 942 Tabla EXPLAIN_ARGUMENT . . . . . 878 CONNECT . . . . . . . . . . . 942 Tabla EXPLAIN_INSTANCE . . . . . . 882 PREPARE . . . . . . . . . . . 942 Tabla EXPLAIN_OBJECT . . . . . . . 885 Tabla EXPLAIN_OPERATOR . . . . . . 888 Apéndice Q. Especificaciones de formato Tabla EXPLAIN_PREDICATE . . . . . . 891 de Backus-Naur (BNF) para los enlaces Tabla EXPLAIN_STATEMENT . . . . . 894 de datos . . . . . . . . . . . . 945 Tabla EXPLAIN_STREAM . . . . . . . 897 Tabla ADVISE_INDEX . . . . . . . . 899 Apéndice R. Información técnica sobre Tabla ADVISE_WORKLOAD . . . . . . 903 DB2 Universal Database . . . . . . . 949 Visión general de la información técnica de Apéndice K. Valores de registro de DB2 Universal Database . . . . . . . 949 EXPLAIN . . . . . . . . . . . . 905 FixPaks para la documentación de DB2 949 Categorías de la información técnica de Apéndice L. Ejemplo de recurrencia: Lista DB2 . . . . . . . . . . . . . 949 de material . . . . . . . . . . . 911 Impresión de manuales de DB2 desde Ejemplo 1: Explosión de primer nivel . . . 911 archivos PDF . . . . . . . . . . . 957 Ejemplo 2: Explosión resumida . . . . . 913 Solicitud de manuales de DB2 impresos . . 958 Ejemplo 3: Control de profundidad . . . . 914 Acceso a la ayuda en línea . . . . . . . 959 Búsqueda de temas mediante el acceso al Apéndice M. Tablas de excepciones . . . 917 Centro de información de DB2 desde un Reglas para crear una tabla de excepciones 917 navegador . . . . . . . . . . . . 961 Gestión de las filas en una tabla de Búsqueda de información de productos excepciones . . . . . . . . . . . . 920 mediante el acceso al Centro de información Consulta de las tablas de excepciones . . . 921 de DB2 desde las herramientas de administración . . . . . . . . . . . 963 Cómo ver documentación técnica en línea Apéndice N. Sentencias de SQL que se directamente desde el CD de documentación permiten en rutinas . . . . . . . . 923 HTML de DB2 . . . . . . . . . . . 965 Actualización de la documentación HTML Apéndice O. CALL invocada desde una instalada en la máquina. . . . . . . . 966 sentencia compilada . . . . . . . . 927 Copia de archivos desde el CD de documentación HTML de DB2 en un Apéndice P. Consideraciones sobre servidor Web . . . . . . . . . . . 967 Extended UNIX Code (EUC) para japonés Resolución de problemas de búsqueda de y chino tradicional . . . . . . . . . 935 documentación de DB2 con Netscape 4.x . . 968 Elementos del lenguaje . . . . . . . . 935 Búsqueda en la documentación de DB2 . . 969 Caracteres . . . . . . . . . . . 935 Información en línea de resolución de Símbolos . . . . . . . . . . . . 935 problemas de DB2 . . . . . . . . . 970 Identificadores . . . . . . . . . . 936 Accesibilidad . . . . . . . . . . . 971 Contenido ix
- 12. Entrada de teclado y navegación . . . . 971 Apéndice S. Avisos. . . . . . . . . 975 Pantalla accesible . . . . . . . . . 972 Marcas registradas . . . . . . . . . 978 Señales de alerta alternativas . . . . . 972 Compatibilidad con tecnologías de Índice . . . . . . . . . . . . . 981 asistencia . . . . . . . . . . . 972 Documentación accesible . . . . . . 972 Cómo ponerse en contacto con IBM 1003 Guías de aprendizaje de DB2 . . . . . . 972 Información sobre productos. . . . . . 1003 Acceso al Centro de información de DB2 desde un navegador . . . . . . . . . 973 x Consulta de SQL, Volumen 1
- 13. Acerca de este manual El manual Consulta de SQL en sus dos volúmenes define el lenguaje SQL que utiliza DB2 Universal Database Versión 8 e incluye: v Información sobre los conceptos de bases de datos relacionales, los elementos del lenguaje, las funciones y los formatos de las consultas (Volumen 1) v Información sobre la sintaxis y la semántica de las sentencias de SQL (Volumen 2). A quién va dirigido este manual Este manual va dirigido a aquellas personas que deseen utilizar el Lenguaje de consulta estructurada (SQL) para acceder a una base de datos. Principalmente, es para los programadores y los administradores de bases de datos, pero también pueden utilizarlo aquellos que acceden a las bases de datos utilizando el procesador de línea de mandatos (CLP). Este manual sirve más de consulta que de guía de aprendizaje. Supone que va a escribir programas de aplicación y, por lo tanto, presenta todas las funciones del gestor de bases de datos. Estructura de este manual Este manual contiene información sobre los siguientes temas principales: v El Capítulo 1, “Conceptos” en la página 1 explica los conceptos básicos de las bases de datos relacionales y de SQL. v El Capítulo 2, “Elementos del lenguaje” en la página 67 describe la sintaxis básica de SQL y los elementos del lenguaje que son comunes a muchas sentencias de SQL. v El Capítulo 3, “Funciones” en la página 265 contiene diagramas de sintaxis, descripciones semánticas, normas y ejemplos de utilización de las funciones de columna y funciones escalares de SQL. v El Capítulo 4, “Consultas” en la página 579 describe los distintos formatos de una consulta. v El Apéndice A, “Límites de SQL” en la página 637 muestra las restricciones de SQL. v El Apéndice B, “SQLCA (área de comunicaciones SQL)” en la página 645 describe la estructura SQLCA. © Copyright IBM Corp. 1993, 2002 xi
- 14. Estructura de este manual v El Apéndice C, “SQLDA (área de descriptores de SQL)” en la página 651 describe la estructura SQLDA. v La Apéndice D, “Vistas de catálogo” en la página 665 describe las vistas de catálogo de la base de datos. v El Apéndice E, “Sistemas federados” en la página 801 describe las opciones y las correlaciones de tipos para sistemas federados. v El Apéndice F, “La base de datos SAMPLE” en la página 847 describe las tablas de muestra utilizadas en los ejemplos. v El Apéndice G, “Nombres de esquema reservados y palabras reservadas” en la página 867 contiene los nombres de esquemas reservados y las palabras reservadas correspondientes a los estándares SQL de IBM y SQL99 ISO/ANS. v El Apéndice H, “Comparación de niveles de aislamiento” en la página 871 contiene un resumen de los niveles de aislamiento. v El Apéndice I, “Interacción de los activadores con las restricciones” en la página 873 explica la interacción de los activadores y las restricciones referenciales. v El Apéndice J, “Tablas de Explain” en la página 877 describe las tablas Explain. v El Apéndice K, “Valores de registro de EXPLAIN” en la página 905 describe la interacción entre sí de los valores de registro especiales CURRENT EXPLAIN MODE y CURRENT EXPLAIN SNAPSHOT y con los mandatos PREP y BIND. v El Apéndice L, “Ejemplo de recurrencia: Lista de material” en la página 911, contiene un ejemplo de una consulta recursiva. v El Apéndice M, “Tablas de excepciones” en la página 917 contiene información sobre tablas creadas por el usuario que se utilizan con la sentencia SET INTEGRITY. v El Apéndice N, “Sentencias de SQL que se permiten en rutinas” en la página 923 lista las sentencias de SQL que es posible ejecutar en rutinas con diferentes contextos de acceso a datos SQL. v El Apéndice O, “CALL invocada desde una sentencia compilada” en la página 927 describe la sentencia CALL que puede invocarse desde una sentencia compilada. v El Apéndice P, “Consideraciones sobre Extended UNIX Code (EUC) para japonés y chino tradicional” en la página 935 muestra las consideraciones a tener en cuenta cuando se utilizan los juegos de caracteres Extended UNIX Code (EUC). v El Apéndice Q, “Especificaciones de formato de Backus-Naur (BNF) para los enlaces de datos” en la página 945 contiene las especificaciones del formato Backus-Naur (BNF) para archivos DATALINK. xii Consulta de SQL, Volumen 1
- 15. Una breve visión general del volumen 2 Una breve visión general del volumen 2 El segundo volumen de Consulta de SQL contiene información sobre la sintaxis y la semántica de las sentencias SQL. A continuación se describen brevemente los capítulos específicos del volumen: v “Sentencias SQL” contiene diagramas de sintaxis, descripciones semánticas, normas y ejemplos de todas las sentencias de SQL. v “Sentencias de control de SQL” contiene diagramas de sintaxis, descripciones semánticas, normas y ejemplos de sentencias de procedimiento de SQL. Lectura de los diagramas de sintaxis En este manual, la sintaxis se describe utilizando la estructura definida de la siguiente manera: Lea los diagramas de sintaxis de izquierda a derecha y de arriba a abajo, siguiendo la línea. El símbolo ─── indica el inicio de un diagrama de sintaxis. El símbolo ─── indica que la sintaxis continúa en la línea siguiente. El símbolo ─── indica que continúa la sintaxis de la línea anterior. El símbolo ── indica el final de un diagrama de sintaxis. Los fragmentos de sintaxis empiezan con el símbolo ├─── y terminan con el símbolo ───┤. Los elementos necesarios aparecen en la línea horizontal (la línea principal). elemento_obligatorio Los elementos opcionales aparecen debajo de la línea principal. elemento_obligatorio elemento_opcional Si aparece un elemento opcional por encima de la línea principal, dicho elemento no tiene ningún efecto en la ejecución y sólo se utiliza para facilitar la lectura. Acerca de este manual xiii
- 16. Lectura de los diagramas de sintaxis elemento_opcional elemento_obligatorio Si puede elegir entre dos o más elementos, aparecen en una pila. Si debe elegir uno de los elementos, un elemento de la pila aparece en la ruta principal. elemento_obligatorio opción1_obligatoria opción2_obligatoria Si la elección de uno de los elementos es opcional, toda la pila aparece por debajo de la línea principal. elemento_obligatorio opción1_opcional opción2_opcional Si uno de los elementos es el valor por omisión, aparecerá por encima de la línea principal y el resto de las opciones se mostrarán por debajo. opción_omisión elemento_obligatorio opción_opcional opción_opcional Una flecha que vuelve a la izquierda, por encima de la línea principal, indica un elemento que se puede repetir. En este caso, los elementos repetidos deben ir separados por uno o varios espacios en blanco. elemento_obligatorio elemento_repetible Si la flecha de repetición contiene una coma, debe separar los elementos repetidos con una coma. , elemento_obligatorio elemento_repetible Una flecha de repetición por encima de una pila indica que puede elegir más de una opción de entre los elementos apilados o repetir una sola opción. xiv Consulta de SQL, Volumen 1
- 17. Lectura de los diagramas de sintaxis Las palabras clave aparecen en mayúsculas (por ejemplo, FROM). Deben escribirse exactamente igual a como aparecen en la sintaxis. Las variables aparecen en minúsculas (por ejemplo, nombre-columna). Representan nombres suministrados por el usuario o valores de la sintaxis. Si aparecen signos de puntuación, paréntesis, operadores aritméticos u otros símbolos, debe entrarlos como parte de la sintaxis. A veces, una sola variable representa un fragmento mayor de la sintaxis. Por ejemplo, en el diagrama siguiente, la variable bloque-parámetros representa todo el fragmento de sintaxis denominado bloque-parámetros: elemento_obligatorio bloque-parámetros bloque-parámetros: parámetro1 parámetro2 parámetro3 parámetro4 Los segmentos adyacentes que aparecen entre “puntos grandes” (*) se pueden especificar en cualquier secuencia. elemento_obligatorio elemento1 * elemento2 * elemento3 * elemento4 El diagrama anterior muestra que el elemento2 y el elemento3 se pueden especificar en cualquier orden. Son válidos los dos diagramas siguientes: elemento_obligatorio elemento1 elemento2 elemento3 elemento4 elemento_obligatorio elemento1 elemento3 elemento2 elemento4 Elementos de sintaxis comunes Las secciones siguientes describen una serie de fragmentos de sintaxis que se utilizan en diagramas de sintaxis. Se hace referencia a los fragmentos de la forma siguiente: fragmento Designador de función Un desginador de función identifica una sola función de forma exclusiva. Los designadores de función suelen aparecen en sentencias DDL para funciones (como, por ejemplo, DROP o ALTER). Sintaxis: Acerca de este manual xv
- 18. Designador de función designador-función: FUNCTION nombre-función ( ) , ( tipo-datos ) SPECIFIC FUNCTION nombre-específico Descripción: FUNCTION nombre-función Identifica una función específica y sólo es válido si hay exactamente una instancia de función con el nombre nombre-función en el esquema. La función identificada puede tener un número cualquiera de parámetros definidos para ella.En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. Si no existe ninguna función con este nombre en el esquema nombrado o implícito, se produce un error (SQLSTATE 42704). Si existe más de una instancia de la función en el esquema mencionado o implicado, se producirá un error (SQLSTATE 42725). FUNCTION nombre-función (tipo-datos,...) Proporciona la signatura de la función, que identifica de manera exclusiva la función. El algoritmo de resolución de funciones no se utiliza. nombre-función Especifica el nombre de la función. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. (tipo-datos, ...) Los valores deben coincidir con los tipos de datos que se han especificado (en la posición correspondiente) en la sentencia CREATE FUNCTION. El número de tipos de datos y la concatenación lógica de los tipos de datos se utiliza para identificar la instancia de función específica. Si un tipo de datos no está calificado, el nombre de tipo se resuelve efectuando una búsqueda en los esquemas de la vía de acceso de SQL. Esto también se aplica a los nombres de tipo de datos especificados para un tipo REFERENCE. xvi Consulta de SQL, Volumen 1
- 19. Designador de función Para los tipos de datos parametrizados no es necesario especificar la longitud, la precisión ni la escala. En su lugar, se puede codificar un conjunto vacío de paréntesis para indicar que estos atributos se han de pasar por alto al buscar coincidencias de un tipo de datos. No puede utilizarse FLOAT() (SQLSTATE 42601), porque el valor del parámetro indica tipos de datos diferentes (REAL o DOUBLE). Si se codifica la longitud, la precisión o la escala, el valor debe coincidir exactamente con el especificado en la sentencia CREATE FUNCTION. No es necesario que un tipo de FLOAT (n) coincida con el valor definido para n, porque 0 < n < 25 significa REAL y 24< n < 54 significa DOUBLE. La coincidencia se produce en base de si el tipo es REAL o DOUBLE. Si en el esquema nombrado o implícito no hay ninguna función con la signatura especificada, se genera un error (SQLSTATE 42883). SPECIFIC FUNCTION nombre-específico Identifica una función definida por el usuario concreta, mediante un nombre que se especifica o se toma por omisión al crear la función. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. El nombre-específico debe identificar una instancia de función específica en el esquema nombrado o implícito; de lo contrario, se produce un error (SQLSTATE 42704). Designador de método Un desginador de método identifica un solo método de forma exclusiva. Los designadores de método suelen aparecen en sentencias DDL para métodos (como, por ejemplo, DROP o ALTER). Sintaxis: designador-método: METHOD nombre-método FOR nombre-tipo ( ) , ( tipo-datos ) SPECIFIC METHOD nombre-específico Descripción: METHOD nombre-método Identifica un método determinado y sólo es válido si hay exactamente una instancia de método cuyo nombre sea nombre-método y su tipo sea Acerca de este manual xvii
- 20. Designador de método nombre-tipo. El método identificado puede tener un número cualquiera de parámetros definidos para él. Si no existe ningún método con este nombre para el tipo, se produce un error (SQLSTATE 42704). Si existe más de una instancia específica del método para el tipo, se produce un error (SQLSTATE 42725). METHOD nombre-método (tipo-datos,...) Proporciona la signatura del método, que identifica de manera exclusiva el método. El algoritmo de resolución de métodos no se utiliza. nombre-método Especifica el nombre del método para el tipo nombre-tipo. (tipo-datos, ...) Los valores deben coincidir con los tipos de datos que se han especificado (en la posición correspondiente) en la sentencia CREATE TYPE. El número de tipos de datos y la concatenación lógica de los tipos de datos se utiliza para identificar la instancia de método específica. Si un tipo de datos no está calificado, el nombre de tipo se resuelve efectuando una búsqueda en los esquemas de la vía de acceso de SQL. Esto también se aplica a los nombres de tipo de datos especificados para un tipo REFERENCE. Para los tipos de datos parametrizados no es necesario especificar la longitud, la precisión ni la escala. En su lugar, se puede codificar un conjunto vacío de paréntesis para indicar que estos atributos se han de pasar por alto al buscar coincidencias de un tipo de datos. No puede utilizarse FLOAT() (SQLSTATE 42601), porque el valor del parámetro indica tipos de datos diferentes (REAL o DOUBLE). Si se codifica la longitud, la precisión o la escala, el valor debe coincidir exactamente con el especificado en la sentencia CREATE TYPE. No es necesario que un tipo de FLOAT (n) coincida con el valor definido para n, porque 0 < n < 25 significa REAL y 24< n < 54 significa DOUBLE. La coincidencia se produce en base de si el tipo es REAL o DOUBLE. Si no existe ningún método para el tipo con la signatura especificada en el esquema nombrado o implícito, se genera un error (SQLSTATE 42883). FOR nombre-tipo Designa el tipo con el cual se debe asociar el método especificado. El nombre debe identificar un tipo que ya esté descrito en el catálogo (SQLSTATE 42704). En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un xviii Consulta de SQL, Volumen 1
- 21. Designador de método nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. SPECIFIC METHOD nombre-específico Identifica un método concreto, mediante el nombre que se especifica o se toma por omisión al crear el método. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. El nombre-específico debe identificar una instancia de método específica en el esquema nombrado o implícito; de lo contrario, se produce un error (SQLSTATE 42704). Designador de procedimiento Un desginador de procedimiento identifica un solo procedimiento almacenado de forma exclusiva. Los designadores de procedimiento suelen aparecen en sentencias DDL para procedimientos (como, por ejemplo, DROP o ALTER). Sintaxis: designador-procedimiento: PROCEDURE nombre-procedimiento ( ) , ( tipo-datos ) SPECIFIC PROCEDURE nombre-específico Descripción: PROCEDURE nombre-procedimiento Identifica un procedimiento concreto y sólo es válido si hay exactamente una instancia de procedimiento con el nombre nombre-procedimiento en el esquema. El procedimiento identificado puede tener un número cualquiera de parámetros definidos para él. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. Si no existe ningún procedimiento con este nombre en el esquema nombrado o implícito, se genera un error (SQLSTATE 42704). Si existe más de una instancia del procedimiento en el esquema mencionado o implicado, se producirá un error (SQLSTATE 42725). Acerca de este manual xix
- 22. Designador de procedimiento PROCEDURE nombre-procedimiento (tipo-datos,...) Proporciona la signatura del procedimiento, que identifica de manera exclusiva el procedimiento. El algoritmo de resolución de procedimientos no se utiliza. nombre-procedimiento Especifica el nombre del procedimiento. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. (tipo-datos, ...) Los valores deben coincidir con los tipos de datos que se han especificado (en la posición correspondiente) en la sentencia CREATE PROCEDURE. El número de tipos de datos y la concatenación lógica de los tipos de datos se utiliza para identificar la instancia de procedimiento específica. Si un tipo de datos no está calificado, el nombre de tipo se resuelve efectuando una búsqueda en los esquemas de la vía de acceso de SQL. Esto también se aplica a los nombres de tipo de datos especificados para un tipo REFERENCE. Para los tipos de datos parametrizados no es necesario especificar la longitud, la precisión ni la escala. En su lugar, se puede codificar un conjunto vacío de paréntesis para indicar que estos atributos se han de pasar por alto al buscar coincidencias de un tipo de datos. No puede utilizarse FLOAT() (SQLSTATE 42601), porque el valor del parámetro indica tipos de datos diferentes (REAL o DOUBLE). Si se codifica la longitud, la precisión o la escala, el valor debe coincidir exactamente con el especificado en la sentencia CREATE PROCEDURE. No es necesario que un tipo de FLOAT (n) coincida con el valor definido para n, porque 0 < n < 25 significa REAL y 24< n < 54 significa DOUBLE. La coincidencia se produce en base de si el tipo es REAL o DOUBLE. Si no existe ningún procedimiento con la signatura especificada en el esquema nombrado o implícito, se genera un error (SQLSTATE 42883). SPECIFIC PROCEDURE nombre-específico Identifica un procedimiento concreto, mediante el nombre que se especifica o se toma por omisión al crear el procedimiento. En las sentencias de SQL dinámicas, el registro especial CURRENT SCHEMA se utiliza como calificador para un nombre de objeto no calificado. En las xx Consulta de SQL, Volumen 1
- 23. Designador de procedimiento sentencias de SQL estáticas, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objeto no calificados. El nombre-específico debe identificar una instancia del procedimiento específico en el esquema nombrado o implícito; de lo contrario, se genera un error (SQLSTATE 42704). Convenios utilizados en este manual Esta sección especifica algunos convenios que se utilizan coherentemente en este manual. Condiciones de error Una condición de error se indica en el texto del manual listando entre corchetes el SQLSTATE asociado al error. Por ejemplo: Si hay una signatura duplicada se genera un error de SQL (SQLSTATE 42723). Convenios de resaltado Se utilizan los siguientes convenios en este manual. Negrita Indica mandatos, palabras clave y otros elementos cuyos nombres están predefinidos por el sistema. Cursiva Indica uno de los casos siguientes: v Nombres o valores (variables) que debe suministrar el usuario. v Énfasis general. v La presentación de un término nuevo. v Una referencia a otra fuente de información. Monoespaciado Indica uno de los casos siguientes: v Archivos y directorios, v Información que se indica al usuario que escriba en un indicador de mandatos o en una ventana. v Ejemplos de valores de datos concretos. v Ejemplos de texto similar al que puede mostrar el sistema. v Ejemplos de mensajes del sistema. Documentación relacionada Las siguientes publicaciones pueden ser útiles en la preparación de aplicaciones: v Administration Guide Acerca de este manual xxi
- 24. Documentación relacionada – Contiene la información necesaria para diseñar, implantar y mantener una base de datos a la que se va a acceder de forma local o en un entorno de cliente/servidor. v Application Development Guide – Explica el proceso de desarrollo de aplicaciones y la forma de codificar, compilar y ejecutar programas de aplicación que utilizan SQL intercalado y API para acceder a la base de datos. v DB2 Universal Database for iSeries SQL Reference – Este manual define el Lenguaje de consulta estructurada (SQL) soportado por DB2 Query Manager y SQL Development Kit en iSeries (AS/400). Contiene información de consulta para las tareas de administración del sistema, administración de la base de datos, programación de aplicaciones y operación. Este manual incluye sintaxis, notas acerca del uso, palabras claves y ejemplos para cada una de las sentencias de SQL utilizadas en sistemas iSeries (AS/400) que ejecutan DB2. v DB2 Universal Database for z/OS and OS/390 SQL Reference – Este manual define el Lenguaje de consulta estructurada (SQL) utilizado en DB2 para z/OS (OS/390). Proporciona formularios de consulta, sentencias de SQL, sentencias de procedimientos de SQL, límites de DB2, SQLCA, SQLDA, tablas de catálogos y palabras reservadas de SQL para sistemas z/OS (OS/390) que ejecutan DB2. v DB2 Spatial Extender Guía del usuario y de consulta – Este manual describe cómo escribir aplicaciones para crear y utilizar un sistema de información geográfica (Geographic Information System, GIS). Para crear y utilizar un GIS es necesario proporcionar una base de datos con recursos y luego consultar los datos para obtener información, tal como ubicaciones, distancias y distribuciones dentro de zonas geográficas. v IBM Consulta de SQL – Este manual contiene todos los elementos comunes de SQL que están distribuidos por todos los productos de base de datos de IBM. Proporciona límites y normas que pueden servir de ayuda en la preparación de programas portátiles que utilicen bases de datos IBM. Este manual proporciona una lista de extensiones SQL e incompatibilidades entre los siguientes estándares y productos: SQL92E, XPG4-SQL, IBM-SQL y los productos de bases de datos relacionales IBM. v American National Standard X3.135-1992, Database Language SQL – Contiene la definición estándar ANSI de SQL. v ISO/IEC 9075:1992, Database Language SQL – Contiene la definición de SQL proporcionada por la norma 1992 de ISO. v ISO/IEC 9075-2:1999, Database Language SQL -- Part 2: Foundation (SQL/Foundation) xxii Consulta de SQL, Volumen 1
- 25. Documentación relacionada – Contiene una gran parte de la definición de SQL proporcionada por la norma 1999 de ISO. v ISO/IEC 9075-4:1999, Database Language SQL -- Part 4: Persistent Stored Modules (SQL/PSM) – Contiene la definición de las sentencias de control de los procedimientos SQL, tal como aparece en la norma 1999 de ISO. v ISO/IEC 9075-5:1999, Database Language SQL -- Part 4: Host Language Bindings (SQL/Bindings) – Contiene la definición de las vinculaciones de lenguaje de sistema principal y de SQL dinámico, tal como aparece en la norma 1999 de ISO. Acerca de este manual xxiii
- 26. Documentación relacionada xxiv Consulta de SQL, Volumen 1
- 27. Capítulo 1. Conceptos En este capítulo se proporciona una vista de alto nivel de los conceptos que son importantes para comprender cuándo utilizar el Lenguaje de consulta estructurada (SQL). El material de consulta contenido en el resto de este manual proporciona una vista más detallada. Bases de datos relacionales Una base de datos relacional es una base de datos que se trata como un conjunto de tablas y se manipula de acuerdo con el modelo de datos relacional. Contiene un conjunto de objetos que se utilizan para almacenar y gestionar los datos, así como para acceder a los mismos. Las tablas, vistas, índices, funciones, activadores y paquetes son ejemplos de estos objetos. Una base de datos relacional particionada es una base de datos relacional cuyos datos se gestionan repartidos en múltiples particiones (también denominadas nodos). Esta separación de los datos entre particiones es transparente para los usuarios de la mayoría de sentencias de SQL. Sin embargo, algunas sentencias DLL (lenguaje de definición de datos) tienen en cuenta la información de las particiones (por ejemplo, CREATE DATABASE PARTITION GROUP). (DLL, lenguaje de definición de datos, es el subconjunto de sentencias de SQL que se utilizan para describir las relaciones de los datos de una base de datos.) Una base de datos federada es una base de datos relacional cuyos datos están almacenados en varias fuentes de datos (tales como bases de datos relacionales separadas). Los datos son tratados como si pertenecieran a una sola gran base de datos y se pueden acceder mediante las consultas SQL normales. Los cambios en los datos se pueden dirigir explícitamente hacia la fuente datos apropiada. Lenguaje de consulta estructurada (SQL) SQL es un lenguaje estandarizado que sirve para definir y manipular los datos de una base de datos relacional. De acuerdo con el modelo relacional de datos, la base de datos se crea como un conjunto de tablas, las relaciones se representan mediante valores en las tablas y los datos se recuperan especificando una tabla de resultados que puede derivarse de una o más tablas base. © Copyright IBM Corp. 1993, 2002 1
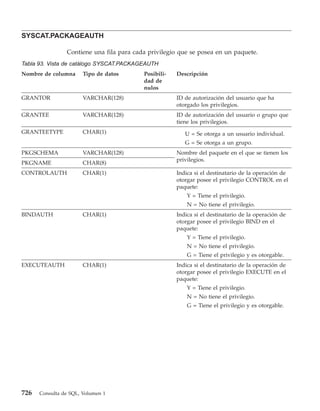
- 28. Las sentencias de SQL las ejecuta un gestor de bases de datos. Una de las funciones del gestor de bases de datos es transformar la especificación de una tabla resultante en una secuencia de operaciones internas que optimicen la recuperación de los datos. Esta transformación se produce en dos fases: preparación y vinculación. Todas las sentencias de SQL ejecutables deben prepararse antes de su ejecución. El resultado de esta preparación es el formato operativo o ejecutable de la sentencia. El método de preparación de una sentencia de SQL y la persistencia de su formato operativo diferencian SQL estático de SQL dinámico. Autorización y privilegios Una autorización permite a un usuario o grupo realizar una tarea general como, por ejemplo, la conexión a una base de datos, la creación de tablas o la administración de un sistema. Un privilegio da a un usuario o a un grupo el derecho a acceder a un objeto específico de la base de datos de una manera concreta. El gestor de bases de datos necesita que un usuario esté específicamente autorizado, ya sea implícita o explícitamente, para utilizar cada función de base de datos necesaria para realizar una tarea específica. Las autorizaciones o los privilegios explícitos se otorgan al usuario (GRANTEETYPE de U).Las autorizaciones o los privilegios implícitos se otorgan a un grupo al que pertenece el usuario (GRANTEETYPE de G).De este modo, para crear una tabla, un usuario debe tener autorización para crear tablas; para modificar una tabla, un usuario debe tener autorización para modificar la tabla y así sucesivamente. 2 Consulta de SQL, Volumen 1
- 29. SYSADM (Administrador del sistema) DBADM SYSCTRL (Administrador de base de datos) (Administrador de recursos del sistema) SYSMAINT (Administrador de mantenimiento del sistema) Usuarios de base de datos con privilegios Figura 1. Jerarquía de autorizaciones y privilegios Las personas con autorización de administrador se encargan de la tarea de controlar el gestor de bases de datos y son responsables de la seguridad e integridad de los datos. Controlan quién va a tener acceso al gestor de bases de datos y hasta qué punto tiene acceso cada usuario. El gestor de bases de datos proporciona dos autorizaciones de administración: v SYSADM - autorización de administrador del sistema La autorización SYSADM es el nivel más alto de autorización y tiene control sobre todos los recursos que el gestor de bases de datos crea y mantiene. La autorización SYSADM incluye todos las autorizaciones de DBADM, SYSCTRL y SYSMAINT, así como la autorización para otorgar o revocar autorizaciones DBADM. v DBADM - autorización de administrador de bases de datos La autorización DBADM es la autorización de administración específica para una sola base de datos. Esta autorización incluye privilegios para crear objetos, emitir mandatos de la base de datos y acceder a los datos de sus tablas mediante sentencias de SQL. La autorización DBADM también incluye la autorización para otorgar o revocar el privilegio CONTROL y privilegios individuales. El gestor de bases de datos también proporciona dos autorizaciones de control del sistema: v SYSCTRL - autorización de control del sistema La autorización SYSCTRL corresponde al nivel más alto de autorización de control del sistema y sólo se aplica a las operaciones que afectan a los recursos del sistema. No permite el acceso directo a los datos. Esta Capítulo 1. Conceptos 3
- 30. autorización incluye privilegios para crear, actualizar o eliminar una base de datos, detener una instancia o una base de datos y crear o eliminar una espacio de tablas. v SYSMAINT - autorización de mantenimiento del sistema La autorización SYSMAINT es el segundo nivel de autorización de control del sistema. Un usuario con autorización SYSMAINT puede realizar operaciones de mantenimiento en todas las bases de datos asociadas a una instancia. No permite el acceso directo a los datos. Esta autorización incluye privilegios para actualizar archivos de configuración de la base de datos, realizar una copia de seguridad de una base de datos o un espacio de tablas, restaurar una base de datos existente y supervisar una base de datos. Las autorizaciones de base de datos se aplican a las actividades que un administrador ha permitido realizar a un usuario en una base de datos; no se aplican a una instancia específica de un objeto de base de datos. Por ejemplo, puede otorgarse a un usuario la autorización para crear paquetes pero no para crear tablas. Los privilegios se aplican las actividades que un administrador o el propietario de un objeto han permitido que realice un usuario en objetos de la base de datos. Los usuarios con privilegios pueden crear objetos, estrictamente definidos por los privilegios que poseen. Por ejemplo, un usuario puede tener el privilegio para crear una vista en una tabla pero no un activador en la misma tabla. Los usuarios con privilegios tienen acceso a los objetos de los que son propietarios y pueden transmitir privilegios sobre sus propios objetos a otros usuarios mediante la sentencia GRANT. El privilegio CONTROL permite a un usuario acceder a un objeto de base de datos específico, si así lo desea, y otorgar o revocar a otros usuarios privilegios sobre ese objeto. Para conceder el privilegio CONTROL se necesita la autorización DBADM. Los privilegios individuales y las autorizaciones de bases de datos permiten una función específica pero no incluyen el derecho a otorgar los mismos privilegios o autorizaciones a otros usuarios. El derecho para otorgar privilegios de tabla, vista o esquema a otros puede ampliarse a otros usuarios mediante la opción WITH GRANT en la sentencia GRANT. Esquemas Un esquema es un conjunto de objetos con nombre. Los esquemas proporcionan una clasificación lógica de los objetos de la base de datos. Un esquema puede contener tablas, vistas, apodos, activadores, funciones, paquetes y otros objetos. 4 Consulta de SQL, Volumen 1
- 31. Un esquema también es un objeto en la base de datos. Se crea explícitamente utilizando la sentencia CREATE SCHEMA con el usuario actual registrado como propietario del esquema. También se puede crear implícitamente cuando se crea otro objeto, a condición de que el usuario tenga la autorización IMPLICIT_SCHEMA. Un nombre de esquema se utiliza como la parte más a la izquierda de las dos partes del nombre de objeto. Si el objeto se califica específicamente con un nombre de esquema al crearse, se asigna el objeto a dicho esquema. Si no se especifica ningún nombre de esquema al crear el objeto, se utiliza el nombre de esquema por omisión. Por ejemplo, un usuario con autorización DBADM crea un esquema llamado C para el usuario A: CREATE SCHEMA C AUTHORIZATION A El usuario A puede emitir la siguiente sentencia para crear una tabla llamada X en el esquema C: CREATE TABLE C.X (COL1 INT) Algunos nombres de esquema están reservados. Por ejemplo, las funciones incorporadas pertenecen al esquema SYSIBM y las funciones preinstaladas definidas por el usuario pertenecen al esquema SYSFUN. Cuando se crea una base de datos, todos los usuarios tienen la autorización IMPLICIT_SCHEMA. Esto permite a cualquier usuario crear objetos en cualquier esquema que aún no exista. Un esquema creado implícitamente permite a cualquier usuario crear otros objetos en dicho esquema. La posibilidad de crear seudónimos, tipos diferenciados, funciones y activadores se amplía a los esquemas creados implícitamente. Los privilegios por omisión de un esquema creado implícitamente proporcionan compatibilidad con las versiones anteriores. Si se revoca la autorización IMPLICIT_SCHEMA de PUBLIC, los esquemas se pueden crear explícitamente utilizando la sentencia CREATE SCHEMA o los usuarios (por ejemplo, los que tienen autorización DBADM) a los que se otorga la autorización IMPLICIT_SCHEMA pueden crearlos implícitamente. Aunque la revocación de la autorización IMPLICIT_SCHEMA de PUBLIC incrementa el control sobre la utilización de los nombres de esquema, también puede producir errores de autorización cuando aplicaciones existentes intentan crear objetos. Los esquemas también tienen privilegios, que permiten al propietario del esquema controlar qué usuarios tienen el privilegio de crear, modificar y eliminar objetos del esquema. A un propietario de esquema se le dan inicialmente todos estos privilegios en el esquema, con la posibilidad de Capítulo 1. Conceptos 5
- 32. otorgarlos a otros usuarios. Un esquema creado implícitamente es de propiedad del sistema y a todos los usuarios se les proporciona inicialmente el privilegio de crear objetos en dicho esquema. Un usuario con autorización SYSADM o DBADM puede cambiar los privilegios que poseen los usuarios en cualquier esquema. Por consiguiente, se puede controlar el acceso para crear, modificar y eliminar objetos en cualquier esquema (incluso uno creado implícitamente). Tablas Las tablas son estructuras lógicas mantenidas por el gestor de bases de datos. Las tablas están formadas por columnas y filas. Las filas de una tabla no están necesariamente ordenadas (el orden lo determina el programa de aplicación). En la intersección de cada columna con una fila hay un elemento de datos específico denominado valor. Una columna es un conjunto de valores del mismo tipo o de uno de sus subtipos. Una fila es una secuencia de valores ordenados de forma que el valor n sea el valor de la columna n de la tabla. Una tabla base se crea con la sentencia CREATE TABLE y se utiliza para conservar los datos habituales de los usuarios. Una tabla resultante es un conjunto de filas que el gestor de bases de datos selecciona o genera a partir de una o varias tablas base para satisfacer una consulta. Una tabla de resumen es una tabla definida por una consulta que se utiliza también para determinar los datos de la tabla. Las tablas de resumen se pueden utilizar para mejorar el rendimiento de las consultas. Si el gestor de bases de datos determina que se puede resolver una parte de una consulta utilizando una tabla de resumen, el gestor de bases de datos puede volver a escribir la consulta para utilizar la tabla de resumen. Esta decisión se basa en valores de configuración de la base de datos como, por ejemplo, los registros especiales CURRENT REFRESH AGE y CURRENT QUERY OPTIMIZATION. Una tabla puede definir el tipo de datos de cada columna por separado o basar los tipos en los atributos de un tipo estructurado definido por el usuario. Esto se denomina una tabla con tipo. Un tipo estructurado definido por el usuario puede formar parte de una jerarquía de tipos. Un subtipo hereda los atributos de su supertipo. De manera similar, una tabla con tipo puede formar parte de una jerarquía de tablas. Una subtabla hereda las columnas de su supertabla. Tenga en cuenta que el término subtipo se aplica a un tipo estructurado definido por el usuario y a todos los tipos estructurados definidos por el usuario que están por debajo del mismo en la jerarquía de tipos. Un subtipo correspondiente de un tipo estructurado T es un tipo estructurado por debajo de T en la jerarquía de tipos. De forma similar, el término subtabla se aplica a una tabla con tipo y a todas las tablas con tipo 6 Consulta de SQL, Volumen 1
- 33. que están por debajo de la misma en la jerarquía de tablas. Una subtabla correspondiente de una tabla T es una tabla que está por debajo de T en la jerarquía de tablas. Una tabla temporal declarada se crea mediante una sentencia DECLARE GLOBAL TEMPORARY TABLE y se utiliza para contener datos temporales para una aplicación individual. Esta tabla se elimina implícitamente cuando la aplicación se desconecta de la base de datos. Vistas Una vista proporciona una manera distinta de ver los datos de una o varias tablas; es una especificación con nombre de una tabla resultante. La especificación es una sentencia SELECT que se ejecuta siempre que se hace referencia a la vista en una sentencia de SQL. Una vista tiene columnas y filas igual que una tabla base. Todas las vistas se pueden utilizar como si fueran tablas base para efectuar una recuperación. Si una vista pueda utilizarse o no en una operación de inserción, actualización o supresión dependerá de su definición. Es posible utilizar las vistas para controlar el acceso a datos sensibles, porque las vistas permiten que muchos usuarios vean presentaciones distintas de los mismos datos. Por ejemplo, es posible que varios usuarios accedan a un tabla de datos sobre los empleados. Un director ve los datos sobre sus empleados pero no de los empleados de otro departamento. Un oficial de reclutamiento ve las fechas de contratación de todos los empleados, pero no sus salarios; un oficial de finanzas ve los salarios, pero no las fechas de contratación. Cada uno de estos usuarios trabaja con una vista derivada de la tabla base. Cada vista se parece a una tabla y tiene nombre propio. Cuando la columna de una vista se deriva directamente de la columna de una tabla base, esa columna de vista hereda las restricciones aplicables a la columna de la tabla base. Por ejemplo, si una vista incluye una clave foránea de su tabla base, las operaciones de inserción y actualización que utilicen dicha vista están sujetas a las mismas restricciones de referencia a las que lo está la tabla base. Asimismo, si la tabla base de una vista es una tabla padre, las operaciones de supresión y actualización que utilicen dicha vista estarán sujetas a las mismas reglas que las operaciones de supresión y actualización de la tabla base. Una vista puede obtener el tipo de datos de cada columna de la tabla resultante o basar los tipos en los atributos de un tipo estructurado definido por el usuario. Esta vista se denomina vista con tipo. De manera similar a una tabla con tipo, una vista con tipo puede formar parte de una jerarquía de vistas. Una subvista hereda las columnas de su supervista. El término subvista Capítulo 1. Conceptos 7
- 34. se aplica a una vista con tipo y a todas las vistas con tipo que están por debajo de la misma en la jerarquía de vistas. Una subvista correspondiente de una vista V es una vista por debajo de V en la jerarquía de vistas con tipo. Una vista puede quedar no operativa (por ejemplo, si se elimina la tabla base); si ocurre esto, la vista ya no estará disponible para operaciones de SQL. Seudónimos Un seudónimo es un nombre alternativo para una tabla o una vista. Se puede utilizar para hacer referencia a una tabla o vista en aquellos casos en los que pueda hacerse referencia a una tabla o vista existente. Un seudónimo no puede utilizarse en todos los contextos; por ejemplo, no puede utilizarse en la condición de comprobación de una restricción de comprobación. Un seudónimo no puede hacer referencia a una tabla temporal declarada. Al igual que las tablas o las vistas, un seudónimo puede crearse, eliminarse y tener comentarios asociados. Sin embargo, a diferencia de las tablas, los seudónimos pueden hacerse referencia entre sí en un proceso llamado encadenamiento. Los seudónimos son nombres de referencia pública, por lo que no es necesaria ninguna autorización ni privilegio especial para utilizarlos. Sin embargo, el acceso a la tabla o a la vista a la que un seudónimo hace referencia sí que requiere la autorización asociada con estos objetos. Hay otros tipos de seudónimos como, por ejemplo, los seudónimos de base de datos y de red. También se pueden crear seudónimos para apodos que hagan referencia a vistas o tablas de datos ubicadas en sistemas federados. Índices Un índice es un conjunto ordenado de punteros para filas de una tabla base. Cada índice se basa en los valores de los datos de una o varias columnas de la tabla. Un índice es un objeto que está separado de los datos de la tabla. Cuando se crea un índice, el gestor de bases de datos crea este objeto y lo mantiene automáticamente. El gestor de bases de datos utiliza los índices para: v Mejorar el rendimiento. En la mayoría de los casos, el acceso a los datos es más rápido con un índice. Aunque no puede crearse un índice para una vista, un índice creado para la tabla en la que se basa una vista puede mejorar a veces el rendimiento de las operaciones en esta vista. v Asegurar la exclusividad. Una tabla con un índice de unicidad no puede tener filas con claves idénticas. 8 Consulta de SQL, Volumen 1
- 35. Claves Una clave es un conjunto de columnas que se pueden utilizar para identificar o para acceder a una fila o filas determinadas. La clave viene identificada en la descripción de una tabla, índice o restricción de referencia. Una misma columna puede formar parte de más de una clave. Una clave compuesta de más de una columna se denomina una clave compuesta. En una tabla con una clave compuesta, el orden de las columnas dentro de la clave compuesta no está restringido por el orden de las columnas en la tabla. El valor de una clave compuesta indica un valor compuesto. Así, por ejemplo la regla “el valor de la clave foránea debe ser igual al valor de la clave primaria” significa que cada componente del valor de la clave foránea debe ser igual al componente del valor correspondiente de la clave primaria. Una clave de unicidad es una clave restringida de manera que no puede tener dos valores iguales. Las columnas de una clave de unicidad no pueden contener valores nulos. El gestor de bases de datos impone la restricción durante la ejecución de cualquier operación que cambie los valores de los datos como, por ejemplo, INSERT o UPDATE. El mecanismo utilizado para imponer la restricción se denomina índice de unicidad. De este modo, cada clave de unicidad es una clave de un índice de unicidad. También se dice que dichos índices tienen el atributo UNIQUE. Una clave primaria es un caso especial de clave de unicidad. Una tabla no puede tener más de una clave primaria. Una clave foránea es una clave que se especifica en la definición de una restricción de referencia. Una clave de particionamiento es una clave que forma parte de la definición de una tabla de una base de datos particionada. La clave de particionamiento se utiliza para determinar la partición en la que se almacena la fila de datos. Si se define una clave de particionamiento, las claves de unicidad y las claves primarias deben incluir las mismas columnas que la clave de particionamiento, pero pueden tener columnas adicionales. Una tabla no puede tener más de una clave de particionamiento. Restricciones Una restricción es una regla que impone el gestor de bases de datos. Hay tres tipos de restricciones: v Una restricción de unicidad es una regla que prohíbe los valores duplicados en una o varias columnas de una tabla. Las restricciones de unicidad a las Capítulo 1. Conceptos 9
- 36. que se da soporte son la clave de unicidad y la clave primaria. Por ejemplo, se puede definir una restricción de unicidad en el identificador de proveedor de la tabla de proveedores para asegurarse de que no se da el mismo identificador de proveedor a dos proveedores. v Una restricción de referencia es una regla lógica acerca de los valores de una o varias columnas de una o varias tablas. Por ejemplo, un conjunto de tablas que comparte información sobre los proveedores de una empresa. Ocasionalmente, el nombre de un proveedor cambia. Puede definir una restricción de referencia que indique que el ID del proveedor de una tabla debe coincidir con un ID de proveedor de la información de proveedor. Esta restricción impide que se realicen operaciones de inserción, actualización o supresión que, de lo contrario, harían que faltara información del proveedor. v Una restricción de comprobación de tabla establece restricciones en los datos que se añaden a una tabla específica. Por ejemplo, una restricción de comprobación de tabla puede garantizar que el nivel salarial de un empleado no sea inferior a 20.000 euros siempre que se añadan o se actualicen datos salariales en una tabla que contiene información de personal. Las restricciones de referencia y de comprobación de tabla pueden activarse y desactivarse. Generalmente es una buena idea, por ejemplo, desactivar la imposición de una restricción cuando se cargan grandes cantidades de datos en una base de datos. Restricciones de unicidad Una restricción de unicidad es la regla que establece que los valores de una clave sólo son válidos si son exclusivos en una tabla. Las restricciones de unicidad son opcionales y pueden definirse en las sentencias CREATE TABLE o ALTER TABLE utilizando la cláusula PRIMARY KEY o la cláusula UNIQUE. Las columnas especificadas en una restricción de unicidad deben definirse como NOT NULL. El gestor de bases de datos utiliza un índice de unicidad para forzar la unicidad de la clave durante los cambios en las columnas de la restricción de unicidad. Una tabla puede tener un número arbitrario de restricciones de unicidad y como máximo una restricción de unicidad definida como la clave primaria. Una tabla no puede tener más de una restricción de unicidad en el mismo conjunto de columnas. Una restricción de unicidad a la que hace referencia la clave foránea de una restricción de referencia se denomina clave padre. 10 Consulta de SQL, Volumen 1
- 37. Cuando se define una restricción de unicidad en una sentencia CREATE TABLE, el gestor de bases de datos crea automáticamente un índice de unicidad y lo designa como un índice principal o de unicidad necesario para el sistema. Cuando se define una restricción de unicidad en una sentencia ALTER TABLE y existe un índice en las mismas columnas, dicho índice se designa como de unicidad y necesario para el sistema. Si no existe tal índice, el gestor de bases de datos crea automáticamente el índice de unicidad y lo designa como un índice principal o de unicidad necesario para el sistema. Observe que existe una distinción entre la definición de una restricción de unicidad y la creación de un índice de unicidad. Aunque ambos impongan la exclusividad, un índice de unicidad permite la existencia de columnas que pueden contener valores nulos y generalmente no puede utilizarse como una clave padre. Restricciones de referencia La integridad de referencia es el estado de una base de datos en la que todos los valores de todas las claves foráneas son válidos. Una clave foránea es una columna o un conjunto de columnas de una tabla cuyos valores deben coincidir obligatoriamente con, como mínimo, un valor de una clave primaria o de una clave de unicidad de una fila de su tabla padre. Una restricción de referencia es la regla que establece que los valores de la clave foránea sólo son válidos si se cumple una de las condiciones siguientes: v Aparecen como valores de una clave padre. v Algún componente de la clave foránea es nulo. La tabla que contiene la clave padre se denomina la tabla padre de la restricción de referencia y se dice que la tabla que contiene la clave foránea es dependiente de dicha tabla. Las restricciones de referencia son opcionales y pueden definirse en la sentencia CREATE TABLE o en la sentencia ALTER TABLE. Las restricciones de referencia las impone el gestor de bases de datos durante la ejecución de las sentencias INSERT, UPDATE, DELETE, ALTER TABLE, ADD CONSTRAINT y SET INTEGRITY. Las restricciones de referencia con una regla de supresión o una regla de actualización de RESTRICT se imponen antes que el resto de restricciones de referencia. Las restricciones de referencia con una regla de supresión o una regla de actualización de NO ACTION se comportan igual que RESTRICT en la mayoría de casos. Tenga en cuenta que es posible combinar las restricciones de referencia, las restricciones de comprobación y los activadores. Capítulo 1. Conceptos 11
- 38. Las reglas de integridad de referencia implican los conceptos y terminología siguientes: Clave padre Clave primaria o clave de unicidad de una restricción de referencia. Fila padre Fila que tiene, como mínimo, una fila dependiente. Tabla padre Tabla que contiene la clave padre de una restricción de referencia. Una tabla puede definirse como padre en un número arbitrario de restricciones de referencia. Una tabla que es padre en una restricción de referencia también puede ser dependiente en una restricción de referencia. Tabla dependiente Tabla que contiene como mínimo una restricción de referencia en su definición. Una tabla puede definirse como dependiente en un número arbitrario de restricciones de referencia. Una tabla que es dependiente en una restricción de referencia también puede ser padre en una restricción de referencia. Tabla descendiente Una tabla es descendiente de la tabla T si es dependiente de T o descendiente de una tabla dependiente de T. Fila dependiente Fila que tiene, como mínimo, una fila padre. Fila descendiente Una fila es descendiente de la fila r si es dependiente de r o descendiente de una dependiente de r. Ciclo de referencia Conjunto de restricciones de referencia en el que cada tabla del conjunto es descendiente de sí misma. Tabla autorreferente Tabla que es padre y dependiente en la misma restricción de referencia. La restricción se denomina restricción de autorreferencia. Fila de autorreferencia Fila que es padre de sí misma. Regla de inserción La regla de inserción de una restricción de referencia es la que establece que un valor de inserción que no sea nulo de la clave foránea debe coincidir con algún valor de la clave padre de la tabla padre. El valor de la clave foránea compuesta será nulo si algún componente del valor es nulo. Es una regla implícita cuando se especifica una clave foránea. 12 Consulta de SQL, Volumen 1
- 39. Regla de actualización La regla de actualización de una restricción de referencia se especifica al definir la restricción de referencia. Las opciones son NO ACTION y RESTRICT. La regla de actualización se aplica al actualizar una fila de la tabla padre o una fila de la tabla dependiente. En el caso de una fila padre, cuando se actualiza un valor de una columna de la clave padre, se aplican las reglas siguientes: v Si cualquier fila de la tabla dependiente coincide con el valor original de la clave, se rechaza la actualización cuando la regla de actualización es RESTRICT. v Si cualquier fila de la tabla dependiente no tiene una clave padre correspondiente cuando se completa la sentencia de actualización (excluyendo los activadores AFTER), se rechaza la actualización cuando la regla de actualización es NO ACTION. En el caso de una fila dependiente, la regla de actualización NO ACTION es implícita cuando se especifica una clave foránea. NO ACTION significa que un valor de actualización que no sea nulo de una clave foránea debe coincidir con algún valor de la clave padre de la tabla padre cuando se complete la sentencia de actualización. El valor de la clave foránea compuesta será nulo si algún componente del valor es nulo. Regla de supresión La regla de supresión de una restricción de referencia se especifica al definir la restricción de referencia. Las opciones son NO ACTION, RESTRICT, CASCADE o SET NULL. SET NULL sólo puede especificarse si hay alguna columna de la clave foránea que permita valores nulos. La regla de supresión de una restricción de referencia se aplica al suprimir una fila de la tabla padre. Para ser más exactos, esta regla se aplica cuando una fila de la tabla padre es el objeto de una operación de supresión o de supresión propagada (definida a continuación) y dicha fila tiene dependientes en la tabla dependiente de la restricción de referencia. Examinemos un ejemplo donde P es la tabla padre, D es la tabla dependiente y p es una fila padre que es el objeto de una operación de supresión o de supresión propagada. La regla de supresión funciona del modo siguiente: v Con RESTRICT o NO ACTION, se produce un error y no se suprime ninguna fila. v Con CASCADE, la operación de supresión se propaga a los dependientes de p en la tabla D. v Con SET NULL, cada columna con posibilidad de nulos de la clave foránea de cada dependiente de p en la tabla D se establece en nulo. Capítulo 1. Conceptos 13
- 40. Cada restricción de referencia en la que una tabla sea padre tiene su propia regla de supresión, y todas las reglas de supresión aplicables se utilizan para determinar el resultado de la operación de supresión. Así, una fila no puede suprimirse si tiene dependientes en una restricción de referencia con una regla de supresión RESTRICT o NO ACTION o la supresión se propaga en cascada a cualquiera de sus descendientes que sean dependientes en una restricción de referencia con la regla de supresión RESTRICT o NO ACTION. La supresión de una fila de la tabla padre P implica a otras tablas y puede afectar a las filas de dichas tablas: v Si la tabla D es dependiente de P y la regla de supresión es RESTRICT o NO ACTION, D se implicará en la operación pero no se verá afectada por la misma. v Si D es dependiente de P y la regla de supresión es SET NULL, D estará implicada en la operación y las filas de D podrán actualizarse durante la operación. v Si D es dependiente de P y la regla de supresión es CASCADE, D estará implicada en la operación y las filas de D podrán suprimirse durante la operación. Si se suprimen filas de D, se dice que la operación de supresión en P se propaga a D. Si D es también una tabla padre, las acciones descritas en esta lista se aplican a su vez a los elementos dependientes de D. De cualquier tabla que pueda estar implicada en una operación de supresión en P se dice que está conectada por supresión a P. Así, una tabla está conectada por supresión a la tabla P si es dependiente de P o es dependiente de una tabla hacia la que se propagan en cascada operaciones de supresión desde P. Restricciones de comprobación de tabla Una restricción de comprobación de tabla es una regla que especifica los valores permitidos en una o varias columnas de cada fila de una tabla. Una restricción es opcional y puede definirse utilizando la sentencia CREATE TABLE o ALTER TABLE. La especificación de restricciones de comprobación de tabla se realiza mediante una forma restringida de condición de búsqueda. Una de las restricciones consiste en que un nombre de columna de una restricción de comprobación de tabla de la tabla T debe identificar una columna de la tabla T. Una tabla puede tener un número arbitrario de restricciones de comprobación de tabla. Una restricción de comprobación de tabla se impone aplicando su condición de búsqueda en cada fila que se inserte o actualice. Si el resultado de la condición de búsqueda es falso en cualquiera de las filas, se produce un error. 14 Consulta de SQL, Volumen 1
- 41. Cuando hay una o varias restricciones de comprobación de tabla definidas en la sentencia ALTER TABLE para una tabla en la que existen datos, éstos se comprueban con la nueva condición antes de que finalice la sentencia ALTER TABLE. La sentencia SET INTEGRITY puede utilizarse para colocar la tabla en estado pendiente de comprobación, lo que permite que la sentencia ALTER TABLE prosiga sin comprobar los datos. Información relacionada: v “SET INTEGRITY sentencia” en la publicación Consulta de SQL, Volumen 2 v Apéndice I, “Interacción de los activadores con las restricciones” en la página 873 Niveles de aislamiento El nivel de aislamiento asociado con un proceso de aplicación define el grado de aislamiento de dicho proceso de aplicación respecto a otros procesos de aplicación que se ejecutan simultáneamente. Por consiguiente, el nivel de aislamiento de un proceso de aplicación especifica: v El grado al que las filas leídas y actualizadas por la aplicación están disponibles para otros procesos de aplicación que se ejecutan simultáneamente. v El grado al que puede afectar a la aplicación la actividad de actualización de otros procesos de aplicación que se ejecutan simultáneamente. El nivel de aislamiento se especifica como un atributo de un paquete y se aplica a los procesos de aplicación que hacen uso del paquete. El nivel de aislamiento se especifica en el proceso de preparación del proceso. En función del tipo de bloqueo, limita o impide el acceso a los datos por parte de procesos de aplicación simultáneos. (Las tablas temporales declaradas y las filas de las mismas no pueden bloquearse, pues sólo la aplicación que las declaró puede acceder a ellas). El gestor de bases de datos da soporte a tres categorías generales de bloqueos: Compartimiento Limita los procesos de aplicación simultáneos a operaciones de sólo lectura de los datos. Actualización Limita los procesos de aplicación simultáneos a operaciones de sólo lectura de los datos, si dichos procesos no han declarado que podrían actualizar la fila. El gestor de bases de datos asume que el proceso que actualmente mira a una fila es posible que la actualice. Exclusivo Evita que los procesos de aplicación simultáneos accedan a los datos Capítulo 1. Conceptos 15
- 42. de todas formas. No se aplica a los procesos de aplicación con un nivel de aislamiento de lectura no confirmada, que pueden leer los datos pero no modificarlos. El bloqueo se produce en la fila de la tabla base. Sin embargo, el gestor de bases de datos puede sustituir múltiples bloqueos de filas por un solo bloqueo de tabla. Esto se denomina escalada de bloqueos. Un proceso de aplicación tiene garantizado al menos el nivel mínimo de bloqueo solicitado. El gestor de bases de datos de DB2 Universal Database da soporte a cuatro niveles de aislamiento. Independientemente del nivel de aislamiento, el gestor de bases de datos coloca bloqueos de exclusividad en cada fila que se inserta, actualiza o suprime. Por lo tanto, los niveles de aislamiento aseguran que las filas que cambia el proceso de aplicación durante una unidad de trabajo no las pueda modificar ningún otro proceso de aplicación hasta que la unidad de trabajo haya finalizado. Los niveles de aislamiento son: v Lectura repetible (RR) Este nivel garantiza que: – Cualquier fila leída durante una unidad de trabajo no puede modificarla ningún otro proceso de aplicación hasta que la unidad de trabajo haya finalizado. Las filas se leen en la misma unidad de trabajo que la sentencia OPEN correspondiente. El uso de la cláusula WITH RELEASE opcional en la sentencia CLOSE significa que, si se vuelve a abrir el cursor, ya no se aplicará ninguna garantía respecto a las lecturas no repetibles y no se aplicarán ya lecturas fantasma a ninguna fila a la que se haya accedido anteriormente. – Las filas modificadas por otro proceso de aplicación no se pueden leer hasta que dicho proceso de aplicación las confirme. El nivel de Lectura repetible no permite ver las filas fantasma (consulte Estabilidad de lectura). Además de los bloqueos de exclusividad, un proceso de aplicación que se ejecute en el nivel RR adquiere, como mínimo, bloqueos de compartimiento en todas las filas a las que hace referencia. Además, el bloqueo se realiza de forma que el proceso de aplicación quede completamente aislado de los efectos de los procesos de aplicación simultáneos. v Estabilidad de lectura (RS) Igual que el nivel de Lectura repetible, el nivel de Estabilidad de lectura asegura que: – Cualquier fila leída durante una unidad de trabajo no puede modificarla ningún otro proceso de aplicación hasta que la unidad de trabajo haya finalizado. Las filas se leen en la misma unidad de trabajo que la sentencia OPEN correspondiente. El uso de la cláusula WITH RELEASE 16 Consulta de SQL, Volumen 1
- 43. opcional en la sentencia CLOSE significa que, si se vuelve a abrir el cursor, ya no se aplicará ninguna garantía respecto a las lecturas no repetibles a ninguna fila a la que se haya accedido anteriormente. – Las filas modificadas por otro proceso de aplicación no se pueden leer hasta que dicho proceso de aplicación las confirme. A diferencia de la Lectura repetible, la Estabilidad de lectura no aísla completamente el proceso de aplicación de los efectos de procesos de aplicación simultáneos. En el nivel RS, los procesos de aplicación que emiten la misma consulta más de una vez pueden ver filas adicionales producidas por la adición de información nueva a la base de datos que realizan otros procesos de aplicación. Estas filas adicionales se denominan filas fantasma. Por ejemplo, puede aparecer una fila fantasma en la situación siguiente: 1. El proceso de aplicación P1 lee el conjunto de filas n que satisfacen alguna condición de búsqueda. 2. Entonces el proceso de aplicación P2 inserta una o más filas que satisfacen la condición de búsqueda y confirma esas nuevas inserciones. 3. P1 lee nuevamente el conjunto de filas con la misma condición de búsqueda y obtiene tanto las filas originales como las filas insertadas por P2. Además de los bloqueos de exclusividad, un proceso de aplicación que se ejecute al nivel de aislamiento RS adquiere, como mínimo, bloqueos de compartimiento en todas las filas calificadas para ello. v Estabilidad del cursor (CS) Al igual que el nivel de Lectura repetible, el nivel de Estabilidad del cursor asegura que cualquier fila que haya sido modificada por otro proceso de aplicación no pueda leerse hasta que sea confirmada por dicho proceso de aplicación. A diferencia de la Lectura repetible, la Estabilidad del cursor sólo asegura que otros procesos de aplicación no modifiquen la fila actual de cada cursor actualizable. De este modo, las filas leídas durante una unidad de trabajo pueden ser modificadas por otros procesos de aplicación. Además de los bloqueos de exclusividad, un proceso de aplicación que se ejecute al nivel de aislamiento CS adquiere, como mínimo, un bloqueo de compartimiento sobre la fila actual de cada cursor. v Lectura no confirmada (UR) Para una operación SELECT INTO, una operación FETCH con un cursor de sólo lectura, una operación de selección completa de INSERT, una operación Capítulo 1. Conceptos 17
- 44. de selección completa de fila en UPDATE o una operación de selección completa escalar (dondequiera que se utilice), el nivel de Lectura no confirmada permite que: – Cualquier fila leída durante una unidad de trabajo sea modificada por otros procesos de aplicación. – Cualquier fila cambiada por otro proceso de aplicación pueda leerse aunque dicho proceso de aplicación no ha confirmado el cambio. Para otras operaciones, se aplican las reglas asociadas con el nivel CS. Información relacionada: v “DECLARE CURSOR sentencia” en la publicación Consulta de SQL, Volumen 2 v Apéndice H, “Comparación de niveles de aislamiento” en la página 871 Consultas Una consulta es un componente de determinadas sentencias de SQL; especifica una tabla resultante (temporal). Información relacionada: v “Consultas de SQL” en la página 579 Expresiones de tabla Una expresión de tabla crea una tabla resultante temporal a partir de una consulta simple. Las cláusulas precisan adicionalmente la tabla resultante. Por ejemplo, puede utilizar una expresión de tabla como consulta para seleccionar todos los directores de varios departamentos, especificar que deben tener más de 15 años de experiencia laboral y que tienen que estar en la sucursal de Nueva York. Una expresión de tabla común es como una vista temporal de una consulta compleja. Se puede hacer referencia a ella en otros lugares de la consulta y puede utilizarse en lugar de una vista. Todos los usos de una expresión de tabla común específica en una consulta compleja comparten la misma vista temporal. Se puede utilizar de forma repetida una expresión de tabla común en una consulta para dar soporte a aplicaciones como, por ejemplo, sistemas de reservas de líneas aéreas, generadores de listas de materiales (BOM) y planificación de redes. 18 Consulta de SQL, Volumen 1
- 45. Información relacionada: v Apéndice L, “Ejemplo de recurrencia: Lista de material” en la página 911 Procesos, simultaneidad y recuperación de aplicaciones Todos los programas SQL se ejecutan como parte de un proceso de aplicación o agente. Un proceso de aplicación implica la ejecución de uno o varios programas y es la unidad a la que el gestor de bases de datos asigna los distintos recursos y bloqueos. Los distintos procesos de la aplicación pueden implicar la ejecución de programas diferentes, o distintas ejecuciones del mismo programa. Puede que más de un proceso de aplicación solicite acceso a los mismos datos al mismo tiempo. El bloqueo es el mecanismo que se utiliza para mantener la integridad de los datos en tales condiciones, con lo que se evita, por ejemplo, que dos procesos de la aplicación actualicen simultáneamente la misma fila de datos. El gestor de bases de datos adquiere bloqueos para evitar que los cambios no confirmados efectuados por un proceso de aplicación sean percibidos accidentalmente por otro proceso. El gestor de bases de datos libera todos los bloqueos que ha adquirido y retenido en nombre de un proceso de aplicación cuando finaliza dicho proceso. Sin embargo, un proceso de aplicación puede solicitar explícitamente que se liberen antes los bloqueos. Esto se consigue utilizando una operación de confirmación, que libera bloqueos adquiridos durante la unidad de trabajo y también confirma cambios en la base de datos durante la unidad de trabajo. El gestor de bases de datos proporciona una forma de restituir los cambios no confirmados realizados por un proceso de aplicación. Esto podría ser necesario en caso de error en un proceso de aplicación o si se produce un punto muerto o un tiempo excedido por bloqueo. Un proceso de aplicación puede solicitar de modo explícito que se restituyan los cambios en la base de datos. Esto se hace utilizando una operación de retrotracción. Una unidad de trabajo es una secuencia recuperable de operaciones dentro de un proceso de aplicación. Una unidad de trabajo se inicia cuando se inicia un proceso de aplicación o cuando termina la unidad de trabajo anterior y no sea debido a la finalización del proceso de aplicación. Una unidad de trabajo finaliza mediante una operación de confirmación, de retrotracción o por el final de un proceso de aplicación. Una operación de retrotracción o confirmación sólo afecta a los cambios realizados en la base de datos durante la unidad de trabajo que está terminando. Capítulo 1. Conceptos 19
- 46. Mientras estos cambios permanecen sin confirmar, otros procesos de aplicaciones no pueden percibirlos y dichos cambios pueden restituirse. Sin embargo, esto no es así cuando el nivel de aislamiento es de lectura no confirmada (UR). Una vez confirmados, los demás procesos de aplicación pueden acceder a estos cambios de la base de datos y éstos ya no se pueden restituir mediante una retrotracción. Tanto la CLI (interfaz de nivel de llamada) de DB2 como SQL incorporado permiten una modalidad de conexión llamada transacciones simultáneas que soporta múltiples conexiones, cada una de las cuales es una transacción independiente. Una aplicación puede tener múltiples conexiones simultáneas con la misma base de datos. Los bloqueos adquiridos por el gestor de bases de datos para un proceso de aplicación se conservan hasta el final de una unidad de trabajo. Sin embargo, esto no es así cuando el nivel de aislamiento es de estabilidad del cursor (CS, en el que el bloqueo se libera cuando el cursor se mueve de una fila a otra) o de lectura no confirmada(UR, en el que no se obtienen bloqueos). No se puede impedir nunca que un proceso de aplicación realice operaciones debido a sus propios bloqueos. Sin embargo, si una aplicación utiliza transacciones simultáneas, los bloqueos de una transacción pueden afectar la operación de una transacción simultánea. El inicio y la finalización de una unidad de trabajo definen los puntos de coherencia en un proceso de aplicación. Por ejemplo, una transacción bancaria puede incluir la transferencia de fondos de una cuenta a otra. Una transacción de este tipo necesitaría que dichos fondos se restaran de la primera cuenta y se sumaran más tarde a la segunda cuenta. Después de esta sustracción, los datos son incoherentes. La coherencia sólo queda restablecida cuando los fondos se han sumado a la segunda cuenta. Cuando se hayan completado los dos pasos, podrá utilizarse la operación de confirmación para finalizar la unidad de trabajo, con lo que los cambios estarán disponibles para otros procesos de aplicación. Si se produce una anomalía antes de que finalice la unidad de trabajo, el gestor de bases de datos retrotraerá los cambios no confirmados para restablecer la coherencia de los datos que se presupone que existía al iniciar la unidad de trabajo. 20 Consulta de SQL, Volumen 1
- 47. Punto de Nuevo punto coherencia de coherencia una unidad de trabajo PERIODO actualizaciones de base de datos Inicio de la Confirmación unidad de trabajo Fin de la unidad de trabajo Figura 2. Unidad de trabajo con una sentencia COMMIT Punto de Nuevo punto coherencia de coherencia una unidad de trabajo actualizaciones restituir PERIODO de base de datos actualizaciones Inicio de la Anomalía; Los datos se devuelven unidad de trabajo Comienzo de la a su estado inicial; retrotracción Fin de la unidad de trabajo Figura 3. Unidad de trabajo con una sentencia ROLLBACK Conceptos relacionados: v “Niveles de aislamiento” en la página 15 Interfaz de nivel de llamada de DB2 (CLI) y Open Database Connectivity (ODBC) La interfaz de nivel de llamada de DB2 es una interfaz de programación de aplicaciones que proporciona funciones para que los programas de aplicación procesen las sentencias de SQL dinámico. Los programas CLI también se pueden compilar utilizando el Software Developer’s Kit de Open Database Capítulo 1. Conceptos 21
- 48. Connectivity (suministrado por Microsoft u otro proveedor), que permite acceder a fuentes de datos ODBC. A diferencia del SQL interno, esta interfaz no requiere precompilación. Las aplicaciones pueden ejecutarse en distintas bases de datos sin necesidad de volver a compilarlas en cada una de estas bases de datos. Las aplicaciones utilizan llamadas a procedimientos en tiempo de ejecución para conectarse a bases de datos, emitir sentencias de SQL y recuperar datos e información de estado. La interfaz CLI de DB2 proporciona muchas características que no están disponibles en SQL interno. Por ejemplo: v La CLI proporciona llamadas de función que soportan una forma de consultar catálogos de bases de datos que es coherente en toda la familia DB2. Esto reduce la necesidad de escribir consultas de catálogo que deban adaptarse a servidores de bases de datos concretos. v La CLI proporciona la capacidad de desplazarse con un cursor de estas maneras: – Hacia adelante, una o más filas – Hacia atrás, una o más filas – Hacia adelante desde la primera fila, una o más filas – Hacia atrás desde la última fila, una o más filas – Desde una posición en el cursor almacenada previamente. v Los procedimientos almacenados llamados desde programas de aplicación que se hayan escrito con la CLI pueden devolver conjuntos resultantes a esos programas. Programas Conectividad de bases de datos Java (JDBC) y SQL incorporado para Java (SQLJ) DB2 Universal Database implanta dos API de programación Java basadas en estándares: Conectividad de bases de datos Java (JDBC) y SQL incorporado para Java (SQLJ). Se pueden utilizar las dos para crear aplicaciones Java y applets que acceden a DB2: v Las llamadas JDBC se convierten en llamadas CLI de DB2 a través de métodos nativos Java. Las peticiones JDBC fluyen del DB2 cliente a través de la CLI de DB2 hasta el servidor de DB2. JDBC no puede utilizar SQL estático. v Las aplicaciones SQLJ utilizan JDBC como base para tareas como conectarse a bases de datos y manejar errores de SQL, pero también pueden contener sentencias de SQL estático intercaladas en los archivos fuente SQLJ. Un archivo fuente SQLJ debe convertirse con el conversor SQLJ para que se pueda compilar el código Java resultante. 22 Consulta de SQL, Volumen 1
- 49. Paquetes Un paquete es un objeto generado durante la preparación de un programa que contiene todas las secciones en un único archivo fuente. Una sección es el formato compilado de una sentencia de SQL. Aunque cada sección corresponde a una sentencia, no cada sentencia no tiene una sección. Las secciones creadas para SQL estático son comparables al formato vinculado u operativo de las sentencias de SQL. Las secciones creadas para SQL dinámico son comparables a las estructuras de control de espacios reservados utilizadas en tiempo de ejecución. Vistas de catálogo El gestor de bases de datos mantiene un conjunto de vistas tablas base que contienen información sobre los datos que se encuentran bajo su control. Estas vistas y tablas base se conocen en su conjunto como el catálogo. El catálogo contiene información acerca de la estructura lógica y física de los objetos de la base de datos como, por ejemplo, tablas, vistas, índices, paquetes y funciones. También contiene información estadística. El gestor de bases de datos garantiza que las descripciones del catálogo siempre sean precisas. Las vistas de catálogo son como cualquier otra vista de la base de datos. Se pueden utilizar sentencias de SQL para ver los datos de las vistas de catálogo. Para modificar ciertos valores del catálogo puede utilizarse un conjunto de vistas actualizables del catálogo. Información relacionada: v “Vistas de catálogo del sistema” en la página 668 conversión de caracteres Una serie es una secuencia de bytes que puede representar caracteres. Todos los caracteres de una serie tienen una representación de codificación común. En algunos casos, puede ser necesario convertir estos caracteres a una representación de códigos diferente, conocida como conversión de caracteres. La conversión de caracteres, cuando es necesaria, es automática y, cuando es satisfactoria, es transparente para la aplicación. La conversión de caracteres puede producirse cuando una sentencia de SQL se ejecuta de manera remota. Tenga en cuenta, por ejemplo, los casos siguientes en los que las representaciones de codificación pueden ser distintas en el sistema de envío y en el de recepción: v Los valores de las variables del lenguaje principal se envían desde el peticionario de aplicaciones al servidor de aplicaciones. Capítulo 1. Conceptos 23
- 50. v Los valores de las columnas del resultado se envían desde el servidor de aplicaciones al peticionario de aplicaciones. A continuación se muestra una lista de los términos utilizados al tratar la conversión de caracteres: juego de caracteres Juego definido de caracteres. Por ejemplo, el siguiente juego de caracteres aparece en varias páginas de códigos: v 26 letras no acentuadas de la A a la Z v 26 letras no acentuadas de la a a la z v dígitos del 0 al 9 v .,:;?()'"/−_&+%*=<> página de códigos Conjunto de asignaciones de caracteres a elementos de código. En el esquema de codificación ASCII para la página de códigos 850, por ejemplo, se asigna a "A" el elemento de código X'41' y a "B" el elemento de códigoX'42'. En una página de códigos, cada elemento de código tiene un solo significado específico. Una página de códigos es un atributo de la base de datos. Cuando un programa de aplicación se conecta a la base de datos, el gestor de bases de datos determina la página de códigos de la aplicación. elemento de código Patrón de bits que representa de forma exclusiva un carácter. esquema de codificación Conjunto de reglas utilizadas para representar datos de tipo carácter, por ejemplo: v ASCII de un solo byte v EBCDIC de un solo byte v ASCII de doble byte v ASCII mixto de un solo byte y de doble byte La figura siguiente muestra cómo un juego de caracteres típico puede correlacionarse con diferentes elementos de código de dos páginas de códigos distintas. Incluso con el mismo esquema de codificación, existen muchas páginas de códigos diferentes y el mismo elemento de código puede representar un carácter diferente en páginas de código diferentes. Además, un byte de una serie de caracteres no representa necesariamente un carácter de un juego de caracteres de un solo byte (SBCS). Las series de caracteres también se utilizan para datos de bits y mixtos. Los datos mixtos son una combinación de caracteres de un solo byte, de doble byte o de múltiples bytes. 24 Consulta de SQL, Volumen 1
- 51. Los datos de bits (columnas definidas como FOR BIT DATA, BLOB o series binarias) no están asociados a ningún juego de caracteres. página de códigos: pp1 (ASCII) página de códigos: pp2 (EBCDIC) 0 1 2 3 4 5 E F 0 1 A B C D E F 0 0 @ P Â 0 # 0 1 1 A Q À 1 $ A J 1 2 " 2 B R Å 2 s % B K S 2 3 3 C S Á 3 t C L T 3 4 4 D T Ã 4 u * D M U 4 5 % 5 E U Ä 5 v ( E N V 5 . > 5 : } E N 8 Ö E ! Â F / * 0 ® F À ¢ ; Á { punto de juego de juego de caracteres ss1 código: 2F caracteres ss1 (en página de códigos pp2) (en página de códigos pp1) Figura 4. Correlación de un juego de caracteres en diferentes páginas de códigos El gestor de bases de datos determina los atributos de páginas de códigos para todas las series de caracteres cuando una aplicación se vincula con una base de datos. Los atributos de página de códigos posibles son: Página de códigos de base de datos La página de códigos de base de datos se almacena en el archivo de configuración de la base de datos. El valor se especifica cuando se crea la base de datos y no puede modificarse. Capítulo 1. Conceptos 25
- 52. Página de códigos de aplicación La página de códigos bajo la que se ejecuta la aplicación. No es necesariamente la misma página de códigos bajo la que se ha vinculación la aplicación. Página de códigos 0 Representa una serie derivada de una expresión que contiene un valor FOR BIT DATA o un valor BLOB. Las páginas de códigos de series de caracteres tienen los atributos siguientes: v Las columnas pueden estar en la página de códigos de la base de datos o en la página de códigos 0 (si se han definido como de caracteres FOR BIT DATA o BLOB). v Las constantes y los registros especiales (por ejemplo, USER, CURRENT SERVER) están en la página de códigos de la base de datos. Las constantes se convierten a la página de códigos de la base de datos cuando una sentencia de SQL se vincula con la base de datos. v Las variables de lenguaje principal de entrada se encuentran en la página de códigos de la aplicación. Para la Versión 8, los datos de serie de variables del lenguaje principal de entrada se convierten, si es necesario, de la página de códigos de la aplicación a la página de códigos de la base de datos antes de su utilización. La excepción se produce cuando se utiliza una variable del lenguaje principal en un contexto en el que se interpretará como datos de bit; por ejemplo, cuando la variable del lenguaje principal debe asignarse a una columna que está definida como FOR BIT DATA. Se utiliza un conjunto de reglas para determinar los atributos de página de códigos para las operaciones que combinan objetos de serie como, por ejemplo, operaciones escalares, operaciones con conjuntos o concatenaciones. Los atributos de la página de códigos se utilizan para determinar los requisitos para la conversión de páginas de códigos de las series durante la ejecución. Información relacionada: v “Asignaciones y comparaciones” en la página 126 v “Reglas para la conversión de series” en la página 150 Supervisores de sucesos Los supervisores de sucesos se utilizan para reunir información sobre la base de datos y las aplicaciones conectadas cuando se producen los eventos especificados. Los sucesos representan transiciones en la actividad de la base de datos: por ejemplo, conexiones, puntos muertos, sentencias y transacciones. Es posible definir un supervisor de sucesos por el tipo de suceso o los sucesos 26 Consulta de SQL, Volumen 1
- 53. que desea supervisar. Por ejemplo, un supervisor de sucesos espera que se produzca un punto muerto. Cuando se produce, reúne la información sobre las aplicaciones implicadas y los bloqueos en contención. Mientras el supervisor de instantáneas suele utilizarse para el mantenimiento preventivo y el análisis de problemas, los supervisores de sucesos se utilizan para alertar a los administradores sobre problemas inmediatos o para rastrear problemas inminentes. Para crear un supervisor de sucesos, utilice la sentencia de SQL CREATE EVENT MONITOR. Los supervisores de sucesos sólo reúnen datos de sucesos cuando están activos. Para activar o desactivar un supervisor de sucesos, utilice la sentencia de SQL SET EVENT MONITOR STATE. El estado de un supervisor de sucesos (si está activo o inactivo) puede determinarse por la función de SQL EVENT_MON_STATE. Cuando se ejecuta la sentencia de SQL CREATE EVENT MONITOR, la definición del supervisor de sucesos que crea se almacena en las tablas de catálogo del sistema de bases de datos siguientes: v SYSCAT.EVENTMONITORS: los supervisores de sucesos definidos para la base de datos. v SYSCAT.EVENTS: Los sucesos supervisados para la base de datos. v SYSCAT.EVENTTABLES: las tablas destino de los supervisores de sucesos de tablas. Cada supervisor de sucesos tiene su propia vista lógica privada de los datos de la instancia en los elementos de datos. Si un supervisor de eventos determinado se desactiva y se vuelve a activar, se restablece su vista de estos contadores. Sólo se ve afectado el supervisor de sucesos que acaba de activarse; todos los otros supervisores de sucesos continuarán utilizando sus vistas de los valores del contador (más cualquier adición nueva). La salida de los sucesos de eventos puede dirigirse a las tablas de SQL, a un archivo o a una área de interconexión con nombre. Conceptos relacionados: v “Database system monitor” en la publicación System Monitor Guide and Reference Tareas relacionadas: v “Collecting information about database system events” en la publicación System Monitor Guide and Reference v “Creating an event monitor” en la publicación System Monitor Guide and Reference Capítulo 1. Conceptos 27
- 54. Información relacionada: v “Event monitor sample output” en la publicación System Monitor Guide and Reference v “Event types” en la publicación System Monitor Guide and Reference Activadores Un activador define un conjunto de acciones que se ejecutan en respuesta a una operación de inserción, actualización o supresión en una tabla determinada. Cuando se ejecuta una de estas operaciones de SQL, se dice que el activador se ha activado. Los activadores son opcionales y se definen mediante la sentencia CREATE TRIGGER. Los activadores pueden utilizarse, junto con las restricciones de referencia y las restricciones de comprobación, para imponer las reglas de integridad de los datos. Los activadores también pueden utilizarse para provocar actualizaciones en otras tablas, para transformar o generar valores automáticamente en las filas insertadas o actualizadas, o para invocar funciones que realicen tareas como la de emitir alertas. Los activadores son un mecanismo útil para definir e imponer reglas empresariales transicionales, que son reglas que incluyen diferentes estados de los datos (por ejemplo, un salario que no se puede aumentar más del 10 por ciento). La utilización de activadores proporciona la lógica que impone las reglas empresariales en la base de datos. Esto significa que las aplicaciones no son responsables de imponer dichas reglas. La lógica centralizada que se imponen en todas las tablas facilita el mantenimiento, porque no se necesitan realizar cambios en los programas de aplicación cuando cambia la lógica. Los elementos siguientes se especifican al crear un activador: v La tabla sujeto especifica la tabla para la que se define el activador. v El suceso activador define una operación de SQL específica que modifica la tabla sujeto. El suceso puede ser una operación de inserción, actualización o supresión. v La hora de activación del activador especifica si el activador debería activarse antes o después de que se produzca el suceso activador. La sentencia que hace que se active un activador incluye un conjunto de filas afectadas. Éstas son las filas de la tabla sujeto que se están insertando, 28 Consulta de SQL, Volumen 1
- 55. actualizando o suprimiendo. La granularidad del activador especifica si las acciones del activador se realizan una vez para la sentencia o una vez para cada una de las filas afectadas. La acción activada está formada por una condición de búsqueda opcional y un conjunto de sentencias de SQL que se ejecutan siempre que se activa el activador. Las sentencias de SQL sólo se ejecutan si la condición de búsqueda se evalúa como verdadera. Si la hora de activación del activador es anterior al suceso activador, las acciones activadas pueden incluir sentencias que seleccionen, establezcan variables de transición y señalen estados de SQL. Si la hora de activación del activador es posterior al suceso activador, las acciones activadas pueden incluir sentencias que seleccionen, inserten, actualicen, supriman o señalen estados de SQL. La acción activada puede hacer referencia a los valores del conjunto de filas afectadas utilizando variables de transición. Las variables de transición utilizan los nombres de las columnas de la tabla sujeto, calificados por un nombre especificado que identifica si la referencia es al valor anterior (antes de la actualización) o al valor nuevo (después de la actualización). El nuevo valor también se puede cambiar utilizando la sentencia variable SET en activadores anteriores, de inserción o actualización. Otra forma de hacer referencia a los valores del conjunto de filas afectadas consisten en utilizar tablas de transición. Las tablas de transición también utilizan los nombres de las columnas de la tabla sujeto pero especifican un nombre para permitir que el conjunto completo de filas afectadas se trate como una tabla. Las tablas de transición sólo se pueden utilizar en activadores posteriores y es posible definir tablas de transición independientes para los valores anteriores y los nuevos. Se pueden especificar varios activadores para una combinación de tabla, suceso o momento de activación. El orden en el que se activan los activadores es el mismo que el orden en que se han creado. Por consiguiente, el activador creado más recientemente es el último activador que se activa. La activación de un activador puede provocar una cascada de activadores, que es el resultado de la activación de un activador que ejecuta sentencias de SQL que provocan la activación de otros activadores o incluso del mismo activador otra vez. Las acciones activadas también pueden causar actualizaciones como resultado de la aplicación de las reglas de integridad de referencia para las supresiones que, a su vez, pueden provocar la activación de activadores adicionales. Con una cascada de activadores, se puede activar una cadena de activadores y reglas de supresión de integridad de referencia, lo que puede producir un cambio significativo en la base de datos como resultado de una sola sentencia INSERT, UPDATE o DELETE. Capítulo 1. Conceptos 29
- 56. Espacios de tablas y otras estructuras de almacenamiento Las estructuras de almacenamiento contienen objetos de base de datos. La estructura básica de almacenamiento es el espacio de tablas; contiene tablas, índices, objetos grandes y datos definidos con un tipo de datos LONG. Existen dos tipos de espacios de tablas: Espacio gestionado por base de datos (DMS) Espacio de tablas que está gestionado por el gestor de bases de datos. Espacio gestionado por el sistema (SMS) Espacio de tablas que está gestionado por el sistema operativo. Todos los espacios de tablas constan de contenedores. Un contenedor describe dónde se almacenan los objetos. Un subdirectorio de un sistema de archivos es un ejemplo de contenedor. Cuando los datos se leen de los contenedores de espacios de tablas, se colocan en un área de la memoria denominada agrupación de almacenamientos intermedios. Una agrupación de almacenamientos intermedios está asociada a un espacio de tablas concreto y, por lo tanto, puede controlar qué datos compartirán las mismas áreas de memoria para el almacenamiento intermedio de datos. En una base de datos particionada, los datos se reparten entre distintas particiones de base de datos. El grupo de particiones de base de datos asignado al espacio de tablas determina qué particiones en concreto se incluyen. Un grupo de particiones de base de datos es un grupo de una o varias particiones definidas como parte de la base de datos. Un espacio de tablas incluye uno o varios contenedores para cada partición del grupo de particiones de base de datos. El gestor de bases de datos utiliza un mapa de particionamiento, asociado con cada grupo de particiones de base de datos, para determinar en qué partición se almacenará un fila de datos en concreto. El mapa de particionamiento es una matriz de 4096 números de partición. El índice del mapa de particionamiento generado por la función de particionamiento para cada fila de una tabla se utiliza para determinar la partición en la que se almacenará una fila. A modo de ejemplo, la figura siguiente muestra cómo se correlaciona una fila con el valor de clave de particionamiento (c1, c2, c3) con un índice de mapa de particionamiento 2 que, a su vez, hace referencia a la partición p5. 30 Consulta de SQL, Volumen 1
- 57. Fila clave de particionamiento (... c1, c2, c3 ...) correlaciones de funciones de particionamiento (c1, c2, c3) para el índice de correlación de particionamiento 2 Correlación de particionamiento p0 p2 p5 p0 p2 p5 ... p0 0 1 2 3 4 5 ... 4095 Las particiones de grupo de nodo son p0, p2 y p5 Nota: Los números de partición comienzan por el 0 Figura 5. Distribución de datos El mapa de particionamiento se puede cambiar, permitiendo cambiar la distribución de los datos sin modificar la clave de particionamiento ni los datos reales. El nuevo mapa de particionamiento se especifica como parte del mandato REDISTRIBUTE DATABASE PARTITION GROUP o de la interfaz de programación de aplicaciones (API) sqludrdt, que lo utilizan para redistribuir las tablas en el grupo de particiones de base de datos. El producto DB2 Data Links Manager proporciona funciones que permiten posibilidades de almacenamiento adicionales. Una tabla de usuario normal también puede incluir columnas (definidas con el tipo de datos DATALINK) que registren enlaces con datos almacenados en archivos externos. Los valores de DATALINK hacen referencia a archivos de datos almacenados en un servidor de archivos externo. Conceptos relacionados: v “Particionamiento de datos entre múltiples particiones” en la página 32 Información relacionada: v “CREATE BUFFERPOOL sentencia” en la publicación Consulta de SQL, Volumen 2 v “CREATE DATABASE PARTITION GROUP sentencia” en la publicación Consulta de SQL, Volumen 2 v “CREATE TABLESPACE sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 1. Conceptos 31
- 58. Particionamiento de datos entre múltiples particiones DB2 permite una gran flexibilidad para repartir los datos entre múltiples particiones (nodos) de una base de datos particionada. Los usuarios pueden elegir la forma de particionar los datos mediante la declaración de claves de particionamiento y pueden determinar qué particiones y en cuántas de ellas pueden repartirse los datos de tabla mediante la selección del grupo de particiones de base de datos y el espacio de tablas en el que se deben almacenar los datos. Además, un mapa de particionamiento (que puede actualizarse) especifica la correlación de los valores de clave de particionamiento para las particiones. Esto posibilita la paralelización flexible de la carga de trabajo para tablas grandes, mientras que permite que se almacenen las tablas mas pequeñas en una o en un pequeño número de particiones si así lo elige el diseñador de la aplicación. Cada partición local puede tener índices locales acerca de los datos que almacenan para proporcionar un acceso a los datos locales de alto rendimiento. Una base de datos particionada da soporte a un modelo de almacenamiento particionado en el que la clave de particionamiento se utiliza para particionar los datos de tabla en un conjunto de particiones de la base de datos. Los datos de índice también se particionan con sus tablas correspondientes y se almacenan localmente en cada partición. Antes de que se puedan utilizar las particiones para almacenar datos de la base de datos, deben definirse en el gestor de bases de datos. Las particiones se definen en un archivo llamado db2nodes.cfg. La clave de particionamiento para una tabla de un espacio de tablas de un grupo de particiones de base de datos particionadas se especifica en la sentencia CREATE TABLE o en la sentencia ALTER TABLE. Si no se especifica, se crea por omisión una clave de particionamiento para una tabla a partir de la primera columna de la clave primaria. Si no se define ninguna clave primaria, la clave de particionamiento por omisión es la primera columna definida en la tabla que tiene un tipo de datos que no sea largo ni LOB. Las tablas particionadas deben tener, como mínimo, una columna que no tenga el tipo de datos largo ni LOB. Una tabla de un espacio de tablas que esté en un grupo de particiones de base de datos de una sola partición sólo tendrá una clave de particionamiento si se especifica explícitamente. El particionamiento por cálculo de clave se utiliza para colocar una fila en una partición, de la manera siguiente: 1. Un algoritmo de cálculo de claves (función de particionamiento) se aplica a todas las columnas de la clave de particionamiento, lo que da como resultado la generación de un valor de índice de mapa de particionamiento. 32 Consulta de SQL, Volumen 1
- 59. 2. El número de partición correspondiente a ese valor de índice en el mapa de particionamiento identifica la partición en la que se va a almacenar la fila. DB2 da soporte a la desagrupación parcial, que significa que una tabla se puede particionar en un subconjunto de particiones del sistema (es decir, un grupo de particiones de base de datos). Las tablas no se tienen que particionar entre todas las particiones del sistema. DB2 tiene la posibilidad de reconocer si los datos a los que se está accediendo para una unión o subconsulta están situados en la misma partición del mismo grupo de particiones de base de datos. Esto se conoce como colocación de tablas. Las filas de las tablas colocadas con los mismos valores de clave de particionamiento se sitúan en la misma partición. DB2 puede elegir realizar el proceso de unión o subconsulta en la partición en la que están almacenados los datos. Esto puede tener ventajas significativas para el rendimiento. Las tablas colocadas deben: v Estar en el mismo grupo de particiones de base de datos, uno que no se esté redistribuyendo. (Durante la redistribución, es posible que las tablas del grupo de particiones de base de datos utilicen mapas de particionamiento distintos, que no estén colocadas). v Tener claves de particionamiento con el mismo número de columnas. v Hacer que las columnas correspondientes de la clave de particionamiento sean compatibles con la partición. v Estar en un grupo de particiones de base de datos de una sola partición definido en la misma partición. Información relacionada: v “Tipos de datos compatibles entre particiones” en la página 153 Bases de datos relacionales distribuidas Una base de datos relacional distribuida consta de un conjunto de tablas y otros objetos distribuidos en distintos sistemas informáticos que están conectados entre sí. Cada sistema tiene un gestor de bases de datos relacionales para manejar las tablas de su entorno. Los gestores de bases de datos se comunican y cooperan entre sí de una manera que permite a un gestor de bases de datos determinado ejecutar sentencias de SQL en otro sistema. Las bases de datos relacionales distribuidas se crean mediante protocolos y funciones de peticionario-servidor formales. Un peticionario de aplicaciones da soporte al extremo correspondiente a la aplicación en una conexión. Transforma una petición de base de datos procedente de la aplicación en Capítulo 1. Conceptos 33
- 60. protocolos de comunicaciones adecuados para ser utilizados en la red de bases de datos distribuidas. Estas peticiones las recibe y procesa un servidor de bases de datos situado en el otro extremo de la conexión. Mediante un trabajo conjunto, el peticionario de aplicaciones y el servidor de bases de datos manejan las consideraciones acerca de las comunicaciones y la ubicación, de forma que la aplicación pueda funcionar como si estuviera accediendo a una base de datos local. Un proceso de aplicación debe conectarse al servidor de aplicaciones de un gestor de bases de datos para que se puedan ejecutar las sentencias de SQL que hacen referencia a tablas o vistas. La sentencia CONNECT establece una conexión entre un proceso de aplicación y su servidor. Hay dos tipos de sentencias CONNECT: v CONNECT (Tipo 1) da soporte a la semántica de una sola base de datos por unidad de trabajo (Unidad de trabajo remota). v CONNECT (Tipo 2) da soporte a la semántica de varias bases de datos por unidad de trabajo (Unidad de trabajo distribuida dirigida por aplicación). La CLI (interfaz de nivel de llamada) de DB2 y SQL incorporado dan soporte a una modalidad de conexión llamada transacciones simultáneas que permite múltiples conexiones, cada una de las cuales es una transacción independiente. Una aplicación puede tener múltiples conexiones simultáneas con la misma base de datos. El servidor de aplicaciones puede ser local o remoto con respecto al entorno en el que se inicia el proceso. Existe un servidor de aplicaciones, aunque el entorno no esté utilizando bases de datos relacionales distribuidas. Este entorno incluye un directorio local que describe los servidores de aplicaciones que pueden identificarse en una sentencia CONNECT. El servidor de aplicaciones ejecuta la forma vinculada de una sentencia de SQL estático que hace referencia a tablas o vistas. La sentencia vinculada se toma de un paquete que el gestor de bases de datos ha creado previamente mediante una operación de vinculación. En su mayor parte, una aplicación conectada a un servidor de aplicaciones puede utilizar las sentencias y las cláusulas soportadas por el gestor de bases de datos del servidor de aplicaciones. Esto es cierto aunque la aplicación esté ejecutándose mediante el peticionario de aplicaciones de un gestor de bases de datos que no soporte algunas de estas sentencias y cláusulas. Unidad de trabajo remota El recurso unidad de trabajo remota permite la preparación y ejecución remotas de las sentencias de SQL. Un proceso de aplicación del sistema A puede conectarse a un servidor de aplicaciones del sistema B y, desde una o más 34 Consulta de SQL, Volumen 1
- 61. unidades de trabajo, ejecutar un número cualquiera de sentencias de SQL estático o dinámico que hagan referencia a objetos de B. Al finalizar una unidad de trabajo en B, el proceso de aplicación puede conectarse a un servidor de aplicaciones del sistema C y así sucesivamente. La mayoría de las sentencias de SQL pueden prepararse y ejecutarse de forma remota, con las restricciones siguientes: v Todos los objetos a los que se hace referencia en una sola sentencia de SQL deben ser gestionados por el mismo servidor de aplicaciones. v Todas las sentencias de SQL de una unidad de trabajo debe ejecutarlas el mismo servidor de aplicaciones. En un momento dado, un proceso de aplicación se encuentra en uno de cuatro estados de conexión posibles: v Conectable y conectado. Un proceso de aplicación está conectado a un servidor de aplicaciones y pueden ejecutarse sentencias CONNECT. Si la conexión implícita se encuentra disponible: – El proceso de aplicación entra en este estado cuando una sentencia CONNECT TO o una sentencia CONNECT sin operandos se ejecuta satisfactoriamente desde el estado conectable y no conectado. – El proceso de aplicación puede entrar en este estado desde el estado conectable implícitamente si se emite cualquier otra sentencia de SQL que no sea CONNECT RESET, DISCONNECT, SET CONNECTION ni RELEASE. Tanto si la conexión implícita está disponible como si no lo está, se entra en este estado cuando: – Se ejecuta satisfactoriamente una sentencia CONNECT TO desde el estado conectable y no conectado. – Se emite satisfactoriamente una sentencia COMMIT o ROLLBACK o tiene lugar una retrotracción forzada que procede de un estado no conectable y conectado. v No conectable y conectado. Un proceso de aplicación está conectado a un servidor de aplicaciones, pero no puede ejecutarse satisfactoriamente una sentencia CONNECT TO para cambiar de servidor de aplicaciones. El proceso de aplicación pasa a este estado desde el estado conectable y conectado al ejecutarse cualquier sentencia de SQL que no sea una de las siguientes: CONNECT TO, CONNECT sin operandos, CONNECT RESET, DISCONNECT, SET CONNECTION, RELEASE, COMMIT o ROLLBACK. v Conectable y no conectado. Capítulo 1. Conceptos 35
- 62. Un proceso de aplicación no está conectado a un servidor de aplicaciones. CONNECT TO es la única sentencia de SQL que puede ejecutarse; de lo contrario, se genera un error (SQLSTATE 08003). Tanto si la conexión implícita está disponible como si no, el proceso de aplicación entra en este estado si se produce un error al emitir una sentencia CONNECT TO o si se produce un error en una unidad de trabajo que provoca la pérdida de la conexión y una retrotracción. Un error originado porque el proceso de aplicación no está en estado conectable o porque el nombre de servidor no se encuentra en el directorio local no provoca una transición a este estado. Si la conexión implícita no está disponible: – El proceso de aplicación está inicialmente en este estado – Las sentencias CONNECT RESET y DISCONNECT provocan una transición a este estado. v Conectable implícitamente (si la conexión implícita se encuentra disponible). Si la conexión implícita se encuentra disponible, éste es el estado inicial de un proceso de aplicación. La sentencia CONNECT RESET provoca una transición a este estado. Si se emite una sentencia COMMIT o ROLLBACK en el estado no conectable y conectado seguida de una sentencia DISCONNECT en el estado conectable y conectado, también se pasa a este estado. La disponibilidad de la conexión implícita viene determinada por las opciones de la instalación, las variables de entorno y los valores de autenticación. No es un error ejecutar sentencias CONNECT consecutivas, porque CONNECT no modifica el estado conectable del proceso de aplicación. Sin embargo, es un error ejecutar sentencias CONNECT RESET consecutivas. También es un error ejecutar cualquier sentencia de SQL que no sea CONNECT TO, CONNECT RESET, CONNECT sin operandos, SET CONNECTION, RELEASE, COMMIT o ROLLBACK y luego ejecutar una sentencia CONNECT TO. Para evitar este error, se deberá ejecutar una sentencia CONNECT RESET, DISCONNECT (precedida de una sentencia COMMIT o ROLLBACK), COMMIT o ROLLBACK antes de la sentencia CONNECT TO. 36 Consulta de SQL, Volumen 1
- 63. CONNECT Principio del proceso RESET Anomalía en la Conectable Implícitamente conexión implícita y conectable No conectado a tem l sis CONNECT de l ía RESET ma no rio na cto co Anomalía del sistema CONNECT TO, TO t isfa COMMIT CT sa con retrotracción NE O CONNECT TO, N C TT o ROLLBACK CO NE COMMIT o C ON ROLLBACK Conectable No conectable y ROLLBACK, y Conectado Conectado COMMIT satisfactorio o punto muerto Sentencia de SQL distinta de Sentencia de SQL distinta de CONNECT RESET, CONNECT TO, CONNECT RESET, COMMIT o ROLLBACK COMMIT o ROLLBACK Figura 6. Transiciones de estado de conexión si la conexión implícita está disponible Capítulo 1. Conceptos 37
- 64. CONNECT RESET Principio del proceso CONNECT TO, COMMIT o CONNECT TO satisfactorio ROLLBACK CONNECT TO Conectable Conectable con anomalía del sistema y Conectado y No conectado CONNECT RESET Sentencia de SQL distinta de CONNECT TO, CONNECT RESET, CONNECT COMMIT o ROLLBACK RESET ROLLBACK, Anomalía del sistema COMMIT satisfactorio con retrotracción o punto muerto No conectable y Conectado Sentencia de SQL distinta de CONNECT RESET, COMMIT o ROLLBACK Figura 7. Transiciones de estado de conexión si la conexión implícita no está disponible Unidad de trabajo distribuida dirigida por aplicación El recurso de unidad de trabajo distribuida dirigida por aplicación también proporciona la preparación y ejecución remota de sentencias de SQL. Un proceso de aplicación en el sistema A puede conectarse a un servidor de aplicaciones en el sistema B emitiendo una sentencia CONNECT o SET CONNECTION. Después, el proceso de aplicación puede ejecutar un número cualquiera de sentencias de SQL estático y dinámico que hagan referencia a objetos de B antes de finalizar la unidad de trabajo. Todos los objetos a los que se hace referencia en una sola sentencia de SQL deben ser gestionados por el mismo servidor de aplicaciones. Sin embargo, a diferencia del recurso de unidad de trabajo remota, pueden participar en la misma unidad de trabajo cualquier número de servidores de aplicaciones. Una operación de retrotracción o confirmación finaliza la unidad de trabajo. 38 Consulta de SQL, Volumen 1
- 65. Una unidad de trabajo distribuida dirigida por aplicación utiliza una conexión de tipo 2. Una conexión de tipo 2 conecta un proceso de aplicación al servidor de aplicaciones identificado y establece las reglas para la unidad de trabajo distribuida dirigida por aplicación. Un proceso de aplicación de tipo 2: v Está siempre conectable v Está en estado conectado o no conectado v Tiene cero o más conexiones. Cada conexión de un proceso de aplicación viene identificada de modo exclusivo por el seudónimo de la base de datos del servidor de aplicaciones de la conexión. Una conexión individual tiene siempre uno de los estados de conexión siguientes: v actual y mantenido v actual y pendiente de liberación v inactivo y mantenido v inactivo y pendiente de liberación Un proceso de aplicación de tipo 2 está inicialmente en estado no conectado y no tiene ninguna conexión. Una conexión está inicialmente en estado actual y mantenido. Capítulo 1. Conceptos 39
- 66. Principio del proceso Estados de una conexión La conexión actual se finaliza intencionadamente o se produce una anomalía que provoca la pérdida de la conexión Actual Latente CONNECT o SET CONNECTION satisfactorios Estados de una conexión CONNECT o SET CONNECTION satisfactorios especificando otra conexión Actual Latente CONNECT o SET CONNECTION satisfactorios especificando una conexión latente existente RELEASE Pendiente Retenida de liberación Figura 8. Unidad distribuida dirigida por aplicación de transiciones de estado de conexión de trabajo Estados de conexión de procesos de aplicación Se aplican las reglas siguientes a la ejecución de una sentencia CONNECT: v Un contexto no puede tener más de una conexión al mismo servidor de aplicaciones al mismo tiempo. v Cuando un proceso de aplicación ejecuta una sentencia SET CONNECTION, el nombre de ubicación especificado debe ser una conexión existente en el conjunto de conexiones del proceso de aplicación. v Cuando un proceso de aplicación ejecuta una sentencia CONNECT y la opción SQLRULES(STD) está en vigor, el nombre de servidor especificado no debe ser una conexión existente en el conjunto de conexiones del proceso 40 Consulta de SQL, Volumen 1
- 67. de aplicación. Para ver una descripción de la opción SQLRULES, consulte el apartado “Opciones que controlan la semántica de la unidad de trabajo distribuida” en la página 43. Si un proceso de aplicación tiene una conexión actual, el proceso de aplicación está en el estado conectado. El registro especial CURRENT SERVER contiene el nombre del servidor de aplicaciones de la conexión actual. El proceso de aplicación puede ejecutar sentencias de SQL que hagan referencia a objetos gestionados por el servidor de aplicaciones. Un proceso de aplicación que está en estado no conectado pasa al estado conectado cuando ejecuta satisfactoriamente una sentencia CONNECT o SET CONNECTION. Si no existe ninguna conexión pero se emiten sentencias de SQL, se realiza una conexión implícita siempre que la variable de entorno DB2DBDFT se haya establecido con el nombre de una base de datos por omisión. Si un proceso de aplicación no tiene una conexión actual, el proceso de aplicación está en estado no conectado. Las únicas sentencias de SQL que se pueden ejecutar son CONNECT, DISCONNECT ALL, DISCONNECT (especificando una base de datos), SET CONNECTION, RELEASE, COMMIT y ROLLBACK. Un proceso de aplicación en el estado conectado pasa al estado no conectado cuando finaliza de manera intencionada su conexión actual o cuando una sentencia de SQL no es satisfactoria y provoca una operación de retrotracción en el servidor de aplicaciones y la pérdida de la conexión. Las conexiones finalizan intencionadamente al ejecutarse satisfactoriamente una sentencia DISCONNECT o una sentencia COMMIT cuando la conexión está en estado pendiente de liberación. (Si la opción DISCONNECT del precompilador está establecida en AUTOMATIC, finalizan todas las conexiones. Si está establecida en CONDITIONAL, finalizan todas las conexiones que no tienen cursores WITH HOLD abiertos.) Estados de conexión Si un proceso de aplicación ejecuta una sentencia CONNECT y el peticionario de aplicaciones conoce el nombre de servidor pero éste no está en el conjunto de conexiones existentes del proceso de aplicación: v La conexión actual se coloca en el estado de conexión inactivo y v El nombre del servidor se añade al conjunto de conexiones y v La nueva conexión se coloca en el estado de conexión actual y en el estado de conexión mantenido. Capítulo 1. Conceptos 41
- 68. Si el nombre de servidor ya se encuentra en el conjunto de conexiones existentes del proceso de aplicación y la aplicación se precompila con la opción SQLRULES(STD), se produce un error (SQLSTATE 08002). Estados mantenido y pendiente de liberación. La sentencia RELEASE controla si una conexión está en el estado mantenido o pendiente de liberación. El estado pendiente de liberación significa que se producirá una desconexión en la próxima operación de confirmación satisfactoria. (Una operación de retrotracción no tiene ningún efecto sobre las conexiones). El estado mantenido significa que no se producirá una desconexión en la próxima operación de confirmación. Todas las conexiones se encuentran inicialmente en el estado mantenido y pueden pasar al estado pendiente de liberación utilizando la sentencia RELEASE. Una vez en el estado pendiente de liberación, una conexión no puede volver a pasar al estado mantenido. Una conexión permanece en el estado pendiente de liberación más allá de los límites de la unidad de trabajo si se emite una sentencia ROLLBACK o si una operación de confirmación no satisfactoria da como resultado una operación de retrotracción. Aunque una conexión no se haya marcado explícitamente para su liberación, todavía puede desconectarse mediante una operación de confirmación, siempre que esta operación cumpla con las condiciones de la opción DISCONNECT del precompilador. Estados actual e inactivo. Con independencia de si una conexión se encuentra en el estado mantenido o pendiente de liberación, también puede estar en el estado actual o inactivo. Una conexión en el estado actual es la conexión que se está utilizando para ejecutar sentencias de SQL mientras se encuentra en este estado. Una conexión en el estado inactivo es una conexión que no es actual. Las únicas sentencias de SQL que pueden fluir en una conexión inactiva son COMMIT, ROLLBACK, DISCONNECT y RELEASE. Las sentencias SET CONNECTION y CONNECT cambian el estado de conexión del servidor especificado a actual y cualquier conexión existente se coloca o permanece en estado inactivo. En todo momento, sólo una conexión puede estar en estado actual. Si una conexión inactiva pasa a ser actual en la misma unidad de trabajo, el estado de todos los bloqueos, cursores y sentencias preparadas es el mismo que el estado en estaban la última vez que la conexión era actual. Cuando finaliza una conexión Cuando finaliza una conexión, se desasignan todos los recursos que el proceso de aplicación adquirió mediante la conexión y todos los recursos que se utilizaron para crear y mantener la conexión. Por ejemplo, si el proceso de 42 Consulta de SQL, Volumen 1
- 69. aplicación ejecuta una sentencia RELEASE, todos los cursores abiertos se cierran al finalizar la conexión durante la siguiente operación de confirmación. Una conexión también puede finalizar a causa de una anomalía en las comunicaciones. Si esta conexión está en estado actual, el proceso de aplicación se coloca en estado no conectado. Todas las conexiones de una proceso de aplicación finalizan cuando finaliza el proceso. Opciones que controlan la semántica de la unidad de trabajo distribuida La semántica de gestión de la conexión de tipo 2 viene determinada por un conjunto de opciones del precompilador. Estas opciones se resumen a continuación, con los valores por omisión indicados con texto en negrita y subrayado. v CONNECT (1 | 2). Especifica si las sentencias CONNECT se procesarán como tipo 1 o como tipo 2. v SQLRULES (DB2 | STD). Especifica si las sentencias CONNECT de tipo 2 deben procesarse según las reglas de DB2, que permiten que CONNECT conmute a una conexión inactiva, o según las reglas SQL92 Standard, que no permiten esta posibilidad. v DISCONNECT (EXPLICIT | CONDITIONAL | AUTOMATIC). Especifica las conexiones de la base de datos que se desconectarán cuando se produzca una operación de confirmación: – Las que se han marcado explícitamente para su liberación mediante la sentencia de SQL RELEASE (EXPLICIT) – Las que no tienen cursores WITH HOLD abiertos y las que se han marcado para su liberación (CONDITIONAL) – Todas las conexiones (AUTOMATIC). v SYNCPOINT (ONEPHASE | TWOPHASE | NONE). Especifica el modo en que se van a coordinar las operaciones COMMIT y ROLLBACK entre varias conexiones de bases de datos: – Las actualizaciones sólo pueden producirse respecto a una base de datos de la unidad de trabajo y el resto de las bases de datos son de sólo lectura (ONEPHASE). Cualquier intento de actualización en otra base de datos producirá un error (SQLSTATE 25000). – Se utiliza un gestor de transacciones (TM) en tiempo de ejecución para coordinar las operaciones COMMIT de dos fases entre las bases de datos que den soporte a este protocolo (TWOPHASE). – No utiliza ningún TM para realizar las operaciones COMMIT de dos fases y no impone un actualizador único y un lector múltiple (NONE). Cuando se ejecuta una sentencia COMMIT o ROLLBACK, las sentencias COMMIT o ROLLBACK individuales se envían a todas las bases de datos. Si hay una o varias operaciones ROLLBACK anómalas, se produce Capítulo 1. Conceptos 43
- 70. un error (SQLSTATE 58005). Si hay una o varias operaciones COMMIT anómalas, se produce un error (SQLSTATE 40003). Para alterar temporalmente cualquiera de las opciones anteriores en tiempo de ejecución, utilice el mandato SET CLIENT o la interfaz de programación de aplicaciones (API) sqlesetc. Sus valores actuales se pueden obtener utilizando el mandato QUERY CLIENT o la API sqleqryc. Observe que no se trata de sentencias de SQL, sino que son API definidas en los distintos lenguajes principales y en el procesador de línea de mandatos (CLP). Consideraciones sobre la representación de los datos Los diversos sistemas representan los datos de maneras distintas. Cuando se mueven datos de un sistema a otro, a veces debe realizarse una conversión de datos. Los productos que soportan DRDA realizan automáticamente las conversiones necesarias en el sistema receptor. Para realizar conversiones de datos numéricos, el sistema necesita conocer el tipo de datos y el modo en que el sistema emisor los representa. Se necesita información adicional para convertir las series de caracteres. La conversión de series depende de la página de códigos de los datos y de la operación que se ha de realizar con dichos datos. Las conversiones de caracteres se llevan a cabo de acuerdo con la Arquitectura de representación de datos de caracteres (CDRA) de IBM. Para obtener más información sobre la conversión de los caracteres, consulte el manual Character Data Representation Architecture: Reference & Registry (SC09-2190-00). Información relacionada: v “CONNECT (Tipo 1) sentencia” en la publicación Consulta de SQL, Volumen 2 v “CONNECT (Tipo 2) sentencia” en la publicación Consulta de SQL, Volumen 2 Sistemas federados de DB2 Sistemas federados Un sistema federado de DB2 es un tipo especial de sistema de gestión de bases de datos distribuidas (DBMS). Un sistema federado está formado por una instancia de DB2 que funciona como un servidor federado, una base de datos que actúa como base de datos federada, una o varias fuentes de datos y clientes (usuarios y aplicaciones) que acceden a la base de datos y a las fuentes de datos. Con un sistema federado es posible enviar peticiones distribuidas a varias fuentes de datos en una sola sentencia de SQL. Por ejemplo, pueden unirse datos ubicados en una tabla DB2 Universal Database una tabla de Oracle y una vista de Sybase en una sola sentencia SQL. 44 Consulta de SQL, Volumen 1
- 71. DB2 para UNIX Clientes de DB2 (usuario final y aplicación) DB2 Life Sciences y Windows Data Connect DB2 para z/OS y OS/390 Blast DB2 para Documentum iServer Servidor federado DB2 Server para de DB2 Microsoft VM y VSE Base de datos Excel federada de DB2 archivos Informix catálogo estructurados global de tablas OLE DB XML XML DB2 Relational Connect Oracle Sybase Microsoft SQL ODBC Server Figura 9. Los componentes de un sistema federado y las fuentes de datos a las que se proporciona soporte El poder de un sistema federado de DB2 consiste en sus posibilidades de: v Unir datos de tablas remotas y fuentes de datos remotas como si todos los datos fueran locales. v Beneficiarse de las ventajas de procesar fuentes de datos enviando peticiones distribuidas a las fuentes de datos para su proceso. v Compensar las limitaciones de SQL en la fuente de datos procesando partes de una petición distribuida en el servidor federado. El servidor DB2 de un sistema federado recibe el nombre de servidor federado. Puede configurarse cualquier número de instancias de DB2 para que funcionen como servidores federados. Es posible utilizar instancias de DB2 existentes como servidor federado o crear instancias nuevas de forma específica para el sistema federado. La instancia federada de DB2 que gestiona el sistema federado se denomina un servidor, porque responde a las peticiones de usuarios finales y aplicaciones clientes. El servidor federado a menudo envía partes de las peticiones que recibe a las fuentes de datos para su proceso. Una operación de bajada es una Capítulo 1. Conceptos 45
- 72. operación que se procesa de forma remota. La instancia federada se denomina el servidor federado, aunque actúe como cliente al bajar las peticiones a las fuentes de datos. Como cualquier otro servidor de aplicaciones, el servidor federado es una instancia del gestor de bases de datos a la que se conectan los procesos de aplicaciones y se someten peticiones. Sin embargo, dos características fundamentales lo distinguen de otros servidores de aplicaciones: v Un servidor federado está configurado para recibir peticiones que podrían estar pensadas total o parcialmente para fuentes de datos. El servidor federado distribuye estas peticiones a las otras fuentes de datos. v Como los otros servidores de aplicaciones, un servidor federado utiliza los protocolos de comunicación DRDA (como, por ejemplo, SNA y TCP/IP) para comunicar con las instancias de la familia DB2. Sin embargo, a diferencia de los otros servidores de aplicaciones, un servidor federado utiliza otros protocolos para comunicarse con las instancias que no son de la familia DB2. Conceptos relacionados: v “Fuentes de datos” en la página 46 v “La base de datos federada” en la página 48 v “El compilador de SQL y el optimizador de consultas” en la página 50 v “Compensación” en la página 51 v “Pushdown analysis” en la publicación Federated Systems Guide Fuentes de datos Normalmente, una fuente de datos del sistema federado es una instancia DBMS relacional (como, por ejemplo, Oracle o Sybase) y una o varias bases de datos a las que la instancia proporciona soporte. Sin embargo, existen otros tipos de fuentes de datos (como, por ejemplo, fuentes de datos Life Sciences y algoritmos de búsqueda) que pueden incluirse en el sistema federado: v Hojas de cálculo como, por ejemplo, Microsoft Excel. v Algoritmos de búsqueda como, por ejemplo, BLAST. v Archivos estructurados-tabla. Estos tipos de archivos tienen una estructura regular formada por una serie de registros. Cada registro contiene el mismo número de campos que están separados mediante un delimitador arbitrario. Dos delimitares secuenciales representan valores nulos. v El software de gestión de documentos Documentum que incluye un depósito para almacenar el contenido de documentos, atributos, relaciones, versiones, rendiciones, formatos, flujo de trabajo y seguridad. v archivos codificados XML. 46 Consulta de SQL, Volumen 1
- 73. En DB2 Universal Database para UNIX y Windows, las fuentes de datos a las que se proporciona soporte son las siguientes: Tabla 1. Versiones de fuentes de datos soportadas y métodos de acceso. Fuente de datos Versiones de Método de acceso Notas fuentes de datos soportadas DB2 Universal 6.1, 7.1, 7.2, 8.1 DRDA Integrado Database para UNIX directamente en y Windows DB2 Versión 8 DB2 Universal 5 con PTF PQ07537 DRDA Integrado Database para z/OS (o posterior) directamente en y OS/390 DB2 Versión 8 DB2 Universal 4.2 (o posterior) DRDA Integrado Database para directamente en iSeries DB2 Versión 8 DB2 Server para 3.3 (o posterior) DRDA Integrado VM y VSE directamente en DB2 Versión 8 Informix 7, 8, 9 SDK cliente de Integrado Informix directamente en DB2 Versión 8 ODBC Controlador ODBC Necesita DB2 3.0. Relational Connect OLE DB OLE DB 2.0 (o Integrado posterior) directamente en DB2 Versión 8 Oracle 7.x, 8.x, 9.x Sofware cliente de Necesita DB2 SQL*Net o Net8 Relational Connect Microsoft SQL 6.5, 7.0, 2000 En Windows, Necesita DB2 Server controlador ODBC Relational Connect 3.0 (o superior) del cliente Microsoft SQL Server. En UNIX, controlador Connect ODBC 3.6 de Data Direct Technologies (anteriormente MERANT). Sybase 10.0, 11.0, 11.1, 11.5, Sybase Open Client Necesita DB2 11.9, 12.0 Relational Connect Capítulo 1. Conceptos 47
- 74. Tabla 1. Versiones de fuentes de datos soportadas y métodos de acceso. (continuación) Fuente de datos Versiones de Método de acceso Notas fuentes de datos soportadas BLAST 2.1.2 Daemon BLAST Necesita DB2 Life (suministrado con el Sciences Data reiniciador) Connect Documentum Servidor de API/biblioteca Necesita DB2 Life Documentum: cliente de Sciences Data EDMS 98 (también Documentum Connect denominado versión 3) y 4i. Microsoft Excel 97, 2000 ninguna Necesita DB2 Life Sciences Data Connect archivos ninguna Necesita DB2 Life estructurados-tabla Sciences Data Connect XML especificación 1.0 ninguna Necesita DB2 Life Sciences Data Connect Las fuentes de datos son semiautónomas. Por ejemplo, el servidor federado puede enviar consultas a fuentes de datos Oracle al mismo tiempo que aplicaciones Oracle acceden a estas fuentes de datos. Un sistema federado DB2 no monopoliza ni restringe el acceso a otras fuentes de datos más allá de las restricciones de integridad y de bloqueo. La base de datos federada Para los usuarios finales y aplicaciones cliente, las fuentes de datos aparecen como una sola base de datos colectiva en DB2. Los usuarios y las aplicaciones interactúan con labase de datos federada gestionada por el servidor federado. La base de datos federada contiene entradas de catálogo que identifican las fuentes de datos y las características de las mismas. El servidor federado consulta la información almacenada en catálogo del sistema de bases de datos federadas y el reiniciador de fuentes de datos para determinar el mejor plan para procesar las sentencias de SQL. El catálogo del sistema de bases de datos federadas contiene información sobre los objetos de la base de datos federada e información sobre los objetos de las fuentes de datos. El catálogo de una base de datos federada se denomina el catálogo global porque contiene información sobre todo el sistema federado. El optimizador de consultas de DB2 utiliza la información del 48 Consulta de SQL, Volumen 1
- 75. catálogo global y el reiniciador de fuentes de datos para planificar la mejor forma de procesar las sentencias de SQL. La información almacenada en el catálogo global incluye información remota y local como, por ejemplo, el nombre de las columnas, los tipos de datos de las columnas, los valores por omisión de las columnas e información sobre el índice. La información de catálogo remota es la información o el nombre que la fuente de datos utiliza. La información de catálogo local es la información o el nombre que la base de datos federada utiliza. Por ejemplo, supongamos que una tabla remota incluye una columna con el nombre de NUMEMP. El catálogo global almacenaría el nombre de la columna remota como NUMEMP. A menos que designe un nombre distinto, el nombre de columna local se almacenará como NUMEMP. Es posible cambiar el nombre de la columna local a Número_Empleado. Los usuarios que sometan consultas que incluyan este columna utilizarán Número_Empleado en sus consultas en lugar de NUMEMP. Las opciones de columna se utilizan para cambiar el nombre local de la columna de la fuente de datos. Para fuentes de datos relacionales, la información almacenada en el catálogo global incluye información tanto remota como local. Para fuentes de datos no relacionales, la información almacenada en el catálogo global incluye varía de una fuente de datos a otra. Para ver la información sobre las tablas de la fuente de datos que está almacenada en el catálogo global, consulte las vistas de catálogo federadas SYSCAT.TABLES, SYSCAT.TABOPTIONS, SYSCAT.COLUMNS y SYSCAT.COLOPTIONS. El sistema federado procesa las sentencias de SQL como si las fuentes de datos fueran tablas relacionales corrientes dentro de la base de datos federada. Esto permite al sistema federado unir datos relacionales con datos en formatos no relacionales. Esto es así incluso cuando las fuentes de datos utilizan dialectos SQL diferentes o ni siquiera proporcionan soporte al SQL. El catálogo global también incluye otra información acerca de las fuentes de datos. Por ejemplo, incluye información que el servidor federado utiliza para conectarse a la fuente de datos y correlacionar las autorizaciones de los usuarios federados con las autorizaciones de los usuarios de la fuente de datos. Conceptos relacionados: v “Sistemas federados” en la página 44 v “El compilador de SQL y el optimizador de consultas” en la página 50 v “Tuning query processing” en la publicación Federated Systems Guide Capítulo 1. Conceptos 49
- 76. Información relacionada: v “Views in the global catalog table containing federated information” en la publicación Federated Systems Guide El compilador de SQL y el optimizador de consultas Para obtener datos de las fuentes de datos, los usuarios y las aplicaciones someten consultas en SQL de DB2 a la base de datos federada. Cuando se somete una consulta, el compilador de SQL de DB2 consulta la información en el catálogo global y el reiniciador de fuentes de datos para ayudarlo a procesar la consulta. Esto incluye información sobre cómo conectarse a la fuente de datos, atributos de servidor, correlaciones, información sobre los índices y datos estadísticos de procesos. Como parte del proceso del compilador de SQL, el optimizador de consultas analiza una consulta. El Compilador desarrolla estrategias alternativas, denominadas planes de acceso, para procesar la consulta. Los planes de acceso podrían llamar a la consulta para que: v La procesaran las fuentes de datos. v La procesa el servidor federado. v La procesaran en parte las fuentes de datos y en parte el servidor federado. DB2 evalúa los planes de acceso principalmente en base a la información sobre las posibilidades de las fuentes de datos y los datos. El reiniciador y el catálogo global contienen esta información. DB2 descompone la consulta en segmentos que se denominan fragmentos de consulta. Normalmente es más efectivo bajar un fragmento de consulta a la fuente de datos si la fuente de datos puede procesar el fragmento. Sin embargo, el optimizador de consultas tiene en cuenta otras funciones como, por ejemplo: v La cantidad de datos que debe procesarse. v La velocidad de proceso de la fuente de datos. v La cantidad de datos que devolverá el fragmento. v El ancho de banda de la comunicación. El optimizador de consultas genera planes de acceso locales y remotos para procesar un fragmento de consulta, en función del coste de recursos. DB2 elige entonces el plan que cree que procesará la consulta con el mínimo coste de recursos. Si las fuentes de datos deben procesar alguno de los fragmentos,DB2 somete estos fragmentos a las fuentes de datos. Después de que las fuentes de datos procesen los fragmentos, los resultados se recuperan y se devuelven a DB2. Si 50 Consulta de SQL, Volumen 1
- 77. DB2 ha realizado alguna parte del proceso, combina sus resultados con los resultados recuperados de la fuente de datos. DB2 devuelve entonces todos los resultados al cliente. Conceptos relacionados: v “Tuning query processing” en la publicación Federated Systems Guide v “Pushdown analysis” en la publicación Federated Systems Guide Tareas relacionadas: v “Global optimization” en la publicación Federated Systems Guide Compensación El servidor federado de DB2 no baja un fragmento de consulta si la fuente de datos no puede procesarlo o si el servidor federado puede procesarlo con mayor rapidez que la fuente de datos. Por ejemplo, supongamos que el dialecto SQL de una fuente de datos no proporcione soporte a una agrupación CUBE en la cláusula GROUP BY. Una consulta que contenga la agrupación CUBE y haga referencia a una tabla de la fuente de datos se envía al servidor federado. DB2 no baja la agrupación CUBE a la fuente de datos sino que procesa la agrupación CUBE directamente. La posibilidad que posee DB2 de procesar el SQL al que la fuente de datos no proporcione soporte se denominacompensación. El servidor federado compensa la falta de funcionalidad de la fuente de datos de dos formas: v Puede pedir a la fuente de datos que utilice una o varias operaciones que sean equivalentes a la función de DB2 utilizada en la consulta. Supongamos que una fuente de datos no proporcione soporte a la función de cotangente (COT(x)) pero sí a la función de tangente (TAN(x)). DB2 puede pedir a la fuente de datos que realice el cálculo (1/TAN(x)), que es equivalente a la función de cotangente (COT(x)). v Puede devolver el conjunto de datos al servidor federado y realizar la función localmente. Cada tipo de RDBMS proporciona soporte a un subconjunto del estándar internacional de SQL. Además, algunos tipos de RDBMS proporcionan soporte a construcciones SQL que exceden este estándar. Un dialecto SQL es la totalidad de SQL a la que un tipo de RDBMS proporciona soporte. Si una construcción SQL se encuentra en el dialecto SQL de DB2 pero no en un dialecto de la fuente de datos, el servidor federado puede implementar esta construcción en nombre de la fuente de datos. Los ejemplos siguientes muestran la posibilidad que DB2 posee de compensar las diferencias en los dialectos SQL: Capítulo 1. Conceptos 51
- 78. v El SQL de DB2 incluye la cláusula expresión-tabla-común. En esta cláusula, se puede especificar un nombre mediante el cual todas las cláusulas FROM de una selección completa pueden hacer referencia a un conjunto resultante. El servidor federado procesará una expresión-tabla-común para fuente de datos aunque el dialecto SQL que la fuente de datos utiliza no incluya la expresión-tabla-común. v Al conectarse a una fuente de datos que no permita que varios cursores estén abiertos en una aplicación, el servidor federado puede simular esta función. El servidor federado lo hace estableciendo conexiones independientes simultáneas con la fuente de datos. De manera similar, el servidor federado puede simular la posibilidad CURSOR WITH HOLD para una fuente de datos que no proporcione esa función. Mediante la compensación, el servidor federado puede proporcionar soporte a la totalidad del dialecto SQL de DB2 para realizar consultas en las fuentes de datos. Incluso en fuentes de datos con un soporte al SQL escaso o que no soporte SQL. El dialecto SQL de DB2 debe utilizarse con un sistema federado, a excepción de las sesiones de paso a través. Conceptos relacionados: v “El compilador de SQL y el optimizador de consultas” en la página 50 v “Sesiones de paso a través” en la página 52 v “Correlaciones de funciones y plantillas de funciones” en la página 63 Sesiones de paso a través Es posible enviar sentencias de SQL directamente a las fuentes de datos utilizando una modalidad especial llamada paso a través. Las sentencias de SQL se envían en el dialecto SQL que la fuente de datos utiliza. Utilice una sesión de paso a través cuando desee realizar una operación que no sea posible con SQL/API de DB2. Por ejemplo, utilice una sesión de paso a través para crear un procedimiento, crear un índice o realizar consultas en el dialecto nativo de la fuente de datos. Nota: Actualmente, las fuentes de datos que proporcionan soporte al paso a través proporcionan el paso a través utilizando SQL. En el futuro, es posible que las fuentes de datos proporcionen soporte al paso a través utilizando una fuente de datos distinta de SQL. De forma similar, es posible utilizar una sesión de paso a través para realizar acciones a las que SQL no proporcione soporte como, por ejemplo, ciertas tareas administrativas. Sin embargo, no es posible utilizar una sesión de paso a través para realizar todas las tareas administrativas. Por ejemplo, es posible crear y eliminar tablas en la fuente de datos pero no iniciar o detener la base de datos remota. 52 Consulta de SQL, Volumen 1
- 79. En una sesión de paso a través puede utilizarse SQL estático o dinámico. El servidor federado proporciona las siguientes sentencias de SQL para gestionar sesiones de paso a través: SET PASSTHRU Abre una sesión de paso a través. Cuando se emite otra sentencia SET PASSTHRU para iniciar una nueva sesión de paso a través, se termina la sesión de paso a través actual. SET PASSTHRU RESET Termina la sesión de paso a través actual. GRANT (Privilegios de servidor) Otorga a un usuario, grupo, lista de ID de autorización o PUBLIC la autorización para iniciar sesiones de paso a través para una fuente de datos específica. REVOKE (Privilegios del servidor) Revoca la autorización para iniciar sesiones de paso a través. Las restricciones siguientes son aplicables a las sesiones de paso a través: v Debe utilizarse el dialecto SQL o los mandatos de lenguaje de la fuente de datos— no es posible utilizar el dialecto SQL de DB2. Por lo tanto, las consultas no se realizan en apodos, sino directamente en los objetos de la fuente de datos. v Al realizar una operación UPDATE o DELETE en una sesión de paso a través, no es posible utilizar la condición WHERE CURRENT OF CURSOR. Conceptos relacionados: v “How client applications interact with data sources” en la publicación Federated Systems Guide v “Querying data sources directly with pass-through” en la publicación Federated Systems Guide Tareas relacionadas: v “Pass-through sessions to Oracle data sources” en la publicación Federated Systems Guide v “Working with nicknames” en la publicación Federated Systems Guide Reiniciadores y módulos de reiniciador Los reiniciadores son mecanismos mediante los cuales el servidor federado interactúa con las fuentes de datos. El servidor federado utiliza las rutinas almacenadas en una biblioteca denominada módulo de reiniciador para implantar un reiniciador. Estas rutinas permiten al servidor federado realizar operaciones como, por ejemplo, conectarse a una fuente de datos y recuperar Capítulo 1. Conceptos 53
- 80. datos de la misma repetidamente. Normalmente, el propietario de la instancia federada de DB2 utiliza la sentencia CREATE WRAPPER para registrar un reiniciador en el sistema federado. Debe crearse un reiniciador para cada tipo de fuente de datos al que se desee acceder. Por ejemplo, supongamos que desea acceder a tres tablas de la base de datos DB2 para z/OS, a una tabla DB2 para iSeries, a dos tablas Informix y a una vista Informix. Necesita crear sólo dos reiniciadores: uno para los objetos de la fuente de datos DB2 y otro para los objetos de la fuente de datos Informix. Cuando se hayan registrado estos reiniciadores en la base de datos federada, podrá utilizarlos para acceder a otros objetos de estas fuentes de datos. Por ejemplo, puede utilizar el reiniciador DRDA con todos los objetos de la fuente de datos de la familia DB2—DB2 para UNIX y Windows, DB2 para z/OS y OS/390, DB2 para iSeries y DB2 Server para VM y VSE. Las definiciones y los apodos del servidor se utilizan para identificar los detalles (nombre, ubicación, etc.) de cada objeto de fuente de datos. Existen reiniciadores para cada fuente de datos soportada. Algunos reiniciadores tienen nombres de reiniciador por omisión. Cuando utiliza el nombre por omisión para crear el reiniciador, el servidor federado reúne automáticamente la biblioteca de la fuente de datos asociada con el reiniciador. Tabla 2. Nombres de reiniciador por omisión para cada fuente de datos. Fuente de datos Nombre(s) de reiniciador por omisión DB2 Universal Database para UNIX y DRDA Windows DB2 Universal Database para z/OS y DRDA OS/390 DB2 Universal Database para iSeries DRDA DB2 Server para VM y VSE DRDA Informix INFORMIX Oracle SQLNet o Net8 Microsoft SQL Server DJXMSSQL3, MSSQLODBC3 ODBC ninguno OLE DB OLEDB Sybase CTLIB, DBLIB BLAST ninguno Documentum ninguno Microsoft Excel ninguno 54 Consulta de SQL, Volumen 1
- 81. Tabla 2. Nombres de reiniciador por omisión para cada fuente de datos. (continuación) Fuente de datos Nombre(s) de reiniciador por omisión Archivos estructurados-tabla ninguno XML ninguno Un reiniciador realiza muchas tareas. Algunas de estas tareas son las siguientes: v Conecta con la fuente de datos. El reiniciador utiliza la API de conexión estándar de la fuente de datos. v Envía consultas a la fuente de datos. Para las fuentes de datos que no proporcionan soporte a SQL, se produce una de las acciones siguientes: – Para las fuentes de datos que sí que proporcionan soporte a SQL, la consulta se envía en SQL. – Para las fuentes de datos que no proporcionan soporte a SQL, la consulta se convierte al lenguaje de consulta nativo de la fuente a a una serie de llamadas a la API de la fuente. v Recibe el conjuntos de resultados de la fuente de datos. El reiniciador utiliza las API estándar de fuentes de datos para recibir el conjunto de resultados. v Responde a las consultas del servidor federado sobre las correlaciones de tipos de datos por omisión para una fuente de datos. El reiniciador contiene las correlaciones de tipos por omisión que se utilizan cuando se crean apodos para un objeto de la fuente de datos. Las correlaciones de tipos de datos que se crean alteran temporalmente las correlaciones de tipos de datos por omisión. Las correlaciones de tipos de datos definidos por el usuario se almacenan en el catálogo global. v Responde a las consultas del servidor federado sobre las correlaciones de funciones por omisión para una fuente de datos. El reiniciador contiene información que el servidor federado necesita para determinar si las funciones de DB2 se correlacionan con funciones de la fuente de datos y de qué forma lo hacen. El compilador de SQL utiliza esta información para determinar si la fuente de datos puede realizar las operaciones de consulta. Las correlaciones de funciones que se crean alteran temporalmente las correlaciones de tipos de funciones por omisión. Las correlaciones de funciones definidas por el usuario se almacenan en el catálogo global. Las opciones de reiniciador se utilizan para configurar el reiniciador o definir la forma en que DB2 utiliza el reiniciador. Actualmente sólo hay una opción de reiniciador, DB2_FENCED. La opción de reiniciador DB2_FENCED indica si DB2 protege el reiniciador o confía en él. Un reiniciador protegido funciona bajo una serie de restricciones. Capítulo 1. Conceptos 55
- 82. Conceptos relacionados: v “Create the wrapper” en la publicación Federated Systems Guide v “Fast track to configuring your data sources” en la publicación Federated Systems Guide Información relacionada: v “Opciones de reiniciador para sistemas federados” en la página 817 Definiciones de servidor y opciones de servidor Después de crear reiniciadores para las fuentes de datos, el propietario de la instancia federada debe definir las fuentes de datos a la base de datos federada. El propietario de la instancia suministra un nombre para identificar la fuente de datos y otra información que pertenece a la fuente de datos. Si la fuente de datos es un RDBMS, esta información incluye: v El tipo y la versión del RDBMS. v El nombre de la base de datos de la fuente de datos del RDBMS. v Los metadatos que son específicos para el RDBMS Por ejemplo, una fuente de datos de la familia DB2 puede tener múltiples bases de datos. La definición debe especificar a qué base de datos puede conectarse un servidor federado. Por el contrario, una fuente de datos Oracle tiene una base de datos y el servidor federado puede conectarse a la base de datos sin conocer su nombre. El nombre de la base de datos no se incluye en la definición de servidor federado de una fuente de datos Oracle. El nombre y otra información que el propietario de la instancia suministra al servidor federado se denominan colectivamente una definición de servidor. Las fuentes de datos responde a peticiones de datos y son servidores por derecho propio. Las sentencias CREATE SERVER y ALTER SERVER se utilizan para crear y modificar una definición de servidor. Para de la información incluida en una definición de servidor se almacena como opciones de servidor. Al crear definiciones de servidor, es importante comprender las opciones que se pueden especificar sobre el servidor. Algunas opciones de servidor configuran el reiniciador y algunas afectan a la forma en que DB2 utiliza el reiniciador. Las opciones de servidor se especifican como parámetros en las sentencias CREATE SERVER y ALTER SERVER. Las opciones de servidor se establecen en valores que persisten a través de conexiones sucesivas con la fuente de datos. Estos valores se almacenan en el catálogo global. Por ejemplo, el nombre de la fuente de datos del RDBMS se establece en la opción de servidor NODE. Algunas fuentes de datos tienen 56 Consulta de SQL, Volumen 1
- 83. varias bases de datos en cada instancia. Para estas fuentes de datos, el nombre de la base de datos a la que se conecta el servidor federado se establece en la opción de servidor DBNAME. Para establecer un valor para una opción de servidor temporalmente se utiliza la sentencia SET SERVER OPTION. Esta sentencia altera temporalmente el valor durante la duración de una sola conexión a la base de datos federada. El valor que prevalece no se almacena en el catálogo global. Conceptos relacionados: v “Supply the server definition” en la publicación Federated Systems Guide Información relacionada: v “Opciones de servidor para sistemas federados” en la página 806 Correlaciones del usuario y opciones del usuario Cuando un servidor federado necesita bajar una petición a una fuente de datos, el servidor debe establecer primero una conexión con la fuente de datos. Para ello, el servidor utiliza un ID de usuario y una contraseña válido para la fuente de datos. Por omisión, el servidor federado intenta acceder a la fuente de datos con el ID de usuario y la contraseña que se utiliza para conectarse con DB2. Si el ID de usuario y la contraseña son los mismos en el servidor federado y en la fuente de datos, se establece la conexión. Si el ID de usuario y la contraseña para acceder al servidor federado difieren del ID de usuario y la contraseña para acceder a una fuente de datos, es necesario definir una asociación entre las dos autorizaciones. Una vez haya definido la asociación, las peticiones distribuidas pueden enviarse a la fuente de datos. Esta asociación se denomina correlación de usuarios. Las correlaciones de usuarios se definen y modifican con las sentencias CREATE USER MAPPING y ALTER USER MAPPING. Estas sentencias incluyen parámetros, denominados opciones de usuario, a los que se asignan valores relacionados con la autorización. Por ejemplo, suponga que un usuario tiene el mismo ID, pero distintas contraseñas, para la base de datos federada y una fuente de datos. Para que el usuario acceda a la fuente de datos, es necesario correlacionar las contraseñas entre sí. Para correlacionar las contraseñas, debe utilizar la sentencia CREATE USER MAPPING y la opción de usuario REMOTE_PASSWORD. Utilice la sentencia ALTER USER MAPPING para modificar una correlación de usuarios existente. Conceptos relacionados: v “Create the user mappings and test the connection to the data source” en la publicación Federated Systems Guide Información relacionada: Capítulo 1. Conceptos 57
- 84. v “ALTER USER MAPPING sentencia” en la publicación Consulta de SQL, Volumen 2 v “CREATE USER MAPPING sentencia” en la publicación Consulta de SQL, Volumen 2 Apodos y objetos de la fuente de datos Después de crear las definiciones del servidor y las correlaciones del usuario, el propietario de la instancia federada debe crear los apodos. Un apodo es un identificador que se utiliza para hacer referencia al objeto ubicado en las fuentes de datos al que desea acceder. Los objetos identificados mediante apodos se denominan objetos de la fuente de datos. La tabla siguiente muestra los objetos de la fuente de datos a los que puede hacerse referencia al crear un apodo. Tabla 3. Fuentes de datos y los objetos para los puede crearse un apodo Fuente de datos Objetos a los que puede hacerse referencia DB2 para UNIX y Windows apodos, tablas de resumen, tablas, vistas DB2 para z/OS y OS/390 tablas, vistas DB2 para iSeries tablas, vistas DB2 Server para VM y VSE tablas, vistas Informix tablas, vistas, sinónimos Microsoft SQL Server tablas, vistas ODBC tablas, vistas Oracle tablas, vistas Sybase tablas, vistas BLAST archivos FASTA indexados para algoritmos de búsqueda BLAST software de gestión de documentos objetos y tablas registradas en una base de documentos de Documentum Microsoft Excel archivos .xls (sólo se accede a la primera hoja del libro de trabajo) archivos estructurados-tabla archivos .txt (archivos de texto que cumplen un formato muy concreto) archivos de códigos XML conjuntos de elementos en un documento XML 58 Consulta de SQL, Volumen 1
- 85. Los apodos no son nombres alternativos para los objetos de la fuente de datos del modo en que lo son los seudónimos. Son punteros mediante los cuales el servidor federado hace referencia a estos objetos. Los apodos suelen definirse con la sentencia CREATE NICKNAME. Cuando un usuario final o una aplicación cliente somete una petición distribuida al servidor federado, no es necesario que la petición especifique las fuentes de datos. En lugar de ello, ésta hace referencia a los objetos de la fuente de datos mediante sus apodos. Los apodos se correlacionan con los objetos concretos en la fuente de datos. Las correlaciones eliminan la necesidad de calificar los apodos mediante nombres de fuentes de datos. La ubicación de los objetos de la fuente de datos es transparente para el usuario final o la aplicación cliente. Supongamos que se define el apodo DEPT para representar una tabla de la base de datos de Informix denominada NFX1.PERSON.DEPT. Desde el servidor federado puede ejecutarse la sentencia SELECT * FROM DEPT. Sin embargo, la sentencia SELECT * FROM NFX1.PERSON.DEPT no puede ejecutarse desde el servidor federado (a excepción de las sesiones de paso a través). Cuando crea un apodo para un objeto de fuente de datos, se añaden metadatos sobre el objeto al catálogo global. El optimizador de consultas utiliza estos metadatos y la información del reiniciador para facilitar el acceso al objeto de la fuente de datos. Por ejemplo, si el apodo es para una tabla que tiene un índice, el catálogo global contiene información acerca del índice. El reiniciador contiene las correlaciones entre los tipos de datos de DB2 y los tipo s de datos de la fuente de datos. Actualmente, no es posible ejecutar operaciones de programas de utilidad de DB2 (LOAD, REORG, REORGCHK, IMPORT, RUNSTATS, etc.) sobre apodos. Conceptos relacionados: v “Create nicknames for each data source object” en la publicación Federated Systems Guide Información relacionada: v “CREATE NICKNAME sentencia” en la publicación Consulta de SQL, Volumen 2 Opciones de columna Es posible proporcionar al catálogo global información adicional sobre el objeto al que el apodo hace referencia mediante metadatos. Estos metadatos describen valores en ciertas columnas del objeto de la fuente de datos. Estos metadatos se asignan a parámetros que se denominan opciones de columna. Las Capítulo 1. Conceptos 59
- 86. opciones de columna indican al reiniciador que gestione los datos de una columna de forma distinta a como lo haría normalmente. Las opciones de columna también se utilizan para proporciona otra información al reiniciador. Por ejemplo, para las fuentes de datos XML, se utiliza una opción de columna para indicar al reiniciador qué expresión XPath debe utilizar al analizar la columna fuera del documento XML. El compilador de SQL y optimizador de consultas utilizan los metadatos para desarrollar planes mejores para acceder a los datos. DB2 trata los objetos a los que hace referencia un apodo como si fueran tablas. Por lo tanto, es posible definir opciones de columna para cualquier objeto de la fuente de datos para el que cree un apodo. Algunas opciones de columna están diseñadas para tipos concretos de fuentes de datos y sólo pueden aplicarse a estas fuentes de datos. Supongamos que una fuente de datos tiene un orden de clasificación que difiere del orden de clasificación de la base de datos federada. El servidor federado normalmente no clasificaría las columnas que contienen datos de caracteres de la fuente de datos. Devolvería los datos a la base de datos federada y realizaría la clasificación localmente. Sin embargo, supongamos que la columna es un tipo de datos de caracteres (CHAR y VARCHAR) y sólo contiene caracteres numéricos (’0’,’1’,...,’9’). Puede indicar esto asignando un valor de ’Y’ a la opción de columna NUMERIC_STRING. Esto proporciona al optimizador de consultas de DB2 la opción de realizar la clasificación en la fuente de datos. Si la clasificación se realiza remotamente, se evita la sobrecargar de llevar los datos al servidor federado y realizar la clasificación localmente. Las opciones de columna pueden definirse en las sentencias CREATE NICKNAME y ALTER NICKNAME. Tareas relacionadas: v “Working with nicknames” en la publicación Federated Systems Guide Información relacionada: v “Opciones de columna para sistemas federados” en la página 804 Correlaciones de tipos de datos Los tipos de datos de la fuente de datos debe correlacionarse con los tipos de datos DB2 correspondientes, de forma que el servidor federado pueda recuperar los datos de las fuentes de datos. Para la mayor parte de fuentes de datos, las correlaciones de tipos por omisión se encuentran en los reiniciadores. Las correlaciones de tipos por omisión para las fuentes de datos 60 Consulta de SQL, Volumen 1
- 87. de DB2 se encuentran en el reiniciador DRDA. Las correlaciones de tipos por omisión para Informix se encuentran en el reiniciador INFORMIX y así sucesivamente. Para algunas fuentes de datos no relacionales, es necesario especificar información sobre los tipos de datos en la sentencia CREATE NICKNAME. Deben especificarse los tipos de datos de DB2 para UNIX y Windows correspondientes para cada columna del objeto de la fuente de datos cuando se crea el apodo. Cada columna debe correlacionarse con una campo o una columna concreto del objeto de la fuente de datos. Por ejemplo: v El tipo FLOAT de Oracle se correlaciona por omisión con el tipo DOUBLE de DB2. v El tipo DATE de Oracle se correlaciona por omisión con el tipo TIMESTAMP de DB2. v El tipo DATA de DB2 para z/OS se correlaciona por omisión con el tipo DATE de DB2. Cuando se devuelven a la base de datos federada valores de una columna de la fuente de datos, los valores se ajustan completamente al tipo de datos de DB2 con el que se ha correlacionado la columna de la fuente de datos. Si se trata de una correlación por omisión, los valores también se ajustan completamente al tipo de la fuente de datos de la correlación. Por ejemplo, supongamos que una tabla Oracle con una columna FLOAT está definida en la base de datos federada. La correlación por omisión del tipo FLOAT de Oracle al tipo DOUBLE de DB2 DOUBLE se aplica automáticamente a esta columna. En consecuencia, los valores que se devuelvan de la columna se ajustarán completamente a FLOAT y a DOUBLE. En algunos reiniciadores, es posible modificar el formato o la longitud de los valores que se devuelven. Para ello, se modifica el tipo de datos de DB2 al que deben ajustarse los valores. Por ejemplo, el tipo de datos DATE de Oracle se utiliza como una indicación de fecha y hora; el tipo de datos DATE de Oracle incluye el siglo, el año, el mes, el día, la hora, los minutos y los segundos. Por omisión, el tipo de datos DATE de Oracle se correlaciona con el tipo de datos TIMESTAMP de DB2. Supongamos que varias columnas de la tabla Oracle tienen un tipo de datos DATE. Y que desea que estas columnas devuelvan sólo la hora, los minutos y los segundos. Puede alterar temporalmente la correlación de tipos de datos por omisión de forma que el tipo de datos DATE de Oracle se correlacione con el tipo de datos TIME de DB2. Cuando se consultan las columnas DATE de Oracle, sólo se devuelve a DB2 la parte de la hora de los valores de indicación de fecha y hora. Capítulo 1. Conceptos 61
- 88. Utilice la sentencia CREATE TYPE MAPPING para crear: v Una correlación de tipos de datos que altera temporalmente una correlación de tipos de datos por omisión v Una correlación de tipos de datos para la que actualmente no existe ninguna correlación. Por ejemplo, cuando un nuevo tipo incorporado está disponible en la fuente de datos o cuando hay un tipo definido por el usuario en la fuente de datos con la que desea correlacionarse. En la sentencia CREATE TYPE MAPPING, puede especificarse si la correlación se aplica cada vez que accede a la fuente de datos o si se aplica a un servidor concreto. Utilice la sentencia ALTER TYPE MAPPING para cambiar una correlación de tipos que se haya creado originalmente con la sentencia CREATE TYPE MAPPING. La sentencia ALTER TYPE MAPPING no puede utilizarse para cambiar las correlaciones de tipos por omisión. Para modificar una correlación de tipos de datos para una columna específica de un objeto de la fuente de datos concreto, utilice los parámetros de opción de columna de la sentencia ALTER NICKNAME. Este sentencia le permite especificar las correlaciones de tipos de datos para determinadas tablas o vistas u otros objetos de la fuente de datos. Si cambia una correlación de tipos, los apodos creados antes de cambiar la correlación de tipos no reflejan la nueva correlación. Tipos de datos no soportados: Los servidores federados de DB2 no proporcionan soporte a: v LONG VARCHAR v LONG VARGRAPHIC v DATALINK v Tipos de datos definidos por el usuario (UDT) creados en la fuente de datos No es posible crear una correlación definida por el usuario para estos tipos de datos. Sin embargo, puede crear un apodo para una vista de la fuente de datos que sea idéntico a la tabla que contiene los tipos de datos definidos por el usuario. La vista debe ’convertir’ la columna de tipo definido por el usuario al tipo incorporado o del sistema. Puede crearse un apodo para una tabla remota que contenga columnas LONG VARCHAR. Sin embargo, los resultados se correlacionarán con un tipo de datos de DB2 local que no será LONG VARCHAR. Conceptos relacionados: 62 Consulta de SQL, Volumen 1
- 89. v “Modifying wrappers” en la publicación Federated Systems Guide Tareas relacionadas: v “Modifying default data type mappings” en la publicación Federated Systems Guide Información relacionada: v “ALTER NICKNAME sentencia” en la publicación Consulta de SQL, Volumen 2 v “CREATE TYPE MAPPING sentencia” en la publicación Consulta de SQL, Volumen 2 v “Correlaciones de tipos de datos en avance por omisión” en la página 818 Correlaciones de funciones y plantillas de funciones Para que el servidor federado reconozca una función de la fuente de datos, la función debe correlacionarse con una función DB2 existente. DB2 suministra correlaciones por omisión entre las funciones de fuente de datos incorporadas existentes y las funciones DB2 incorporadas. Para la mayor parte de fuentes de datos, las correlaciones de funciones por omisión se encuentran en los reiniciadores. Las correlaciones de funciones por omisión de funciones DB2 para UNIX y Windows a funciones DB2 para z/OS se encuentran en el reiniciador DRDA. Las correlaciones de funciones por omisión de funciones DB2 para UNIX y Windows a funciones Sybase se encuentran en los reiniciadores CTLIB y DBLIB y así sucesivamente. Para utilizar una función de la fuente de datos que el servidor federado no reconoce, el usuario debe crear una correlación. La correlación debe crearse entre una función de la fuente de datos y una función complementaria situada en la base de datos federada. Las correlaciones de funciones suelen utilizarse cuando una nueva función incorporada y una nueva función definida por el usuario está disponible en la fuente de datos. Las correlaciones de funciones también se utilizan cuando no existe una función complementaria de DB2 y el usuario debe crear una en el servidor federado de DB2 que satisfaga los requisitos siguientes: v Si la función de fuente de datos tiene parámetros de entrada: – La función complementaria de DB2 debe tener el mismo número de parámetros de entrada que tiene la función de fuente de datos. – Los tipos de datos de los parámetros de entrada para la función complementaria de DB2 deben ser compatibles con los tipos de datos correspondientes de los parámetros de entrada de la función de fuente de datos. v Si la función de fuente de datos no tiene parámetros de entrada: Capítulo 1. Conceptos 63
- 90. – La función complementaria de DB2 no puede tener ningún parámetro de entrada. Nota: Cuando se crea una correlación de funciones, es posible que los valores devueltos a partir de una función evaluada en la fuente de datos sean distintos de los valores devueltos a partir de una función compatible evaluada en la base de datos federada de DB2. DB2 utilizará la correlación de funciones pero es posible que se produzca un error de sintaxis de SQL o resultados inesperados. La función complementaria de DB2 puede ser una función completa o una plantilla de función. Una plantilla de función es una función de DB2 que puede crearse para invocar una función de una fuente de datos. El servidor federado reconoce una función de la fuente de datos cuando existe una correlación entre la función de la fuente de datos y una función complementaria situada en la base de datos federada. Cuando no existe ninguna función complementaria, puede crearse una función que actúa como complementaria. Sin embargo, a diferencia de una función regular, una plantilla de función no tiene código ejecutable. Después de crear una plantilla de función, debe crear la correlación de funciones entre la plantilla y la función de la fuente de datos. La plantilla de función se crea con la sentencia CREATE FUNCTION, utilizando el parámetro AS TEMPLATE. Una correlación de funciones se crea con la sentencia CREATE FUNCTION MAPPING. Cuando el servidor federado recibe consultas que especifiquen la plantilla de función, el servidor federado invocará la función de la fuente de datos. Conceptos relacionados: v “Opciones de correlación de funciones” en la página 64 Información relacionada: v “Opciones de correlación de funciones para sistemas federados” en la página 805 Opciones de correlación de funciones La sentencia CREATE FUNCTION MAPPING incluye parámetros denominados opciones de correlación de funciones. El usuario puede asignar valores que pertenecen a la correlación o a la función de la fuente de datos de la correlación. Por ejemplo, pueden incluirse las estadísticas estimadas sobre la actividad general que se consumirá cuando se invoque la función de la fuente de datos. El optimizador de consultas utiliza estos valores estimados para decidir si debería ser la fuente de datos o la base de datos federada de DB2 quien invocara la función. 64 Consulta de SQL, Volumen 1
- 91. Información relacionada: v “Opciones de correlación de funciones para sistemas federados” en la página 805 Especificaciones de índice Cuando crea un apodo para una tabla de la fuente de datos, se añade información sobre los índices que tenga la tabla de la fuente de datos al catálogo global. El optimizador de consultas utiliza esta información para acelerar el proceso de las peticiones distribuidas. La información de catálogo sobre un índice de la fuente de datos es un conjunto de metadatos y se denomina una especificación de índice. Un servidor federado no crea una especificación de índice cuando se crea un apodo para: v Una tabla que no tiene índices. v Una vista, que no suele tener almacenada ninguna información sobre los índices en el catálogo remoto. v Un objeto de la fuente de datos, que no tiene un catálogo remoto del que el servidor federado pueda obtener la información sobre los índices. Nota: No es posible crear una especificación de índice para una vista Informix. Supongamos que se crea un apodo para una tabla que no tiene ningún índice pero que la tabla adquiere un índice más tarde. Supongamos que una tabla adquiere un índice nuevo además de los que tenía cuando se creó el apodo. Como la información sobre índices se proporciona al catálogo global en el momento en que se crea el apodo, el servidor federado desconoce la existencia de índices nuevos. De forma similar, cuando se crea un apodo para una vista, el servidor federado no es consciente de la tabla subyacente (y los índices de la misma) a partir de la cual se ha generado la vista. En estas circunstancias, es posible suministrar la información sobre índices necesaria al catálogo global. Puede crear una especificación de índice para las tablas que no tienen índices. La especificación de índice indica al optimizador de la consulta en qué columna o columnas de la tabla debe buscar para buscar los datos con rapidez. En un sistema federado, se utiliza la sentencia CREATE INDEX frente a un apodo para suministrar información sobre las especificaciones de índice al catálogo global. Si una tabla adquiere un índice nuevo, la sentencia CREATE INDEX que ha creado hará referencia al apodo de la tabla y contendrá información sobre el índice de la tabla de la fuente de datos. Si se crea un apodo para una vista, la sentencia CREATE INDEX que cree hará referencia al apodo de la vista y contendrá información sobre el índice de la tabla subyacente para la vista. Capítulo 1. Conceptos 65
- 92. Conceptos relacionados: v “El compilador de SQL y el optimizador de consultas” en la página 50 v “Overview of the tasks to set up a federated system” en la publicación Federated Systems Guide v “Modifying wrappers” en la publicación Federated Systems Guide Información relacionada: v “CREATE INDEX sentencia” en la publicación Consulta de SQL, Volumen 2 66 Consulta de SQL, Volumen 1
- 93. Capítulo 2. Elementos del lenguaje Este capítulo describe los elementos del lenguaje que son comunes a muchas sentencias de SQL: v “Caracteres” v “Símbolos” en la página 69 v “Identificadores” en la página 71 v “Tipos de datos” en la página 101 v “Constantes” en la página 155 v “Registros especiales” en la página 158 v “Funciones” en la página 181 v “Métodos” en la página 192 v “Expresiones” en la página 202 v “Predicados” en la página 242 Caracteres Los símbolos básicos de las palabras clave y de los operadores del lenguaje SQL son caracteres de un solo byte que forman parte de todos los juegos de caracteres IBM. Los caracteres del lenguaje se clasifican en letras, dígitos y caracteres especiales. Una letra es cualquiera de las 26 letras mayúsculas (A - Z) y 26 letras minúsculas (a - z) más los tres caracteres ($, # y @), que se incluyen para la compatibilidad con los productos de base de datos de lenguaje principal (por ejemplo, en la página de códigos 850, $ está en la posición X'24', # está en la posición X'23' y @ está en la posición X'40'). Las letras también incluyen los caracteres alfabéticos de los juegos de caracteres ampliados. Los juegos de caracteres ampliados contienen caracteres alfabéticos adicionales, tales como caracteres con signos diacríticos (u es un ejemplo de signo diacrítico). Los caracteres disponibles dependen de la página de códigos que se utiliza. Un dígito es cualquier carácter del 0 al 9. Un carácter especial es cualquiera de los caracteres listados a continuación: blanco − signo menos " comillas dobles . punto % porcentaje / barra inclinada © Copyright IBM Corp. 1993, 2002 67
- 94. & signo & : dos puntos ' apóstrofo o comillas ; punto y coma simples ( abrir paréntesis < menor que ) cerrar paréntesis = igual * asterisco > mayor que + signo más ? signo de interrogación , coma _ subrayado | barra vertical ^ signo de intercalación ! signo de admiración Todos los caracteres de múltiples bytes se tratan como letras, excepto el blanco de doble byte, que es un carácter especial. 68 Consulta de SQL, Volumen 1
- 95. Símbolos Los símbolos son las unidades sintácticas básicas de SQL. Un símbolo es una secuencia de uno o varios caracteres. Un símbolo no puede contener caracteres en blanco, a menos que sea una constante de tipo serie o un identificador delimitado, que pueden contener blancos. Los símbolos se clasifican en ordinarios y delimitadores: v Un símbolo ordinario es una constante numérica, un identificador ordinario, un identificador del lenguaje principal o una palabra clave. Ejemplos 1 .1 +2 SELECT E 3 v Un símbolo delimitador es una constante de tipo serie, un identificador delimitado, un símbolo de operador o cualquier carácter especial mostrado en los diagramas de sintaxis. Un signo de interrogación también es un símbolo delimitador cuando actúa como marcador de parámetros. Ejemplos , ’serie’ "fld1" = . Espacios: Un espacio es una secuencia de uno o varios caracteres en blanco. Los símbolos que no son constantes de tipo serie ni identificadores delimitados no deben incluir ningún espacio. Los símbolos pueden ir seguidos de un espacio. Cada símbolo ordinario debe ir seguido por un espacio o por un símbolo delimitador si lo permite la sintaxis. Comentarios: Las sentencias de SQL estático pueden incluir comentarios del lenguaje principal o comentarios de SQL. Se puede especificar cualquiera de estos tipos de comentario dondequiera que se pueda especificar un espacio, excepto dentro de un símbolo delimitador o entre las palabras clave EXEC y SQL. Los comentarios de SQL comienzan con dos guiones consecutivos (--) y finalizan con el final de la línea. Sensibilidad a mayúsculas y minúsculas: Los símbolos pueden incluir letras minúsculas, pero las letras minúsculas de un símbolo ordinario se convierten a mayúsculas, excepto en las variables del lenguaje principal en C, que tienen identificadores sensibles a las mayúsculas y minúsculas. Los símbolos delimitadores no se convierten nunca a mayúsculas. Por lo tanto, la sentencia: select * from EMPLOYEE where lastname = ’Smith’; después de la conversión, es equivalente a: SELECT * FROM EMPLOYEE WHERE LASTNAME = ’Smith’; Las letras alfabéticas de múltiples bytes no se convierten a mayúsculas. Los caracteres de un solo byte (de la ″a″ a la ″z″) sí se convierten a mayúsculas. Capítulo 2. Elementos del lenguaje 69
- 96. Información relacionada: v “Cómo se invocan las sentencias de SQL” en la publicación Consulta de SQL, Volumen 2 v “PREPARE sentencia” en la publicación Consulta de SQL, Volumen 2 70 Consulta de SQL, Volumen 1
- 97. Identificadores Un identificador es un símbolo que se utiliza para formar un nombre. En una sentencia de SQL, un identificador es un identificador de SQL o un identificador del lenguaje principal. v identificadores de SQL Existen dos tipos de identificadores de SQL: ordinarios y delimitados. – Un identificador ordinario es una letra seguida de cero o más caracteres, cada uno de los cuales puede ser una letra mayúscula, un dígito o el carácter de subrayado. Un identificador ordinario no debe ser idéntico a una palabra reservada. Ejemplos WKLYSAL WKLY_SAL – Un identificador delimitado es una secuencia de uno o varios caracteres entre comillas dobles. Dos comillas consecutivas se utilizan para representar unas comillas dentro del identificador delimitado. De esta manera un identificador puede incluir letras en minúsculas. Ejemplos "WKLY_SAL" "WKLY SAL" "UNION" "wkly_sal" Las conversión de caracteres de los identificadores creados en una página de códigos de doble byte pero utilizados por una aplicación o una base de datos en una página de códigos de múltiples bytes pueden necesitar una consideración especial. v Identificadores de lenguaje principal Un identificador de lenguaje principal es un nombre declarado en el programa de lenguaje principal. Las reglas para formar un identificador de lenguaje principal son las reglas del lenguaje principal. Un identificador de lenguaje principal no debe tener una longitud mayor que 255 caracteres y no debe comenzar con los caracteres ’SQL’ ni ’DB2’ (ni en mayúsculas ni en minúsculas). Convenios de denominación y calificaciones de nombre de objeto explícitas Las reglas para formar el nombre de un objeto dependen del tipo de objeto. Los nombres de los objetos de una base de datos pueden constar de un solo identificador o pueden ser objetos calificados mediante esquema que consten de dos identificadores. Los nombres de los objetos calificados mediante esquema pueden especificarse sin el nombre de esquema; en este caso, el nombre de esquema es implícito. En las sentencias de SQL dinámico, un nombre de objeto calificado con un esquema utiliza implícitamente el valor de registro especial CURRENT Capítulo 2. Elementos del lenguaje 71
- 98. SCHEMA como calificador para las referencias al nombre de objeto no calificadas. Por omisión, se establece en el ID de autorización actual. Si la sentencia de SQL dinámico está contenida en un paquete que muestra un comportamiento de vinculación, definición o invocación, el registro especial CURRENT SCHEMA no se utiliza en la calificación. En un paquete con comportamiento de vinculación, se utiliza el calificador por omisión del paquete como el valor para la calificación implícita de las referencias al objeto no calificadas. En un paquete con comportamiento de definición, se utiliza el ID de autorización de la persona que define la rutina como el valor para la calificación implícita de las referencias al objeto no calificadas en la rutina. En un paquete con comportamiento de invocación, se utiliza el ID en vigor al invocar la rutina como el valor para la calificación implícita de las referencias al objeto no calificadas en las sentencias de SQL dinámico de la rutina. Para obtener más información, consulte el apartado “Características de SQL dinámico durante la ejecución” en la página 80. En las sentencias de SQL estático, la opción de precompilación/vinculación QUALIFIER especifica implícitamente el calificador para los nombres de objetos de base de datos no calificados. Por omisión, este valor se establece en el ID de autorización del paquete. Los nombres de objeto siguientes, cuando se utilizan en el contexto de un procedimiento de SQL, sólo pueden utilizar los caracteres permitidos en un identificador ordinario, aunque los nombres estén delimitados: v nombre-condición v etiqueta v nombre-parámetro v nombre-procedimiento v nombre-variable-SQL v nombre-sentencia Los diagramas de sintaxis utilizan distintos términos para tipos diferentes de nombres. La lista siguiente define dichos términos. nombre-seudónimo Nombre calificado mediante esquema que designa un seudónimo. nombre-atributo Identificador que designa un atributo de un tipo de datos estructurados. nombre-autorización Identificador que designa un usuario o un grupo: v Los caracteres válidos van de la ″A″ a la ″Z″, de la ″a″ a la ″z″, del 0 al 9, #, @, $ y _. 72 Consulta de SQL, Volumen 1
- 99. v El nombre no debe empezar por los caracteres 'SYS', 'IBM' ni 'SQL'. v El nombre no debe ser: ADMINS, GUESTS, LOCAL, PUBLIC ni USERS. v Un ID de autorización delimitado no debe contener letras en minúsculas. nombre-agrupalmacinter Identificador que designa una agrupación de almacenamientos intermedios. nombre-columna Nombre calificado o no calificado que designa una columna de una tabla o de una vista. El calificador es un nombre de tabla, un nombre de vista, un apodo o un nombre de correlación. nombre-condición Identificador que designa una condición en un procedimiento de SQL. nombre-restricción Identificador que designa una restricción de referencia, una restricción de clave primaria, una restricción de unicidad o una restricción de comprobación de tabla. nombre-correlación Identificador que designa una tabla resultante. nombre-cursor Identificador que designa un cursor de SQL. Para compatibilidad entre sistemas principales, se puede utilizar un carácter de guión en el nombre. nombre-fuente-datos Identificador que designa una fuente de datos. Este identificador es la primera de las tres partes de un nombre de objeto remoto. nombre-descriptor Dos puntos seguidos de un identificador del lenguaje principal que designa un área de descriptores de SQL (SQLDA). Para ver la descripción de un identificador de lenguaje principal,consulte el apartado “Referencias a variables del lenguaje principal” en la página 91. Observe que un nombre de descriptor nunca incluye una variable indicadora. nombre-tipo-diferenciado Nombre calificado o no calificado que designa un tipo diferenciado. El gestor de bases de datos califica implícitamente un nombre de tipo diferenciado no calificado en una sentencia de SQL según el contexto. Capítulo 2. Elementos del lenguaje 73
- 100. nombre-supervisor-sucesos Identificador que designa un supervisor de sucesos. nombre-correlación-funciones Identificador que designa una correlación de funciones. nombre-función Nombre calificado o no calificado que designa una función. El gestor de bases de datos califica implícitamente un nombre de función no calificado en una sentencia de SQL según el contexto. nombre-grupo Identificador no calificado que designa un grupo de transformación definido para un tipo estructurado. variable-lengprinc Secuencia de símbolos que designa una variable del lenguaje principal. Una variable del lenguaje principal incluye, como mínimo, un identificador de lenguaje principal, como se explica en el apartado “Referencias a variables del lenguaje principal” en la página 91. nombre-índice Nombre calificado mediante esquema que designa un índice o una especificación de índice. etiqueta Identificador que designa una etiqueta en un procedimiento de SQL. nombre-método Identificador que designa un método. El contexto de esquema de un método está determinado por el esquema del tipo indicado (o de un supertipo del tipo indicado) del método. apodo Nombre calificado mediante esquema que designa una referencia de servidor federado a una tabla o vista. nombre-grupo-particiones-bd Identificador que designa un grupo de particiones de base de datos. nombre-paquete Nombre calificado mediante esquema que designa un paquete. Si un paquete tiene un ID de versión que no es la serie vacía, el nombre del paquete también incluye el ID de versión al final del nombre, en el formato siguiente: id-esquema.id-paquete.id-versión. 74 Consulta de SQL, Volumen 1
- 101. nombre-parámetro Identificador que designa un parámetro al que se puede hacer referencia en un procedimiento, una función definida por el usuario, un método o una extensión de índice. nombre-procedimiento Nombre calificado o no calificado que designa un procedimiento. El gestor de bases de datos califica implícitamente un nombre de procedimiento no calificado en una sentencia de SQL según el contexto. nombre-autorización-remoto Identificador que designa un usuario de fuente de datos. Las normas para los nombres de autorización varían de fuente de datos a fuente de datos. nombre-función-remota Nombre que designa una función registrada en una base de datos de fuente de datos. nombre-objeto-remoto Nombre de tres partes que designa una tabla de fuente de datos o vista y que identifica la fuente de datos en la que reside la tabla o la vista. Las partes de este nombres son nombre-fuente-datos, nombre-esquema-remoto y nombre-tabla-remota. nombre-esquema-remoto Nombre que designa el esquema al que pertenece una tabla de fuente de datos o vista. Este nombre es la segunda de las tres partes de un nombre de objeto remoto. nombre-tabla-remota Nombre que designa una tabla o una vista en una fuente de datos. Este nombre es la tercera de las tres partes de un nombre de objeto remoto. nombre-tipo-remoto Tipo de datos soportado por una base de datos de fuente de datos. No utilice el formato largo para los tipos internos (utilice CHAR en vez de CHARACTER, por ejemplo). nombre-puntosalvar Identificador que designa un punto de salvar. nombre-esquema Identificador que proporciona una agrupación lógica de objetos de SQL. Un nombre de esquema que se utiliza como calificador del nombre de un objeto puede determinarse implícitamente: v a partir del valor del registro especial CURRENT SCHEMA Capítulo 2. Elementos del lenguaje 75
- 102. v a partir del valor de la opción de precompilación/vinculación QUALIFIER v sobre la base de un algoritmo de resolución que utilice el registro especial CURRENT PATH v sobre la base del nombre de esquema de otro objeto en la misma sentencia de SQL. Para evitar complicaciones, es recomendable no utilizar el nombre SESSION como esquema, excepto para el esquema de tablas temporales globales declaradas (las cuales deben utilizar el nombre de esquema SESSION). nombre-servidor Identificador que designa un servidor de aplicaciones. En un sistema federado, el nombre de servidor también designa el nombre local de una fuente de datos. nombre-específico Nombre, calificado o no calificado, que designa un nombre específico. El gestor de bases de datos califica implícitamente un nombre específico no calificado en una sentencia de SQL según el contexto. nombre-variable-SQL El nombre de una variable local en una sentencia de procedimiento SQL. Los nombres de variables SQL se pueden utilizar en otras sentencias de SQL donde esté permitido un nombre de variable del lenguaje principal. El nombre puede estar calificado por la etiqueta de la sentencia compuesta donde se declaró la variable de SQL. nombre-sentencia Identificador que designa una sentencia de SQL preparada. nombre-supertipo Nombre calificado o no calificado que designa el supertipo de un tipo. El gestor de bases de datos califica implícitamente un nombre de supertipo no calificado en una sentencia de SQL según el contexto. nombre-tabla Nombre calificado mediante esquema que designa una tabla. nombre-espacio-tablas Identificador que designa un espacio de tablas. 76 Consulta de SQL, Volumen 1
- 103. nombre-activador Nombre calificado mediante esquema que designa un activador. nombre-correlación-tipos Identificador que designa una correlación de tipos de datos. nombre-tipo Nombre calificado o no calificado que designa un tipo. El gestor de bases de datos califica implícitamente un nombre de tipo no calificado en una sentencia de SQL según el contexto. nombre-tabla-tipo Nombre calificado mediante esquema que designa una tabla con tipo. nombre-vista-tipo Nombre calificado mediante esquema que designa una vista con tipo. nombre-vista Nombre calificado mediante esquema que designa una vista. nombre-reiniciador Identificador que designa un reiniciador. Seudónimos Un seudónimo de tabla se puede considerar como un nombre alternativo de una tabla o una vista. Por lo tanto, en una sentencia de SQL se puede hacer referencia a una tabla o a una vista por su nombre o por su seudónimo de tabla. Un seudónimo se puede utilizar siempre que se pueda utilizar el nombre de una tabla o una vista. Se puede crear un seudónimo aunque no exista el objeto (aunque debe existir en el momento de compilar una sentencia que hace referencia al mismo). Puede hacer referencia a otro seudónimo si no se realizan referencias circulares ni repetitivas a lo largo de la cadena de seudónimos. Un seudónimo sólo puede hacer referencia a una tabla, una vista o un seudónimo de la misma base de datos. Un seudónimo no se puede utilizar cuando se espera un nombre de tabla o de vista nuevo como, por ejemplo, en las sentencias CREATE TABLE o CREATE VIEW; por ejemplo, si se ha creado el seudónimo PERSONAL, las sentencias posteriores como, por ejemplo, CREATE TABLE PERSONAL... devolverán un error. La opción de para hacer referencia a una tabla o una vista mediante un seudónimo no se muestra explícitamente en los diagramas de sintaxis, ni se menciona en las descripciones de las sentencias de SQL. Un seudónimo no calificado nuevo no puede tener el mismo nombre completamente calificado que una tabla, una vista o un seudónimo existente. Capítulo 2. Elementos del lenguaje 77
- 104. El efecto de utilizar un seudónimo en una sentencia de SQL es similar al de la sustitución de texto. El seudónimo, que debe definirse antes de compilar la sentencia de SQL, se sustituye en el momento de compilar la sentencia por el nombre base calificado de la tabla o vista. Por ejemplo, si PBIRD.SALES es un seudónimo de DSPN014.DIST4_SALES_148, entonces en el momento de la compilación: SELECT * FROM PBIRD.SALES se convierte en realidad en SELECT * FROM DSPN014.DIST4_SALES_148 En un sistema federado, los usos y restricciones de la sentencia mencionada no sólo se aplican a los seudónimo de tablas, sino también a los seudónimo de apodos. Por consiguiente, un seudónimo de apodo se puede utilizar en vez del apodo en una sentencia de SQL; se puede crear un seudónimo para un apodo que aún no exista, siempre que el apodo se cree antes de que las sentencias que hacen a la referencia se compilen; un seudónimo para un apodo puede hacer referencia a otro seudónimo para este apodo y así sucesivamente. En la tolerancia de sintaxis de las aplicaciones que se ejecutan bajo otros sistemas de gestión de bases de datos relacionales, se puede utilizar SYNONYM en vez de ALIAS en las sentencias CREATE ALIAS y DROP ALIAS. ID de autorización y nombres de autorización Un ID de autorización es una serie de caracteres obtenida por el gestor de bases de datos cuando se establece una conexión entre el gestor de bases de datos y un proceso de aplicación o un proceso de preparación de programa. Designa un conjunto de privilegios. También puede designar a un usuario o a un grupo de usuarios, pero su propiedad no la controla el gestor de bases de datos. El gestor de bases de datos utiliza los ID de autorización para proporcionar: v El control de autorizaciones de sentencias de SQL v Un valor por omisión para la opción de precompilación/vinculación QUALIFIER y el registro especial CURRENT SCHEMA. También se incluye el ID de autorización en el registro especial CURRENT PATH por omisión y en la opción de precompilación/vinculación FUNCPATH. Se aplica un ID de autorización a cada sentencia de SQL. El ID de autorización que se aplica a una sentencia de SQL estático es el ID de autorización que se utiliza durante la vinculación de programas. El ID de autorización correspondiente a una sentencia de SQL dinámico se basa en la 78 Consulta de SQL, Volumen 1
- 105. opción DYNAMICRULES proporcionada durante el momento de la vinculación y en el entorno actual de ejecución del paquete que emite la sentencia de SQL dinámico: v En un paquete que tenga un comportamiento de vinculación, el ID de autorización utilizado es el ID de autorización del propietario del paquete. v En un paquete que tenga un comportamiento de definición, el ID de autorización utilizado es el ID de autorización correspondiente a la persona que define la rutina. v En un paquete que tenga un comportamiento de ejecución, el ID de autorización utilizado es el ID de autorización actual del usuario que ejecute el paquete. v En un paquete que tenga un comportamiento de invocación, el ID de autorización utilizado es el ID de autorización actualmente en vigor al invocar la rutina. Este ID se denomina ID de autorización de ejecución. Para obtener más información, consulte el apartado “Características de SQL dinámico durante la ejecución” en la página 80. Un nombre de autorización especificado en una sentencia de SQL no se debe confundir con el ID de autorización de la sentencia. Un nombre de autorización es un identificador que se utiliza en varias sentencias de SQL. Un nombre de autorización se utiliza en la sentencia CREATE SCHEMA para designar al propietario del esquema. Un nombre de autorización se utiliza en las sentencias GRANT y REVOKE para designar el destino de la operación de otorgamiento (grant) o revocación (revoke). Si se otorgan privilegios a X, esto significa que X (o un miembro del grupo X) será posteriormente el ID de autorización de las sentencias que necesiten dichos privilegios. Ejemplos: v Suponga que SMITH es el ID de usuario y el ID de autorización que el gestor de bases de datos ha obtenido al establecer una conexión con el proceso de aplicación. La siguiente sentencia se ejecuta interactivamente: GRANT SELECT ON TDEPT TO KEENE SMITH es el ID de autorización de la sentencia. Por lo tanto, en una sentencia de SQL dinámico, el valor por omisión del registro especial CURRENT SCHEMA será SMITH y, en SQL estático, el valor por omisión de la opción de precompilación/vinculación QUALIFIER será SMITH. La autorización para ejecutar la sentencia se compara con SMITH y SMITH es el calificador implícito de nombre-tabla de acuerdo con las reglas de calificación descritas en el apartado “Convenios de denominación y calificaciones de nombre de objeto explícitas” en la página 71. KEENE es un nombre de autorización especificado en la sentencia. Se otorga el privilegio SELECT en SMITH.TDEPT a KEENE. Capítulo 2. Elementos del lenguaje 79
- 106. v Suponga que SMITH tiene autorización de administración y es el ID de autorización de las siguientes sentencias de SQL dinámico sin que se emita ninguna sentencia SET SCHEMA durante la sesión: DROP TABLE TDEPT Elimina la tabla SMITH.TDEPT. DROP TABLE SMITH.TDEPT Elimina la tabla SMITH.TDEPT. DROP TABLE KEENE.TDEPT Elimina la tabla KEENE.TDEPT. Observe que KEENE.TDEPT y SMITH.TDEPT son tablas diferentes. CREATE SCHEMA PAYROLL AUTHORIZATION KEENE KEENE es el nombre de autorización especificado en la sentencia que crea un esquema denominado PAYROLL. KEENE es el propietario del esquema PAYROLL y se le otorgan los privilegios CREATEIN, ALTERIN y DROPIN, con la posibilidad de otorgarlos a otros. Características de SQL dinámico durante la ejecución La opción DYNAMICRULES BIND determina el ID de autorización que se utiliza para comprobar la autorización cuando se procesan sentencias de SQL dinámico. Además, la opción también controla otros atributos de SQL dinámico como, por ejemplo, el calificador implícito que se utiliza para las referencias a objetos no calificadas y si es posible invocar dinámicamente ciertas sentencias de SQL. El conjunto de valores para el ID de autorización y otros atributos de SQL dinámico se denomina el comportamiento de las sentencias de SQL dinámico. Los cuatro comportamientos posibles son ejecución, vinculación, definición e invocación. Tal como se muestra en la tabla siguiente, la combinación del valor de la opción DYNAMICRULES BIND y el entorno de ejecución determina el comportamiento que se utiliza. Es valor por omisión es DYNAMICRULES RUN, que implica un comportamiento de ejecución. Tabla 4. Forma en que DYNAMICRULES y el entorno de ejecución determinan el comportamiento de las sentencias de SQL dinámico Valor de DYNAMICRULES Comportamiento de las sentencias de SQL dinámico Entorno de programa Entorno de rutina autónomo BIND Comportamiento de Comportamiento de vinculación vinculación RUN Comportamiento de ejecución Comportamiento de ejecución 80 Consulta de SQL, Volumen 1
- 107. Tabla 4. Forma en que DYNAMICRULES y el entorno de ejecución determinan el comportamiento de las sentencias de SQL dinámico (continuación) Valor de DYNAMICRULES Comportamiento de las sentencias de SQL dinámico Entorno de programa Entorno de rutina autónomo DEFINEBIND Comportamiento de Comportamiento de definición vinculación DEFINERUN Comportamiento de ejecución Comportamiento de definición INVOKEBIND Comportamiento de Comportamiento de vinculación invocación INVOKERUN Comportamiento de ejecución Comportamiento de invocación Comportamiento de ejecución DB2 utiliza el ID de autorización del usuario (el ID que inicialmente se conectó a DB2) que ejecuta el paquete como el valor que se utilizará para la comprobación de autorización de las sentencias de SQL dinámico y para el valor inicial utilizado para la calificación implícita de las referencias a objetos no calificadas de las sentencias de SQL dinámico. Comportamiento de vinculación Durante la ejecución, DB2 utiliza todas las reglas que se aplican a SQL estático para la autorización y la calificación. Utiliza el ID de autorización del propietario del paquete como el valor que se utilizará para la comprobación de autorización de las sentencias de SQL dinámico y el calificador por omisión del paquete para la calificación implícita de las referencias a objetos no calificadas de las sentencias de SQL dinámico. Comportamiento de definición El comportamiento de definición sólo se aplica si la sentencia de SQL dinámico está en un paquete que se ejecuta en un contexto de rutina y el paquete se ha vinculado con DYNAMICRULES DEFINEBIND o DYNAMICRULES DEFINERUN. DB2 utiliza el ID de autorización de la persona que define la rutina (no de la que vincula el paquete de la rutina) como el valor que se utilizará para la comprobación de autorización de las Capítulo 2. Elementos del lenguaje 81
- 108. sentencias de SQL dinámico y para la calificación implícita de las referencias a objetos no calificadas de sentencias de SQL dinámico de dicha rutina. Comportamiento de invocación El comportamiento de invocación sólo se aplica si la sentencia de SQL dinámico está en un paquete que se ejecuta en un contexto de rutina y el paquete se ha vinculado con DYNAMICRULES INVOKEBIND o DYNAMICRULES INVOKERUN. DB2 utiliza el ID de autorización de la sentencia en vigor cuando se invoca la rutina como el valor que se utilizará para la comprobación de autorización de SQL dinámico y para la calificación implícita de las referencias a objetos no calificadas de sentencias de SQL dinámico de dicha rutina. La tabla siguiente muestra un resumen. Entorno que se invoca ID utilizado Cualquier SQL estático Valor implícito o explícito del propietario (OWNER) del paquete del que procedía el SQL que invocaba la rutina Utilizado en definiciones de vistas o Persona que define la vista o el activador activadores SQL dinámico de un paquete con Valor implícito o explícito del propietario comportamiento de vinculación (OWNER) del paquete del que procedía el SQL que invocaba la rutina SQL dinámico de un paquete con ID utilizado para efectuar la conexión inicial a comportamiento de ejecución DB2 SQL dinámico de un paquete con Persona que define la rutina que utiliza el comportamiento de definición paquete del que procedía el SQL que invocaba la rutina SQL dinámico de un paquete con El ID autorización actual que invoca la rutina comportamiento de invocación Sentencias restringidas cuando no se aplica el comportamiento de ejecución Cuando está en vigor un comportamiento de vinculación, definición o invocación, no es posible utilizar las siguientes sentencias de SQL dinámico: GRANT, REVOKE, ALTER, CREATE, DROP, COMMENT, RENAME, SET INTEGRITY, SET EVENT MONITOR STATE; o consultas que hacen referencia a un apodo. 82 Consulta de SQL, Volumen 1
- 109. Consideraciones respecto a la opción DYNAMICRULES No se puede utilizar el registro especial CURRENT SCHEMA para calificar las referencias a objetos no calificadas en las sentencias de SQL dinámico ejecutadas desde un paquete con comportamiento de vinculación, definición o invocación. Esto es así incluso después de emitir la sentencia SET CURRENT SCHEMA para cambiar el registro especial CURRENT SCHEMA; el valor del registro se cambia pero no se utiliza. En caso de que se haga referencia a varios paquetes durante una sola conexión, todas las sentencias de SQL dinámico que estos paquetes hayan preparado mostrarán el comportamiento especificado por la opción DYNAMICRULES para dicho paquete en concreto y el entorno en el que se utilicen. Es importante tener presente que, cuando un paquete muestra un comportamiento de vinculación, no debe otorgarse a la persona que vincula el paquete ninguna autorización que no se desee que tenga el usuario del paquete ya que una sentencia dinámica utilizará el ID de autorización del propietario del paquete. De forma similar, cuando un paquete muestra un comportamiento de definición, no debe otorgarse a la persona que define la rutina ninguna autorización que no se desee que tenga el usuario del paquete. ID de autorización y preparación de sentencias Si se especifica la opción VALIDATE BIND durante la ejecución, los privilegios necesarios para manejar tablas y vistas también deben existir durante la vinculación. Si estos privilegios o los objetos referenciados no existen y está en vigor la opción SQLERROR NOPACKAGE, la operación de vinculación no será satisfactoria. Si se especifica la opción SQLERROR CONTINUE, la operación de vinculación será satisfactoria y se marcarán las sentencias erróneas. Si se intenta ejecutar una de estas sentencias, se producirá un error. Si un paquete se vincula con la opción VALIDATE RUN, se realiza todo el proceso normal de vinculación, pero no es necesario que existan todavía los privilegios necesarios para utilizar las tablas y vistas referenciadas en la aplicación. Si durante la vinculación no existe un privilegio necesario, se realiza una operación de vinculación incremental cada vez que se ejecuta por primera vez la sentencia en una aplicación y deben existir todos los privilegios que la sentencia necesita. Si no existe un privilegio necesario, la ejecución de la sentencia no es satisfactoria. La comprobación de autorización durante la ejecución se realiza utilizando el ID de autorización del propietario del paquete. Capítulo 2. Elementos del lenguaje 83
- 110. Nombres de columna El significado de un nombre de columna depende de su contexto. Un nombre de columna sirve para: v Declarar el nombre de una columna como, por ejemplo, en una sentencia CREATE TABLE. v Identificar una columna como, por ejemplo, en una sentencia CREATE INDEX. v Especificar los valores de la columna como, por ejemplo, en los contextos siguientes: – En una función de columna, un nombre de columna especifica todos los valores de la columna en la tabla de resultado intermedia o de grupo a los que se aplica la función. Por ejemplo, MAX(SALARY) aplica la función MAX a todos los valores de la columna SALARY de un grupo. – En una cláusula GROUP BY o ORDER BY, un nombre de columna especifica todos los valores de la tabla de resultado intermedia a los que se aplica la cláusula. Por ejemplo, ORDER BY DEPT ordena una tabla de resultado intermedia según los valores de la columna DEPT. – En una expresión, una condición de búsqueda o una función escalar, un nombre de columna especifica un valor para cada fila o grupo al que se aplica la construcción. Por ejemplo, cuando la condición de búsqueda CODE = 20 se aplica a alguna fila, el valor especificado por el nombre de columna CODE es el valor de la columna CODE en esa fila. v Redenominar temporalmente una columna, como en la cláusula-correlación de una referencia-tabla en una cláusula FROM. Nombre de columna calificados Un calificador para un nombre de columna puede ser un nombre de tabla, vista, apodo o seudónimo o un nombre de correlación. El hecho de que un nombre de columna pueda calificarse depende del contexto: v Según la forma de la sentencia COMMENT ON, puede que se deba calificar un nombre de una sola columna. No se deben calificar nombres de varias columnas. v Donde el nombre de columna especifique valores de la columna, puede calificarse como opción del usuario. v En la cláusula de asignación de una sentencia UPDATE, puede calificarse en la opción del usuario. v En todos los demás contextos, un nombre de columna no debe calificarse. Cuando un calificador es opcional, puede cumplir dos finalidades. Estos casos se describen en el apartado “Calificadores de nombres de columna para evitar 84 Consulta de SQL, Volumen 1
- 111. ambigüedades” en la página 87 y “Calificadores de nombres de columna en referencias correlacionadas” en la página 89. Nombres de correlación Un nombre de correlación puede definirse en la cláusula FROM de una consulta y en la primera cláusula de una sentencia UPDATE o DELETE. Por ejemplo, la cláusula FROM X.MYTABLE Z establece Z como nombre de correlación para X.MYTABLE. FROM X.MYTABLE Z Con Z definida como nombre de correlación para X.MYTABLE, sólo puede utilizarse Z para calificar una referencia a una columna de esa instancia de X.MYTABLE en esa sentencia SELECT. Un nombre de correlación sólo se asocia a una tabla, vista, apodo, seudónimo, expresión de tabla anidada o función de tabla sólo dentro del contexto en el que está definido. Por lo tanto, puede definirse el mismo nombre de correlación con distintos propósitos en diferentes sentencias o bien en distintas cláusulas de la misma sentencia. Como calificador, un nombre de correlación puede utilizarse para evitar ambigüedades o para establecer una referencia correlacionada. También puede utilizarse simplemente como nombre abreviado de una tabla, vista, apodo o seudónimo. En el caso de una expresión de tabla anidada o una función de tabla, es necesario un nombre de correlación para identificar la tabla resultante. En el ejemplo, Z podría haberse utilizado simplemente para evitar tener que entrar X.MYTABLE más de una vez. Si se especifica un nombre de correlación para una tabla, vista, apodo o seudónimo, cualquier referencia a una columna de esa instancia de la tabla, vista, apodo o seudónimo debe utilizar el nombre de correlación en lugar del nombre de tabla, vista, apodo o seudónimo. Por ejemplo, la referencia a EMPLOYEE.PROJECT del ejemplo siguiente no es correcto, porque se ha especificado un nombre de correlación para EMPLOYEE: Ejemplo FROM EMPLOYEE E WHERE EMPLOYEE.PROJECT=’ABC’ * incorrecto* La referencia calificada para PROJECT debe utilizar, en su lugar, el nombre de correlación ″E″, tal como se muestra abajo: FROM EMPLOYEE E WHERE E.PROJECT=’ABC’ Capítulo 2. Elementos del lenguaje 85
- 112. Los nombres especificados en una cláusula FROM pueden estar expuestos o no expuestos. Se dice que un nombre de tabla, vista, apodo o seudónimo está expuesto en la cláusula FROM si no se especifica un nombre de correlación. El nombre de la correlación es siempre un nombre expuesto. Por ejemplo, en la siguiente cláusula FROM, se especifica un nombre de correlación para EMPLOYEE pero no para DEPARTMENT, de modo que DEPARTMENT es un nombre expuesto y EMPLOYEE no lo es: FROM EMPLOYEE E, DEPARTMENT Un nombre de tabla, vista, apodo o seudónimo que está expuesto en una cláusula FROM puede ser igual que otro nombre de tabla, vista o apodo expuesto en esa cláusula FROM o cualquier nombre de correlación de la cláusula FROM. Esta situación puede dar como resultado una serie de referencias ambiguas de nombres de columna que acaban devolviendo un código de error (SQLSTATE 42702). Las dos primeras cláusulas FROM mostradas más abajo son correctas, porque cada una no contiene más de una referencia a EMPLOYEE que esté expuesta: 1. Dada una cláusula FROM: FROM EMPLOYEE E1, EMPLOYEE una referencia calificada como, por ejemplo, EMPLOYEE.PROJECT indica una columna de la segunda instancia de EMPLOYEE en la cláusula FROM. La referencia calificada a la primera instancia de EMPLOYEE debe utilizar el nombre de correlación “E1” (E1.PROJECT). 2. Dada una cláusula FROM: FROM EMPLOYEE, EMPLOYEE E2 una referencia calificada como, por ejemplo, EMPOYEE.PROJECT indica una columna de la primera instancia de EMPLOYEE en la cláusula FROM. Una referencia calificada a la segunda instancia de EMPLOYEE debe utilizar el nombre de correlación “E2” (E2.PROJECT). 3. Dada una cláusula FROM: FROM EMPLOYEE, EMPLOYEE los dos nombres de tabla expuestos que se incluyen en esta cláusula (EMPLOYEE y EMPLOYEE) son los mismos. Esto está permitido, pero las referencias a nombres de columnas específicos resultarían ambiguas (SQLSTATE 42702). 4. Dada la sentencia siguiente: SELECT * FROM EMPLOYEE E1, EMPLOYEE E2 * incorrecto * WHERE EMPLOYEE.PROJECT = ’ABC’ 86 Consulta de SQL, Volumen 1
- 113. la referencia calificada EMPLOYEE.PROJECT es incorrecta, porque las dos instancias de EMPLOYEE en la cláusula FROM tienen nombres de correlación. En cambio, las referencias a PROJECT deben estar calificadas con algún nombre de correlación (E1.PROJECT o E2.PROJECT). 5. Dada una cláusula FROM: FROM EMPLOYEE, X.EMPLOYEE una referencia a una columna en la segunda instancia de EMPLOYEE debe utilizar X.EMPLPYEE (X.EMPLOYEE.PROJECT). Si X es el valor del registro especial CURRENT SCHEMA en SQL dinámico o la opción de precompilación/vinculación QUALIFIER de SQL estático, no se puede hacer ninguna referencia a las columnas porque resultaría ambigua. La utilización del nombre de correlación en la cláusula FROM permite, también, la opción de especificar una lista de nombres de columna que se han de asociar con las columnas de la tabla resultante. Igual que los nombres de correlación, estos nombres de columna listados se convierten en los nombres expuestos de las columnas que deben utilizarse en las referencias a las columnas en toda la consulta. Si se especifica una lista de nombres de columna, los nombres de columna de la tabla principal se convierten en no expuestos. Dada una cláusula FROM: FROM DEPARTMENT D (NUM,NAME,MGR,ANUM,LOC) una referencia calificada como, por ejemplo, D.NUM indica la primera columna de la tabla DEPARTMENT que se ha definido en la tabla como DEPTNO. Una referencia a D.DEPTNO utilizando esta cláusula FROM es incorrecta ya que el nombre de columna DEPTNO es un nombre de columna no expuesto. Calificadores de nombres de columna para evitar ambigüedades En el contexto de una función, de una cláusula GROUP BY, de una cláusula ORDER BY, de una expresión o de una condición de búsqueda, un nombre de columna hace referencia a los valores de una columna en alguna tabla, vista, apodo, expresión de tabla anidada o función de tabla. Las tablas, vistas, apodos, expresiones de tablas anidadas y funciones de tabla donde puede residir la columna se denominan tablas de objetos del contexto. Dos o más tablas de objetos pueden contener columnas con el mismo nombre; un nombre de columna se puede calificar para indicar la tabla de la cual procede la columna. Los calificadores de nombres de columna también son útiles en los procedimientos de SQL para diferenciar los nombres de columna de los nombres de variables de SQL utilizados en sentencias de SQL. Capítulo 2. Elementos del lenguaje 87
- 114. Una expresión de tabla anidada o una función de tabla trata las referencias-tabla que la preceden en la cláusula FROM como tablas de objetos. Las referencias-tabla que siguen no se tratan como tablas de objetos. Designadores de tablas: Un calificador que designa una tabla de objeto específica se conoce como designador de tabla. La cláusula que identifica las tablas de objetos también establece los designadores de tabla para ellas. Por ejemplo, las tablas de objetos de una expresión en una cláusula SELECT se nombran en la cláusula FROM que la sigue: SELECT CORZ.COLA, OWNY.MYTABLE.COLA FROM OWNX.MYTABLE CORZ, OWNY.MYTABLE Los designadores en la cláusula FROM se establecen como sigue: v Un nombre que sigue a una tabla, vista, apodo, seudónimo, expresión de tabla anidada o función de tabla es a la vez un nombre de correlación y un designador de tabla. Así pues, CORZ es un designador de tabla. CORZ sirve para calificar el primer nombre de columna de la lista de selección. v Una tabla expuesta, un nombre de vista, un apodo o seudónimo es un designador de tabla. Así pues, OWNY.MYTABLE es un designador de tabla. OWNY.MYTABLE sirve para calificar el nombre de la segunda columna de la lista de selección. Cada designador de tabla debe ser exclusivo en una cláusula FROM determinada para evitar la aparición de referencias ambiguas a columnas. Evitar referencias no definidas o ambiguas: Cuando un nombre de columna hace referencia a valores de una columna, debe existir una sola tabla de objetos que incluya una columna con ese nombre. Las situaciones siguientes se consideran errores: v Ninguna tabla de objetos contiene una columna con el nombre especificado. La referencia no está definida. v El nombre de columna está calificado mediante un designador de tabla, pero la tabla designada no incluye una columna con el nombre especificado. De nuevo, la referencia no está definida. v El nombre no está calificado, y hay más de una tabla de objetos que incluye una columna con ese nombre. La referencia es ambigua. v El designador de tabla califica al nombre de columna, pero la tabla designada no es única en la cláusula FROM y ambas ocurrencias de la tabla designada incluyen la columna. La referencia es ambigua. v El nombre de columna de una expresión de tabla anidada que no va precedida por la palabra clave TABLE o en una función de tabla o expresión de tabla anidada que es el operando derecho de una unión externa derecha o una unión externa completa y el nombre de columna no 88 Consulta de SQL, Volumen 1
- 115. hace referencia a una columna de una referencia-tabla de la selección completa de la expresión de tabla anidada. La referencia no está definida. Evite las referencias ambiguas calificando un nombre de columna con un designador de tabla definido exclusivamente. Si la columna está en varias tablas de objetos con nombres distintos, los nombres de tabla pueden utilizarse como designadores. Las referencias ambiguas también se pueden evitar sin la utilización del designador de tabla dando nombres exclusivos a las columnas de una de las tablas de objetos utilizando la lista de nombres de columna que siguen al nombre de correlación. Al calificar una columna con la forma de nombre expuesto de tabla de un designador de tabla, se puede utilizar la forma calificada o no calificada del nombre de tabla expuesto. Sin embargo, el calificador y la tabla utilizados deben ser iguales después de calificar completamente el nombre de tabla, vista o apodo y el designador de tabla. 1. Si el ID de autorización de la sentencia es CORPDATA: SELECT CORPDATA.EMPLOYEE.WORKDEPT FROM EMPLOYEE es una sentencia válida. 2. Si el ID de autorización de la sentencia es REGION: SELECT CORPDATA.EMPLOYEE.WORKDEPT FROM EMPLOYEE * incorrecto * no es válido, porque EMPLOYEE representa la tabla REGION.EMPLOYEE, pero el calificador para WORKDEPT representa una tabla distinta, CORPDATA.EMPLOYEE. Calificadores de nombres de columna en referencias correlacionadas Una selección completa es una forma de consulta que puede utilizarse como componente de varias sentencias de SQL. Una selección completa utilizada en una condición de búsqueda de cualquier sentencia se denomina subconsulta. Una selección completa utilizada para recuperar un único valor como, por ejemplo, una expresión en una sentencia se denomina una selección completa escalar o subconsulta escalar. Una selección completa utilizada en la cláusula FROM de una consulta se denomina expresión de tabla anidada. Se hace referencia a las subconsultas de las condiciones de búsqueda, subconsultas escalares y expresiones de tabla anidadas como subconsultas en el resto de este tema. Una subconsulta puede contener subconsultas propias y éstas, a su vez, pueden contener subconsultas. De este modo, una sentencia de SQL puede contener una jerarquía de subconsultas. Los elementos de la jerarquía que contienen subconsultas están en un nivel superior que las subconsultas que contienen. Capítulo 2. Elementos del lenguaje 89
- 116. Cada elemento de la jerarquía contiene uno o más designadores de tabla. Una consulta puede hacer referencia no solamente a las columnas de las tablas identificadas en su mismo nivel dentro de la jerarquía, sino también a las columnas de las tablas anteriormente identificadas en la jerarquía, hasta alcanzar el estrato más elevado. Una referencia a una columna de una tabla identificada en un nivel superior se llama referencia correlacionada. Para la compatibilidad con los estándares existentes de SQL, se permiten nombres de columna calificados y no calificados como referencias correlacionadas. Sin embargo, es aconsejable calificar todas las referencias de columnas utilizadas en subconsultas; de lo contrario, los nombres de columna idénticos pueden conducir a resultados no deseados. Por ejemplo, si se modifica una tabla de una jerarquía de modo que contenga el mismo nombre de columna que la referencia correlacionada y la sentencia se vuelve a preparar, la referencia se aplicará en la tabla modificada. Cuando se califica un nombre de columna en una subconsulta, se busca en cada nivel de jerarquía, comenzando en la misma subconsulta en la que aparece el nombre de columna calificado y continuando hacia niveles superiores de la jerarquía, hasta que se encuentre un designador de tabla que coincida con el calificador. Una vez encontrado, se verifica que la tabla contenga la columna en cuestión. Si se encuentra la tabla en un nivel superior que el nivel que contiene el nombre de columna, es que éste es una referencia correlacionada para el nivel donde se encontró el designador de tabla. Una expresión de tabla anidada debe ir precedida por la palabra clave TABLE opcional para buscar en la jerarquía superior la selección completa de la expresión de tabla anidada. Cuando el nombre de columna de una subconsulta no se califica, se busca en las tablas a las que se hace referencia en cada nivel de la jerarquía, empezando en la misma subconsulta en la que aparece el nombre de columna y siguiendo hacia niveles superiores de la jerarquía hasta que se encuentre un nombre de columna que coincida. Si la columna se encuentra en una tabla en un nivel superior al nivel que contiene el nombre de columna, es que éste es una referencia correlacionada para el nivel donde se ha encontrado la tabla que contiene la columna. Si se encuentra el nombre de columna en más de una tabla en un nivel en concreto, la referencia es ambigua y se considera un error. En cualquier caso, en el siguiente ejemplo T hace referencia al designador de tabla que contiene la columna C. Un nombre de columna, T.C (donde T representa un calificador implícito o explícito), es una referencia correlacionada solamente si se dan estas condiciones: v T.C se utiliza en una expresión de una subconsulta. v T no designa una tabla utilizada en la cláusula de la subconsulta. 90 Consulta de SQL, Volumen 1
- 117. v T designa una tabla utilizada en un nivel superior de la jerarquía que contiene la subconsulta. Debido a que una misma tabla, vista o apodo pueden estar identificados en muchos niveles, se recomienda utilizar nombres de correlación exclusivos como designadores de tabla. Si se utiliza T para designar una tabla en más de un nivel (T es el propio nombre de tabla o es un nombre de correlación duplicado), T.C hace referencia al nivel donde se utiliza T que contiene de forma más directa la subconsulta que incluye T.C. Si es necesario un nivel de correlación superior, debe utilizarse un nombre de correlación exclusivo. La referencia correlacionada T.C identifica un valor de C en una fila o grupo de T a la que se aplican dos condiciones de búsqueda: la condición 1 en la subconsulta, y la condición 2 en algún nivel superior. Si se utiliza la condición 2 en una cláusula WHERE, se evalúa la subconsulta para cada fila a la que se aplica la condición 2. Si se utiliza la condición 2 en una cláusula HAVING, se evalúa la subconsulta para cada grupo al que se aplica la condición 2. Por ejemplo, en la sentencia siguiente, la referencia correlacionada X.WORKDEPT (en la última línea) hace referencia al valor de WORKDEPT en la tabla EMPLOYEE en el nivel de la primera cláusula FROM. (Dicha cláusula establece X como nombre de correlación para EMPLOYEE.) La sentencia lista los empleados que tienen un salario inferior al promedio de su departamento. SELECT EMPNO, LASTNAME, WORKDEPT FROM EMPLOYEE X WHERE SALARY < (SELECT AVG(SALARY) FROM EMPLOYEE WHERE WORKDEPT = X.WORKDEPT) El ejemplo siguiente utiliza ESTE como nombre de correlación. La sentencia elimina las filas de los departamentos que no tienen empleados. DELETE FROM DEPARTMENT THIS WHERE NOT EXISTS(SELECT * FROM EMPLOYEE WHERE WORKDEPT = ESTE.DEPTNO) Referencias a variables del lenguaje principal Una variable del lenguaje principal es: v Una variable de un lenguaje principal como por ejemplo, una variable C, una variable C++, un elemento de datos COBOL, una variable FORTRAN o una variable Java o: v Una construcción del lenguaje principal generada por un precompilador de SQL a partir de una variable declarada mediante extensiones de SQL Capítulo 2. Elementos del lenguaje 91
- 118. a la que se hace referencia en una sentencia de SQL. Las variables de lenguaje principal se definen directamente mediante las sentencias del lenguaje principal o indirectamente mediante extensiones de SQL. Una variable del lenguaje principal en una sentencia de SQL debe identificar una variable del lenguaje principal descrita en el programa según las normas para la declaración de variables del lenguaje principal. Todas las variables del lenguaje principal utilizadas en una sentencia de SQL deben estar declaradas en una sección DECLARE de SQL en todos los lenguajes principales excepto en REXX. No se debe declarar ninguna variable fuera de una sección DECLARE de SQL con nombres que sean idénticos a variables declaradas en una sección DECLARE de SQL. Una sección DECLARE de SQL empieza por BEGIN DECLARE SECTION y termina por END DECLARE SECTION. La metavariable variable-lengprinc, tal como se utiliza en los diagramas de sintaxis, muestra una referencia a una variable del lenguaje principal. Una variable de lenguaje principal en la cláusula VALUES INTO o en la cláusula INTO de una sentencia FETCH o SELECT INTO, identifica una variable de lenguaje principal a la que se asigna un valor procedente de una columna de una fila o una expresión. En todos los demás contextos, una variable-lengprinc especifica un valor que ha de pasarse al gestor de bases de datos desde el programa de aplicación. variables del lenguaje principal en SQL dinámico En sentencias de SQL dinámico, se utilizan los marcadores de parámetros en lugar de las variables del lenguaje principal. Un marcador de parámetros es un signo de interrogación (?) que representa una posición en una sentencia de SQL dinámico en la que la aplicación proporcionará un valor; es decir, donde se encontrará una variable de lenguaje principal si la serie de la sentencia es una sentencia de SQL estático. El siguiente ejemplo muestra una sentencia de SQL estático que emplea variables de lenguaje principal: INSERT INTO DEPARTMENT VALUES (:hv_deptno, :hv_deptname, :hv_mgrno, :hv_admrdept) Este ejemplo muestra una sentencia de SQL dinámico que utiliza marcadores de parámetros: INSERT INTO DEPARTMENT VALUES (?, ?, ?, ?) Generalmente, la metavariable variable-lengprinc se puede expandir en los diagramas de sintaxis a: :identificador-lengprinc INDICATOR :identificador-lengprinc 92 Consulta de SQL, Volumen 1
- 119. Cada identificador-lengprinc debe declararse en el programa fuente. La variable designada por el segundo identificador-lengprinc debe tener un tipo de datos de entero pequeño. El primer identificador-lengprinc designa la variable principal. Según la operación, proporciona un valor al gestor de bases de datos o bien el gestor de bases de datos le proporciona un valor. Una variable del lenguaje principal de entrada proporciona un valor en la página de códigos de la aplicación en tiempo de ejecución. A la variable del lenguaje principal de salida se le proporciona un valor que, si es necesario, se convierte a la página de códigos de la aplicación en tiempo de ejecución cuando los datos se copian en la variable de la aplicación de salida. Una variable del lenguaje principal determinada puede servir tanto de variable de entrada como de salida en el mismo programa. El segundo identificador-lengprinc designa su variable indicadora. La finalidad de la variable indicadora es: v Especificar el valor nulo. Un valor negativo de la variable indicadora especifica el valor nulo. Un valor de -2 indica una conversión numérica o un error de expresión aritmética ocurrido al obtener el resultado v Registra la longitud original de una serie truncada (si la fuente del valor no es un tipo de gran objeto) v Registra la parte correspondiente a los segundos de una hora si la hora se trunca al asignarse a una variable del lenguaje principal. Por ejemplo, si se utiliza :HV1:HV2 para especificar un valor de inserción o de actualización y si HV2 es negativo, el valor especificado es el valor nulo. Si HV2 no es negativo, el valor especificado es el valor de HV1. Del mismo modo, si se especifica :HV1:HV2 en una cláusula VALUES INTO o en una sentencia FETCH o SELECT INTO y si el valor devuelto es nulo, HV1 no se cambia y HV2 se establece en un valor negativo. Si la base de datos está configurada con DFT_SQLMATHWARN definido en sí (o lo estaba durante la vinculación de una sentencia de SQL estático), HV2 podría ser -2. Si HV2 es -2, no podría devolverse un valor para HV1 debido a un error en la conversión al tipo numérico de HV1 o a un error al evaluar una expresión aritmética utilizada para determinar el valor de HV1. Cuando se accede a una base de datos con una versión cliente anterior a DB2 Universal Database Versión 5, HV2 será -1 para las excepciones aritméticas. Si el valor devuelto no es nulo, se asigna dicho valor a HV1 y HV2 se establece en cero (a no ser que la asignación a HV1 necesite el truncamiento de una serie que sea no LOB, en cuyo caso HV2 se establece en la longitud original de la serie). Si una asignación necesita el truncamiento de la parte correspondiente a los segundos de una hora, HV2 se establece en el número de segundos. Capítulo 2. Elementos del lenguaje 93
- 120. Si se omite el segundo identificador del lenguaje principal, la variable de lenguaje principal carece de variable indicadora. El valor especificado por la referencia a la variable del lenguaje principal :HV1 siempre es el valor de HV1 y los valores nulos no se pueden asignar a la variable. Por este motivo, esta forma no debe utilizarse en una cláusula INTO a no ser que la columna correspondiente no pueda incluir valores nulos. Si se utiliza esta forma y la columna contiene valores nulos, el gestor de bases de datos generará un error en tiempo de ejecución. Una sentencia de SQL que haga referencia a variables de lenguaje principal debe pertenecer al ámbito de la declaración de esas variables de lenguaje principal. En cuanto a las variables a las que la sentencia SELECT del cursor hace referencia, esa regla se aplica más a la sentencia OPEN que a la sentencia DECLARE CURSOR. Ejemplo: Utilizando la tabla PROJECT, asigne a la variable de lenguaje principal PNAME (VARCHAR(26)) el nombre de proyecto (PROJNAME), a la variable de lenguaje principal STAFF (dec(5,2)) el nivel principal de personal (PRSTAFF) y a la variable de lenguaje principal MAJPROJ (char(6)) el proyecto principal (MAJPROJ) para el proyecto (PROJNO) ‘IF1000’. Las columnas PRSTAFF y MAJPROJ pueden contener valores nulos, por lo tanto proporcione las variables indicadoras STAFF_IND (smallint) y MAJPROJ_IND (smallint). SELECT PROJNAME, PRSTAFF, MAJPROJ INTO :PNAME, :STAFF :STAFF_IND, :MAJPROJ :MAJPROJ_IND FROM PROJECT WHERE PROJNO = ’IF1000’ Consideraciones acerca de MBCS: Si es o no es posible utilizar los caracteres de múltiples bytes en un nombre de variable del lenguaje principal depende del lenguaje principal. Referencias a las variables del lenguaje principal de BLOB, CLOB y DBCLOB Las variables regulares BLOB, CLOB y DBCLOB, las variables localizadoras LOB (consulte “Referencias a variables localizadoras” en la página 95), y las variables de referencia a archivos LOB (consulte “Referencias a las variables de referencia de archivos BLOB, CLOB y DBCLOB” en la página 96) se pueden definir en todos los lenguajes principales. Donde se pueden utilizar valores LOB, el término variable-lengprinc en un diagrama de sintaxis puede hacer referencia a una variable de lenguaje principal normal, a una variable localizadora o a una variable de referencia a archivos. Puesto que no son tipos de datos nativos, se utilizan las extensiones SQL y los precompiladores generan las construcciones de lenguaje principal necesarias para poder representar a cada variable. En cuanto a REXX, las variables LOB se correlacionan con series. 94 Consulta de SQL, Volumen 1
- 121. A veces es posible definir una variable lo suficientemente grande como para contener todo un valor de gran objeto. Si es así y no hay ninguna ventaja de rendimiento si se utiliza la transferencia diferida de datos desde el servidor, no es necesario un localizador. No obstante, puesto que el lenguaje principal o las restricciones de espacio se oponen al almacenamiento de un gran objeto entero en el almacenamiento temporal de una vez o por motivos de rendimiento, se puede hacer referencia a un gran objeto por medio de un localizador y las partes de dicho objeto se pueden seleccionar o actualizar en las variables de lenguaje principal que contengan sólo una parte del gran objeto. Como sucede con el resto de variables de lenguaje principal, una variable localizadora de LOB puede tener asociada una variable indicadora. Las variables indicadoras para las variables de lenguaje principal de localizador de gran objeto funcionan de la misma manera que las variables de indicador de otros tipos de datos. Cuando una base de datos devuelve un valor nulo, se define la variable indicadora y la variable localizadora de lenguaje principal no se cambia. Esto significa que un localizador jamás puede apuntar a un valor nulo. Referencias a variables localizadoras Una variable localizadora es una variable del lenguaje principal que contiene el localizador que representa un valor de LOB en el servidor de aplicaciones. Una variable localizadora de una sentencia de SQL debe identificar una variable localizadora descrita en el programa de acuerdo a las reglas de declaración de variables localizadoras. Siempre se produce indirectamente a través de una sentencia de SQL. El término variable localizadora, tal como se utiliza en los diagramas de sintaxis, muestra una referencia a una variable localizadora. La metavariable variable-localizadora puede expandirse para que incluya un identificador-lengprinc igual que para la variable-lengprinc. Cuando la variable de indicador asociada con un localizador es nula, el valor del LOB al que se hace referencia también es nulo. Si se hace referencia a una variable localizadora que en ese momento no represente ningún valor, se producirá un error (SQLSTATE 0F001). Durante la confirmación de la transacción, o en cualquier finalización de transacción, se liberan todos los localizadores que la transacción había adquirido. Capítulo 2. Elementos del lenguaje 95
- 122. Referencias a las variables de referencia de archivos BLOB, CLOB y DBCLOB Las variables de referencia a archivos BLOB, CLOB y DBCLOB sirven para la entrada y salida directa de archivo para los LOB y pueden definirse en todos los lenguajes principales. Puesto que no son tipos de datos nativos, se utilizan las extensiones SQL y los precompiladores generan las construcciones de lenguaje principal necesarias para poder representar a cada variable. En cuanto a REXX, las variables LOB se correlacionan con series. Una variable de referencia a archivos representa (más que contiene) al archivo, de igual manera que un localizador de LOB representa, más que contiene, a los bytes LOB. Las consultas, actualizaciones e inserciones pueden utilizar variables de referencia a archivos para almacenar o recuperar valores de una sola columna. Una variable de referencia a archivos tiene las siguientes propiedades: Tipo de datos BLOB, CLOB o DBCLOB. Esta propiedad se especifica al declarar la variable. Dirección La dirección debe ser especificada por el programa de aplicación durante la ejecución (como parte del valor de Opciones de archivo). La dirección puede ser: v De entrada (se utiliza como fuente de datos en las sentencias EXECUTE, OPEN, UPDATE, INSERT o DELETE). v De salida (se utiliza como datos de destino en sentencias las FETCH o SELECT INTO). Nombre del archivo Debe especificarlo el programa de aplicación en tiempo de ejecución. Puede ser: v El nombre completo de la vía de acceso de un archivo (opción que se recomienda). v Un nombre de archivo relativo. Si se proporciona un nombre de archivo relativo, se añade a la vía de acceso actual del proceso cliente. En una aplicación, sólo debe hacerse referencia a un archivo en una variable de referencia a archivos. Longitud del nombre de archivo Debe especificarlo el programa de aplicación en tiempo de ejecución. Es la longitud del nombre de archivo (en bytes). 96 Consulta de SQL, Volumen 1
- 123. Opciones de archivo Una aplicación debe asignar una las opciones a una variable de referencia a archivos antes de utilizar dicha variable. Las opciones se establecen mediante un valor INTEGER en un campo de la estructura de la variable de referencia a archivos. Se debe especificar alguna de estas opciones para cada variable de referencia a archivos: v Entrada (de cliente a servidor) SQL_FILE_READ Archivo regular que se puede abrir, leer y cerrar. (La opción es SQL-FILE-READ en COBOL, sql_file_read en FORTRAN y READ en REXX.) v Salida (de servidor a cliente) SQL_FILE_CREATE Crear un nuevo archivo. Si el archivo ya existe, se devuelve un error. (La opción es SQL-FILE-CREATE en COBOL, sql_file_create en FORTRAN y CREATE en REXX.) SQL_FILE_OVERWRITE (sobreescribir) Si ya existe un archivo con el nombre especificado, se sobreescribe el contenido del archivo; de lo contrario, se crea un nuevo archivo.(La opción es SQL-FILE-OVERWRITE en COBOL, sql_file_overwrite en FORTRAN y OVERWRITE en REXX.) SQL_FILE_APPEND Si ya existe un archivo con el nombre especificado, la salida se añade a éste; de lo contrario, se crea un nuevo Capítulo 2. Elementos del lenguaje 97
- 124. archivo. (La opción es SQL-FILE-APPEND en COBOL, sql_file_append en FORTRAN y APPEND en REXX.) Longitud de datos No se utiliza en la entrada. En la salida, la implantación establece la longitud de datos en la longitud de los nuevos datos grabados en el archivo. La longitud se mide en bytes. Como sucede con el resto de variables del lenguaje principal, una variable de referencia a archivos puede tener asociada una variable de indicador. Ejemplo de una variable de referencia a archivos de salida (en C): Suponga una sección de declaración codificada como: EXEC SQL BEGIN DECLARE SECTION SQL TYPE IS CLOB_FILE hv_text_file; char hv_patent_title[64]; EXEC SQL END DECLARE SECTION Una vez procesada: EXEC SQL BEGIN DECLARE SECTION /* SQL TYPE IS CLOB_FILE hv_text_file; */ struct { unsigned long name_length; // Longitud del nombre del archivo unsigned long data_length; // Longitud de datos unsigned long file_options; // Opciones de archivo char name[255]; // Nombre del archivo } hv_text_file; char hv_patent_title[64]; EXEC SQL END DECLARE SECTION El código siguiente puede utilizarse para seleccionar en una columna CLOB de la base de datos para un nuevo archivo al que :hv_text_file hace referencia. strcpy(hv_text_file.name, "/u/gainer/papers/sigmod.94"); hv_text_file.name_length = strlen("/u/gainer/papers/sigmod.94"); hv_text_file.file_options = SQL_FILE_CREATE; EXEC SQL SELECT content INTO :hv_text_file from papers WHERE TITLE = ’The Relational Theory behind Juggling’; Ejemplo de una variable de referencia a archivos de entrada (en C): Tomando la misma sección de declaración que antes, se puede utilizar el siguiente código para insertar datos de un archivo normal al que :hv_text_file hace referencia en una columna CLOB. 98 Consulta de SQL, Volumen 1
- 125. strcpy(hv_text_file.name, "/u/gainer/patents/chips.13"); hv_text_file.name_length = strlen("/u/gainer/patents/chips.13"); hv_text_file.file_options = SQL_FILE_READ: strcpy(:hv_patent_title, "A Method for Pipelining Chip Consumption"); EXEC SQL INSERT INTO patents( title, text ) VALUES(:hv_patent_title, :hv_text_file); Referencias a variables de lenguaje principal de tipo estructurado Las variables de tipo estructurado se pueden definir en todos los lenguajes principales, excepto FORTRAN, REXX y Java. Puesto que no son tipos de datos nativos, se utilizan las extensiones SQL y los precompiladores generan las construcciones de lenguaje principal necesarias para poder representar a cada variable. Al igual que en todas las demás variables de lenguaje principal, una variable de tipo estructurado puede tener una variable indicadora asociada. Las variables indicadoras correspondientes a las variables de lenguaje principal de tipo estructurado actúan de la misma manera que las variables indicadoras de otros tipos de datos. Cuando una base de datos devuelve un valor nulo, se define la variable indicadora y la variable de lenguaje principal de tipo estructurado no cambia. La variable de lenguaje principal propiamente dicha correspondiente a un tipo estructurado está definida como tipo de datos interno. El tipo de datos interno asociado al tipo estructurado debe ser asignable: v desde el resultado de la función de transformación FROM SQL para el tipo estructurado tal como está definida por la opción especificada TRANSFORM GROUP del mandato de precompilación; y v al parámetro de la función de transformación TO SQL para el tipo estructurado tal como está definida por la opción especificada TRANSFORM GROUP del mandato de precompilación. Si se utiliza un marcador de parámetros en lugar de una variable de lenguaje principal, se deben especificar las características apropiadas del tipo de parámetro en la SQLDA. Esto requiere un conjunto ″duplicado″ de estructuras SQLVAR en la SQLDA, y el campo SQLDATATYPE_NAME de la SQLVAR debe contener el nombre de esquema y nombre de tipo del tipo estructurado. Si se omite el esquema en la estructura SQLDA, se produce un error (SQLSTATE 07002). Ejemplo: Defina las variables de lenguaje principal hv_poly y hv_point (de tipo POLYGON, utilizando el tipo interno BLOB(1048576)) en un programa C. Capítulo 2. Elementos del lenguaje 99
- 126. EXEC SQL BEGIN DECLARE SECTION; SQL estático TYPE IS POLYGON AS BLOB(1M) hv_poly, hv_point; EXEC SQL END DECLARE SECTION; Conceptos relacionados: v “Consultas” en la página 18 Información relacionada: v “CREATE ALIAS sentencia” en la publicación Consulta de SQL, Volumen 2 v “PREPARE sentencia” en la publicación Consulta de SQL, Volumen 2 v “SET SCHEMA sentencia” en la publicación Consulta de SQL, Volumen 2 v Apéndice A, “Límites de SQL” en la página 637 v Apéndice C, “SQLDA (área de descriptores de SQL)” en la página 651 v Apéndice G, “Nombres de esquema reservados y palabras reservadas” en la página 867 v Apéndice P, “Consideraciones sobre Extended UNIX Code (EUC) para japonés y chino tradicional” en la página 935 v “Gran objeto (LOB)” en la página 108 100 Consulta de SQL, Volumen 1
- 127. Tipos de datos Tipos de datos La unidad más pequeña de datos que se puede manipular en SQL se denomina un valor. Los valores se interpretan según el tipo de datos de su fuente. Entre los fuentes se incluyen: v Constantes v Columnas v Variables del lenguaje principal v Funciones v Expresiones v Registros especiales. DB2 da soporte a una serie de tipos de datos internos. También proporciona soporte para los tipos de datos definidos por el usuario. La Figura 10 en la página 102 ilustra los tipos de datos internos a los que se da soporte. Capítulo 2. Elementos del lenguaje 101
- 128. tipos de datos incor- porados datos fecha hora serie numérico externos firmado DATALINK hora indicación fecha exacto aproximado hora TIME TIMESTAMP DATE punto binario de flotante carácter gráfico longitud variable BLOB precisión precisión única doble longitud longitud longitud longitud fija variable fija variable REAL DOUBLE CHAR GRAPHIC VARCHAR CLOB VARGRAPHIC DBCLOB entero decimal binario 16 bits 32 bits 64 bits empaq. SMALLINT INTEGER BIGINT DECIMAL Figura 10. Tipos de datos internos de DB2 soportados Todos los tipos de datos incluyen el valor nulo. El valor nulo es un valor especial que se diferencia de todos los valores que no son nulos y, por lo tanto, indica la ausencia de un valor (no nulo). Aunque todos los tipos de datos incluyen el valor nulo, las columnas definidas como NOT NULL no pueden contener valores nulos. Información relacionada: v “Tipos definidos por el usuario” en la página 117 102 Consulta de SQL, Volumen 1
- 129. Números Todos los números tienen un signo y una precisión. El signo se considera positivo si el valor de un número es cero. La precisión es el número de bits o de dígitos excluyendo el signo. Entero pequeño (SMALLINT) Un entero pequeño es un entero de dos bytes con una precisión de 5 dígitos. El rango de pequeños enteros va de -32 768 a 32 767. Entero grande (INTEGER) Un entero grande es un entero de cuatro bytes con una precisión de 10 dígitos. El rango de enteros grandes va de −2 147 483 648 a +2 147 483 647. Entero superior (BIGINT) Un entero superior es un entero de ocho bytes con una precisión de 19 dígitos. El rango de los enteros superiores va de −9 223 372 036 854 775 808 a +9 223 372 036 854 775 807. Coma flotante de precisión simple (REAL) Un número de coma flotante de precisión simple es una aproximación de 32 bits de un número real. El número puede ser cero o puede estar en el rango de -3,402E+38 a -1,175E-37, o de 1,175E-37 a 3,402E+38. Coma flotante de doble precisión (DOUBLE o FLOAT) Una número de coma flotante de doble precisión es una aproximación de 64 bits de un número real. El número puede ser cero o puede estar en el rango de -1,79769E+308 a -2,225E-307, o de 2,225E-307 a 1,79769E+308. Decimal (DECIMAL o NUMERIC) Un valor decimal es un número decimal empaquetado con una coma decimal implícita. La posición de la coma decimal la determinan la precisión y la escala del número. La escala, que es el número de dígitos en la parte de la fracción del número, no puede ser negativa ni mayor que la precisión. La precisión máxima es de 31 dígitos. Todos los valores de una columna decimal tienen la misma precisión y escala. El rango de una variable decimal o de los números de una columna decimal es de −n a +n, donde el valor absoluto de n es el número mayor que puede representarse con la precisión y escalas aplicables. El rango máximo va de -10**31+1 a 10**31-1. Información relacionada: v Apéndice C, “SQLDA (área de descriptores de SQL)” en la página 651 Capítulo 2. Elementos del lenguaje 103
- 130. Series de caracteres Una serie de caracteres es una secuencia de bytes. La longitud de la serie es el número de bytes en la secuencia. Si la longitud es cero, el valor se denomina la serie vacía. Este valor no debe confundirse con el valor nulo. Serie de caracteres de longitud fija (CHAR) Todos los valores de una columna de series de longitud fija tienen la misma longitud, que está determinada por el atributo de longitud de la columna. El atributo de longitud debe estar entre 1 y 254, inclusive. Series de caracteres de longitud variable Existen tres tipos de series de caracteres de longitud variable: v Un valor VARCHAR puede tener una longitud máxima de 32 672 bytes. v Un valor LONG VARCHAR puede tener una longitud máxima de 32 700 bytes. v Un valor CLOB (gran objeto de caracteres) puede tener una longitud máxima de 2 gigabytes (2 147 483 647 bytes). Un CLOB se utiliza para almacenar datos basados en caracteres SBCS o mixtos (SBCS y MBCS) (como, por ejemplo, documentos escritos con un solo juego de caracteres) y, por lo tanto, tiene una página de códigos SBCS o mixta asociada). Se aplican restricciones especiales a las expresiones que dan como resultado un tipo de datos LONG VARCHAR o CLOB y a las columnas de tipo estructurado; estas expresiones y columnas no se permiten en: v Una lista SELECT precedida por la cláusula DISTINCT v Una cláusula GROUP BY v Una cláusula ORDER BY v Una función de columna con la cláusula DISTINCT v Una subselección de un operador de conjunto que no sea UNION ALL v Un predicado BETWEEN o IN básico y cuantificado v Una función de columna v Las funciones escalares VARGRAPHIC, TRANSLATE y de fecha y hora v El operando patrón de un predicado LIKE o el operando de serie de búsqueda de una función POSSTR v La representación en una serie de un valor de fecha y hora. Además de las restricciones descritas anteriormente, las expresiones que den como resultado datos de tipo LONG VARCHAR o CLOB no se permiten en: v Un predicado BETWEEN o IN básico y cuantificado v Una función de columna v Las funciones escalares VARGRAPHIC, TRANSLATE y fecha y hora 104 Consulta de SQL, Volumen 1
- 131. v El operando patrón de un predicado LIKE o el operando de serie de búsqueda de la función POSSTR v La representación en una serie de un valor de fecha y hora. Las funciones del esquema SYSFUN que toman como argumento VARCHAR no aceptarán las VARCHAR que tengan más de 4 000 bytes de longitud como argumento. Sin embargo, muchas de estas funciones también pueden tener una signatura alternativa que acepte un CLOB(1M). Para estas funciones, el usuario puede convertir explícitamente las series VARCHAR mayores que 4 000 en datos CLOB y luego reconvertir el resultado en datos VARCHAR de la longitud deseada. Las series de caracteres terminadas en nulo que se encuentran en C se manejan de manera diferente, dependiendo del nivel de estándares de la opción de precompilación. Cada serie de caracteres se define con más detalle como: Datos de bits Datos que no están asociado con una página de códigos. Datos del juego de caracteres de un solo byte(SBCS) Datos en los que cada carácter está representado por un solo byte. Datos mixtos Datos que pueden contener una mezcla de caracteres de un juego de caracteres de un solo byte y de un juego de caracteres de múltiples bytes (MBCS). Los datos SBCS sólo están soportados en una base de datos SBCS. Sólo se da soporte a los datos mixtos en una base de datos MBCS. Capítulo 2. Elementos del lenguaje 105
- 132. Series gráficas Una serie gráfica es una secuencia de bytes que representa datos de caracteres de doble byte. La longitud de la serie es el número de caracteres de doble byte de la secuencia. Si la longitud es cero, el valor se denomina la serie vacía. Este valor no debe confundirse con el valor nulo. Las series gráficas no se comprueban para asegurarse de que sus valores sólo contienen elementos de código de caracteres de doble byte. (La excepción a esta regla es una aplicación precompilada con la opción WCHARTYPE CONVERT. En este caso, sí que se efectúa la validación.) En lugar de esto, el gestor de bases de datos supone que los datos de caracteres de doble byte están contenidos en campos de datos gráficos. El gestor de bases de datos sí que comprueba que un valor de la longitud de una serie gráfica sea número par de bytes. Las series gráficas terminadas en nulo que se encuentran en C se manejan de manera diferente, dependiendo del nivel de estándares de la opción de precompilación. Este tipo de datos no puede crearse en una tabla. Sólo se puede utilizar para insertar datos en la base de datos y recuperarlos de la misma. Series gráficas de longitud fija (GRAPHIC) Todos los valores de una columna de series gráficas de longitud fija tienen la misma longitud, que viene determinada por el atributo de longitud de la columna. El atributo de longitud debe estar entre 1 y 127, inclusive. Series gráficas de longitud variable Existen tres tipos de series gráficas de longitud variable: v Un valor VARGRAPHIC puede tener una longitud máxima de 16 336 caracteres de doble byte. v Un valor LONG VARGRAPHIC puede tener una longitud máxima de 16 350 caracteres de doble byte. v Un valor DBCLOB (gran objeto de caracteres de doble byte) puede tener una longitud máxima de 1 073 741 823 caracteres de doble byte. Un DBCLOB se utiliza para almacenar datos DBCS grandes basados en caracteres (por ejemplo, documentos escritos con un solo juego de caracteres) y, por lo tanto, tiene asociada una página de códigos DBCS). Se aplican restricciones especiales a una expresión que dé como resultado una serie gráfica de longitud variable cuya longitud máxima sea mayor que 127 bytes. Estas restricciones son las mismas que las especificadas en el apartado “Series de caracteres de longitud variable” en la página 104. 106 Consulta de SQL, Volumen 1
- 133. Series binarias Una serie binaria es una secuencia de bytes. A diferencia de las series de caracteres, que suelen contener datos de texto, las series binarios se utilizan para contener datos no tradicionales como, por ejemplo, imágenes, voz o soportes mixtos. Las series de caracteres del subtipo FOR BIT DATA puede utilizarse para fines similares, pero los dos tipos de datos no son compatibles. La función escalar BLOB puede utilizarse para convertir una serie de caracteres FOR BIT DATA en una serie binaria. Las series binarias no están asociadas a ninguna página de códigos. Tienen las mismas restricciones que las series de caracteres (consulte los detalles en el apartado “Series de caracteres de longitud variable” en la página 104). Gran objeto binario (BLOB) Un gran objeto binario es una serie binario de longitud variable que puede tener una longitud máxima de 2 gigabytes (2 147 483 647 bytes). Los valores BLOB pueden contener datos estructurados para que los utilicen las funciones definidas por el usuario y los tipos definidos por el usuario. Igual que las series de caracteres FOR BIT DATA, las series BLOB no están asociadas a ninguna página de códigos. Capítulo 2. Elementos del lenguaje 107
- 134. Gran objeto (LOB) El término gran objeto y el acrónimo genérico LOB hace referencia al tipo de datos BLOB, CLOB o DBCLOB. Los valores LOB están sujetos a las restricciones que se aplican a los valores LONG VARCHAR, que se describen en el apartado “Series de caracteres de longitud variable” en la página 104. Estas restricciones se aplican incluso si el atributo de longitud de la serie LOB es de 254 bytes o menor. Los valores LOB pueden ser muy grandes y la transferencia de dichos valores desde servidor de bases de datos a las variables del lenguaje principal del programa de aplicación cliente puede tardar mucho tiempo. Como normalmente los programas de aplicación procesan los valores LOB de fragmento en fragmento en lugar de como un todo, las aplicaciones pueden hacer referencia a un valor LOB utilizando un localizador de gran objeto. Un localizador de gran objeto o localizador de LOB es una variable del lenguaje principal cuyo valor representa un solo valor LOB del servidor de bases de datos. Un programa de aplicación puede seleccionar un valor LOB en un localizador de LOB. Entonces, utilizando el localizador de LOB, el programa de aplicación puede solicitar operaciones de base de datos basadas en el valor LOB (por ejemplo, aplicar las funciones escalares SUBSTR, CONCAT, VALUE o LENGTH, realizar una asignación, efectuar búsquedas en el LOB con LIKE o POSSTR o aplicar funciones definidas por el usuario sobre el LOB) proporcionando el valor del localizador como entrada. La salida resultante (los datos asignados a una variable del lenguaje principal cliente), sería normalmente un subconjunto pequeño del valor LOB de entrada. Los localizadores de LOB también pueden representar, además de valores base, el valor asociado con una expresión LOB. Por ejemplo, un localizador de LOB puede representar el valor asociado con: SUBSTR( <lob 1> CONCAT <lob 2> CONCAT <lob 3>, <inicio>, <longitud> ) Cuando se selecciona un valor nulo en una variable del lenguaje principal normal, la variable indicadora se establece en -1, lo que significa que el valor es nulo. Sin embargo, en el caso de los localizadores de LOB, el significado de las variables indicadoras es ligeramente distinto. Como una variable del lenguaje principal del localizador en sí nunca puede ser nula, un valor negativo de variable indicadora significa que el valor LOB representado por el localizador de LOB es nulo. La información de nulo se mantiene local para el cliente en virtud del valor de la variable indicadora — el servidor no hace ningún seguimiento de los valores nulos con localizadores válidos. 108 Consulta de SQL, Volumen 1
- 135. Es importante comprender que un localizador de LOB representa un valor, no una fila ni una ubicación en la base de datos. Cuando se ha seleccionado un valor en un localizador, no hay ninguna operación que se pueda efectuar en la fila o tabla originales que afecte al valor al que hace referencia el localizador. El valor asociado con un localizador es válido hasta que finaliza la transacción o hasta que el localizador se libera explícitamente, lo primero que se produzca. Los localizadores no fuerzan copias adicionales de los datos para proporcionar esta función. En su lugar, el mecanismo del localizador almacena una descripción del valor LOB base. La materialización del valor LOB (o expresión, tal como se muestra arriba) se difiere hasta que se asigna realmente a alguna ubicación: un almacenamiento intermedio del usuario en forma de una variable del lenguaje principal u otro registro de la base de datos. Un localizador de LOB es sólo un mecanismo utilizado para hacer referencia a un valor LOB durante una transacción; no persiste más allá de la transacción en la que se ha creado. No es un tipo de base de datos; nunca se almacena en la base de datos y, como resultado, no puede participar en vistas ni en restricciones de comprobación. Sin embargo, como un localizador de LOB es una representación cliente de un tipo LOB, hay SQLTYPE para localizadores de LOB para que puedan describirse dentro de una estructura SQLDA que se utiliza por sentencias FETCH, OPEN y EXECUTE. Capítulo 2. Elementos del lenguaje 109
- 136. Valores de fecha y hora Entre los tipos de datos de fecha y hora se incluyen DATE, TIME y TIMESTAMP. Aunque los valores de fecha y hora se pueden utilizar en algunas operaciones aritméticas y de series y son compatibles con algunas series, no son ni series ni números. Fecha Una fecha es un valor que se divide en tres partes (año, mes y día). El rango de la parte correspondiente al año va de 0001 a 9999. El rango de la parte correspondiente al mes va de 1 a 12. El rango de la parte correspondiente al día va de 1 a x, donde x depende del mes. La representación interna de una fecha es una serie de 4 bytes. Cada byte consta de 2 dígitos decimales empaquetados. Los 2 primeros bytes representan el año, el tercer byte el mes y el último byte el día. La longitud de una columna DATE, tal como se describe en el SQLDA, es de 10 bytes, que es la longitud adecuada para una representación de serie de caracteres del valor. Hora Una hora es un valor que se divide en tres partes (hora, minuto y segundo) que indica una hora del día de un reloj de 24 horas. El rango de la parte correspondiente a la hora va de 0 a 24. El rango de la otra parte va de 0 a 59. Si la hora es 24, las especificaciones de los minutos y segundos son cero. La representación interna de la hora es una serie de 3 bytes. Cada byte consta de 2 dígitos decimales empaquetados. El primer byte representa la hora, el segundo byte el minuto y el último byte el segundo. La longitud de la columna TIME, tal como se describe en SQLDA, es de 8 bytes, que es la longitud adecuada para una representación de serie de caracteres del valor. Indicación de fecha y hora Una indicación de fecha y hora es un valor dividido en siete partes (año, mes, día, hora, minuto, segundo y microsegundo) que indica una fecha y una hora como las definidas más arriba, excepto en que la hora incluye la especificación fraccional de los microsegundos. La representación interna de la indicación de fecha y hora es una serie de 10 bytes. Cada byte consta de 2 dígitos decimales empaquetados. Los 4 primeros bytes representan la fecha, los 3 bytes siguientes la hora y los últimos 3 bytes los microsegundos. 110 Consulta de SQL, Volumen 1
- 137. La longitud de una columna TIMESTAMP, tal como se describe en el SQLDA, es de 26 bytes, que es la longitud adecuada para la representación de serie de caracteres del valor. Representación de serie de los valores de fecha y hora Los valores cuyos tipos de datos son DATE, TIME o TIMESTAMP se representan en un formato interno que es transparente para el usuario. Sin embargo, los valores de fecha, hora e indicación de fecha y hora también pueden representarse mediante series. Esto resulta útil porque no existen constantes ni variables cuyo tipo de datos sean DATE, TIME o TIMESTAMP. Antes de poder recuperar un valor de fecha y hora, éste debe asignarse a una variable de serie. La función GRAPHIC (sólo para bases de datos Unicode) puede utilizarse para cambiar el valor de fecha y hora a una representación de serie. Normalmente, la representación de serie es el formato por omisión de los valores de fecha y hora asociados con el código territorial de la aplicación, a menos que se alteren temporalmente por la especificación de la opción DATETIME al precompilar el programa o vincularlo con la base de datos. Con independencia de su longitud, no puede utilizarse una serie de gran objeto, un valor LONG VARCHAR ni un valor LONG VARGRAPHIC para representar un valor de fecha y hora (SQLSTATE 42884). Cuando se utiliza una representación de serie válida de un valor de fecha y hora en una operación con un valor de fecha y hora interno, la representación de serie se convierte al formato interno del valor de fecha, hora o indicación de fecha y hora antes de realizar la operación. Las series de fecha, hora e indicación de fecha y hora sólo deben contener caracteres y dígitos. Series de fecha: Una representación de serie de una fecha es una serie que empieza por un dígito y que tiene una longitud de 8 caracteres como mínimo. Pueden incluirse blancos de cola; pueden omitirse los ceros iniciales de las partes correspondientes al mes y al día. Los formatos válidos para las series se indican en la tabla siguiente. Cada formato se identifica mediante el nombre y la abreviatura asociada. Tabla 5. Formatos para las representaciones de serie de fechas Nombre del formato Abreviatura Formato de Ejemplo fecha International Standards ISO aaaa-mm-dd 1991-10-27 Organization Estándar IBM USA USA mm/dd/aaaa 10/27/1991 Estándar IBM European EUR dd.mm.aaaa 27.10.1991 Capítulo 2. Elementos del lenguaje 111
- 138. Tabla 5. Formatos para las representaciones de serie de fechas (continuación) Nombre del formato Abreviatura Formato de Ejemplo fecha Era Japanese Industrial Standard JIS aaaa-mm-dd 1991-10-27 Christian Definido-sitio LOC Depende del — código territorial de la aplicación Series de hora: Una representación de serie de una hora es una serie que empieza por un dígito y que tiene una longitud de 4 caracteres como mínimo. Pueden incluirse blancos de cola; puede omitirse un cero inicial de la parte correspondiente a la hora y pueden omitirse por completo los segundos. Si se omiten los segundos, se supone una especificación implícita de 0 segundos. De este modo, 13:30 es equivalente a 13:30:00. Los formatos válidos para las series de horas se indican en la tabla siguiente. Cada formato se identifica mediante el nombre y la abreviatura asociada. Tabla 6. Formatos para representaciones de serie de horas Nombre del formato Abreviatura Formato de la Ejemplo hora International Standards ISO hh.mm.ss 13.30.05 Organization2 Estándar IBM USA USA hh:mm AM o 1:30 PM PM Estándar IBM European EUR hh.mm.ss 13.30.05 Era Japanese Industrial Standard JIS hh:mm:ss 13:30:05 Christian Definido-sitio LOC Depende del — código territorial de la aplicación Notas: 1. En el formato ISO, EUR y JIS, .ss (o :ss) es opcional. 2. La organización International Standards Organization ha cambiado el formato de la hora, de modo que ahora es idéntico al de Japanese Industrial Standard Christian Era. Por lo tanto, utilice el formato JIS si una aplicación necesita el formato actual de International Standards Organization. 112 Consulta de SQL, Volumen 1
- 139. 3. En el formato de serie de hora USA, puede omitirse la especificación de los minutos, con lo que se indica una especificación implícita de 00 minutos. Por lo tanto 1 PM es equivalente a 1:00 PM. 4. En el formato de hora USA, la hora no debe ser mayor que 12 y no puede ser 0, excepto en el caso especial de las 00:00 AM. Hay un solo espacio antes de AM y PM. Si se utiliza el formato JIS del reloj de 24 horas, la correspondencia entre el formato USA y el reloj de 24 horas es la siguiente: 12:01 AM a 12:59 AM corresponde a 00:01:00 a 00:59:00. 01:00 AM a 11:59 AM corresponde a 01:00:00 a 11:59:00. 12:00 PM (mediodía) a 11:59 PM corresponde a 12:00:00 a 23:59:00. 12:00 AM (medianoche) corresponde a 24:00:00 y 00:00 AM (medianoche) corresponde a 00:00:00. Series de indicación de fecha y hora: Una representación de serie de una indicación de fecha y hora es una serie que empieza por un dígito y que tiene una longitud de 16 caracteres como mínimo. La representación de serie completa de una indicación de fecha y hora tiene el formato aaaa-mm-dd-hh.mm.ss.nnnnnn. Se pueden incluir los blancos de cola. Pueden omitirse los ceros iniciales de las partes correspondientes al mes, día y hora de la indicación de fecha y hora y se pueden truncar los microsegundos u omitirse por completo. Si se omite cualquier cero de cola en la parte correspondiente a los microsegundos, se asume la especificación implícita de 0 para los dígitos que faltan. Por lo tanto, 1991-3-2-8.30.00 es equivalente a 1991-03-02-08.30.00.000000. Las sentencias de SQL también dan soporte a la representación de serie ODBC de una indicación de fecha y hora, pero sólo como un valor de entrada. La representación de serie ODBC de una indicación de fecha y hora tiene el formato aaaa-mm-dd hh:mm:ss.nnnnnn. Capítulo 2. Elementos del lenguaje 113
- 140. Valores DATALINK Un valor DATALINK es un valor encapsulado que contiene una referencia lógica de la base de datos a un archivo almacenado fuera de la base de datos. Los atributos de este valor encapsulado son los siguientes: tipo de enlace El tipo de enlace soportado actualmente es 'URL' (Uniform Resource Locator). ubicación de datos Es la ubicación de un archivo enlazado a una referencia dentro de DB2, en forma de un URL. Para este URL se pueden utilizar estos nombres de esquema: v HTTP v FILE v UNC v DFS Las demás partes del URL son: v el nombre del servidor de archivos para los esquemas HTTP, FILE y UNC v el nombre de la célula para el esquema DFS v la vía de acceso completa dentro del servidor de archivos o célula comentario Hasta 200 bytes de información descriptiva, incluido el atributo de ubicación de los datos. Está pensado para los usos específicos de una aplicación, como, por ejemplo, una identificación alternativa o más detallada de la ubicación de los datos. Los caracteres en blanco iniciales y de cola se eliminan durante el análisis de los atributos de ubicación de datos en forma de URL. Además, los nombres de esquema ('http', 'file', 'unc', 'dfs') y de lenguaje principal no son sensibles las mayúsculas/minúsculas y se convierten siempre a mayúsculas para guardarlos en la base de datos. Cuando se recupera un valor DATALINK de una base de datos, se intercala un símbolo de accesos dentro del atributo de URL si la columna DATALINK está definida con READ PERMISSION DB o WRITE PERMISSION ADMIN. El símbolo se genera dinámicamente y no es una parte permanente del valor DATALINK almacenado en la base de datos. Un valor DATALINK puede tener solamente un atributo de comentario y un atributo vacío de ubicación de datos. Incluso es posible que un valor de este tipo se almacene en una columna, pero, naturalmente, no se enlazará ningún 114 Consulta de SQL, Volumen 1
- 141. archivo a esta columna. La longitud total del comentario y el atributo de ubicación de datos de un valor DATALINK está actualmente limitado a 200 bytes. Es importante distinguir entre las referencias DATALINK a archivos y las variables de referencia a archivos LOB. La semejanza es que ambas contienen una representación de un archivo. No obstante: v Los valores DATALINK quedan retenidos en la base de datos y tanto los enlaces como los datos de los archivos enlazados pueden considerarse una ampliación natural de datos en la base de datos. v Las variables de referencia a archivos existen temporalmente en el cliente y pueden considerarse una alternativa al almacenamiento intermedio de un programa principal. Utilice las funciones escalares incorporadas para crear un valor DATALINK (DLVALUE, DLNEWCOPY, DLPREVIOUSCOPY y DLREPLACECONTENT) y para extraer los valores encapsulados de un valor DATALINK (DLCOMMENT, DLLINKTYPE, DLURLCOMPLETE, DLURLPATH, DLURLPATHONLY, DLURLSCHEME, DLURLSERVER, DLURLCOMPLETEONLY, DLURLCOMPLETEWRITE y DLURLPATHWRITE). Información relacionada: v “Identificadores” en la página 71 v Apéndice Q, “Especificaciones de formato de Backus-Naur (BNF) para los enlaces de datos” en la página 945 Capítulo 2. Elementos del lenguaje 115
- 142. Valores XML El tipo de datos XML es una representación interna de XML y sólo puede utilizarse como entrada a funciones que acepten este datos como entrada. XML es un tipo de datos transitorio que no puede almacenarse en la base de datos ni devolverse a una aplicación. Entre los valores válidos para el tipo de datos XML se incluyen los siguientes: v Un elemento v Un bosque de elementos v El contenido textual de un elemento v Un valor XML vacío Actualmente, la única operación que se permite consiste en serializar (utilizando la función XML2CLOB) el valor XML en una serie que se almacena como un valor CLOB. 116 Consulta de SQL, Volumen 1
- 143. Tipos definidos por el usuario Existen tres tipos de datos definidos por el usuario: v Tipo diferenciado v Tipo estructurado v Tipo de referencia Cada uno de ellos se describe en los apartados siguientes. Tipos diferenciados Un tipo diferenciado es un tipo de datos definido por el usuario que comparte su representación interna con un tipo existente (su tipo “fuente”), pero se considera un tipo independiente e incompatible para la mayoría de operaciones. Por ejemplo, se desea definir un tipo de imagen, un tipo de texto y un tipo de audio, todos ellos tienen semánticas bastante diferentes, pero utilizan el tipo de datos interno BLOB para su representación interna. El siguiente ejemplo ilustra la creación de un tipo diferenciado denominado AUDIO: CREATE DISTINCT TYPE AUDIO AS BLOB (1M) Aunque AUDIO tenga la misma representación que el tipo de datos interno BLOB, se considera un tipo independiente; esto permite la creación de funciones escritas especialmente para AUDIO y asegura que dichas funciones no se aplicarán a valores de ningún otro tipo de datos (imágenes, texto, etc.) Los tipos diferenciados tienen identificadores calificados. Si no se utiliza el nombre de esquema para calificar el nombre del tipo diferenciado cuando se emplea en sentencias que no son CREATE DISTINCT TYPE, DROP DISTINCT TYPE o COMMENT ON DISTINCT TYPE, en la vía de acceso de SQL se busca por orden el primer esquema con un tipo diferenciado que coincida. Los tipos diferenciados dan soporte a una gran escritura asegurando que sólo aquellas funciones y operadores que están explícitamente definidos en un tipo diferenciado se puedan aplicar a sus instancias. Por esta razón, un tipo diferenciado no adquiere automáticamente las funciones y operadores de su tipo fuente, ya que estas podrían no tener ningún significado. (Por ejemplo, la función LENGTH del tipo AUDIO puede devolver la longitud de su objeto en segundos en lugar de bytes.) Los tipos diferenciados que derivan de los tipos LONG VARCHAR, LONG VARGRAPHIC, LOB o DATALINK están sujetos a las mismas restricciones que su tipo fuente. Sin embargo, se puede especificar explícitamente que ciertas funciones y ciertos operadores del tipo fuente se apliquen al tipo diferenciado. Esto puede Capítulo 2. Elementos del lenguaje 117
- 144. hacerse creando funciones definidas por el usuario que se deriven de funciones definidas en el tipo fuente del tipo diferenciado. Los operadores de comparación se generan automáticamente para los tipos diferenciados definidos por el usuario, excepto los que utilicen LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB o DATALINK como tipo fuente. Además, se generan funciones para dar soporte a la conversión del tipo fuente al tipo diferenciado y del tipo diferenciado al tipo fuente. Tipos estructurados Un tipo estructurado es un tipo de datos definido por el usuario con una estructura definida en la base de datos. Contiene una secuencia de atributos con nombre, cada uno de los cuales tiene un tipo de datos. Un tipo estructurado también incluye un conjunto de especificaciones de método. Un tipo estructurado puede utilizarse como tipo de una tabla, de una vista o de una columna. Cuando se utiliza como tipo para una tabla o vista, esa tabla o vista se denomina tabla con tipo o vista con tipo, respectivamente. Para las tablas con tipo y vistas con tipo, los nombres y tipos de datos de los atributos del tipo estructurado pasan a ser los nombres y tipos de datos de las columnas de esta tabla o vista con tipo. Las filas de la tabla o vista con tipo pueden considerarse una representación de instancias del tipo estructurado. Cuando se utiliza como tipo de datos para una columna, la columna contiene valores de ese tipo estructurado (o valores de cualquiera de los subtipos de ese tipo, tal como se describe más abajo). Los métodos se utilizan para recuperar o manipular atributos de un objeto de columna estructurado. Terminología: Un supertipo es un tipo estructurado para el que se han definido otros tipos estructurados, llamados subtipos. Un subtipo hereda todos los atributos y métodos de su supertipo y puede tener definidos otros atributos y métodos. El conjunto de tipos estructurados que están relacionados con un supertipo común se denomina jerarquía de tipos y el tipo que no tiene ningún supertipo se denomina el tipo raíz de la jerarquía de tipos. El término subtipo se aplica a un tipo estructurado definido por el usuario y a todos los tipos estructurados definidos por el usuario que están debajo de él en la jerarquía de tipos. Por tanto, un subtipo de un tipo estructurado T es T y todos los tipos estructurados por debajo de T en la jerarquía. Un subtipo propio de un tipo estructurado T es un tipo estructurado por debajo de T en la jerarquía de tipos. Existen restricciones respecto a la existencia de definiciones recursivas de tipos en una jerarquía de tipos. Por esta razón, es necesario desarrollar una forma abreviada de hacer referencia al tipo específico de definiciones recursivas que están permitidas. Se utilizan las definiciones siguientes: v Utiliza directamente: Se dice que un tipo A utiliza directamente otro tipo B sólo si se cumple una de estas condiciones: 118 Consulta de SQL, Volumen 1
- 145. 1. el tipo A tiene un atributo del tipo B 2. el tipo B es un subtipo de A, o un supertipo de A v Utiliza indirectamente: Se dice que un tipo A utiliza indirectamente un tipo B sólo si se cumple una de estas condiciones: 1. el tipo A utiliza directamente el tipo B 2. el tipo A utiliza directamente cierto tipo C, y el tipo C utiliza indirectamente el tipo B Un tipo puede no estar definido para que uno de sus tipos de atributo se utilice, directa o indirectamente, a sí mismo. Si es necesario tener una configuración así, considere la posibilidad de utilizar una referencia como atributo. Por ejemplo, en el caso de atributos de tipos estructurados, no puede existir una instancia de ″empleado″ que tenga el atributo ″director″ cuando ″director″ es de tipo ″empleado″. En cambio, puede existir un atributo ″director″ cuyo tipo sea REF(empleado). Un tipo no se puede descartar si ciertos otros objetos utilizan el tipo, ya sea directa o indirectamente. Por ejemplo, no se puede descartar un tipo si una columna de una tabla o vista hace uso directa o indirectamente del tipo. Tipos de referencia Un tipo de referencia es un tipo compañero de un tipo estructurado. De manera similar a un tipo diferenciado, un tipo de referencia es un tipo escalar que comparte una representación común con uno de los tipos de datos internos. Todos los tipos de la jerarquía de tipos comparten esta misma representación. La representación de un tipo de referencia se define cuando se crea el tipo raíz de una jerarquía de tipos. Cuando se utiliza un tipo de referencia, se especifica un tipo estructurado como parámetro del tipo. Este parámetro se denomina el tipo de destino de la referencia. El destino de una referencia siempre es una fila de una tabla con tipo o una vista con tipo. Cuando se utiliza un tipo de referencia, puede tener definido un ámbito. El ámbito identifica una tabla (denominada tabla de destino) o una vista (denominada vista de destino) que contiene la fila de destino de un valor de referencia. La tabla de destino o la vista de destino debe tener el mismo tipo que el tipo de destino del tipo de referencia. Una instancia de un tipo de referencia con ámbito identifica de forma exclusiva una fila en una tabla con tipo o en una vista con tipo, denominada fila de destino. Información relacionada: v “DROP sentencia” en la publicación Consulta de SQL, Volumen 2 v “CURRENT PATH” en la página 172 v “Series de caracteres” en la página 104 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 119
- 146. Promoción de tipos de datos Los tipos de datos se pueden clasificar en grupos de tipos de datos relacionados. Dentro de estos grupos, existe un orden de prioridad en el que se considera que un tipo de datos precede a otro tipo de datos. Esta prioridad se utiliza para permitir la promoción de un tipo de datos a un tipo de datos posterior en el orden de prioridad. Por ejemplo, el tipo de datos CHAR puede promocionarse a VARCHAR, INTEGER puede promocionarse a DOUBLE-PRECISION pero CLOB NO es promocionable a VARCHAR. La promoción de tipos de datos se utiliza en estos casos: v Para realizar la resolución de la función v Para convertir tipos definidos por el usuario v Para asignar tipos definidos por el usuario a tipos de datos internos La Tabla 7 muestra la lista de prioridad (por orden) para cada tipo de datos y se puede utilizar para determinar los tipos de datos a los que se puede promover un tipo de datos determinado. La tabla muestra que la mejor elección siempre es el mismo tipo de datos en lugar de elegir la promoción a otro tipo de datos. Tabla 7. Tabla de prioridades de tipos de datos Tipo de datos Lista de prioridad de tipos de datos (por orden de mejor a peor) CHAR CHAR, VARCHAR, LONG VARCHAR, CLOB VARCHAR VARCHAR, LONG VARCHAR, CLOB LONG LONG VARCHAR, CLOB VARCHAR GRAPHIC GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC, DBCLOB VARGRAPHIC VARGRAPHIC, LONG VARGRAPHIC, DBCLOB LONG LONG VARGRAPHIC, DBCLOB VARGRAPHIC BLOB BLOB CLOB CLOB DBCLOB DBCLOB SMALLINT SMALLINT, INTEGER, BIGINT, decimal, real, double INTEGER INTEGER, BIGINT, decimal, real, double BIGINT BIGINT, decimal, real, double decimal decimal, real, double real real, double double double 120 Consulta de SQL, Volumen 1
- 147. Tabla 7. Tabla de prioridades de tipos de datos (continuación) Tipo de datos Lista de prioridad de tipos de datos (por orden de mejor a peor) DATE DATE TIME TIME TIMESTAMP TIMESTAMP DATALINK DATALINK udt udt (mismo nombre) o un supertipo de udt REF(T) REF(S) (en el caso de que S sea un supertipo de T) Notas: 1. Los tipos en minúsculas anteriores se definen de la siguiente manera: v decimal = DECIMAL(p,s) o NUMERIC(p,s) v real = REAL o FLOAT(n), donde n not es mayor que 24 v double = DOUBLE, DOUBLE-PRECISION, FLOAT o FLOAT(n), donde n es mayor que 24 v udt = un tipo definido por el usuario Los sinónimos, más cortos o más lagos, de los tipos de datos listados se consideran iguales a la forma listada. 2. Para una base de datos Unicode, los siguientes se consideran tipos de datos equivalentes: v CHAR y GRAPHIC v VARCHAR y VARGRAPHIC v LONG VARCHAR y LONG VARGRAPHIC v CLOB y DBCLOB Información relacionada: v “Funciones” en la página 181 v “Conversiones entre tipos de datos” en la página 122 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 121
- 148. Conversiones entre tipos de datos En muchas ocasiones, un valor con un tipo de datos determinado necesita convertirse a un tipo de datos diferente o al mismo tipo de datos con una longitud, precisión o escala diferentes. La promoción del tipo de datos es un ejemplo en el que la promoción de un tipo de datos a otro tipo de datos necesita que el valor se convierta al nuevo tipo de datos. Un tipo de datos que se puede convertir a otro tipo de datos es convertible de un tipo de datos fuente al tipo de datos de destino. La conversión entre tipos de datos puede realizarse explícitamente utilizando la especificación CAST pero también puede efectuarse implícitamente durante las asignaciones que implican tipos definidos por el usuario. Además, al crear funciones definidas por el usuario derivadas, los tipos de datos de los parámetros de la función fuente deben poder convertirse a los tipos de datos de la función que se está creando. La Tabla 8 en la página 124 muestra las conversiones permitidas entre tipos de datos internos. La primera columna representa el tipo de datos del operando cast (tipo de datos fuente) y los tipos de datos en la parte superior representan el tipo de datos de destino de la especificación CAST. En una base de datos Unicode, si se produce un truncamiento al convertir una serie de caracteres o gráfica a otro tipo de datos, se devuelve una advertencia si se trunca algún carácter que no sea un blanco. Este comportamiento de truncamiento es distinto de la asignación de series de caracteres o gráficas a un destino cuando se produce un error si se trunca algún carácter que no es un blanco. Se da soporte a las siguientes conversiones en las que intervienen tipos diferenciados: v Conversión de un tipo diferenciado DT a su tipo de datos fuente S v Conversión del tipo de datos fuente S de un tipo diferenciado DT al tipo diferenciado DT v Conversión del tipo diferenciado DT al mismo tipo diferenciado DT v Conversión de un tipo de datos A a un tipo diferenciado DT donde A se puede promocionar al tipo de datos fuente S del tipo diferenciado DT v Conversión de INTEGER a un tipo diferenciado DT con un tipo de datos fuente SMALLINT v Conversión de DOUBLE a un tipo diferenciado DT con un tipo de datos fuente REAL v Conversión de VARCHAR a un tipo diferenciado DT con un tipo de datos fuente CHAR 122 Consulta de SQL, Volumen 1
- 149. v Conversión de VARGRAPHIC a un tipo diferenciado DT con un tipo de datos fuente GRAPHIC v Para una base de datos Unicode, conversión de VARCHAR o VARGRAPHIC a un tipo diferenciado DT con un tipo de datos fuente CHAR o GRAPHIC. No es posible especificar FOR BIT DATA cuando se realiza una conversión a un tipo de carácter. No es posible convertir un valor de tipo estructurado en algo diferente. Un tipo estructurado ST no necesita convertirse a uno de sus supertipos, porque todos los métodos de los supertipos de ST son aplicables a ST. Si la operación deseada sólo es aplicable a un subtipo de ST, utilice la expresión de tratamiento de subtipos para tratar ST como uno de sus subtipos. Cuando un tipo de datos definido por el usuario e implicado en una conversión no está calificado por un nombre de esquema, se utiliza la vía de acceso de SQL para buscar el primer esquema que incluya el tipo de datos definido por el usuario con este nombre. Se da soporte a las siguientes conversiones donde intervienen tipos de referencia: v conversión de un tipo de referencia RT en su tipo de datos de representación S v conversión del tipo de datos de representación S de un tipo de referencia RT en el tipo de referencia RT v Conversión de un tipo de referencia RT con un tipo de destino T a un tipo de referencia RS con un tipo de destino S donde S es un supertipo de T. v Conversión de un tipo de datos A en un tipo de referencia RT donde A se puede promocionar al tipo de datos de representación S del tipo de referencia RT. Cuando el tipo de destino de un tipo de datos de referencia implicado en una conversión no está calificado por un nombre de esquema, se utiliza la vía de acceso de SQL para buscar el primer esquema que incluya el tipo de datos definido por el usuario con este nombre. Capítulo 2. Elementos del lenguaje 123
- 150. Tabla 8. Conversiones soportadas entre tipos de datos internos Tipo de datos S I B D R D C V L C G V L D D T T B de destino → M N I E E O H A O L R A O B A I I L A T G C A U A R N O A R N C T M M O L E I I L B R C G B P G G L E E E B L G N M L H V H R V O S I E T A E A A I A A B T N R L R R C P R A T C H G M Tipo de datos fuente ↓ H I P A C R SMALLINT Y Y Y Y Y Y Y - - - - - - - - - - - INTEGER Y Y Y Y Y Y Y - - - - - - - - - - - BIGINT Y Y Y Y Y Y Y - - - - - - - - - - - DECIMAL Y Y Y Y Y Y Y - - - - - - - - - - - REAL Y Y Y Y Y Y Y - - - - - - - - - - - DOUBLE Y Y Y Y Y Y Y - - - - - - - - - - - 1 1 CHAR Y Y Y Y - - Y Y Y Y Y Y - - Y Y Y Y 1 1 VARCHAR Y Y Y Y - - Y Y Y Y Y Y - - Y Y Y Y 1 1 LONG VARCHAR - - - - - - Y Y Y Y - - Y Y - - - Y 1 CLOB - - - - - - Y Y Y Y - - - Y - - - Y 1 1 1 1 1 GRAPHIC - - - - - - Y Y - - Y Y Y Y Y Y Y Y 1 1 1 1 1 VARGRAPHIC - - - - - - Y Y - - Y Y Y Y Y Y Y Y 1 1 LONG - - - - - - - - Y Y Y Y Y Y - - - Y VARGRAPHIC DBCLOB - - - - - - - - - Y1 Y Y Y Y - - - Y 1 1 DATE - - - - - - Y Y - - Y Y - - Y - - - 1 1 TIME - - - - - - Y Y - - Y Y - - - Y - - 1 1 TIMESTAMP - - - - - - Y Y - - Y Y - - Y Y Y - BLOB - - - - - - - - - - - - - - - - - Y Notas v Vea la descripción que precede a la tabla para conocer las conversiones soportadas donde intervienen tipos definidos por el usuario y tipos de referencia. v Sólo un tipo DATALINK puede convertirse a un tipo DATALINK. v No es posible convertir un valor de tipo estructurado en algo diferente. 1 Conversión sólo soportada para bases de datos Unicode. 124 Consulta de SQL, Volumen 1
- 151. Información relacionada: v “Expresiones” en la página 202 v “CREATE FUNCTION sentencia” en la publicación Consulta de SQL, Volumen 2 v “CURRENT PATH” en la página 172 v “Promoción de tipos de datos” en la página 120 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 125
- 152. Asignaciones y comparaciones Las operaciones básicas de SQL son la asignación y la comparación. Las operaciones de asignación se realizan durante la ejecución de sentencias de variables de transición INSERT, UPDATE, FETCH, SELECT INTO, VALUES INTO y SET. Los argumentos de las funciones también se asignan cuando se invoca una función. Las operaciones de comparación se realizan durante la ejecución de las sentencias que incluyen predicados y otros elementos del lenguaje como, por ejemplo, MAX, MIN, DISTINCT, GROUP BY y ORDER BY. Una regla básica para las dos operaciones es que el tipo de datos de los operandos implicados debe ser compatible. La regla de compatibilidad también se aplica a las operaciones de conjuntos. Otra regla básica para las operaciones de asignación es que no pueda asignarse un valor nulo a una columna que no pueda contener valores nulos, ni a una variable del lenguaje principal que no tenga una variable indicadora asociada. Sólo se da soporte a las asignaciones y comparaciones que implican datos tanto de caracteres como gráficos cuando una de las series es un literal. La matriz de compatibilidad a continuación que muestra las compatibilidades de tipos de datos para operaciones de asignación y comparación. Tabla 9. Compatibilidad de tipos de datos para asignaciones y comparaciones Operandos Entero Número Coma Serie de Serie Fecha Hora Indi- Serie UDT binario decimal flotante caracteres gráfica cación binaria de fecha y hora 2 Entero Sí Sí Sí No No No No No No binario 2 Número Sí Sí Sí No No No No No No decimal 2 Coma Sí Sí Sí No No No No No No flotante 6,7 1 1 1 3 2 Serie de No No No Sí Sí No caracteres 6,7 1 1 1 2 Serie No No No Sí Sí No gráfica 1 1 2 Fecha No No No Sí No No No 1 1 2 Hora No No No No Sí No No 126 Consulta de SQL, Volumen 1
- 153. Tabla 9. Compatibilidad de tipos de datos para asignaciones y comparaciones (continuación) Operandos Entero Número Coma Serie de Serie Fecha Hora Indi- Serie UDT binario decimal flotante caracteres gráfica cación binaria de fecha y hora 1 1 2 Indicación No No No No No Sí No de fecha y hora 3 2 Serie No No No No No No No No Sí binaria 2 2 2 2 2 2 2 2 2 UDT Sí 1 La compatibilidad de los valores de indicación de fecha y hora y de las series está limitada a la asignación y la comparación: v Los valores de fecha y hora se pueden asignar a las columnas de series y a las variables de series. v Una representación de serie válida de una fecha se puede asignar a una columna de fecha o comparar con una fecha. v Una representación de serie válida de una hora se puede asignar a una columna de hora o comparar con una hora. v Una representación de serie válida de una indicación de fecha y hora se puede asignar a una columna de indicación de fecha y hora o comparar con una indicación de fecha y hora. (El soporte a series gráficas sólo está disponible para bases de datos Unicode.) 2 Un valor de tipo diferenciado definido por el usuario sólo se puede comparar con un valor definido con el mismo tipo diferenciado definido por el usuario. En general, se da soporte a las asignaciones entre un valor de tipo diferenciado y su tipo de datos fuente. Un tipo estructurado definido por el usuario no es comparable y sólo se puede asignar a un operando del mismo tipo estructurado o a uno de sus subtipos. Para obtener más información, vea “Asignación de tipos definidos por el usuario” en la página 137. 3 Observe que esto significa que las series de caracteres definidas con el atributo FOR BIT DATA tampoco son compatibles con las series binarias. 4 Un operando DATALINK sólo puede asignarse a otro operando DATALINK. El valor DATALINK sólo puede asignarse a una columna si la columna está definida con NO LINK CONTROL o el archivo existe y todavía no está bajo el control del enlace del archivo. 5 Para obtener información sobre la asignación y comparación de tipos de referencia, consulte “Asignación de tipos de referencia” en la página 137 y “Comparaciones de tipos de referencia” en la página 144. 6 Sólo soportado para bases de datos Unicode. 7 Las series de datos de bits y gráficas no son compatibles. Capítulo 2. Elementos del lenguaje 127
- 154. Asignaciones numéricas La regla básica para las asignaciones numéricas es que la parte entera de un número decimal o entero no se trunca nunca. Si la escala del número de destino es menor que la escala del número asignado, se trunca el exceso de dígitos de la fracción de un número decimal. De decimal o entero a coma flotante: Los números de coma flotante son aproximaciones de números reales. Por lo tanto, cuando se asigna un número decimal o entero a una columna variable o de coma flotante, es posible que el resultado no sea idéntico al número original. De coma flotante o decimal a entero: Cuando un número de coma flotante o decimal se asigna a una columna o variable de enteros, se pierde la parte correspondiente a la fracción del número. De decimal a decimal: Cuando se asigna un número decimal a una columna o variable decimal, el número se convierte, si es necesario, a la precisión y escala del destino. Se añade o elimina el número necesario de ceros iniciales y, en la fracción del número, se añaden los ceros de cola necesarios o se eliminan los dígitos de cola necesarios. De entero a decimal: Cuando se asigna un entero a una columna o variable decimal, primero el número se convierte a un número decimal temporal y, después, si es necesario, a la precisión y escala del destino. La precisión y escala del número decimal temporal es de 5,0 para un entero pequeño, 11,0 para un entero grande o 19,0 para un entero superior. De coma flotante a decimal: Cuando se convierte un número de coma flotante a decimal, primero el número se convierte a un número decimal temporal de precisión 31 y después, si es necesario, se trunca a la precisión y escala del destino. En esta conversión, el número se redondea (utilizando la aritmética de coma flotante) a una precisión de 31 dígitos decimales. Como resultado, los números menores que 0,5*10-31 se reducen a 0. Se da a la escala el valor más grande posible que permita representar la parte entera del número sin pérdida de significación. Asignaciones de series Existen dos tipos de asignaciones: v La asignación de almacenamiento es cuando se asigna un valor a una columna o parámetro de una rutina. v La asignación de recuperación es cuando se asigna un valor a una variable del lenguaje principal. Las reglas para la asignación de series difieren según el tipo de asignación. 128 Consulta de SQL, Volumen 1
- 155. Asignación de almacenamiento: La regla básica es que la longitud de la serie asignada a una columna o a un parámetro de rutina no debe ser mayor que el atributo de longitud de la columna o del parámetro de rutina. Si la longitud de la serie es mayor que el atributo de longitud de la columna o del parámetro de rutina, se pueden producir las siguientes situaciones: v La serie se asigna con los blancos de cola truncados (de todos los tipos de serie excepto de las series largas) para ajustarse al atributo de longitud de la columna de destino o del parámetro de rutina v Se devuelve un error (SQLSTATE 22001) cuando: – Se truncarían caracteres que no son blancos de una serie que no es larga – Se truncaría cualquier carácter (o byte) de una serie larga. Si se asigna una serie a una columna de longitud fija y la longitud de la serie es menor que el atributo de longitud del destino, la serie se rellena por la derecha con el número necesario de blancos de un solo byte, de doble byte o UCS-2. El carácter de relleno siempre es el blanco, incluso para las columnas definidas con el atributo FOR BIT DATA. (UCS-2 define varios caracteres SPACE con distintas propiedades. Para una base de datos Unicode, el gestor de bases de datos siempre utilizará ASCII SPACE en la posición x’0020’ como blanco UCS-2. Para una base de datos EUC, se utiliza IDEOGRAPHIC SPACE en la posición x’3000’ para rellenar las series GRAPHIC.) Asignación de recuperación: La longitud de una serie asignada a una variable del lenguaje principal puede ser mayor que el atributo de longitud de la variable del lenguaje principal. Cuando una serie se asigna a una variable del lenguaje principal y la longitud de la serie es mayor que la longitud del atributo de longitud de la variable, la serie se trunca por la derecha el número necesario de caracteres (o bytes). Cuando ocurre esto, se devuelve un aviso (SQLSTATE 01004) y se asigna el valor ’W’ al campo SQLWARN1 de la SQLCA. Además, si se proporciona una variable indicadora y la fuente del valor no es LOB, la variable indicadora se establece en la longitud original de la serie. Si se asigna una serie de caracteres a una variable de longitud fija y la longitud de la serie es menor que el atributo de longitud del destino, la serie se rellena por la derecha con el número necesario de blancos de un solo byte, de doble byte o UCS-2. El carácter de relleno siempre es un blanco, incluso para las series definidas con el atributo FOR BIT DATA. (UCS-2 define varios caracteres SPACE con distintas propiedades. Para una base de datos Unicode, el gestor de bases de datos siempre utilizará ASCII SPACE en la posición x’0020’ como blanco UCS-2. Para una base de datos EUC, se utiliza IDEOGRAPHIC SPACE en la posición x’3000’ para rellenar las series GRAPHIC.) Capítulo 2. Elementos del lenguaje 129
- 156. La asignación de recuperación de las variables del lenguaje principal terminadas en nulo en C se maneja en base a las opciones especificadas con los mandatos PREP o BIND. Reglas de conversión para la asignación de series: Una serie de caracteres o una serie gráfica asignada a una columna o a una variable del lenguaje principal se convierte primero, si es necesario, a la página de códigos del destino. La conversión de los caracteres sólo es necesaria si son ciertas todas las afirmaciones siguientes: v Las páginas de códigos son diferentes. v La serie no es nula ni está vacía. v Ninguna serie tiene un valor de página de códigos de 0 (FOR BIT DATA). Para las bases de datos Unicode, las series de caracteres pueden asignarse a una columna gráfica y las series gráficas pueden asignarse a una columna de caracteres. Consideraciones de MBCS para la asignación de las series de caracteres: Existen varias consideraciones al asignar series de caracteres que pueden contener caracteres de un solo byte y de múltiples bytes. Estas consideraciones se aplican a todas las series de caracteres, incluyendo las definidas como FOR BIT DATA. v El relleno con blancos siempre se realiza utilizando el carácter blanco de un solo byte (X'20'). v El truncamiento de blancos siempre se realiza en base al carácter blanco de un solo byte (X'20'). El carácter blanco de doble byte se trata como cualquier otro carácter con respecto al truncamiento. v La asignación de una serie de caracteres a una variable del lenguaje principal puede dar como resultado la fragmentación de caracteres MBCS si la variable del lenguaje principal de destino no es lo suficientemente grande para contener toda la serie fuente. Si se fragmenta un carácter MBCS, cada byte del fragmento del carácter MBCS destino se establece en el destino en un carácter blanco de un solo byte (X'20'), no se mueven más bytes de la fuente y SQLWARN1 se establece en ’W’ para indicar el truncamiento. Observe que se aplica el mismo manejo de fragmentos de caracteres MBCS incluso cuando la serie de caracteres está definida como FOR BIT DATA. Consideraciones de DBCS para la asignación de las series gráficas: Las asignaciones de series gráficas se procesan de manera análoga a la de las series de caracteres. Para las bases de datos que no son Unicode, los tipos de datos de serie gráfica sólo son compatibles con otros tipos de datos de serie gráfica y nunca con tipos de datos numéricos, de serie de caracteres o de indicación de fecha y hora. Para las bases de Unicode, los tipos de datos de serie gráfica son compatibles con tipos de datos de serie de caracteres. 130 Consulta de SQL, Volumen 1
- 157. Si se asigna un valor de serie gráfica a una columna de serie gráfica, la longitud del valor no debe ser mayor que la longitud de la columna. Si un valor de serie gráfica (la serie ’fuente’) se asigna a un tipo de datos de serie gráfica de longitud fija (el ’destino’, que puede ser una columna o una variable del lenguaje principal), y la longitud de la serie fuente es menor que el destino, éste contendrá una copia de la serie fuente que se habrá rellenado por la derecha con el número necesario de caracteres blancos de doble byte para crear un valor cuya longitud sea igual a la del destino. Si se asigna un valor de serie gráfica a una variable de lenguaje principal de serie gráfica y la longitud de la serie fuente es mayor que la longitud de la variable del lenguaje principal, ésta contendrá una copia de la serie fuente que se habrá truncado por la derecha el número necesario de caracteres de doble byte para crear un valor cuya longitud sea igual al de la variable del lenguaje principal. (Tenga en cuenta que para este caso, es necesario que el truncamiento no implique la bisección de un carácter de doble byte; si hubiera que realizar una bisección, el valor fuente o la variable del lenguaje principal de destino tendrían un tipo de datos de serie gráfica mal definido.) El distintivo de aviso SQLWARN1 de SQLCA se establecerá en ’W’. La variable indicadora, si se especifica, contendrá la longitud original (en caracteres de doble byte) de la serie fuente. Sin embargo, en el caso de DBCLOB, la variable indicadora no contiene la longitud original. La asignación de recuperación de las variables del lenguaje principal terminadas en nulo en C (declaradas utilizando wchar_t) se maneja sobre la base de las opciones especificadas con los mandatos PREP o BIND. Asignaciones de fecha y hora La regla básica para las asignaciones de fecha y hora es que un valor DATE, TIME o TIMESTAMP sólo puede asignarse a una columna con un tipo de datos coincidente (ya sea DATE, TIME o TIMESTAMP), a una variable de serie de longitud variable o fija o a una columna de serie. La asignación no debe ser a una columna o variable LONG VARCHAR, CLOB, LONG VARGRAPHIC, DBCLOB ni BLOB. Cuando un valor de fecha y hora se asigna a una variable de serie o a una columna de serie, la conversión a una representación de serie es automática. Los ceros iniciales no se omiten de ninguna parte de la fecha, de la hora ni de la indicación de fecha y hora. La longitud necesaria del destino variará, según el formato de la representación de serie. Si la longitud del destino es mayor que la necesaria y el destino es una serie de longitud fija, se rellena por la derecha con blancos. Si la longitud del destino es menor que la necesaria, el resultado depende del tipo del valor de indicación de fecha y hora implicado y del tipo de destino. Capítulo 2. Elementos del lenguaje 131
- 158. Cuando el destino es una variable del lenguaje principal, se aplican las reglas siguientes: v Para DATE: Si la longitud de la variable es menor que 10 caracteres, se produce un error. v Para TIME: Si se utiliza el formato USA, la longitud de la variable no debe ser menor que 8 caracteres; en otros formatos la longitud no debe ser menor que 5 caracteres. Si se utilizan los formatos ISO o JIS, y la longitud de la variable del lenguaje principal es menor que 8 caracteres, la parte correspondiente a los segundos de la hora se omite del resultado y se asigna a la variable indicadora, si se proporciona. El campo SQLWARN1 de la SQLCA se establece de manera que indica la omisión. v Para TIMESTAMP: Si la variable del lenguaje principal es menor que 19 caracteres, se produce un error. Si la longitud es menor que 26 caracteres pero mayor o igual que 19 caracteres, los dígitos de cola de la parte correspondiente a los microsegundos del valor se omiten. El campo SQLWARN1 de la SQLCA se establece de manera que indica la omisión. Asignaciones de DATALINK La asignación de un valor a una columna DATALINK da como resultado el establecimiento de un enlace con un archivo a no ser que los atributos de enlace del valor estén vacíos o que la columna esté definida con NO LINK CONTROL. En los casos en que ya exista un valor enlazado en la columna, este archivo queda desenlazado. La asignación de un valor nulo donde ya existe un valor enlazado también desenlaza el archivo asociado con el valor anterior. Si la aplicación proporciona la misma ubicación de datos que la que ya existe en la columna, se retiene el enlace. Hay varias razones por las que puede producirse este hecho: v Se cambia el comentario. v Si la tabla se coloca en el estado de reconciliación de Datalink no posible (DRNP), pueden restablecerse los enlaces en la tabla al proporcionarse unos atributos de enlace idénticos a los de la columna. v Si la columna se define con WRITE PERMISSION ADMIN y se cambia el contenido del archivo, puede establecerse una versión nueva del enlace proporcionando un valor de DATALINK construido utilizando la función DLURLNEWCOPY con la misma ubicación de los datos. v Si la columna se define con WRITE PERMISSION ADMIN y se cambia el contenido del archivo pero el cambio debe restituirse, puede restituirse la versión existente del enlace proporcionando un valor de DATALINK construido utilizando la función DLURLPREVIOUSCOPY con la misma ubicación de los datos. 132 Consulta de SQL, Volumen 1
- 159. v El contenido del archivo al que se hace referencia se sustituye por otro archivo especificado en la función escalar DLURLREPLACECONTENT. Un valor DATALINK puede asignarse a una columna de cualquiera de las maneras siguientes: v Se puede utilizar la función escalar DLVALUE para crear un nuevo valor DATALINK y asignarlo a una columna. A no ser que el valor sólo contenga un comentario o que el URL sea exactamente el mismo, la acción de asignación enlazará el archivo. v Se puede crear un valor DATALINK en un parámetro de CLI con la función SQLBuildDataLink de CLI. A continuación, este valor puede asignarse a una columna. A no ser que el valor sólo contenga un comentario o que el URL sea exactamente el mismo, la acción de asignación enlazará el archivo. v Se puede utilizar la función escalar DLURLNEWCOPY para construir un valor de DATALINK y asignarlo a una columna. La ubicación de los datos a la que hace referencia el valor de DATALINK construido debe ser la misma que la que ya existe en la columna. Con la asignación mediante una sentencia UPDATE se restablece el enlace con el archivo. Se tomará una copia de seguridad del archivo si la columna se define con RECOVERY YES. Este tipo de asignación se utiliza para comunicar a la base de datos que el archivo se ha actualizado. Así se informa a la base de datos de la existencia del archivo nuevo y ésta restablecerá un enlace nuevo con el archivo. v Se puede utilizar la función escalar DLURLPREVIOUSCOPY para construir un valor de DATALINK y asignarlo a una columna. La ubicación de los datos a la que hace referencia el valor de DATALINK construido debe ser la misma que la que ya existe en la columna. Con la asignación mediante una sentencia UPDATE se restituye el enlace. También se restaurará el archivo en la versión anterior si la columna está definida con RECOVERY YES. Este tipo de asignación se utiliza para restituir los cambios realizados en el archivo desde la versión anterior confirmada. v Se puede utilizar la función escalar DLURLREPLACECONTENT para crear un nuevo valor DATALINK y asignarlo a una columna. Con la asignación no sólo se enlazará el archivo, sino que también se sustituirá el contenido con otro archivo especificado en la función escalar DLURLREPLACECONTENT. Cuando se asigna un valor a una columna DATALINK, las siguientes condiciones de error devuelven SQLSTATE 428D1: v El formato de la Ubicación de datos (URL) no es válido (código de razón 21). v El servidor de archivos no está registrado con esta base de datos (código de razón 22). v El tipo de enlace especificado no es válido (código de razón 23). Capítulo 2. Elementos del lenguaje 133
- 160. v La longitud del comentario o del URL no es válida (código de razón 27). Tenga en cuenta que el tamaño de un resultado de función o parámetro de URL es el mismo en la entrada y en la salida y que dicho tamaño está limitado por la longitud de la columna DATALINK. Sin embargo, en algunos casos el valor del URL se devuelve con un símbolo de accesos adjunto. En las situaciones en que esto sea posible, la ubicación de la salida debe tener espacio de almacenamiento suficiente para el símbolo de accesos y la longitud de la columna DATALINK. En consecuencia, la longitud real del comentario y del URL (en su formato totalmente ampliado) que se proporciona en la entrada debe restringirse para adaptarse al espacio de almacenamiento de la salida. Si se sobrepasa la longitud restringida, surge este error. v La ubicación de los datos de entrada no contiene un símbolo de escritura válido (código de razón 32). La asignación requiere que en la ubicación de los datos exista un símbolo de escritura válido. Este requisito sólo se aplica cuando la columna está definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE y el valor de DATALINK está construido mediante la función escalar DLURLNEWCOPY o DLURLPREVIOUSCOPY. Por otra parte, un usuario tiene la opción de proporcionar un símbolo de escritura para una columna DATALINK definida con WRITE PERMISSION ADMIN NOT REQUIRING TOKEN FOR UPDATE. Sin embargo, si el símbolo no es válido, se produce el mismo error. Este error también puede producirse al construir un valor de DATALINK si se utiliza la función escalar DLURLNEWCOPY o DLURLPREVIOUSCOPY con el valor ’1’ especificado en el segundo argumento pero el valor no contiene un símbolo de escritura válido. v El valor de DATALINK construido por la función escalar DLURLPREVIOUSCOPY sólo puede asignarse a una columna DATALINK definida con WRITE PERMISSION ADMIN y RECOVERY YES (código de razón 33). v El valor de DATALINK construido por la función escalar DLURLNEWCOPY o DLURLPREVIOUSCOPY no coincide con el valor que ya existe en la columna (código de razón 34). v El valor de DATALINK construido por la función escalar DLURLNEWCOPY o DLURLPREVIOUSCOPY no puede utilizarse en una sentencia INSERT para asignar un valor nuevo (código de razón 35). v El valor de DATALINK con DFS de esquema no puede asignarse a una columna DATALINK definida con WRITE PERMISSION ADMIN (código de razón 38). v El valor de DATALINK construido por la función escalar DLURLNEWCOPY no puede asignarse a una columna DATALINK definida con WRITE PERMISSION BLOCKED (código de razón 39). 134 Consulta de SQL, Volumen 1
- 161. v El mismo valor de DATALINK construido por la función escalar DLURLNEWCOPY o DLURLPREVIOUSCOPY no puede asignarse varias veces en la misma transacción (código de razón 41). v El valor de DATALINK construido por la función escalar DLURLREPLACECONTENT sólo puede asignarse a una columna DATALINK definida con NO LINK CONTROL si el segundo argumento es una serie vacía o un valor nulo (código de razón 42). v La operación de desenlace del archivo de sustitución especificado en la función escalar DLREPLACECONTENT no se ha confirmado (código de razón 43). v El archivo de sustitución especificado en la función escalar DLREPLACECONTENT se está utilizando en otro proceso de sustitución (código de razón 44). v El archivo que hace referencia a DATALINK se está utilizando como archivo de sustitución en otra operación (código de razón 45). v El formato del archivo de sustitución especificado en la función escalar DLREPLACECONTENT no es válido (código de razón 46). v El archivo de sustitución especificado en la función escalar DLREPLACECONTENT no puede ser un directorio ni un enlace simbólico (código de razón 47). v El archivo de sustitución especificado en la función escalar DLREPLACECONTENT se está enlazando con una base de datos (código de razón 48). v El gestor de archivos Data Links no puede encontrar el archivo de sustitución especificado en la función escalar DLREPLACECONTENT (código de razón 49). v El valor de DATALINK construido por la función escalar DLURLNEWCOPY con un símbolo de escritura contenido en el valor de ubicación de los datos sólo puede asignarse a una columna DATALINK con WRITE PERMISSION ADMIN (código de razón 50). Cuando la asignación también vaya a crear un enlace, pueden producirse los errores siguientes: v El servidor de archivos no está disponible actualmente (SQLSTATE 57050). v El archivo no existe (SQLSTATE 428D1, código de razón 24). v El archivo ya está enlazado con otra columna (SQLSTATE 428D1, código de razón 25). Tenga en cuenta que surgirá este error aunque el enlace sea con una base de datos diferente. v No se puede acceder al archivo de referencia para el enlace (código de razón 26). Capítulo 2. Elementos del lenguaje 135
- 162. v El símbolo de escritura intercalado en la ubicación de los datos no coincide con el símbolo de escritura utilizado para abrir el archivo (SQLSTATE 428D1, código de razón 36). v El archivo al que hace referencia el valor de DATALINK está en estado de actualización en proceso (SQLSTATE 428D1, código de razón 37). v La copia archivada anterior del archivo al que hace referencia el valor de DATALINK no está disponible (SQLSTATE 428D1, código de razón 40). Además, cuando la asignación elimine un enlace existente, pueden producirse los errores siguientes: v El servidor de archivos no está disponible actualmente (SQLSTATE 57050). v El archivo con control de integridad referencial no presenta un estado correcto según Data Links File Manager (SQLSTATE 58004). v El archivo al que hace referencia el valor de DATALINK está en estado de actualización en proceso (SQLSTATE 428D1, código de razón 37). Si al recuperar un valor de DATALINK para acceso de escritura (utilizando la función escalar DLURLCOMPLETEWRITE o DLURLPATHWRITE), la columna DATALINK se define con WRITE PERMISSION ADMIN, se comprueba el privilegio de acceso a directorios en el servidor de archivos (gestor de archivos DataLink). El usuario que envía la consulta debe tener la autorización para grabar en los archivos bajo dicho directorio antes de que se genere un símbolo de escritura y se intercale en el valor devuelto por DATALINK. Si el usuario no tiene autorización para grabar, no se generará ningún símbolo y la sentencia SELECT será insatisfactoria (SQLSTATE 42511, código de razón 1). Pueden asignarse partes de un valor de DATALINK a variables del lenguaje principal mediante la aplicación de funciones escalares como, por ejemplo, DLLINKTYPE o DLURLPATH). Tenga en cuenta que, normalmente, no se intenta acceder al servidor de archivos en el momento de la recuperación. Por lo tanto, es posible que fallen los intentos subsiguientes de acceso al servidor de archivos mediante mandatos de sistema de archivos. Puede que sea necesario acceder al servidor de archivos para determinar el nombre de prefijo asociado con una vía de acceso. Se puede cambiar en el servidor de archivos cuando se mueva el punto de montaje de un sistema de archivos. El primer acceso a un archivo de un servidor causará que se recuperen los valores necesarios del servidor de archivos y se coloquen en la antememoria del servidor de bases de datos para la subsiguiente recuperación de valores DATALINK de este servidor de archivos. Se devuelve un error si no se puede acceder al servidor de archivos (SQLSTATE 57050). 136 Consulta de SQL, Volumen 1
- 163. Si se utilizan las funciones escalares DLURLCOMPLETEWRITE o DLURLPATHWRITE para recuperar un valor de DATALINK, es posible que sea necesario acceder al servidor de archivos para determinar el privilegio de acceso a directorios que posee un usuario sobre una vía de acceso. Se devuelve un error si no se puede acceder al servidor de archivos (SQLSTATE 57050). Cuando se recupera un valor de DATALINK, se comprueba el registro de servidores de archivos en el servidor de bases de datos para confirmar que el servidor de archivos todavía está registrado con el servidor de bases de datos (SQLSTATE 55022). Además, es posible que se devuelva un aviso cuando se recupere un valor DATALINK por encontrarse la tabla en un estado pendiente de reconciliación o en un estado de reconciliación no posible (SQLSTATE 01627). Asignación de tipos definidos por el usuario Con los tipos definidos por el usuario, se aplican diferentes reglas para las asignaciones a variables del lenguaje principal que se utilizan para todas las asignaciones. Tipos diferenciados: La asignación a variables del lenguaje principal se realiza basándose en el tipo fuente del tipo diferenciado. Es decir, sigue la regla: v Un valor de un tipo diferenciado en el lado derecho de una asignación se puede asignar a una variable del lenguaje principal en el lado izquierdo sólo si el tipo fuente del tipo diferenciado se puede asignar a la variable del lenguaje principal. Si el destino de la asignación es una columna basada en un tipo diferenciado, el tipo de datos fuente debe ser convertible al tipo de datos de destino. Tipos estructurados: La asignación realizada con variables del lenguaje principal está basada en el tipo declarado de la variable del lenguaje principal; es decir, sigue la regla siguiente: Un valor de un tipo estructurado situado en el lado derecho de una asignación se puede asignar a una variable de lenguaje principal, situada en el lado izquierdo, sólo si el tipo declarado de la variable es el tipo estructurado o un supertipo del tipo estructurado. Si el destino de la asignación es una columna de un tipo estructurado, el tipo de datos fuente debe ser el tipo de datos destino o un subtipo de él. Asignación de tipos de referencia Un tipo de referencia cuyo tipo destino sea T se puede asignar a una columna de tipo de referencia que también es un tipo de referencia cuyo tipo destino sea S, donde S es un supertipo de T. Si se realiza una asignación a una columna o variable de referencia con ámbito, no tiene lugar ninguna Capítulo 2. Elementos del lenguaje 137
- 164. comprobación para asegurarse de que el valor real que se asigna exista en la tabla o vista de destino definidos por el ámbito. La asignación a variables del lenguaje principal tiene lugar sobre la base del tipo de representación del tipo de referencia. Es decir, sigue la regla: v Un valor de un tipo de referencia del lado derecho de una asignación puede asignarse a una variable del lenguaje principal del lado izquierdo si y sólo si el tipo de representación de este tipo de referencia puede asignarse a esta variable del lenguaje principal. Si el destino de la asignación es una columna y el lado derecho de la asignación es una variable del lenguaje principal, la variable del lenguaje principal debe convertirse explícitamente al tipo de referencia de la columna de destino. Comparaciones numéricas Los números se comparan algebraicamente; es decir, tomando en consideración el signo. Por ejemplo, −2 es menor que +1. Si un número es un entero y el otro es un decimal, la comparación se realiza con una copia temporal del entero, que se ha convertido a decimal. Cuando se comparan números decimales con escalas diferentes, la comparación se realiza con una copia temporal de uno de los números que se ha extendido con ceros de cola para que su parte correspondiente a la fracción tenga el mismo número de dígitos que el otro número. Si un número es de coma flotante y el otro es un entero o un decimal, la comparación se efectúa con una copia temporal del otro número, que se ha convertido a coma flotante de doble precisión. Dos números de coma flotante sólo son iguales si las configuraciones de bits de sus formatos normalizados son idénticos. Comparaciones de series Las series de caracteres se comparan de acuerdo con el orden de clasificación especificado cuando se ha creado la base de datos, excepto aquellos con el atributo FOR BIT DATA que siempre se comparan de acuerdo con sus valores de bits. Cuando se comparan series de caracteres de longitudes desiguales, la comparación se realiza utilizando una copia lógica de la serie más corta que se ha rellenado por la derecha con suficientes blancos de un solo byte para extender su longitud a la de la serie más larga. Esta extensión lógica se realiza para todas las series de caracteres incluyendo las que tienen el distintivo FOR BIT DATA. 138 Consulta de SQL, Volumen 1
- 165. Las series de caracteres (excepto las series de caracteres con el distintivo FOR BIT DATA) se comparan de acuerdo con el orden de clasificación especificado al crear la base de datos. Por ejemplo, el orden de clasificación por omisión proporcionado por el gestor de bases de datos puede dar el mismo peso a la versión en minúsculas y en mayúsculas del mismo carácter. El gestor de bases de datos realiza una comparación en dos pasos para asegurarse de que sólo se consideran iguales las series idénticas. En el primer paso, las series se comparan de acuerdo con el orden de clasificación de la base de datos. Si los pesos de los caracteres de las series son iguales, se realiza un segundo paso de ″desempate″ para comparar las series en base a sus valores de elemento de código real. Dos series son iguales si los dos están vacías o si todos los bytes correspondientes son iguales. Si cualquier operando es nulo, el resultado es desconocido. No se da soporte a las series largas ni a las series LOB las operaciones de comparación que utilizan operadores de comparación básicos (=, <>, <, >, <= y >=). Están soportadas en comparaciones que utilizan el predicado LIKE y la función POSSTR. Los fragmentos de series largas y series LOB de un máximo de 4.000 bytes se pueden comparar utilizando las funciones escalares SUBSTR y VARCHAR. Por ejemplo, si se tienen las columnas: MI_SHORT_CLOB CLOB(300) MI_LONG_VAR LONG VARCHAR entonces lo siguiente será válido: WHERE VARCHAR(MI_SHORT_CLOB) > VARCHAR(SUBSTR(MI_LONG_VAR,1,300)) Ejemplos: Para estos ejemplos, ’A’, ’Á’, ’a’ y ’á’, tienen los valores de elemento de código X’41’, X’C1’, X’61’ y X’E1’ respectivamente. Considere un orden de clasificación en el que los caracteres ’A’, ’Á’, ’a’, ’á’ tengan los pesos 136, 139, 135 y 138. Entonces, los caracteres se clasifican en el orden de sus pesos de la forma siguiente: ’a’ < ’A’ < ’á’ < ’Á’ Ahora considere cuatro caracteres DBCS D1, D2, D3 y D4 con los elementos de código 0xC141, 0xC161, 0xE141 y 0xE161, respectivamente. Si estos caracteres DBCS están en columnas CHAR, se clasifican como una secuencia de bytes según los pesos de clasificación de estos bytes. Los primeros bytes Capítulo 2. Elementos del lenguaje 139
- 166. tienen pesos de 138 y 139, por consiguiente D3 y D4 vienen antes que D2 y D1; los segundos bytes tienen pesos de 135 y 136. Por consiguiente, el orden es el siguiente: D4 < D3 < D2 < D1 Sin embargo, si los valores que se comparan tienen el atributo FOR BIT DATA o si estos caracteres DBCS se guardaron en una columna GRAPHIC, los pesos de clasificación no se tienen en cuenta y los caracteres se comparan de acuerdo con los elementos de código del modo siguiente: ’A’ < ’a’ < ’Á’ < ’á’ Los caracteres DBCS se clasifican como secuencia de bytes, en el orden de los elementos de código del modo siguiente: D1 < D2 < D3 < D4 Ahora considere un orden de clasificación en el que los caracteres ’A’, ’Á’, ’a’, ’á’ tengan los pesos (no exclusivos) 74, 75, 74 y 75. Si consideramos únicamente los pesos de clasificación (primer pase), ’a’ es igual a ’A’ y ’á’ es igual a ’Á’. Los elementos de código de los caracteres de utilizan para romper el empate (segundo pase) del modo siguiente: ’A’ < ’a’ < ’Á’ < ’á’ Los caracteres DBCS de las columnas CHAR se clasifican como una secuencia de bytes, de acuerdo con sus pesos (primer pase) y luego de acuerdo con los elementos de código para romper el empate (segundo pase). Los primeros bytes tienen pesos iguales, por lo tanto los elementos de código (0xC1 y 0xE1) rompen el empate. Por consiguiente, los caracteres D1 y D2 se clasifican antes que los caracteres D3 y D4. A continuación, se comparan los segundos bytes de una forma similar y el resultado es el siguiente: D1 < D2 < D3 < D4 Una vez más, si los datos de las columnas CHAR tienen el atributo FOR BIT DATA o si los caracteres DBCS se guardan en una columna GRAPHIC, los pesos de clasificación no se tienen en cuenta y se comparan los caracteres de acuerdo con los elementos de código: D1 < D2 < D3 < D4 Para este ejemplo en concreto, el resultado parece ser el mismo que cuando se utilizaron los pesos de clasificación, pero obviamente, éste no siempre es el caso. Reglas de conversión para la comparación: Cuando se comparan dos series, primero una de ellas se convierte, si es necesario, al esquema de codificación y a la página de códigos de la otra serie. 140 Consulta de SQL, Volumen 1
- 167. Clasificación de los resultados: Los resultados que necesitan clasificarse se ordenan en base a las reglas de comparación de series que se tratan en “Comparaciones de series” en la página 138. La comparación se efectúa en el servidor de bases de datos. Al devolver los resultados a la aplicación cliente, se puede llevar a cabo una conversión de la página de códigos. Esta conversión de la pagina de códigos subsiguiente no afecta al orden del conjunto resultante determinado por el servidor. Consideraciones de MBCS para la comparación de series: Las series de caracteres SBCS/MBCS mixtas se comparan de acuerdo con el orden de clasificación especificado cuando se ha creado la base de datos. Para las bases de datos creadas con el orden de clasificación (SYSTEM) por omisión, todos los caracteres ASCII de un solo byte se clasifican según el orden correcto, pero los caracteres de doble byte no se encuentran necesariamente por orden de elemento de código. Para las bases de datos creadas con el orden IDENTITY, todos los caracteres de doble byte se clasifican correctamente por orden de elemento de código, pero los caracteres ASCII de un solo byte también se clasifican por orden de elemento de código. Para las bases de datos creadas con el orden COMPATIBILITY, se utiliza un orden de acomodación que clasifica correctamente la mayoría de los caracteres de doble byte y resulta casi correcto para ASCII. Ésta era la tabla de clasificación por omisión en DB2 Versión 2. Las series de caracteres mixtas se comparan byte a byte. Esto puede provocar resultados anómalos para los caracteres de múltiples bytes que aparezcan en series mixtas, porque cada byte se toma en cuenta independientemente. Ejemplo: Para este ejemplo, los caracteres de doble byte ’A’, ’B’, ’a’ y ’b’ tienen los valores de elemento de código X'8260', X'8261', X'8281' y X'8282', respectivamente. Considere un orden de clasificación en el que los elementos de código X'8260', X'8261', X'8281' y X'8282' tengan los pesos 96, 65, 193 y 194. Entonces: ’B’ < ’A’ < ’a’ < ’b’ y ’AB’ < ’AA’ < ’Aa’ < ’Ab’ < ’aB’ < ’aA’ < ’aa’ < ’ab’ Las comparaciones de series gráficas se procesan de manera análoga a la de las series de caracteres. Capítulo 2. Elementos del lenguaje 141
- 168. Las comparaciones de series gráficas son válidas entre todos los tipos de datos de series gráficas excepto LONG VARGRAPHIC. Los tipos de datos LONG VARGRAPHIC y DBCLOB no están permitidos en una operación de comparación. Para series gráficas, el orden de clasificación de la base de datos no se utiliza. En su lugar, las series gráficas se comparan siempre en base a los valores numéricos (binarios) de sus bytes correspondientes. Utilizando el ejemplo anterior, si los literales fuesen series gráficas, entonces: ’A’ < ’B’ < ’a’ < ’b’ y ’AA’ < ’AB’ < ’Aa’ < ’Ab’ < ’aA’ < ’aB’ < ’aa’ < ’ab’ Cuando se comparan series gráficas de longitudes distintas, la comparación se realiza utilizando una copia lógica de la serie más corta que se ha rellenado por la derecha con suficientes caracteres blancos de doble byte para extender su longitud a la de la serie más larga. Dos valores gráficos son iguales si los dos están vacíos o si todos los gráficos correspondientes son iguales. Si cualquier operando es nulo, el resultado es desconocido. Si dos valores no son iguales, su relación se determina por una simple comparación de series binarias. Tal como se indica en esta sección, la comparación de series byte a byte puede producir resultados insólitos; es decir, un resultado que difiere de lo que se espera en una comparación carácter a carácter. Los ejemplos que se muestran suponen que se utiliza la misma página de códigos MBCS, sin embargo, la situación puede complicarse más cuando se utilizan distintas páginas de códigos de múltiples bytes con el mismo idioma nacional. Por ejemplo, considere el caso de la comparación de una serie de una página de códigos DBCS japonesa y una página de códigos EUC japonesa. Comparaciones de fecha y hora Un valor DATE, TIME o TIMESTAMP puede compararse con otro valor del mismo tipo de datos o con una representación de serie de dicho tipo de datos. Todas las comparaciones son cronológicas, lo que significa que cuanto más alejado en el tiempo esté del 1 de enero de 0001, mayor es el valor de dicho punto en el tiempo. Las comparaciones que implican valores TIME y representaciones de serie de valores de hora siempre incluyen los segundos. Si la representación de serie omite los segundos, se implica que son cero segundos. 142 Consulta de SQL, Volumen 1
- 169. Las comparaciones que implican valores TIMESTAMP son cronológicas sin tener en cuenta las representaciones que puedan considerarse equivalentes. Ejemplo: TIMESTAMP(’1990-02-23-00.00.00’) > ’1990-02-22-24.00.00’ Comparaciones de tipos definidos por el usuario Los valores con un tipo diferenciado definido por el usuario sólo se pueden comparar con valores que sean exactamente del mismo tipo diferenciado definido por el usuario. El tipo diferenciado definido por el usuario debe haberse definido utilizando la cláusula WITH COMPARISONS. Ejemplo: Considere por ejemplo el siguiente tipo diferenciado YOUTH y la tabla CAMP_DB2_ROSTER: CREATE DISTINCT TYPE YOUTH AS INTEGER WITH COMPARISONS CREATE TABLE CAMP_DB2_ROSTER ( NAME VARCHAR(20), ATTENDEE_NUMBER INTEGER NOT NULL, AGE YOUTH, HIGH_SCHOOL_LEVEL YOUTH) La comparación siguiente es válida: SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > HIGH_SCHOOL_LEVEL La comparación siguiente no es válida: SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > ATTENDEE_NUMBER Sin embargo, AGE se puede comparar con ATTENDEE_NUMBER utilizando una función o una especificación CAST para convertir entre el tipo diferenciado y el tipo fuente. Todas las comparaciones siguientes son válidas: SELECT * FROM CAMP_DB2_ROSTER WHERE INTEGER(AGE) > ATTENDEE_NUMBER SELECT * FROM CAMP_DB2_ROSTER WHERE CAST( AGE AS INTEGER) > ATTENDEE_NUMBER SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > YOUTH(ATTENDEE_NUMBER) SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > CAST(ATTENDEE_NUMBER AS YOUTH) Capítulo 2. Elementos del lenguaje 143
- 170. Los valores con un tipo estructurado definido por el usuario no se pueden comparar con ningún otro valor (se pueden utilizar los predicados NULL y TYPE). Comparaciones de tipos de referencia Los valores de un tipo de referencia sólo pueden compararse si sus tipos de destino tienen un supertipo común. Sólo se encontrará la función de comparación adecuada si el nombre de esquema del supertipo común se incluye en la vía de acceso de la función. Se realiza la comparación si se utiliza el tipo de representación de los tipos de referencia. El ámbito de la referencia no se tiene en cuenta en la comparación. Información relacionada: v “Identificadores” en la página 71 v “Predicado LIKE” en la página 255 v “POSSTR” en la página 450 v “Valores de fecha y hora” en la página 110 v “Conversiones entre tipos de datos” en la página 122 v “Reglas para los tipos de datos del resultado” en la página 145 v “Reglas para la conversión de series” en la página 150 144 Consulta de SQL, Volumen 1
- 171. Reglas para los tipos de datos del resultado Los tipos de datos de un resultado los determinan las reglas que se aplican a los operandos de una operación. Esta sección explica dichas reglas. Estas reglas se aplican a: v Las columnas correspondientes en selecciones completas de operaciones de conjuntos (UNION, INTERSECT y EXCEPT) v Expresiones resultantes de una expresión CASE v Los argumentos de la función escalar COALESCE (o VALUE) v Los valores de expresiones de la lista de entrada de un predicado IN v Las expresiones correspondientes de una cláusula VALUES de múltiples filas. Estas reglas se aplican, sujetas a otras restricciones, sobre series largas para las distintas operaciones. A continuación encontrará las reglas que se refieren a los distintos tipos de datos. En algunos casos, se utiliza una tabla para mostrar los posibles tipos de datos resultantes. Estas tablas identifican el tipo de datos resultante, incluida la longitud aplicable o precisión y la escala. El tipo resultante se determina teniendo en cuenta los operandos. Si hay más de un par de operandos, empiece considerando el primer par. Esto da un tipo resultante que es el que se examina con el siguiente operando para determinar el siguiente tipo resultante, etcétera. El último tipo resultante intermedio y el último operando determinan el tipo resultante para la operación. El proceso de operaciones se realiza de izquierda a derecha, por lo tanto los tipos del resultado intermedios son importantes cuando se repiten operaciones. Por ejemplo, examinemos una situación que implique: CHAR(2) UNION CHAR(4) UNION VARCHAR(3) El primer par da como resultado un tipo CHAR(4). Los valores del resultado siempre tienen 4 caracteres. El tipo resultante final es VARCHAR(4). Los valores del resultado de la primera operación UNION siempre tendrán una longitud de 4. Series de caracteres Las series de caracteres son compatibles con otras series de caracteres. Las series de caracteres incluyen los tipos CHAR, VARCHAR, LONG VARCHAR y CLOB. Capítulo 2. Elementos del lenguaje 145
- 172. Si un operando es... Y el otro operando es... El tipo de datos del resultado es... CHAR(x) CHAR(y) CHAR(z) donde z = max(x,y) CHAR(x) VARCHAR(y) VARCHAR(z) donde z = max(x,y) VARCHAR(x) CHAR(y) o VARCHAR(z) donde z = max(x,y) VARCHAR(y) LONG VARCHAR CHAR(y), LONG VARCHAR VARCHAR(y) o LONG VARCHAR CLOB(x) CHAR(y), CLOB(z) donde z = max(x,y) VARCHAR(y) o CLOB(y) CLOB(x) LONG VARCHAR CLOB(z) donde z = max(x,32700) La página de códigos de la serie de caracteres del resultado se derivará en base a las reglas de conversión de series. Series gráficas Las series gráficas son compatibles con otras series gráficas. Las series gráficas incluyen los tipos de datos GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC y DBCLOB. Si un operando es... Y el otro operando es... El tipo de datos del resultado es... GRAPHIC(x) GRAPHIC(y) GRAPHIC(z) donde z = max(x,y) VARGRAPHIC(x) GRAPHIC(y) o VARGRAPHIC(z) donde z = VARGRAPHIC(y) max(x,y) LONG VARGRAPHIC GRAPHIC(y), LONG VARGRAPHIC VARGRAPHIC(y) o LONG VARGRAPHIC DBCLOB(x) GRAPHIC(y), DBCLOB(z) donde z = max (x,y) VARGRAPHIC(y) o DBCLOB(y) DBCLOB(x) LONG VARGRAPHIC DBCLOB(z) donde z = max (x,16350) La página de códigos de la serie gráfica del resultado se derivará en base a las reglas de conversión de series. Series de caracteres y gráficas en una base de datos Unicode En una base de datos Unicode, las series de caracteres y las series gráficas son compatibles. 146 Consulta de SQL, Volumen 1
- 173. Si un operando es... Y el otro operando es... El tipo de datos del resultado es... GRAPHIC(x) CHAR(y) o GRAPHIC(z) donde z = max(x,y) GRAPHIC(y) VARGRAPHIC(x) CHAR(y) o VARGRAPHIC(z) donde z = VARCHAR(y) max(x,y) VARCHAR(x) GRAPHIC(y) o VARGRAPHIC(z) donde z = VARGRAPHIC max(x,y) LONG VARGRAPHIC CHAR(y) o LONG VARGRAPHIC VARCHAR(y) o LONG VARCHAR LONG VARCHAR GRAPHIC(y) o LONG VARGRAPHIC VARGRAPHIC(y) DBCLOB(x) CHAR(y) o DBCLOB(z) donde z = max (x,y) VARCHAR(y) o CLOB(y) DBCLOB(x) LONG VARCHAR DBCLOB(z) donde z = max (x,16350) CLOB(x) GRAPHIC(y) o DBCLOB(z) donde z = max (x,y) VARGRAPHIC(y) CLOB(x) LONG VARGRAPHIC DBCLOB(z) donde z = max (x,16350) Gran objeto binario (BLOB) Un BLOB sólo es compatible con otro BLOB y el resultado es un BLOB. La función escalar BLOB puede utilizarse para convertir desde otros tipos si éstos deben tratarse como tipos BLOB. La longitud del resultado BLOB es la longitud mayor de todos los tipos de datos. Numérico Los tipos numéricos son compatibles con otros tipos numéricos. Los tipos numéricos incluyen SMALLINT, INTEGER, BIGINT,DECIMAL, REAL y DOUBLE. Si un operando es... Y el otro operando es... El tipo de datos del resultado es... SMALLINT SMALLINT SMALLINT INTEGER INTEGER INTEGER INTEGER SMALLINT INTEGER BIGINT BIGINT BIGINT BIGINT INTEGER BIGINT BIGINT SMALLINT BIGINT Capítulo 2. Elementos del lenguaje 147
- 174. Si un operando es... Y el otro operando es... El tipo de datos del resultado es... DECIMAL(w,x) SMALLINT DECIMAL(p,x) donde p = x+max(w-x,5)1 DECIMAL(w,x) INTEGER DECIMAL(p,x) donde p = x+max(w-x,11)1 DECIMAL(w,x) BIGINT DECIMAL(p,x) donde p = x+max(w-x,19)1 DECIMAL(w,x) DECIMAL(y,z) DECIMAL(p,s) donde p = max(x,z)+max(w-x,y-z)1s = max(x,z) REAL REAL REAL REAL DECIMAL, BIGINT, DOUBLE INTEGER o SMALLINT DOUBLE cualquier tipo numérico DOUBLE 1 La precisión no puede exceder de 31. DATE Una fecha es compatible con otra fecha o con cualquier expresión CHAR o VARCHAR que contiene una representación de serie válida de una fecha. El tipo de datos del resultado es DATE. TIME Una hora es compatible con otra hora o con cualquier expresión CHAR o VARCHAR que contenta una representación de serie válida de una hora. El tipo de datos del resultado es TIME. TIMESTAMP Una indicación de fecha y hora es compatible con otra indicación de fecha y hora o con cualquier expresión CHAR o VARCHAR que contenga una representación de serie válida de una indicación de fecha y hora. El tipo de datos del resultado es TIMESTAMP. DATALINK Un enlace de datos es compatible con otro enlace de datos. El tipo de datos del resultado es DATALINK. La longitud del resultado DATALINK es la longitud mayor de todos los tipos de datos. Tipos definidos por el usuario Tipos diferenciados: Un tipo diferenciado definido por el usuario sólo es compatible con el mismo tipo diferenciado definido por el usuario. El tipo de datos del resultado es el tipo diferenciado definido por el usuario. 148 Consulta de SQL, Volumen 1
- 175. Tipos de referencia: Un tipo de referencia es compatible con otro tipo de referencia en el caso de que sus tipos de destino tengan un supertipo común. El tipo de datos del resultado es un tipo de referencia que tiene un supertipo común como tipo de destino. Si todos los operandos tienen la tabla de ámbito idéntica, el resultado tiene esta tabla de ámbito. De lo contrario, el resultado no tiene ámbito. Tipos estructurados: Un tipo estructurado es compatible con otro tipo de estructurado siempre tengan un supertipo común. El tipo de datos estático de la columna del tipo estructurado resultante es el tipo estructurado que es el supertipo menos común de cualquiera de las dos columnas. Por ejemplo, considere la siguiente jerarquía de tipos estructurados: A / B C / D E / F G Los tipos estructurados del tipo estático E y F son compatibles con el tipo estático resultante de B, que es el supertipo menos común de E y F. Atributo con posibilidad de nulos del resultado A excepción de INTERSECT y EXCEPT, el resultado permite nulos a menos que ambos operandos no permitan nulos. v Para INTERSECT, si cualquier operando no permite nulos, el resultado no permite nulos (la intersección nunca sería nula). v Para EXCEPT, si el primer operando no permite nulos, el resultado no permite nulos (el resultado sólo puede ser valores del primer operando). Información relacionada: v “BLOB” en la página 321 v “Reglas para la conversión de series” en la página 150 Capítulo 2. Elementos del lenguaje 149
- 176. Reglas para la conversión de series La página de códigos utilizada para realizar una operación se determina por las reglas que se aplican a los operandos en dicha operación. Esta sección explica dichas reglas. Estas reglas se aplican a: v Las columnas de serie correspondientes en selecciones completas con operaciones de conjuntos (UNION, INTERSECT y EXCEPT) v Los operandos de concatenación v Los operandos de predicados (a excepción de LIKE) v Expresiones resultantes de una expresión CASE v Los argumentos de la función escalar COALESCE (y VALUE) v Los valores de expresiones de la lista de entrada de un predicado IN v Las expresiones correspondientes de una cláusula VALUES de múltiples filas. En cada caso, la página de códigos del resultado se determina en el momento del enlace, y la ejecución de la operación puede implicar la conversión de series a la página de códigos identificada por dicha página de códigos. Un carácter que no tenga una conversión válida se correlaciona con el carácter de sustitución del juego de caracteres y SQLWARN10 se establece en ’W’ en la SQLCA. La página de códigos del resultado se determina por las páginas de códigos de los operandos. Las páginas de códigos de los dos primeros operandos determinan una página de códigos del resultado intermedia, esta página de códigos y la del siguiente operando determinan una nueva página de códigos del resultado intermedia (si se aplica), etcétera. La última página de códigos del resultado intermedia y la página de códigos del último operando determinan la página de códigos de la serie o columna del resultado. En cada par de páginas de códigos, el resultado se determina por la aplicación secuencial de las reglas siguientes: v Si las páginas de códigos son iguales, el resultado es dicha página de códigos. v Si cualquiera de las dos páginas de códigos es BIT DATA (página de códigos 0), la página de códigos del resultado es BIT DATA. v En una base de datos Unicode, si una página de códigos denota datos en un esquema de codificación que es distinto de la otra página de códigos, el resultado es UCS-2 sobre UTF-8 (es decir, los datos de tipo gráfico sobre los datos de tipo carácter). (En una base de datos que no sea Unicode, no se permite la conversión entre distintos esquemas de codificación. 150 Consulta de SQL, Volumen 1
- 177. v Para los operandos que son variables del lenguaje principal (cuya página de códigos no es BIT DATA), la página de códigos resultante es la página de códigos de la base de datos. Los datos de entrada de este tipo de variables del lenguaje principal se convierten de la página de códigos de la aplicación a la página de códigos de la base de datos antes de utilizarse. Las conversiones a la página de códigos del resultado se realizan, si es necesario, para: v Un operando del operador de concatenación v El argumento seleccionado de la función escalar COALESCE (o VALUE) v La expresión del resultado seleccionada de la expresión CASE v Las expresiones de la lista in del predicado IN v Las expresiones correspondientes de una cláusula VALUES de múltiples filas v Las columnas correspondientes que hacen referencia en operaciones de conjuntos. La conversión de los caracteres es necesaria si son ciertas todas las afirmaciones siguientes: v Las páginas de códigos son diferentes v Ninguna serie es BIT DATA v La serie no es nula ni está vacía Ejemplos Ejemplo 1: Suponga lo siguiente en una base de datos creada con la página de códigos 850: Expresión Tipo Página de códigos COL_1 columna 850 HV_2 variable del lenguaje 437 principal Cuando se evalúa el predicado: COL_1 CONCAT :HV_2 la página de códigos del resultado de los dos operandos es 850, porque los datos de variables del lenguaje principal se convertirán a página de códigos de la base de datos antes de utilizarse. Ejemplo 2: Utilizando la información del ejemplo anterior para evaluar el predicado: Capítulo 2. Elementos del lenguaje 151
- 178. COALESCE(COL_1, :HV_2:NULLIND,) la página de códigos del resultado es 850. Por lo tanto, la página de códigos del resultado para la función escalar COALESCE será la página de códigos 850. 152 Consulta de SQL, Volumen 1
- 179. Tipos de datos compatibles entre particiones La compatibilidad entre particiones se define entre los tipos de base de datos de las columnas correspondientes de las claves de particionamiento. Los tipos de datos compatibles entre particiones tienen la propiedad de que dos variables, una de cada tipo, con el mismo valor, se correlacionan con el mismo índice de mapa de particionamiento por la misma función de partición. La Tabla 10 muestra la compatibilidad de los tipos de datos en particiones. La compatibilidad entre particiones tiene las características siguientes: v Se utilizan formatos internos para DATE, TIME y TIMESTAMP. No son compatibles entre sí y ninguno es compatible con CHAR. v La compatibilidad entre particiones no se ve afectada por las columnas con definiciones NOT NULL o FOR BIT DATA. v Los valores NULL de los tipos de datos compatibles se tratan de manera idéntica. Se pueden generar resultados diferentes para los valores NULL de tipos de datos no compatibles. v Se utiliza el tipo de datos base del UDT para analizar la compatibilidad entre particiones. v Los decimales del mismo valor de la clave de particionamiento se tratan de manera idéntica, incluso si difieren su escala y precisión. v La función de generación aleatoria proporcionada por el sistema ignora los blancos de cola de las series de caracteres (CHAR, VARCHAR, GRAPHIC o VARGRAPHIC). v CHAR o VARCHAR de diferentes longitudes son tipos de datos compatibles. v Los valores REAL o DOUBLE se tratan de manera idéntica incluso si su precisión es diferente. Tabla 10. Compatibilidades entre particiones Operan- Entero Número Coma Serie de Serie Fecha Hora Indi- Tipo Tipo dos binario decimal flotante caracteres gráfica cación diferen- estruc- de ciado turado fecha y hora 1 Entero Sí No No No No No No No No binario 1 Número No Sí No No No No No No No decimal 1 Coma No No Sí No No No No No No flotante Capítulo 2. Elementos del lenguaje 153
- 180. Tabla 10. Compatibilidades entre particiones (continuación) Operan- Entero Número Coma Serie de Serie Fecha Hora Indi- Tipo Tipo dos binario decimal flotante caracteres gráfica cación diferen- estruc- de ciado turado fecha y hora Serie de No No No Sí2 No No No No 1 No caracteres3 1 Serie No No No No Sí No No No No gráfica3 1 Fecha No No No No No Sí No No No 1 Hora No No No No No No Sí No No 1 Indicación No No No No No No No Sí No de fecha y hora 1 1 1 1 1 1 1 1 1 Tipo No diferenciado Tipo No No No No No No No No No No estructurado3 Nota: 1 El valor de un tipo diferenciado definido por el usuario (UDT) es compatible, a nivel de partición, con el tipo fuente del UDT o cualquier otro UDT con un tipo fuente compatible a nivel de partición. 2 El atributo FOR BIT DATA no afecta a la compatibilidad entre particiones. 3 Observe que los tipos estructurados definidos por el usuario y los tipos de datos LONG VARCHAR, LONG VARGRAPHIC, CLOB, DBCLOB y BLOB no son aplicables para la compatibilidad de particiones, pues no están soportados en las claves de particionamiento. 154 Consulta de SQL, Volumen 1
- 181. Constantes Una constante (a veces llamada un literal) especifica un valor. Las constantes se clasifican en constantes de tipo serie y constantes numéricas. Las constantes numéricas pueden, a su vez, ser constantes enteras, de coma flotante y decimales. Todas las constantes tienen el atributo NOT NULL. Un valor de cero negativo en una constante numérica (-0) indica el mismo valor que un cero sin el signo (0). Los tipos definidos por el usuario son difíciles de escribir. Esto significa que un tipo definido por el usuario sólo es compatible con su propio tipo. Sin embargo, una constante tiene un tipo interno. Por lo tanto, una operación que implique un tipo definido por el usuario y una constante sólo es posible si el tipo definido por el usuario se ha convertido al tipo interno de la constante o si la constante se ha convertido al tipo definido por el usuario. Por ejemplo, si se utiliza la tabla y el tipo diferenciado del apartado “Comparaciones de tipos definidos por el usuario” en la página 143, serán válidas las siguientes comparaciones con la constante 14: SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > CAST(14 AS YOUTH) SELECT * FROM CAMP_DB2_ROSTER WHERE CAST(AGE AS INTEGER) > 14 No será válida la siguiente comparación: SELECT * FROM CAMP_DB2_ROSTER WHERE AGE > 14 Constantes enteras Una constante entera especifica un entero en forma de número, con signo o sin signo, con un máximo de 19 dígitos que no incluye ninguna coma decimal. El tipo de datos de una constante entera es entero grande si su valor está comprendido en el rango de un entero grande. El tipo de datos de una constante entera es un entero superior si su valor se encuentra fuera del rango de un entero grande, pero está comprendido en el rango de un entero superior. Una constante definida fuera del rango de valores enteros superior se considera una constante decimal. Observe que la representación literal más pequeña de una constante entera grabde es -2 147 483 647, y no -2 147 483 648, que es el límite para los valores enteros. De manera similar, la representación literal más pequeña de una constante entera superior es -9 223 372 036 854 775 807, y no -9 223 372 036 854 775 808, que es el límite para los valores enteros superiores. Capítulo 2. Elementos del lenguaje 155
- 182. Ejemplos: 64 -15 +100 32767 720176 12345678901 En los diagramas de sintaxis, el término 'entero' se utiliza para una constante entera grande que no debe incluir un signo. Constantes de coma flotante Una constante de coma flotante especifica un número de coma flotante en forma de dos números separados por una E. El primer número puede incluir un signo y una coma decimal; el segundo número puede incluir un signo, pero no una coma decimal. El tipo de datos de una constante de coma flotante es de precisión doble. El valor de la constante es el producto del primer número y la potencia de 10 especificada por el segundo número; este valor debe estar dentro del rango de los números de coma flotante. El número de caracteres de la constante no debe exceder de 30. Ejemplos: 15E1 2,E5 2,2E-1 +5,E+2 Constantes decimales Una constante decimal es un número con o sin signo de 31 dígitos de longitud como máximo y que incluye una coma decimal o no está comprendido dentro del rango de enteros binarios. Debe estar comprendido en el rango de números decimales. La precisión es el número total de dígitos (incluyendo los ceros iniciales y de cola); la escala es el número de dígitos situados a la derecha de la coma decimal (incluyendo los ceros de cola). Ejemplos: 25,5 1000, -15, +37589,3333333333 Constantes de series de caracteres Una constante de serie de caracteres especifica una serie de caracteres de longitud variable y consta de una secuencia de caracteres que empieza y finaliza por un apóstrofo ('). Esta modalidad de constante de tipo serie especifica la serie de caracteres contenida entre los delimitadores de series. La longitud de la serie de caracteres no debe ser mayor que 32.672 bytes. Se utilizan dos delimitadores de series consecutivos para representar un delimitador de series dentro de la serie de caracteres. Ejemplos: '12/14/1985' '32' 'DON''T CHANGE' El valor de una constante se convierte siempre en la página de códigos de la base de datos cuando se vincula con la base de datos. Se considera que está 156 Consulta de SQL, Volumen 1
- 183. en la página de códigos de la base de datos. Por lo tanto, si se utiliza en una expresión que combina una constante con una columna FOR BIT DATA y cuyo resultado es FOR BIT DATA, el valor de la constante no se convertirá desde su representación de página de códigos de base de datos. Constantes hexadecimales Una constante hexadecimal especifica una serie de caracteres de longitud variable de la página de códigos del servidor de aplicaciones. El formato de una constante hexadecimal es una X seguida por una secuencia de caracteres que empieza y termina con un apóstrofo ('). Los caracteres que se incluyen entre los apóstrofos deben corresponder a una cantidad par de dígitos hexadecimales. El número de dígitos hexadecimales no debe exceder de 16.336 o, de lo contrario, se producirá un error (SQLSTATE -54002). Un dígito hexadecimal representa 4 bits. Se especifica como un dígito o cualquiera de las letras de la ″A″ a la ″F″ (en mayúsculas o en minúsculas), donde A representa el patrón de bits '1010', B representa '1011', etc. Si una constante hexadecimal no tiene el formato correcto (por ejemplo, contiene un dígito hexadecimal no válido o un número impar de dígitos hexadecimales), se genera un error (SQLSTATE 42606). Ejemplos: X'FFFF' que representa el patrón de bits '1111111111111111' X'4672616E6B' que representa el patrón VARCHAR de la serie ASCII 'Frank' Constantes de series gráficas Una constante de serie gráfica especifica una serie gráfica de longitud variable que consta de una secuencia de caracteres de doble byte que empieza y termina con un apóstrofo de un solo byte (') y que está precedida por una G o una N de un solo byte. Los caracteres entre los apóstrofos deben representar un número par de bytes y la longitud de la serie gráfico no debe sobrepasar los 16 336 bytes. Ejemplos: G'serie de caracteres de doble byte' N'serie de caracteres de doble byte' El apóstrofo no debe aparecer como parte de un carácter MBCS para que se considere como delimitador. Información relacionada: v “Expresiones” en la página 202 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 157
- 184. Registros especiales Registros especiales Un registro especial es un área de almacenamiento que el gestor de bases de datos define para un proceso de aplicación. Se utiliza para almacenar información a la que se puede hacer referencia en sentencias de SQL. Los registros especiales se encuentran en la página de códigos de la base de datos. El nombre de un registro especial puede especificarse con el carácter de subrayado; por ejemplo, CURRENT_DATE. Algunos registros especiales puede actualizarse utilizando la sentencia SET. La tabla siguiente muestra cuáles de estos registros especiales pueden actualizarse. Tabla 11. Registros especiales actualizables Registro especial Actualizable CLIENT ACCTNG Sí CLIENT APPLNAME Sí CLIENT USERID Sí CLIENT WRKSTNNAME Sí CURRENT DATE No CURRENT DBPARTITIONNUM No CURRENT DEFAULT TRANSFORM GROUP Sí CURRENT DEGREE Sí CURRENT EXPLAIN MODE Sí CURRENT EXPLAIN SNAPSHOT Sí CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION Sí CURRENT PATH Sí CURRENT QUERY OPTIMIZATION Sí CURRENT REFRESH AGE Sí CURRENT SCHEMA Sí CURRENT SERVER No CURRENT TIME No CURRENT TIMESTAMP No CURRENT TIMEZONE No USER No 158 Consulta de SQL, Volumen 1
- 185. Cuando se hace referencia a un registro especial en una rutina, el valor del registro especial de la rutina depende de si el registro especial es actualizable o no. Para registros especiales no actualizables, el valor se define en el valor por omisión del registro especial. Para registros especiales actualizables, el valor inicial se hereda del invocador de la rutina y puede modificarse con una sentencia SET posterior dentro de la rutina. Capítulo 2. Elementos del lenguaje 159
- 186. CLIENT ACCTNG El registro especial CLIENT ACCTNG contiene el valor de la serie de contabilidad de la información de cliente especificada para esta conexión. El tipo de datos del registro es VARCHAR(255). El valor por omisión de este registro es una serie vacía. El valor de la serie de contabilidad puede cambiarse utilizando la API para Establecer información de cliente (sqleseti). Tenga en cuenta que el valor proporcionado a través de la API sqleseti está en la página de códigos de aplicación y el valor del registro especial se almacena en la página de códigos de base de datos. En función de los valores de datos utilizados al establecer la información de cliente, puede que, durante la conversión de la página de códigos, se produzca el truncamiento del valor de datos almacenado en el registro especial. Ejemplo: Obtenga el valor actual de la serie de contabilidad para esta conexión. VALUES (CLIENT ACCTNG) INTO :ACCT_STRING 160 Consulta de SQL, Volumen 1
- 187. CLIENT APPLNAME El registro especial CLIENT APPLNAME contiene el valor del nombre de aplicación de la información de cliente especificada para esta conexión. El tipo de datos del registro es VARCHAR(255). El valor por omisión de este registro es una serie vacía. El valor del nombre de aplicación puede cambiarse utilizando la API para Establecer información de cliente (sqleseti). Tenga en cuenta que el valor proporcionado a través de la API sqleseti está en la página de códigos de aplicación y el valor del registro especial se almacena en la página de códigos de base de datos. En función de los valores de datos utilizados al establecer la información de cliente, puede que, durante la conversión de la página de códigos, se produzca el truncamiento del valor de datos almacenado en el registro especial. Ejemplo: Seleccione los departamentos a los que se les permite utilizar la aplicación que se está usando en esta conexión. SELECT DEPT FROM DEPT_APPL_MAP WHERE APPL_NAME = CLIENT APPLNAME Capítulo 2. Elementos del lenguaje 161
- 188. CLIENT USERID El registro especial CLIENT USERID contiene el valor del ID de usuario de cliente de la información de cliente especificada para esta conexión. El tipo de datos del registro es VARCHAR(255). El valor por omisión de este registro es una serie vacía. El valor del ID de usuario de cliente puede cambiarse utilizando la API para Establecer información de cliente (sqleseti). Tenga en cuenta que el valor proporcionado a través de la API sqleseti está en la página de códigos de aplicación y el valor del registro especial se almacena en la página de códigos de base de datos. En función de los valores de datos utilizados al establecer la información de cliente, puede que, durante la conversión de la página de códigos, se produzca el truncamiento del valor de datos almacenado en el registro especial. Ejemplo: Averigüe en qué departamento funciona el ID de usuario de cliente actual. SELECT DEPT FROM DEPT_USERID_MAP WHERE USER_ID = CLIENT USERID 162 Consulta de SQL, Volumen 1
- 189. CLIENT WRKSTNNAME El registro especial CLIENT WRKSTNNAME contiene el valor del nombre de estación de trabajo de la información de cliente especificada para esta conexión. El tipo de datos del registro es VARCHAR(255). El valor por omisión de este registro es una serie vacía. El valor del nombre de estación de trabajo puede cambiarse utilizando la API para Establecer información de cliente (sqleseti). Tenga en cuenta que el valor proporcionado a través de la API sqleseti está en la página de códigos de aplicación y el valor del registro especial se almacena en la página de códigos de base de datos. En función de los valores de datos utilizados al establecer la información de cliente, puede que, durante la conversión de la página de códigos, se produzca el truncamiento del valor de datos almacenado en el registro especial. Ejemplo: Obtenga el nombre de estación de trabajo que se está utilizando para esta conexión. VALUES (CLIENT WRKSTNNAME) INTO :WS_NAME Capítulo 2. Elementos del lenguaje 163
- 190. CURRENT DATE El registro especial CURRENT DATE (o CURRENT_DATE) especifica una fecha basada en la lectura del reloj cuando se ejecuta la sentencia de SQL en el servidor de aplicaciones. Si este registro especial se utiliza más de una vez en la misma sentencia de SQL o bien con CURRENT TIME o CURRENT TIMESTAMP en una sola sentencia, todos los valores se basan en la misma lectura del reloj. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT DATE no se hereda de la sentencia que la invoca. En un sistema federado, CURRENT DATE se puede utilizar en una consulta prevista para fuentes de datos. Cuando se procesa la consulta, la fecha devuelta se obtendrá del registro CURRENT DATE, en el servidor federado, no de las fuentes de datos. Ejemplo: Utilizando la tabla PROJECT, establezca la fecha final del proyecto (PRENDATE) del proyecto MA2111 (PROJNO) en la fecha actual. UPDATE PROJECT SET PRENDATE = CURRENT DATE WHERE PROJNO = ’MA2111’ 164 Consulta de SQL, Volumen 1
- 191. CURRENT DBPARTITIONNUM El registro especial CURRENT DBPARTITIONNUM (o CURRENT_DBPARTITIONNUM)especifica un valor INTEGER que identifica el número de nodo coordinador de la sentencia. Para las sentencias emitidas desde una aplicación, el coordinador es la partición a la que se conecta la aplicación. Para las sentencias emitidas desde una rutina, el coordinador es la partición a la que se invoca la rutina. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT DBPARTITIONNUM nunca se hereda de la sentencia que la invoca. CURRENT DBPARTITIONNUM devuelve 0 si la instancia de base de datos no está definida para soportar el particionamiento. (En otras palabras, si no hay ningún archivo db2nodes.cfg. Para las bases de datos particionadas, el archivodb2nodes.cfg existe y contiene las definiciones de las particiones o los nodos). Es posible cambiar CURRENT DBPARTITIONNUM mediante la sentencia CONNECT, pero sólo bajo ciertas condiciones. Para compatibilidad con versiones anteriores a la Versión 8, la palabra clave NODE puede sustituirse por DBPARTITIONNUM. Ejemplo: Establezca la variable del lenguaje principal APPL_NODE (entero) en el número de la partición a la que está conectada la aplicación. VALUES CURRENT DBPARTITIONNUM INTO :APPL_NODE Información relacionada: v “CONNECT (Tipo 1) sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 2. Elementos del lenguaje 165
- 192. CURRENT DEFAULT TRANSFORM GROUP El registro especial CURRENT DEFAULT TRANSFORM GROUP (o CURRENT_DEFAULT_TRANSFORM_GROUP) especifica un valor VARCHAR (18) que identifica el nombre del grupo de transformación utilizado por las sentencias de SQL dinámico para intercambiar valores de tipos estructurados, definidos por el usuario, con programas de lenguaje principal. Este registro especial no especifica los grupos de transformación utilizados en las sentencias de SQL dinámico o en el intercambio de parámetros y resultados con funciones externas o métodos. Su valor puede definirse mediante la sentencia SET CURRENT DEFAULT TRANSFORM GROUP. Si no se define ningún valor, el valor inicial del registro especial es la serie vacía (VARCHAR con una longitud de cero). En un sentencia de SQL dinámico (es decir, una sentencia que interacciona con variables del lenguaje principal), el nombre del grupo de transformación utilizado para intercambiar valores es el mismo que el nombre de este registro especial, a menos que el registro contenga la serie vacía. Si el registro contiene la serie vacía (no se ha definido ningún valor utilizando la sentencia SET CURRENT DEFAULT TRANSFORM GROUP), se utiliza el grupo de transformación DB2_PROGRAM para la transformación. Si el grupo de transformación DB2_PROGRAM no está definido para el tipo estructurado indicado, se emite un error durante la ejecución (SQLSTATE 42741). Ejemplos: Establezca el grupo de transformación por omisión en MYSTRUCT1. Las funciones TO SQL y FROM SQL definidas en la transformación MYSTRUCT1 se utilizan para intercambiar variables de tipo estructurado, definidas por el usuario, con el programa de lenguaje principal. SET CURRENT DEFAULT TRANSFORM GROUP = MYSTRUCT1 Recupere el nombre del grupo de transformación por omisión asignado a este registro especial. VALUES (CURRENT DEFAULT TRANSFORM GROUP) 166 Consulta de SQL, Volumen 1
- 193. CURRENT DEGREE El registro especial CURRENT DEGREE (o CURRENT_DEGREE) especifica el grado de paralelismo intrapartición para la ejecución de sentencias de SQL dinámico. (Para SQL estático, la opción de vinculación de DEGREE proporciona el mismo control.) El tipo de datos del registro es CHAR(5). Los valores válidos son ANY o la representación de serie de un entero entre 1 y 32 767, inclusive. Si el valor de CURRENT DEGREE representado como un entero es 1 cuando una sentencia de SQL se prepara dinámicamente, la ejecución de esta sentencia no utilizará el paralelismo intrapartición. Si el valor de CURRENT DEGREE representado como un entero es mayor que 1 y menor o igual a 32 767 cuando una sentencia de SQL se prepara dinámicamente, la ejecución de esta sentencia puede implicar el paralelismo intrapartición con el grado especificado. Si el valor de CURRENT DEGREE es ANY cuando una sentencia de SQL se prepara dinámicamente, la ejecución de dicha sentencia puede implicar el paralelismo intrapartición que utiliza un grado determinado por el gestor de bases de datos. El grado de paralelismo real durante la ejecución será el menor de los valores siguientes: v El valor del parámetro de configuración del grado de consulta máximo(max_querydegree) v El grado de ejecución de la aplicación v El grado de compilación de la sentencia de SQL. Si el parámetro de configuración del gestor de bases de datos intra_parallel se establece en NO, el valor del registro especial CURRENT DEGREE se ignorará con el fin de optimizar y la sentencia no utilizará el paralelismo intrapartición. El valor puede cambiarse invocando la sentencia SET CURRENT DEGREE. El valor inicial de CURRENT DEGREE lo determina el parámetro de configuración de la base de datos dft_degree. Información relacionada: v “SET CURRENT DEGREE sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 2. Elementos del lenguaje 167
- 194. CURRENT EXPLAIN MODE El registro especial CURRENT EXPLAIN MODE (o CURRENT_EXPLAIN_MODE) contiene un valor VARCHAR(254) que controla la actuación del recurso Explain con respecto a sentencias de SQL dinámico admisibles. Este recurso genera e inserta información de Explain en las tablas de Explain. Esta información no incluye la instantánea de Explain. Los valores posibles son YES, NO, EXPLAIN, RECOMMEND INDEXES y EVALUATE INDEXES. (Para SQL estático, la opción de vinculación de EXPLAIN proporciona el mismo control. En el caso de los mandatos PREP y BIND, los valores de la opción EXPLAIN son: YES, NO y ALL.) YES Habilita el recurso Explain y hace que la información de Explain para una sentencia de SQL dinámico se capture al compilar la sentencia. EXPLAIN Se habilita el recurso pero no se ejecutan las sentencias dinámicas. NO Inhabilita el recurso Explain. RECOMMEND INDEXES Recomienda un conjunto de índices para cada consulta dinámica. Llena la tabla ADVISE_INDEX con el conjunto de índices. EVALUATE INDEXES Explica las consultas dinámicas como si existieran los índices recomendados. Los índices se seleccionan de la tabla ADVISE_INDEX. El valor inicial es NO. Este valor puede cambiarse invocando la sentencia SET CURRENT EXPLAIN MODE. Los valores de los registros especiales CURRENT EXPLAIN MODE y CURRENT EXPLAIN SNAPSHOT interactúan al invocar el recurso Explain. El registro especial CURRENT EXPLAIN MODE también interactúa con la opción de vinculación EXPLAIN. RECOMMEND INDEXES y EVALUATE INDEXES sólo se pueden establecer para el registro CURRENT EXPLAIN MODE y deben establecerse utilizando la sentencia SET CURRENT EXPLAIN MODE. Ejemplo: Establezca la variable de lenguaje principal EXPL_MODE (VARCHAR(254)) en el valor que hay actualmente en el registro especial CURRENT EXPLAIN MODE. VALUES CURRENT EXPLAIN MODE INTO :EXPL_MODE Información relacionada: v “SET CURRENT EXPLAIN MODE sentencia” en la publicación Consulta de SQL, Volumen 2 168 Consulta de SQL, Volumen 1
- 195. v Apéndice K, “Valores de registro de EXPLAIN” en la página 905 Capítulo 2. Elementos del lenguaje 169
- 196. CURRENT EXPLAIN SNAPSHOT El registro especial CURRENT EXPLAIN SNAPSHOT (o CURRENT_EXPLAIN_SNAPSHOT contiene un valor CHAR(8) que controla el funcionamiento del recurso de instantáneas de Explain. Este recurso genera información comprimida que incluye información sobre planes de acceso, costes del operador y estadísticas en tiempo de vinculación. Sólo las siguientes sentencias tienen en cuenta el valor de este registro: DELETE, INSERT, SELECT, SELECT INTO, UPDATE, VALUES y VALUES INTO. Los valores posibles son YES, NO y EXPLAIN. (Para SQL estático, la opción de vinculación EXPLSNAP proporciona el mismo control. En el caso de los mandatos PREP y BIND, los valores de la opción EXPLSNAP son: YES, NO y ALL.) YES Habilita el recurso de instantáneas Explain y realiza una instantánea de la representación interna de una sentencia de SQL dinámico al compilar la sentencia. EXPLAIN Se habilita el recurso pero no se ejecutan las sentencias dinámicas. NO Inhabilita el servicio de instantánea de Explain. El valor inicial es NO. Este valor puede cambiarse invocando la sentencia SET CURRENT EXPLAIN SNAPSHOT. Los valores de los registros especiales CURRENT EXPLAIN SNAPSHOT y CURRENT EXPLAIN MODE interactúan al invocar el recurso Explain. El registro especial CURRENT EXPLAIN SNAPSHOT también interactúa con la opción de vinculación EXPLSNAP. Ejemplo: Establezca la variable del lenguaje principal EXPL_SNAP (char(8)) en el valor que contiene actualmente el registro especial CURRENT EXPLAIN SNAPSHOT. VALUES CURRENT EXPLAIN SNAPSHOT INTO :EXPL_SNAP Información relacionada: v “SET CURRENT EXPLAIN SNAPSHOT sentencia” en la publicación Consulta de SQL, Volumen 2 v Apéndice K, “Valores de registro de EXPLAIN” en la página 905 170 Consulta de SQL, Volumen 1
- 197. CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION El registro especial CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION especifica un valor VARCHAR(254) que identifica los tipos de tablas que pueden tenerse en cuenta al optimizar el proceso de las series de SQL dinámico. Las consultas de SQL incorporado estático nunca tienen en cuenta las tablas de consulta materializadas. El valor inicial de CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION es SYSTEM. Su valor puede cambiarse con la sentencia SET CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION. Información relacionada: v “SET CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 2. Elementos del lenguaje 171
- 198. CURRENT PATH El registro especial CURRENT PATH (o CURRENT_PATH) especifica un valor VARCHAR(254) que identifica la vía de acceso de SQL que se ha de utilizar para resolver las referencias de funciones y las referencias de tipos de datos de sentencias de SQL preparadas dinámicamente. CURRENT FUNCTION PATH es sinónimo de CURRENT PATH. CURRENT PATH también se utiliza para resolver las referencias de procedimientos almacenados en sentencias CALL. El valor inicial es el valor por omisión que se especifica más abajo. Para SQL estático, la opción de vinculación FUNCPATH proporciona una vía de acceso de SQL que se utiliza para la resolución de funciones y tipos de datos. El registro especial CURRENT PATH contiene una lista de uno o varios nombres de esquema escritos entre comillas dobles y separados por comas. Por ejemplo, una vía de acceso de SQL que especifica que el gestor de bases de datos primero debe mirar en el esquema FERMAT, luego en el esquema XGRAPHIC y por último en el esquema SYSIBM se devuelve en el registro especial CURRENT PATH de la siguiente manera: "FERMAT","XGRAPHIC","SYSIBM" El valor por omisión es“SYSIBM”,“SYSFUN”,“SYSPROC”,X, donde X es el valor del registro especial USER, delimitado por comillas dobles. El valor puede cambiarse invocando la sentencia SET CURRENT PATH. No es necesario especificar el esquema SYSIBM. Si no se incluye en la vía de acceso de SQL, se supone implícitamente que es el primer esquema. SYSIBM no toma ninguno de los 254 caracteres si se asume implícitamente. Un tipo de datos que no está calificado con un nombre de esquema se calificará implícitamente con el primer esquema de la vía de acceso de SQL que contenga un tipo de datos con el mismo nombre no calificado. Existen excepciones a esta regla, como se indica en las descripciones de las sentencias siguientes: CREATE DISTINCT TYPE, CREATE FUNCTION, COMMENT y DROP. Ejemplo: Utilizando la vista de catálogo SYSCAT.VIEWS, busque todas las vistas que se hayan creado con el mismo valor que el valor actual del registro especial CURRENT PATH. SELECT VIEWNAME, VIEWSCHEMA FROM SYSCAT.VIEWS WHERE FUNC_PATH = CURRENT PATH Información relacionada: v “Funciones” en la página 181 v “SET PATH sentencia” en la publicación Consulta de SQL, Volumen 2 172 Consulta de SQL, Volumen 1
- 199. CURRENT QUERY OPTIMIZATION El registro especial CURRENT QUERY OPTIMIZATION (o CURRENT_QUERY_OPTIMIZATION) especifica un valor INTEGER que controla la clase de optimización de consulta que realiza el gestor de bases de datos al vincular sentencias de SQL dinámico. La opción de vinculación QUERYOPT controla la clase de optimización de consulta para las sentencias de SQL estático. Los valores posibles oscilan entre 0 y 9. Por ejemplo, si la clase de optimización de consulta se establece en 0 (optimización mínima), el valor del registro especial es 0. El valor por omisión está determinado por el parámetro de configuración de la base de datos dft_queryopt. El valor puede cambiarse invocando la sentencia SET CURRENT QUERY OPTIMIZATION. Ejemplo: Utilizando la vista de catálogo SYSCAT.PACKAGES, busque todos los planes que se han vinculado con el mismo valor que el valor actual del registro especial CURRENT QUERY OPTIMIZATION. SELECT PKGNAME, PKGSCHEMA FROM SYSCAT.PACKAGES WHERE QUERYOPT = CURRENT QUERY OPTIMIZATION Información relacionada: v “SET CURRENT QUERY OPTIMIZATION sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 2. Elementos del lenguaje 173
- 200. CURRENT REFRESH AGE El registro especial CURRENT REFRESH AGE especifica un valor de duración de indicación de fecha y hora con un tipo de datos de DECIMAL(20,6). Es la duración máxima desde que se produjo un suceso de indicación de fecha y hora concreto en un objeto de datos de la antememoria (por ejemplo, una sentencia REFRESH TABLE procesada en una tabla de consulta materializada REFRESH DEFERRED mantenida por el sistema) de forma que el objeto de datos de la antememoria pueda utilizarse para optimizar el proceso de la consulta. Si CURRENT REFRESH AGE tiene un valor de 99 999 999 999 999 (ANY) y la clase de optimización de la consulta es 5 o superior, los tipos de tablas especificados en CURRENT MAINTAINED TABLE TYPES FOR OPTIMIZATION se tienen en cuenta al optimizar el proceso de consulta de SQL dinámico. El valor inicial de CURRENT REFRESH AGE es cero. El valor puede cambiarse invocando la sentencia SET CURRENT REFRESH AGE. Información relacionada: v “SET CURRENT REFRESH AGE sentencia” en la publicación Consulta de SQL, Volumen 2 174 Consulta de SQL, Volumen 1
- 201. CURRENT SCHEMA El registro especial CURRENT SCHEMA (o CURRENT_SCHEMA) especifica un valor VARCHAR(128) que identifica el nombre de esquema utilizado para calificar las referencias a objetos de base de datos, donde corresponda, en sentencias de SQL preparadas dinámicamente. Para conseguir la compatibilidad con DB2 para OS/390, CURRENT SQLID (o CURRENT_SQLID) es un sinónimo de CURRENT SCHEMA. El valor inicial de CURRENT SCHEMA es el ID de autorización del usuario de la sesión actual. El valor puede cambiarse invocando la sentencia SET SCHEMA. La opción de vinculación QUALIFIER controla el nombre de esquema utilizado para calificar las referencias a objetos de base de datos, donde corresponda, para sentencias de SQL estático. Ejemplo: Establezca el esquema para la calificación de objetos en 'D123'. SET CURRENT SCHEMA = 'D123' Capítulo 2. Elementos del lenguaje 175
- 202. CURRENT SERVER El registro especial CURRENT SERVER (o CURRENT_SERVER) especifica un valor VARCHAR(18) que identifica el servidor de aplicaciones actual. El registro contiene el nombre real del servidor de aplicaciones, no un seudónimo. Es posible cambiar CURRENT SERVER mediante la sentencia CONNECT, pero sólo bajo ciertas condiciones. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT SERVER no se hereda de la sentencia que la invoca. Ejemplo: Establezca la variable del lenguaje principal APPL_SERVE (VARCHAR(18)) en el nombre del servidor de aplicaciones al que está conectada la aplicación. VALUES CURRENT SERVER INTO :APPL_SERVE Información relacionada: v “CONNECT (Tipo 1) sentencia” en la publicación Consulta de SQL, Volumen 2 176 Consulta de SQL, Volumen 1
- 203. CURRENT TIME El registro especial CURRENT TIME (o CURRENT_TIME) especifica una hora basada en la lectura del reloj cuando se ejecuta la sentencia de SQL en el servidor de aplicaciones. Si este registro especial se utiliza más de una vez en la misma sentencia de SQL o bien con CURRENT DATE o CURRENT TIMESTAMP en una sola sentencia, todos los valores se basan en la misma lectura del reloj. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT TIME no se hereda de la sentencia que la invoca. En un sistema federado, CURRENT TIME se puede utilizar en una consulta destinada a fuentes de datos. Cuando se procesa la consulta, la hora devuelta se obtendrá del registro CURRENT TIME del servidor federado, no de las fuentes de datos. Ejemplo: Utilizando la tabla CL_SCHED, seleccione todas las clases (CLASS_CODE) que empiezan (STARTING) más tarde hoy. Las clases de hoy tienen un valor 3 en la columna DAY. SELECT CLASS_CODE FROM CL_SCHED WHERE STARTING > CURRENT TIME AND DAY = 3 Capítulo 2. Elementos del lenguaje 177
- 204. CURRENT TIMESTAMP El registro especial CURRENT TIMESTAMP (o CURRENT_TIMESTAMP) especifica una indicación de fecha y hora basada en la lectura del reloj cuando se ejecuta la sentencia de SQL en el servidor de aplicaciones. Si este registro especial se utiliza más de una vez en la misma sentencia de SQL o bien con CURRENT DATE o CURRENT TIME en una sola sentencia, todos los valores se basan en la misma lectura del reloj. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT TIMESTAMP no se hereda de la sentencia que la invoca. En un sistema federado, CURRENT TIMESTAMP se puede utilizar en una consulta destinada a fuentes de datos. Cuando se procesa la consulta, la indicación de fecha y hora se obtendrá del registro CURRENT TIMESTAMP del servidor federado, no de las fuentes de datos. Ejemplo: Inserte una fila en la tabla IN_TRAY. El valor de la columna RECEIVED mostrará la indicación de fecha y hora en la que se ha añadido la fila. Los valores de las otras tres columnas se obtienen de las variables del lenguaje principal SRC (char(8)), SUB (char(64)) y TXT (VARCHAR(200)). INSERT INTO IN_TRAY VALUES (CURRENT TIMESTAMP, :SRC, :SUB, :TXT) 178 Consulta de SQL, Volumen 1
- 205. CURRENT TIMEZONE El registro especial CURRENT TIMEZONE (o CURRENT_TIMEZONE) especifica la diferencia entre UTC (Hora coordinada universal, conocida anteriormente como GMT) y la hora local del servidor de aplicaciones. La diferencia se representa por un período de tiempo (un número decimal cuyos dos primeros dígitos corresponden a las horas, los dos siguientes a los minutos y los dos últimos a los segundos). El número de horas está entre -24 y 24, exclusive. Al restar CURRENT TIMEZONE de la hora local se convierte esa hora a UTC. La hora se calcula a partir de la hora del sistema operativo en el momento en que se ejecuta la sentencia de SQL. (El valor de CURRENT TIMEZONE se determina a partir de las funciones de tiempo de ejecución de C). El registro especial CURRENT TIMEZONE se puede utilizar allí donde se utilice una expresión de tipo de datos DECIMAL(6,0); por ejemplo, en operaciones aritméticas de hora e indicación de fecha y hora. Cuando se utiliza en una sentencia de SQL incluida en una rutina, CURRENT TIMEZONE no se hereda de la sentencia que la invoca. Ejemplo: Inserte un registro en la tabla IN_TRAY utilizando una indicación de fecha y hora UTC para la columna RECEIVED. INSERT INTO IN_TRAY VALUES ( CURRENT TIMESTAMP - CURRENT TIMEZONE, :source, :subject, :notetext ) Capítulo 2. Elementos del lenguaje 179
- 206. USER El registro especial USER especifica el ID de autorización de tiempo de ejecución que se pasa al gestor de bases de datos cuando se inicia una aplicación en una base de datos. El tipo de datos del registro es VARCHAR(128). Cuando se utiliza en una sentencia de SQL incluida en una rutina, USER no se hereda de la sentencia que lo invoca. Ejemplo: Seleccione todas las notas de la tabla IN_TRAY que el usuario haya colocado ahí. SELECT * FROM IN_TRAY WHERE SOURCE = USER 180 Consulta de SQL, Volumen 1
- 207. Funciones Una función de base de datos es una relación entre un conjunto de valores de datos de entrada y un conjunto de valores del resultado. Por ejemplo, se pueden pasar a la función TIMESTAMP valores de datos de entrada del tipo DATE y TIME y el resultado será TIMESTAMP. Las funciones pueden ser incorporadas o bien definidas por el usuario. v Con el gestor de bases de datos se proporcionan funciones incorporadas. Devuelven un solo valor del resultado y se identifican como parte del esquema SYSIBM. Entre estas funciones se incluyen funciones de columna (por ejemplo, AVG), funciones con operadores (por ejemplo, +) y funciones de conversión (por ejemplo, DECIMAL). v Las funciones definidas por el usuario son funciones que están registradas en una base de datos de SYSCAT.ROUTINES (utilizando la sentencia CREATE FUNCTION). Estas funciones nunca forman parte del esquema SYSIBM. El gestor de bases de datos proporciona un conjunto de estas funciones en un esquema denominado SYSFUN. Las funciones definidas por el usuario amplían las posibilidades del sistema de bases de datos añadiendo definiciones de funciones (proporcionadas por usuarios o proveedores) que pueden aplicarse en el propio núcleo de la base de datos. La ampliación de las funciones de la base de datos permite que la base de datos explote las mismas funciones en su núcleo que las que utiliza una aplicación, proporcionando más sinergia entre la aplicación y la base de datos. Funciones definidas por el usuario externas, de SQL y derivadas Una función definida por el usuario puede ser una función externa, una función de SQL o una función derivada. Una función externa se define en la base de datos con una referencia a una biblioteca de códigos objeto y una función en dicha biblioteca que se ejecutará cuando se invoque la función. Las funciones externas no pueden ser funciones de columna. Una función de SQL se define para la base de datos utilizando solamente la sentencia RETURN de SQL. Puede devolver un valor escalar, una fila o una tabla. Las funciones de SQL no pueden ser funciones de columna. Una función derivada se define para la base de datos con una referencia a otra función incorporada o definida por el usuario que ya se conoce en la base de datos. Las funciones derivadas pueden ser funciones escalares o funciones de columna. Son útiles para dar soporte a funciones existentes con tipos definidos por el usuario. Funciones definidas por el usuario escalares, de columna, de fila y de tabla Cada función definida por el usuario también se clasifica como función escalar, de columna o de tabla. Una función escalar es una función que Capítulo 2. Elementos del lenguaje 181
- 208. devuelve una respuesta de un solo valor cada vez que se invoca. Por ejemplo, la función incorporada SUBSTR() es una función escalar. Las UDF escalares pueden ser externas o derivadas. Una función de columna es la que recibe un conjunto de valores similares (una columna) y devuelve una respuesta de un solo valor. A veces éstas se denominan también funciones de agregación en DB2.Un ejemplo de una función de columna es la función incorporada AVG(). No puede definirse una UDF de columna externa para DB2, pero puede definirse una UDF de columna, que se deriva de las funciones de columna incorporadas. Es útil para tipos diferenciados. Por ejemplo, si está definido un tipo diferenciado SHOESIZE con un tipo base INTEGER, se podría definir una UDF AVG(SHOESIZE), derivada de la función incorporada AVG(INTEGER), que sería una función de columna. Una función de fila es una función que devuelve una fila de valores. Se puede utilizar sólo como función de transformación, que correlaciona valores de atributos de un tipo estructurado con valores de una fila. Las funciones de fila deben estar definidas como funciones de SQL. Una función de tabla es una función que devuelve una tabla a la sentencia de SQL donde se invoca la función. Sólo se puede hacer referencia a la función en la cláusula FROM de una sentencia SELECT. Una función así puede utilizarse para aplicar la potencia de proceso del lenguaje SQL a datos que no son de DB2, o para convertir tales datos a una tabla DB2. Esta función podría, por ejemplo, tomar un archivo y convertirlo en una tabla, tomar muestras de datos de la Web y disponerlos en forma de tabla o acceder a una base de datos Lotus Notes y devolver información sobre mensajes de correo, tal como la fecha, el remitente y el texto del mensaje. Esta información puede unirse a otras tablas de la base de datos. Una función de tabla se puede definir como una función externa o como una función de SQL. (Una función de tabla no puede ser una función derivada). Signaturas de función Una función se identifica por su esquema, un nombre de función el número de parámetros y los tipos de datos de sus parámetros. Esto se denomina signatura de función, que debe ser exclusiva en la base de datos. Varias funciones pueden tener el mismo nombre dentro de un esquema, siempre que el número de parámetros o bien los tipos de datos de los parámetros sean diferentes. Un nombre de función para el que existen múltiples instancias de función se llama función sobrecargada. Un nombre de función puede estar sobrecargado dentro de un esquema, en cuyo caso hay más de una función con el mismo nombre en el esquema. Estas funciones deben tener tipos de parámetros distintos. Un nombre de función también puede estar sobrecargado en una vía de acceso de SQL, en cuyo caso hay más de una 182 Consulta de SQL, Volumen 1
- 209. función con el mismo nombre en la vía de acceso. Estas funciones no es necesario que tengan tipos de parámetros distintos. Una función se puede invocar haciendo referencia (en un contexto que lo permita) a su nombre calificado (esquema y nombre de función), seguido por la lista de argumentos, entre paréntesis. También se puede invocar sin especificar el nombre del esquema, obteniendo como resultado una serie de posibles funciones de diferentes esquemas que tienen los mismos parámetros o bien parámetros aceptables. En este caso, la vía de acceso de SQL se utiliza como ayuda para resolver la función. La vía de acceso de SQL es una lista de esquemas que se examinan para identificar una función con el mismo nombre, número de parámetros y tipos de datos aceptables. Para las sentencias de SQL estático, la vía de acceso de SQL se especifica utilizando la opción de vinculación FUNCPATH. Para las sentencias de SQL dinámico, la vía de acceso de SQL es el valor del registro especial CURRENT PATH. El acceso a las funciones se controla mediante el privilegio EXECUTE. Se utilizan sentencias GRANT y REVOKE para especificar quién puede o no puede ejecutar una función o conjunto de funciones determinadas. Se necesita el privilegio EXECUTE (o la autoridad DBADM) para invocar una función. La persona que define la función recibe el privilegio EXECUTE de forma automática. Si se trata de una función externa o de una función de SQL que tienen la opción WITH GRANT en todos los objetos subyacentes, la persona que la define también recibe la opción WITH GRANT con el privilegio EXECUTE sobre la función. La persona que la define (o SYSADM o DBADM) debe otorgarlo entonces al usuario que desee invocar la función desde una sentencia de SQL o hacer referencia a la misma en una sentencia de DDL (como, por ejemplo, CREATE VIEW, CREATE TRIGGER o al definir una restricción) o crear otra función derivada de esta función. Si no se otorga a un usuario el privilegio EXECUTE, el algoritmo de resolución de función no tendrá en cuenta la función aunque ésta se corresponda mucho mejor. Las funciones incorporadas (funciones SYSIBM) y las funciones SYSFUN tienen otorgado el privilegio EXECUTE en PUBLIC de forma implícita. Resolución de función Después de invocar una función, el gestor de bases de datos debe decidir cuál de las posibles funciones con el mismo nombre es la “más apropiada ”. Esto incluye la resolución de funciones incorporadas y definidas por el usuario. Un argumento es un valor que se pasa a una función en una invocación. Cuando se invoca una función en SQL, se pasa una lista de cero o más argumentos. Son argumentos posicionales en tanto que la semántica de dichos argumentos viene determinada por su posición en la lista de argumentos. Un parámetro es una definición formal de una entrada para una función. Cuando una función está definida en la base de datos, ya sea internamente (una función incorporada) o por el usuario (una función definida por el usuario), se Capítulo 2. Elementos del lenguaje 183
- 210. especifican sus parámetros (cero o más) y el orden de sus definiciones define su posición y su semántica. Por lo tanto, cada parámetro es una entrada posicional particular de una función. En la invocación, un argumento corresponde a un parámetro determinado en virtud a la posición que éste ocupe en la lista de argumentos. El gestor de bases de datos utiliza el nombre de la función que se facilita en la invocación, el privilegio EXECUTE sobre la función, el número y los tipos de datos de los argumentos, todas las funciones que tienen el mismo nombre en la vía de acceso de SQL y los tipos de datos de sus parámetros correspondientes como punto de referencia para decidir si se selecciona o no una función. A continuación se muestran los resultados posibles del proceso de decisión: v Una función determinada se considera como la mejor. Por ejemplo, con las funciones denominadas RISK en el esquema TEST con las signaturas definidas como: TEST.RISK(INTEGER) TEST.RISK(DOUBLE) una vía de acceso de SQL que incluya el esquema TEST y la siguiente referencia de función (donde DB es una columna DOUBLE): SELECT ... RISK(DB) ... se elegirá el segundo RISK. La siguiente referencia de función (donde SI es una columna SMALLINT): SELECT ... RISK(SI) ... elegirá el primer RISK, ya que SMALLINT se puede promover a INTEGER y es una coincidencia mejor que DOUBLE, que se encuentra más abajo en la lista de prioridad. Cuando se tienen en cuenta argumentos que son tipos estructurados, la lista de prioridad incluye los supertipos del tipo estático del argumento. La función que mejor se ajusta es la definida con el parámetro de supertipo más cercano, en la jerarquía de tipos estructurados, al tipo estático del argumento de función. v Ninguna función se considera la mejor. Tomando como ejemplo las dos mismas funciones del caso anterior y la siguiente referencia de función (donde C es una columna CHAR(5)): SELECT ... RISK(C) ... el argumento es incoherente con el parámetro de las dos funciones RISK. 184 Consulta de SQL, Volumen 1
- 211. v Una función determinada se selecciona según la vía de acceso de SQL y el número de argumentos, así como sus tipos de datos, que se han pasado en la invocación. Por ejemplo, dadas unas funciones denominadas RANDOM con las signaturas definidas como: TEST.RANDOM(INTEGER) PROD.RANDOM(INTEGER) y una vía de acceso de SQL de: "TEST","PROD" la siguiente referencia de función: SELECT ... RANDOM(432) ... elegirá TEST.RANDOM, ya que las dos funciones RANDOM son coincidencias igualmente buenas (coincidencias exactas en este caso particular) y ambos esquemas están en la vía de acceso, pero TEST precede a PROD en la vía de acceso de SQL. Determinación de la mejor opción La comparación de los tipos de datos de los argumentos con los tipos de datos definidos de los parámetros de las funciones en cuestión, constituye la base primordial para tomar la decisión de qué función de un grupo de funciones con el mismo nombre se considera “más adecuada”. Tenga en cuenta que los tipos de datos de los resultados de las funciones o el tipo de función (de columna, escalar o de tabla) en cuestión no se tiene en cuenta en esta determinación. La resolución de las funciones se realiza siguiendo los pasos siguientes: 1. En primer lugar, busque todas aquellas funciones del catálogo (SYSCAT.ROUTINES) y funciones incorporadas que cumplan las condiciones siguientes: v En las invocaciones donde se ha especificado el nombre de esquema (una referencia calificada), el nombre de esquema y el nombre de función coinciden con el nombre de invocación. v En las invocaciones donde no se ha especificado el nombre de esquema (una referencia no calificada), el nombre de función coincide con el nombre de invocación y tiene un nombre de esquema que coincide con uno de los esquemas de la vía de acceso de SQL. v La persona que la invoca tiene el privilegio EXECUTE sobre la función. v El número de parámetros definidos debe coincidir con la invocación. v Cada argumento de invocación coincide con el tipo de datos del parámetro definido correspondiente de la función o es “promocionable” al mismo. Capítulo 2. Elementos del lenguaje 185
- 212. 2. A continuación, examine de izquierda a derecha cada argumento de la invocación de la función. Para cada argumento, elimine todas las funciones que no sean la mejor coincidencia para ese argumento. La mejor opción para un argumento dado es el primer tipo de datos que aparece en la lista de prioridad correspondiente al tipo de datos del argumento para el cual existe una función con un parámetro de ese tipo de datos. En esta comparación no se tienen en cuenta las longitudes, precisiones y escalas ni el atributo FOR BIT DATA. Por ejemplo, un argumento DECIMAL(9,1) se considera una coincidencia exacta para un parámetro DECIMAL(6,5) mientras que un argumento VARCHAR(19) es una coincidencia exacta para un parámetro VARCHAR(6). La mejor coincidencia para un argumento de tipo estructurado definido por el usuario es el propio argumento; la siguiente mejor coincidencia es el supertipo inmediato, y así sucesivamente para cada supertipo del argumento. Observe que sólo se tiene en cuenta el tipo estático (tipo declarado) del argumento de tipo estructurado, no el tipo dinámico (tipo más específico). 3. Si después del paso 2 queda más de una función elegible, todas las funciones elegibles restantes deben tener signaturas idénticas pero encontrarse en esquemas diferentes. Elija la función cuyo esquema aparezca antes en la vía de acceso de SQL del usuario. 4. Si después del paso 2 no queda ninguna función elegible, se devolverá un error (SQLSTATE 42884). Consideraciones sobre la vía de acceso de funciones para las funciones incorporadas Las funciones incorporadas residen en un esquema especial denominado SYSIBM. Hay funciones adicionales disponibles en los esquemas SYSFUN y SYSPROC que no se consideran funciones incorporadas ya que se han desarrollado como funciones definidas por el usuario y carecen de consideraciones de proceso especiales. Los usuarios no pueden definir funciones adicionales en los esquemas SYSIBM, SYSFUN ni SYSPROC (ni en cualquier esquema cuyo nombre empiece por las letras SYS). Como ya se ha indicado, las funciones incorporadas participan en el proceso de resolución de las funciones exactamente como lo hacen las funciones definidas por el usuario. Una diferencia entre ambas, desde el punto de vista de la resolución de función, es que las funciones incorporadas siempre deben tenerse en cuenta durante la resolución de función. Por este motivo, si se omite SYSIBM de los resultados de vía de acceso se asume (para la resolución de las funciones y los tipos de datos) que SYSIBM es el primer esquema de la vía de acceso. Por ejemplo, si la vía de acceso de SQL de un usuario está definida de la siguiente manera: 186 Consulta de SQL, Volumen 1
- 213. "SHAREFUN","SYSIBM","SYSFUN" y hay una función LENGTH definida en el esquema SHAREFUN con el mismo número y los mismos tipos de argumentos que SYSIBM.LENGTH, una referencia no calificada a LENGTH en la sentencia de SQL de este usuario hará que se seleccione SHAREFUN.LENGTH. No obstante, si la vía de acceso de SQL del usuario está definida de la siguiente forma: "SHAREFUN","SYSFUN" y existe la misma función SHAREFUN.LENGTH, una referencia no calificada a LENGTH en la sentencia de SQL de este usuario hará que se seleccione SYSIBM.LENGTH, ya que SYSIBM aparece implícitamente antes en la vía de acceso. Para minimizar los posibles problemas en este área: v No utilice nunca los nombres de funciones incorporadas para funciones definidas por el usuario. v Si, por algún motivo, es necesario crear una función definida por el usuario con el mismo nombre que una función incorporada, asegúrese de calificar todas las referencias a la misma. Ejemplo de resolución de función A continuación se muestra un ejemplo de una resolución de función satisfactoria. (Observe que no se muestran todas las palabras clave necesarias.) Existen siete funciones ACT, en tres esquemas diferentes, registradas del modo siguiente: CREATE FUNCTION AUGUSTUS.ACT (CHAR(5), INT, DOUBLE) SPECIFIC ACT_1 ... CREATE FUNCTION AUGUSTUS.ACT (INT, INT, DOUBLE) SPECIFIC ACT_2 ... CREATE FUNCTION AUGUSTUS.ACT (INT, INT, DOUBLE, INT) SPECIFIC ACT_3 ... CREATE FUNCTION JULIUS.ACT (INT, DOUBLE, DOUBLE) SPECIFIC ACT_4 ... CREATE FUNCTION JULIUS.ACT (INT, INT, DOUBLE) SPECIFIC ACT_5 ... CREATE FUNCTION JULIUS.ACT (SMALLINT, INT, DOUBLE) SPECIFIC ACT_6 ... CREATE FUNCTION NERO.ACT (INT, INT, DEC(7,2)) SPECIFIC ACT_7 ... La referencia de función es la siguiente (donde I1 e I2 son columnas INTEGER y D es una columna DECIMAL): SELECT ... ACT(I1, I2, D) ... Suponga que la aplicación que efectúa esta referencia tiene una vía de acceso de SQL establecida como: "JULIUS","AUGUSTUS","CAESAR" De acuerdo con el algoritmo... v La función con el nombre específico ACT_7 se elimina como candidato, porque el esquema NERO no está incluido en la vía de acceso de SQL. Capítulo 2. Elementos del lenguaje 187
- 214. v La función con el nombre específico ACT_3 se elimina como candidato, porque tiene el número incorrecto de parámetros. ACT_1 y ACT_6 se eliminan porque, en ambos casos, el primer argumento no se puede promocionar al tipo de datos del primer parámetro. v Como sigue habiendo más de un candidato, los argumentos se tienen en cuenta siguiendo un orden. v Para el primer argumento, las funciones restantes, ACT_2, ACT_4 y ACT_5 coinciden exactamente con el tipo de argumento. No se puede pasar por alto ninguna de las funciones; así pues, se debe examinar el argumento siguiente. v Para este segundo argumento, ACT_2 y ACT_5 coinciden exactamente, pero no sucede lo mismo con ACT_4, por lo cual queda descartado. Se examina el siguiente argumento para determinar alguna diferencia entre ACT_2 y ACT_5. v Para el tercer y último argumento, ni ACT_2 ni ACT_5 coinciden exactamente con el tipo de argumento, pero ambos son igualmente aceptables. v Quedan dos funciones, ACT_2 y ACT_5, con signaturas de parámetros idénticas. La criba final consiste en determinar el esquema de qué función aparece primero en la vía de acceso de SQL y, en base a ello, se elige ACT_5. invocación de funciones Cuando ya se ha seleccionado la función, pueden darse todavía algunos motivos por los cuales no se pueda utilizar alguna función. Cada función está definida para devolver un resultado con un tipo de datos concreto. Si este tipo de datos resultante no es compatible con el contexto en el que se invoca la función, se producirá un error. Por ejemplo, con las funciones denominadas STEP, en esta ocasión con tipos de datos diferentes como resultado: STEP(SMALLINT) devuelve CHAR(5) STEP(DOUBLE) devuelve INTEGER y la referencia de función siguiente (donde S es una columna SMALLINT): SELECT ... 3 + STEP(S) ... como hay una coincidencia exacta de tipo de argumento, se elige la primera operación STEP. Se produce un error en la sentencia porque el tipo resultante es CHAR(5) en lugar de un tipo numérico, tal como necesita un argumento del operador de suma. Otros ejemplos en los que puede ocurrir esto son los siguientes, ambos darán como resultado un error en la sentencia: v Se ha hecho referencia a la función en una cláusula FROM, pero la función seleccionada en el paso de resolución de las funciones ha sido una función escalar o de columna. 188 Consulta de SQL, Volumen 1
- 215. v El caso contrario en el que el contexto llama a una función escalar o de columna y la resolución de la función selecciona una función de tabla. En los casos donde los argumentos de la invocación de la función no coinciden exactamente con los tipos de datos de los parámetros de la función seleccionada, los argumentos se convierten al tipo de datos del parámetro durante la ejecución, utilizando las mismas reglas que para la asignación a columnas. También se incluye el caso en el que la precisión, escala o longitud difiere entre el argumento y el parámetro. Semántica de vinculación conservadora Existen casos en los que las rutinas y los tipos de datos se resuelven cuando se procesa una sentencia y el gestor de bases de datos debe poder repetir esta resolución. Esto sucede en: v Sentencias en paquetes de DML estático v Vistas v Activadores v Restricciones de comprobación v Rutinas de SQL En el caso de las sentencias en paquetes de DML estático, las referencias a la rutina y al tipo de datos se resuelven durante una operación de vinculación. Las referencias a la rutina y al tipo de datos en las vistas, activadores, rutinas de SQL y restricciones de comprobación se resuelven cuando se crea el objeto de base de datos. Si la resolución de la rutina se realiza de nuevo en alguna referencia a rutina de estos objetos, podría cambiar de comportamiento si: v Se ha añadido una rutina nueva con una signatura más adecuada pero el ejecutable real realiza operaciones distintas. v A la persona que la ha definido se le ha otorgado el privilegio de ejecución sobre una rutina con una signatura más adecuada pero el ejecutable real realiza operaciones distintas. Similarmente, si la resolución se ejecuta de nuevo para cualquier tipo de datos de estos objetos, podría cambiar el comportamiento si se ha añadido un nuevo tipo de datos con el mismo nombre en un esquema diferente que también está en la vía de acceso de SQL. Para evitar esto, el gestor de bases de datos aplica la semántica de vinculación conservadora cuando lo considera necesario. Esto asegura que las referencias a la rutina y al tipo de datos se resuelvan utilizando la misma vía de acceso de SQL y el mismo conjunto de rutinas con las que se resolvió cuando se vinculó anteriormente. La indicación de fecha y hora de creación de las rutinas y los tipos de datos tenidos en cuenta durante la resolución no es posterior a la hora en que se vinculó la sentencia. (Las funciones incorporadas añadidas a partir de la Versión 6.1 tienen una Capítulo 2. Elementos del lenguaje 189
- 216. indicación de fecha y hora de creación basada en la hora de creación o migración de la base de datos.) De esta forma, sólo se tendrán en cuenta las rutinas y los tipos de datos que se tuvieron en cuenta durante la resolución de la rutina y del tipo de datos cuando se procesó originalmente la sentencia. Por tanto, las rutinas y los tipos de datos creados o autorizados recientemente no se tendrán en cuenta cuando se aplica la semántica de vinculación conservadora. Piense en una base de datos con dos funciones que tienen las signaturas SCHEMA1.BAR(INTEGER) y SCHEMA2.BAR(DOUBLE). Suponga que una vía de acceso de SQL contiene los dos esquemas, SCHEMA1 y SCHEMA2 (aunque su orden en la vía de acceso de SQL carece de importancia). A USER1 se le ha otorgado el privilegio EXECUTE sobre la función SCHEMA2.BAR(DOUBLE). Suponga que USER1 crea una vista que llama a BAR(INT_VAL). Esta se resolverá en la función SCHEMA2.BAR(DOUBLE). La vista siempre utilizará SCHEMA2.BAR(DOUBLE), aunque alguien otorgue a USER1 el privilegio EXECUTE sobre SCHEMA1.BAR(INTEGER) después de crear la vista. En el caso de los paquetes de DML estático, los paquetes se pueden volver a vincular implícitamente o emitiendo explícitamente el mandato REBIND (o la API correspondiente) o el mandato BIND (o la API correspondiente). La revinculación implícita se ejecuta siempre para resolver rutinas y tipos de datos con la semántica de vinculación conservadora. El mandato REBIND proporciona la posibilidad de resolver con la semántica de vinculación conservadora (RESOLVE CONSERVATIVE) o resolver teniendo en cuenta las rutinas y tipos datos nuevos (RESOLVE ANY, la opción por omisión). La revinculación implícita de un paquete siempre resuelve la misma rutina. Aunque se hay otorgado el privilegio EXECUTE sobre una rutina más adecuada, la rutina no se tendrá en cuenta. La revinculación explícita de un paquete puede dar como resultado la selección de una rutina distinta. (Pero si se especifica RESOLVE CONSERVATIVE, la resolución de la rutina seguirá la semántica de vinculación conservadora). Si una rutina se ha especificado durante la creación de una vista, activador, restricción o cuerpo de rutina SQL, la instancia concreta de la rutina que se utilizará viene determinada por la resolución de rutina en el momento en que se crea el objeto. Aunque posteriormente se otorgue el privilegio EXECUTE después de crear el objeto, la rutina concreta que el objeto utiliza no cambiará. Piense en una base de datos con dos funciones que tienen las signaturas SCHEMA1.BAR(INTEGER) y SCHEMA2.BAR(DOUBLE). A USER1 se le ha otorgado el privilegio EXECUTE sobre la función SCHEMA2.BAR(DOUBLE). Suponga que USER1 crea una vista que llama a BAR(INT_VAL). Esta se resolverá en la función SCHEMA2.BAR(DOUBLE). La vista siempre utilizará 190 Consulta de SQL, Volumen 1
- 217. SCHEMA2.BAR(DOUBLE), aunque alguien otorgue a USER1 el privilegio EXECUTE sobre SCHEMA1.BAR(INTEGER) después de crear la vista. El mismo comportamiento se produce en otros objetos de la base de datos. Por ejemplo, si un paquete se revincula de forma implícita (tal vez después de eliminar un índice), el paquete hará referencia a la misma rutina concreta tanto antes como después de la revinculación implícita. Sin embargo, la revinculación explícito de un paquete, puede dar como resultado la selección de una rutina distinta. Información relacionada: v “CURRENT PATH” en la página 172 v “Promoción de tipos de datos” en la página 120 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 191
- 218. Métodos Un método de base de datos de un tipo estructurado es una relación entre un conjunto de valores de datos de entrada y un conjunto de valores resultantes, donde el primer valor de entrada (o argumento sujeto) tiene el mismo tipo, o es un subtipo del tipo sujeto (también llamado parámetro sujeto) del método. Por ejemplo, es posible pasar valores de datos de entrada de tipo VARCHAR a un método denominado CITY, de tipo ADDRESS y el resultado será un valor ADDRESS (o un subtipo de ADDRESS). Los métodos se definen implícita o explícitamente, como parte de la definición de un tipo estructurado definido por el usuario. Los métodos definidos implícitamente se crean para cada tipo estructurado. Se definen métodos observadores para cada atributo del tipo estructurado. Los métodos observadores permiten que una aplicación obtenga el valor de un atributo para una instancia del tipo. También se definen métodos mutadores para cada atributo, que permiten que una aplicación cambie la instancia de tipo modificando el valor de un atributo de una instancia de tipo. El método CITY descrito anteriormente es un ejemplo de método mutador para el tipo ADDRESS. Los métodos definidos explícitamente o métodos definidos por el usuario son métodos que se registran en el catálogo SYSCAT.ROUTINES de una base de datos, utilizando una combinación de las sentencias CREATE TYPE (o ALTER TYPE ADD METHOD) y CREATE METHOD. Todos los métodos definidos para un tipo estructurado se definen en el mismo esquema que el tipo. Los métodos definidos por el usuario para tipos estructurados amplían la función de sistema de bases de datos añadiendo definiciones de método (proporcionadas por usuarios o proveedores) que pueden aplicarse a instancias de tipo estructurado en el núcleo de la base de datos. La definición de los métodos de la base de datos permite que la base de datos explote los mismos métodos en su núcleo que los que utiliza una aplicación, proporcionando más sinergia entre la aplicación y la base de datos. Métodos definidos por el usuario externos y SQL Un método definido por el usuario puede ser externo o estar basado en una expresión SQL. Un método externo se define para la base de datos con una referencia a una biblioteca de códigos objeto y una función en dicha biblioteca que se ejecutará cuando se invoque el método. Un método basado en una expresión SQL devuelve el resultado de la expresión SQL cuando se invoca el método. Tales métodos no necesitan ninguna biblioteca de códigos objeto, ya que están escritos completamente en SQL. 192 Consulta de SQL, Volumen 1
- 219. Un método definido por el usuario puede devolver un solo valor cada vez que se invoca. Este valor puede ser un tipo estructurado. Un método se puede definir como preservador del tipo (utilizando SELF AS RESULT), para permitir que el tipo dinámico del argumento sujeto sea el tipo devuelto del método. Todos los métodos mutadores definidos implícitamente son preservadores del tipo. Signaturas de método Un método se identifica por su tipo sujeto, un nombre de método, el número de parámetros y los tipos de datos de sus parámetros. Esto se denomina una signatura de método y debe ser exclusiva en la base de datos. Puede existir más de un método con el mismo nombre para un tipo estructurado, siempre que: v El número de parámetros o los tipos de datos de los parámetros sean diferentes o v Los métodos formen parte de la misma jerarquía de métodos (es decir, los métodos estén en una relación de alteración temporal o alteren temporalmente el mismo método original) o v No exista la misma signatura de función (utilizando el tipo sujeto o cualquiera de sus subtipos o supertipos como primer parámetro). Un nombre de método que tiene varias instancias de método se denomina método sobrecargado. Un nombre de método puede estar sobrecargado dentro de un tipo, lo que significa que existe más de un método de ese nombre para el tipo (todos los cuales tienen diferentes tipos de parámetros). Un nombre de método también puede estar sobrecargado en la jerarquía de tipos sujeto, en cuyo caso existe más de un método con ese nombre en la jerarquía de tipos. Estos métodos deben tener tipos de parámetros distintos. Un método se puede invocar haciendo referencia (en un contexto permitido) al nombre de método, precedido por una referencia a una instancia de tipo estructurado (el argumento sujeto) y por el operador de doble punto. A continuación debe seguir una lista de argumentos entre paréntesis. El método que se invoca realmente depende del tipo estático del tipo sujeto, utilizando el proceso de resolución de métodos descrito en la sección siguiente. Los métodos definidos con WITH FUNCTION ACCESS también se pueden invocar utilizando la invocación de funciones, en cuyo caso se aplican las reglas normales para la resolución de la función. Si la resolución de la función da como resultado un método definido con WITH FUNCTION ACCESS, se procesan todos los pasos siguientes de invocación de métodos. Capítulo 2. Elementos del lenguaje 193
- 220. El acceso a los métodos se controla mediante el privilegio EXECUTE. Se utilizan sentencias GRANT y REVOKE para especificar quién puede o no puede ejecutar un método o conjunto de métodos determinado. Se necesita el privilegio EXECUTE (o la autoridad DBADM) para invocar un método. La persona que define el método recibe el privilegio EXECUTE de forma automática. Si se trata de un método externo o un método SQL que tienen la opción WITH GRANT en todos los objetos subyacentes, la persona que lo define también recibe la opción WITH GRANT con el privilegio EXECUTE sobre el método. La persona que lo define (o SYSADM o DBADM) debe otorgarlo entonces al usuario que desee invocar el método desde una sentencia de SQL o hacer referencia al mismo en una sentencia de DDL (como, por ejemplo, CREATE VIEW, CREATE TRIGGER o al definir una restricción). Si no se otorga a un usuario el privilegio EXECUTE, el algoritmo de resolución de métodos no tendrá en cuenta el método aunque éste se corresponda mucho mejor. Resolución de métodos Después de invocar un método, el gestor de bases de datos debe decidir cuál de los posibles métodos con el mismo nombre es el “más apropiado ”. Las funciones (incorporadas o definidas por el usuario) no se tienen en cuenta durante la resolución del método. Un argumento es un valor que se pasa a un método en una invocación. Cuando un método se invoca en SQL, se le pasa el argumento sujeto (de algún tipo estructurado) y opcionalmente una lista de argumentos. Son argumentos posicionales en tanto que la semántica de dichos argumentos viene determinada por su posición en la lista de argumentos. Un parámetro es una definición formal de una entrada en un método. Cuando se define un método para la base de datos, ya sea implícitamente (método generado por el sistema para un tipo) o por un usuario (método definido por el usuario), se especifican sus parámetros (con el parámetro sujeto como primer parámetro) y el orden de sus definiciones determina sus posiciones y su semántica. Por tanto, cada parámetro es una entrada posicional determinada de un método. En la invocación, un argumento corresponde a un parámetro determinado en virtud a la posición que éste ocupe en la lista de argumentos. El gestor de bases de datos utiliza el nombre de método proporcionado en la invocación, el privilegio EXECUTE sobre el método, el número y los tipos de datos de los argumentos, todos los métodos que tienen el mismo nombre para el tipo estático del argumento sujeto y los tipos de datos de sus parámetros correspondientes como base para decidir si selecciona o no un método. A continuación se muestran los resultados posibles del proceso de decisión: v Un método determinado se considera que es el más apropiado. Por ejemplo, para los métodos denominados RISK del tipo SITE con signaturas definidas como: 194 Consulta de SQL, Volumen 1
- 221. PROXIMITY(INTEGER) FOR SITE PROXIMITY(DOUBLE) FOR SITE la siguiente invocación de método (donde ST es una columna SITE, DB es una columna DOUBLE): SELECT ST..PROXIMITY(DB) ... se elegiría el segundo PROXIMITY. La siguiente invocación de método (donde SI es una columna SMALLINT): SELECT ST..PROXIMITY(SI) ... elegirá el primer PROXIMITY, ya que SMALLINT se puede promover a INTEGER y es una coincidencia mejor que DOUBLE, que se encuentra más abajo en la lista de prioridad. Cuando se tienen en cuenta argumentos que son tipos estructurados, la lista de prioridad incluye los supertipos del tipo estático del argumento. La función que mejor se ajusta es la definida con el parámetro de supertipo más cercano, en la jerarquía de tipos estructurados, al tipo estático del argumento de función. v Ningún método se considera una opción aceptable. Tomando como ejemplo las dos mismas funciones del caso anterior y la siguiente referencia de función (donde C es una columna CHAR(5)): SELECT ST..PROXIMITY(C) ... el argumento es incoherente con el parámetro de las dos funciones PROXIMITY. v Se selecciona un método determinado basándose en los métodos de la jerarquía de tipos y en el número y tipos de datos de los argumentos pasados en la invocación. Por ejemplo, para los métodos denominados RISK de los tipos SITE y DRILLSITE (un subtipo de SITE) con signaturas definidas como: RISK(INTEGER) FOR DRILLSITE RISK(DOUBLE) FOR SITE y la siguiente invocación de método (donde DRST es una columna DRILLSITE, DB es una columna DOUBLE): SELECT DRST..RISK(DB) ... se elegirá el segundo RISK, ya que DRILLSITE se puede promocionar a SITE. La siguiente referencia a método (donde SI es una columna SMALLINT): SELECT DRST..RISK(SI) ... Capítulo 2. Elementos del lenguaje 195
- 222. elegirá el primer RISK, ya que SMALLINT se puede promocionar a INTEGER, que está más cerca en la lista de prioridad que DOUBLE, y DRILLSITE es una opción mejor que SITE, que es un supertipo. Los métodos con la misma jerarquía de tipos no pueden tener las mismas signaturas, teniendo en cuenta parámetros distintos al parámetro sujeto. Determinación de la mejor opción La comparación de los tipos de datos de los argumentos con los tipos de datos definidos de los parámetros de los métodos en cuestión, constituye la base primordial para decidir qué método de un grupo de métodos con el mismo nombre se considera el “más apropiado”. Observe que los tipos de datos de los resultados de los métodos en cuestión no intervienen en esa decisión. La resolución del método se realiza siguiendo los pasos siguientes: 1. En primer lugar, busque todos los métodos del catálogo (SYSCAT.ROUTINES) que cumplan las condiciones siguientes: v El nombre del método coincide con el nombre de invocación, y el parámetro sujeto es el mismo tipo o es un supertipo del tipo estático del argumento sujeto. v La persona que lo invoca tiene el privilegio EXECUTE sobre el método. v El número de parámetros definidos debe coincidir con la invocación. v Cada argumento de invocación coincide con el tipo de datos del parámetro definido correspondiente del método o es “promocionable” a ese tipo. 2. A continuación, examine de izquierda a derecha cada argumento de la invocación del método. El argumento situado más a la izquierda (y por tanto el primer argumento) es el parámetro SELF implícito. Por ejemplo, un método definido para el tipo ADDRESS_T tiene un primer parámetro implícito de tipo ADDRESS_T. Para cada argumento, elimine todas las funciones que no sean la mejor coincidencia para ese argumento. La mejor opción para un argumento dado es el primer tipo de datos que aparece en la lista de prioridad correspondiente al tipo de datos del argumento para el cual existe una función con un parámetro de ese tipo de datos. La longitud, la precisión, la escala y el atributo FOR BIT DATA no se tienen en cuenta en esta comparación. Por ejemplo, un argumento DECIMAL(9,1) se considera una coincidencia exacta para un parámetro DECIMAL(6,5) mientras que un argumento VARCHAR(19) es una coincidencia exacta para un parámetro VARCHAR(6). La mejor coincidencia para un argumento de tipo estructurado definido por el usuario es el propio argumento; la siguiente mejor coincidencia es el supertipo inmediato, y así sucesivamente para cada supertipo del 196 Consulta de SQL, Volumen 1
- 223. argumento. Observe que sólo se tiene en cuenta el tipo estático (tipo declarado) del argumento de tipo estructurado, no el tipo dinámico (tipo más específico). 3. Como máximo, después del paso 2 queda un método elegible. Este es el método que se elige. 4. Si después del paso 2 no queda ningún método elegible, se produce un error (SQLSTATE 42884). Ejemplo de resolución de método A continuación se muestra un ejemplo de una resolución de método satisfactoria. Existen siete métodos FOO para tres tipos estructurados definidos en una jerarquía de GOVERNOR como un subtipo de EMPEROR, como un subtipo de HEADOFSTATE, registrados con las signaturas siguientes: CREATE METHOD FOO (CHAR(5), INT, DOUBLE) FOR HEADOFSTATE SPECIFIC FOO_1 ... CREATE METHOD FOO (INT, INT, DOUBLE) FOR HEADOFSTATE SPECIFIC FOO_2 ... CREATE METHOD FOO (INT, INT, DOUBLE, INT) FOR HEADOFSTATE SPECIFIC FOO_3 ... CREATE METHOD FOO (INT, DOUBLE, DOUBLE) FOR EMPEROR SPECIFIC FOO_4 ... CREATE METHOD FOO (INT, INT, DOUBLE) FOR EMPEROR SPECIFIC FOO_5 ... CREATE METHOD FOO (SMALLINT, INT, DOUBLE) FOR EMPEROR SPECIFIC FOO_6 ... CREATE METHOD FOO (INT, INT, DEC(7,2)) FOR GOVERNOR SPECIFIC FOO_7 ... La referencia al método es la siguiente (donde I1 e I2 son columnas INTEGER, D es una columna DECIMAL y E es una columna EMPEROR): SELECT E..FOO(I1, I2, D) ... De acuerdo con el algoritmo... v FOO_7 se elimina como candidato, porque el tipo GOVERNOR es un subtipo (no un supertipo) de EMPEROR. v FOO_3 se elimina como candidato, porque tiene un número erróneo de parámetros. v FOO_1 y FOO_6 se eliminan porque, en ambos casos, el primer argumento (no el argumento sujeto) no se puede promocionar al tipo de datos del primer parámetro. Como sigue habiendo más de un candidato, los argumentos se tienen en cuenta siguiendo un orden. v Para el argumento sujeto, FOO_2 es un supertipo, mientras que FOO_4 y FOO_5 coinciden con el argumento sujeto. v Para el primer argumento, los métodos restantes, FOO_4 y FOO_5, coinciden exactamente con el tipo del argumento. No se puede asignar ningún método y, por tanto, se debe examinar el argumento siguiente. v Para este segundo argumento, FOO_5 es una coincidencia exacta pero FOO_4 no lo es, por lo cual se descarta. Esto deja FOO_5 como método elegido. Capítulo 2. Elementos del lenguaje 197
- 224. Invocación de métodos Una vez seleccionado el método, pueden todavía existir algunos motivos por los cuales no se pueda utilizar el método. Cada método está definido para devolver un resultado con un tipo de datos específico. Si este tipo de datos resultante no es compatible con el contexto donde se invoca el método, se produce un error. Por ejemplo, suponga que se definen los siguientes métodos llamados STEP, cada uno con un tipo de datos diferentes como resultado: STEP(SMALLINT) FOR TYPEA RETURNS CHAR(5) STEP(DOUBLE) FOR TYPEA RETURNS INTEGER y la siguiente referencia a método (donde S es una columna SMALLINT y TA es una columna TYPEA): SELECT 3 + TA..STEP(S) ... en este caso se elige el primer STEP, pues hay una coincidencia exacta del tipo del argumento. Se produce un error en la sentencia, porque el tipo resultante es CHAR(5) en lugar de un tipo numérico, tal como necesita un argumento del operador de suma. Empezando por el método que se ha seleccionado, se utiliza el algoritmo descrito en “Asignación dinámica de métodos” para crear el conjunto de métodos asignables durante la compilación. En “Asignación dinámica de métodos” se describe con exactitud el método que se invoca. Observe que cuando el método seleccionado es un método conservador del tipo: v el tipo estático resultante tras la resolución de la función es el mismo que el tipo estático del argumento sujeto de la invocación del método v el tipo dinámico resultante cuando se invoca el método es el mismo que el tipo dinámico del argumento sujeto de la invocación del método. Esto puede ser un subtipo del tipo resultante especificado en la definición del método conservador del tipo, que a su vez puede ser un supertipo del tipo dinámico devuelto realmente cuando se procesa el método. En los casos donde los argumentos de la invocación del método no coinciden exactamente con los tipos de datos de los parámetros del método seleccionado, los argumentos se convierten al tipo de datos del parámetro durante la ejecución, utilizando las mismas reglas que para la asignación a columnas. Esto incluye el caso en el que la precisión, escala o longitud difiere entre el argumento y el parámetro, pero excluye el caso en el que el tipo dinámico del argumento es un subtipo del tipo estático del parámetro. 198 Consulta de SQL, Volumen 1
- 225. Asignación dinámica de métodos Los métodos proporcionan la funcionalidad y encapsulan los datos de un tipo. Un método se define para un tipo y siempre puede asociarse con este tipo. Uno de los parámetros del método es el parámetro implícito SELF. El parámetro SELF es del tipo para el que se ha declarado el método. El argumento que se pasa al argumento SELF cuando se invoca el método en una sentencia DML se denomina sujeto. Cuando se selecciona un método utilizando la resolución de métodos (vea “Resolución de métodos” en la página 194), o se ha especificado un método en una sentencia de DDL, este método se conoce como el “método autorizado aplicable más específico”. Si el sujeto es de tipo estructurado, es posible que el método tenga uno o varios métodos alternativos. Entonces, DB2 debe determinar a cuál de estos métodos debe invocar, en base al tipo dinámico (tipo más específico) del sujeto en tiempo de ejecución. Esta determinación se denomina “determinación del método asignable más específico”. Este proceso se describe aquí. 1. En la jerarquía de métodos, busque el método original del que forme parte el método autorizado más específico. Se denomina el método raíz. 2. Cree el conjunto de métodos asignables, que debe incluir los siguientes: v El método autorizado aplicable más específico. v Cualquier método que altere temporalmente el método autorizado aplicable más específico y que esté definido para un tipo que sea un subtipo del sujeto de esta invocación. 3. Determine el método asignable más específico, de la forma siguiente: a. Empiece con un método arbitrario que sea un elemento del conjunto de métodos asignables y que sea un método del tipo dinámico del sujeto o de uno de sus supertipos. Es el método asignable inicial más específico. b. Itere por los elementos del conjunto de métodos asignables. Para cada método: Si el método está definido para uno de los subtipos adecuados del tipo para el que está definido el método asignable más específico y si está definido para uno de los supertipos del tipo más específico del sujeto, repita el paso 2 con este método como el método asignable más específico; de lo contrario, siga iterando. 4. Invoque el método asignable más específico. Ejemplo: Se proporcionan tres tipos: ″Persona″, ″Empleado″ y″Director″. Existe un método original ″ingresos″, definido para ″Persona″, que calcula los ingresos de una persona. Por omisión, una persona es un desempleado (un niño, un jubilado, etc.). Por lo tanto, ″ingresos″ para el tipo ″Persona″ siempre devuelve cero. Para el tipo ″Empleado″ y para el tipo ″Director″, deben aplicarse Capítulo 2. Elementos del lenguaje 199
- 226. algoritmos distintos para calcular los ingresos. Por lo tanto, el método ″ingresos″ para el tipo ″Persona″ se altera temporalmente en ″Empleado″ y en ″Director″. Cree y rellene una tabla de la manera siguiente: CREATE TABLE aTable (id integer, personColumn Person); INSERT INTO aTable VALUES (0, Persona()), (1, Empleado()), (2, Director()); Liste todas las personas que tengan unos ingresos mínimos de $40000: SELECT id, persona, name FROM aTable WHERE persona..ingresos() >= 40000; Utilizando la resolución de métodos, se selecciona el método ″ingresos″ para el tipo ″Persona″ como el método autorizado aplicable más específico. 1. El método raíz es ″ingresos″ para ″Persona″. 2. El segundo paso del algoritmo anterior se lleva a cabo para construir el conjunto de métodos asignables: v Se incluye el método ″ingresos″ para el tipo ″Persona″, porque es el método autorizado aplicable más específico. v Se incluye el método ″ingresos″ para el tipo ″Empleado″ e ″ingresos″ para ″Director″, porque ambos métodos alteran temporalmente el método raíz y tanto ″Empleado″ como ″Director″ son subtipos de ″Persona″. Por lo tanto, el conjunto de métodos asignables es: {″ingresos″ para ″Persona″, ″ingresos″ para ″Empleado″, ″ingresos″ para ″Director″}. 3. Determine el método asignable más específico: v Para un sujeto cuyo tipo más específico sea ″Persona″: a. Deje que el método asignable inicial más específico sea ″ingresos″ para el tipo ″Persona″. b. Como no hay ningún otro método en el conjunto de métodos asignables que esté definido para un subtipo adecuado de ″Persona″ y para un supertipo del tipo más específico del sujeto, ″ingresos″ para el tipo ″Persona″ es el método asignable más específico. v Para un sujeto cuyo tipo más específico sea ″Empleado″: a. Deje que el método asignable inicial más específico sea ″ingresos″ para el tipo ″Persona″. b. Itere por el conjunto de métodos asignables. Como el método ″ingresos″ para el tipo ″Empleado″ está definido para un subtipo adecuado de ″Persona″ y para un supertipo del tipo más específico del sujeto (Nota: Un tipo es su propio supertipo y subtipo)el método ″ingresos″ para el tipo ″Empleado″ es una opción mejor para el 200 Consulta de SQL, Volumen 1
- 227. método asignable más específico. Repita este paso con el método ″ingresos″ para el tipo ″Empleado″ como el método asignable más específico. c. Como no hay ningún otro método en el conjunto de métodos asignables que esté definido para un subtipo adecuado de ″Empleado″ y para un supertipo del tipo más específico del sujeto, el método ″ingresos″ para el tipo ″Empleado″ es el método asignable más específico. v Para un sujeto cuyo tipo más específico sea ″Director″: a. Deje que el método asignable inicial más específico sea ″ingresos″ para el tipo ″Persona″. b. Itere por el conjunto de métodos asignables. Como el método ″ingresos″ para el tipo ″Director″ está definido para un subtipo adecuado de ″Persona″ y para un supertipo del tipo más específico del sujeto (Nota: Un tipo es su propio supertipo y subtipo), el método ″ingresos″ para el tipo ″Director″ es una opción mejor para el método asignable más específico. Repita este paso con el método ″ingresos″ para el tipo ″Director″ como el método asignable más específico. c. Como no hay ningún otro método en el conjunto de métodos asignables que esté definido para un subtipo adecuado de ″Director″ y para un supertipo del tipo más específico del sujeto, el método ″ingresos″ para el tipo ″Director″ es el método asignable más específico. 4. Invoque el método asignable más específico. Información relacionada: v “Promoción de tipos de datos” en la página 120 v “Asignaciones y comparaciones” en la página 126 Capítulo 2. Elementos del lenguaje 201
- 228. Expresiones Una expresión especifica un valor. Puede ser un valor simple, formado sólo por una constante o un nombre de columna, o puede ser más complejo. Si se utilizan repetidamente expresiones complejas similares, puede plantearse la utilización de una función SQL para encapsular una expresión común. En una base de datos Unicode, una expresión que acepte una serie de caracteres o gráfica aceptará todo tipo de serie para el que se soporte la conversión. expresión: operador función + (expresión) − constante nombre-columna variable-lengprinc registro-especial (1) (seleccióncompleta-escalar) (2) duración-etiquetada (3) expresión-case (4) especificación-cast (5) operación-desreferencia (6) función-OLAP (7) función-XML (8) invocación-método (9) tratamiento-subtipo (10) referencia-secuencia operador: (11) CONCAT / * + − 202 Consulta de SQL, Volumen 1
- 229. Notas: 1 Vea “Selección completa escalar” en la página 210 para obtener más información. 2 Vea “Duraciones etiquetadas” en la página 210 para obtener más información. 3 Vea “Expresiones CASE” en la página 216 para obtener más información. 4 Vea “Especificaciones CAST” en la página 219 para obtener más información. 5 Vea “Operaciones de desreferencia” en la página 222 para obtener más información. 6 Vea “Funciones OLAP” en la página 223 para obtener más información. 7 Vea “Funciones XML” en la página 230 para obtener más información. 8 Vea “Invocación de métodos” en la página 235 para obtener más información. 9 Vea “Tratamiento de los subtipos” en la página 236 para obtener más información. 10 Vea “Referencia de secuencia” en la página 237 para obtener más información. 11 || se utiliza como sinónimo de CONCAT. Expresiones son operadores Si no se utilizan operadores, el resultado de la expresión es el valor especificado. Ejemplos: SALARY:SALARY’SALARY’MAX(SALARY) Expresiones con el operador de concatenación El operador de concatenación (CONCAT) enlaza dos operandos de serie para formar una expresión de serie. Los operandos de la concatenación deben ser series compatibles. Es preciso tener en cuenta que una serie binaria no se puede concatenar con una serie de caracteres, incluso las que se definen como FOR BIT DATA (SQLSTATE 42884). En una base de datos Unicode, una concatenación que implique operandos de series de caracteres y operandos de series gráficas convertirá primero los operandos de caracteres en operandos gráficos. Observe que, en una base de datos que no sea Unicode, la concatenación no puede implicar operandos de caracteres y operandos gráficos. Capítulo 2. Elementos del lenguaje 203
- 230. Si ambos operandos pueden ser nulos, el resultado también podrá ser nulo; si alguno de ellos es nulo, el resultado es el valor nulo. De lo contrario, el resultado constará de la serie del primer operando seguida por la del segundo. La comprobación se efectúa para detectar los datos mixtos formados defectuosamente al realizar la concatenación. La longitud del resultado es la suma de las longitudes de los operandos. El tipo de datos y el atributo de longitud del resultado vienen determinados por los de los operandos, tal como se muestra en la tabla siguiente: Tabla 12. Tipo de datos y longitud de los operandos concatenados Operandos Atributos de Resultado longitud combinados CHAR(A) CHAR(B) <255 CHAR(A+B) CHAR(A) CHAR(B) >254 VARCHAR(A+B) CHAR(A) VARCHAR(B) <4001 VARCHAR(A+B) CHAR(A) VARCHAR(B) >4000 LONG VARCHAR CHAR(A) LONG VARCHAR - LONG VARCHAR VARCHAR(A) VARCHAR(B) <4001 VARCHAR(A+B) VARCHAR(A) VARCHAR(B) >4000 LONG VARCHAR VARCHAR(A) LONG VARCHAR - LONG VARCHAR LONG VARCHAR LONG VARCHAR - LONG VARCHAR CLOB(A) CHAR(B) - CLOB(MIN(A+B, 2G)) CLOB(A) VARCHAR(B) - CLOB(MIN(A+B, 2G)) CLOB(A) LONG VARCHAR - CLOB(MIN(A+32K, 2G)) CLOB(A) CLOB(B) - CLOB(MIN(A+B, 2G)) GRAPHIC(A) GRAPHIC(B) <128 GRAPHIC(A+B) GRAPHIC(A) GRAPHIC(B) >127 VARGRAPHIC(A+B) GRAPHIC(A) VARGRAPHIC(B) <2001 VARGRAPHIC(A+B) GRAPHIC(A) VARGRAPHIC(B) >2000 LONG VARGRAPHIC GRAPHIC(A) LONG VARGRAPHIC - LONG VARGRAPHIC 204 Consulta de SQL, Volumen 1
- 231. Tabla 12. Tipo de datos y longitud de los operandos concatenados (continuación) Operandos Atributos de Resultado longitud combinados VARGRAPHIC(A) VARGRAPHIC(B) <2001 VARGRAPHIC(A+B) VARGRAPHIC(A) VARGRAPHIC(B) >2000 LONG VARGRAPHIC VARGRAPHIC(A) LONG VARGRAPHIC - LONG VARGRAPHIC LONG VARGRAPHIC LONG - LONG VARGRAPHIC VARGRAPHIC DBCLOB(A) GRAPHIC(B) - DBCLOB(MIN(A+B, 1G)) DBCLOB(A) VARGRAPHIC(B) - DBCLOB(MIN(A+B, 1G)) DBCLOB(A) LONG VARGRAPHIC - DBCLOB(MIN(A+16K, 1G)) DBCLOB(A) DBCLOB(B) - DBCLOB(MIN(A+B, 1G)) BLOB(A) BLOB(B) - BLOB(MIN(A+B, 2G)) Observe que, para que haya compatibilidad con las versiones anteriores, no hay escalada automática de los resultados que implica tipos de datos LONG a los tipos de datos LOB. Por ejemplo, la concatenación de un valor CHAR(200) y un valor LONG VARCHAR totalmente completo da como resultado un error en lugar de una promoción de un tipo de datos CLOB. La página de códigos del resultado se considera una página de códigos derivada que viene determinada por la página de códigos de sus operandos. Un operando puede ser un marcador de parámetros. Si se utiliza un marcador de parámetros, el tipo de datos y los atributos de longitud del operando se consideran los mismos que los del operando que no es el marcador de parámetros. El orden de las operaciones tiene su importancia, puesto que determina estos atributos en casos en los que se produce una concatenación anidada. Ejemplo 1: Si FIRSTNME es Pierre y LASTNAME es Fermat, entonces lo siguiente: FIRSTNME CONCAT ’ ’ CONCAT LASTNAME devuelve el valor Pierre Fermat Ejemplo 2: Dado: Capítulo 2. Elementos del lenguaje 205
- 232. v COLA definido como VARCHAR(5) con valor ’AA’ v :host_var definida como una variable del lenguaje principal con una longitud 5 y el valor ’BB ’ v COLC definido como CHAR(5) con valor ’CC’ v COLD definido como CHAR(5) con valor ’DDDDD’ El valor de COLA CONCAT :host_var CONCAT COLC CONCAT COLD es ’AABB CC DDDDD’ El tipo de datos es VARCHAR, el atributo de longitud es 17 y la página de códigos resultante es la página de códigos de la base de datos. Ejemplo 3: Dado: COLA definido como CHAR(10) COLB definido como VARCHAR(5) El marcador de parámetros de la expresión: COLA CONCAT COLB CONCAT ? se considera VARCHAR(15), porque COLA CONCAT COLB se evalúa primero, dando como resultado el primer operando de la segunda operación CONCAT. Tipos definidos por el usuario No se puede utilizar un tipo definido por el usuario con el operador de concatenación, aunque sea un tipo diferenciado con un tipo de datos fuente de tipo serie. Para poder concatenar, es preciso crear una función con el operador CONCAT como fuente. Por ejemplo, si existieran los tipos diferenciados TITLE y TITLE_DESCRIPTION y ambos tuvieran los tipos de datos VARCHAR(25), la siguiente función definida por el usuario, ATTACH, se podría utilizar para concatenarlos. CREATE FUNCTION ATTACH (TITLE, TITLE_DESCRIPTION) RETURNS VARCHAR(50) SOURCE CONCAT (VARCHAR(), VARCHAR()) También existe la posibilidad de sobrecargar el operador de concatenación empleando una función definida por el usuario para añadir los tipos de datos nuevos. CREATE FUNCTION CONCAT (TITLE, TITLE_DESCRIPTION) RETURNS VARCHAR(50) SOURCE CONCAT (VARCHAR(), VARCHAR()) Expresiones con operadores aritméticos Si se utilizan operadores aritméticos, el resultado de la expresión es un valor derivado de la aplicación de los operadores a los valores de los operandos. Si cualquier operando puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en sí, el resultado puede ser nulo. 206 Consulta de SQL, Volumen 1
- 233. Si algún operando tiene el valor nulo, el resultado de la expresión es el valor nulo. Los operadores numéricos se pueden aplicar a tipos numéricos con signo y a tipos de fecha y hora (vea “Aritmética de fecha y hora en SQL” en la página 211). Por ejemplo, USER+2 no es válido. Las funciones derivadas se pueden definir para operaciones aritméticas sobre tipos diferenciados con un tipo fuente que sea un tipo numérico con signo. El operador de prefijo + (más unario) no modifica su operando. El operador de prefijo − (menos unario) invierte el signo de un operando distinto de cero y, si el tipo de datos de A es un entero pequeño, el tipo de datos de −A será un entero grande. El primer carácter del símbolo que sigue a un operador de prefijo no debe ser un signo más ni un signo menos. Los operadores infijos +, −, * y / especifican, respectivamente, una suma, una resta, una multiplicación y una división. El valor del segundo operando de una división no debe ser cero. Estos operadores también se pueden tratar como funciones. Por consiguiente, la expresión ″+″(a,b) es equivalente a la función de “operador” cuya expresión es a+b. Errores aritméticos Si se produce un error aritmético como, por ejemplo, una división por cero o se produce un desbordamiento numérico durante el proceso de una expresión, se devuelve un error y la sentencia de SQL que procesa la expresión falla con un error (SQLSTATE 22003 ó 22012). Una base de datos puede configurarse (utilizando DFT_SQLMATHWARN establecido en sí) para que los errores aritméticos devuelvan un valor nulo para la expresión, emitan un aviso (SQLSTATE 01519 ó 01564) y prosigan con el proceso de la sentencia de SQL. Cuando los errores aritméticos se tratan como nulos, hay implicaciones en los resultados de las sentencias de SQL. A continuación encontrará algunos ejemplos de dichas implicaciones. v Un error aritmético que se produce en la expresión que es el argumento de una función de columna provoca que se ignore la fila en la determinación del resultado de la función de columna. Si el error aritmético ha sido un desbordamiento, puede afectar de manera significativa a los valores del resultado. v Un error aritmético que se produce en la expresión de un predicado en una cláusula WHERE puede hacer que no se incluyan filas en el resultado. v Un error aritmético que se produce en la expresión de un predicado en una restricción de comprobación da como resultado el proceso de actualización o inserción ya que la restricción no es falsa. Capítulo 2. Elementos del lenguaje 207
- 234. Si estos tipos de efectos no son aceptables, deben seguirse pasos adicionales para manejar el error aritmético y producir resultados aceptables. Algunos ejemplos son: v añadir una expresión case para comprobar la división por cero y establecer el valor deseado para dicha situación v añadir predicados adicionales para manejar los nulos (por ejemplo, una restricción de comprobación en columnas sin posibilidad de nulos daría: check (c1*c2 is not null and c1*c2>5000) para hacer que la restricción se violase en un desbordamiento). Dos operandos enteros Si ambos operandos de un operador aritmético son enteros, la operación se realiza en binario y el resultado es un entero grande a no ser que uno de los operandos (o ambos) sea un entero superior, en cuyo caso el resultado es un entero superior. Se pierde cualquier resto de una división. El resultado de una operación aritmética de enteros (incluyendo el menos unitario) debe estar dentro del rango del tipo del resultado. Operandos enteros y decimales Si un operando es un entero y el otro es un decimal, la operación se realiza en decimal utilizando una copia temporal del entero que se habrá convertido a número decimal con la precisión p y la escala 0; p es 19 para un entero superior, 11 para un entero grande y 5 para un entero pequeño. Dos operandos decimales Si los dos operandos son decimales, la operación se efectúa en decimal. El resultado de cualquier operación aritmética decimal es un número decimal con una precisión y una escala que dependen de la operación y de la precisión y la escala de los operandos. Si la operación es una suma o una resta y los operandos no tienen la misma escala, la operación se efectúa con una copia temporal de uno de los operandos. La copia del operando más corto se extiende con ceros de cola de manera que la parte de la fracción tenga el mismo número de dígitos que el otro operando. El resultado de una operación decimal no debe tener una precisión mayor que 31. El resultado de una suma, resta y multiplicación decimal se obtiene de un resultado temporal que puede tener una precisión mayor que 31. Si la precisión del resultado temporal no es mayor que 31, el resultado final es el mismo que el resultado temporal. Aritmética decimal en SQL Las fórmulas siguientes definen la precisión y la escala del resultado de las operaciones decimales en SQL. Los símbolos p y s indican la precisión y la escala del primer operando y los símbolos p' y s' indican y la precisión y la escala del segundo operando. 208 Consulta de SQL, Volumen 1
- 235. Sumas y restas La precisión es min(31,max(p-s,p’-s’) +max(s,s’)+1). La escala del resultado de una suma o una resta es max (s,s’). Multiplicaciones La precisión del resultado de una multiplicación es min (31,p+p’) y la escala es min(31,s+s’). Divisiones La precisión del resultado de la división es 31. La escala es 31-p+s-s'. La escala no debe ser negativa. Nota: El parámetro de configuración de base de datos MIN_DEC_DIV_3 modifica la escala para las operaciones aritméticas decimales que incluyen la división. Si el valor del parámetro se establece en NO, la escala se calcula como 31-p+s-s'. Si el parámetro se establece en YES, la escala se calcula como MAX(3, 31-p+ s-s'). Esto asegura que el resultado de una división decimal tenga siempre una escala de 3 como mínimo (la precisión es siempre 31). Operandos de coma flotante Si cualquiera de los dos operandos de un operador aritmético es de coma flotante, la operación se realiza en coma flotante, convirtiendo primero los operandos a números de coma flotante de doble precisión, si es necesario. Por lo tanto, si cualquier elemento de una expresión es un número de coma flotante, el resultado de la expresión es un número de coma flotante de precisión doble. Una operación en la que intervenga un número de coma flotante y un entero se realiza con una copia temporal del entero que se ha convertido a coma flotante de precisión doble. Una operación en la que intervenga un número de coma flotante y un número decimal se efectúa con una copia temporal del número decimal que se ha convertido a coma flotante de precisión doble. El resultado de una operación de coma flotante debe estar dentro del rango de los números de coma flotante. Tipos definidos por el usuarios como operandos Un tipo definido por el usuario no puede utilizarse con operadores aritméticos ni siquiera aunque el tipo de datos fuente sea numérico. Para llevar a cabo una operación aritmética, cree una función con el operador aritmético como fuente. Por ejemplo, si existen los tipos diferenciados INCOME y EXPENSES, y ambos tienen tipos de datos DECIMAL(8,2), se podría utilizar la función REVENUE definida por el usuario para restar uno de otro, de la forma siguiente: CREATE FUNCTION REVENUE (INCOME, EXPENSES) RETURNS DECIMAL(8,2) SOURCE "-" (DECIMAL, DECIMAL) Capítulo 2. Elementos del lenguaje 209
- 236. El operador - (menos) se puede sobrecargar de forma alternativa utilizando la función definida por el usuario para restar los tipos de datos nuevos. CREATE FUNCTION "-" (INCOME, EXPENSES) RETURNS DECIMAL(8,2) SOURCE "-" (DECIMAL, DECIMAL) Selección completa escalar Una selección completa escalar, tal como se utiliza en una expresión, es una selección completa, entre paréntesis, que devuelve una única fila formada por un solo valor de columna. Si la selección completa no devuelve una fila, el resultado de la expresión es el valor nulo. Si el elemento de la lista de selección es una expresión que simplemente es un nombre de columna o una operación de desreferencia, el nombre de columna del resultado está basado en el nombre de la columna. Operaciones de fecha y hora y duraciones Los valores de fecha y hora se pueden aumentar, disminuir y restar. Estas operaciones pueden incluir números decimales llamados duraciones. A continuación se muestra una definición de las duraciones y una especificación de las reglas para la aritmética de la fecha y hora. Una duración es un número que representa un intervalo de tiempo. Existen cuatro tipos de duraciones: Duraciones etiquetadas duración-etiquetada: función YEAR (expresión) YEARS constante MONTH nombre-columna MONTHS variable-lengprinc DAY DAYS HOUR HOURS MINUTE MINUTES SECOND SECONDS MICROSECOND MICROSECONDS Una duración etiquetada representa una unidad de tiempo específica expresada por un número (que puede ser el resultado de una expresión) seguido de una de las siete palabras clave de duración: YEARS, MONTHS, DAYS, HOURS, MINUTES, SECONDS o MICROSECONDS. (También se acepta la forma singular de estas palabras clave: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND y MICROSECOND.) El número especificado se convierte como si se asignara a un número DECIMAL(15,0). Sólo puede utilizarse una duración 210 Consulta de SQL, Volumen 1
- 237. etiquetada como operando de un operador aritmético en el que el otro operando sea un valor de tipo de datos DATE, TIME o TIMESTAMP. Así pues, la expresión HIREDATE + 2 MONTHS + 14 DAYS es válida, mientras que la expresión HIREDATE + (2 MONTHS + 14 DAYS) no lo es. En ambas expresiones, las duraciones etiquetadas son 2 MONTHS (meses) y 14 DAYS (días). Duración de fecha Una duración de fecha representa un número de años, meses y días, expresados como un número DECIMAL(8,0). Para que se interprete correctamente, el número debe tener el formato aaaammdd., donde aaaa representa el número de años, mm el número de meses y dd el número de días. (El punto en el formato indica un tipo de datos DECIMAL.) El resultado de restar un valor de fecha de otro, como sucede en la expresión HIREDATE − BRTHDATE, es una duración de fecha. Duración de hora Una duración de hora representa un número de horas, minutos y segundos, expresado como un número DECIMAL(6,0). Para interpretarse correctamente, el número debe tener el formato hhmmss., donde hh representa el número de horas, mm el número de minutos y ss el número de segundos. (El punto en el formato indica un tipo de datos DECIMAL.) El resultado de restar un valor de hora de otro es una duración de hora. Duración de indicación de fecha y hora Una duración de indicación de fecha y hora representa un número de años, meses, días, horas, minutos, segundos y microsegundos expresado como un número DECIMAL(20,6). Para que se interprete correctamente, el número debe tener el formato aaaammddhhmmss.zzzzzz, donde aaaa, mm, dd, hh, mm, ss y zzzzzz representan el número de años, meses, días, horas, minutos, segundos y microsegundos respectivamente. El resultado de restar un valor de indicación de fecha y hora de otro es una duración de indicación de fecha y hora. Aritmética de fecha y hora en SQL Las únicas operaciones aritméticas que pueden efectuarse con valores de fecha y hora son la suma y la resta. Si un valor de fecha y hora es un operando de suma, el otro operando debe ser una duración. A continuación, encontrará las reglas específicas que rigen la utilización del operador de suma con valores de fecha y hora. v Si un operando es una fecha, el otro operando debe ser una duración de fecha o una duración etiquetada de YEARS, MONTHS o DAYS. v Si un operando es una hora, el otro operando debe ser una duración de hora o una duración etiquetada de HOURS, MINUTES o SECONDS. v Si un operando es una fecha y hora, el otro operando debe ser una duración. Cualquier tipo de duración es válido. Capítulo 2. Elementos del lenguaje 211
- 238. v Ningún operando del operador de suma puede ser un marcador de parámetros. Las normas para la utilización del operador de resta con valores de fecha y hora no son las mismas que para la suma, porque un valor de fecha y hora no puede restarse de una duración, y porque la operación de restar dos valores de fecha y hora no es la misma que la operación de restar una duración de un valor de fecha y hora. A continuación se muestran las normas específicas que rigen la utilización del operador de resta con valores de fecha y hora. v El primer operando es una fecha, el segundo operando debe ser una fecha, una duración de fecha, una representación de una fecha en forma de serie o una duración etiquetada de YEARS, MONTHS o DAYS. v Si el segundo operando es una fecha, el primer operando debe ser una fecha o una representación de una fecha en forma de serie. v Si el primer operando es una hora, el segundo operando debe ser una hora, una duración de hora, una representación de una hora en forma de serie o una duración etiquetada de HOURS, MINUTES o SECONDS. v Si el segundo operando es una hora, el primer operando debe ser una hora o una representación de una hora en forma de serie. v Si el primer operando es una fecha y hora, el segundo operando debe ser una fecha y hora, una representación de una fecha y hora en forma de serie o una duración. v Si el segundo operando es una fecha y hora, el primer operando debe ser una fecha y hora o una representación de una fecha y hora en forma de serie. v Ningún operando del operador de resta puede ser un marcador de parámetros. Aritmética de fecha Las fechas se pueden restar, aumentar o disminuir. Resta de fechas: Al restar un fecha (DATE2) de otra (DATE1) se obtiene como resultado una duración de fecha que especifica el número de años, meses y días entre las dos fechas. El tipo de datos del resultado es DECIMAL(8,0). Si DATE1 es mayor o igual que DATE2, DATE2 se resta de DATE1. Si DATE1 es menor que DATE2, DATE1 se resta de DATE2 y el signo del resultado se convierte en negativo. La descripción siguiente clarifica los pasos que intervienen en el resultado de la operación = DATE1 − DATE2. Si DAY(DATE2) <= DAY(DATE1) entonces DAY(RESULT) = DAY(DATE1) − DAY(DATE2). Si DAY(DATE2) > DAY(DATE1) entonces DAY(RESULT) = N + DAY(DATE1) − DAY(DATE2) donde N = el último día de MONTH(DATE2). MONTH(DATE2) se aumenta en 1. 212 Consulta de SQL, Volumen 1
- 239. Si MONTH(DATE2) <= MONTH(DATE1) entonces MONTH(RESULT) = MONTH(DATE1) - MONTH(DATE2). Si MONTH(DATE2) > MONTH(DATE1) entonces MONTH(RESULT) = 12 + MONTH(DATE1) - MONTH(DATE2). YEAR(DATE2) se aumenta en 1. YEAR(RESULT) = YEAR(DATE1) − YEAR(DATE2). Por ejemplo, el resultado de DATE('15/3/2000') − '31/12/1999' es 00000215. (o una duración de 0 años, 2 meses y 15 días). Incremento y disminución de las fechas: Al añadir o restar una duración a una fecha se obtiene como resultado también una fecha. (En esta operación, un mes equivale a una página de un calendario. La adición de meses a una fecha es como ir pasando páginas a un calendario, empezando por la página en la que aparece la fecha.) El resultado debe estar comprendido entre las fechas 1 de enero de 0001 y 31 de diciembre de 9999, ambos inclusive. Si se suma o resta una duración de años, solamente la parte de la fecha correspondiente a los años se verá afectada. Tanto el mes como el día permanecen inalterados, a no ser que el resultado fuera el 29 de febrero en un año no bisiesto. En este caso, el día se cambia a 28 y se define un indicador de aviso en la SQLCA para indicar el ajuste. Del mismo modo, si se suma o resta una duración de meses, solamente los meses, y los años si fuera necesario, se verán afectados. La parte de una fecha correspondiente a los años no se cambia a no ser que el resultado no fuera válido (31 de setiembre, por ejemplo). En este caso, el día se establece en el último día del mes y se define un indicador de aviso en la SQLCA para indicar el ajuste. Al añadir o restar una duración de días afectará, obviamente, a la parte de la fecha correspondiente a los días y potencialmente al mes y al año. Las duraciones de fecha, ya sean positivas o negativas, también se pueden añadir y restar a las fechas. Tal como ocurre con las duraciones etiquetadas, se obtiene como resultado una fecha válida y se define un indicador de aviso en la SQLCA siempre que se deba efectuar un ajuste de fin de mes. Cuando se suma una duración de fecha positiva a una fecha, o una duración de fecha negativa se resta de una fecha, la fecha aumenta el número especificado de años, meses y días, en ese orden. Así pues, DATE1 + X, donde X es un número DECIMAL(8,0) positivo, equivale a la expresión: DATE1 + YEAR(X) YEARS + MONTH(X) MONTHS + DAY(X) DAYS. Cuando una duración de fecha positiva se resta de una fecha, o bien se añade una duración de fecha negativa a una fecha, la fecha disminuye en el número Capítulo 2. Elementos del lenguaje 213
- 240. días, meses y años especificados, en este orden. Así pues, DATE1 − X, donde X es un número DECIMAL(8,0) positivo, equivale a la expresión: DATE1 − DAY(X) DAYS − MONTH(X) MONTHS − YEAR(X) YEARS. Al añadir duraciones a fechas, la adición de un mes a una fecha determinada da la misma fecha un mes posterior a menos que la fecha no exista en el siguiente mes. En este caso, se establece la fecha correspondiente al último día del siguiente mes. Por ejemplo, 28 de enero más un mes da como resultado 28 de febrero y si se añade un mes al 29, 30 ó 31 de enero también se obtendrá como resultado el 28 de febrero o bien 29 de febrero si se trata de un año bisiesto. Nota: Si se añade uno o más meses a una fecha determinada y del resultado se resta la misma cantidad de meses, la fecha final no tiene por qué ser necesariamente la misma que la original. Aritmética de las horas Las horas se pueden restar, aumentar o disminuir. Resta de los valores de horas: El resultado de restar una hora (HOUR2) de otra (HOUR1) es una duración que especifica el número de horas, minutos y segundos entre las dos horas. El tipo de datos del resultado es DECIMAL(6,0). Si HOUR1 es mayor o igual que HOUR2, HOUR2 se resta de HOUR1. Si HOUR1 es menor que HOUR2, HOUR1 se resta de HOUR2 y el signo del resultado se convierte en negativo. La descripción siguiente clarifica los pasos que intervienen en el resultado de la operación = HOUR1 − HOUR2. Si SECOND(TIME2) <= SECOND(TIME1) entonces SECOND(RESULT) = SECOND(HOUR1) − SECOND(HOUR2). Si SECOND(TIME2) > SECOND(TIME1) entonces SECOND(RESULT) = 60 + SECOND(HOUR1) − SECOND(HOUR2). MINUTE(HOUR2) se aumenta entonces en 1. Si MINUTE(TIME2) <= MINUTE(TIME1)entonces MINUTE(RESULT) = MINUTE(HOUR1) − MINUTE(HOUR2). Si MINUTE(TIME1) > MINUTE(TIME1) entonces MINUTE(RESULT) = 60 + MINUTE(HOUR1) − MINUTE(HOUR2). HOUR(HOUR2) se aumenta entonces en 1. HOUR(RESULT) = HOUR(TIME1) − HOUR(TIME2). Por ejemplo, el resultado de TIME(’11:02:26’) − ’00:32:56’ es 102930. (una duración de 10 horas, 29 minutos y 30 segundos). Incremento y disminución de los valores de horas: El resultado de sumar una duración a una hora, o de restar una duración de una hora, es una hora. Se rechaza cualquier desbordamiento o subdesbordamiento de horas, 214 Consulta de SQL, Volumen 1
- 241. garantizando de este modo que el resultado sea siempre una hora. Si se suma o resta una duración de horas, sólo se ve afectada la parte correspondiente a las horas. Los minutos y los segundos no cambian. De manera parecida, si se suma o resta una duración de minutos, sólo se afecta a los minutos y, si fuera necesario, a las horas. La parte correspondiente a los segundos no cambia. Al añadir o restar una duración de segundos afectará, obviamente, a la parte de la fecha correspondiente a los segundos y potencialmente a los minutos y a las horas. Las duraciones de hora, tanto positivas como negativas, pueden también sumarse y restarse a las horas. El resultado es una hora que se ha incrementado o disminuido en el número especificado de horas, minutos y segundos, por ese orden. TIME1 + X, donde “X” es un número DECIMAL(6,0), es equivalente a la expresión: TIME1 + HOUR(X) HOURS + MINUTE(X) MINUTES + SECOND(X) SECONDS Nota: Aunque la hora ’24:00:00’ se acepta como una hora válida, no se devuelve nunca como resultado de una suma o resta de horas, ni siquiera aunque el operando de duración sea cero (por ejemplo, hora(’24:00:00’)±0 segundos = ’00:00:00’). Aritmética de la indicación de fecha y hora Las indicaciones de fecha y hora se pueden restar, incrementar o disminuir. Resta de indicaciones de fecha y hora: El resultado de restar una indicación de fecha y hora (TS2) de otra (TS1) es una duración de indicación de fecha y hora que especifica el número de años, meses, días, horas, minutos, segundos y microsegundos entre las dos indicaciones de fecha y hora. El tipo de datos del resultado es DECIMAL(20,6). Si TS1 es mayor o igual que TS2, TS2 se resta de TS1. Si TS1 es menor que TS2, TS1 se resta de TS2 y el signo del resultado se convierte en negativo. La descripción siguiente clarifica los pasos que intervienen en el resultado de la operación = TS1 − TS2: Si MICROSECOND(TS2) <= MICROSECOND(TS1) entonces MICROSECOND(RESULT) = MICROSECOND(TS1) − MICROSECOND(TS2). Si MICROSECOND(TS2) > MICROSECOND(TS1) entonces MICROSECOND(RESULT) = 1000000 + MICROSECOND(TS1) − MICROSECOND(TS2) y SECOND(TS2) se aumenta en 1. La parte correspondiente a los segundos y minutos de la indicación de fecha y hora se resta tal como se especifica en las reglas para la resta de horas. Capítulo 2. Elementos del lenguaje 215
- 242. Sí HOUR(TS2) <= HOUR(TS1) entonces HOUR(RESULT) = HOUR(TS1) − HOUR(TS2). Si HOUR(TS2) > HOUR(TS1) entonces HOUR(RESULT) = 24 + HOUR(TS1) − HOUR(TS2) y DAY(TS2) se aumenta en 1. La parte correspondiente a la fecha de las indicaciones de fecha y hora se resta tal como se especifica en las reglas para la resta de fechas. Incremento y disminución de indicaciones de fecha y hora: El resultado de sumar o restar una duración con una indicación de fecha y hora es también una indicación de fecha y hora. El cálculo con fechas y horas se realiza tal como se ha definido anteriormente, excepto que se acarrea un desbordamiento o subdesbordamiento a la parte de fecha del resultado, que debe estar dentro del rango de fechas válidas. El desbordamiento de microsegundos pasa a segundos. Prioridad de las operaciones Las expresiones entre paréntesis y las expresiones de desreferencia se evalúan primero de izquierda a derecha. (Los paréntesis también se utilizan en sentencias de subselección, condiciones de búsqueda y funciones. Sin embargo, no deben utilizarse para agrupar arbitrariamente secciones dentro de sentencias de SQL.) Cuando del orden de evaluación no se especifica mediante paréntesis, los operadores de prefijo se aplican antes que la multiplicación y división, y la multiplicación y división se aplican antes que la suma y la resta. Los operadores de un mismo nivel de prioridad se aplican de izquierda a derecha. 1.10 * (Salario + Extra) + Salario / :VAR3 2 1 4 3 Figura 11. Prioridad de las operaciones Expresiones CASE expresión-case: ELSE NULL CASE cláusula-searched-when END cláusula-simple-when ELSE expresión-resultado 216 Consulta de SQL, Volumen 1
- 243. cláusula-searched-when: WHEN condición-búsqueda THEN expresión-resultado NULL cláusula-simple-when: expresión WHEN expresión THEN expresión-resultado NULL Las expresiones CASE permiten seleccionar una expresión en función de la evaluación de una o varias condiciones. En general, el valor de la expresión-case es el valor de la expresión-resultado que sigue a la primera (más a la izquierda) expresión case que se evalúa como cierta. Si ninguna se evalúa como cierta y está presente la palabra clave ELSE, el resultado es el valor de la expresión-resultado o NULL. Si ninguna se evalúa como cierta y no se utiliza la palabra clave ELSE, el resultado es NULL. Tenga presente que cuando una expresión CASE se evalúa como desconocida (debido a valores NULL), la expresión CASE no es cierta y por eso se trata igual que una expresión CASE que se evalúa como falsa. Si la expresión CASE está en una cláusula VALUES, un predicado IN, una cláusula GROUP BY o en una cláusula ORDER BY, la condición-búsqueda de una cláusula-searched-when no puede ser un predicado cuantificado, un predicado IN que hace uso de una selección completa ni un predicado EXISTS (SQLSTATE 42625). Cuando se utiliza la cláusula-simple-when, se comprueba si el valor de la expresión anterior a la primera palabra clave WHEN es igual al valor de la expresión posterior a la palabra clave WHEN. Por lo tanto, el tipo de datos de la expresión anterior a la primera palabra clave WHEN debe ser comparable a los tipos de datos de cada expresión posterior a la palabra o palabras clave WHEN. La expresión anterior a la primera palabra clave WHEN de una cláusula-simple-when no puede incluir ninguna función que sea una variante o que tenga una acción externa (SQLSTATE 42845). Una expresión-resultado es una expresión que sigue a las palabras clave THEN o ELSE. Debe haber, como mínimo, una expresión-resultado en la expresión CASE (NULL no puede especificarse para cada case) (SQLSTATE 42625). Todas las expresiones-resultado deben tener tipos de datos compatibles (SQLSTATE 42804). Capítulo 2. Elementos del lenguaje 217
- 244. Ejemplos: v Si el primer carácter de un número de departamento corresponde a una división dentro de la organización, se puede utilizar una expresión CASE para listar el nombre completo de la división a la que pertenece cada empleado: SELECT EMPNO, LASTNAME, CASE SUBSTR(WORKDEPT,1,1) WHEN ’A’ THEN ’Administración’ WHEN ’B’ THEN ’Recursos humanos’ WHEN ’C’ THEN ’Contabilidad’ WHEN ’D’ THEN ’Diseño’ WHEN ’E’ THEN ’Operaciones’ END FROM EMPLOYEE; v El número de años de formación académica se usa en la tabla EMPLOYEE para obtener el nivel de formación. Una expresión CASE se puede utilizar para agrupar estos datos y para mostrar el nivel de formación. SELECT EMPNO, FIRSTNME, MIDINIT, LASTNAME, CASE WHEN EDLEVEL < 15 THEN ’SECONDARY’ WHEN EDLEVEL < 19 THEN ’COLLEGE’ ELSE ’POST GRADUATE’ END FROM EMPLOYEE v Otro ejemplo interesante del uso de una expresión CASE consiste en la protección de los errores que surjan de una división por 0. Por ejemplo, el siguiente código detecta los empleados que perciben más de un 25% de sus ingresos en comisiones, pero que su sueldo no se basa enteramente en comisiones. SELECT EMPNO, WORKDEPT, SALARY+COMM FROM EMPLOYEE WHERE (CASE WHEN SALARY=0 THEN NULL ELSE COMM/SALARY END) > 0.25; v Las siguientes expresiones CASE son iguales: SELECT LASTNAME, CASE WHEN LASTNAME = ’Haas’ THEN ’Presidente’ ... SELECT LASTNAME, CASE LASTNAME WHEN ’Haas’ THEN ’Presidente’ ... Existen dos funciones escalares, NULLIF y COALESCE, que sirven exclusivamente para manejar un subconjunto de la funcionalidad que una expresión CASE puede ofrecer. La Tabla 13 en la página 219 muestra la expresión equivalente al utilizar CASE o estas funciones. 218 Consulta de SQL, Volumen 1
- 245. Tabla 13. Expresiones CASE equivalentes Expresión Expresión equivalente CASE WHEN e1=e2 THEN NULL ELSE e1 END NULLIF(e1,e2) CASE WHEN e1 IS NOT NULL THEN e1 ELSE e2 COALESCE(e1,e2) END CASE WHEN e1 IS NOT NULL THEN e1 ELSE COALESCE(e1,e2,...,eN) COALESCE(e2,...,eN) END Especificaciones CAST especificación-cast: CAST ( expresión AS tipo-datos NULL marcador-parámetros ) (1) SCOPE nombre-tabla-tipo nombre-vista-tipo Notas: 1 La cláusula SCOPE sólo se aplica al tipo de datos REF. La especificación CAST devuelve el operando cast (el primer operando) convertido al tipo especificado por el tipo de datos. Si no se soporta cast, se devuelve un error (SQLSTATE 42846). expresión Si el operando cast es una expresión (distinta del marcador de parámetros o NULL), el resultado es el valor del argumento convertido al tipo de datos de destino especificado. Al convertir series de caracteres (que no sean CLOB) en una serie de caracteres de longitud diferente, se devuelve un aviso (SQLSTATE 01004) si se truncan otros caracteres que no sean los blancos de cola. Al convertir series de caracteres gráficas (que no sean DBCLOB) en una serie de caracteres gráfica con una longitud diferente, se devuelve un aviso (SQLSTATE 01004) si se truncan otros caracteres que no sean los blancos de cola. Para los operandos BLOB, CLOB y DBCLOB de cast, el mensaje de aviso aparece si se trunca cualquier carácter. NULL Si el operando cast es la palabra clave NULL, el resultado es un valor nulo que tiene el tipo de datos especificado. Capítulo 2. Elementos del lenguaje 219
- 246. marcador-parámetros Un marcador de parámetros (especificado como un signo de interrogación) se suele considerar como una expresión pero se documenta independientemente en este caso porque tiene un significado especial. Si el operando cast es un marcador-parámetros, el tipo de datos especificado se considera una promesa de que la sustitución se podrá asignar al tipo de datos especificado (utilizando la asignación de almacenamiento para series). Un marcador de parámetros como este se considera un marcador de parámetros con tipo. Los marcadores de parámetros con tipo se tratan como cualquier otro valor con tipo en lo referente a la resolución de la función, a DESCRIBE de una lista de selección o a la asignación de columnas. tipo de datos Nombre de un tipo de datos existente. Si el nombre de tipo no está calificado, la vía de acceso de SQL se utiliza para realizar la resolución del tipo de datos. Un tipo de datos que tenga asociados atributos como, por ejemplo, la longitud o la precisión y escala debe incluir dichos atributos al especificar el tipo de datos (CHAR toma por omisión la longitud de 1 y DECIMAL toma por omisión una precisión de 5 y una escala de 0 si no se especifican). Las restricciones sobre los tipos de datos soportados se basan en el operando cast especificado. v Para un operando cast que sea una expresión, los tipos de datos de destino a los que se da soporte dependen del tipo de datos del operando cast (tipo de datos fuente). v Para un operando cast que sea la palabra clave NULL se puede utilizar cualquier tipo de datos existente. v Para un operando cast que sea un marcador de parámetros, el tipo de datos de destino puede ser cualquier tipo de datos existente. Si el tipo de datos es un tipo diferenciado definido por el usuario, la aplicación que hace uso del marcador de parámetros utilizará el tipo de datos fuente del tipo diferenciado definido por el usuario. Si el tipo de datos es un tipo estructurado definido por el usuario, la aplicación que hace uso del marcador de parámetros utilizará el tipo de parámetro de entrada de la función de transformación TO de SQL para el tipo estructurado definido por el usuario. SCOPE Cuando el tipo de datos es un tipo de referencia, puede definirse un ámbito que identifique la tabla de destino o la vista de destino de la referencia. nombre-tabla-tipo El nombre de una tabla con tipo. Ya debe existir la tabla (SQLSTATE 42704). La conversión debe hacerse hacia el tipo-datos REF(S), donde S es el tipo de nombre-tabla-tipo (SQLSTATE 428DM). 220 Consulta de SQL, Volumen 1
- 247. nombre-vista-tipo El nombre de una vista con tipo. La vista debe existir o tener el mismo nombre que la vista a crear que incluye la conversión del tipo de datos como parte de la definición de la vista (SQLSTATE 42704). La conversión debe hacerse hacia el tipo-datos REF(S), donde S es el tipo de nombre-vista-tipo (SQLSTATE 428DM). Cuando se convierten datos numéricos en datos de caracteres, el tipo de datos resultante es una serie de caracteres de longitud fija. . Cuando se convierten datos de caracteres en datos numéricos, el tipo de datos resultante depende del tipo de número especificado. Por ejemplo, si se convierte hacia un entero, pasará a ser un entero grande. . Ejemplos: v A una aplicación sólo le interesa la parte entera de SALARY (definido como decimal (9,2)) de la tabla EMPLOYEE. Se podría preparar la siguiente consulta, con el número de empleado y el valor del entero de SALARY. SELECT EMPNO, CAST(SALARY AS INTEGER) FROM EMPLOYEE v Supongamos que hay un tipo diferenciado denominado T_AGE que se define como SMALLINT y se utiliza para crear la columna AGE en la tabla PERSONNEL. Supongamos también que existe también un tipo diferenciado denominado R_YEAR que está definido en INTEGER y que se utiliza para crear la columna RETIRE_YEAR en la tabla PERSONNEL. Se podría preparar la siguiente sentencia de actualización. UPDATE PERSONNEL SET RETIRE_YEAR =? WHERE AGE = CAST( ? AS T_AGE) El primer parámetro es un marcador de parámetros no tipificado que tendría un tipo de datos de R_YEAR, si bien la aplicación utilizará un entero para este marcador de parámetros. Esto no necesita la especificación explícita de CAST porque se trata de una asignación. El segundo marcador de parámetros es un marcador de parámetros con tipo que se convierte como un tipo diferenciado T_AGE. Esto cumple el requisito de que la comparación debe realizarse con tipos de datos compatibles. La aplicación utilizará el tipo de datos fuente (que es SMALLINT) para procesarlo con este marcador de parámetros. El proceso satisfactorio de esta sentencia supone que la vía de acceso de función incluye el nombre de esquema del esquema (o esquemas) donde están definidos los dos tipos diferenciados. v Una aplicación suministra un valor que es una serie de bits como, por ejemplo, una corriente de audio y no debería realizarse la conversión de página de códigos antes de que se utilice en una sentencia SQL. La aplicación podría utilizar la siguiente funciónCAST: Capítulo 2. Elementos del lenguaje 221
- 248. CAST( ? AS VARCHAR(10000) FOR BIT DATA) Operaciones de desreferencia operación-desreferencia: expresión-ref-ámbito −> nombre1 ( ) , expresión El ámbito de la expresión de referencia con ámbito es una tabla o vista llamada tabla o vista destino. La expresión de referencia con ámbito identifica una fila destino. La fila destino es la fila de la tabla o vista destino (o de una sus subtablas o subvistas) cuyo valor de la columna de identificador de objeto (OID) coincide con la expresión de referencia. Se puede utilizar la operación de desreferencia para acceder a una columna de la fila destino, o para invocar un método, utilizando la fila destino como sujeto del método. El resultado de una operación de desreferencia puede siempre ser nulo. La operación de desreferencia tiene prioridad por encima de todos los otros operadores. expresión-ref-ámbito Una expresión que es un tipo de referencia que tiene un ámbito (SQLSTATE 428DT). Si la expresión es una variable del lenguaje principal, un marcador de parámetros u otro valor de tipo de referencia sin ámbito, se necesita una especificación CAST con una cláusula SCOPE para proporcionar un ámbito a la referencia. nombre1 Especifica un identificador no calificado. Si nombre1 no va seguido por ningún paréntesis y nombre1 coincide con el nombre de un atributo del tipo destino, el valor de la operación de desreferencia es el valor de la columna mencionada de la fila destino. En este caso, el tipo de datos de la columna (que puede contener nulos) determina el tipo del resultado de la operación de desreferencia. Si no existe ninguna fila destino cuyo identificador de objeto coincida con la expresión de referencia, el resultado de la operación de desreferencia es nulo. Si la operación de desreferencia se utiliza en una lista de selección y no se incluye como parte de una expresión, nombre1 pasa a ser el nombre de la columna resultante. Si nombre1 va seguido por un paréntesis o nombre1 no coincide con el nombre de un atributo del tipo destino, la operación de desreferencia se trata como una invocación de método. El nombre del método invocado es nombre1. El sujeto del método es la fila destino, que se considera como una instancia de su tipo estructurado. Si no existe ninguna fila destino cuyo identificador de objeto coincida con la expresión de referencia, el 222 Consulta de SQL, Volumen 1
- 249. sujeto del método es un valor nulo del tipo destino. Las expresiones entre paréntesis, si las hay, proporcionan los restantes parámetros de la invocación del método. El proceso normal se utiliza para la resolución de la invocación del método. El tipo resultante del método seleccionado (que puede contener nulos) determina el tipo resultante de la operación de desreferencia. El ID de autorización de la sentencia que utiliza una operación de desreferencia debe tener el privilegio SELECT sobre la tabla de destino de la expresión-ref-ámbito (SQLSTATE 42501). Una operación de desreferencia no puede nunca modificar valores de la base de datos. Si se utiliza una operación de desreferencia para invocar un método mutador, éste modifica una copia de la fila destino y devuelve la copia, dejando inalterada la base de datos. Ejemplos: v Suponga que existe una tabla EMPLOYEE que contiene una columna denominada DEPTREF, que es un tipo de referencia con ámbito para una tabla con tipo basada en un tipo que incluye el atributo DEPTNAME. Los valores de DEPTREF de la tabla EMPLOYEE deben corresponderse con los valores de la columna de OID de la tabla de destino de la columna DEPTREF. SELECT EMPNO, DEPTREF−>DEPTNAME FROM EMPLOYEE v Utilizando las mismas tablas que en el ejemplo anterior, utilice una operación de desreferencia para invocar un método llamado BUDGET, con la fila destino como parámetro sujeto y '1997' como parámetro adicional. SELECT EMPNO, DEPTREF−>BUDGET(’1997’) AS DEPTBUDGET97 FROM EMPLOYEE Funciones OLAP función-OLAP: función-ordenación función-numeración función-agregación función-ordenación: RANK () OVER ( DENSE_RANK () cláusula-partición-ventana cláusula-orden-ventana ) Capítulo 2. Elementos del lenguaje 223
- 250. función-numeración: ROW_NUMBER () OVER ( cláusula-partición-ventana ) cláusula-orden-ventana función-agregación: función-columna OVER ( cláusula-partición-ventana cláusula-orden-ventana cláusula-grupo-agregación-ventana RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) cláusula-grupo-agregación-ventana cláusula-partición-ventana: , PARTITION BY expresión-particionamiento cláusula-orden-ventana: , opción asc ORDER BY expresión-clave-clasificación opción desc ORDER OF diseñador-tabla opción asc: NULLS LAST ASC NULLS FIRST opción desc: NULLS FIRST DESC NULLS LAST 224 Consulta de SQL, Volumen 1
- 251. cláusula-grupo-agregación-ventana: ROWS inicio-grupo RANGE entre-grupo final-grupo inicio-grupo: UNBOUNDED PRECEDING constante-sin-signo PRECEDING CURRENT ROW entre-grupo: BETWEEN límite-grupo1 AND límite-grupo2 límite-grupo1: UNBOUNDED PRECEDING constante-sin-signo PRECEDING constante-sin-signo FOLLOWING CURRENT ROW límite-grupo2: UNBOUNDED FOLLOWING constante-sin-signo PRECEDING constante-sin-signo FOLLOWING CURRENT ROW final-grupo: UNBOUNDED FOLLOWING constante-sin-signo FOLLOWING Las funciones OLAP (On-Line Analytical Processing) devuelven información sobre ordenación y numeración de filas y sobre funciones de columna existentes, así como un valor escalar en el resultado de una consulta. Se puede incluir una función OLAP en expresiones, en una lista de selección o en la cláusula ORDER BY de una sentencia SELECT (SQLSTATE 42903). Las funciones OLAP no se pueden utilizar como argumento de una función de columna (SQLSTATE 42607). La función OLAP se aplica a la tabla resultante de la subselección más interna donde reside la función OLAP. Cuando se utiliza una función OLAP, se especifica una ventana que define las filas a las que se aplica la función, y en qué orden. Cuando la función OLAP se utiliza con una función de columna, las filas pertinentes se pueden definir Capítulo 2. Elementos del lenguaje 225
- 252. con más detalle, con respecto a la fila actual, en forma de rango o indicando un número de filas que preceden y siguen a la fila actual. Por ejemplo, dentro de una división por meses, se puede calcular un valor promedio respecto a los tres meses anteriores. La función de ordenación calcula la posición ordinal de una fila dentro de la ventana. Las filas que no son distintas con respecto a la ordenación dentro de sus ventanas tienen asignada la misma posición. Los resultados de la ordenación se pueden definir con o sin huecos en los números que resultan de valores duplicados. Si se especifica RANK, la posición de una fila se define como 1 más el número de filas que preceden estrictamente a la fila. Por lo tanto, si dos o más filas no difieren con respecto a la ordenación, habrá uno o más huecos en la numeración jerárquica secuencial. Si se especifica DENSE_RANK (o DENSERANK), el rango de una fila se define como 1 más el número de filas que la preceden que son distintas respecto a la ordenación. Por tanto, no habrá huecos en la numeración jerárquica secuencial. La función ROW_NUMBER (o ROWNUMBER) calcula el número secuencial de la fila dentro de la ventana definida por la ordenación, empezando por 1 para la primera fila. Si la cláusula ORDER BY no está especificada en la ventana, los números de fila se asignan a las filas en un orden arbitrario, tal como son devueltas por la subselección (no de acuerdo con ninguna cláusula ORDER BY de la sentencia-select). El tipo de datos del resultado de RANK, DENSE_RANK o ROW_NUMBER es BIGINT. El resultado no puede ser nulo. PARTITION BY (expresión-particionamiento,...) Define la partición que se utiliza para aplicar la función. Una expresión-particionamiento es una expresión utilizada para definir el particionamiento del conjunto resultante. Cada nombre-columna referenciado en una expresión-particionamiento debe identificar, sin ambigüedades, una columna del conjunto resultante de la sentencia de subselección donde reside la función OLAP (SQLSTATE 42702 ó 42703). Una expresión-particionamiento no puede incluir una selección completa escalar (SQLSTATE 42822) ni ninguna función que no sea determinista o que tenga una acción externa (SQLSTATE 42845). ORDER BY (expresión-clave-clasificación,...) Define la ordenación de las filas dentro de una partición que determina el valor de la función OLAP o el significado de los valores de fila en la cláusula-grupo-agregación-ventana (no define la ordenación del conjunto resultante de la consulta). 226 Consulta de SQL, Volumen 1
- 253. expresión-clave-clasificación Una expresión utilizada para definir la ordenación de las filas dentro de una partición de ventana. Cada nombre de columna referenciado en una expresión-clave-clasificación debe identificar, sin ambigüedades, una columna del conjunto resultante de la subselección, incluida la función OLAP (SQLSTATE 42702 ó 42703). Una expresión-clave-clasificación no puede incluir una selección completa escalar (SQLSTATE 42822) ni una función que no sea determinista o que tenga una acción externa (SQLSTATE 42845). Esta cláusula es necesaria para las funciones RANK y DENSE_RANK (SQLSTATE 42601). ASC Utiliza los valores de la expresión-clave-clasificación en orden ascendente. DESC Utiliza los valores de la expresión-clave-clasificación en orden descendente. NULLS FIRST La ordenación de la ventana tiene en cuenta los valores nulos antes de todos los valores no nulos en el orden de clasificación. NULLS LAST La ordenación de la ventana tiene en cuenta los valores nulos después de todos los valores no nulos en el orden de clasificación. ORDER OF diseñador-tabla Especifica que debe aplicarse el mismo orden utilizado en diseñador-tabla a la tabla resultante de la subselección. Debe haber una referencia de tabla que se corresponda con diseñador-tabla en la cláusula FROM de la subselección que especifica esta cláusula (SQLSTATE 42703). La subselección (o selección completa) correspondiente al diseñador-tabla especificado debe incluir una cláusula ORDER BY que dependa de los datos (SQLSTATE 428FI). El orden que se aplica es el mismo que si las columnas de la cláusula ORDER BY de la subselección anidada (o selección completa) se incluyeran en la subselección exterior (o selección completa) y estas columnas se especificaran en lugar de la cláusula ORDER OF. cláusula-grupo-agregación-ventana El grupo de agregación de una fila R es un conjunto de filas definidas en relación a R (en la ordenación de las filas de la partición de R). Esta cláusula especifica el grupo de agregación. Si no se especifica esta cláusula, el valor por omisión es el mismo que RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, lo que proporciona un resultado de agregación acumulativo. Capítulo 2. Elementos del lenguaje 227
- 254. ROWS Indica que el grupo de agregación se define mediante el contaje de filas. RANGE Indica que el grupo de agregación se define mediante un valor de desplazamiento con respecto a una clave de clasificación. inicio-grupo Especifica el punto de inicio del grupo de agregación. El final del grupo de agrupación es la fila actual. La cláusula inicio-grupo es equivalente a una cláusula entre-grupo en la forma ″BETWEEN inicio-grupo AND CURRENT ROW″. entre-grupo Especifica el inicio y final del grupo de agregación basándose en ROWS o RANGE. final-grupo Especifica el punto final del grupo de agregación. El inicio del grupo de agregación es la fila actual. La especificación de la cláusula final-grupo es equivalente a la de una cláusula entre-grupo del formato ″BETWEEN CURRENT ROW AND final-grupo″. UNBOUNDED PRECEDING Incluye la partición completa que precede a la fila actual. Esto se puede especificar con ROWS o RANGE. También se puede especificar con varias expresiones-clave-clasificación en la cláusula-orden-ventana. UNBOUNDED FOLLOWING Incluye la partición completa que sigue a la fila actual. Esto se puede especificar con ROWS o RANGE. También se puede especificar con varias expresiones-clave-clasificación en la cláusula-orden-ventana. CURRENT ROW Especifica el inicio o el final del grupo de agregación basándose en la fila actual. Si se especifica ROWS, la fila actual es el límite del grupo de agregación. Si se especifica RANGE, el límite del grupo de agregación incluye el conjunto de filas con los mismos valores para las expresiones-clave-clasificación que la fila actual. Esta cláusula no se puede especificar en límite-grupo2 si límite-grupo1 especifica el valor FOLLOWING. valor PRECEDING Especifica el rango o número de filas que preceden a la fila actual. Si se especifica ROWS, valor es un entero positivo que indica un número de filas. Si se especifica RANGE, el tipo de datos de valor debe ser comparable con el tipo de la expresión-clave-clasificación de la cláusula-orden-ventana. Sólo puede haber una sola expresión-clave-clasificación y el tipo de datos de esa expresión debe 228 Consulta de SQL, Volumen 1
- 255. permitir la operación de resta. Esta cláusula no se puede especificar en límite-grupo2 si límite-grupo1 es CURRENT ROW o valor FOLLOWING. valor FOLLOWING Especifica el rango o número de filas que siguen a la fila actual. Si se especifica ROWS, valor es un entero positivo que indica un número de filas. Si se especifica RANGE, el tipo de datos de valor debe ser comparable con el tipo de la expresión-clave-clasificación de la cláusula-orden-ventana. Sólo puede haber una sola expresión-clave-clasificación y el tipo de datos de esa expresión debe permitir la operación de suma. Ejemplos: v Este ejemplo muestra la ordenación de los empleados, dispuestos por apellidos, de acuerdo con un salario total (salario más prima) que sea mayor que $30.000. SELECT EMPNO, LASTNAME, FIRSTNME, SALARY+BONUS AS TOTAL_SALARY, RANK() OVER (ORDER BY SALARY+BONUS DESC) AS RANK_SALARY FROM EMPLOYEE WHERE SALARY+BONUS > 30000 ORDER BY LASTNAME Observe que si el resultado debe estar ordenado de acuerdo con la escala de salarios, debe sustituir ORDER BY LASTNAME por: ORDER BY RANK_SALARY o ORDER BY RANK() OVER (ORDER BY SALARY+BONUS DESC) v Este ejemplo ordena los departamentos de acuerdo con su salario total medio. SELECT WORKDEPT, AVG(SALARY+BONUS) AS AVG_TOTAL_SALARY, RANK() OVER (ORDER BY AVG(SALARY+BONUS) DESC) AS RANK_AVG_SAL FROM EMPLOYEE GROUP BY WORKDEPT ORDER BY RANK_AVG_SAL v Este ejemplo ordena los empleados de un departamento de acuerdo con su nivel de formación. Si varios empleados de un departamento tienen el mismo nivel, ello no debe suponer un aumento del nivel siguiente. SELECT WORKDEPT, EMPNO, LASTNAME, FIRSTNME, EDLEVEL, DENSE_RANK() OVER (PARTITION BY WORKDEPT ORDER BY EDLEVEL DESC) AS RANK_EDLEVEL FROM EMPLOYEE ORDER BY WORKDEPT, LASTNAME v Este ejemplo proporciona números a las filas del resultado de una consulta. Capítulo 2. Elementos del lenguaje 229
- 256. SELECT ROW_NUMBER() OVER (ORDER BY WORKDEPT, LASTNAME) AS NUMBER, LASTNAME, SALARY FROM EMPLOYEE ORDER BY WORKDEPT, LASTNAME v Este ejemplo lista los cinco empleados con mayores ingresos. SELECT EMPNO, LASTNAME, FIRSTNME, TOTAL_SALARY, RANK_SALARY FROM (SELECT EMPNO, LASTNAME, FIRSTNME, SALARY+BONUS AS TOTAL_SALARY, RANK() OVER (ORDER BY SALARY+BONUS DESC) AS RANK_SALARY FROM EMPLOYEE) AS RANKED_EMPLOYEE WHERE RANK_SALARY < 6 ORDER BY RANK_SALARY Observe que primero se ha utilizado una expresión de tabla anidada para calcular el resultado, incluidos los niveles de ordenación, para poder utilizar el nivel en la cláusula WHERE. También se podría haber utilizado una expresión de tabla común. Funciones XML Función-XML: XML2CLOB ( Función-xmlagg ) Función-xmlelement Función-xmlagg: XMLAGG ( Función-xmlelement ) , ASC ORDER BY clave-clasificación DESC clave-clasificación: nombre-columna expresión-clave-clasificación Función-xmlelement: XMLELEMENT ( NAME nombre-elemento 230 Consulta de SQL, Volumen 1
- 257. ) Función-xmlattributes , contenido-elemento , Función-xmlattributes , contenido-elemento Función-xmlattributes: , XMLATTRIBUTES ( valor-atributo ) AS nombre-atributo XML2CLOB Devuelve el argumento como un valor CLOB. El esquema es SYSIBM. El argumento debe ser una expresión del tipo de datos XML. El resultado tiene el tipo de datos CLOB. XMLAGG Devuelve la concatenación de un conjunto de datos XML. El esquema es SYSIBM. El tipo de datos del resultado es XML y su longitud está establecida en 1 073 741 823. Si la función XMLAGG se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es la concatenación de los valores del conjunto. ORDER BY Especifica el orden de las filas del mismo conjunto de agrupación que se procesan en la agregación. Si se omite la cláusula ORDER BY o si ésta no puede distinguir el orden de los datos de la columna, las filas del mismo conjunto de agrupación se ordenan de forma arbitraria. clave-clasificación La clave de clasificación puede ser un nombre de columna o una expresión-clave-clasificación. Observe que si la clave de clasificación es una constante, no hace referencia a la posición de la columna de salida(como en la cláusula ORDER BY normal) sino que es simplemente una constante, que no implica ninguna clave de clasificación. Las restricciones respecto a la utilización de la función XMLAGG son las siguientes: v Las funciones de columna no pueden utilizarse como entrada directa (SQLSTATE 42607). v XMLAGG no puede utilizarse como función de columna de una función agregada OLAP (SQLSTATE 42601). Capítulo 2. Elementos del lenguaje 231
- 258. XMLELEMENT Construye un elemento XML a partir de los argumentos. El esquema es SYSIBM. Esta función toma un nombre de elemento, una colección de atributos opcional y cero o más argumentos que formarán el contenido del elemento. El tipo de datos del resultado es XML. NAME Esta palabra clave precede el nombre de un elemento XML. nombre-elemento El nombre del elemento XML. Función-xmlattributes Atributos XML que son el resultado de la función XMLATTRIBUTES. Si se especifica, debe aparecer en el segundo argumento de XMLELEMENT como la función XMLATTRIBUTES con el formato apropiado. contenido-elemento El contenido de los elementos generados se especifica mediante una expresión o una lista de expresiones. El tipo de datos del resultado de la expresión debe ser SMALLINT, INTEGER, BIGINT, DECIMAL, NUMERIC, REAL, DOUBLE, CHAR, VARCHAR, LONG VARCHAR, CLOB, GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC, DBCLOB, DATE, TIME, TIMESTAMP, XML cualquier tipo diferenciado cuyo tipo fuente sea uno de los tipos de datos anteriores. No se permiten datos de serie de caracteres que estén definidos como FOR BIT DATA. Las expresiones pueden ser cualquier expresión de SQL, pero no pueden incluir una selección completa escalar ni una subconsulta. XMLATTRIBUTES Construye los atributos XML a partir de los argumentos. El esquema es SYSIBM. El resultado tiene el mismo tipo de datos XML interno que los argumentos. valor-atributo El valor de atributo es una expresión. El tipo de datos del resultado de la expresión debe ser SMALLINT, INTEGER, BIGINT, DECIMAL, NUMERIC, REAL, DOUBLE, CHAR, VARCHAR, LONG VARCHAR, CLOB, GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC, DBCLOB, DATE, TIME, TIMESTAMP cualquier tipo diferenciado cuyo tipo fuente sea uno de los tipos de datos anteriores. No se permiten datos de serie de caracteres que estén definidos como FOR BIT DATA. La expresión puede ser cualquier expresión de SQL pero no puede incluir una selección completa escalar ni una subconsulta. Si la expresión no es una referencia de columna simple, debe especificarse un nombre de atributo. No se permiten los nombres de atributos duplicados (SQLSTATE 42713). 232 Consulta de SQL, Volumen 1
- 259. nombre-atributo El nombre de atributo es un identificador SQL. Ejemplos: v Construya un valor CLOB a partir de la expresión devuelta por la función XMLELEMENT. La consulta SELECT e.empno, XML2CLOB(XMLELEMENT(NAME "Emp", e.firstnme || ’ ’ || e.lastname)) AS "Result" FROM employee e WHERE e.edlevel = 12 genera el resultado siguiente: EMPNO Result 000290 <Emp>JOHN PARKER</Emp> 000310 <Emp>MAUDE SETRIGHT</Emp> v Genere un elemento departamental (para cada departamento) con una lista de empleados, clasificados por el apellido del empleado: SELECT XML2CLOB(XMLELEMENT(NAME "Department", XMLATTRIBUTES(e.workdept AS "name"), XMLAGG(XMLELEMENT(NAME "emp", e.lastname) ORDER BY e.lastname ) )) AS "dept_list" FROM employee e WHERE e.workdept IN (’C01’,’E21’) GROUP BY workdept Esta consulta genera la salida siguiente. Observe que en realidad no se genera ningún espacio ni carácter de salto de línea en el resultado; la salida siguiente se ha formateado para proporcionar mayor claridad. dept_list <Department name = "C01"> <emp>KWAN</emp> <emp>NICHOLLS</emp> <emp>QUINTANA</emp> </Department> <Department name = "E21"> <emp>GOUNOT</emp> <emp>LEE</emp> <emp>MEHTA</emp> <emp>SPENSER</emp> </Department> v Para cada departamento que informe al departamento A00, cree un elemento XML vacío denominado Mgr con un atributo de ID igual al MGRNO. La consulta SELECT d.deptno, XML2CLOB(XMLELEMENT(NAME "Mgr", XMLATTRIBUTES(d.mgrno))) AS "Result" FROM department d WHERE d.admrdept = ’A00’ Capítulo 2. Elementos del lenguaje 233
- 260. genera el resultado siguiente: DEPTNO Result A00 <Mgr ID="000010"/> B01 <Mgr ID="000020"/> C01 <Mgr ID="000030"/> D01 <Mgr/> v Genere un elemento de XML denominado Emp para cada empleado, con elementos anidados para el nombre completo del empleado y la fecha en que fue contratado. La consulta SELECT e.empno, XML2CLOB (XMLELEMENT(NAME "Emp", XMLELEMENT(NAME "name", e.firstnme || ’ ’ || e.lastname), XMLELEMENT(NAME "hiredate", e.hiredate))) AS "Result" FROM employee e WHERE e.edlevel = 12 genera el resultado siguiente (formateado aquí para su conveniencia; el XML de salida no tiene caracteres de espacios en blanco ajenos): EMPNO Result 000290 <Emp> <name>JOHN PARKER</name> <hiredate>1980-05-30</hiredate> </Emp> 000310 <Emp> <name>MAUDE SETRIGHT</name> <hiredate>1964-09-12</hiredate> </Emp> v Utilizando la función XMLATTRIBUTES, junto con las funciones XML2CLOB y XMLELEMENT, construya los atributos XML. La consulta SELECT XML2CLOB(XMLELEMENT(NAME "Emp:Exempt", XMLATTRIBUTES(e.firstnme, e.lastname AS "name:last", e."midinit"))) AS "result" FROM employee e WHERE e.lastname=’GEYER’ genera el resultado siguiente: <Emp:Exempt FIRSTNME="JOHN" name:last="GEYER" MIDINIT="B" /> 234 Consulta de SQL, Volumen 1
- 261. Invocación de métodos invocación-método: expresión-sujeto..nombre-método ( ) , expresión El método observador y el método mutador, ambos generados por el sistema, así como los métodos definidos por el usuario se invocan utilizando el operador formado por dos puntos. expresión-sujeto Es una expresión con un tipo resultante estático que es un tipo estructurado definido por el usuario. nombre-método Es el nombre no calificado de un método. El tipo estático de expresión-sujeto o uno de sus supertipos debe incluir un método que tenga el nombre especificado. (expresión,...) Los argumentos de nombre-método se especifican entre paréntesis. Se pueden utilizar paréntesis vacíos para indicar que no existen argumentos. El nombre-método y los tipos de datos de las expresiones argumento especificadas se utilizan para obtener el método específico, basándose en el tipo estático de expresión-sujeto. El operador .. utilizado para invocar el método es un operador infijo que define una prioridad de operaciones de izquierda a derecha. Por ejemplo, las dos expresiones siguientes son equivalentes: a..b..c + x..y..z y ((a..b)..c) + ((x..y)..z) Si un método no tiene ningún otro parámetro que no sea su sujeto, éste se puede invocar con o sin paréntesis. Por ejemplo, las dos expresiones siguientes son equivalentes: point1..xpoint1..x() Los sujetos nulos de una invocación de método se gestionan de este modo: v Si un método mutador generado por el sistema se invoca con un sujeto nulo, se produce un error (SQLSTATE 2202D) Capítulo 2. Elementos del lenguaje 235
- 262. v Si cualquier método distinto de un método mutador generado por el sistema se invoca con un sujeto nulo, el método no se ejecuta y su resultado es nulo. Esta regla incluye los métodos definidos por el usuario con SELF AS RESULT. Cuando se crea un objeto de base de datos (por ejemplo, un paquete, vista o activador), se determina el método de ajuste óptimo que existe para cada invocación de método. Nota: Los métodos de los tipos definidos con WITH FUNCTION ACCESS también se pueden invocar utilizando la notación normal de funciones. La resolución de la función considera como aceptables todas las funciones, así como los métodos con acceso a función. Sin embargo, las funciones no se pueden invocar utilizando la invocación de método. La resolución del método considera aceptables todos los métodos, pero no las funciones. Si la resolución no proporciona una función o método apropiado, se produce un error (SQLSTATE 42884). Ejemplo: v Este ejemplo utiliza el operador .. para invocar un método llamado AREA. Se supone que existe una tabla llamada RINGS, con una columna CIRCLE_COL del tipo estructurado CIRCLE. Se supone también que el método AREA se ha definido previamente para el tipo CIRCLE como AREA() RETURNS DOUBLE. SELECT CIRCLE_COL..AREA() FROM RINGS Tratamiento de los subtipos tratamiento-subtipo: TREAT ( expresión AS tipo-datos ) El tratamiento-subtipo se utiliza para convertir una expresión de tipo estructurado en uno de sus subtipos. El tipo estático de expresión debe ser un tipo estructurado definido por el usuario, y ese tipo debe ser el mismo que tipo-datos o que un subtipo de él. Si el nombre de tipo especificado en tipo-datos no está calificado, se utiliza la vía de acceso de SQL para resolver la referencia al tipo. El tipo estático del resultado de tratamiento-subtipo es tipo-datos, y el valor del tratamiento-subtipo es el valor de la expresión. Durante la ejecución, si el tipo dinámico de la expresión no es tipo-datos o un subtipo de tipo-datos, se produce un error (SQLSTATE 0D000). Ejemplo: v En este ejemplo, todas las instancias de objetos de la columna CIRCLE_COL están definidas con el tipo dinámico COLOREDCIRCLE para una aplicación. Se utiliza la consulta siguiente para invocar el método RGB para 236 Consulta de SQL, Volumen 1
- 263. tales objetos. Se supone que existe una tabla llamada RINGS, con una columna CIRCLE_COL del tipo estructurado CIRCLE. Se supone también que COLOREDCIRCLE es un subtipo de CIRCLE y que el método RGB se ha definido previamente para COLOREDCIRCLE como RGB() RETURNS DOUBLE. SELECT TREAT (CIRCLE_COL AS COLOREDCIRCLE)..RGB() FROM RINGS Durante la ejecución, si hay instancias del tipo dinámico CIRCLE, se produce un error (SQLSTATE 0D000). Este error se puede evitar utilizando el predicado TYPE en una expresión CASE, del modo siguiente: SELECT (CASE WHEN CIRCLE_COL IS OF (COLOREDCIRCLE) THEN TREAT (CIRCLE_COL AS COLOREDCIRCLE)..RGB() ELSE NULL END) FROM RINGS Referencia de secuencia referencia-secuencia: expresión-nextval expresión-prevval expresión-nextval: NEXTVAL FOR nombre-secuencia expresión-prevval: PREVVAL FOR nombre-secuencia NEXTVAL FOR nombre-secuencia Una expresión NEXTVAL genera y devuelve el siguiente valor de la secuencia especificada por nombre-secuencia. PREVVAL FOR nombre-secuencia Una expresión PREVVAL devuelve el valor generado más recientemente de la secuencia especificada para una sentencia anterior del proceso de aplicación actual. Se puede hacer referencia a este valor repetidamente utilizando expresiones PREVVAL que especifican el nombre de la secuencia. Pueden existir múltiples instancias de las expresiones PREVVAL especificando el mismo nombre de secuencia en una sola sentencia; todas ellas devuelven el mismo valor. Una expresión PREVVAL sólo se puede utilizar si ya se ha hecho referencia a una expresión NEXTVAL que especifica el mismo nombre de Capítulo 2. Elementos del lenguaje 237
- 264. secuencia en el proceso de aplicación actual, ya sea en la transacción actual ya sea en una transacción anterior (SQLSTATE 51035). Notas: v Se genera un valor nuevo para una secuencia cuando la expresión NEXTVAL especifica el nombre de dicha secuencia. Sin embargo, si existen múltiples instancias de una expresión NEXTVAL que especifican el mismo nombre de secuencia en una consulta, el contador para la secuencia se incrementa sólo una vez para cada fila del resultado y todas las instancias de NEXTVAL devuelven el mismo valor para una fila del resultado. v Se puede utilizar el mismo número de secuencia como valor de clave de unicidad en dos tablas independientes haciendo referencia al número de secuencia con una expresión NEXTVAL para la primera fila (esto genera el valor de secuencia) y una expresión PREVVAL para las demás filas (la instancia de PREVVAL hace referencia al valor de secuencia generado más recientemente en la sesión actual), tal como se muestra a continuación: INSERT INTO order(orderno, cutno) VALUES (NEXTVAL FOR order_seq, 123456); INSERT INTO line_item (orderno, partno, quantity) VALUES (PREVVAL FOR order_seq, 987654, 1); v Las expresiones NEXTVAL y PREVVAL pueden especificarse en los lugares siguientes: – sentencia-select o sentencia SELECT INTO (en la cláusula-select, a condición de que la sentencia no contenga una palabra clave DISTINCT, una cláusula GROUP BY, una cláusula ORDER BY, una palabra clave UNION, una palabra clave INTERSECT o una palabra clave EXCEPT) – sentencia INSERT (en una cláusula VALUES) – sentencia INSERT (en la cláusula-select de la selección completa (fullselect)) – sentencia UPDATE (en la cláusula SET (una sentencia UPDATE buscada o colocada), excepto que no se puede especificar NEXTVAL en la cláusula-select de la selección completa de una expresión de la cláusula SET) – setencia SET variable (excepto en la cláusula-select de la selección completa de una expresión; una expresión NEXTVAL puede especificarse en un activador, pero una expresión PREVVAL no puede especificarse) – sentencia VALUES INTO (en la cláusula-select de la selección completa (fullselect) de una expresión) – sentencia CREATE PROCEDURE (en el cuerpo-rutina de un procedimiento SQL) – sentencia CREATE TRIGGER en la acción-activada (se puede especificar una expresión NEXTVAL, pero no se puede especificar una expresión PREVVAL) 238 Consulta de SQL, Volumen 1
- 265. v No se pueden especificar expresiones NEXTVAL y PREVVAL (SQLSTATE 428F9) en los lugares siguientes: – las condiciones de unión de una unión externa completa – el valor DEFAULT de una columna en una sentencia CREATE o ALTER TABLE – la definición de columna generada en una sentencia CREATE o ALTER TABLE – la definición de tabla de resumen de una sentencia CREATE TABLE o ALTER TABLE – la condición de una restricción CHECK – la sentencia CREATE TRIGGER (se puede especificar una expresión NEXTVAL, pero no se puede especificar una expresión PREVVAL) – Sentencia CREATE VIEW – Sentencia CREATE METHOD – Sentencia CREATE FUNCTION v Además, no se puede especificar una expresión NEXTVAL (SQLSTATE 428F9) en los lugares siguientes: – la expresión CASE – la lista de parámetros de una función agregada – la subconsulta en un contexto distinto de los explícitamente permitidos mencionados anteriormente – la sentencia SELECT para la que la SELECT externa contiene un operador DISTINCT – la condición de unión de una unión – la sentencia SELECT para la que la SELECT externa contiene una cláusula GROUP BY – la sentencia SELECT para la que la SELECT externa está combinada con otra sentencia SELECT utilizando el operador establecido UNION, INTERSECT o EXCEPT – la expresión de tabla anidada – la lista de parámetros de una función de tabla – la cláusula WHERE de la sentencia SELECT más externa o una sentencia DELETE o UPDATE – la cláusula ORDER BY de la sentencia SELECT más externa – la cláusula-select de la selección completa (fullselect) de una expresión, en la cláusula SET de una sentencia UPDATE – la sentencia IF, WHILE, DO ... UNTIL o CASE de una rutina SQL Capítulo 2. Elementos del lenguaje 239
- 266. v Cuando se genera un valor para una secuencia, se consume dicho valor y, la siguiente vez que se solicita un valor, se genera un valor nuevo. Esto es válido incluso cuando la sentencia que contiene la expresión NEXTVAL falla o se retrotrae. Si una sentencia INSERT incluye una expresión NEXTVAL en la lista VALUES para la columna y si se produce un error en algún punto durante la ejecución de INSERT (puede ser un problema al generar el siguiente valor de secuencia o un problema con el valor de otra columna), se produce una anomalía de inserción (SQLSTATE 23505) y se considera que el valor generado para la secuencia se ha consumido. En algunos casos, al volver a emitir la misma sentencia INSERT se puede obtener un resultado satisfactorio. Por ejemplo, considere un error que es el resultado de la existencia de un índice de unicidad para la columna para la que se ha utilizado NEXTVAL y el valor de secuencia generado ya existe en el índice. Es posible que el siguiente valor generado para la secuencia sea un valor que no existe en el índice y, por consiguiente, el INSERT subsiguiente dará un resultado satisfactorio. v Si al generar un valor para un secuencia, se excede el valor máximo para la secuencia (o el valor mínimo para una secuencia descendente) y no se permiten ciclos, se producirá un error (SQLSTATE 23522). En este caso, el usuario puede modificar (ALTER) la secuencia para ampliar el rango de valores aceptables, habilitar ciclos para la secuencia o eliminar (DROP) la secuencia y crear (CREATE) una nueva con un tipo de datos diferente que tenga un mayor rango de valores. Por ejemplo, una secuencia puede haberse definido con un tipo de datos de SMALLINT y, finalmente, la secuencia se queda sin valores asignables. Elimine (DROP) y vuelva a crear la secuencia con la nueva definición para volver a definir la secuencia como INTEGER. v Una referencia a una expresión NEXTVAL en la sentencia de selección (select) de un cursor hace referencia a un valor que se genera para una fila de la tabla resultante. Se genera un valor de secuencia para una expresión NEXTVAL para cada fila que se busca desde la base de datos. Si se realiza el bloqueo en el cliente, puede que los valores se hayan generado en el servidor antes del proceso de la sentencia FETCH. Esto puede producirse cuando existe bloqueo de las filas de la tabla resultante. Si la aplicación cliente no capta (FETCH) explícitamente todas las filas que la base de datos ha materializado, la aplicación no verá los resultados de todos los valores de secuencia generados (para las filas materializadas que no se ha devuelto). v Una referencia a una expresión PREVVAL de la sentencia de selección (select) de un cursor hace referencia a un valor que se ha generado para la secuencia especificada antes de la apertura del cursor. Sin embargo, el cierre del cursor puede afectar a los valores devueltos por PREVVAL para la 240 Consulta de SQL, Volumen 1
- 267. secuencia especificada en las sentencias futuras o incluso para la misma sentencia en el caso de que se vuelva a abrir el cursor. Esto sucederá cuando la sentencia de selección del cursor incluya una referencia a NEXTVAL para el mismo nombre de secuencia. Ejemplos: Supongamos que existe una tabla llamada ″order″ y que se crea una secuencia llamada ″order_seq″ del modo siguiente: CREATE SEQUENCE order_seq START WITH 1 INCREMENT BY 1 NO MAXVALUE NO CYCLE CACHE 24 A continuación se muestran algunos ejemplos de cómo generar un número de secuencia ″order_seq″ con una expresión NEXTVAL: INSERT INTO order(orderno, custno) VALUES (NEXTVAL FOR order_seq, 123456); o UPDATE order SET orderno = NEXTVAL FOR order_seq WHERE custno = 123456; o VALUES NEXTVAL FOR order_seq INTO :hv_seq; Información relacionada: v “Identificadores” en la página 71 v “Predicado TYPE” en la página 262 v “CHAR” en la página 323 v “INTEGER” en la página 407 v “Selección completa” en la página 623 v “CREATE TABLE sentencia” en la publicación Consulta de SQL, Volumen 2 v “Métodos” en la página 192 v “CREATE FUNCTION (escalar de SQL, tabla o fila) sentencia” en la publicación Consulta de SQL, Volumen 2 v “Conversiones entre tipos de datos” en la página 122 v “Asignaciones y comparaciones” en la página 126 v “Reglas para los tipos de datos del resultado” en la página 145 v “Reglas para la conversión de series” en la página 150 Capítulo 2. Elementos del lenguaje 241
- 268. Predicados Predicados Un predicado especifica una condición que es cierta, falsa o desconocida acerca de una fila o un grupo determinado. Las siguientes reglas se aplican a todos los tipos de predicados: v Todos los valores especificados en un predicado debe ser compatibles. v Una expresión que se utiliza en un predicado básico, cuantificado, IN o BETWEEN no debe dar como resultado una serie de caracteres con un atributo de longitud superior a 4 000, una serie de caracteres gráficos con un atributo de longitud superior a 2 000 ni una serie LOB de cualquier tamaño. v El valor de una variable de lenguaje principal puede ser nulo (es decir, la variable puede tener una variable indicadora negativa). v La conversión de la página de códigos de los operandos de los predicados que implican dos o más operandos, a excepción de LIKE, se realiza según las reglas de conversión de series. v La utilización de un valor DATALINK se limita al predicado NULL. v La utilización de un valor de tipo estructurado está limitado al predicado NULL y al predicado TYPE. v En una base de datos Unicode, todos los predicados que acepten una serie de caracteres o gráfica aceptarán todo tipo de serie para el que se soporte la conversión. Una selección completa es una forma de sentencia SELECT que, cuando se utiliza en un predicado, también se denomina una subconsulta. Información relacionada: v “Selección completa” en la página 623 v “Reglas para la conversión de series” en la página 150 242 Consulta de SQL, Volumen 1
- 269. Condiciones de búsqueda condición-búsqueda: predicado NOT SELECTIVITY constante-numérica (condición-búsqueda) AND predicado OR NOT SELECTIVITY constante-numérica (condición-búsqueda) Una condición de búsqueda especifica una condición que es “verdadera,” “falsa,” o “desconocida” acerca de una fila determinada. El resultado de una condición de búsqueda se deriva por la aplicación de operadores lógicos (AND, OR, NOT) especificados al resultado de cada predicado especificado. Si no se especifican operadores lógicos, el resultado de la condición de búsqueda es el resultado del predicado especificado. AND y OR se definen en la Tabla 14, en la que P y Q son unos predicados cualesquiera: Tabla 14. Tablas de evaluación para AND y OR P Q P AND Q P OR Q Verdadero Verdadero Verdadero Verdadero Verdadero Falso Falso Verdadero Verdadero Desconocido Desconocido Verdadero Falso Verdadero Falso Verdadero Falso Falso Falso Falso Falso Desconocido Falso Desconocido Desconocido Verdadero Desconocido Verdadero Desconocido Falso Falso Desconocido Desconocido Desconocido Desconocido Desconocido NOT(verdadero) es falso, NOT(falso) es verdadero y NOT(desconocido) es desconocido. En primer lugar se evalúan las condiciones de búsqueda entre paréntesis. Si el orden de evaluación no se especifica mediante paréntesis, NOT se aplica antes Capítulo 2. Elementos del lenguaje 243
- 270. que AND y AND es aplica antes que OR. El orden en el que se evalúan los operadores del mismo nivel de prioridad no está definido, para permitir la optimización de condiciones de búsqueda. MAJPROJ = 'MA2100' AND DEPTNO = 'D11' OR DEPTNO = 'B03' OR DEPTNO = 'E11' 1 2 or 3 2 or 3 MAJPROJ = 'MA2100' AND (DEPTNO = 'D11' OR DEPTNO = 'B03') OR DEPTNO = 'E11' 2 1 3 Figura 12. Orden de evaluación de las condiciones de búsqueda SELECTIVITY valor La cláusula SELECTIVITY se utiliza para indicar a DB2 qué porcentaje de selectividad prevista corresponde al predicado. SELECTIVITY se puede especificar sólo cuando el predicado es un predicado definido por el usuario. Un predicado definido por el usuario consta de una invocación de función definida por el usuario, en el contexto de una especificación de predicado que coincide con la existente en la cláusula PREDICATES de CREATE FUNCTION. Por ejemplo, si la función foo está definida con PREDICATES WHEN=1..., es válido utilizar SELECTIVITY de este modo: SELECT * FROM STORES WHERE foo(parm,parm) = 1 SELECTIVITY 0.004 El valor de selectividad debe ser un valor literal numérico comprendido dentro del rango inclusivo 0-1 (SQLSTATE 42615). Si SELECTIVITY no se especifica, el valor por omisión es 0.01 (es decir, el predicado definido por el usuario debe descartar todas las filas de la tabla excepto un 1 por ciento. El valor por omisión de SELECTIVITY se puede modificar para una función determinada actualizando su columna SELECTIVITY en la vista SYSSTAT.FUNCTIONS. Se obtiene un error si la cláusula SELECTIVITY se especifica para un predicado no definido por el usuario (SQLSTATE 428E5). Se puede utilizar una función definida por el usuario (UDF) como predicado definido por el usuario y, por tanto, puede permitir la utilización de índices si: 244 Consulta de SQL, Volumen 1
- 271. v La especificación de predicado está presente en la sentencia CREATE FUNCTION v la UDF se invoca en una cláusula WHERE que se compara (sintácticamente) de la misma manera que se especifica en la especificación de predicado v no existe ninguna negación (operador NOT) Ejemplos: En la consulta siguiente, la especificación UDF interna de la cláusula WHERE cumple las tres condiciones y se considera que es un predicado definido por el usuario. SELECT * FROM customers WHERE within(location, :sanJose) = 1 SELECTIVITY 0.2 Sin embargo, la presencia de within en la consulta siguiente no permite el uso de índices debido a la negación, y no se considera un predicado definido por el usuario. SELECT * FROM customers WHERE NOT(within(location, :sanJose) = 1) SELECTIVITY 0.3 En el ejemplo siguiente, se identifican los clientes y tiendas que están a una determinada distancia entre sí. La distancia de una tienda a otra se calcula mediante el radio de la ciudad donde viven los clientes. SELECT * FROM customers, stores WHERE distance(customers.loc, stores.loc) < CityRadius(stores.loc) SELECTIVITY 0.02 En la consulta anterior, se considera que el predicado contenido en la cláusula WHERE es un predicado definido por el usuario. El resultado producido por CityRadius se utiliza como argumento de búsqueda para la función productora de rangos. Sin embargo, como el resultado devuelto por CityRadius se utiliza como función productora de rangos, el predicado definido por el usuario no podrá utilizar la extensión de índice definida para la columna stores.loc. Por lo tanto, la UDF sólo utilizará el índice definido en la columna customers.loc. Información relacionada: v “CREATE FUNCTION (Escalar externa) sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 2. Elementos del lenguaje 245
- 272. Predicado básico expresión = expresión (1) <> < > (1) <= (1) >= Notas: 1 También se da soporte a los formatos siguientes de operadores de comparación en predicados básicos y cuantificados: ^=, ^<, ^>, !=, !< y !>. En las páginas de códigos 437, 819 y 850, se da soporte a los formatos ¬=, ¬< y ¬>. Todos estos formatos específicos para el producto de los operadores de comparación solamente están pensados para dar soporte al SQL existente que emplea estos operadores y no se recomienda su utilización para escribir sentencias de SQL nuevas. Un predicado básico compara dos valores. Si el valor de cualquier operando es nulo, el resultado del predicado será desconocido. De lo contrario el resultado es verdadero o falso. Para valores x e y: Predicado Es verdadero si y sólo si... x=y x es igual a y x <> y x es diferente de y x<y x es menor que y x>y x es mayor que y x >= y x es mayor o igual que y x <= y x es menor o igual que y Ejemplos: EMPNO=’528671’ SALARY < 20000 PRSTAFF <> :VAR1 SALARY > (SELECT AVG(SALARY) FROM EMPLOYEE) 246 Consulta de SQL, Volumen 1
- 273. Predicado cuantificado expresión1 = SOME (selección completa1) (1) ANY <> ALL < > <= >= , ( expresión2 ) = SOME (selección completa2) ANY Notas: 1 También se da soporte a los formatos siguientes de operadores de comparación en predicados básicos y cuantificados: ^=, ^<, ^>, !=, !< y !>. En las páginas de códigos 437, 819 y 850, se da soporte a los formatos ¬=, ¬< y ¬>. Todos estos formatos específicos para el producto de los operadores de comparación solamente están pensados para dar soporte al SQL existente que emplea estos operadores y no se recomienda su utilización para escribir sentencias de SQL nuevas. Un predicado cuantificado compara un valor o valores con un grupo de valores. La selección completa debe identificar un número de columnas que sea el mismo que el número de expresiones especificadas a la izquierda del operador del predicado (SQLSTATE 428C4). La selección completa puede devolver cualquier número de filas. Cuando se especifica ALL: v El resultado del predicado es verdadero si la selección completa no devuelve ningún valor o si la relación especificada es verdadera para cada valor que devuelva la selección completa. v El resultado es falso si la relación especificada es falsa para un valor como mínimo que devuelve la selección completa. v El resultado es desconocido si la relación especificada no es falsa para ninguno de los valores que devuelve la selección completa y una comparación como mínimo es desconocida debido a un valor nulo. Cuando se especifica SOME o ANY: v El resultado del predicado es verdadero si la relación especificada es verdadera para cada valor de una fila como mínimo que devuelve la selección completa. Capítulo 2. Elementos del lenguaje 247
- 274. v El resultado es falso si la selección completa no devuelve ninguna fila o si la relación especificada es falsa para como mínimo un valor de cada fila que devuelve la selección completa. v El resultado es desconocido si la relación especificada no es verdadera para cualquiera de las filas y, como mínimo, una comparación es desconocida debido a un valor nulo. Ejemplos: Utilice las tablas siguientes al hacer referencia a los ejemplos siguientes. TBLAB: TBLXY: COLA COLB COLX COLY 1 12 2 22 2 12 3 23 3 13 4 14 - - Figura 13. Ejemplo 1 SELECT COLA FROM TBLAB WHERE COLA = ANY(SELECT COLX FROM TBLXY) Da como resultado 2,3. La subselección devuelve (2,3). COLA en las filas 2 y 3 es igual al menos a uno de estos valores. Ejemplo 2 SELECT COLA FROM TBLAB WHERE COLA > ANY(SELECT COLX FROM TBLXY) Da como resultado 3,4. La subselección devuelve (2,3). COLA en las filas 3 y 4 es mayor que al menos uno de estos valores. Ejemplo 3 SELECT COLA FROM TBLAB WHERE COLA > ALL(SELECT COLX FROM TBLXY) Da como resultado 4. La subselección devuelve (2,3). COLA en la fila 4 es el único que es mayor que estos dos valores. Ejemplo 4 SELECT COLA FROM TBLAB WHERE COLA > ALL(SELECT COLX FROM TBLXY WHERE COLX<0) 248 Consulta de SQL, Volumen 1
- 275. Da como resultado 1,2,3,4, nulo. La subselección no devuelve ningún valor. Por lo tanto, el predicado es verdadero para todas las filas de TBLAB. Ejemplo 5 SELECT * FROM TBLAB WHERE (COLA,COLB+10) = SOME (SELECT COLX, COLY FROM TBLXY) La subselección devuelve todas las entradas de TBLXY. El predicado es verdadero para la subselección, por lo tanto el resultado es el siguiente: COLA COLB ----------- ----------- 2 12 3 13 Ejemplo 6 SELECT * FROM TBLAB WHERE (COLA,COLB) = ANY (SELECT COLX,COLY-10 FROM TBLXY) La subselección devuelve COLX y COLY-10 de TBLXY. El predicado es verdadero para la subselección, por lo tanto el resultado es el siguiente: COLA COLB ----------- ----------- 2 12 3 13 Capítulo 2. Elementos del lenguaje 249
- 276. Predicado BETWEEN expresión BETWEEN expresión AND expresión NOT El predicado BETWEEN compara un valor con un rango de valores. El predicado BETWEEN: valor1 BETWEEN valor2 AND valor3 es equivalente a la condición de búsqueda: valor1 >= valor2 AND valor1 <= valor3 El predicado BETWEEN: valor1 NOT BETWEEN valor2 AND valor3 es equivalente a la condición de búsqueda: NOT(valor1 BETWEEN valor2 AND valor3); es decir, valor1 < valor2 OR valor1 > valor3. El primer operando (expresión) no puede incluir ninguna función que sea variante o que tenga una acción externa (SQLSTATE 426804). En una mezcla de valores de indicación de fecha y hora y representaciones de serie de caracteres, todos los valores se convierten al tipo de datos del operando de fecha y hora. Ejemplos: Ejemplo 1 EMPLOYEE.SALARY BETWEEN 20000 AND 40000 Devuelve todos los salarios comprendidos entre 20.000 y 40.000 dólares. Ejemplo 2 SALARY NOT BETWEEN 20000 + :HV1 AND 40000 Suponiendo que :HV1 es 5000, da como resultado todos los salarios que son inferiores a 25.000 dólares y superiores a 40.000. 250 Consulta de SQL, Volumen 1
- 277. Predicado EXISTS EXISTS (selección completa) El predicado EXISTS comprueba la existencia de ciertas filas. La selección completa puede especificar cualquier número de columnas y v El resultado es verdadero sólo si el número de filas especificadas mediante la selección completa no es cero. v El resultado es falso sólo si el número de filas especificadas es cero v El resultado no puede ser desconocido. Ejemplo: EXISTS (SELECT * FROM TEMPL WHERE SALARY < 10000) Capítulo 2. Elementos del lenguaje 251
- 278. Predicado IN expresión1 IN (selección completa1) NOT , ( expresión2 ) expresión2 , ( expresión3 ) IN (selección completa2) NOT El predicado IN compara un valor o valores con un conjunto de valores. La selección completa debe identificar un número de columnas que sea el mismo que el número de expresiones especificadas a la izquierda de la palabra clave IN (SQLSTATE 428C4). La selección completa puede devolver cualquier número de filas. v Un predicado IN del formato: expresión IN expresión es equivalente a un predicado básico del formato: expresión = expresión v Un predicado IN del formato: expresión IN (selección completa) es equivalente a un predicado cuantificado del formato: expresión = ANY (selección completa) v Un predicado IN del formato: expresión NOT IN (selección completa) es equivalente a un predicado cuantificado del formato: expresión <> ALL (selección completa) v Un predicado IN del formato: expresión IN (expresióna, expresiónb, ..., expresiónk) es equivalente a: expresión = ANY (selección completa) donde selección completa en el formato de la cláusula-values es: VALUES (expresióna), (expresiónb), ..., (expresiónk) v Un predicado IN del formato: (expresióna, expresiónb,..., expresiónk) IN (selección completa) 252 Consulta de SQL, Volumen 1
- 279. es equivalente a un predicado cuantificado del formato: (expresióna, expresiónb,..., expresiónk) = ANY (selección completa) Los valores para expresión1 y expresión2 o la columna de selección completa1 del predicado IN deben ser compatibles. Cada valor de expresión3 y su columna correspondiente de selección completa2 del predicado IN deben ser compatibles. Pueden utilizarse las reglas para tipos de datos del resultado para determinar los atributos del resultado utilizados en la comparación. Los valores para las expresiones del predicado IN (incluyendo las columnas correspondientes de una selección completa)pueden tener páginas de códigos diferentes. Si se precisa realizar una conversión, la página de códigos se determina aplicando las reglas para las conversiones de series a la lista IN primero y, posteriormente, al predicado, utilizando la página de códigos derivada para la lista IN como segundo operando. Ejemplos: Ejemplo 1: Lo siguiente es verdadero si el valor de la fila bajo evaluación de la columna DEPTNO contiene D01, B01 o C01: DEPTNO IN (’D01’, ’B01’, ’C01’) Ejemplo 2: Lo siguiente se considera verdadero sólo si EMPNO (número de empleado) a la izquierda coincide con EMPNO de un empleado del departamento E11: EMPNO IN (SELECT EMPNO FROM EMPLOYEE WHERE WORKDEPT = ’E11’) Ejemplo 3: Dada la siguiente información, este ejemplo se considera verdadero si el valor específico de la fila de la columna COL_1 coincide con cualquier valor de la lista: Tabla 15. Ejemplo de predicado IN Expresiones Tipo Página de códigos COL_1 columna 850 variable del lenguaje HV_2 principal 437 variable del lenguaje HV_3 principal 437 CON_1 constante 850 Cuando se evalúa el predicado: COL_1 IN (:HV_2, :HV_3, CON_4) Capítulo 2. Elementos del lenguaje 253
- 280. las dos variables de lenguaje principal se convertirán a la página de códigos 850, en base a las reglas para las conversiones de series. Ejemplo 4: Lo siguiente se considera verdadero si el año especificado en EMENDATE (la fecha en que ha finalizado la actividad de un empleado en un proyecto) coincide con cualquiera de los valores especificados en la lista (el año actual o los dos años anteriores): YEAR(EMENDATE) IN (YEAR(CURRENT DATE), YEAR(CURRENT DATE - 1 YEAR), YEAR(CURRENT DATE - 2 YEARS)) Ejemplo 5: Lo siguiente se considera verdadero si tanto ID como DEPT del lado izquierdo coinciden con MANAGER y DEPTNUMB respectivamente para cualquier fila de la tabla ORG. (ID, DEPT) IN (SELECT MANAGER, DEPTNUMB FROM ORG) Información relacionada: v “Reglas para los tipos de datos del resultado” en la página 145 v “Reglas para la conversión de series” en la página 150 254 Consulta de SQL, Volumen 1
- 281. Predicado LIKE expresión-comparación LIKE expresión-patrón NOT ESCAPE expresión-escape El predicado LIKE busca series que sigan un patrón determinado. El patrón se especifica mediante una serie de caracteres en la que los signos de subrayado y de tanto por ciento tienen significados especiales. Los blancos de cola de un patrón también forman parte del patrón. Si el valor del cualquier argumento es nulo, el resultado del predicado LIKE es desconocido. Los valores de expresión-comparación, expresión-patrón y expresión-escape son expresiones de serie compatibles. Existen diferencias muy pequeñas en los tipos de expresiones de serie a las que se da soporte para cada uno de estos argumentos. Los tipos válidos de expresiones se listan en la descripción de cada argumento. Ninguna de las expresiones puede dar como resultado un tipo diferenciado. No obstante, puede ser una función que convierte un tipo diferenciado a su tipo de fuente. expresión-comparación Expresión que especifica la serie que se debe examinar para ver si cumple determinados patrones de caracteres. La expresión puede especificarse mediante: v Una constante v Un registro especial v Una variable del lenguaje principal (incluida una variable localizadora o una variable de referencia a archivos) v Una función escalar v Un localizador de gran objeto v Un nombre de columna v Una expresión que concatene cualquiera de los elementos anteriores expresión-patrón Expresión que especifica la serie que debe coincidir. La expresión puede especificarse mediante: v Una constante v Un registro especial Capítulo 2. Elementos del lenguaje 255
- 282. v Una variable del lenguaje principal v Una función escalar cuyos operandos sean cualquiera de los elementos anteriores v Una expresión que concatene cualquiera de los elementos anteriores Con las siguientes restricciones: v Ningún elemento de la expresión puede ser de tipo LONG VARCHAR, CLOB, LONG VARGRAPHIC ni DBCLOB. Además, no puede ser una variable de referencia a archivos BLOB. v La longitud real de expresión-patrón no puede ser mayor que 32.672 bytes. Una descripción simple de la utilización del patrón LIKE es que el patrón se utiliza para especificar el criterio de conformidad para los valores de la expresión-comparación donde: v El carácter de subrayado (_) representa cualquier carácter. v El signo de porcentaje (%) representa una serie de ninguno o más caracteres. v Cualquier otro carácter se representa a sí mismo. Si la expresión-patrón necesita incluir el signo de subrayado o de porcentaje, se utiliza la expresión-escape para anteponer un carácter al carácter de subrayado o de porcentaje en el patrón. A continuación encontrará una descripción exacta de la utilización del patrón LIKE. Observe que esta descripción no considera el uso de la expresión-escape; su uso se describe más adelante. v Supongamos que m indique el valor de expresión-comparación y que p indique el valor de expresión-patrón. La serie p se interpreta como una secuencia del número mínimo de especificadores de subserie de modo que cada carácter de p forma parte exacta de un especificador de subserie. Un especificador de subserie es un signo de subrayado, un signo de tanto por ciento o bien una secuencia de caracteres no vacía que no sea un signo de subrayado ni de tanto por ciento. El resultado del predicado es desconocido si m o p es el valor nulo. De lo contrario, el resultado es verdadero o falso. El resultado es verdadero si m y p son dos series vacías o existe una partición de m en subseries de modo que: – Una subserie de m es una secuencia de cero o más caracteres continuos y cada carácter de m forma parte exacta de una subserie. – Si el especificador de subserie n es un subrayado, la subserie n de m es cualquier carácter. 256 Consulta de SQL, Volumen 1
- 283. – Si el especificador de subserie n es un signo de tanto por ciento, la subserie n de m es cualquier secuencia de cero o más caracteres. – Si el especificador de subserie n no es un subrayado ni un signo de tanto por ciento, la subserie n de m es igual al especificador de subserie y tiene la misma longitud que el especificador de subserie. – El número de subseries de m es igual al número de especificadores de subserie. Por consiguiente, si p es una serie vacía y m no es una serie vacía, el resultado es falso. Del mismo modo, si m es una serie vacía y p no es una serie vacía (excepto en el caso de una serie que sólo contenga signos de porcentaje), el resultado es falso. El predicado m NOT LIKE p es equivalente a la condición de búsqueda NOT (m LIKE p). Cuando se especifica la expresión-escape, la expresión-patrón no debe contener el carácter de escape identificado por la expresión-escape excepto cuando viene seguido inmediatamente por el carácter de escape, el carácter de subrayado o el carácter de tanto por ciento (SQLSTATE 22025). Si la expresión-comparación es una serie de caracteres de una base de datos MBCS, puede contener datos mixtos. En este caso, el patrón puede estar compuesto por caracteres SBCS y MBCS. Los caracteres especiales del patrón se interpretan de la forma siguiente: v Un signo de subrayado SBCS representa un carácter SBCS. v Un signo de subrayado DBCS representa un carácter MBCS. v Un signo de tanto por ciento (SBCS o DBCS) representa una serie de cero o más caracteres SBCS o MBCS. expresión-escape Este argumento opcional es una expresión que especifica un carácter que modifica el significado especial de los caracteres de subrayado (_) y de porcentaje (%) en la expresión-patrón. De este modo, el predicado LIKE permite comparar valores que contengan los caracteres de porcentaje y subrayado efectivos. La expresión puede especificarse mediante: v una constante v un registro especial v una variable del lenguaje principal v una función escalar cuyos operandos sean cualquiera de los elementos anteriores v una expresión que concatene cualquiera de los elementos anteriores Capítulo 2. Elementos del lenguaje 257
- 284. teniendo en cuenta las siguientes restricciones: v Ningún elemento de la expresión puede ser de tipo LONG VARCHAR, CLOB, LONG VARGRAPHIC o DBCLOB. Además, no puede ser una variable de referencia a archivos BLOB. v El resultado de la expresión debe ser un carácter SBCS o DBCS o una serie binaria que contenga exactamente 1 byte (SQLSTATE 22019). Cuando los caracteres de escape están presentes en la serie patrón, tanto un signo de carácter de subrayado, un signo de tanto por ciento como un carácter de escape pueden representar una ocurrencia literal por sí mismos. Esto es verdadero si el carácter viene precedido por un número impar de caracteres de escape sucesivos. De lo contrario, no es verdadero. En un patrón, una secuencia de caracteres de escape sucesivos se trata de la siguiente manera: v Supongamos que S es una secuencia y que no forma parte de una secuencia más grande de caracteres de escape sucesivos. Supongamos asimismo que S contiene en total n caracteres. Las reglas que rigen a S dependen del valor de n: – Si n es impar, S debe ir seguido por un carácter de subrayado o bien por un signo de tanto por ciento (SQLSTATE 22025). S y el carácter que le sigue representan (n-1)/2 ocurrencias literales del carácter de escape seguido por una ocurrencia literal del signo de subrayado o de tanto por ciento. – Si n es par, S representa n/2 ocurrencias literales del carácter de escape. A diferencia de cuando n es impar, S podría finalizar el patrón. Si no finaliza el patrón, puede ir seguido por cualquier carácter (a excepción, obviamente, de un carácter de escape, ya que vulneraría la suposición de que S no forma parte de una secuencia más grande de caracteres de escape sucesivos). Si S va seguido por un signo de subrayado o de tanto por ciento, ese carácter tiene su significado especial. A continuación se ilustra el efecto de ocurrencias sucesivas del carácter de escape (que, en este caso, es la barra inclinada invertida () ). Serie patrón Patrón real % Un signo de tanto por ciento % Una barra invertida seguida por un cero o varios caracteres arbitrarios % Una barra invertida seguida por un signo de tanto por ciento 258 Consulta de SQL, Volumen 1
- 285. La página de códigos utilizada en la comparación se basa en la página de códigos del valor de expresión-comparación. v El valor de la expresión-comparación no se convierte nunca. v Si la página de códigos de la expresión-patrón es diferente de la página de códigos de la expresión-comparación, el valor de la expresión-patrón se convierte a la página de códigos de la expresión-comparación, a menos que algún operando se haya definido como FOR BIT DATA (en cuyo caso no se efectúa la conversión). v Si la página de códigos de la expresión-escape es diferente de la página de códigos de la expresión-comparación, el valor de la expresión-escape se convierte a la página de códigos de la expresión-comparación, a menos que algún operando se defina como FOR BIT DATA (en cuyo caso no se efectúa la conversión). Notas: v El número de blancos finales es importante tanto en la expresión comparación como en la expresión-patrón. Si las series no tienen la misma longitud, la más corta se rellena con espacios en blanco. Por ejemplo, la expresión ’PADDED ’ LIKE ’PADDED’ no daría lugar a una comparación. v Si el patrón especificado en un predicado LIKE es un marcador de parámetro y se utiliza una variable del lenguaje principal de caracteres de longitud fija para sustituir el marcador de parámetro, el valor especificado para la variable del lenguaje principal debe tener la longitud correcta. Si no se especifica la longitud correcta, la operación de selección no devolverá los resultados esperados. Por ejemplo, si la variable del lenguaje principal está definida como CHAR(10) y se asigna el valor WYSE% a dicha variable del lenguaje principal, ésta se rellena con espacios en blanco en la asignación. El patrón utilizado es: ’WYSE% ’ El gestor de bases de datos busca todos los valores que empiezan con WYSE y terminan con cinco espacios en blanco. Si se desea buscar sólo los valores que empiezan con ’WYSE’, debe asignarse el valor ’WSYE%%%%%%’ a la variable del lenguaje principal. Ejemplos: v Busque la serie ’SYSTEMS’ que aparezca en la columna PROJNAME de la tabla PROJECT. SELECT PROJNAME FROM PROJECT WHERE PROJECT.PROJNAME LIKE ’%SYSTEMS%’ v Busque una serie con un primer carácter ’J’ que tenga exactamente dos caracteres de longitud en la columna FIRSTNAME de la tabla EMPLOYEE. Capítulo 2. Elementos del lenguaje 259
- 286. SELECT FIRSTNME FROM EMPLOYEE WHERE EMPLOYEE.FIRSTNME LIKE ’J_’ v Busque una serie de caracteres, de cualquier longitud, cuyo primer carácter sea ’J’, en la columna FIRSTNAME de la tabla EMPLOYEE. SELECT FIRSTNME FROM EMPLOYEE WHERE EMPLOYEE.FIRSTNME LIKE ’J%’ v En la tabla CORP_SERVERS, busque una serie en la columna LA_SERVERS que coincida con el valor del registro especial CURRENT SERVER. SELECT LA_SERVERS FROM CORP_SERVERS WHERE CORP_SERVERS.LA_SERVERS LIKE CURRENT SERVER v Recupere todas las series que empiecen por la secuencia de caracteres ’%_’ en la columna A de la tabla T. SELECT A FROM T WHERE T.A LIKE ’%_%’ ESCAPE ’’ v Utilice la función escalar BLOB para obtener un carácter de escape de un byte que sea compatible con los tipos de datos coincidentes y de patrón (ambos BLOB). SELECT COLBLOB FROM TABLET WHERE COLBLOB LIKE :pattern_var ESCAPE BLOB(X’OE’) 260 Consulta de SQL, Volumen 1
- 287. Predicado NULL expresión IS NULL NOT El predicado NULL comprueba la existencia de valores nulos. El resultado de un predicado NULL no puede ser desconocido. Si el valor de la expresión es nulo, el resultado es verdadero. Si el valor no es nulo, el resultado es falso. Si se especifica NOT, el resultado se invierte. Ejemplos: PHONENO IS NULL SALARY IS NOT NULL Capítulo 2. Elementos del lenguaje 261
- 288. Predicado TYPE expresión IS OF NOT IS OF DYNAMIC TYPE NOT , ( nombre de tipo ) ONLY Un predicado TYPE compara el tipo de una expresión con uno o más tipos estructurados definidos por el usuario. El tipo dinámico de una expresión que implica desreferenciar un tipo de referencia es el tipo real de la fila referenciada de la tabla o vista con tipo de destino. Puede diferenciarse del tipo de destino de una expresión que implica la referencia, denominado el tipo estático de la expresión. Si el valor de expresión es nulo, el resultado del predicado será desconocido. El resultado del predicado será verdadero si el tipo dinámico de la expresión es un subtipo de uno de los tipos estructurados especificados por nombre de tipo; de lo contrario, el resultado será falso. Si ONLY precede cualquier nombre de tipo, no se tienen en cuenta los subtipos correspondientes de este tipo. Si nombre de tipo no está calificado, se resuelve utilizando la vía de acceso de SQL. Cada nombre de tipo debe identificar un tipo definido por el usuario que esté en la jerarquía de tipos del tipo estático de expresión (SQLSTATE 428DU). Debe utilizarse la función DEREF siempre que el predicado TYPE tenga una expresión que implique un valor de tipo de referencia. El tipo estático de esta forma de expresión es el tipo de destino de la referencia. La sintaxis IS OF y OF DYNAMIC TYPE son alternativas equivalentes para el predicado TYPE. Asimismo, IS NOT OF y NOT OF DYNAMIC TYPE son alternativas equivalentes. Ejemplos: Existe una jerarquía de tablas que tiene una tabla raíz EMPLOYEE de tipo EMP y una subtabla MANAGER de tipo MGR. Otra tabla, ACTIVITIES, incluye una columna denominada WHO_RESPONSIBLE que está definida como REF(EMP) SCOPE EMPLOYEE. Lo siguiente es un predicado de tipo 262 Consulta de SQL, Volumen 1
- 289. que devuelve un resultado verdadero cuando una fila correspondiente a WHO_RESPONSIBLE es un director (″manager″): DEREF (WHO_RESPONSIBLE) IS OF (MGR) Si una tabla contiene una columna EMPLOYEE de tipo EMP, EMPLOYEE puede contener valores de tipo EMP y también valores de sus subtipos, tales como MGR. El predicado siguiente EMPL IS OF (MGR) devuelve un resultado verdadero cuando EMPL no es nulo y es realmente un director. Información relacionada: v “DEREF” en la página 356 Capítulo 2. Elementos del lenguaje 263
- 290. 264 Consulta de SQL, Volumen 1
- 291. Capítulo 3. Funciones Resumen de las funciones Una función es una operación que se indica mediante un nombre de función seguido por un par de paréntesis que contienen la especificación de los argumentos (es posible que no haya argumentos). Las funciones incorporadas las proporciona el gestor de bases de datos; devuelven un resultado de un solo valor y se identifican como parte del esquema SYSIBM. Entre las funciones incorporadas se incluyen las funciones de columna (como, por ejemplo, AVG), las funciones con operadores (por ejemplo, “+”), las funciones de conversión (como DECIMAL), y otras (como SUBSTR). Las funciones definidas por el usuario se registran en una base de datos de SYSCAT.ROUTINES (utilizando la sentencia CREATE FUNCTION). Estas funciones nunca forman parte del esquema SYSIBM. Se proporciona un conjunto de estas funciones con el gestor de bases de datos en un esquema denominado SYSFUN y otro en un esquema denominado SYSPROC. Las funciones se clasifican como funciones agregadas (de columna), funciones escalares, funciones de fila y funciones de tabla. v El argumento de una función de columna es un conjunto de valores similares. Una función de columna devuelve un solo valor (posiblemente nulo) y puede especificarse en una sentencia de SQL donde sea posible utilizar una expresión. v Los argumentos de una función escalar son valores escalares individuales, que pueden ser de tipos distintos y tener significados diferentes. Una función escalar devuelve un solo valor (posiblemente nulo) y puede especificarse en una sentencia de SQL donde sea posible utilizar una expresión. v El argumento de una función de fila es un tipo estructurado. Una función de fila devuelve una fila de tipos de datos incorporados y sólo se puede especificar como función de transformación para un tipo estructurado. v Los argumentos de una función de tabla son valores escalares individuales, que pueden ser de tipos distintos y tener significados diferentes. Una función de tabla devuelve una tabla a la sentencia SQL y sólo puede especificarse en la cláusula FROM de una sentencia SELECT. © Copyright IBM Corp. 1993, 2002 265
- 292. El nombre de la función, combinado con el esquema, proporciona el nombre completamente calificado de la función. La combinación del esquema, el nombre de función y los parámetros de entrada constituye una signatura de función. En algunos casos, el tipo de parámetro de entrada se especifica como un tipo de datos incorporados concreto y, en otros casos, se especifica mediante una variable general como cualquier-tipo-numérico. Si se especifica un tipo de datos concreto, una coincidencia exacta sólo se obtendrá con el tipo de datos especificado. Si se utiliza una variable general, cada uno de los tipos de datos asociados con dicha variable da como resultado una coincidencia exacta. Es posible que existan funciones adicionales, porque las funciones definidas por el usuario pueden crearse en esquemas distintos, utilizando como fuente una de las signaturas de función. También es posible crear funciones externas en las aplicaciones. Conceptos relacionados: v “Funciones agregadas” en la página 289 Información relacionada: v “Funciones” en la página 181 v “Subselección” en la página 580 v “CREATE FUNCTION sentencia” en la publicación Consulta de SQL, Volumen 2 266 Consulta de SQL, Volumen 1
- 293. La tabla siguiente resume la información acerca de las funciones a las que se proporciona soporte. El nombre de la función, combinado con el esquema, proporciona el nombre completamente calificado de la función. La columna “Parámetros de entrada” muestra el tipo de datos esperado para cada argumento durante la invocación de función. Muchas de las funciones incluyen variaciones de los parámetros de entrada que permiten utilizar diferentes tipos de datos o un número diferente de argumentos. La combinación del esquema, nombre de función y parámetros de entrada conforman una signatura de función. La columna “Devuelve” muestra los tipos de datos posibles de los valores devueltos por la función. Tabla 16. Funciones soportadas Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve el valor absoluto del argumento. ABS o ABSVAL Cualquier expresión que devuelve un tipo de datos Mismo tipo de datos y numérico incorporado. longitud que el argumento SYSFUN Devuelve el valor absoluto del argumento. SMALLINT SMALLINT ABS o ABSVAL INTEGER INTEGER BIGINT BIGINT DOUBLE DOUBLE SYSFUN Devuelve el arco coseno del argumento, en forma de ángulo expresado ACOS en radianes. DOUBLE DOUBLE SYSFUN Devuelve el valor de código ASCII del carácter más a la izquierda del argumento, expresado en forma de entero. ASCII CHAR INTEGER VARCHAR(4000) INTEGER CLOB(1M) INTEGER SYSFUN Devuelve el arco seno del argumento, en forma de ángulo expresado ASIN en radianes. DOUBLE DOUBLE SYSFUN Devuelve el arco tangente del argumento, en forma de ángulo ATAN expresado en radianes. DOUBLE DOUBLE SYSFUN Devuelve el arco tangente de las coordenadas x e y, especificadas por el primer y segundo argumentos respectivamente, en forma de ángulo ATAN2 expresado en radianes. DOUBLE, DOUBLE DOUBLE SYSIBM Devuelve la arcotangente hiperbólica del argumento, donde el ATANH argumento es un ángulo expresado en radianes. DOUBLE DOUBLE Capítulo 3. Funciones 267
- 294. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve el promedio de un conjunto de números (función de AVG columna). 4 1 tipo-numérico tipo-numérico SYSIBM Devuelve una representación de entero de 64 bits de un número o serie de caracteres en el formato de una constante de enteros. BIGINT tipo-numérico BIGINT VARCHAR BIGINT SYSIBM Convierte el tipo fuente a BLOB, con una longitud opcional. BLOB tipo-serie BLOB tipo-serie, INTEGER BLOB SYSFUN Devuelve el entero más pequeño que es mayor o igual al argumento. SMALLINT SMALLINT CEIL o CEILING INTEGER INTEGER BIGINT BIGINT DOUBLE DOUBLE SYSIBM Devuelve una representación de serie del tipo fuente. tipo-caracteres CHAR tipo-caracteres, INTEGER CHAR(entero) tipo-fechahora CHAR 2 tipo-fechahora, palabraclave CHAR CHAR SMALLINT CHAR(6) INTEGER CHAR(11) BIGINT CHAR(20) DECIMAL CHAR(2+precisión) DECIMAL, VARCHAR CHAR(2+precisión) SYSFUN Devuelve una representación de serie de caracteres de un número de CHAR coma flotante. DOUBLE CHAR(24) SYSFUN Devuelve el carácter que tiene el valor de código ASCII especificado por el argumento. El valor del argumento debe estar entre 0 y 255; de CHR lo contrario, el valor de retorno es nulo. INTEGER CHAR(1) CLOB SYSIBM Convierte el tipo fuente a CLOB, con una longitud opcional. tipo-caracteres CLOB tipo-caracteres, INTEGER CLOB 268 Consulta de SQL, Volumen 1
- 295. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve el primer argumento que no es nulo del conjunto de COALESCE 3 argumentos. cualquier-tipo, cualquier-tipo-compatible-unión, ... cualquier-tipo SYSIBM Devuelve la concatenación de 2 argumentos de serie. CONCAT o || tipo-serie, tipo-serie-compatible tipo-serie máx SYSIBM Devuelve el coeficiente de correlación de un conjunto de pares de CORRELATION o CORR números. tipo-numérico, tipo-numérico DOUBLE SYSFUN Devuelve el coseno del argumento, donde el argumento es un ángulo COS expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve el coseno hiperbólico del argumento, donde el argumento es COSH un ángulo expresado en radianes. DOUBLE DOUBLE SYSFUN Devuelve la cotangente del argumento, donde el argumento es un COT ángulo expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve la cuenta del número de filas en un conjunto de filas o COUNT valores (función de columna). 4 cualquier-tipo-incorporado INTEGER SYSIBM Devuelve el número de filas o de valores de un conjunto de filas o de valores (función de columna). El resultado puede ser mayor que el COUNT_BIG valor máximo de entero. 4 cualquier-tipo-incorporado DECIMAL(31,0) SYSIBM Devuelve la covarianza de un conjunto de pares de números. COVARIANCE o COVAR tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve una fecha de un solo valor de entrada. DATE DATE DATE TIMESTAMP DATE DOUBLE DATE VARCHAR DATE SYSIBM Devuelve la parte correspondiente al día de un valor. VARCHAR INTEGER DAY DATE INTEGER TIMESTAMP INTEGER DECIMAL INTEGER Capítulo 3. Funciones 269
- 296. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Devuelve una serie de caracteres en mayúsculas y minúsculas mezcladas que contiene el nombre del día (por ejemplo viernes) correspondiente a la parte de día del argumento basándose en el entorno nacional existente al emitirse db2start. DAYNAME VARCHAR(26) VARCHAR(100) DATE VARCHAR(100) TIMESTAMP VARCHAR(100) SYSFUN Devuelve el día de la semana del argumento, en forma de valor entero comprendido dentro del rango 1-7, donde 1 representa el domingo. DAYOFWEEK VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSFUN Devuelve el día de la semana del argumento, en forma de valor entero comprendido dentro del rango 1-7, donde 1 representa el lunes. DAYOFWEEK_ISO VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSFUN Devuelve el día del año del argumento como un valor entero en el rango de 1 a 366. DAYOFYEAR VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSIBM Devuelve una representación de entero de una fecha. VARCHAR INTEGER DAYS TIMESTAMP INTEGER DATE INTEGER SYSIBM Convierte el tipo fuente a DBCLOB, con una longitud opcional. DBCLOB tipo-gráfico DBCLOB tipo-gráfico, INTEGER DBCLOB SYSIBM Devuelve el número de partición de base de datos de la fila. El DBPARTITIONNUM 3 argumento es un nombre de columna dentro de una tabla. cualquier-tipo INTEGER SYSIBM Devuelve la representación decimal de un número, con la precisión y escala opcionales. DECIMAL o DEC tipo-numérico DECIMAL tipo-numérico, INTEGER DECIMAL tipo-numérico INTEGER, INTEGER DECIMAL 270 Consulta de SQL, Volumen 1
- 297. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve la representación decimal de una serie de caracteres, con precisión, escala y caracteres decimales opcionales. VARCHAR DECIMAL DECIMAL o DEC VARCHAR, INTEGER DECIMAL VARCHAR, INTEGER, INTEGER DECIMAL VARCHAR, INTEGER, INTEGER, VARCHAR DECIMAL SYSIBM Devuelve un valor que es el resultado del descifrado de datos cifrados utilizando una serie de contraseña. DECRYPT_BIN VARCHAR FOR BIT DATA VARCHAR FOR BIT DATA VARCHAR FOR BIT DATA, VARCHAR VARCHAR FOR BIT DATA SYSIBM Devuelve un valor que es el resultado del descifrado de datos cifrados utilizando una serie de contraseña. DECRYPT_CHAR VARCHAR FOR BIT DATA VARCHAR VARCHAR FOR BIT DATA, VARCHAR VARCHAR SYSFUN Devuelve el número de grados convertidos del argumento expresados DEGREES en radianes. DOUBLE DOUBLE SYSIBM Devuelve una instancia del tipo de destino del argumento del tipo de referencia. DEREF REF(cualquier-tipo-estructurado) con ámbito definido cualquier-tipo-estructurado (igual que el tipo de destino de entrada) SYSFUN Devuelve la diferencia entre los sonidos de las palabras de las dos series argumento, tal como esa diferencia se determina mediante la DIFFERENCE utilización de la función SOUNDEX. Un valor de 4 significa que las series tienen igual sonido. VARCHAR(4000), VARCHAR(4000) INTEGER SYSIBM Devuelve la representación de serie de caracteres de un número. DIGITS DECIMAL CHAR SYSIBM Devuelve el atributo de comentario de un valor DATALINK. DLCOMMENT DATALINK VARCHAR(254) SYSIBM Devuelve el atributo del tipo de enlace de un valor DATALINK. DLLINKTYPE DATALINK VARCHAR(4) SYSIBM Devuelve un valor DATALINK que tiene un atributo que indica que se DLNEWCOPY ha modificado el archivo referenciado. DATALINK VARCHAR(254) SYSIBM Devuelve un valor DATALINK que tiene un atributo que indica que DLPREVIOUSCOPY debería restaurarse la versión anterior del archivo. DATALINK VARCHAR(254) Capítulo 3. Funciones 271
- 298. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve un valor DATALINK. Cuando la función está al lado derecho de una cláusula SET de una sentencia UPDATE o está en una cláusula VALUES dentro de una sentencia INSERT, la asignación del valor DLREPLACECONTENT devuelto provoca la sustitución del contenido de un archivo por otro archivo y la creación de un enlace con el mismo. DATALINK VARCHAR(254) SYSIBM Devuelve el URL completo (incluido el símbolo de acceso) de un valor DLURLCOMPLETE DATALINK. DATALINK VARCHAR SYSIBM Devuelve el atributo de ubicación de datos a partir de un valor DLURLCOMPLETEONLY DATALINK, con un tipo de enlace de URL. DATALINK VARCHAR(254) SYSIBM Devuelve el valor URL completo a partir de un valor DATALINK, con DLURLCOMPLETEWRITE un tipo de enlace de URL. DATALINK VARCHAR(254) SYSIBM Devuelve la vía de acceso y el nombre de archivo (incluido el símbolo DLURLPATH de acceso) de un valor DATALINK. DATALINK VARCHAR SYSIBM Devuelve la vía de acceso y el nombre de archivo (sin símbolo de DLURLPATHONLY accesos) de un valor DATALINK. DATALINK VARCHAR SYSIBM Devuelve la vía de acceso y el nombre de archivo necesarios para acceder a un archivo de un servidor determinado a partir de un valor DLURLPATHWRITE DATALINK con un tipo de enlace de URL. DATALINK VARCHAR(254) SYSIBM Devuelve el esquema del atributo del URL de un valor DATALINK. DLURLSCHEME DATALINK VARCHAR SYSIBM Devuelve el servidor del atributo del URL de un valor DATALINK. DLURLSERVER DATALINK VARCHAR SYSIBM Crea un valor DATALINK a partir de un argumento ubicación-datos, un argumento tipo de enlace y un argumento serie-comentario opcional. DLVALUE VARCHAR DATALINK VARCHAR, VARCHAR DATALINK VARCHAR, VARCHAR, VARCHAR DATALINK DOUBLE o SYSIBM Devuelve la representación en coma flotante de un número. DOUBLE_PRECISION tipo-numérico DOUBLE 272 Consulta de SQL, Volumen 1
- 299. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Devuelve el número de coma flotante, correspondiente a la representación de serie de caracteres de un número. Se ignoran los DOUBLE blancos iniciales y de cola de argumento. VARCHAR DOUBLE SYSIBM Devuelve un valor que es el resultado del descifrado de una expresión de serie de datos. ENCRYPT VARCHAR VARCHAR FOR BIT DATA VARCHAR, VARCHAR VARCHAR FOR BIT DATA VARCHAR, VARCHAR, VARCHAR VARCHAR FOR BIT DATA SYSIBM Devuelve el estado operativo de un supervisor de sucesos en EVENT_MON_STATE particular. VARCHAR INTEGER SYSFUN Devuelve la función exponencial del argumento. EXP DOUBLE DOUBLE FLOAT SYSIBM Igual que DOUBLE. SYSFUN Devuelve el valor de entero más grande que es menor o igual al argumento. SMALLINT SMALLINT FLOOR INTEGER INTEGER BIGINT BIGINT DOUBLE DOUBLE SYSIBM Devuelve la indicación de contraseña si se encuentra alguna. GETHINT VARCHAR o CLOB VARCHAR SYSIBM Devuelve una serie de caracteres de datos de bits que es exclusiva GENERATE_UNIQUE comparada a cualquier otra ejecución de la misma función. ningún argumento CHAR(13) FOR BIT DATA SYSFUN Devuelve la información necesaria para instalar una rutina idéntica en otro servidor de bases de datos que se ejecute al mismo nivel y ejecute GET_ROUTINE_SAR el mismo sistema operativo. BLOB(3M), CHAR(2), VARCHAR(257) BLOB(3M) SYSIBM Convierte el tipo fuente a GRAPHIC, con una longitud opcional. GRAPHIC tipo-gráfico GRAPHIC tipo-gráfico, INTEGER GRAPHIC Capítulo 3. Funciones 273
- 300. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Se utiliza con conjuntos-agrupaciones y supergrupos para indicar filas de subtotales generadas por un conjunto de agrupaciones (función de columna). El valor devuelto es: 1 El valor del argumento de la fila devuelta es un valor nulo y GROUPING la fila se ha generado para un conjunto de agrupaciones. Esta fila generada proporciona un subtotal para un conjunto de agrupaciones. 0 en otro caso. cualquier-tipo SMALLINT SYSIBM Devuelve el índice de mapa de particionamiento (de 0 a 4095) de la HASHEDVALUE 3 fila. El argumento es un nombre de columna dentro de una tabla. cualquier-tipo INTEGER SYSIBM Devuelve la representación hexadecimal de un valor. HEX cualquier-tipo-incorporado VARCHAR SYSIBM Devuelve la parte correspondiente a la hora de un valor. VARCHAR INTEGER HOUR TIME INTEGER TIMESTAMP INTEGER DECIMAL INTEGER SYSIBM Devuelve el valor asignado más recientemente para una columna de IDENTITY_VAL_LOCAL identidad. DECIMAL SYSFUN Devuelve una serie donde se han suprimido argumento3 bytes de argumento1 empezando en argumento2 y donde argumento4 se ha insertado en argumento1 empezando en argumento2. INSERT VARCHAR(4000), INTEGER, INTEGER, VARCHAR(4000) VARCHAR(4000) CLOB(1M), INTEGER, INTEGER, CLOB(1M) CLOB(1M) BLOB(1M), INTEGER, INTEGER, BLOB(1M) BLOB(1M) SYSIBM Devuelve la representación de entero de un número. INTEGER o INT tipo-numérico INTEGER VARCHAR INTEGER SYSFUN Devuelve un valor de entero que representa el número de días desde el 1 de enero de 4712 A.C. (el inicio del calendario Juliano) hasta el valor de fecha especificado en el argumento. JULIAN_DAY VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER 274 Consulta de SQL, Volumen 1
- 301. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve una serie en la que todos los caracteres se han convertido a minúsculas. LCASE o LOWER CHAR CHAR VARCHAR VARCHAR SYSFUN Devuelve una serie en la que todos los caracteres se han convertido a minúsculas. LCASE sólo manejará caracteres del conjunto no variante.Por lo tanto, LCASE(UCASE(serie)) no devolverá LCASE necesariamente el mismo resultado que LCASE(serie). VARCHAR(4000) VARCHAR(4000) CLOB(1M) CLOB(1M) SYSFUN Devuelve una serie que consta de los argumento2 bytes más a la izquierda del argumento1. LEFT VARCHAR(4000), INTEGER VARCHAR(4000) CLOB(1M), INTEGER CLOB(1M) BLOB(1M), INTEGER BLOB(1M) SYSIBM Devuelve la longitud del operando en bytes (excepto los tipos de serie LENGTH de doble byte que devuelven la longitud en caracteres). cualquier-tipo-incorporado INTEGER SYSFUN Devuelve el logaritmo natural del argumento (igual que LOG). LN DOUBLE DOUBLE SYSFUN Devuelve la posición inicial de la primera ocurrencia del argumento1 en el argumento2. Si se especifica el tercer argumento opcional, indica la posición del carácter en el argumento2 en el que la búsqueda tiene que empezar. Si el argumento1 no se encuentra en el argumento2, se devuelve el valor 0. VARCHAR(4000), VARCHAR(4000) INTEGER LOCATE VARCHAR(4000), VARCHAR(4000), INTEGER INTEGER CLOB(1M), CLOB(1M) INTEGER CLOB(1M), CLOB(1M), INTEGER INTEGER BLOB(1M), BLOB(1M) INTEGER BLOB(1M), BLOB(1M), INTEGER INTEGER SYSFUN Devuelve el logaritmo natural del argumento (igual que LN). LOG DOUBLE DOUBLE SYSFUN Devuelve el logaritmo de base 10 del argumento. LOG10 DOUBLE DOUBLE SYSIBM Devuelve una serie larga. LONG_VARCHAR tipo-caracteres LONG VARCHAR Capítulo 3. Funciones 275
- 302. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Convierte el tipo fuente a LONG_VARGRAPHIC. LONG_VARGRAPHIC tipo-gráfico LONG VARGRAPHIC SYSIBM Devuelve los caracteres del argumento habiendo eliminado los blancos iniciales. CHAR VARCHAR LTRIM VARCHAR VARCHAR GRAPHIC VARGRAPHIC VARGRAPHIC VARGRAPHIC SYSFUN Devuelve los caracteres del argumento habiendo eliminado los blancos iniciales. LTRIM VARCHAR(4000) VARCHAR(4000) CLOB(1M) CLOB(1M) SYSIBM Devuelve el valor máximo de un conjunto de valores (función de MAX columna). 5 cualquier-tipo-incorporado igual que un tipo de entrada SYSIBM Devuelve la parte correspondiente a los microsegundos (unidad-tiempo) de un valor. MICROSECOND VARCHAR INTEGER TIMESTAMP INTEGER DECIMAL INTEGER SYSFUN Devuelve un valor entero en el rango de 0 a 86.400 que representa el número de segundos entre la medianoche y el valor de hora especificado en el argumento. MIDNIGHT_SECONDS VARCHAR(26) INTEGER TIME INTEGER TIMESTAMP INTEGER SYSIBM Devuelve el valor mínimo de un conjunto de valores (función de MIN columna). 5 cualquier-tipo-incorporado igual que un tipo de entrada SYSIBM Devuelve la parte correspondiente a los minutos de un valor. VARCHAR INTEGER MINUTE TIME INTEGER TIMESTAMP INTEGER DECIMAL INTEGER 276 Consulta de SQL, Volumen 1
- 303. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Devuelve el resto (módulos) del argumento1 dividido por el argumento2. El resultado sólo es negativo si el argumento1 es negativo. MOD SMALLINT, SMALLINT SMALLINT INTEGER, INTEGER INTEGER BIGINT, BIGINT BIGINT SYSIBM Devuelve la parte correspondiente al mes de un valor. VARCHAR INTEGER MONTH DATE INTEGER TIMESTAMP INTEGER DECIMAL INTEGER SYSFUN Devuelve una serie de caracteres en mayúsculas y minúsculas mezcladas que contiene el nombre del mes (por ejemplo, enero) correspondiente a la parte de mes del argumento que es una fecha o una indicación de la fecha y hora, basándose en el entorno nacional MONTHNAME existente al iniciar la base de datos. VARCHAR(26) VARCHAR(100) DATE VARCHAR(100) TIMESTAMP VARCHAR(100) MQDB2 Publica datos en una ubicación MQSeries. MQPUBLISH VARCHAR(4000) INTEGER MQDB2 Devuelve un mensaje de una ubicación MQSeries. MQREAD tipo-serie VARCHAR(4000) MQDB2 Devuelve una tabla con mensajes y metadatos de mensaje de una MQREADALL ubicación MQSeries. Véase “MQREADALL” en la página 521. MQDB2 Devuelve un mensaje de una ubicación MQSeries y elimina el mensaje MQRECEIVE de la cola asociada. tipo-serie VARCHAR(4000) MQDB2 Devuelve una tabla que contiene los mensajes y metadatos de mensaje MQRECEIVEALL de una ubicación MQSeries y elimina los mensajes de la cola asociada. Vea “MQRECEIVEALL” en la página 525 MQDB2 Envía datos a una ubicación MQSeries. MQSEND VARCHAR(4000) INTEGER MQDB2 Abona a los mensajes de MQSeries publicados acerca de un tema MQSUBSCRIBE específico. tipo-serie INTEGER Capítulo 3. Funciones 277
- 304. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve MQDB2 Elimina el abono a los mensajes de MQSeries publicados acerca de un MQUNSUBSCRIBE tema específico. tipo-serie INTEGER SYSIBM Devuelve el producto de dos argumentos como un valor decimal. Esta función es útil cuando la suma de las precisiones de argumento es MULTIPLY_ALT superior a 31. tipo-numérico-exacto, tipo-numérico-exacto DECIMAL SYSIBM Devuelve NULL si los argumentos son igual, de lo contrario devuelve NULLIF 3 el primer argumento. cualquier-tipo 5, cualquier-tipo-comparable5 cualquier-tipo SYSIBM Devuelve la posición en la que una serie está contenida en otra. POSSTR tipo-serie, tipo-serie-compatible INTEGER SYSFUN Devuelve el valor del argumento1 elevado a la potencia del argumento2. INTEGER, INTEGER INTEGER POWER BIGINT, BIGINT BIGINT DOUBLE, INTEGER DOUBLE DOUBLE, DOUBLE DOUBLE SYSFUN Pasa la información necesaria para crear y definir una rutina SQL en el servidor de bases de datos. PUT_ROUTINE_SAR BLOB(3M) BLOB(3M), VARCHAR(128), INTEGER SYSFUN Devuelve un valor entero en el rango de 1 a 4 que representa el trimestre del año para la fecha especificada en el argumento. QUARTER VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSFUN Devuelve el número de radianes convertidos del argumento que se RADIANS expresa en grados. DOUBLE DOUBLE SYSIBM Genera un error en la SQLCA. El sqlstate devuelto se indica por el 3 argumento1. El segundo argumento contiene cualquier texto que se ha RAISE_ERROR de devolver. 6 VARCHAR, VARCHAR cualquier-tipo SYSFUN Devuelve un valor aleatorio de coma flotante comprendido entre 0 y 1, utilizando el argumento como valor generador opcional. RAND ningún argumento necesario DOUBLE INTEGER DOUBLE 278 Consulta de SQL, Volumen 1
- 305. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve la representación de coma flotante de precisión simple REAL correspondiente a un número. tipo-numérico REAL SYSIBM Devuelve una serie formateada con códigos XML y que contiene REC2XML nombres de columna y datos de columna. DECIMAL, VARCHAR, VARCHAR, cualquier-tipo7 VARCHAR SYSIBM Devuelve cantidades que se utilizan para calcular estadísticas de REGR_AVGX diagnósticos. tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve cantidades que se utilizan para calcular estadísticas de REGR_AVGY diagnósticos. tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve el número de pares de números no nulos que se utilizan REGR_COUNT para acomodar la línea de regresión. tipo-numérico,tipo-numérico INTEGER REGR_INTERCEPT o SYSIBM Devuelve la intersección y de la línea de regresión. REGR_ICPT tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve el coeficiente de determinación de la regresión. REGR_R2 tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve la inclinación de la línea. REGR_SLOPE tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve cantidades que se utilizan para calcular estadísticas de REGR_SXX diagnósticos. tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve cantidades que se utilizan para calcular estadísticas de REGR_SXY diagnósticos. tipo-numérico,tipo-numérico DOUBLE SYSIBM Devuelve cantidades que se utilizan para calcular estadísticas de REGR_SYY diagnósticos. tipo-numérico,tipo-numérico DOUBLE SYSFUN Devuelve una serie de caracteres compuesta del argumento1 repetido argumento2 veces. REPEAT VARCHAR(4000), INTEGER VARCHAR(4000) CLOB(1M), INTEGER CLOB(1M) BLOB(1M), INTEGER BLOB(1M) Capítulo 3. Funciones 279
- 306. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Sustituye todas las ocurrencias del argumento2 en el argumento1 por el argumento3. REPLACE VARCHAR(4000), VARCHAR(4000), VARCHAR(4000) VARCHAR(4000) CLOB(1M), CLOB(1M), CLOB(1M) CLOB(1M) BLOB(1M), BLOB(1M), BLOB(1M) BLOB(1M) SYSFUN Devuelve una serie que consta de los argumento2 bytes más a la derecha del argumento1. RIGHT VARCHAR(4000), INTEGER VARCHAR(4000) CLOB(1M), INTEGER CLOB(1M) BLOB(1M), INTEGER BLOB(1M) SYSFUN Devuelve el primer argumento redondeado a argumento2 posiciones a la derecha de la coma decimal. Si argumento2 es negativo, argumento1 se redondea al valor absoluto de argumento2 posiciones a la izquierda de la coma decimal. ROUND INTEGER, INTEGER INTEGER BIGINT, INTEGER BIGINT DOUBLE, INTEGER DOUBLE SYSIBM Devuelve los caracteres del argumento habiendo eliminado los blancos de cola. CHAR VARCHAR RTRIM VARCHAR VARCHAR GRAPHIC VARGRAPHIC VARGRAPHIC VARGRAPHIC SYSFUN Devuelve los caracteres del argumento habiendo eliminado los blancos de cola. RTRIM VARCHAR(4000) VARCHAR(4000) CLOB(1M) CLOB(1M) SYSIBM Devuelve la parte correspondiente a los segundos (unidad-tiempo) de un valor. VARCHAR INTEGER SECOND TIME INTEGER TIMESTAMP INTEGER DECIMAL INTEGER 280 Consulta de SQL, Volumen 1
- 307. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Devuelve un indicador del signo del argumento. Si el argumento es menor que cero, se devuelve -1. Si el argumento es igual a cero, devuelve 0. Si el argumento es mayor que cero, devuelve 1. SMALLINT SMALLINT SIGN INTEGER INTEGER BIGINT BIGINT DOUBLE DOUBLE SYSFUN Devuelve el seno del argumento, donde el argumento es un ángulo SIN expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve el seno hiperbólico del argumento, donde el argumento es SINH un ángulo expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve una representación de entero pequeño de un número. SMALLINT tipo-numérico SMALLINT VARCHAR SMALLINT SYSFUN Devuelve un código de 4 caracteres que representa el sonido de las palabras del argumento. El resultado se puede utilizar para compararlo SOUNDEX con el sonido de otras series. Consulte también DIFFERENCE. VARCHAR(4000) CHAR(4) SYSFUN Devuelve una serie de caracteres que consta de argumento1 espacios en SPACE blanco. INTEGER VARCHAR(4000) SYSFUN Devuelve una tabla de la instantánea de la antememoria de sentencias SQLCACHE_SNAPSHOT de SQL dinámicas de db2 (función de tabla). Vea “SQLCACHE_SNAPSHOT” en la página 571. SYSFUN Devuelve la raíz cuadrada del argumento. SQRT DOUBLE DOUBLE SYSIBM Devuelve la desviación estándar de un conjunto de números (función STDDEV de columna). DOUBLE DOUBLE SYSIBM Devuelve una subserie de una serie argumento1 empezando en el argumento2 de argumento3 caracteres. Si no se especifica el argumento3, se supone el resto de la serie. SUBSTR tipo-serie, INTEGER tipo-serie tipo-serie, INTEGER, INTEGER tipo-serie SYSIBM Devuelve la suma de un conjunto de números (función de columna). SUM 4 1 tipo-numérico tipo-numérico-máx Capítulo 3. Funciones 281
- 308. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve un nombre no calificado de una tabla o vista basado en el nombre de objeto dado en el argumento1 y el nombre de esquema opcional dado en el argumento2. Se utiliza para resolver los TABLE_NAME seudónimos. VARCHAR VARCHAR(128) VARCHAR, VARCHAR VARCHAR(128) SYSIBM Devuelve la parte correspondiente al nombre de esquema del nombre de tabla o vista de dos partes dado por el nombre del objeto del argumento1 y el nombre de esquema opcional del argumento2. Se utiliza TABLE_SCHEMA para resolver los seudónimos. VARCHAR VARCHAR(128) VARCHAR, VARCHAR VARCHAR(128) SYSFUN Devuelve la tangente del argumento, donde el argumento es un ángulo TAN expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve la tangente hiperbólica del argumento, donde el argumento TANH es un ángulo expresado en radianes. DOUBLE DOUBLE SYSIBM Devuelve una hora de un valor. TIME TIME TIME TIMESTAMP TIME VARCHAR TIME SYSIBM Devuelve una indicación de la hora de un valor o de un par de valores. TIMESTAMP TIMESTAMP VARCHAR TIMESTAMP TIMESTAMP VARCHAR, VARCHAR TIMESTAMP VARCHAR, TIME TIMESTAMP DATE, VARCHAR TIMESTAMP DATE, TIME TIMESTAMP SYSIBM Devuelve una indicación de fecha y hora a partir de una serie de caracteres que se ha interpretado utilizando una plantilla de formato TIMESTAMP_FORMAT (argumento2). VARCHAR, VARCHAR TIMESTAMP 282 Consulta de SQL, Volumen 1
- 309. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSFUN Devuelve el valor de una indicación de la hora basado en un argumento de fecha, hora o indicación de la hora. Si el argumento es una fecha, inserta ceros para todos los elementos de hora. Si el argumento es una hora, inserta el valor de CURRENT DATE para los elementos de fecha y ceros para el elemento de fracción de hora. TIMESTAMP_ISO DATE TIMESTAMP TIME TIMESTAMP TIMESTAMP TIMESTAMP VARCHAR(26) TIMESTAMP SYSFUN Devuelve un número estimado de intervalos de tipo argumento1 basado en la diferencia entre dos indicaciones de la hora. El segundo argumento es el resultado de restar los dos tipos de indicación de la hora y convertir el resultado a CHAR. Los valores válidos de intervalo (argumento1) son: 1 Fracciones de segundo 2 Segundos TIMESTAMPDIFF 4 Minutos 8 Horas 16 Días 32 Semanas 64 Meses 128 Trimestres 256 Años INTEGER, CHAR(22) INTEGER SYSIBM Devuelve una representación de caracteres de una indicación de fecha y hora. TO_CHAR Igual que VARCHAR_FORMAT. Igual que VARCHAR_FORMAT. SYSIBM Devuelve una indicación de fecha y hora a partir de una serie de caracteres. TO_DATE Igual que TIMESTAMP_FORMAT. Igual que TIMESTAMP_FORMAT. Capítulo 3. Funciones 283
- 310. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve una serie en la que uno o más caracteres pueden haberse convertido a otros caracteres. CHAR CHAR VARCHAR VARCHAR CHAR, VARCHAR, VARCHAR CHAR VARCHAR, VARCHAR, VARCHAR VARCHAR CHAR, VARCHAR, VARCHAR, VARCHAR CHAR TRANSLATE VARCHAR, VARCHAR, VARCHAR, VARCHAR VARCHAR GRAPHIC, VARGRAPHIC, VARGRAPHIC GRAPHIC VARGRAPHIC, VARGRAPHIC, VARGRAPHIC VARGRAPHIC GRAPHIC, VARGRAPHIC, VARGRAPHIC, GRAPHIC VARGRAPHIC VARGRAPHIC, VARGRAPHIC, VARGRAPHIC, VARGRAPHIC VARGRAPHIC SYSFUN Devuelve el argumento1 truncado a argumento2 posiciones a la derecha de la coma decimal. Si el argumento2 es negativo, el argumento1 se trunca al valor absoluto del argumento2 posiciones a la izquierda de la coma decimal. TRUNC o TRUNCATE INTEGER, INTEGER INTEGER BIGINT, INTEGER BIGINT DOUBLE, INTEGER DOUBLE SYSIBM Devuelve el identificador de tipo de datos interno del tipo de datos 3 dinámico del argumento. Tenga en cuenta que el resultado de esta TYPE_ID función no es portátil a través de las bases de datos. cualquier-tipo-estructurado INTEGER SYSIBM Devuelve el nombre no calificado del tipo de datos dinámico del TYPE_NAME 3 argumento. cualquier-tipo-estructurado VARCHAR(18) SYSIBM Devuelve el nombre de esquema del tipo dinámico del argumento. TYPE_SCHEMA 3 cualquier-tipo-estructurado VARCHAR(128) SYSIBM Devuelve una serie en la que todos los caracteres se han convertido a mayúsculas. UCASE o UPPER CHAR CHAR VARCHAR VARCHAR SYSFUN Devuelve una serie en la que todos los caracteres se han convertido a UCASE mayúsculas. VARCHAR VARCHAR 3 VALUE SYSIBM Igual que COALESCE. 284 Consulta de SQL, Volumen 1
- 311. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Devuelve una representación VARCHAR del primer argumento. Si hay un segundo argumento presente, especifica la longitud del resultado. VARCHAR tipo-caracteres VARCHAR tipo-caracteres, INTEGER VARCHAR tipo-fechahora VARCHAR SYSIBM Devuelve una representación de caracteres de una indicación de fecha y hora (argumento1) con el formato indicado en una plantilla de formato (argumento2). VARCHAR_FORMAT TIMESTAMP, VARCHAR VARCHAR VARCHAR, VARCHAR VARCHAR SYSIBM Devuelve una representación VARGRAPHIC del primer argumento. Si hay un segundo argumento presente, especifica la longitud del resultado. VARGRAPHIC tipo-gráfico VARGRAPHIC tipo-gráfico, INTEGER VARGRAPHIC VARCHAR VARGRAPHIC SYSIBM Devuelve la varianza de un conjunto de números (función de VARIANCE o VAR columna). DOUBLE DOUBLE SYSFUN Devuelve la semana del año del argumento, en forma de valor entero comprendido dentro del rango 1-54. WEEK VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSFUN Devuelve la semana del año del argumento, en forma de valor entero comprendido dentro del rango 1-53. El primer día de la semana es lunes. La semana 1 es la primera semana del año que contendrá un jueves. WEEK_ISO VARCHAR(26) INTEGER DATE INTEGER TIMESTAMP INTEGER SYSIBM Devuelve la parte correspondiente al año de un valor. VARCHAR INTEGER YEAR DATE INTEGER TIMESTAMP INTEGER DECIMAL INTEGER SYSIBM Suma dos operandos numéricos. “+” tipo-numérico, tipo-numérico tipo-numérico máx Capítulo 3. Funciones 285
- 312. Tabla 16. Funciones soportadas (continuación) Nombre de función Esquema Descripción Parámetros de entrada Devuelve SYSIBM Operador más unitario. “+” tipo-numérico tipo-numérico SYSIBM Operador más de fecha y hora. DATE, DECIMAL(8,0) DATE TIME, DECIMAL(6,0) TIME TIMESTAMP, DECIMAL(20,6) TIMESTAMP “+” DECIMAL(8,0), DATE DATE DECIMAL(6,0), TIME TIME DECIMAL(20,6), TIMESTAMP TIMESTAMP tipo-fechahora, DOUBLE, código-duración-etiquetada tipo-fechahora SYSIBM Resta dos operandos numéricos. “−” tipo-numérico, tipo-numérico tipo-numérico máx SYSIBM Operador menos unitario. “−” 1 tipo-numérico tipo-numérico SYSIBM Operador menos de fecha y hora. DATE, DATE DECIMAL(8,0) TIME, TIME DECIMAL(6,0) TIMESTAMP, TIMESTAMP DECIMAL(20,6) DATE, VARCHAR DECIMAL(8,0) TIME, VARCHAR DECIMAL(6,0) TIMESTAMP, VARCHAR DECIMAL(20,6) “−” VARCHAR, DATE DECIMAL(8,0) VARCHAR, TIME DECIMAL(6,0) VARCHAR, TIMESTAMP DECIMAL(20,6) DATE, DECIMAL(8,0) DATE TIME, DECIMAL(6,0) TIME TIMESTAMP, DECIMAL(20,6) TIMESTAMP tipo-fechahora, DOUBLE, código-duración-etiquetada tipo-fechahora SYSIBM Multiplica dos operandos numéricos. “*” tipo-numérico, tipo-numérico tipo-numérico máx SYSIBM Divide dos operadores numéricos. “⁄” tipo-numérico, tipo-numérico tipo-numérico máx “” SYSIBM Igual que CONCAT. 286 Consulta de SQL, Volumen 1
- 313. Notas v En las referencias a tipos de datos de serie que no se califican por una longitud, debe suponerse que dan soporte a la longitud máxima para el tipo de datos. v En las referencias a un tipo de datos DECIMAL sin precisión ni escala, debe suponerse que se permite cualquier precisión y escala soportadas. Claves para la tabla cualquier-tipo-incorporado Cualquier tipo de datos que no sea un tipo diferenciado. cualquier-tipo Cualquier tipo definido en la base de datos. cualquier-tipo-estructurado Cualquier tipo estructurado definido por el usuario que esté definido para la base de datos. cualquier-tipo-comparable Cualquier tipo que sea comparable con otros tipos de argumentos, tal como está definido en “Asignaciones y comparaciones” en la página 126. cualquier-tipo-compatible-unión Cualquier tipo que sea compatible con otros tipos de argumentos, tal como está definido en “Reglas para los tipos de datos del resultado” en la página 145. tipo-caracteres Cualquier tipo de serie de caracteres: CHAR, VARCHAR, LONG VARCHAR, CLOB. tipo-serie-compatible Un tipo de serie que proviene de la misma agrupación que otro argumento (por ejemplo, si un argumento es un tipo-caracteres, el otro también debe ser un tipo-caracteres). tipo-fechahora Cualquier otro tipo de indicación de fecha y hora: DATE, TIME, TIMESTAMP. tipo-numérico-exacto Cualquiera de los tipos numéricos exactos: SMALLINT, INTEGER, BIGINT, DECIMAL tipo-gráfico Cualquier tipo de serie de caracteres de doble byte: GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC, DBCLOB. código-duración-etiquetada Como tipo es un SMALLINT. Si la función se invoca utilizando la forma de infijo del operador más o menos, se pueden utilizar las duraciones-etiquetadas del apartado “Duraciones etiquetadas” en la página 210. En una función fuente que no utilice el carácter de operador de más o menos como el nombre, se deben utilizar los siguientes valores para el argumento código-duración-etiquetada cuando se invoca la función. 1 YEAR o YEARS 2 MONTH o MONTHS 3 DAY o DAYS 4 HOUR o HOURS 5 MINUTE o MINUTES 6 SECOND o SECONDS 7 MICROSECOND o MICROSECONDS tipo-LOB Cualquier tipo de gran objeto: BLOB, CLOB, DBCLOB. tipo-numérico-máx El tipo numérico máximo de los argumentos donde máximo se define como el tipo-numérico más a la derecha. tipo-serie-máx El tipo de serie máximo de los argumentos donde máximo se define como el tipo-caracteres o el tipo-gráfico más a la derecha. Si los argumentos son BLOB, el tipo-serie-máx es BLOB. tipo-numérico Cualquiera de los tipos numéricos: SMALLINT, INTEGER, BIGINT, DECIMAL, REAL, DOUBLE. tipo-serie Cualquier tipo de tipo de caracteres, tipo-gráfico o BLOB. Capítulo 3. Funciones 287
- 314. Notas de la tabla 1 Cuando el parámetro de entrada es SMALLINT, el tipo del resultado es INTEGER. Cuando el parámetro de entrada es REAL, el tipo del resultado es DOUBLE. 2 Las palabras clave permitidas son ISO, USA, EUR, JIS y LOCAL. Esta signatura de función no está soportada como función derivada. 3 Esta función no se puede utilizar como función fuente. 4 Las palabras clave ALL o DISTINCT pueden utilizarse antes del primer parámetro. Si se especifica DISTINCT, no se da soporte a la utilización de tipos estructurados definidos por el usuario, tipos de series largas ni de un tipo DATALINK. 5 No se da soporte a la utilización de tipos estructurados definidos por el usuario, tipos de series largas ni de un tipo DATALINK. 6 El tipo devuelto por RAISE_ERROR depende del contexto de su utilización. RAISE_ERROR, si no hay conversión hacia un tipo determinado, devolverá un tipo adecuado para su invocación en una expresión CASE. 7 No se soporta el uso de tipo-gráfico, tipo-LOB, tipos de serie larga y tipos DATALINK. 288 Consulta de SQL, Volumen 1
- 315. Funciones agregadas El argumento de una función de columna es un conjunto de valores derivados de una expresión. La expresión puede incluir columnas, pero no puede incluir una seleccióncompleta-escalar ni otra función de columna (SQLSTATE 42607). El ámbito del conjunto es un grupo o una tabla resultante intermedia. Si se especifica una cláusula GROUP BY en una consulta y el resultado intermedio de las cláusulas FROM, WHERE, GROUP BY y HAVING es el conjunto vacío, las funciones de columna no se aplican; el resultado de la consulta es el conjunto vacío; el SQLCODE se establece en +100 y el SQLSTATE se establece en ’02000’. Si no se especifica una cláusula GROUP BY en una consulta y el resultado intermedio de las cláusulas FROM, WHERE y HAVING es el conjunto vacío, las funciones de columna se aplican al conjunto vacío. Por ejemplo, el resultado de la siguiente sentencia SELECT es el número de valores diferenciado de JOBCODE para los empleados en el departamento D01: SELECT COUNT(DISTINCT JOBCODE) FROM CORPDATA.EMPLOYEE WHERE WORKDEPT = ’D01’ La palabra clave DISTINCT no se considera un argumento de la función, sino una especificación de una operación que se realiza antes de aplicar la función. Si se especifica DISTINCT, se eliminan los valores duplicados. Si se especifica ALL implícita o explícitamente, no se eliminan los valores duplicados. Se pueden utilizar expresiones en las funciones de columna. Por ejemplo: SELECT MAX(BONUS + 1000) INTO :TOP_SALESREP_BONUS FROM EMPLOYEE WHERE COMM > 5000 Las funciones de columna puede esta calificadas mediante un nombre de esquema (por ejemplo, SYSIBM.COUNT(*)). Conceptos relacionados: v “Consultas” en la página 18 Capítulo 3. Funciones 289
- 316. AVG ALL AVG ( expresión ) DISTINCT El esquema es SYSIBM. La función AVG devuelve el promedio de un conjunto de números. Los valores del argumento deben ser números (sólo tipos internos) y su suma debe estar dentro del rango del tipo de datos del resultado, excepto para un tipo de datos de resultado decimal. Para los resultados decimales, la suma debe estar dentro del rango soportado por un tipo de datos decimal que tenga una precisión de 31 y una escala idéntica a la escala de los valores del argumento. El resultado puede ser nulo. El tipo de datos del resultado es el mismo que el tipo de datos de los valores del argumento, excepto que: v El resultado es un entero grande si los valores del argumento son enteros pequeños. v El resultado es de coma flotante de precisión doble si los valores del argumento son de coma flotante de precisión simple. Si el tipo de datos de los valores del argumento es decimal con la precisión p y la escala s, la precisión del resultado es 31 y la escala es 31-p+s. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si se especifica DISTINCT, se eliminan los valores duplicados redundantes. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es el valor promedio del conjunto. El orden en el que los valores se añaden es indefinido, pero cada resultado intermedio debe estar en el rango del tipo de datos del resultado. Si el tipo del resultado es entero, se pierde la parte correspondiente a la fracción del promedio. Ejemplos: v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal AVERAGE (decimal(5,2)) en el nivel promedio de los trabajadores (PRSTAFF) de los proyectos del departamento (DEPTNO) ’D11’. 290 Consulta de SQL, Volumen 1
- 317. SELECT AVG(PRSTAFF) INTO :AVERAGE FROM PROJECT WHERE DEPTNO = ’D11’ Da como resultado que AVERAGE se establece en 4,25 (es decir 17/4) cuando se utiliza la tabla de ejemplo. v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal ANY_CALC (decimal(5,2)) en el promedio de cada valor de nivel exclusivo de los trabajadores (PRSTAFF) de proyectos del departamento (DEPTNO) ’D11’. SELECT AVG(DISTINCT PRSTAFF) INTO :ANY_CALC FROM PROJECT WHERE DEPTNO = ’D11’ El resultado es que ANY_CALC se establece en 4,66 (es decir 14/3) cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 291
- 318. CORRELATION CORRELATION ( expresión1 , expresión2 ) CORR El esquema es SYSIBM. La función CORRELATION devuelve el coeficiente de correlación de un conjunto de pares de números. Los valores del argumento deben ser números. El tipo de datos del resultado es de coma flotante de precisión doble. El resultado puede ser nulo. Cuando no es nulo, el resultado está entre −1 y 1. La función se aplica al conjunto de pares (expresión1, expresión2) derivado de los valores del argumento por la eliminación de todos los pares para los que expresión1 o expresión2 es nulo. Si la función se aplica a un conjunto vacío o si STDDEV(expresión1) o STDDEV(expresión2) es igual a cero, el resultado es un valor nulo. De lo contrario, el resultado es el coeficiente de correlación para los pares de valores del conjunto. El resultado es equivalente a la expresión siguiente: COVARIANCE(expresión1,expresión2)/ (STDDEV(expresión1)* STDDEV(expresión2)) El orden en el que los valores se agregan no está definido, pero cada resultado intermedio debe estar dentro del rango del tipo de datos del resultado. Ejemplo: v Utilizando la tabla EMPLOYEE, establezca la variable de lenguaje principal CORRLN (coma flotante de precisión doble) en la correlación entre salario y bono para los empleados del departamento (WORKDEPT) ’A00’. SELECT CORRELATION(SALARY, BONUS) INTO :CORRLN FROM EMPLOYEE WHERE WORKDEPT = ’A00’ CORRLN se establece en 9,99853953399538E-001 aproximadamente cuando se utiliza la tabla de ejemplo. 292 Consulta de SQL, Volumen 1
- 319. COUNT ALL COUNT ( expresión ) DISTINCT * El esquema es SYSIBM. La función COUNT devuelve el número de filas o valores de un conjunto de filas o valores. El tipo de datos de expresión no puede ser un LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK, un tipo diferenciado para cualquiera de estos tipos ni un tipo estructurado (SQLSTATE 42907). El resultado de la función es un entero grande. El resultado no puede ser nulo. El argumento de COUNT(*) es un conjunto de filas. El resultado es el número de filas del conjunto. Una fila que sólo incluye valores NULL se incluye en la cuenta. El argumento de COUNT(DISTINCT expresión) es un conjunto de valores. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos y duplicados. El resultado es el número de distintos valores no nulos del conjunto. El argumento de COUNT(expresión) o COUNT(ALL expresión) es un conjunto de valores. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. El resultado es el número de valores no nulos del conjunto, incluyendo los duplicados. Ejemplos: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal FEMALE (int) en el número de filas en que el valor de la columna SEX es ’F’. SELECT COUNT(*) INTO :FEMALE FROM EMPLOYEE WHERE SEX = ’F’ El resultado es que FEMALE se establece en 13 cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 293
- 320. v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal FEMALE_IN_DEPT (int) en el número de departamentos (WORKDEPT) que tienen como mínimo una mujer como miembro. SELECT COUNT(DISTINCT WORKDEPT) INTO :FEMALE_IN_DEPT FROM EMPLOYEE WHERE SEX = ’F’ El resultado es que FEMALE_IN_DEPT se establece en 5 cuando se utiliza la tabla de ejemplo. (Hay como mínimo una mujer en los departamentos A00, C01, D11, D21 y E11.) 294 Consulta de SQL, Volumen 1
- 321. COUNT_BIG ALL COUNT_BIG ( expresión ) DISTINCT * El esquema es SYSIBM. La función COUNT_BIG devuelve el número de filas o valores de un conjunto de filas o valores. Es similar a COUNT excepto que el resultado puede ser mayor que el valor máximo de entero. El tipo de datos resultante de expresión no puede ser un LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK, un tipo diferenciado para cualquiera de estos tipos ni un tipo estructurado (SQLSTATE 42907). El resultado de la función es un decimal con la precisión 31 y la escala 0. El resultado no puede ser nulo. El argumento de COUNT_BIG(*) es un conjunto de filas. El resultado es el número de filas del conjunto. Una fila que sólo incluye valores NULL se incluye en la cuenta. El argumento de COUNT_BIG(DISTINCT expresión) es un conjunto de valores. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos y duplicados. El resultado es el número de distintos valores no nulos del conjunto. El argumento de COUNT_BIG(expresión) o COUNT_BIG(ALL expresión) es un conjunto de valores. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. El resultado es el número de valores no nulos del conjunto, incluyendo los duplicados. Ejemplos: v Consulte los ejemplos de COUNT y sustituya COUNT_BIG por las apariciones de COUNT. Los resultados son los mismos excepto por el tipo de datos del resultado. v Algunas aplicaciones pueden necesitar la utilización de COUNT pero necesitan dar soporte a valores mayores que el entero más grande. Esto se puede conseguir mediante la utilización de funciones derivadas definidas por el usuario y la definición de la vía de acceso de SQL. Las siguientes series de sentencias muestran cómo crear una función derivada para dar soporte a COUNT(*) basándose en COUNT_BIG y devolver un valor Capítulo 3. Funciones 295
- 322. decimal con una precisión de 15. La vía de acceso de SQL se establece de manera que se utilice la función derivada basada en COUNT_BIG en las sentencias subsiguientes, tal como la consulta mostrada. CREATE FUNCTION RICK.COUNT() RETURNS DECIMAL(15,0) SOURCE SYSIBM.COUNT_BIG(); SET CURRENT FUNCTION PATH RICK, SYSTEM PATH; SELECT COUNT(*) FROM EMPLOYEE; Observe que la función derivada se define sin parámetros para dar soporte a COUNT(*). Esto sólo es efectivo si utiliza COUNT como nombre de la función y no califica la función con el nombre de esquema cuando se utiliza. Para conseguir el mismo efecto que COUNT(*) con un nombre distinto de COUNT, invoque la función sin parámetros. Por lo tanto, si RICK.COUNT se ha definido como RICK.MYCOUNT, la consulta se tendría que haber escrito de la siguiente manera: SELECT MYCOUNT() FROM EMPLOYEE; Si la cuenta se efectúa en una columna específica, la función derivada debe especificar el tipo de columna. Las sentencias siguientes crean una función derivada que tomará cualquier columna CHAR como argumento y utilizará COUNT_BIG para realizar el contaje. CREATE FUNCTION RICK.COUNT(CHAR()) RETURNS DOUBLE SOURCE SYSIBM.COUNT_BIG(CHAR()); SELECT COUNT(DISTINCT WORKDEPT) FROM EMPLOYEE; 296 Consulta de SQL, Volumen 1
- 323. COVARIANCE COVARIANCE ( expresión1 , expresión2 ) COVAR El esquema es SYSIBM. La función COVARIANCE devuelve la covarianza (del contenido) de un conjunto de pares de números. Los valores del argumento deben ser números. El tipo de datos del resultado es de coma flotante de precisión doble. El resultado puede ser nulo. La función se aplica al conjunto de pares (expresión1, expresión2) derivado de los valores del argumento por la eliminación de todos los pares para los que expresión1 o expresión2 es nulo. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es la covarianza de los pares de valores del conjunto. El resultado es equivalente a lo siguiente: 1. Establezca que avgexp1 es el resultado de AVG(expresión1) y que avgexp2 es el resultado de AVG(expresión2). 2. El resultado de COVARIANCE(expresión1, expresión2) es AVG( (expresión1 - avgexp1) * (expresión2 - avgexp2 ) El orden en el que los valores se agregan no está definido, pero cada resultado intermedio debe estar dentro del rango del tipo de datos del resultado. Ejemplo: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal COVARNCE (coma flotante de precisión doble) en la covarianza entre salario y bono para los empleados del departamento (WORKDEPT) ’A00’. SELECT COVARIANCE(SALARY, BONUS) INTO :COVARNCE FROM EMPLOYEE WHERE WORKDEPT = ’A00’ COVARNCE se establece en 1,68888888888889E+006 aproximadamente cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 297
- 324. GROUPING GROUPING ( expresión ) El esquema es SYSIBM. Utilizada con conjuntos-agrupaciones y supergrupos, la función GROUPING devuelve un valor que indica si una fila devuelta en un conjunto de respuestas de GROUP BY es una fila generada por un conjunto de agrupaciones que excluye la columna representada por la expresión o no. El argumento puede ser de cualquier tipo, pero debe ser un elemento de una cláusula GROUP BY. El resultado de la función es un entero pequeño. Se establece en uno de los valores siguientes: 1 El valor de la expresión de la fila devuelta es un valor nulo y la fila se ha generado por el supergrupo. Esta fila generada puede utilizarse para proporcionar valores de subtotales para la expresión GROUP BY. 0 El valor no es el de arriba. Ejemplo: La siguiente consulta: SELECT SALES_DATE, SALES_PERSON, SUM(SALES) AS UNITS_SOLD, GROUPING(SALES_DATE) AS DATE_GROUP, GROUPING(SALES_PERSON) AS SALES_GROUP FROM SALES GROUP BY CUBE (SALES_DATE, SALES_PERSON) ORDER BY SALES_DATE, SALES_PERSON da como resultado: SALES_DATE SALES_PERSON UNITS_SOLD DATE_GROUP SALES_GROUP ---------- --------------- ----------- ----------- ----------- 12/31/1995 GOUNOT 1 0 0 12/31/1995 LEE 6 0 0 12/31/1995 LUCCHESSI 1 0 0 12/31/1995 - 8 0 1 03/29/1996 GOUNOT 11 0 0 03/29/1996 LEE 12 0 0 03/29/1996 LUCCHESSI 4 0 0 03/29/1996 - 27 0 1 03/30/1996 GOUNOT 21 0 0 03/30/1996 LEE 21 0 0 03/30/1996 LUCCHESSI 4 0 0 03/30/1996 - 46 0 1 298 Consulta de SQL, Volumen 1
- 325. 03/31/1996 GOUNOT 3 0 0 03/31/1996 LEE 27 0 0 03/31/1996 LUCCHESSI 1 0 0 03/31/1996 - 31 0 1 04/01/1996 GOUNOT 14 0 0 04/01/1996 LEE 25 0 0 04/01/1996 LUCCHESSI 4 0 0 04/01/1996 - 43 0 1 - GOUNOT 50 1 0 - LEE 91 1 0 - LUCCHESSI 14 1 0 - - 155 1 1 Una aplicación puede reconocer una fila de subtotales de SALES_DATE por el hecho de que el valor de DATE_GROUP es 0 y el valor de SALES_GROUP es 1. Una fila de subtotales SALES_PERSON puede reconocerse por el hecho de que el valor de DATE_GROUP es 1 y el valor de SALES_GROUP es 0. Un fila de total general puede reconocerse por el valor 1 de DATE_GROUP y SALES_GROUP. Información relacionada: v “Subselección” en la página 580 Capítulo 3. Funciones 299
- 326. MAX ALL MAX ( expresión ) DISTINCT El esquema es SYSIBM. La función MAX devuelve el valor máximo de un conjunto de valores. Los valores del argumento pueden ser de cualquier tipo interno que no sea una serie larga ni DATALINK. El tipo de datos resultante de expresión no puede ser un LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK, un tipo diferenciado para cualquiera de estos tipos ni un tipo estructurado (SQLSTATE 42907). El tipo de datos, la longitud y la página de códigos del resultado son iguales que el tipo de datos, la longitud y la página de códigos de los valores del argumento. El resultado se considera un valor derivado y puede ser nulo. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es el valor máximo del conjunto. La especificación de DISTINCT no tiene ningún efecto en el resultado y, por lo tanto, no es aconsejable. Se incluye para la compatibilidad con otros sistemas relacionados. Ejemplos: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal MAX_SALARY (decimal(7,2)) en el valor del salario máximo mensual (SALARY/12). SELECT MAX(SALARY) / 12 INTO :MAX_SALARY FROM EMPLOYEE El resultado es que MAX_SALARY se establece en 4395,83 cuando se utiliza esta tabla de ejemplo. v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal LAST_PROJ(char(24)) en el nombre de proyecto (PROJNAME) que es el último en el orden de clasificación. 300 Consulta de SQL, Volumen 1
- 327. SELECT MAX(PROJNAME) INTO :LAST_PROJ FROM PROJECT Da como resultado que LAST_PROJ se establece en ’WELD LINE PLANNING’ cuando se utiliza la tabla de ejemplo. v De manera parecida al ejemplo anterior, establezca la variable del lenguaje principal LAST_PROJ (char(40)) en el nombre del proyecto que es el último en el orden de clasificación cuando se concatena un nombre de proyecto con la variable del lenguaje principal PROJSUPP. PROJSUPP es '_Support'; tiene un tipo de datos char(8). SELECT MAX(PROJNAME CONCAT PROJSUPP) INTO :LAST_PROJ FROM PROJECT Da como resultado que LAST_PROJ se establece en 'WELD LINE PLANNING_SUPPORT' cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 301
- 328. MIN ALL MIN ( expresión ) DISTINCT La función MIN devuelve el valor mínimo de un conjunto de valores. Los valores del argumento pueden ser de cualquier tipo interno que no sea una serie larga ni DATALINK. El tipo de datos resultante de expresión no puede ser un LONG VARCHAR, LONG VARGRAPHIC, BLOB, CLOB, DBCLOB, DATALINK, un tipo diferenciado para cualquiera de estos tipos ni un tipo estructurado (SQLSTATE 42907). El tipo de datos, la longitud y la página de códigos del resultado son iguales que el tipo de datos, la longitud y la página de códigos de los valores del argumento. El resultado se considera un valor derivado y puede ser nulo. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si la función se aplica a un conjunto vacío, el resultado de la función es un valor nulo. De lo contrario, el resultado es el valor mínimo del conjunto. La especificación de DISTINCT no tiene ningún efecto en el resultado y, por lo tanto, no es aconsejable. Se incluye para la compatibilidad con otros sistemas relacionados. Ejemplos: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal COMM_SPREAD (decimal(7,2)) en la diferencia entre la comisión máxima y mínima (COMM) de los miembros del departamento (WORKDEPT) ’D11’. SELECT MAX(COMM) - MIN(COMM) INTO :COMM_SPREAD FROM EMPLOYEE WHERE WORKDEPT = ’D11’ El resultado es que COMM_SPREAD se establece en 1118 (es decir, 2580 - 1462) cuando se utiliza la tabla de ejemplo. v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal (FIRST_FINISHED (char(10)) en la fecha de finalización estimada (PRENDATE) del primer proyecto que se ha de terminar. 302 Consulta de SQL, Volumen 1
- 329. SELECT MIN(PRENDATE) INTO :FIRST_FINISHED FROM PROJECT Da como resultado que FIRST_FINISHED se establece en ’1982-09-15’ cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 303
- 330. Funciones de regresión REGR_AVGX ( expresión1 , expresión2 ) REGR_AVGY REGR_COUNT REGR_INTERCEPT REGR_ICPT REGR_R2 REGR_SLOPE REGR_SXX REGR_SXY REGR_SYY El esquema es SYSIBM. Las funciones de regresión soportan la adecuación de una línea de regresión mínimo-cuadrados-normales del formato y = a * x + b para un conjunto de pares de números. El primer elemento de cada par (expresión1) se interpreta como un valor de la variable dependiente (p. ej., un ″valor y″). El segundo elemento de cada par (expresión2 ) se interpreta como un valor de la variable independiente (p. ej., un ″valor x″). La función REGR_COUNT devuelve el número de pares de números no nulos utilizados para acomodar la línea de regresión (vea más abajo). La función REGR_INTERCEPT (su formato corto es REGR_ICPT) devuelve la intersección y de la línea de regresión (″b″ en la ecuación anterior) La función REGR_R2 devuelve el coeficiente de determinación (llamado también ″cuadrado-R″ o ″mejor-adecuación″) para la regresión. La función REGR_SLOPE devuelve la inclinación de la línea (el parámetro ″a″ de la ecuación anterior). Las funciones REGR_AVGX, REGR_AVGY, REGR_SXX, REGR_SYY y REGR_SXY devuelven cantidades que pueden utilizarse para calcular varias estadísticas de diagnóstico necesarias para la evaluación de la calidad y la validez estadística del modelo de regresión (vea más abajo). Los valores del argumento deben ser números. El tipo de datos del resultado de REGR_COUNT es un entero. Para las demás funciones, el tipo de datos del resultado es de coma flotante de precisión doble. El resultado puede ser nulo. Cuando no es nulo, el resultado de REGR_R2 está entre 0 y 1 y el resultado de REGR_SXX y REGR_SYY no es negativo. 304 Consulta de SQL, Volumen 1
- 331. Cada función se aplica al conjunto de pares (expresión1, expresión2) derivado de los valores del argumento por la eliminación de todos los pares para los que expresión1 o expresión2 es nulo. Si el conjunto no está vacío y VARIANCE(expresión2) es positivo, REGR_COUNT devuelve el número de pares no nulos del conjunto y las demás funciones devuelven los resultados que se definen de la siguiente manera: REGR_SLOPE(expresión1,expresión2) = COVARIANCE(expresión1,expresión2)/VARIANCE(expresión2) REGR_INTERCEPT(expresión1, expresión2) = AVG(expresión1) - REGR_SLOPE(expresión1, expresión2) * AVG(expresión2) REGR_R2(expresión1, expresión2) = POWER(CORRELATION(expresión1, expresión2), 2) if VARIANCE(expresión1)>0 REGR_R2(expresión1, expresión2) = 1 if VARIANCE(expresion1)=0 REGR_AVGX(expresión1, expresión2) = AVG(expresión2) REGR_AVGY(expresión1, expresión2) = AVG(expresión1) REGR_SXX(expresión1, expresión2) = REGR_COUNT(expresión1, expresión2) * VARIANCE(expresión2) REGR_SYY(expresión1, expresión2) = REGR_COUNT(expresión1, expresión2) * VARIANCE(expresión1) REGR_SXY(expresión1, expresión2) = REGR_COUNT(expresión1, expresión2) * COVARIANCE(expresión1, expresión2) Si el conjunto no está vacío y VARIANCE(expresión2) es igual a cero, la línea de regresión tiene una inclinación infinita o no está definida. En este caso, las funciones REGR_SLOPE, REGR_INTERCEPT y REGR_R2 devuelven cada una un valor nulo y las demás funciones devuelven valores tal como se ha definido arriba. Si el conjunto está vacío, REGR_COUNT devuelve cero y las demás funciones devuelven un valor nulo. El orden en el que los valores se agregan no está definido, pero cada resultado intermedio debe estar dentro del rango del tipo de datos del resultado. Las funciones de regresión se calculan simultáneamente durante un solo paso a través de los datos. En general, es más eficaz utilizar las funciones de regresión para calcular las estadísticas necesarias para un análisis de regresión que realizar cálculos equivalentes utilizando las funciones normales de columna como AVERAGE, VARIANCE, COVARIANCE, etcétera. Las estadísticas de diagnóstico normales que acompañan a un análisis de regresión-lineal se pueden calcular en términos de las funciones anteriores. Por ejemplo: R2 ajustada 1 - ( (1 - REGR_R2) * ((REGR_COUNT - 1) / (REGR_COUNT - 2)) ) Capítulo 3. Funciones 305
- 332. Error estándar SQRT( (REGR_SYY- (POWER(REGR_SXY,2)/REGR_SXX))/(REGR_COUNT-2) ) Suma total de cuadrados REGR_SYY Suma de cuadrados de regresión POWER(REGR_SXY,2) / REGR_SXX Suma de cuadrados residuales (Suma total de cuadrados)-(Suma de cuadrados de regresión) t estadística de inclinación REGR_SLOPE * SQRT(REGR_SXX) / (Error estándar) t estadística para intersección y REGR_INTERCEPT/((Error estándar)*SQRT((1/REGR_COUNT)+ (POWER(REGR_AVGX,2)/REGR_SXX)) Ejemplo: v Utilizando la tabla EMPLOYEE, calcule la línea de regresión de cuadrados-mínimos-normales que expresa el bono de un empleado del departamento (WORKDEPT) ’A00’ como una función lineal del salario del empleado. Establezca las variables del lenguaje principal SLOPE, ICPT, RSQR (coma flotante de precisión doble) en la inclinación, intersección y coeficiente de determinación de la línea de regresión, respectivamente. Establezca también las variables del lenguaje principal AVGSAL y AVGBONUS en el salario promedio y el bono promedio, respectivamente, de los empleados del departamento ’A00’, y establezca la variable del lenguaje principal CNT (entero) en el número de empleados del departamento ’A00’ para los que están disponibles los datos de salario y de bono. Almacene las demás estadísticas de regresión en las variables del lenguaje principal SXX, SYY y SXY. SELECT REGR_SLOPE(BONUS,SALARY), REGR_INTERCEPT(BONUS,SALARY), REGR_R2(BONUS,SALARY), REGR_COUNT(BONUS,SALARY), REGR_AVGX(BONUS,SALARY), REGR_AVGY(BONUS,SALARY), REGR_SXX(BONUS,SALARY), REGR_SYY(BONUS,SALARY), REGR_SXY(BONUS,SALARY) INTO :SLOPE, :ICPT, :RSQR, :CNT, :AVGSAL, :AVGBONUS, :SXX, :SYY, :SXY FROM EMPLOYEE WHERE WORKDEPT = ’A00’ Al utilizar la tabla de ejemplo, las variables del lenguaje principal se establecen en los siguientes valores aproximados: 306 Consulta de SQL, Volumen 1
- 333. SLOPE: +1.71002671916749E-002 ICPT: +1.00871888623260E+002 RSQR: +9.99707928128685E-001 CNT: 3 AVGSAL: +4.28333333333333E+004 AVGBONUS: +8.33333333333333E+002 SXX: +2.96291666666667E+008 SYY: +8.66666666666667E+004 SXY: +5.06666666666667E+006 Capítulo 3. Funciones 307
- 334. STDDEV ALL STDDEV ( expresión ) DISTINCT El esquema es SYSIBM. La función STDDEV devuelve la desviación estándar de un conjunto de números. Los valores del argumento deben ser números. El tipo de datos del resultado es de coma flotante de precisión doble. El resultado puede ser nulo. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si se especifica DISTINCT, se eliminan los valores duplicados redundantes. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es la desviación estándar de los valores del conjunto. El orden en el que los valores se agregan no está definido, pero cada resultado intermedio debe estar dentro del rango del tipo de datos del resultado. Ejemplo: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal DEV (coma flotante de precisión doble) en la desviación estándar de los salarios para los empleados del departamento (WORKDEPT) ’A00’. SELECT STDDEV(SALARY) INTO :DEV FROM EMPLOYEE WHERE WORKDEPT = ’A00’ Da como resultado que DEV se establece en 9938,00 aproximadamente cuando se utiliza la tabla de ejemplo. 308 Consulta de SQL, Volumen 1
- 335. SUM ALL SUM ( expresión ) DISTINCT El esquema es SYSIBM. La función SUM devuelve la suma de un conjunto de números. Los valores del argumento deben ser números (sólo tipos internos) y su suma debe estar dentro del rango del tipo de datos del resultado. El tipo de datos del resultado es el mismo que el tipo de datos de los valores del argumento excepto que: v El resultado es un entero grande si los valores del argumento son enteros pequeños. v El resultado es de coma flotante de precisión doble si los valores del argumento son de coma flotante de precisión simple. Si el tipo de datos de los valores del argumento es decimal, la precisión del resultado es 31 y la escala es la misma que la de los valores del argumento. El resultado puede ser nulo. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si se especifica DISTINCT, también se eliminan los valores duplicados redundantes. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es la suma de los valores del conjunto. Ejemplo: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal JOB_BONUS (decimal(9,2)) en el total de bonificaciones (BONUS) pagadas a los conserjes (JOB=’CLERK’). SELECT SUM(BONUS) INTO :JOB_BONUS FROM EMPLOYEE WHERE JOB = ’CLERK’ El resultado es que JOB_BONUS se establece en 2800 cuando se utiliza la tabla de ejemplo. Capítulo 3. Funciones 309
- 336. VARIANCE ALL VARIANCE ( expresión ) VAR DISTINCT El esquema es SYSIBM. La función VARIANCE devuelve la varianza de un conjunto de números. Los valores del argumento deben ser números. El tipo de datos del resultado es de coma flotante de precisión doble. El resultado puede ser nulo. La función se aplica al conjunto de valores derivados de los valores del argumento por la eliminación de los valores nulos. Si se especifica DISTINCT, se eliminan los valores duplicados redundantes. Si la función se aplica a un conjunto vacío, el resultado es un valor nulo. De lo contrario, el resultado es la varianza de los valores del conjunto. El orden en el que los valores se añaden es indefinido, pero cada resultado intermedio debe estar en el rango del tipo de datos del resultado. Ejemplo: v Utilizando la tabla EMPLOYEE, establezca la variable del lenguaje principal VARNCE (coma flotante de precisión doble) en la varianza de los salarios para los empleados del departamento (WORKDEPT) ’A00’. SELECT VARIANCE(SALARY) INTO :VARNCE FROM EMPLOYEE WHERE WORKDEPT = ’A00’ Da como resultado que VARNCE se establece en 98763888,88 aproximadamente cuando se utiliza la tabla de ejemplo. 310 Consulta de SQL, Volumen 1
- 337. Funciones escalares Una función escalar se puede utilizar siempre que se pueda utilizar una expresión. Sin embargo, las restricciones que se aplican a la utilización de expresiones y a las funciones de columna también se aplican cuando se utiliza una expresión o una función de columna en una función escalar. Por ejemplo, el argumento de una función escalar sólo puede ser una función de columna si está permitida una función de columna en el contexto en el que se utiliza la función escalar. Las restricciones en la utilización de funciones de columna no se aplican a las funciones escalares, porque una función escalar se aplica a un solo valor en lugar de a un conjunto de valores. El resultado de la siguiente sentencia SELECT contiene un mismo número de filas igual al número de empleados que hay en el departamento D01: SELECT EMPNO, LASTNAME, YEAR(CURRENT DATE - BRTHDATE) FROM EMPLOYEE WHERE WORKDEPT = ’D01’ Las funciones escalares puede esta calificadas mediante un nombre de esquema (por ejemplo, SYSIBM.CHAR(123)). En una base de datos Unicode, todas las funciones escalares que acepten una serie de caracteres o gráfica aceptarán todos los tipos de serie para los que se soporte la conversión. Capítulo 3. Funciones 311
- 338. ABS o ABSVAL ABS ( expresión ) ABSVAL El esquema es SYSIBM. Esta función está disponible por primera vez en el FixPak 2 de la Versión 7.1. La versión SYSFUN de la función ABS (o ABSVAL) continúa estando disponible. Devuelve el valor absoluto del argumento. El argumento puede ser de cualquier tipo de datos numérico interno. El resultado tiene el mismo tipo de datos y el mismo atributo de longitud que el argumento. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el argumento es el valor negativo máximo para SMALLINT, INTEGER o BIGINT, el resultado es un error de desbordamiento. Ejemplo: ABS(-51234) devuelve un INTEGER con un valor de 51234. 312 Consulta de SQL, Volumen 1
- 339. ACOS ACOS ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función ACOS continúa estando disponible). Devuelve el coseno del arco del argumento como un ángulo expresado en radianes. El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. Ejemplo: Suponga que la variable del lenguaje principal ACOSINE es una variable del lenguaje principal DECIMAL(10,9) con un valor de 0,070737202. SELECT ACOS(:ACOSINE) FROM SYSIBM.SYSDUMMY1 Esta sentencia devuelve el valor aproximado1,49. Capítulo 3. Funciones 313
- 340. ASCII ASCII ( expresión ) El esquema es SYSFUN. Devuelve el valor de código ASCII del carácter situado más a la izquierda del argumento como un entero. El argumento puede ser de cualquier tipo de serie de caracteres interno. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB la longitud máxima es de 1.048.576 bytes. LONG VARCHAR se convierte a CLOB para que lo procese la función. El resultado de la función siempre es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 314 Consulta de SQL, Volumen 1
- 341. ASIN ASIN ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función ASIN continúa estando disponible). Devuelve el seno del arco del argumento como un ángulo expresado en radianes. El argumento puede ser de cualquier tipo numérico interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. Capítulo 3. Funciones 315
- 342. ATAN ATAN ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función ATAN continúa estando disponible). Devuelve la tangente del arco del argumento como un ángulo expresado en radianes. El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. 316 Consulta de SQL, Volumen 1
- 343. ATAN2 ATAN2 ( expresión , expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función ATAN2 continúa estando disponible). Devuelve la tangente del arco de las coordenadas x e y como un ángulo expresado en radianes. Las coordenadas x e y se especifican por el primer y el segundo argumento, respectivamente. El primer argumento y el segundo pueden ser de cualquier tipo de datos numérico interno. Los dos se convierten a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. Capítulo 3. Funciones 317
- 344. ATANH ATANH ATANH ( expresión ) El esquema es SYSIBM. Devuelve la arcotangente hiperbólica del argumento, donde el argumento es un ángulo expresado en radianes. El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. 318 Consulta de SQL, Volumen 1
- 345. BIGINT BIGINT ( expresión-numérica ) expresión-caracteres expresión-fechahora El esquema es SYSIBM. La función BIGINT devuelve una representación entera de 64 bits de un número, serie de caracteres, fecha, hora o indicación de fecha y hora en forma de una constante entera. expresión-numérica Una expresión que devuelve un valor de cualquier tipo de datos numérico interno. Si el argumento es una expresión-numérica, el resultado es el mismo número que sería si el argumento se asignase a una columna o variable de enteros superiores. Si la parte correspondiente a los enteros del argumento no está dentro del rango de enteros, se produce un error. La parte correspondiente a los decimales del argumento se trunca si está presente. expresión-caracteres Una expresión que devuelve un valor de serie de caracteres de longitud no mayor que la longitud máxima de una constante de caracteres. Se eliminan los blancos iniciales y de cola y la serie resultante debe ajustarse a las reglas para la formación de una constante de enteros SQL (SQLSTATE 22018). La serie de caracteres no puede ser una serie larga. Si el argumento es una expresión-caracteres, el resultado es el mismo número que sería si la constante de enteros correspondiente se asignase a una columna o variable de enteros superiores. expresión-fechahora Una expresión que sea uno de los tipos de datos siguientes: v DATE. El resultado es un valor BIGINT que representa la fecha como aaaammdd. v TIME. El resultado es un valor BIGINT que representa la hora como hhmmss. v TIMESTAMP. El resultado es un valor BIGINT que representa la indicación de fecha y hora como aaaammddhhmmss. La parte de los microsegundos del valor de indicación de fecha y hora no se incluye en el resultado. El resultado de la función es un entero superior. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 319
- 346. Ejemplos: v En la tabla ORDERS_HISTORY, cuente el número de órdenes y devuelva el resultado como un valor de entero superior. SELECT BIGINT (COUNT_BIG(*)) FROM ORDERS_HISTORY v Utilizando la tabla EMPLOYEE, seleccione la columna EMPNO en el formato de enteros superiores para procesarla más en la aplicación. SELECT BIGINT (EMPNO) FROM EMPLOYEE v Suponga que la columna RECEIVED (indicación de fecha y hora) tiene un valor interno equivalente a ’1988-12-22-14.07.21.136421’. BIGINT(RECEIVED) da como resultado el valor 19 881 222 140 721. v Suponga que la columna STARTTIME (hora) tiene un valor interno equivalente a ’12:03:04’. BIGINT(STARTTIME) da como resultado el valor 120 304. 320 Consulta de SQL, Volumen 1
- 347. BLOB BLOB ( expresión-serie ) , entero El esquema es SYSIBM. La función BLOB devuelve una representación BLOB de una serie de cualquier tipo. expresión-serie Una expresión-serie cuyo valor puede ser una serie de caracteres, una serie gráfica o una serie binaria. entero Un valor entero que especifica el atributo de longitud del tipo de datos BLOB resultante. Si no se especifica entero, el atributo de longitud del resultado es el mismo que la longitud de la entrada, excepto cuando la entrada es gráfica. En este caso, el atributo de longitud del resultado es el doble de la longitud de la entrada. El resultado de la función es un BLOB. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplos v Suponiendo una tabla con una columna BLOB denominada TOPOGRAPHIC_MAP y una columna VARCHAR denominada MAP_NAME, localice los mapas que contienen la serie ’Pellow Island’ y devuelva una sola serie binaria con el nombre del mapa concatenado delante del mapa real. SELECT BLOB(MAP_NAME || ’: ’) || TOPOGRAPHIC_MAP FROM ONTARIO_SERIES_4 WHERE TOPOGRAPHIC_MAP LIKE BLOB(’%Pellow Island%’) Capítulo 3. Funciones 321
- 348. CEILING o CEIL CEILING ( expresión ) CEIL El esquema es SYSIBM. (La versión SYSFUN de la función CEILING o CEIL continúa estando disponible). Devuelve el valor del entero más pequeño que es mayor o igual que el argumento. El argumento puede ser de cualquier tipo numérico interno. El resultado de la función tiene el mismo tipo de datos y el mismo atributo de longitud que el argumento, con la excepción de que la escala es 0 si el argumento es DECIMAL. Por ejemplo, un argumento con un tipo de datos de DECIMAL(5,5) devuelve DECIMAL(5,0). El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. 322 Consulta de SQL, Volumen 1
- 349. CHAR De fecha y hora a caracteres : CHAR ( expresión-fechahora ) , ISO USA EUR JIS LOCAL De caracteres a caracteres : CHAR ( expresión-caracteres ) , entero De entero a carácter: CHAR ( expresión-entero ) De decimal a carácter: CHAR ( expresión-decimal ) , carácter-decimal De coma flotante a caracteres: CHAR ( expresión-coma-flotante ) , carácter-decimal El esquema es SYSIBM. La signatura SYSFUN.CHAR(expresión-coma-flotante) continúa estando disponible. En este caso, el carácter decimal es sensible la configuración local y, por lo tanto, devuelve un punto o una coma, dependiendo del idioma del servidor de la base de datos. La función CHAR devuelve una representación de serie de caracteres de longitud fija de: v Un valor de fecha y hora, si el primer argumento es una fecha, una hora o una indicación de fecha y hora v Una serie de caracteres, si el primer argumento es cualquier tipo de serie de caracteres v Un número entero, si el primer argumento es SMALLINT, INTEGER o BIGINT Capítulo 3. Funciones 323
- 350. v Un número decimal, si el primer argumento es un número decimal v Un número de coma flotante de precisión doble, si el primer argumento es DOUBLE o REAL. El primer argumento debe ser de un tipo de datos interno. Nota: La expresión CAST también se puede utilizar para devolver una expresión-serie. El resultado de la función es una serie de caracteres de longitud fija. Si el primer argumento puede ser nulo, el resultado puede ser nulo. Si el primer argumento es nulo, el resultado es el valor nulo. De fecha y hora a caracteres expresión-fechahora Una expresión que es de uno de los tres tipos de datos siguientes fecha El resultado es la representación de serie de caracteres de la fecha en el formato especificado por el segundo argumento. La longitud del resultado es 10. Se produce un error si se especifica el segundo argumento y no es un valor válido (SQLSTATE 42703). hora El resultado es la representación de serie de caracteres de la hora en el formato especificado por el segundo argumento. La longitud del resultado es 8. Se produce un error si se especifica el segundo argumento y no es un valor válido (SQLSTATE 42703). indicación de fecha y hora El segundo argumento no es aplicable y no se debe especificar (SQLSTATE 42815). El resultado es la representación de serie de caracteres de la indicación de fecha y hora. La longitud del resultado es 26. La página de códigos de la serie es la página de códigos de la base de datos en el servidor de aplicaciones. De caracteres a caracteres expresión-caracteres Una expresión que devuelve un valor que es de un tipo de datos CHAR, VARCHAR, LONG VARCHAR o CLOB. entero el atributo de longitud para la serie de caracteres de longitud fija resultante. El valor debe estar entre 0 y 254. 324 Consulta de SQL, Volumen 1
- 351. Si la longitud de la expresión-caracteres es menor que el atributo de longitud del resultado, el resultado se rellena con blancos hasta la longitud del resultado. Si la longitud de la expresión-caracteres es mayor que el atributo de longitud del resultado, se lleva a cabo un truncamiento. Se devuelve un error (SQLSTATE 01004) a menos que todos los caracteres truncados sean blancos y la expresión-caracteres no fuese una serie larga (LONG VARCHAR o CLOB). De entero a carácter expresión-entero Una expresión que devuelve un valor que es de un tipo de datos entero (SMALLINT, INTEGER o BIGINT). El resultado es la representación de serie de caracteres del argumento en el formato de una constante de enteros de SQL. El resultado consta de n caracteres que son dígitos significativos que representan el valor del argumento con un signo menos que lo precede si el argumento es negativo. Se justifica por la izquierda. v Si el primer argumento es un entero pequeño: La longitud del resultado es 6. Si el número de caracteres del resultado es menor que 6, entonces el resultado se rellena por la derecha con blancos hasta la longitud de 6. v Si el primer argumento es un entero grande: La longitud del resultado es 11. Si el número de caracteres del resultado es menor que 11, entonces el resultado se rellena por la derecha con blancos hasta la longitud de 11. v Si el primer argumento es un entero superior: La longitud del resultado es 20. Si el número de caracteres del resultado es menor que 20, el resultado se rellena por la derecha con blancos hasta la longitud de 20. La página de códigos de la serie es la página de códigos de la base de datos en el servidor de aplicaciones. De decimal a carácter expresión-decimal Una expresión que devuelve un valor que es de un tipo de datos decimal. Si se desean una precisión y escala diferentes, puede utilizarse primero la función escalar DECIMAL para realizar el cambio. carácter-decimal Especifica la constante de caracteres de un solo byte que se utiliza para delimitar los dígitos decimales en la serie de caracteres del resultado. El carácter no puede ser un dígito, el signo más (’+’), el Capítulo 3. Funciones 325
- 352. signo menos (’-’) ni un espacio en blanco (SQLSTATE 42815). El valor por omisión es el carácter punto (’.’). El resultado es la representación de serie de caracteres de longitud fija del argumento. El resultado incluye un carácter decimal y p dígitos, donde p es la precisión de la expresión-decimal con un signo menos precedente si el argumento es negativo. La longitud del resultado es 2+p, donde p es la precisión de la expresión-decimal. Esto significa que un valor positivo siempre incluirá un blanco de cola. La página de códigos de la serie es la página de códigos de la base de datos en el servidor de aplicaciones. De coma flotante a caracteres expresión-coma-flotante Una expresión que devuelve un valor que es de un tipo de datos de coma flotante (DOUBLE o REAL). carácter-decimal Especifica la constante de caracteres de un solo byte que se utiliza para delimitar los dígitos decimales en la serie de caracteres del resultado. El carácter no puede ser un dígito, el signo más (+), el signo menos (−) ni un espacio en blanco (SQLSTATE 42815). El valor por omisión es el carácter punto (.). El resultado es la representación de serie de caracteres de longitud fija del argumento en la forma de una constante de coma flotante. La longitud del resultado es 24. Si el argumento es negativo, el primer carácter del resultado es un signo menos. De lo contrario, el primer carácter es un dígito. Si el valor del argumento es cero, el resultado es 0E0. De lo contrario, el resultado incluye el número más pequeño de caracteres que puedan representar el valor del argumento de tal modo que la mantisa conste de un solo dígito distinto de cero seguido del carácter-decimal y una secuencia de dígitos. Si el número de caracteres del resultado es menor que 24, el resultado se rellena por la derecha con blancos hasta la longitud de 24. La página de códigos de la serie es la página de códigos de la base de datos en el servidor de aplicaciones. Ejemplos: v Supongamos que la columna PRSTDATE tiene un valor interno equivalente a 1988-12-25. CHAR(PRSTDATE, USA) Da como resultado el valor ‘12/25/1988’. 326 Consulta de SQL, Volumen 1
- 353. v Suponga que la columna STARTING tiene un valor interno equivalente a 17:12:30, la variable del lenguaje principal HOUR_DUR (decimal(6,0)) es una duración en horas con un valor de 050000, (es decir, 5 horas). CHAR(STARTING, USA) Da como resultado el valor ’5:12 PM’. CHAR(STARTING + :HOUR_DUR, USA) Da como resultado el valor ’10:12 PM’. v Suponga que la columna RECEIVED (indicación de fecha y hora) tiene un valor interno equivalente a la combinación de las columnas PRSTDATE y STARTING. CHAR(RECEIVED) Da como resultado el valor ‘1988-12-25-17.12.30.000000’. v Utilice la función CHAR para que el tipo sea de caracteres de longitud fija y para reducir la longitud de los resultados visualizados a 10 caracteres para la columna LASTNAME (definido como VARCHAR(15)) de la tabla EMPLOYEE. SELECT CHAR(LASTNAME,10) FROM EMPLOYEE Para filas que tengan LASTNAME con una longitud mayor que 10 caracteres (excluyendo los blancos de cola), se devuelve un aviso de que el valor se ha truncado. v Utilice la función CHAR para devolver los valores para EDLEVEL (definido como smallint) como una serie de caracteres de longitud fija. SELECT CHAR(EDLEVEL) FROM EMPLOYEE Un EDLEVEL de 18 se devolvería como el valor CHAR(6) ’18 ’ (18 seguido de cuatro blancos). v Suponga que STAFF tiene una columna SALARY definida como decimal con la precisión 9 y la escala 2. El valor actual es 18357.50 y se debe visualizar con una coma decimal (18357,50). CHAR(SALARY, ’,’) devuelve el valor ’00018357,50’. v Suponga que la misma columna SALARY que se resta de 20000.25 se ha de visualizar con el carácter decimal por omisión. CHAR(20000.25 - SALARY) devuelve el valor ’-0001642.75’. v Suponga que la variable del lenguaje principal, SEASONS_TICKETS, tiene un tipo de datos entero y un valor 10000. Capítulo 3. Funciones 327
- 354. CHAR(DECIMAL(:SEASONS_TICKETS,7,2)) Da como resultado el valor de caracteres ’10000.00 ’. v Suponga una variable del lenguaje principal, DOUBLE_NUM, que tiene un tipo de datos doble y un valor de -987.654321E-35. CHAR(:DOUBLE_NUM) Da como resultado el valor de caracteres ’-9.87654321E-33 ’. Como el tipo de datos del resultado es CHAR(24), hay 9 blancos de cola en el resultado. Información relacionada: v “Expresiones” en la página 202 328 Consulta de SQL, Volumen 1
- 355. CHR CHR ( expresión ) El esquema es SYSFUN. Devuelve el carácter que tiene el valor del código ASCII especificado por el argumento. El argumento puede ser INTEGER o SMALLINT. El valor del argumento debe estar entre 0 y 255; de lo contrario, el valor de retorno es nulo. El resultado de la función es CHAR(1). El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 329
- 356. CLOB CLOB ( expresión-serie-caracteres ) , entero El esquema es SYSIBM. La función CLOB devuelve una representación CLOB de un tipo de serie de caracteres. expresión-serie-caracteres Una expresión que devuelve un valor que es una serie de caracteres. entero Un valor entero que especifica el atributo de longitud del tipo de datos CLOB resultante. El valor debe estar entre 0 y 2 147 483 647. Si no se especifica entero, la longitud del resultado es la misma que la longitud del primer argumento. El resultado de la función es CLOB. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 330 Consulta de SQL, Volumen 1
- 357. COALESCE (1) COALESCE ( expresión , expresión ) Notas: 1 VALUE es sinónimo de COALESCE. El esquema es SYSIBM. COALESCE devuelve el primer argumento que no es nulo. Los argumentos se evalúan en el orden en que se especifican, y el resultado de la función es el primer argumento que no es nulo. El resultado sólo puede ser nulo si todos los argumentos pueden ser nulos, y el resultado sólo es nulo si todos los argumentos son nulos. El argumento seleccionado se convierte, si es necesario, a los atributos del resultado. Los argumentos deben ser compatibles. Puede ser de un tipo de datos interno o definido por el usuario. (Esta función no puede utilizarse como una función fuente cuando se crea una función definida por el usuario. Como esta función acepta cualquier tipo de datos compatible como argumento, no es necesario crear signaturas adicionales para dar soporte a los tipos de datos diferenciados definidos por el usuario). Ejemplos: v Cuando se seleccionan todos los valores de todas las filas de la tabla DEPARTMENT, si falta el director del departamento (MGRNO) (es decir, es nulo), se ha de devolver un valor de ’ABSENT’. SELECT DEPTNO, DEPTNAME, COALESCE(MGRNO, ’ABSENT’), ADMRDEPT FROM DEPARTMENT v Cuando se selecciona el número de empleado (EMPNO) y el salario (SALARY) de todas las filas de la tabla EMPLOYEE, si falta el salario (es decir, es nulo), se ha de devolver un valor de cero. SELECT EMPNO, COALESCE(SALARY, 0) FROM EMPLOYEE Información relacionada: v “Reglas para los tipos de datos del resultado” en la página 145 Capítulo 3. Funciones 331
- 358. CONCAT (1) CONCAT ( expresión1 , expresión2 ) Notas: 1 || se utiliza como sinónimo de CONCAT. El esquema es SYSIBM. Devuelve la concatenación de dos argumentos de serie. Los dos argumentos deben ser de tipos compatibles. El resultado de la función es una serie. La longitud es la suma de las longitudes de los dos argumentos. Si cualquier argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Información relacionada: v “Expresiones” en la página 202 332 Consulta de SQL, Volumen 1
- 359. COS COS ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función COS continúa estando disponible). Devuelve el coseno del argumento, donde el argumento es un ángulo expresado en radianes. El argumento puede ser de cualquier tipo numérico interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. Capítulo 3. Funciones 333
- 360. COSH COSH ( expresión ) El esquema es SYSIBM. Devuelve el coseno hiperbólico del argumento, donde el argumento es un ángulo expresado en radianes. El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. 334 Consulta de SQL, Volumen 1
- 361. COT COT ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función COT continúa estando disponible). Devuelve la cotangente del argumento, donde el argumento es un ángulo expresado en radianes. El argumento puede ser de cualquier tipo numérico interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. Capítulo 3. Funciones 335
- 362. DATE DATE ( expresión ) El esquema es SYSIBM. La función DATE devuelve una fecha de un valor. El argumento debe ser una fecha, indicación de fecha y hora, número positivo menor o igual que 3 652 059, representación de serie válida de una fecha o una indicación de fecha y hora o una serie de longitud 7 que no sea CLOB, LONG VARCHAR ni LONG VARGRAPHIC. Sólo las bases de datos Unicode dan soporte a un argumento que es una representación de serie gráfica de una fecha o una indicación de fecha y hora. Si el argumento es una serie de longitud 7, debe representar una fecha válida en el formato aaaannn, donde aaaa son los dígitos que indican el año y nnn los son dígitos entre 001 y 366, que indican un día de dicho año. El resultado de la función es una fecha. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una fecha, una indicación de fecha y hora o una representación válida de una fecha o indicación de fecha y hora en forma de serie: – El resultado es la parte correspondiente a la fecha del valor. v Si el argumento es un número: – El resultado es la fecha de n-1 días después de 1 de enero de 0001, donde n es la parte integral del número. v Si el argumento es una serie con una longitud de 7: – El resultado es la fecha representada por la serie. Ejemplos: Suponga que la columna RECEIVED (indicación de fecha y hora) tiene un valor interno equivalente a ‘1988-12-25-17.12.30.000000’. v Este ejemplo da como resultado una representación interna de ‘1988-12-25’. DATE(RECEIVED) v Este ejemplo da como resultado una representación interna de ‘1988-12-25’. DATE(’1988-12-25’) 336 Consulta de SQL, Volumen 1
- 363. v Este ejemplo da como resultado una representación interna de ‘1988-12-25’. DATE(’25.12.1988’) v Este ejemplo da como resultado una representación interna de ‘0001-02-04’. DATE(35) Capítulo 3. Funciones 337
- 364. DAY DAY ( expresión ) El esquema es SYSIBM. La función DAY devuelve la parte correspondiente al día de un valor. El argumento debe ser una fecha, una indicación de fecha y hora, una duración de fecha, una duración de indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una fecha, una indicación de fecha y hora o una representación válida de una fecha o indicación de fecha y hora en forma de serie: – El resultado es la parte correspondiente al día del valor, que es un entero entre 1 y 31. v Si el argumento es una duración de fecha o duración de indicación de fecha y hora: – El resultado es la parte correspondiente al día del valor, que es un entero entre −99 y 99. El resultado que no es cero tiene el mismo signo que el argumento. Ejemplos: v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal END_DAY (smallint) en el día en que está planificado que el proyecto WELD LINE PLANNING (PROJNAME) finalice (PRENDATE). SELECT DAY(PRENDATE) INTO :END_DAY FROM PROJECT WHERE PROJNAME = ’WELD LINE PLANNING’ Da como resultado que END_DAY se establece en 15 cuando se utiliza la tabla de ejemplo. v Supongamos que la columna DATE1 (fecha) tiene un valor interno equivalente a 2000-03-15 y la columna DATE2 (fecha) tiene un valor interno equivalente a 1999-12-31. DAY(DATE1 - DATE2) 338 Consulta de SQL, Volumen 1
- 365. Da como resultado el valor 15. Capítulo 3. Funciones 339
- 366. DAYNAME DAYNAME ( expresión ) El esquema es SYSFUN. Devuelve una serie de caracteres en mayúsculas y minúsculas mezcladas que contienen el nombre del día (p. ej., Viernes) para la parte del día del argumento basándose en el entorno nacional del momento en que se ha iniciado la base de datos. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es VARCHAR(100). El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 340 Consulta de SQL, Volumen 1
- 367. DAYOFWEEK DAYOFWEEK ( expresión ) Devuelve el día de la semana del argumento como un valor entero en el rango de 1 a 7, donde 1 representa el Domingo. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o de una indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 341
- 368. DAYOFWEEK_ISO DAYOFWEEK_ISO ( expresión ) El esquema es SYSFUN. Devuelve el día de la semana del argumento, en forma de valor entero comprendido dentro del rango 1-7, donde 1 representa el lunes. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o de una indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 342 Consulta de SQL, Volumen 1
- 369. DAYOFYEAR DAYOFYEAR ( expresión ) El esquema es SYSFUN. Devuelve el día del año del argumento como un valor entero en el rango de 1 a 366. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 343
- 370. >DAYS DAYS ( expresión ) El esquema es SYSIBM. La función DAYS devuelve una representación de entero de una fecha. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. El resultado es 1 más que el número de días desde el 1 de enero de 0001 hasta D, donde D es la fecha que podría darse si se aplicase la función DATE al argumento. Ejemplos: v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal EDUCATION_DAYS (int) en el número de días transcurridos (PRENDATE - PRSTDATE) estimados para el proyecto (PROJNO) ‘IF2000’. SELECT DAYS(PRENDATE) - DAYS(PRSTDATE) INTO :EDUCATION_DAYS FROM PROJECT WHERE PROJNO = ’IF2000’ El resultado de EDUCATION_DAYS se define en 396. v Utilizando la tabla PROJECT, establezca la variable del lenguaje principal TOTAL_DAYS (int) en la suma de los días transcurridos (PRENDATE - PRSTDATE) estimados para todos los proyectos del departamento (DEPTNO) ‘E21’. SELECT SUM(DAYS(PRENDATE) − DAYS(PRSTDATE)) INTO :TOTAL_DAYS FROM PROJECT WHERE DEPTNO = ’E21’ Da como resultado que TOTAL_DAYS se establece en 1584 cuando se utiliza la tabla de ejemplo. 344 Consulta de SQL, Volumen 1
- 371. DBCLOB DBCLOB ( expresión-gráfica ) , entero El esquema es SYSIBM. La función DBCLOB devuelve una representación DBCLOB de un tipo de serie gráfica. expresión-gráfica Una expresión que devuelve un valor que es una serie gráfica. entero Un valor entero que especifica el atributo de longitud del tipo de datos DBCLOB resultante. El valor debe estar entre 0 y 1 073 741 823. Si no se especifica entero, la longitud del resultado es la misma que la longitud del primer argumento. El resultado de la función es DBCLOB. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 345
- 372. DBPARTITIONNUM DBPARTITIONNUM ( nombre-columna ) El esquema es SYSIBM. La función DBPARTITIONNUM devuelve el número de partición de la fila. Por ejemplo, si se utiliza en una cláusula SELECT, devuelve el número de partición para cada fila de la tabla que se ha utilizado para formar el resultado de la sentencia SELECT. El número de partición devuelto en las tablas y variables de transición procede de los valores de transición actuales de las columnas de claves de particionamiento. Por ejemplo, en un activador BEFORE INSERT, la función devolverá el número de partición proyectado teniendo en cuenta los valores actuales de las nuevas variables de transición. No obstante, un activador BEFORE INSERT subsiguiente puede modificar los valores de las columnas de claves de particionamiento. De este modo, el número de partición final de la fila cuando se inserte en la base de datos puede ser diferente del valor proyectado. El argumento debe ser el nombre calificado o no calificado de una columna de una tabla. La columna puede tener cualquier tipo de datos. (Esta función no puede utilizarse como una función fuente cuando se crea una función definida por el usuario. Como acepta cualquier tipo de datos como argumento, no es necesario crear signaturas adicionales para dar soporte a los tipos diferenciados definidos por el usuario). Si nombre-columna hace referencia a una columna de una vista, la expresión de la vista para la columna debe hacer referencia a una columna de la tabla base principal y la vista debe ser suprimible. Una expresión de tabla anidada o común sigue las mismas reglas que una vista. La fila específica (y tabla) para la que se devuelve el número de partición mediante la función DBPARTITIONNUM se determina por el contexto de la sentencia de SQL que utiliza la función. El tipo de datos del resultado es INTEGER y nunca es nulo. Puesto que se devuelve información a nivel de fila, los resultados son los mismos, sin tener en cuenta las columnas que se especifican para la tabla. Si no hay ningún archivo db2nodes.cfg, el resultado es 0. La función DBPARTITIONNUM no puede utilizarse en tablas duplicadas, dentro de restricciones de comprobación ni en la definición de columnas generadas (SQLSTATE 42881). 346 Consulta de SQL, Volumen 1
- 373. Para compatibilidad con versiones anteriores a la Versión 8, la palabra clave NODENUMBER puede sustituirse por DBPARTITIONNUM. Ejemplos: v Cuente el número de filas en las que la fila para un EMPLOYEE está en una partición diferente de la descripción del departamento del empleado en DEPARTMENT. SELECT COUNT(*) FROM DEPARTMENT D, EMPLOYEE E WHERE D.DEPTNO=E.WORKDEPT AND DBPARTITIONNUM(E.LASTNAME) <> DBPARTITIONNUM(D.DEPTNO) v Una las tablas EMPLOYEE y DEPARTMENT donde las filas de las dos tablas estén en la misma partición. SELECT * FROM DEPARTMENT D, EMPLOYEE E WHERE DBPARTITIONNUM(E.LASTNAME) = DBPARTITIONNUM(D.DEPTNO) v Anote cronológicamente el número de empleado y el número de partición proyectado de la nueva fila en una tabla denominada EMPINSERTLOG1 para cualquier inserción de empleados creando un activador BEFORE en la tabla EMPLOYEE. CREATE TRIGGER EMPINSLOGTRIG1 BEFORE INSERT ON EMPLOYEE REFERENCING NEW AW NEWTABLE FOR EACH ROW MODE DB2SQL INSERT INTO EMPINSERTLOG1 VALUES(NEWTABLE.EMPNO, DBPARTITIONNUM (NEWTABLE.EMPNO)) Información relacionada: v “CREATE VIEW sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 3. Funciones 347
- 374. DECIMAL De numérico a decimal : DECIMAL ( expresión-numérica DEC ) , entero-precisión , entero-escala De carácter a decimal: DECIMAL ( expresión-caracteres DEC ) , entero-precisión , entero-escala , carácter-decimal De fecha y hora a decimal: DECIMAL ( expresión-fechahora DEC ) , entero-precisión , entero-escala El esquema es SYSIBM. La función DECIMAL devuelve una representación decimal de: v Un número v Una representación de serie de caracteres de un número decimal v Una representación de serie de caracteres de un número entero v Una representación de serie de caracteres de un número de coma flotante v Un valor de fecha y hora, si el argumento es una fecha, una hora o una indicación de fecha y hora El resultado de la función es un número decimal con precisión p y escala s, donde p y s son el segundo y el tercer argumento, respectivamente. Si el primer argumento puede ser nulo, el resultado puede ser nulo; si el primer argumento es nulo, el resultado es el valor nulo. De numérico a decimal 348 Consulta de SQL, Volumen 1
- 375. expresión-numérica Una expresión que devuelve un valor de cualquier tipo de datos numérico. entero-precisión Una constante de enteros con un valor en el rango de 1 a 31. El valor por omisión para entero-precisión depende del tipo de datos de expresión-numérica: v 15 para coma flotante y decimal v 19 para entero superior v 11 para entero grande v 5 para entero pequeño. entero-escala Una constante de enteros en el rango de 0 al valor de entero-precisión. El valor por omisión es cero. El resultado es el mismo número que sería si se asignase el primer argumento a una columna o variable decimal con precisión p y escala s, donde p y s son el segundo y el tercer argumento, respectivamente. Se produce un error si el número de dígitos decimales significativos necesarios para representar la parte correspondiente a los enteros es mayor que p−s. De carácter a decimal expresión-caracteres Una expresión que devuelve un valor que es una serie de caracteres con una longitud no mayor que la longitud máxima de una constante de caracteres (4.000 bytes). No puede tener un tipo de datos CLOB ni LONG VARCHAR. Los blancos iniciales o de cola se eliminan de la serie. La subserie resultante debe ajustarse a las reglas para formar una constante decimal o de entero SQL (SQLSTATE 22018). La expresión-caracteres se convierte a la página de códigos de la base de datos si es necesario que coincida con la página de códigos de la constante carácter-decimal. entero-precisión Una constante de enteros con un valor en el rango de 1 a 31 que especifica la precisión del resultado. Si no se especifica, el valor por omisión es 15. entero-escala Una constante de enteros con un valor en el rango entre 0 y entero-precisión que especifica la escala del resultado. Si no se especifica, el valor por omisión es 0. Capítulo 3. Funciones 349
- 376. carácter-decimal Especifica la constante de caracteres de un solo byte utilizada para delimitar los dígitos decimales en expresión-caracteres de la parte correspondiente a los enteros del número. El carácter no puede ser un dígito, el signo más (+), el signo menos (−) ni un blanco y puede aparecer como máximo una vez en expresión-caracteres (SQLSTATE 42815). El resultado es un número decimal con la precisión p y la escala s, donde p y s son el segundo y el tercer argumento, respectivamente. Los dígitos se truncan por el final del número decimal si el número de dígitos a la derecha del carácter decimal es mayor que la escala. Se produce un error si el número de dígitos significativos a la izquierda del carácter decimal (la parte correspondiente a los enteros del número) de expresión-caracteres es mayor que p−s (SQLSTATE 22003).El carácter decimal por omisión no es válido en la subserie si se especifica un valor diferente para el argumento carácter-decimal (SQLSTATE 22018). De fecha y hora a decimal expresión-fechahora Una expresión que sea uno de los tipos de datos siguientes: v DATE. El resultado es un valor DECIMAL(8,0) que representa la fecha como aaaammdd. v TIME. El resultado es un valor DECIMAL(6,0) que representa la hora como hhmmss. v TIMESTAMP. El resultado es un valor DECIMAL(20,6) que representa la indicación de fecha y hora como aaaammddhhmmss. Este función permite que el usuario especifique una precisión o una precisión y una escala. Sin embargo, una escala no puede especificarse sin especificar una precisión. El valor por omisión para (precisión,escala) es (8,0) para DATE, (6,0) para TIME y (20,6) para TIMESTAMP. El resultado es un número decimal con la precisión p y la escala s, donde p y s son el segundo y el tercer argumento, respectivamente. Los dígitos se truncan por el final si el número de dígitos a la derecha del carácter decimal es mayor que la escala. Se produce un error si el número de dígitos significativos a la izquierda del carácter decimal (la parte correspondiente a los enteros del número) de expresión-fechahora es mayor que p−s (SQLSTATE 22003). Ejemplos: 350 Consulta de SQL, Volumen 1
- 377. v Utilice la función DECIMAL para forzar a que se devuelva un tipo de datos DECIMAL (con una precisión de 5 y una escala de 2) en una lista-selección para la columna EDLEVEL (tipo de datos = SMALLINT) en la tabla EMPLOYEE. La columna EMPNO debe aparecer también en la lista de selección. SELECT EMPNO, DECIMAL(EDLEVEL,5,2) FROM EMPLOYEE v Suponga que la variable del lenguaje principal PERIOD es de tipo INTEGER. En este caso, para utilizar su valor como duración de fecha debe convertirse a decimal(8,0). SELECT PRSTDATE + DECIMAL(:PERIOD,8) FROM PROJECT v Suponga que las actualizaciones en la columna SALARY se entran mediante una ventana como una serie de caracteres que utiliza la coma como carácter decimal (por ejemplo, el usuario entra 21400,50). Cuando se ha validado por la aplicación, se asigna a la variable del lenguaje principal newsalary definida como CHAR(10). UPDATE STAFF SET SALARY = DECIMAL(:newsalary, 9, 2, ’,’) WHERE ID = :empid; El valor de newsalary se convierte en 21400.50. v Añada el carácter decimal por omisión (.) al valor. DECIMAL(’21400,50’, 9, 2, ’.’) Falla porque se especifica un punto (.) como el carácter decimal, pero aparece una coma (,) en el primer argumento como delimitador. v Suponga que la columna STARTING (hora) tiene un valor interno equivalente a ’12:10:00’. DECIMAL(STARTING) da como resultado el valor 121 000. v Suponga que la columna RECEIVED (indicación de fecha y hora) tiene un valor interno equivalente a ’1988-12-22-14.07.21.136421’. DECIMAL(RECEIVED) da como resultado el valor 19 881 222 140 721.136421. v La tabla siguiente muestra el resultado decimal y la precisión y la escala resultante para varios valores de entrada de fecha y hora. DECIMAL(argumentos) Precisión y Resultado escala DECIMAL(2000-03-21) (8,0) 20000321 Capítulo 3. Funciones 351
- 378. DECIMAL(argumentos) Precisión y Resultado escala DECIMAL(2000-03-21, 10) (10,0) 20000321 DECIMAL(2000-03-21, 12, 2) (12,2) 20000321.00 DECIMAL(12:02:21) (6,0) 120221 DECIMAL(12:02:21, 10) (10,0) 120221 DECIMAL(12:02:21, 10, 2) (10,2) 120221.00 DECIMAL(2000-03-21- (20, 6) 20000321120221.123456 12.02.21.123456) DECIMAL(2000-03-21- (23, 6) 20000321120221.123456 12.02.21.123456, 23) DECIMAL(2000-03-21- (23, 4) 20000321120221.1234 12.02.21.123456, 23, 4) 352 Consulta de SQL, Volumen 1
- 379. DECRYPT_BIN y DECRYPT_CHAR DECRYPT_BIN ( datos-cifrados ) DECRYPT_CHAR , expresión-serie-contraseña El esquema es SYSIBM. Las funciones DECRYPT_BIN y DECRYPT_CHAR devuelven un valor que es el resultado del descifrado de datos-cifrados. La contraseña utilizada para el descifrado es el valor de expresión-serie-contraseña o el valor de ENCRYPTION PASSWORD asignado por la sentencia SET ENCRYPTION PASSWORD. Las funciones DECRYPT_BIN y DECRYPT_CHAR sólo pueden descifrar valores que se han cifrado utilizando la función ENCRYPT (SQLSTATE 428FE). datos-cifrados Una expresión que devuelve un valor CHAR FOR BIT DATA o VARCHAR FOR BIT DATA como una serie de datos cifrada completa. La serie de datos se tiene que haber cifrado utilizando la función ENCRYPT. expresión-serie-contraseña Una expresión que devuelve un valor CHAR o VARCHAR con un mínimo de 6 bytes y no más de 127 bytes (SQLSTATE 428FC). Esta expresión debe ser la misma contraseña utilizada para cifrar los datos o, de lo contrario, el descifrado producirá un error (SQLSTATE 428FD). Si el valor del argumento de contraseña es nulo o no se proporciona, los datos se cifrarán utilizando el valor de ENCRYPTION PASSWORD, que tiene que haberse establecido para la sesión (SQLSTATE 51039). El resultado de la función DECRYPT_BIN es VARCHAR FOR BIT DATA. El resultado de la función DECRYPT_CHAR es VARCHAR. Si los datos-cifrados incluían una indicación, la función no devuelve la indicación. El atributo de longitud del resultado es la longitud del tipo de datos de los datos-cifrados menos 8 bytes. La longitud real del valor devuelto por la función coincidirá con la longitud de la serie original que se ha cifrado. Si datos-cifrados incluye bytes más allá de la serie cifrada, la función no devolverá estos bytes. Si el primer argumento puede ser nulo, el resultado puede ser nulo. Si el primer argumento es nulo, el resultado es el valor nulo. Si los datos se descifran en un sistema diferente que utiliza una página de códigos diferente de la página de códigos en la que se han cifrado los datos, puede que se produzca una expansión al convertir el valor descifrado a la página de códigos de la base de datos. En dichas situaciones, el valor datos-cifrados debe calcularse en una serie VARCHAR con un número mayor de bytes. Capítulo 3. Funciones 353
- 380. Ejemplos: Ejemplo 1: Este ejemplo utiliza el valor de ENCRYPTION PASSWORD para retener la contraseña de cifrado. SET ENCRYPTION PASSWORD = ’Ben123’; INSERT INTO EMP(SSN) VALUES ENCRYPT(’289-46-8832’); SELECT DECRYPT_CHAR(SSN) FROM EMP; Esto devuelve el valor ’289-46-8832’. Ejemplo 2: Este ejemplo pasa explícitamente la contraseña de cifrado. INSERT INTO EMP (SSN) VALUES ENCRYPT(’289-46-8832’,’Ben123’,’’); SELECT DECRYPT(SSN,’Ben123’) FROM EMP; Este ejemplo devuelve el valor ’289-46-8832’. Información relacionada: v “SET ENCRYPTION PASSWORD sentencia” en la publicación Consulta de SQL, Volumen 2 v “ENCRYPT” en la página 382 v “GETHINT” en la página 389 354 Consulta de SQL, Volumen 1
- 381. DEGREES DEGREES ( expresión ) El esquema es SYSFUN. Devuelve el número de grados convertidos del argumento expresado en radianes. El argumento puede ser de cualquier tipo numérico interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 355
- 382. DEREF DEREF ( expresión ) La función DEREF devuelve una instancia del tipo de destino del argumento. El argumento puede ser cualquier valor con un tipo de datos de referencia que tenga un ámbito definido (SQLSTATE 428DT). El tipo de datos estático del resultado es el tipo de destino del argumento. El tipo de datos dinámico del resultado es un subtipo del tipo de destino del argumento. El resultado puede ser nulo. El resultado es un valor nulo si expresión es un valor nulo o si expresión es una referencia que no tiene un OID correspondiente en la tabla de destino. El resultado es una instancia del subtipo del tipo de destino de la referencia. El resultado se determina buscando la fila de la tabla de destino o vista de destino de la referencia que tenga un identificador de objeto que se corresponda con el valor de la referencia. El tipo de esta fila determina el tipo dinámico del resultado. Puesto que el tipo del resultado puede estar basado en una fila de una subtabla o subvista de la tabla de destino o vista de destino, el ID de autorización de la sentencia debe tener un privilegio SELECT sobre la tabla de destino y todas sus subtablas o sobre la vista de destino y todas sus subvistas (SQLSTATE 42501). Ejemplos: Suponga que EMPLOYEE es una tabla de tipo EMP, y que su columna de identificador de objeto se llama EMPID. En este caso, la consulta siguiente devuelve un objeto de tipo EMP (o uno de sus subtipos) para cada fila de la tabla EMPLOYEE (y de sus subtablas). Para ejecutar esta consulta es necesario tener privilegio SELECT sobre EMPLOYEE y todas sus subtablas. SELECT DEREF(EMPID) FROM EMPLOYEE Información relacionada: v “TYPE_NAME” en la página 507 356 Consulta de SQL, Volumen 1
- 383. DIFFERENCE DIFFERENCE ( expresión , expresión ) El esquema es SYSFUN. Devuelve un valor de 0 a 4 que representa la diferencia entre los sonidos de dos series basándose en la aplicación de la función SOUNDEX en las series. El valor 4 es la mejor coincidencia de sonido posible. Los argumentos pueden ser series de caracteres que sean CHAR o VARCHAR de un máximo de 4.000 bytes. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplo: VALUES (DIFFERENCE(’CONSTRAINT’,’CONSTANT’),SOUNDEX(’CONSTRAINT’), SOUNDEX(’CONSTANT’)), (DIFFERENCE(’CONSTRAINT’,’CONTRITE’),SOUNDEX(’CONSTRAINT’), SOUNDEX(’CONTRITE’)) Este ejemplo devuelve lo siguiente. 1 2 3 ----------- ---- ---- 4 C523 C523 2 C523 C536 En la primera fila, las palabras tienen el mismo resultado de SOUNDEX, mientras que en la segunda fila las palabras sólo tienen algún parecido. Capítulo 3. Funciones 357
- 384. DIGITS DIGITS ( expresión ) El esquema es SYSIBM. La función DIGITS devuelve una representación de serie de caracteres de un número. El argumento debe ser una expresión que devuelva un valor con el tipo SMALLINT, INTEGER, BIGINT o DECIMAL. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. El resultado de la función es una serie de caracteres de longitud fija que representa el valor absoluto del argumento sin tener en cuenta su escala. El resultado no incluye el signo ni el carácter decimal. En su lugar, consta exclusivamente de dígitos, incluyendo, si es necesario, ceros iniciales para rellenar la serie. La longitud de la serie es: v 5 si el argumento es un entero pequeño v 10 si el argumento es un entero grande v 19 si el argumento es un entero superior v p si el argumento es un número decimal con una precisión de p. Ejemplos: v Suponga que una tabla llamada TABLEX contiene una columna INTEGER llamada INTCOL que contiene números de 10 dígitos. Liste las cuatro combinaciones de dígitos de los cuatro primeros dígitos de la columna INTCOL. SELECT DISTINCT SUBSTR(DIGITS(INTCOL),1,4) FROM TABLEX v Suponga que la columna COLUMNX tiene el tipo de datos DECIMAL(6,2) y que uno de sus valores es -6.28. Entonces, para este valor: DIGITS(COLUMNX) devuelve el valor '000628'. El resultado es una serie de longitud seis (la precisión de la columna) con ceros iniciales que rellenan la serie hasta esta longitud. No aparecen ni el signo ni la coma decimal en el resultado. 358 Consulta de SQL, Volumen 1
- 385. DLCOMMENT DLCOMMENT ( expresión-datalink ) El esquema es SYSIBM. La función DLCOMMENT devuelve el valor del comentario, si existe, de un valor DATALINK. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos de DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplo: v Prepare una sentencia para seleccionar la fecha, la descripción y el comentario (en el enlace de la columna ARTICLES) de la tabla HOCKEY_GOALS. Las filas a seleccionar son las correspondientes a los goles marcados por cualquiera de los dos hermanos Richard (Maurice o Henri). stmtvar = "SELECT DATE_OF_GOAL, DESCRIPTION, DLCOMMENT(ARTICLES) FROM HOCKEY_GOALS WHERE BY_PLAYER = ’Maurice Richard’ OR BY_PLAYER = ’Henri Richard’ "; EXEC SQL PREPARE HOCKEY_STMT FROM :stmtvar; v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’Un comentario’) la siguiente función que realiza una operación con este valor: DLCOMMENT(COLA) devolverá el valor: Un comentario Capítulo 3. Funciones 359
- 386. DLLINKTYPE DLLINKTYPE ( expresión-datalink ) El esquema es SYSIBM. La función DLLINKTYPE devuelve el valor de tipoenlace de un valor DATALINK. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(4). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLLINKTYPE(COLA) devolverá el valor: URL 360 Consulta de SQL, Volumen 1
- 387. DLNEWCOPY DLNEWCOPY ( ubicación-datos , tiene-símbolo ) El esquema es SYSIBM. La función DLNEWCOPY devuelve un valor DATALINK que tiene un atributo que indica que se ha modificado el archivo referenciado. Si se asigna este valor a una columna DATALINK como resultado de una sentencia SQL UPDATE, se comunica a DB2 que ha finalizado una actualización del archivo enlazado. Si la columna DATALINK está definida con RECOVERY YES, la nueva versión del archivo enlazado se archiva de forma asíncrona. Si se asigna este valor a una columna DATALINK como resultado de una sentencia SQL INSERT, se devuelve un error (SQLSTATE 428D1). ubicación-datos Una expresión VARCHAR(200) que especifica un serie de caracteres de longitud variable que contiene un valor de URL completo. El valor puede haberse obtenido anteriormente mediante una sentencia SELECT utilizando la función DLURLCOMPLETEWRITE. tiene-símbolo Un valor INTEGER que indica si la ubicación de los datos contiene un símbolo de escritura. 0 La ubicación de los datos no contiene un símbolo de escritura. 1 La ubicación de los datos contiene un símbolo de escritura. Se produce un error si el valor no es ni 0 ni 1 (SQLSTATE 42815), o si el símbolo intercalado en la ubicación de los datos no es válido (SQLSTATE 428D1). El resultado de la función es un valor DATALINK sin el símbolo de escritura. Ni ubicación-datos ni tiene-símbolo puede ser nulo. Para una columna DATALINK definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE, el símbolo de escritura debe estar en la ubicación de los datos para que se complete la sentencia SQL UPDATE (SQLSTATE 428D1). Por otra parte, para WRITE PERMISSION ADMIN NOT REQUIRING TOKEN FOR UPDATE no se requiere el símbolo de escritura pero se permite en la ubicación de los datos. Para una columna DATALINK definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE, el símbolo de escritura debe ser el mismo que el utilizado para abrir el archivo especificado, si se había abierto (SQLSTATE 428D1). Capítulo 3. Funciones 361
- 388. Para cualquier columna WRITE PERMISSION ADMIN, aunque el símbolo de escritura haya caducado, el símbolo sigue considerándose válido siempre que se utilice el mismo símbolo para abrir el archivo especificado para acceso de escritura. En caso de que no se haya realizado ninguna actualización del archivo o el archivo DATALINK esté enlazado con otras opciones como, por ejemplo, WRITE PERMISSION BLOCKED/FS o NO LINK CONTROL, esta función se comportará como DLVALUE. Ejemplos: v Dado un valor DATALINK que se haya insertado en la columna COLA (definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE) en la tabla TBLA utilizando la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) Utilice la función escalar DLURLCOMPLETEWRITE para buscar el valor: SELECT DLURLCOMPLETEWRITE(COLA) FROM TBLA WHERE ... Devuelve: HTTP://DLFS.ALMADEN.IBM.COM/x/y/****************;a.b donde **************** representa el símbolo de escritura. Utilice el valor anterior para localizar y actualizar el contenido del archivo. Emita la siguiente sentencia SQL UPDATE para indicar que el archivo se ha modificado de forma satisfactoria: UPDATE TBLA SET COLA = DLNEWCOPY(’http://dlfs.almaden.ibm.com/x/y/******** ********;a.b’, 1) WHERE ... donde **************** representa el mismo símbolo de escritura utilizado para modificar el archivo al que el valor de URL hace referencia. Observe que si COLA está definido con WRITE PERMISSION ADMIN NOT REQUIRING TOKEN FOR UPDATE, el símbolo de escritura no es necesario en el ejemplo anterior. v El valor del segundo argumento (tiene-símbolo) puede sustituirse por la sentencia CASE siguiente. Suponga que el valor de URL está contenido en una variable denominada url_file. Emita la siguiente sentencia SQL UPDATE para indicar que el archivo se ha modificado de forma satisfactoria: 362 Consulta de SQL, Volumen 1
- 389. EXEC SQL UPDATE TBLA SET COLA = DLNEWCOPY(:url_file, (CASE WHEN LENGTH(:url_file) = LENGTH(DLURLCOMPLETEONLY(COLA)) THEN 0 ELSE 1 END)) WHERE ... Capítulo 3. Funciones 363
- 390. DLPREVIOUSCOPY DLPREVIOUSCOPY ( ubicación-datos , tiene-símbolo ) El esquema es SYSIBM. La función DLPREVIOUSCOPY devuelve un valor DATALINK que tiene un atributo que indica que debería restaurarse la versión anterior del archivo. Si se asigna este valor a una columna DATALINK como resultado de una sentencia SQL UPDATE, provoca que DB2 restaure el archivo enlazado de la versión confirmada anteriormente. Si se asigna este valor a una columna DATALINK como resultado de una sentencia SQL INSERT, se devuelve un error (SQLSTATE 428D1). ubicación-datos Una expresión VARCHAR(200) que especifica un serie de caracteres de longitud variable que contiene un valor de URL completo. El valor puede haberse obtenido anteriormente mediante una sentencia SELECT utilizando la función DLURLCOMPLETEWRITE. tiene-símbolo Un valor INTEGER que indica si la ubicación de los datos contiene un símbolo de escritura. 0 La ubicación de los datos no contiene un símbolo de escritura. 1 La ubicación de los datos contiene un símbolo de escritura. Se produce un error si el valor no es ni 0 ni 1 (SQLSTATE 42815), o si el símbolo intercalado en la ubicación de los datos no es válido (SQLSTATE 428D1). El resultado de la función es un valor DATALINK sin el símbolo de escritura. Ni ubicación-datos ni tiene-símbolo puede ser nulo. Para una columna DATALINK definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE, el símbolo de escritura debe estar en la ubicación de los datos para que se complete la sentencia SQL UPDATE (SQLSTATE 428D1). Por otra parte, para WRITE PERMISSION ADMIN NOT REQUIRING TOKEN FOR UPDATE no se requiere el símbolo de escritura pero se permite en la ubicación de los datos. Para una columna DATALINK definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE, el símbolo de escritura debe ser el mismo que el utilizado para abrir el archivo especificado, si se había abierto (SQLSTATE 428D1). 364 Consulta de SQL, Volumen 1
- 391. Para cualquier columna WRITE PERMISSION ADMIN, aunque el símbolo de escritura haya caducado, el símbolo sigue considerándose válido siempre que se utilice el mismo símbolo para abrir el archivo especificado para acceso de escritura. Ejemplos: v Dado un valor DATALINK que se haya insertado en la columna COLA (definida con WRITE PERMISSION ADMIN REQUIRING TOKEN FOR UPDATE y RECOVERY YES) en la tabla TBLA utilizando la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) Utilice la función escalar DLURLCOMPLETEWRITE para buscar el valor: SELECT DLURLCOMPLETEWRITE(COLA) FROM TBLA WHERE ... Devuelve: HTTP://DLFS.ALMADEN.IBM.COM/x/y/****************;a.b donde **************** representa el símbolo de escritura. Utilice el valor anterior para localizar y actualizar el contenido del archivo. Emita la sentencia SQL UPDATE siguiente para restituir los cambios en el archivo y restaurarlo en la versión confirmada anterior. UPDATE TBLA SET COLA = DLPREVIOUSCOPY(’http://dlfs.almaden.ibm.com/x/y/******** ********;a.b’, 1) WHERE ... donde **************** representa el mismo símbolo de escritura utilizado para modificar el archivo al que el valor de URL hace referencia. Observe que si COLA está definido con WRITE PERMISSION ADMIN NOT REQUIRING TOKEN FOR UPDATE, el símbolo de escritura no es necesario en el ejemplo anterior. v El valor del segundo argumento (tiene-símbolo) puede sustituirse por la sentencia CASE siguiente. Suponga que el valor de URL está contenido en una variable denominada url_file. Emita la sentencia SQL UPDATE siguiente para restituir los cambios en el archivo y restaurarlo en la versión confirmada anterior. EXEC SQL UPDATE TBLA SET COLA = DLPREVIOUSCOPY(:url_file, (CASE WHEN LENGTH(:url_file) = LENGTH(DLURLCOMPLETEONLY(COLA)) THEN 0 ELSE 1 END)) WHERE ... Capítulo 3. Funciones 365
- 392. DLREPLACECONTENT DLREPLACECONTENT ( destino-ubicación-datos , fuente-ubicación-datos ) , serie-comentario El esquema es SYSIBM. La función DLREPLACECONTENT devuelve un valor DATALINK. Cuando la función está al lado derecho de una cláusula SET de una sentencia UPDATE o está en una cláusula VALUES dentro de una sentencia INSERT, la asignación del valor devuelto provoca la sustitución del contenido de un archivo por otro archivo y la creación de un enlace con el mismo. El proceso de sustitución del archivo propiamente dicho se realiza durante el proceso de confirmación de la transacción actual. destino-ubicación-datos Una expresión VARCHAR(200) que especifica un serie de caracteres de longitud variable que contiene un valor de URL completo. fuente-ubicación-datos Una expresión VARCHAR que especifica la ubicación de los datos de un archivo en formato URL. Como resultado de una asignación en una sentencia UPDATE o INSERT, el nombre de este archivo se cambia al del archivo al que hace referencia el destino-ubicación-datos; los atributos de propiedad y permiso del archivo de destino se conservan. Existe la restricción de que la fuente-ubicación-datos sólo puede ser una de las siguientes: v Un valor de longitud cero v Un valor NULL v El valor de destino-ubicación-datos más una serie de sufijo. La serie de sufijo puede tener una longitud máxima de 20 caracteres. Los caracteres de la serie de sufijo deben pertenecer al junto de caracteres URL. Además, la serie no puede contener un carácter “” bajo el esquema UNC ni el carácter“/” bajo otros esquemas válidos (SQLSTATE 428D1). serie-comentario Un valor VARCHAR opcional que contiene un comentario o información adicional sobre la ubicación. El resultado de la función es un valor DATALINK. Si algún argumento puede ser nulo, el resultado puede ser nulo; si el destino-ubicación-datos es nulo, el resultado es el valor nulo. Si la fuente-ubicación-datos es nula, una serie de longitud cero o exactamente igual que el destino-ubicación-datos, el efecto de DLREPLACECONTENT es el mismo que DLVALUE. 366 Consulta de SQL, Volumen 1
- 393. Ejemplo: v Sustituya el contenido de un archivo enlazado por otro archivo. Dado un valor DATALINK que se ha insertado en la columna PICT_FILE de la tabla TBLA utilizando la sentencia INSERT siguiente: EXEC SQL INSERT INTO TBLA (PICT_ID, PICT_FILE) VALUES(1000, DLVALUE(’HTTP://HOSTA.COM/dlfs/image-data/pict1.gif’)); Sustituya el contenido de este archivo por otro archivo emitiendo la sentencia SQL UPDATE siguiente: EXEC SQL UPDATE TBLA SET PICT_FILE = DLREPLACECONTENT(’HTTP://HOSTA.COM/dlfs/image-data/pict1.gif’, ’HTTP://HOSTA.COM/dlfs/image-data/pict1.gif.new’) WHERE PICT_ID = 1000; Capítulo 3. Funciones 367
- 394. DLURLCOMPLETE DLURLCOMPLETE ( expresión-datalink ) La función DLURLCOMPLETE devuelve el atributo de ubicación de datos a partir de un valor DATALINK, con un tipo de enlace de URL. Cuando expresión-datalink es una columna DATALINK definida con el atributo READ PERMISSION DB, el valor incluye un símbolo de accesos de archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye el comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLCOMPLETE(COLA) devuelve: HTTP://DLFS.ALMADEN.IBM.COM/x/y/****************;a.b donde **************** representa el símbolo de accesos. 368 Consulta de SQL, Volumen 1
- 395. DLURLCOMPLETEONLY DLURLCOMPLETEONLY ( expresión-datalink ) El esquema es SYSIBM. La función DLURLCOMPLETEONLY devuelve el atributo de ubicación de datos a partir de un valor DATALINK, con un tipo de enlace de URL. El valor devuelto nunca incluye un símbolo de accesos de archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye un comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se haya insertado en la columna COLA de DATALINK (definido con READ PERMISSION DB) en la tabla TBLA utilizando la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLCOMPLETEONLY(COLA) devuelve: HTTP://DLFS.ALMADEN.IBM.COM/x/y/a.b Capítulo 3. Funciones 369
- 396. DLURLCOMPLETEWRITE DLURLCOMPLETEWRITE ( expresión-datalink ) El esquema es SYSIBM. La función DLURLCOMPLETEWRITE devuelve el valor de URL completo a partir de un valor DATALINK con un tipo de enlace de URL. Si el valor de DATALINK generado a partir de expresión-datalink procede de una columna DATALINK definida con WRITE PERMISSION ADMIN, se incluye un símbolo de escritura en el valor devuelto. El valor devuelto puede utilizarse para localizar y actualizar el archivo enlazado. Si la columna DATALINK está definida con otra opción de WRITE PERMISSION (no ADMIN) o con NO LINK CONTROL, DLURLCOMPLETEWRITE sólo devuelve el valor del URL sin un símbolo de escritura. Si la referencia de archivo se deriva de una columna DATALINK definida con WRITE PERMISSION FS, no se necesita ningún símbolo para grabar en el archivo, porque el sistema de archivos controla el permiso de escritura; si la referencia de archivo se deriva de una columna DATALINK definida con WRITE PERMISSION BLOCKED, no puede escribirse nada en el archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye un comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se haya insertado en la columna COLA de DATALINK (definido con WRITE PERMISSION ADMIN) en la tabla TBLA utilizando la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLCOMPLETEWRITE(COLA) devuelve: HTTP://DLFS.ALMADEN.IBM.COM/x/y/****************;a.b 370 Consulta de SQL, Volumen 1
- 397. donde **************** representa el símbolo de escritura. Si COLA no está definido con WRITE PERMISSION ADMIN, el símbolo de escritura no aparecerá. Capítulo 3. Funciones 371
- 398. DLURLPATH DLURLPATH ( expresión-datalink ) El esquema es SYSIBM. La función DLURLPATH devuelve la vía de acceso y el nombre de archivo necesarios para acceder a un archivo de un servidor determinado desde un valor DATALINK con un tipoenlace de URL. Cuando expresión-datalink es una columna DATALINK definida con el atributo READ PERMISSION DB, el valor incluye un símbolo de accesos de archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye el comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLPATH(COLA) devolverá el valor: /x/y/****************;a.b (donde **************** representa el símbolo de accesos) 372 Consulta de SQL, Volumen 1
- 399. DLURLPATHONLY DLURLPATHONLY ( expresión-datalink ) El esquema es SYSIBM. La función DLURLPATHONLY devuelve la vía de acceso y el nombre de archivo necesarios para acceder a un archivo de un servidor determinado desde un valor DATALINK con un tipo de enlace de URL. El valor devuelto NUNCA incluye un símbolo de accesos de archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye el comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLPATHONLY(COLA) devolverá el valor: /x/y/a.b Capítulo 3. Funciones 373
- 400. DLURLPATHWRITE DLURLPATHWRITE ( expresión-datalink ) El esquema es SYSIBM. La función DLURLPATHWRITE devuelve la vía de acceso y el nombre de archivo necesarios para acceder a un archivo de un servidor determinado desde un valor DATALINK con un tipo de enlace de URL. El valor devuelto incluye un símbolo de escritura si el valor de DATALINK generado a partir de expresión-datalink procede de una columna DATALINK definida con WRITE PERMISSION ADMIN. Si la columna DATALINK está definida con otras opciones de WRITE PERMISSION (no ADMIN) o con NO LINK CONTROL, DLURLPATHWRITE devuelve la vía de acceso y el nombre de archivo sin un símbolo de escritura. Si la referencia de archivo se deriva de una columna DATALINK definida con WRITE PERMISSION FS, no se necesita ningún símbolo para grabar en el archivo, porque el sistema de archivos controla el permiso de escritura; si la referencia de archivo se deriva de una columna DATALINK definida con WRITE PERMISSION BLOCKED, no puede escribirse nada en el archivo. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye un comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se haya insertado en la columna COLA de DATALINK (definido con WRITE PERMISSION ADMIN) en la tabla TBLA utilizando la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLPATHWRITE(COLA) devuelve: /x/y/****************;a.b 374 Consulta de SQL, Volumen 1
- 401. donde **************** representa el símbolo de escritura. Si COLA no está definido con WRITE PERMISSION ADMIN, el símbolo de escritura no aparecerá. Capítulo 3. Funciones 375
- 402. DLURLSCHEME DLURLSCHEME ( expresión-datalink ) El esquema es SYSIBM. La función DLURLSCHEME devuelve el esquema de un valor DATALINK con un tipoenlace de URL. El valor siempre estará en mayúsculas. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(20). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye el comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLSCHEME(COLA) devolverá el valor: HTTP 376 Consulta de SQL, Volumen 1
- 403. DLURLSERVER DLURLSERVER ( expresión-datalink ) El esquema es SYSIBM. La función DLURLSERVER devuelve el servidor de archivos de un valor DATALINK con un tipoenlace de URL. El valor siempre estará en mayúsculas. El argumento debe ser una expresión que dé como resultado un valor con el tipo de datos DATALINK. El resultado de la función es VARCHAR(254). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Si el valor DATALINK sólo incluye el comentario, el resultado devuelto es una serie de longitud cero. Ejemplo: v Dado un valor DATALINK que se había insertado en la columna COLA de una fila de la tabla TBLA mediante la función escalar: DLVALUE(’http://dlfs.almaden.ibm.com/x/y/a.b’,’URL’,’un comentario’) la siguiente función que realiza una operación con este valor: DLURLSERVER(COLA) devolverá el valor: DLFS.ALMADEN.IBM.COM Capítulo 3. Funciones 377
- 404. DLVALUE DLVALUE ( ubicación-datos , serie-tipoenlace , serie-comentario ) El esquema es SYSIBM. La función DLVALUE devuelve un valor DATALINK. Cuando la función está al lado derecho de una cláusula SET dentro de una sentencia UPDATE o está en una cláusula VALUES dentro de una sentencia INSERT, normalmente también crea un enlace con un archivo. No obstante, si sólo se especifica un comentario (en cuyo caso la serie ubicación-datos tiene longitud-cero), el valor DATALINK se crea con atributos de enlace vacíos, por lo que no hay enlace de archivo. ubicación-datos Si el tipo de enlace es URL, ésta es una expresión que proporciona una serie de caracteres de longitud variable que contiene un valor de URL completo. serie-tipoenlace Una expresión VARCHAR opcional que especifica el tipo de enlace del valor DATALINK. El único valor válido es ’URL’ (SQLSTATE 428D1). serie-comentario Un valor VARCHAR(254) opcional que proporciona comentarios o información adicional sobre la ubicación. La longitud de ubicación-datos más la de serie-comentarios no debe sobrepasar los 200 bytes. El resultado de la función es un valor DATALINK. Si cualquier argumento de la función DLVALUE puede ser nulo, el resultado puede ser nulo; si ubicación-datos es nula, el resultado es el valor nulo. Cuando defina un valor DATALINK mediante esta función, tenga en cuenta la longitud máxima del destino del valor. Por ejemplo, si se define una columna como DATALINK(200), la longitud máxima de ubicación-datos más comentario suma 200 bytes. Ejemplo: v Inserte una fila en la tabla. Los valores de URL para los dos primeros enlaces se incluyen en las variables denominadas url_article y url_snapshot. La variable denominada url_snapshot_comment contiene un comentario que acompaña el enlace de snapshot. Todavía no existe el enlace de movie, sólo un comentario en la variable denominada url_movie_comment. 378 Consulta de SQL, Volumen 1
- 405. EXEC SQL INSERT INTO HOCKEY_GOALS VALUES(’Maurice Richard’, ’Montreal Canadien’, ’?’, ’Boston Bruins, ’1952-04-24’, ’Winning goal in game 7 of Stanley Cup final’, DLVALUE(:url_article), DLVALUE(:url_snapshot, ’URL’, :url_snapshot_comment), DLVALUE(’’, ’URL’, :url_movie_comment) ); Capítulo 3. Funciones 379
- 406. De numérico a doble : DOUBLE ( expresión-numérica ) FLOAT DOUBLE_PRECISION De serie de caracteres a doble : DOUBLE ( expresión-serie ) El esquema es SYSIBM. Sin embargo, el esquema de DOUBLE(expresión-serie) es SYSFUN. La función DOUBLE devuelve un número de coma flotante correspondiente a: v un número si el argumento es una expresión numérica v una representación de serie de caracteres de un número si el argumento es una expresión de serie. De numérico a doble expresión-numérica El argumento es una expresión que devuelve un valor de cualquier tipo de datos numérico interno. El resultado de la función es un número de coma flotante de precisión doble. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. El resultado es el mismo número que sería si el argumento se hubiese asignado a una columna o variable de coma flotante de precisión doble. De serie de caracteres a doble expresión-serie El argumento puede ser de tipo CHAR o VARCHAR en el formato de una constante numérica. Se ignoran los blancos iniciales y de cola. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. El resultado es el mismo número que sería si la serie se considerase una constante y se asignase a una columna o variable de coma flotante de precisión doble. 380 Consulta de SQL, Volumen 1
- 407. Ejemplo: Utilizando la tabla EMPLOYEE, busque la proporción de salario y comisiones para los empleados cuya comisión no sea cero. Las columnas implicadas (SALARY y COMM) tienen tipos de datos DECIMAL. Para eliminar la posibilidad de resultados fuera de rango, se aplica DOUBLE a SALARY para que la división se lleve a cabo en coma flotante: SELECT EMPNO, DOUBLE(SALARY)/COMM FROM EMPLOYEE WHERE COMM > 0 Capítulo 3. Funciones 381
- 408. ENCRYPT ENCRYPT ( expresión-serie-datos ) , expresión-serie-contraseña , expresión-serie-indicación El esquema es SYSIBM. La función ENCRYPT devuelve un valor que es el resultado del cifrado de expresión-serie-datos. La contraseña utilizada para el cifrado es el valor de expresión-serie-contraseña o el valor de ENCRYPTION PASSWORD (asignado utilizando la sentencia SET ENCRYPTION PASSWORD). expresión-serie-datos Una expresión que devuelve un valor CHAR o VARCHAR que se debe cifrar. El atributo de longitud para el tipo de datos de expresión-serie-datos está limitado a 32663 sin ningún argumento expresión-serie-indicación y a 32631 cuando se especifica el argumento expresión-serie-indicación (SQLSTATE 42815). expresión-serie-contraseña Una expresión que devuelve un valor CHAR o VARCHAR con un mínimo de 6 bytes y no más de 127 bytes (SQLSTATE 428FC). El valor representa la contraseña utilizada para cifrar la expresión-serie-datos. Si el valor del argumento de contraseña es nulo o no se proporciona, los datos se cifrarán utilizando el valor de ENCRYPTION PASSWORD, que tiene que haberse establecido para la sesión (SQLSTATE 51039). expresión-serie-indicación Una expresión que devuelve un valor CHAR o VARCHAR de un máximo de 32 bytes que ayudará a los propietarios de datos a recordar las contraseñas (por ejemplo, ’Océano’ como indicación para recordar ’Pacífico’). Si se proporciona un valor de indicación, la indicación se incorpora en el resultado y puede recuperarse utilizando la función GETHINT. Si este argumento es nulo o no se proporciona, no se incorporará ninguna indicación en el resultado. El tipo de datos de resultado de la función es VARCHAR FOR BIT DATA. El atributo de longitud del resultado es: v Cuando se especifica el parámetro de indicación opcional, el atributo de longitud de los datos no cifrados + 8 bytes + el número de bytes hasta el siguiente límite de 8 bytes + 32 bytes para la longitud de la indicación. v Sin parámetro de indicación, el atributo de longitud de los datos no cifrados + 8 bytes + el número de bytes hasta el siguiente límite de 8 bytes. 382 Consulta de SQL, Volumen 1
- 409. Si el primer argumento puede ser nulo, el resultado puede ser nulo; si el primer argumento es nulo, el resultado es el valor nulo. Tenga en cuenta que el resultado cifrado tiene una longitud mayor que la del valor expresión-serie-datos. Por consiguiente, al asignar valores cifrados, asegúrese de que el destino se declara con un tamaño suficiente para contener el valor cifrado entero. Notas: v Algoritmo de cifrado: El algoritmo de cifrado interno utilizado es la cifra de bloque RC2 con relleno, la clave secreta de 128 bits se deriva de la contraseña utilizando una conversión de mensaje MD2. v Contraseñas y datos de cifrado La gestión de contraseñas es responsabilidad del usuario. Una vez que se han cifrado los datos, sólo se puede utilizar para descifrarlos la contraseña utilizada para cifrarlos (SQLSTATE 428FD). Tenga cuidado al utilizar las variables CHAR para establecer valores de contraseña porque pueden estar rellenadas con espacios en blanco. El resultado cifrado puede contener el terminador nulo y otros caracteres no imprimibles. v Definición de columna de tabla: Cuando defina columnas y tipos para que contengan datos cifrados, calcule siempre el atributo de longitud del modo siguiente. Para datos cifrados sin indicación: Longitud máxima de los datos no cifrados + 8 bytes + el número de bytes hasta el siguiente límite de 8 bytes = longitud de columna de datos cifrados. Para datos cifrados con indicación interna: Longitud máxima de los datos no cifrados + 8 bytes + el número de bytes hasta el siguiente límite de 8 bytes + 32 bytes para la longitud de la indicación = longitud de columna de datos cifrados. Cualquier asignación o cálculo a una longitud inferior a la longitud de datos sugerida puede producir un descifrado anómalo en el futuro y hacer que se pierdan datos. Los espacios en blanco son valores de datos cifrados válidos que se pueden truncar al almacenarse en una columna que es demasiado pequeña. Ejemplos de cálculos de longitud de columna: Longitud máxima de datos no cifrados 6 bytes 8 bytes 8 bytes Número de bytes hasta el siguiente límite de de 8 bytes 2 bytes --------- Longitud de columna de datos cifrados 16 bytes Longitud máxima de datos no cifrados 32 bytes 8 bytes 8 bytes Capítulo 3. Funciones 383
- 410. Número de bytes hasta el siguiente límite de 8 bytes 8 bytes --------- Longitud de columna de datos cifrados 48 bytes v Administración de datos cifrados: Los datos cifrados sólo se pueden descifrar en servidores que soporten las funciones de descifrado que corresponden a la función ENCRYPT. Por lo tanto, el duplicado de columnas con datos cifrados sólo se debe realizar en servidores que soporten la función DECRYPT_BIN o DECRYPT_CHAR. Ejemplos: Ejemplo 1: Este ejemplo utiliza el valor de ENCRYPTION PASSWORD para retener la contraseña de cifrado. SET ENCRYPTION PASSWORD = ’Ben123’; INSERT INTO EMP(SSN) VALUES ENCRYPT(’289-46-8832’); Ejemplo 2: Este ejemplo pasa explícitamente la contraseña de cifrado. INSERT INTO EMP(SSN) VALUES ENCRYPT(’289-46-8832’,’Ben123’); Ejemplo 3: La indicación ’Océano’ se almacena para ayudar al usuario a recordar la contraseña de cifrado de ’Pacífico’. INSERT INTO EMP(SSN) VALUES ENCRYPT(’289-46-8832’,’Pacífico’,’Océano’); Información relacionada: v “DECRYPT_BIN y DECRYPT_CHAR” en la página 353 v “GETHINT” en la página 389 384 Consulta de SQL, Volumen 1
- 411. EVENT_MON_STATE EVENT_MON_STATE ( expresión-serie ) El esquema es SYSIBM. La función EVENT_MON_STATE devuelve el estado actual de un supervisor de sucesos. El argumento es una expresión de serie con un tipo resultante de CHAR o VARCHAR y un valor que es el nombre de un supervisor de sucesos. Si el supervisor de sucesos nombrado no existe en la tabla del catálogo SYSCAT.EVENTMONITORS, se devolverá SQLSTATE 42704. El resultado es un entero con uno de los valores siguientes: v 0 El supervisor de sucesos está inactivo. 1 El supervisor de sucesos está activo. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplo: v El siguiente ejemplo selecciona todos los supervisores de sucesos definidos e indica si cada uno está activo o inactivo: SELECT EVMONNAME, CASE WHEN EVENT_MON_STATE(EVMONNAME) = 0 THEN ’Inactivo’ WHEN EVENT_MON_STATE(EVMONNAME) = 1 THEN ’Activo’ END FROM SYSCAT.EVENTMONITORS Capítulo 3. Funciones 385
- 412. EXP EXP ( expresión ) El esquema es SYSFUN. Devuelve la función exponencial del argumento. El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 386 Consulta de SQL, Volumen 1
- 413. FLOAT FLOAT ( expresión-numérica ) El esquema es SYSIBM. La función FLOAT devuelve una representación de coma flotante de un número. FLOAT es sinónimo de DOUBLE. Información relacionada: v “” en la página 380 Capítulo 3. Funciones 387
- 414. FLOOR FLOOR ( expresión ) El esquema es SYSIBM. (La versión SYSFUN de la función FLOOR continúa estando disponible). Devuelve el valor del entero más grande que es menor o igual que el argumento. El resultado de la función tiene el mismo tipo de datos y el mismo atributo de longitud que el argumento, con la excepción de que la escala es 0 si el argumento es DECIMAL. Por ejemplo, un argumento con un tipo de datos de DECIMAL(5,5) devuelve DECIMAL(5,0). El resultado puede ser nulo si el argumento puede ser nulo o la base de datos está configurada con DFT_SQLMATHWARN establecido en YES; el resultado es el valor nulo si el argumento es nulo. 388 Consulta de SQL, Volumen 1
- 415. GETHINT GETHINT ( datos-cifrados ) El esquema es SYSIBM. La función GETHINT devolverá la indicación de contraseña si se encuentra alguna en datos-cifrados. Una indicación de contraseña es una expresión que ayuda a los propietarios de datos a recordar las contraseñas (por ejemplo, ’Océano’ como indicación para recordar ’Pacífico’). datos-cifrados Una expresión que devuelve un valor CHAR FOR BIT DATA o VARCHAR FOR BIT DATA que es una serie de datos cifrada completa. La serie de datos se tiene que haber cifrado utilizando la función ENCRYPT (SQLSTATE 428FE). El resultado de la función es VARCHAR(32). El resultado puede ser nulo; si la función ENCRYPT no ha añadido el parámetro de indicación a los datos-cifrados o el primer argumento es nulo, el resultado será el valor nulo. Ejemplo: En este ejemplo se almacena la indicación ’Océano’ para ayudar al usuario a recordar la contraseña de cifrado ’Pacífico’. INSERT INTO EMP (SSN) VALUES ENCRYPT(’289-46-8832’, ’Pacífico’,’Océano’); SELECT GETHINT(SSN) FROM EMP; El valor devuelto es ’Océano’. Información relacionada: v “DECRYPT_BIN y DECRYPT_CHAR” en la página 353 v “ENCRYPT” en la página 382 Capítulo 3. Funciones 389
- 416. GENERATE_UNIQUE GENERATE_UNIQUE ( ) El esquema es SYSIBM. La función GENERATE_UNIQUE devuelve una serie de caracteres de datos de bits de 13 bytes de longitud (CHAR(13) FOR BIT DATA) que es exclusiva comparada con cualquier otra ejecución de la misma función. (Se utiliza el reloj del sistema para generar la indicación de la Hora Universal Coordinada (UTC) interna junto con el número de partición en la que se ejecuta la función. Los ajustes que retrasan el reloj del sistema real podrían generar valores duplicados). La función se define como no determinista. No hay ningún argumento para esta función (se han de especificar los paréntesis vacíos). El resultado de la función es un valor exclusivo que incluye el formato interno de la Hora universal coordinada (UTC) y el número de partición en la que se ha procesado la función. El resultado no puede ser nulo. El resultado de esta función se puede utilizar para proporcionar valores exclusivos en una tabla. Cada valor sucesivo será mayor que el valor anterior, proporcionando una secuencia que se puede utilizar en una tabla. El valor incluye el número de partición en el que se ha ejecutado la función para que una tabla particionada en múltiples particiones también tenga valores exclusivos en algunas secuencias. La secuencia se basa en la hora en que se ha ejecutado la función. Esta función difiere de la utilización del registro especial CURRENT TIMESTAMP en que se genera un valor exclusivo para cada fila de una sentencia de inserción de múltiples filas o en una sentencia de inserción con una selección completa. El valor de indicación de fecha y hora que forma parte del resultado de esta función puede determinarse utilizando la función escalar TIMESTAMP con el resultado de GENERATE_UNIQUE como argumento. Ejemplos: v Cree una tabla que incluya una columna que sea exclusiva para cada fila. Llene esta columna utilizando la función GENERATE_UNIQUE. Tenga en cuenta que la columna UNIQUE_ID tiene especificado ″FOR BIT DATA″ para identificar la columna como una serie de caracteres de datos de bits. 390 Consulta de SQL, Volumen 1
- 417. CREATE TABLE EMP_UPDATE (UNIQUE_ID CHAR(13) FOR BIT DATA, EMPNO CHAR(6), TEXT VARCHAR(1000)) INSERT INTO EMP_UPDATE VALUES (GENERATE_UNIQUE(), ’000020’, ’Actualizar entrada...’), (GENERATE_UNIQUE(), ’000050’, ’Actualizar entrada...’) Esta tabla tendrá un identificador exclusivo para cada fila siempre que la columna UNIQUE_ID se establezca siempre utilizando GENERATE_UNIQUE. Esto se puede realizar introduciendo un activador en la tabla. CREATE TRIGGER EMP_UPDATE_UNIQUE NO CASCADE BEFORE INSERT ON EMP_UPDATE REFERENCING NEW AS NEW_UPD FOR EACH ROW MODE DB2SQL SNEW_UPD.UNIQUE_ID = GENERATE_UNIQUE() Con este activador definido, la sentencia INSERT anterior se emitiría sin la primera columna, tal como se indica a continuación. INSERT INTO EMP_UPDATE (EMPNO, TEXT) VALUES (’000020’, ’Actualizar entrada 1...’), (’000050’, ’Actualizar entrada 2...’) Puede devolverse la indicación de fecha y hora (en UTC) para el momento en que se ha añadido una fila a EMP_UPDATE utilizando: SELECT TIMESTAMP (UNIQUE_ID), EMPNO, TEXT FROM EMP_UPDATE Por lo tanto, no hay necesidad de tener una columna de indicación de fecha y hora en la tabla para registrar el momento en que se ha insertado una fila. Capítulo 3. Funciones 391
- 418. GRAPHIC GRAPHIC ( expresión-gráfica ) , entero El esquema es SYSIBM. La función GRAPHIC devuelve una representación de serie gráfica de longitud fija de: v Una serie gráfica, si el primer argumento es cualquier tipo de serie gráfica v Un valor de fecha y hora (sólo para bases de datos Unicode), si el primer argumento es una fecha, una hora o una indicación de fecha y hora. expresión-gráfica Una expresión que devuelve un valor que es una serie gráfica. entero Un valor entero que especifica el atributo de longitud del tipo de datos GRAPHIC resultante. El valor debe estar entre 1 y 127. Si no se especifica entero, la longitud del resultado es la misma que la longitud del primer argumento. El resultado de la función es GRAPHIC. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. De fecha y hora a gráfico: GRAPHIC ( expresión-fechahora ) , ISO USA EUR JIS LOCAL De fecha y hora a gráfico expresión-fechahora Una expresión que es de uno de los tres tipos de datos siguientes fecha El resultado es la representación de serie gráfica de la fecha en el formato especificado por el segundo argumento. La longitud del resultado es 10. Se produce un error si se especifica el segundo argumento y no es un valor válido (SQLSTATE 42703). hora El resultado es la representación de serie gráfica de la hora en el formato especificado por el segundo 392 Consulta de SQL, Volumen 1
- 419. argumento. La longitud del resultado es 8. Se produce un error si se especifica el segundo argumento y no es un valor válido (SQLSTATE 42703). indicación de fecha y hora El segundo argumento no es aplicable y no se debe especificar (SQLSTATE 42815). El resultado es la representación de serie gráfica de la indicación de fecha y hora. La longitud del resultado es 26. La página de códigos de la serie es la página de códigos de la base de datos en el servidor de aplicaciones. Capítulo 3. Funciones 393
- 420. HASHEDVALUE HASHEDVALUE ( nombre-columna ) El esquema es SYSIBM. La función HASHEDVALUE devuelve el índice de mapa de particionamiento de la fila obtenido mediante la aplicación de la función de partición en el valor de clave de particionamiento de la fila. Por ejemplo, si se utiliza en una cláusula SELECT, devuelve el índice de mapa de particionamiento de cada fila de la tabla que se ha utilizado para formar el resultado de la sentencia SELECT. El índice de mapa de particionamiento devuelto en las tablas y variables de transición procede de los valores de transición actuales de las columnas de claves de particionamiento. Por ejemplo, en un activador BEFORE INSERT, la función devolverá el índice de mapa de particionamiento proyectado teniendo en cuenta los valores actuales de las nuevas variables de transición. No obstante, un activador BEFORE INSERT subsiguiente puede modificar los valores de las columnas de claves de particionamiento. De este modo, el índice de mapa de particionamiento final de la fila cuando se inserte en la base de datos puede ser diferente del valor proyectado. El argumento debe ser el nombre calificado o no calificado de una columna de una tabla. La columna puede tener cualquier tipo de datos. (Esta función no puede utilizarse como una función fuente cuando se crea una función definida por el usuario. Como acepta cualquier tipo de datos como argumento, no es necesario crear signaturas adicionales para dar soporte a los tipos diferenciados definidos por el usuario). Si nombre-columna hace referencia a una columna de una vista, la expresión de la vista para la columna debe hacer referencia a una columna de la tabla base principal y la vista debe ser suprimible. Una expresión de tabla anidada o común sigue las mismas reglas que una vista. La fila específica (y la tabla) para la que la función HASHEDVALUE devuelve el índice de mapa de particionamiento se determina por el contexto de la sentencia de SQL que utiliza la función. El tipo de datos del resultado es INTEGER en el rango de 0 a 4095. Para una tabla sin clave de particionamiento, el resultado siempre es 0. No se devuelve nunca un valor nulo. Puesto que se devuelve información a nivel de fila, los resultados son los mismos, sin tener en cuenta las columnas que se especifican para la tabla. 394 Consulta de SQL, Volumen 1
- 421. La función HASHEDVALUE no puede utilizarse en tablas duplicadas, dentro de restricciones de comprobación ni en la definición de columnas generadas (SQLSTATE 42881). Para compatibilidad con versiones anteriores a la Versión 8, el nombre de función PARTITION puede sustituirse por HASHEDVALUE. Ejemplo: v Liste los números de empleado (EMPNO) de la tabla EMPLOYEE para todas las filas con un índice de mapa de particionamiento de 100. SELECT EMPNO FROM EMPLOYEE WHERE HASHEDVALUE(PHONENO) = 100 v Anote el número de empleado y el índice de mapa de particionamiento previsto de la nueva fila en una tabla denominada EMPINSERTLOG2 para cualquier inserción de empleados creando un activador BEFORE en la tabla EMPLOYEE. CREATE TRIGGER EMPINSLOGTRIG2 BEFORE INSERT ON EMPLOYEE REFERENCING NEW AW NEWTABLE FOR EACH MODE ROW MODE DB2SQL INSERT INTO EMPINSERTLOG2 VALUES(NEWTABLE.EMPNO, HASHEDVALUE(NEWTABLE.EMPNO)) Información relacionada: v “CREATE VIEW sentencia” en la publicación Consulta de SQL, Volumen 2 Capítulo 3. Funciones 395
- 422. HEX HEX ( expresión ) El esquema es SYSIBM. La función HEX devuelve una representación hexadecimal de un valor como una serie de caracteres. El argumento puede ser una expresión que sea un valor de cualquier tipo de datos interno, con una longitud máxima de 16.336 bytes. El resultado de la función es una serie de caracteres. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. La página de códigos es la página de códigos de la base de datos. El resultado es una serie de dígitos hexadecimales. Los dos primeros bytes representan el primer byte del argumento, los dos siguientes el segundo byte del argumento, etcétera. Si el argumento es un valor de indicación de fecha y hora o un valor numérico el resultado es la representación hexadecimal del formato interno del argumento. La representación hexadecimal que se devuelve puede ser diferente según el servidor de aplicaciones donde se ejecuta la función. Los casos en que las diferencias pueden ser evidentes son: v Los argumentos de serie de caracteres cuando se ejecuta la función HEX en un cliente ASCII con un servidor EBCDIC o en un cliente EBCDIC con un servidor ASCII. v Los argumentos numéricos (en algunos casos) cuando se ejecuta la función HEX donde los sistemas cliente y servidor tienen distintas clasificaciones de bytes para los valores numéricos. El tipo y la longitud del resultado varían basándose en el tipo y la longitud de los argumentos de serie de caracteres. v Serie de caracteres – Longitud fija no mayor que 127 - El resultado es una serie de caracteres de longitud fija el doble de la longitud definida del argumento. – Longitud fija mayor que 127 - El resultado es una serie de caracteres de longitud variable el doble de la longitud definida del argumento. – Longitud variable 396 Consulta de SQL, Volumen 1
- 423. - El resultado es una serie de caracteres de longitud variable con una longitud máxima el doble de la longitud máxima definida del argumento. v Serie gráfica – Longitud fija no mayor que 63 - El resultado es una serie de caracteres de longitud fija cuatro veces la longitud definida del argumento. v Longitud fija mayor que 63 – El resultado es una serie de caracteres de longitud variable cuatro veces la longitud definida del argumento. v Longitud variable – El resultado es una serie de caracteres de longitud variable con una longitud máxima cuatro veces la longitud máxima definida del argumento. Ejemplos: Suponga que utiliza un servidor de aplicaciones DB2 para AIX en los ejemplos siguientes. v Utilizando la tabla DEPARTMENT establezca la variable del lenguaje principal HEX_MGRNO (char(12)) en la representación hexadecimal del número del director (MGRNO) para el departamento ‘PLANNING’ (DEPTNAME). SELECT HEX(MGRNO) INTO :HEX_MGRNO FROM DEPARTMENT WHERE DEPTNAME = ’PLANNING’ HEX_MGRNO se establecerá en ’303030303230’ cuando se utilice la tabla de ejemplo (el valor de caracteres es ’000020’). v Suponga que COL_1 es una columna con un tipo de datos de char(1) y un valor de 'B'. La representación hexadecimal de la letra 'B' es X'42'. HEX(COL_1) devuelve una serie de dos caracteres '42'. v Suponga que COL_3 es una columna con un tipo de datos de decimal(6,2) y un valor de 40,1. Una serie de ocho caracteres '0004010C' es el resultado de aplicar la función HEX a la representación interna del valor decimal 40,1. Capítulo 3. Funciones 397
- 424. HOUR HOUR ( expresión ) El esquema es SYSIBM. La función HOUR devuelve la parte correspondiente a la hora de un valor. El argumento debe ser una hora, una indicación de fecha y hora, una duración de hora, una duración de indicación de fecha y hora o una representación de serie de caracteres válida de una hora o de una fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una hora, una indicación de fecha y hora o una representación de serie válida de una hora o de una fecha y hora: – El resultado es la parte correspondiente a la hora del valor, que es un entero entre 0 y 24. v Si el argumento es una duración de hora o una duración de indicación de fecha y hora: – El resultado es la parte correspondiente a la hora del valor, que es un entero entre −99 y 99. El resultado que no es cero tiene el mismo signo que el argumento. Ejemplo: Utilizando la tabla de ejemplo CL_SCHED, seleccione todas las clases que empiezan por la tarde. SELECT * FROM CL_SCHED WHERE HOUR(STARTING) BETWEEN 12 AND 17 398 Consulta de SQL, Volumen 1
- 425. IDENTITY_VAL_LOCAL IDENTITY_VAL_LOCAL ( ) El esquema es SYSIBM. La función IDENTITY_VAL_LOCAL es una función no determinista que devuelve el valor asignado más recientemente de una columna de identidad, donde la asignación se ha producido como resultado de una sentencia de inserción (INSERT) de fila individual utilizando una cláusula VALUES. La función no tiene parámetros de entrada. El resultado es un DECIMAL(31,0), independientemente del tipo de datos real de la columna de identidad correspondiente. El valor devuelto por la función es el valor asignado a la columna de identidad de la tabla identificada en la sentencia INSERT de fila individual más reciente. La sentencia INSERT debe contener una cláusula VALUES en una tabla que contenga una columna de identidad. La sentencia INSERT también debe ejecutarse al mismo nivel; es decir, el valor debe estar disponible localmente en el nivel al que se ha asignado, hasta que se sustituya por el siguiente valor asignado. (Se inicia un nivel nuevo cada vez que se invoca un activador o una rutina). El valor asignado es un valor proporcionado por el usuario (si la columna de identidad está definida como GENERATED BY DEFAULT) o un valor de identidad generado por DB2. La función devuelve un valor nulo en las situaciones siguientes: v Cuando no se ha emitido una sentencia INSERT de fila individual con una cláusula VALUES en el nivel de proceso actual para una tabla que contiene una columna de identidad. v Cuando se ha producido una operación COMMIT o ROLLBACK de una unidad de trabajo desde que se emitió la sentencia INSERT más reciente que asignó un valor. (A menos que se desactive la confirmación automática, las interfaces que realizan confirmaciones automáticas después de cada sentencia devolverán un valor nulo cuando se invoque la función en sentencias independientes). El resultado de la función no queda afectado por lo siguiente: v Una sentencia INSERT de fila individual con una cláusula VALUES para una tabla sin columna de identidad. v Una sentencia INSERT de múltiples filas con una cláusula VALUES. v Una sentencia INSERT con una selección completa. Capítulo 3. Funciones 399
- 426. v Una sentencia ROLLBACK TO SAVEPOINT. Notas: v Las expresiones de la cláusula VALUES de una sentencia INSERT se evalúan antes que las asignaciones para las columnas de destino de la sentencia INSERT. Por consiguiente, una invocación de una función IDENTITY_VAL_LOCAL en la cláusula VALUES de una sentencia INSERT utilizará el valor asignado más recientemente de una columna de identidad de una sentencia INSERT anterior. La función devuelve el valor nulo si no se ha ejecutado ninguna sentencia INSERT de fila individual anterior con una cláusula VALUES para una tabla que contiene una columna de identidad dentro del mismo nivel que la función IDENTITY_VAL_LOCAL. v El valor de columna de identidad de la tabla para la que se define el activador puede determinarse dentro de un activador, haciendo referencia a la variable de transición activador para la columna de identidad. v El resultado de la invocación de la función IDENTITY_VAL_LOCAL desde dentro de la condición activador de un activador de inserción es un valor nulo. v Es posible que existan múltiples activadores de inserción anteriores o posteriores para una tabla. En este caso, cada activador se procesa por separado y los valores de identidad asignados por una acción activada no están disponibles para las demás acciones activadas utilizando la función IDENTITY_VAL_LOCAL. Esto es válido incluso aunque las múltiples acciones activadas estén definidas conceptualmente al mismo nivel. v Generalmente no es recomendable utilizar la función IDENTITY_VAL_LOCAL en el cuerpo de un activador anterior (before) de inserción. El resultado de la invocación de la función IDENTITY_VAL_LOCAL desde dentro de la acción activada de un activador de inserción anterior es el valor nulo. El valor de la columna de identidad de la tabla para la que se ha definido el activador no se puede obtener invocando la función IDENTITY_VAL_LOCAL en la acción activada de un activador de inserción anterior. Sin embargo, el valor de la columna de identidad puede obtenerse en la acción activada, haciendo referencia a la variable de transición activador para la columna de identidad. v El resultado de invocar la función IDENTITY_VAL_LOCAL desde la acción activada de un activador posterior (after) de inserción es el valor asignado a una columna de identidad de la tabla identificada en la sentencia INSERT de fila individual más reciente invocada en la misma acción activada que tenía una cláusula VALUES para una tabla que contenía una columna de identidad. (Esto se aplica a los activadores posteriores (after) de inserción FOR EACH ROW y FOR EACH STATEMENT). Si, antes de la invocación de la función IDENTITY_VAL_LOCAL, no se ha ejecutado una sentencia 400 Consulta de SQL, Volumen 1
- 427. INSERT de fila individual con una cláusula VALUES para una tabla que contiene una columna de identidad dentro de la misma acción activada, la función devolverá un valor nulo. v Dado que los resultados de la función IDENTITY_VAL_LOCAL no son deterministas, el resultado de una invocación de la función IDENTITY_VAL_LOCAL dentro de la sentencia SELECT de un cursor puede variar para cada sentencia FETCH. v El valor asignado es el valor realmente asignado a la columna de identidad (es decir, el valor que se devolverá en una sentencia SELECT subsiguiente). Este valor no es necesariamente el valor proporcionado en la cláusula VALUES de la sentencia INSERT o un valor generado por DB2. El valor asignado puede ser un valor especificado en una sentencia de variable de transición SET, dentro del cuerpo de un activador de inserción anterior, para una variable de transición activador asociada con la columna de identidad. v El valor devuelto por la función es imprevisible después de una operación INSERT de fila individual anómala con una cláusula VALUES en una tabla con una columna de identidad. El valor puede ser el valor que se devolvería de la función si ésta se hubiera invocado antes del INSERT anómalo o puede ser el valor que se asignaría si el INSERT hubiera sido satisfactorio. El valor real devuelto depende del punto de anomalía y, por consiguiente, es imprevisible. Ejemplos: Ejemplo 1: Establezca la variable IVAR en el valor asignado a la columna de identidad de la tabla EMPLOYEE. Si esta inserción es la primera en la tabla EMPLOYEE, IVAR tendrá un valor de 1. CREATE TABLE EMPLOYEE (EMPNO INTEGER GENERATED ALWAYS AS IDENTITY, NAME CHAR(30), SALARY DECIMAL(5,2), DEPTNO SMALLINT) Ejemplo 2: Una función IDENTITY_VAL_LOCAL invocada en una sentencia INSERT devuelve el valor asociado con la sentencia INSERT de fila individual anterior, con una cláusula VALUES para una tabla con una columna de identidad. Para este ejemplo suponga que existen dos tablas, T1 y T2. T1 y T2 tienen una columna de identidad llamada C1. DB2 genera valores en secuencia, empezando por 1, para la columna C1 de la tabla T1 y valores en secuencia, empezando por 10, para la columna C1 de la tabla T2. CREATE TABLE T1 (C1 INTEGER GENERATED ALWAYS AS IDENTITY, C2 INTEGER) CREATE TABLE T2 Capítulo 3. Funciones 401
- 428. (C1 DECIMAL(15,0) GENERATED BY DEFAULT AS IDENTITY (START WITH 10), C2 INTEGER) INSERT INTO T1 (C2) VALUES (5) INSERT INTO T1 (C2) VALUES (6) SELECT * FROM T1 lo que da un resultado de: C1 C2 ----------- ---------- 1 5 2 6 y ahora, declarando la función para la variable IVAR: VALUES IDENTITY_VAL_LOCAL() INTO :IVAR En este punto, la función IDENTITY_VAL_LOCAL devolverá un valor de 2 en IVAR, porque ése es el valor que DB2 ha asignado más recientemente. La sentencia INSERT siguiente inserta una fila individual en T2, donde la columna C2 obtiene un valor de 2 de la función IDENTITY_VAL_LOCAL. INSERT INTO T2 (C2) VALUES (IDENTITY_VAL_LOCAL()) SELECT * FROM T2 WHERE C1 = DECIMAL(IDENTITY_VAL_LOCAL(),15,0) lo que devuelve un resultado de: C1 C2 ----------------- ---------- 10. 2 La invocación de la función IDENTITY_VAL_LOCAL después de esta inserción produce un valor de 10, que es el valor generado por DB2 para la columna C1 de T2. En un entorno anidado que incluya un activador, utilice la función IDENTITY_VAL_LOCAL para recuperar el valor de identidad asignado en un nivel determinado, incluso aunque puedan haber valores de identidad asignados en niveles inferiores. Suponga que existen tres tablas, EMPLOYEE, EMP_ACT y ACCT_LOG. Hay un activador de inserción posterior definido en EMPLOYEE que produce inserciones adicionales en las tablas EMP_ACT y ACCT_LOG. CREATE TABLE EMPLOYEE (EMPNO SMALLINT GENERATED ALWAYS AS IDENTITY (START WITH 1000), NAME CHAR(30), SALARY DECIMAL(5,2), DEPTNO SMALLINT); 402 Consulta de SQL, Volumen 1
- 429. CREATE TABLE EMP_ACT (ACNT_NUM SMALLINT GENERATED ALWAYS AS IDENTITY (START WITH 1), EMPNO SMALLINT); CREATE TABLE ACCT_LOG (ID SMALLINT GENERATED ALWAYS AS IDENTITY (START WITH 100), ACNT_NUM SMALLINT, EMPNO SMALLINT); CREATE TRIGGER NEW_HIRE AFTER INSERT ON EMPLOYEE REFERENCING NEW AS NEW_EMP FOR EACH ROW MODE DB2SQL BEGIN ATOMIC INSERT INTO EMP_ACT (EMPNO) VALUES (NEW_EMP.EMPNO); INSERT INTO ACCT_LOG (ACNT_NUM EMPNO) VALUES (IDENTITY_VAL_LOCAL(), NEW_EMP.EMPNO); END La primera sentencia INSERT activada inserta una fila en la tabla EMP_ACT. Esta sentencia INSERT utiliza una variable de transición activador para la columna EMPNO de la tabla EMPLOYEE, para indicar que el valor de identidad para la columna EMPNO de la tabla EMPLOYEE debe copiarse en la columna EMPNO de la tabla EMP_ACT. La función IDENTITY_VAL_LOCAL no se ha podido utilizar para obtener el valor asignado a la columna EMPNO de la tabla EMPLOYEE. Esto se debe a que no se ha emitido una sentencia INSERT en este nivel del anidamiento y, por lo tanto, si se hubiera invocado la función IDENTITY_VAL_LOCAL en la cláusula VALUES de INSERT para EMP_ACT, se hubiera devuelto un valor nulo. Esta sentencia INSERT para la tabla EMP_ACT también hace que se genere un nuevo valor de columna de identidad para la columna ACNT_NUM. Una segunda sentencia INSERT activada inserta una fila en la tabla ACCT_LOG. Esta sentencia invoca la función IDENTITY_VAL_LOCAL para indicar que el valor de identidad asignado a la columna ACNT_NUM de la tabla EMP_ACT en la sentencia INSERT anterior de la acción activada debe copiarse en la columna ACNT_NUM de la tabla ACCT_LOG. A la columna EMPNO se le asigna el mismo valor que a la columna EMPNO de la tabla EMPLOYEE. Desde la aplicación que realiza la invocación (es decir, el nivel en el que se emite INSERT en EMPLOYEE), establezca la variable IVAR en el valor asignado a la columna EMPNO de la tabla EMPLOYEE por la sentencia INSERT original. INSERT INTO EMPLOYEE (NAME, SALARY, DEPTNO) VALUES (’Rupert’, 989.99, 50); Capítulo 3. Funciones 403
- 430. El contenido de las tres tablas después de procesar la sentencia INSERT original y todas las acciones activadas es: SELECT EMPNO, SUBSTR(NAME,10) AS NAME, SALARY, DEPTNO FROM EMPLOYEE; EMPNO NAME SALARY DEPTNO ----------- ----------- ---------------------------------- ----------- 1000 Rupert 989.99 50 SELECT ACNT_NUM, EMPNO FROM EMP_ACT; ACNT_NUM EMPNO ----------- ----------- 1 1000 SELECT * FROM ACCT_LOG; ID ACNT_NUM EMPNO ----------- ----------- ----------- 100 1 1000 El resultado de la función IDENTITY_VAL_LOCAL es el valor asignado más recientemente para una columna de identidad en el mismo nivel de anidamiento. Después de procesar la sentencia INSERT original y todas las acciones activadas, la función IDENTITY_VAL_LOCAL devuelve un valor de 1000, porque éste es el valor asignado a la columna EMPNO de la tabla EMPLOYEE. La sentencia VALUES siguiente hace que IVAR se establezca en 1000. La inserción en la tabla EMP_ACT (que se ha producido después de la inserción en la tabla EMPLOYEE y a un nivel de anidamiento inferior) no tiene ningún efecto en lo que devuelve esta invocación de la función IDENTITY_VAL_LOCAL. VALUES IDENTITY_VAL_LOCAL() INTO :IVAR; Ejemplos relacionados: v “fnuse.out -- HOW TO USE BUILT-IN SQL FUNCTIONS (C)” v “fnuse.sqc -- How to use built-in SQL functions (C)” v “fnuse.out -- HOW TO USE FUNCTIONS (C++)” v “fnuse.sqC -- How to use built-in SQL functions (C++)” 404 Consulta de SQL, Volumen 1
- 431. INSERT INSERT ( expresión1 , expresión2 , expresión3 , expresión4 ) El esquema es SYSFUN. Devuelve una serie en la que se han suprimido expresión3 bytes de expresión1, empezando en la expresión2 y donde se ha insertado la expresión4 en la expresión1 empezando en la expresión2. Si la longitud de la serie del resultado excede el máximo para el tipo de retorno, se produce un error (SQLSTATE 38552). El primer argumento es una serie de caracteres o un tipo de serie binaria. El segundo argumento y el tercero deben ser un valor numérico con un tipo de datos SMALLINT o INTEGER. Si el primer argumento es una serie de caracteres, entonces el cuarto argumento también ha de ser una serie de caracteres. Si el primer argumento es una serie binaria, entonces el cuarto argumento también ha de ser una serie binaria. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB o serie binaria la longitud máxima es de 1.048.576 bytes. Para el primer y cuarto argumentos, CHAR se convierte a VARCHAR y LONG VARCHAR a CLOB(1M); para el segundo y tercer argumentos, SMALLINT se convierte a INTEGER para que lo procese la función. El resultado se basa en los tipos de argumentos tal como sigue: v VARCHAR(4000) si el primer argumento y el cuarto son VARCHAR (no exceden de 4.000 bytes) o CHAR v CLOB(1M) si el primer argumento o el cuarto es CLOB o LONG VARCHAR v BLOB(1M) si el primer argumento y el cuarto son BLOB. El resultado puede ser nulo; si cualquier argumento es nulo, el resultado es el valor nulo. Ejemplo: v Suprima un carácter de la palabra ’DINING’ e inserte ’VID’, empezando en el tercer carácter. VALUES CHAR(INSERT(’DINING’, 3, 1, ’VID’), 10) Este ejemplo devuelve lo siguiente: 1 ---------- DIVIDING Capítulo 3. Funciones 405
- 432. Tal como se menciona, el resultado de la función INSERT es VARCHAR(4000). En este ejemplo, se ha utilizado la función CHAR para limitar la salida de INSERT a 10 bytes. La ubicación inicial de una serie en particular se puede encontrar utilizando la función LOCATE. Información relacionada: v “LOCATE” en la página 416 406 Consulta de SQL, Volumen 1
- 433. INTEGER INTEGER ( expresión-numérica ) INT expresión-caracteres expresión-fecha expresión-hora El esquema es SYSIBM. La función INTEGER devuelve una representación entera de un número, serie de caracteres, fecha u hora en forma de una constante entera. expresión-numérica Una expresión que devuelve un valor de cualquier tipo de datos numérico interno. Si el argumento es una expresión-numérica, el resultado es el mismo número que sería si el argumento se asignase a una columna o variable de enteros grandes. Si la parte correspondiente a los enteros del argumento no está dentro del rango de enteros, se produce un error. La parte correspondiente a los decimales del argumento se trunca si está presente. expresión-caracteres Una expresión que devuelve un valor de serie de caracteres de longitud no mayor que la longitud máxima de una constante de caracteres. Se eliminan los blancos iniciales y de cola y la serie resultante debe ajustarse a las reglas para la formación de una constante de enteros SQL (SQLSTATE 22018). La serie de caracteres no puede ser una serie larga. Si el argumento es una expresión-caracteres, el resultado es el mismo número que sería si la constante de enteros correspondiente se asignase a una columna o variable de enteros grandes. expresión-fecha Una expresión que devuelve un valor del tipo de datos DATE. El resultado es un valor INTEGER que representa la fecha como aaaammdd. expresión-hora Una expresión que devuelve un valor del tipo de datos TIME. El resultado es un valor INTEGER que representa la hora como hhmmss. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplos: v Utilizando la tabla EMPLOYEE, seleccione una lista que contenga el salario (SALARY) dividido por el nivel de formación (EDLEVEL). Trunque Capítulo 3. Funciones 407
- 434. cualquier decimal en el cálculo. La lista también debe contener los valores utilizados en el cálculo y el número de empleado (EMPNO). La lista debe estar en orden descendente del valor calculado. SELECT INTEGER (SALARY / EDLEVEL), SALARY, EDLEVEL, EMPNO FROM EMPLOYEE ORDER BY 1 DESC v Utilizando la tabla EMPLOYEE, seleccione la columna EMPNO en el formato de enteros para procesarla más en la aplicación. SELECT INTEGER(EMPNO) FROM EMPLOYEE v Suponga que la columna BIRTHDATE (fecha) tiene un valor interno equivalente a ’1964-07-20’. INTEGER(BIRTHDATE) da como resultado el valor 19 640 720. v Suponga que la columna STARTTIME (hora) tiene un valor interno equivalente a ’12:03:04’. INTEGER(STARTTIME) da como resultado el valor 120 304. 408 Consulta de SQL, Volumen 1
- 435. JULIAN_DAY JULIAN_DAY ( expresión ) El esquema es SYSFUN. Devuelve un valor entero que representa el número de días desde el 1 de enero de 4712 A.C. (el inicio del calendario Juliano) hasta el valor de la fecha especificada en el argumento. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o de una indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 409
- 436. LCASE o LOWER LCASE ( expresión-serie ) LOWER El esquema es SYSIBM. (La versión SYSFUN de esta función continúa estando disponible con el soporte para los argumentos LONG VARCHAR y CLOB). Las funciones LCASE o LOWER devuelve una serie en la cual todos los caracteres SBCS se han convertido a minúsculas (es decir, los caracteres de la A a la Z se convertirán en los caracteres de la a a la z, y los caracteres con signos diacríticos se convertirán a sus minúsculas equivalentes, si existen. Por ejemplo, en la página de códigos 850, É se correlaciona con é). Puesto que no se convierten todos los caracteres, LCASE(UCASE(expresión-serie)) no devuelve necesariamente el mismo resultado que LCASE(expresión-serie). El argumento debe ser una expresión cuyo valor sea un tipo de datos CHAR o VARCHAR. El resultado de la función tiene el mismo tipo de datos y el mismo atributo de longitud que el argumento. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Notas: Esta función se ha ampliado para reconocer las propiedades de minúsculas y mayúsculas de un carácter Unicode. En una base de datos Unicode, todos los caracteres Unicode se convierten correctamente a minúsculas. Ejemplo: Asegúrese de que los caracteres del valor de la columna JOB de la tabla EMPLOYEE se devuelvan en minúsculas. SELECT LCASE(JOB) FROM EMPLOYEE WHERE EMPNO = ’000020’; El resultado es el valor ’director’. Información relacionada: v “Función escalar” en la página 411 410 Consulta de SQL, Volumen 1
- 437. Función escalar LCASE ( expresión ) El esquema es SYSFUN. Devuelve una serie en la que todos los caracteres de la A a la Z se han convertido en caracteres de la a a la z (caracteres con signos diacríticos no convertidos). Tenga en cuenta que, por lo tanto, LCASE(UCASE(serie)) no devolverá necesariamente el mismo resultado que LCASE(serie). El argumento puede ser de cualquier tipo de serie de caracteres interno. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB la longitud máxima es de 1.048.576 bytes. El resultado de la función es: v VARCHAR(4000) si el argumento es VARCHAR (no excede de 4.000 bytes) o CHAR v CLOB(1 M) si el argumento es CLOB o LONG VARCHAR El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 411
- 438. LEFT LEFT ( expresión1 , expresión2 ) El esquema es SYSFUN. Devuelve una serie que consta de los expresión2 bytes situados más a la izquierda de expresión1. El valor expresión1 se rellena con blancos por la derecha para que la subserie especificada de expresión1 exista siempre. El primer argumento es una serie de caracteres o un tipo de serie binaria. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB o serie binaria la longitud máxima es de 1.048.576 bytes. El segundo argumento debe ser del tipo de datos INTEGER o SMALLINT. El resultado de la función es: v VARCHAR(4000) si el argumento es VARCHAR (no excede de 4.000 bytes) o CHAR v CLOB(1 M) si el argumento es CLOB o LONG VARCHAR v BLOB(1 M) si el argumento es BLOB. El resultado puede ser nulo; si cualquier argumento es nulo, el resultado es el valor nulo. 412 Consulta de SQL, Volumen 1
- 439. LENGTH LENGTH ( expresión ) El esquema es SYSIBM. La función LENGTH devuelve la longitud de un valor. El argumento puede ser una expresión que devuelve un valor de cualquier tipo de datos internos. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. El resultado es la longitud del argumento. La longitud no incluye el byte indicador de nulo de los argumentos de columna que permiten valores nulos. La longitud de las series incluyen blancos pero no incluyen el campo de control de longitud de las series de longitud variable. La longitud de una serie de longitud variable es la longitud real, no la longitud máxima. La longitud de una serie gráfica es el número de caracteres DBCS. La longitud de todos los demás valores es el número de bytes utilizados para representar el valor: v 2 para entero pequeño v 4 para entero grande v (p/2)+1 para números decimales con la precisión p v La longitud de la serie para series binarias v La longitud de la serie para series de caracteres v 4 para coma flotante de precisión simple v 8 para coma flotante de precisión doble v 4 para fecha v 3 para hora v 10 para fecha y hora Ejemplos: v Suponga que la variable del lenguaje principal ADDRESS es una serie de caracteres de longitud variable con un valor de '895 Don Mills Road'. LENGTH(:ADDRESS) Devuelve el valor 18. v Suponga que START_DATE es una columna de tipo DATE. Capítulo 3. Funciones 413
- 440. LENGTH(START_DATE) Devuelve el valor 4. v Este ejemplo devuelve el valor 10. LENGTH(CHAR(START_DATE, EUR)) 414 Consulta de SQL, Volumen 1
- 441. LN LN ( expresión ) El esquema es SYSFUN. Devuelve el logaritmo natural del argumento (igual que LOG). El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 415
- 442. LOCATE LOCATE ( expresión1 , expresión2 ) , expresión3 El esquema es SYSFUN. Devuelve la posición inicial de la primera ocurrencia de expresión1 en la expresión2. Si se especifica la expresión3 opcional, indica la posición de los caracteres en expresión2 en la que tiene que empezar la búsqueda. Si no se encuentra la expresión1 en la expresión2, se devuelve el valor 0. Si el primer argumento es una serie de caracteres, entonces el segundo ha de ser una serie de caracteres. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB la longitud máxima es de 1.048.576 bytes. Si el primer argumento es una serie binaria, entonces el segundo argumento debe ser una serie binaria con una longitud máxima de 1.048.576 bytes. El tercer argumento debe ser INTEGER o SMALLINT. El resultado de la función es INTEGER. El resultado puede ser nulo; si cualquier argumento es nulo, el resultado es el valor nulo. Ejemplo: v Busque la ubicación de la letra ’N’ (primera ocurrencia) en la palabra ’DINING’. VALUES LOCATE (’N’, ’DINING’) Este ejemplo devuelve lo siguiente: 1 ----------- 3 416 Consulta de SQL, Volumen 1
- 443. LOG LOG ( expresión ) El esquema es SYSFUN. Devuelve el logaritmo natural del argumento (igual que LN). El argumento puede ser de cualquier tipo de datos interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 417
- 444. LOG10 LOG10 ( expresión ) El esquema es SYSFUN. Devuelve el logaritmo de base 10 del argumento. El argumento puede ser de cualquier tipo numérico interno. Se convierte a un número de coma flotante de precisión doble para que lo procese la función. El resultado de la función es un número de coma flotante de precisión doble. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 418 Consulta de SQL, Volumen 1
- 445. LONG_VARCHAR LONG_VARCHAR ( expresión-serie-caracteres ) El esquema es SYSIBM. La función LONG_VARCHAR devuelve una representación LONG VARCHAR de un tipo de datos de serie de caracteres. expresión-serie-caracteres Una expresión que devuelve un valor que es una serie de caracteres con una longitud máxima de 32 700 bytes. El resultado de la función es LONG VARCHAR. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 419
- 446. LONG_VARGRAPHIC LONG_VARGRAPHIC ( expresión-gráfica ) El esquema es SYSIBM. La función LONG_VARGRAPHIC devuelve una representación LONG VARGRAPHIC de una serie de caracteres de doble byte. expresión-gráfica Una expresión que devuelve un valor que es una serie gráfica con una longitud máxima de 16 350 caracteres de doble byte. El resultado de la función es LONG VARGRAPHIC. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. 420 Consulta de SQL, Volumen 1
- 447. LTRIM LTRIM ( expresión-serie ) El esquema es SYSIBM. (La versión SYSFUN de esta función continúa estando disponible con el soporte para los argumentos LONG VARCHAR y CLOB). La función LTRIM elimina los blancos del principio de la expresión-serie. El argumento puede ser un tipo de datos CHAR, VARCHAR, GRAPHIC o VARGRAPHIC. v Si el argumento es una serie gráfica de una base de datos DBCS o EUC, se eliminan los blancos de doble byte iniciales. v Si el argumento es una serie gráfica de una base de datos Unicode, se eliminan los blancos UCS-2 iniciales. v De lo contrario, se eliminan los blancos de un solo byte iniciales. El tipo de datos del resultado de la función es: v VARCHAR si el tipo de datos de expresión-serie es VARCHAR o CHAR v VARGRAPHIC si el tipo de datos de expresión-serie es VARGRAPHIC o GRAPHIC El parámetro de longitud del tipo devuelto es el mismo que el parámetro de longitud del tipo de datos del argumento. La longitud real del resultado para las series de caracteres es la longitud de expresión-serie menos el número de bytes eliminados debido a caracteres en blanco. La longitud real del resultado para series gráficas es la longitud (en número de caracteres de doble byte) de expresión-serie menos el número de caracteres en blanco de doble byte eliminados. Si elimina todos los caracteres se obtiene una serie vacía de longitud variable (longitud de cero). Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplo: Suponga que la variable del lenguaje principal HELLO está definida como CHAR(9) y tiene el valor de ’ Hola’. VALUES LTRIM(:HELLO) El resultado es ’Hola’. Información relacionada: Capítulo 3. Funciones 421
- 448. v “Función escalar” en la página 423 422 Consulta de SQL, Volumen 1
- 449. Función escalar LTRIM ( expresión ) El esquema es SYSFUN. Devuelve los caracteres del argumento con los blancos iniciales eliminados. El argumento puede ser de cualquier tipo de serie de caracteres interno. Para un VARCHAR la longitud máxima es de 4.000 bytes y para un CLOB la longitud máxima es de 1.048.576 bytes. El resultado de la función es: v VARCHAR(4000) si el argumento es VARCHAR (no excede de 4.000 bytes) o CHAR v CLOB(1 M) si el argumento es CLOB o LONG VARCHAR. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 423
- 450. MICROSECOND MICROSECOND ( expresión ) El esquema es SYSIBM. La función MICROSECOND devuelve la parte correspondiente a los microsegundos de un valor. El argumento debe ser una indicación de fecha y hora, duración de indicación de fecha y hora o una representación de serie de caracteres válida de una indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una indicación de fecha y hora o una representación de serie válida de una indicación de fecha y hora: – El entero está en el rango de 0 a 999 999. v Si el argumento es una duración: – El resultado refleja la parte correspondiente a los microsegundos del valor que es un entero entre −999 999 y 999 999. El resultado que no es cero tiene el mismo signo que el argumento. Ejemplo: v Suponga que una tabla TABLEA contiene dos columnas, TS1 y TS2, del tipo TIMESTAMP. Seleccione todas las filas cuya parte correspondiente a los microsegundos de TS1 no sea cero y las partes correspondientes a los segundos de TS1 y TS2 sean idénticas. SELECT * FROM TABLEA WHERE MICROSECOND(TS1) <> 0 AND SECOND(TS1) = SECOND(TS2) 424 Consulta de SQL, Volumen 1
- 451. MIDNIGHT_SECONDS MIDNIGHT_SECONDS ( expresión ) El esquema es SYSFUN. Devuelve un valor entero en el rango de 0 a 86 400 que representa el número de segundos entre medianoche y el valor de la hora especificado en el argumento. El argumento debe ser una hora, una indicación de fecha y hora o una representación de serie de caracteres válida de una hora o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es INTEGER. El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Ejemplos: v Encuentre el número de segundos entre la medianoche y 00:10:10 y la medianoche y 13:10:10. VALUES (MIDNIGHT_SECONDS(’00:10:10’), MIDNIGHT_SECONDS(’13:10:10’)) Este ejemplo devuelve lo siguiente: 1 2 ----------- ----------- 610 47410 Puesto que un minuto es 60 segundos, hay 610 segundos entre la medianoche y la hora especificada. Es lo mismo para el segundo ejemplo. Hay 3600 segundos en una hora y 60 segundos en un minuto, dando como resultado 47410 segundos entre la hora especificada y la medianoche. v Encuentre el número de segundos entre la medianoche y 24:00:00, y la medianoche y 00:00:00. VALUES (MIDNIGHT_SECONDS(’24:00:00’), MIDNIGHT_SECONDS(’00:00:00’)) Este ejemplo devuelve lo siguiente: 1 2 ----------- ----------- 86400 0 Observe que estos dos valores representan el mismo momento en el tiempo, pero devuelven distintos valores MIDNIGHT_SECONDS. Capítulo 3. Funciones 425
- 452. MINUTE MINUTE ( expresión ) El esquema es SYSIBM. La función MINUTE devuelve la parte correspondiente a los minutos de un valor. El argumento debe ser una hora, una indicación de fecha y hora, una duración de hora, una duración de indicación de fecha y hora o una representación de serie de caracteres válida de una hora o de una fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una hora, una indicación de fecha y hora o una representación de serie válida de una hora o de una fecha y hora: – El resultado es la parte correspondiente a los minutos de un valor, que es un entero entre 0 y 59. v Si el argumento es una duración de hora o una duración de indicación de fecha y hora: – El resultado es la parte correspondiente a los minutos del valor, que es un entero entre −99 y 99. El resultado que no es cero tiene el mismo signo que el argumento. Ejemplo: v Utilizando la tabla de ejemplo CL_SCHED, seleccione todas las clases con una duración inferior a 50 minutos. SELECT * FROM CL_SCHED WHERE HOUR(ENDING - STARTING) = 0 AND MINUTE(ENDING - STARTING) < 50 426 Consulta de SQL, Volumen 1
- 453. MOD MOD ( expresión , expresión ) El esquema es SYSFUN. Devuelve el resto del primer argumento dividido por el segundo argumento. El resultado sólo es negativo si el primer argumento es negativo. El resultado de la función es: v SMALLINT si ambos argumentos son SMALLINT v INTEGER si un argumento es INTEGER y el otro es INTEGER o SMALLINT v BIGINT si un argumento es BIGINT y el otro argumento es BIGINT, INTEGER o SMALLINT. El resultado puede ser nulo; si cualquier argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 427
- 454. MONTH MONTH ( expresión ) El esquema es SYSIBM. La función MONTH devuelve la parte correspondiente al mes de un valor. El argumento debe ser una fecha, una indicación de fecha y hora, una duración de fecha, una duración de indicación de fecha y hora o una representación de válida de una fecha o indicación de fecha y hora en forma de serie que no sea CLOB ni LONG VARCHAR. El resultado de la función es un entero grande. Si el argumento puede ser nulo, el resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Las demás reglas dependen del tipo de datos del argumento: v Si el argumento es una fecha, una indicación de fecha y hora o una representación de serie válida de una fecha o indicación de fecha y hora: – El resultado es la parte correspondiente al mes del valor, que es un entero entre 1 y 12. v Si el argumento es una duración de fecha o duración de indicación de fecha y hora: – El resultado es la parte correspondiente al mes del valor, que es un entero entre −99 y 99. El resultado que no es cero tiene el mismo signo que el argumento. Ejemplo: v Seleccione todas las filas de la tabla EMPLOYEE de las personas que han nacido (BIRTHDATE) en diciembre (DECEMBER). SELECT * FROM EMPLOYEE WHERE MONTH(BIRTHDATE) = 12 428 Consulta de SQL, Volumen 1
- 455. MONTHNAME MONTHNAME ( expresión ) El esquema es SYSFUN. Devuelve una serie de caracteres en mayúsculas y minúsculas mezcladas que contienen el nombre del mes (p. ej., Enero) para la parte del mes del argumento basado en el entorno nacional del momento en que se ha iniciado la base de datos. El argumento debe ser una fecha, una indicación de fecha y hora o una representación de serie de caracteres válida de una fecha o indicación de fecha y hora que no sea CLOB ni LONG VARCHAR. El resultado de la función es VARCHAR(100). El resultado puede ser nulo; si el argumento es nulo, el resultado es el valor nulo. Capítulo 3. Funciones 429
- 456. MQPUBLISH MQPUBLISH ( datos-msj servicio-publicación , política-servicio , ) , tema (1) , id-correl Notas: 1 El id-correl no se puede especificar a no ser que se haya definido un servicio y una política. El esquema es DB2MQ. La función MQPUBLISH publica datos en MQSeries. Esta función requiere la instalación de MQSeries Publish/Subscribe o MQSeries Integrator. Para obtener más detalles, visite http://www.ibm.com/software/MQSeries. La función MQPUBLISH publica los datos contenidos en datos-msj en el publicador de MQSeries especificado en servicio-publicación, utilizando la política de calidad de la política de servicio definida por política-servicio. Se puede especificar un tema opcional para el mensaje y también se puede especificar un identificador de correlación de mensaje opcional definido por el usuario. La función devuelve un valor de ’1’ si se realiza satisfactoriamente o de ’0’ si no se realiza satisfactoriamente. servicio-publicación Serie que contiene el destino MQSeries lógico donde se debe enviar el mensaje. Si se especifica, el servicio-publicación debe hacer referencia a un Punto de servicio de publicación definido en el archivo de depósito AMT.XML. Un punto de servicio es un punto final lógico desde el cual se envía o se recibe un mensaje. Las definiciones de punto de servicio incluyen el nombre del Gestor de colas y de la Cola de MQSeries. Consulte el manual MQSeries Application Messaging Interface para obtener detalles adicionales. Si no se especifica servicio-publicación, se utilizará DB2.DEFAULT.PUBLISHER. El tamaño máximo de servicio-publicación es de 48 bytes. política-servicio Serie que contiene la Política de servicio AMI de MQSeries que se debe utilizar en el manejo de este mensaje. Si se especifica, la política-servicio debe hacer referencia a una Política definida en el archivo de depósito AMT.XML. Una Política de servicio define un conjunto de opciones de calidad de servicio que deben aplicarse a esta operación de mensajería. 430 Consulta de SQL, Volumen 1
- 457. Estas opciones incluyen la prioridad de mensaje y la permanencia de mensaje. Consulte el manual MQSeries Application Messaging Interface para obtener detalles adicionales. Si no se especifica política-servicio, se utilizará el valor por omisión DB2.DEFAULT.POLICY. El tamaño máximo de política-servicio es de 48 bytes. datos-msj Expresión de serie que contiene los datos que se deben enviar a través de MQSeries. El tamaño máximo si la serie de tipo VARCHAR es de 4000 bytes. Si la serie es de tipo CLOB, puede tener un tamaño de hasta 1MB. tema Expresión de serie que contiene el tema para la publicación del mensaje. Si no se especifica ningún tema, no se asociará ninguno con el mensaje. El tamaño máximo de tema es de 40 bytes. Se pueden especificar múltiples temas en una serie (de una longitud máxima de 40). Cada tema debe estar separado por dos puntos. Por ejemplo, ″t1:t2:el tercer tema″ indica que el mensaje está asociado con los tres temas: t1, t2 y ″el tercer tema″. id-correl Expresión de serie opcional que contiene un identificador de correlación que se debe asociar con este mensaje. El id-correl se especifica normalmente en escenarios de petición y respuesta para asociar las peticiones con las respuestas. Si no se especifica, no se añadirá ningún ID de correlación al mensaje. El tamaño máximo de id-correl es de 24 bytes. Ejemplos Ejemplo 1: En este ejemplo se publica la serie ″Testing 123″ en el servicio de publicación por omisión (DB2.DEFAULT.PUBLISHER) utilizando la política por omisión (DB2.DEFAULT.POLICY). No se especifica ningún identificador de correlación ni tema para el mensaje. VALUES MQPUBLISH(’Testing 123’) Ejemplo 2: En este ejemplo se publica la serie ″Testing 345″ en el servicio de publicación ″MYPUBLISHER″ bajo el tema ″TESTS″. Se utiliza la política por omisión y no se especifica ningún identificador de correlación. VALUES MQPUBLISH(’MYPUBLISHER’,’Testing 345’,’TESTS’) Ejemplo 3: En este ejemplo se publica la serie ″Testing 678″ en el servicio de publicación ″MYPUBLISHER″ utilizando la política ″MYPOLICY″ con un identificador de correlación de ″TEST1″. El mensaje se publica con el tema ″TESTS″. VALUES MQPUBLISH(’MYPUBLISHER’,’MYPOLICY’,’Testing 678’,’TESTS’,’TEST1’) Capítulo 3. Funciones 431
- 458. Ejemplo 4: En este ejemplo se publica la serie ″Testing 901″ en el servicio de publicación ″MYPUBLISHER″ bajo el tema ″TESTS″ utilizando la política por omisión (DB2.DEFAULT.POLICY) y sin identificador de correlación. VALUES MQPUBLISH(’Testing 901’,’TESTS’) Todos los ejemplos devuelve el valor ’1’ si la operación se realiza satisfactoriamente. 432 Consulta de SQL, Volumen 1
- 459. MQREAD MQREAD ( ) servicio-recepción , política-servicio El esquema es MQDB2. La función MQREAD devuelve un mensaje de la ubicación MQSeries especificada por servicio-recepción, utilizando la política de calidad de servicio definida en política-servicio. Al ejecutar esta operación no se elimina el mensaje de la cola asociada con servicio-recepción, sino que, en lugar de ello, se devuelve el mensaje situado en la cabecera de la cola. El resultado de la función es VARCHAR(4000). Si no hay mensajes disponibles para devolverse, el resultado es el valor nulo. servicio-recepción Serie que contiene el destino MQSeries lógico desde el que se debe recibir el mensaje. Si se especifica, el servicio-recepción debe hacer referencia a un Punto de servicio definido en el archivo de depósito AMT.XML. Un punto de servicio es un punto final lógico desde el que se envía o se recibe un mensaje. Las definiciones de puntos de servicio incluyen el nombre del Gestor de colas y de la Cola de MQSeries. Consulte el manual MQSeries Application Messaging Interface para obtener detalles adicionales. Si no se especifica servicio-recepción, se utilizará DB2.DEFAULT.SERVICE. El tamaño máximo de servicio-recepción es de 48 bytes. política-servicio Serie que contiene la Política de servicio AMI de MQSeries utilizada en el manejo de este mensaje. Si se especifica, la política-servicio debe hacer referencia a una Política definida en el archivo de depósito AMT.XML. Una Política de servicio define un conjunto de opciones de calidad de servicio que deben aplicarse a esta operación de mensajería. Estas opciones incluyen la prioridad de mensaje y la permanencia de mens