Jerarquia de memorias
Descargar como PPT, PDF1 recomendación5,902 vistas

El documento describe las jerarquías de memoria en arquitectura de computadoras. Existen varios niveles de memoria organizados de menor a mayor tamaño y latencia. Esto se debe a que los programas tienden a acceder datos cercanos en el espacio y tiempo, lo que optimiza el rendimiento. Las caches buscan aprovechar esta localidad al almacenar de forma temporal datos recientes de la memoria principal de mayor tamaño y latencia.































![Mecanismo aleatorio contador clk + Indice a usar Fallo de cache Blq anterior Nuevo blq de reemplazo semilla X(i+1) = [m.X(i) + k] mod n](https://image.slidesharecdn.com/jerarquia-de-memorias3865/85/Jerarquia-de-memorias-32-320.jpg)






































Jerarquia de memorias
- 1. Jerarquías de memorias Arquitectura de Computadoras II Fac. Cs. Exactas UNCPBA
- 2. Introducción Los programas comparten en la memoria tanto su código como sus datos . Estrategia de optimización de rendimiento posibilitar a la CPU el acceso ilimitado y rápido tanto al código como a los datos. Inconveniente tecnológicamente , cuanto más grandes son las memorias (más capacidad) más lentas y costosas resultan.
- 3. Introducción Ley de localidad todo programa favorece una parte de su espacio de direcciones en cualquier instante de tiempo. 2 dimensiones: Localidad temporal (tiempo). Si se referencia un elemento tenderá a ser referenciado pronto. Localidad espacial (espacio). Si se referencia un elemento, los elementos cercanos a él tenderán a ser referenciados pronto.
- 4. Introducción Jerarquía de memoria reacción natural a la localidad y tecnología El principio de localidad y la directriz que el hardware más pequeño es más rápido mantienen el concepto de una jerarquía basada en diferentes localidades y tamaños. Organizada en varios niveles -cada uno más pequeño, más caro y más rápido que el anterior- Todos los datos de un nivel se encuentran también en el nivel siguiente, y todos los datos de ese nivel inferior se encuentran también en el siguiente a él, hasta el extremo inferior de la jerarquía.
- 5. Ejemplos de jerarquías de memoria D red disco RAM cache CPU disco RAM Cache L2 I CPU
- 6. Terminología básica El nivel superior -el más cercano al procesador es mas rápido y pequeño que el nivel inferior. Mínima unidad de información en una jerarquía de dos niveles bloque
- 7. Terminología básica (1) Acierto (hit) : un acceso a un bloque de memoria que se encuentra en el nivel superior Fallo (miss) : el bloque no se encuentra en ese nivel Frecuencia de aciertos : fracción de accesos a memoria encontrados en el nivel superior Frecuencia de fallos (1 - frecuencia de aciertos) : fracción de accesos a memoria no encontrados en el nivel superior
- 8. Terminología básica (2) Tiempo de acierto : tiempo necesario para acceder a un dato presente en el nivel superior de la jerarquía incluye el tiempo necesario para saber si el acceso es un acierto o un fallo Penalización de fallo : tiempo necesario para sustituir un bloque de nivel superior por el correspondiente bloque de nivel más bajo, más el tiempo necesario para proporcionar este bloque al dispositivo que lo solicito (generalmente la CPU).
- 9. Penalización de fallo... 2 componentes: tiempo de acceso : tiempo necesario para acceder a la primera palabra de un bloque en un fallo relacionado con la latencia del nivel más bajo tiempo de transferencia : tiempo para transferir las restantes palabras del bloque relacionado con el ancho de banda entre las memoria de nivel más bajo y más alto.
- 10. Direccionamiento CPU Dirección de memoria 1 0 0 1 0 1 1 1 0 0 1 1 0 0 1 0 1 0 1 1 0 0 1 0 1 0 0 1 1 0 Dirección de la estructura de bloque DEB Dirección de desplazamiento de bloque OFS Log 2 # blq # blqs
- 11. Rendimiento de la jerarquía T medio de accesos = T acierto + Frecuencia de fallos * Penalización de fallo
- 12. Modificaciones de la CPU Los procesadores diseñados sin jerarquía de memoria son más simples (los accesos a memoria siempre emplean la misma cantidad de tiempo) Los fallos en una jerarquía de memoria implican que la CPU debe manejar tiempos de acceso a memoria variables penalización del orden de decenas de ciclos la CPU espera a que se termine el ciclo de memoria penalización del orden de cientos de ciclos la CPU es interrumpida para atender otras tareas mientras dura el fallo CPU debe soportar interrupciones por accesos a memoria
- 13. Clasificación de las jerarquías de memoria Ubicación del bloque Dónde puede ubicarse un bloque en el nivel superior Identificación del bloque Cómo se encuentra un bloque en el nivel superior Sustitución de bloque Qué bloque debe reemplazarse en caso de fallo Estrategia de escritura Qué ocurre en una escritura
- 14. Primer nivel : Memoria CACHE Memorias muy rápidas Poca capacidad Se interponen entre el procesador y la memoria principal CPU Cache RAM Nivel de cache
- 15. Ubicación de un bloque en la cache correspondencia directa cada bloque debe ir solamente en un lugar dentro de la cache asociativa un bloque puede ubicarse en cualquier lugar de la cache asociativa por conjuntos un bloque puede ser colocado en un grupo restringido de lugares de la cache un conjunto es un grupo de dos o más bloques de la cache
- 16. Ecuaciones de ubicación de bloques correspondencia directa ubicación = DEB mod # bloques de cache asociativa ubicación = cualquiera asociativa por conjuntos ubicación = DEB mod # de conj. de cache
- 17. Notas . . . En una cache asociativa por conjuntos, si hay n bloques por conjunto, la cache se llama asociativa por conjuntos de n vías (asociatividad n) Una cache de correspondencia directa podría decirse que es asociativa por conjuntos de una sola vía Una cache totalmente asociativa posee un solo conjunto con grado de asociatividad m (si posee m bloques en total)
- 18. Ejemplo cache de 8 bloques memoria de 32 celdas. cache asociativa por conjuntos tiene 4 conjuntos de 2 bloques c/u
- 19. Identificación de un bloque de cache Bloque de datos etiqueta (DEB) etiqueta de dirección en cada bloque que identifica la dirección de la estructura de bloque 0 1 1 0 1 0 1 1 Dirección de memoria DEB comparador Hit Bloque de cache
- 20. Ejemplo Cache asociativa : el bloque puede estar en cualquier lado, por lo que hay que buscarlo en todas las etiquetas Cache de correspondencia directa : sólo se debe buscar una etiqueta Cache asociativa por conjuntos : se deben buscar todas las etiquetas del conjunto en el que puede estar el bloque
- 21. Más notas... La búsqueda de contenidos de las etiquetas debe hacerse (para los casos de asociatividades) en paralelo para lograr un buen rendimiento en velocidad de acceso a un dato de la cache. Para saber si una entrada de la cache tiene o no un bloque válido se agrega a la etiqueta un bit de validez que indica si su bloque correspondiente tiene datos válidos o no
- 22. Nuevo direccionamiento Dirección de memoria D E B 1 0 0 1 0 1 0 1 1 0 0 1 0 1 0 0 1 1 0 Dirección de desplazamiento de bloque OFS 1 0 0 1 0 1 1 1 0 0 1 1 0 0 1 0 1 0 1 1 0 0 1 0 1 0 0 1 1 0 Etiqueta Indice
- 23. Mas notas... El campo índice se usa para seleccionar el conjunto, y el etiqueta para la comparación Si se incrementa la asociatividad : aumenta el número de bloques por conjunto disminuye el tamaño del índice aumenta el tamaño de la etiqueta Una cache totalmente asociativa no tiene índice y la parte de etiqueta posee la dirección de la estructura de bloque total.
- 24. Ejemplo (parte 1) Caché de 512 bytes dividida en bloques de 16 bytes (32 bloques) La caché está, a su vez, agrupada en 8 conjuntos de 4 bloques cada uno (4 vías). El nivel inferior es una RAM de 16 Kbytes. Entonces tiene 1024 bloques de 16 bytes cada uno 0 1 2 3 4 5 6 7 0 1 . . . . . . . . . . . . . . . . . . . . . . . . 1023
- 25. Ejemplo (parte 2) Si la dirección que necesita la CPU es 9000 entonces: bloque = 9000 DIV 16 = 562 desplaz = 9000 MOD 16 = 8 En la caché irá en el conjunto: conjunto = 562 MOD 8 = 2 y el valor de la etiqueta será: etiqueta = 562 DIV 8 = 70 70 2 8 etiqueta indice desplazamiento
- 26. Ejemplo (parte 3) en binario sería: 9000 = 1000 1100 101 000 Como el bloque es de 16 bytes, el desplazamiento lo dan los 4 últimos bits desplazamiento = 1000 ( = 8) dir. est. bloque = 1000 1100 10 Como la caché es de 8 conjuntos, entonces, el MOD 8 representa los últimos 3 bits de la dirección de estructura de bloque. Entonces: indice = 010 ( = 2) etiqueta = 1000 110 ( = 70) 1000110 010 1000 etiqueta indice desplazamiento
- 27. Uso de los campos de la DEB Cache 1 Cache 2 Cache 3 D e c o d i f i c a d o r desplazamiento etiqueta indice datos
- 28. Diagrama de bloques del subsistema de cache CPU Memoria de etiquetas memoria de datos bloque presencia Memoria Dir DEB # blq dato offset pres
- 29. Sustitución de bloques Ante un fallo de cache es necesario traer un bloque nuevo y ubicarlo en algún lugar del nivel superior Si existe algún bloque de cache con datos no válidos, el reemplazo se hace en ese lugar Debido a la alta frecuencia de aciertos de la cache es necesario tomar estrategias de reemplazo
- 30. Sustitución de bloques Si la cache es de mapeo directo no hay problema, ya que el nuevo bloque puede ir en un solo lugar En caso de caches asociativas el bloque puede ubicarse en diferentes lugares. Estrategias: reemplazo aleatorio reemplazo pseudo aleatorio LRU (menos recientemente usado)
- 31. Sustitución de bloques Aleatorio : Mediante algún mecanismo de hardware se seleccionan uniformemente los bloques candidatos. Pseudo aleatorio : para obtener una distribución de bloques con un comportamiento reproducible útil durante la depuración del hardware. LRU : disminuye la posibilidad de desechar información que se necesitará pronto se registran los accesos a los bloques de manera que el bloque sustituido es aquel que hace más tiempo que no se usa.
- 32. Mecanismo aleatorio contador clk + Indice a usar Fallo de cache Blq anterior Nuevo blq de reemplazo semilla X(i+1) = [m.X(i) + k] mod n
- 33. Mecanismo pseudo aleatorio Semilla cíclica + Indice a usar Fallo de cache Blq anterior Nuevo blq de reemplazo Para ahorrar la demora del sumador se calcula el bloque para el siguiente fallo y se usa el anterior para atender el fallo actual
- 34. Más notas... La estrategia aleatoria es sencilla de construir en hardware Cuando el número de bloques a gestionar aumenta, la estrategia LRU se convierte es muy cara frecuentemente se utiliza una aproximación de ésta La política de reemplazo juega un papel más importante en las caches más pequeñas que en las más grandes donde hay más opciones para sustituir. Asociatividad 2 vías 4 vías 8 vías tamaño LRU aleatorio LRU aleatorio LRU aleatorio 16 Kb 5.18% 5.69% 4.67% 5.29% 4.39% 4.96% 64 Kb 1.88% 2.01% 1.54% 1.66% 1.39% 1.53% 256 Kb 1.15% 1.17% 1.17% 1.13% 1.12% 1.12%
- 35. Estrategias de escritura Lecturas 91% Escrituras 9% El bloque se lee simultáneamente a la lectura de la etiqueta para que la lectura del bloque comience tan rápido como esté disponible la DEB Si la lectura es un acierto el bloque pasa inmediatamente a la CPU Si es un fracaso no hay beneficio, pero tampoco perjuicio El procesador especifica el tamaño de la escritura -normalmente entre 1 y 8 bytes- y sólo esa porción del bloque debe ser cambiada
- 36. Estrategias de escritura Políticas de escritura: Escritura directa : la información se escribe en el bloque de cache y también en el bloque de memoria de nivel inferior. Postescritura : la información se escribe solo en el bloque de la cache. El bloque modificado de la cache se escribe en memoria principal sólo cuando es reemplazado.
- 37. Ventajas de cada política Postescritura las escrituras se realizan a velocidad de la cache múltiples escrituras de un bloque requieren una única escritura en la memoria de nivel inferior Escritura directa los fallos de lectura no ocasionan escrituras en el nivel inferior más fácil de implementar que el anterior mantiene siempre coherente la memoria cache y la memoria inferior (útil en sistemas multiproceso en los que varias CPU's acceden simultáneamente a los datos)
- 38. Fallos de escritura El fallo se produce cuando se intenta escribir una palabra de un bloque que no está en la cache políticas Ubicar en escritura : el bloque se carga en la cache, seguido de las acciones anteriores de acierto de escritura. Esto es similar a un fallo de lectura. No ubicar en escritura : el bloque se modifica en el nivel inferior y no se carga en la cache.
- 39. Rendimiento de la cache Tiempo de CPU ciclos de reloj de ejecución del programa ciclos de reloj de espera al sistema de memoria T CPU = (ciclos ejecución-CPU + ciclos detención-memoria ) * T ciclo de reloj Ejecución de instrucciones aciertos de cache Accesos a memoria RAM penalizaciones de fallo
- 40. Rendimiento de la cache T CPU = (ciclos ejecución-CPU + ciclos detención-memoria ) * T ciclo de reloj ciclos detención-memoria = accesos memoria * PF * FF programa Con : Factorizando el recuento de instrucciones: T CPU = IC * (CPI ejecución + accesos-memoria * FF * PF) * T ciclo instrucción
- 41. Tipos de fallos de cache Forzosos : el primer acceso a un bloque no está en la cache; así que el bloque debe ser traído a la misma. Estos también se denominan fallos de arranque en frío o de primera referencia. Capacidad : si la cache no puede contener todos los bloques necesarios durante la ejecución de un programa, se presentarán fallos de capacidad debido a los bloques que se descartan y luego se recuperan. Conflicto : si la estrategia de ubicación es asociativa por conjuntos o de mapeo directo, estos fallos ocurrirán, ya que se puede descartar un bloque y posteriormente recuperarlo si a un conjunto le corresponden demasiados bloques.
- 42. Mas notas... Los fallos forzosos son independientes de la cache Los de capacidad disminuyen cuando la capacidad aumenta Los fallos de conflicto dependen de la asociatividad de la memoria: si es totalmente asociativa no existen conflictos, en la de mapeo directo los conflictos aumentan hasta su máximo posible Incrementar la capacidad de la cache reduce los fallos de conflicto así como los de capacidad, ya que una cache mayor dispersa las referencias.
- 43. Caches de Data/Inst o unificadas Cache de datos e instrucciones separadas: La CPU sabe que tipo de lectura realiza (D/I) Aumenta el ancho de banda Permite optimizar los parámetros independientemente Disminuye los fallos de conflicto en la cache de inst. Cache unificada: Más simple de implementar No se necesitan puertos duales en la CPU para D/I No limita el espacio máximo para datos e inst. (fallos de capacidad)
- 44. Caches de Data/Inst o unificadas Tamaño (Kb) Instrucciones (%) Datos (%) Unificada (%) 0,25 22,2 26,8 28,6 0,50 17,9 20,9 23,9 1 14,3 16,0 19,0 2 11,6 11,8 14,9 4 8,6 8,7 11,2 8 5,8 6,8 8,3 16 3,6 5,3 5,9 32 2,2 4,0 4,3 64 1,4 2,8 2,9 128 1,0 2,1 1,9 256 0,9 1,9 1,6
- 45. Segundo nivel de la jerarquía Memoria virtual
- 46. Segundo nivel: memoria principal CPU Cache RAM Nivel de memoria virtual Disco Rendimiento latencia ancho de banda Nivel inferior demasiado lento respecto al superior
- 47. Latencia de la memoria RAM latencia : Tiempo de acceso : tiempo que transcurre desde que se pide una lectura hasta que llega la palabra deseada Duración del ciclo : tiempo mínimo entre peticiones consecutivas a memoria pedido lectura pedido Tiempo de acceso Duración del ciclo
- 48. Aspectos físicos de las RAM SRAM (Static RAM) Construidas a partir de 2 transistores por bit. Tecnología más cara Menor capacidad Mayor velocidad Usadas en las memorias cache
- 49. Aspectos físicos de las RAM DRAM (Dinamic RAM) Usan un capacitor como elemento de memoria Direccionamiento doble RAS CAS Tecnología más barata Mayor capacidad Más lentas Usadas en las memorias de masa GND RAS CAS W/R Lógica de bit
- 50. Aspectos físicos de las RAM
- 51. Cronograma de acceso a una DRAM Secuencia de Acceso 1 - direccion de fila 2 - activación de RAS# 3 - retardo RAS/CAS 4 - dirección de columna 5 - activación CAS# 6 - lectura o escritura (R/W#)
- 52. Organizaciones de las memorias DRAM
- 53. Ejemplo 1 ciclo de reloj para enviar la dirección. 6 ciclos de reloj para el tiempo de acceso por palabra. 1 ciclo de reloj para enviar una palabra de datos. Dado un bloque de 4 palabras (de 2 byte c/u 64 bits) Caso I PF= 32 ciclos AB = 64/32 = 2 bits Caso II PF= 16 ciclos AB = 64/16 = 4 bits Caso III PF= 11 ciclos AB = 64/11 aprox. 6 bits Memoria convencional Memoria mas ancha Memoria entrelazada
- 54. Modos de las DRAM 6 modos principales Modo de página (Page Mode y Fast Page Mode) Modo EDO Page (Enhanced Data Out Page Mode) Modo nibble Columna estática Modo Síncrono (SDRAM) Modo DDR (Double Data Rate)
- 55. Modo Página • Permiten acceder más rápidamente posiciones de memoria contenidas en la misma fila. • Normalmente se desactivan RAS# y CAS# al final. • El acceso al primer elemento es normal. • A continuación se mantiene RAS# activa y se direcciona sólo la columna mediante CAS# • Necesitan hardware especial.
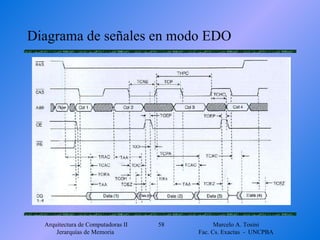
- 56. Modo EDO (Enhanced Data Out) Enhanced Data Out o Hyperpage consiste en no desactivar los drivers de salida cuando #CAS está a nivel alto. Se reduce el tiempo que #CAS debe permanecer a nivel bajo y aumenta el tiempo que los datos permanecen disponibles en el bus La actividad de los drivers de salida se controla con #OE
- 57. Diagrama de señales en modo Pagina
- 58. Diagrama de señales en modo EDO
- 59. Modo Burst and Nibble • Idénticas en funcionamiento a las modo de página • Contador de columnas interno • Incremento automático con la señal CAS# Ante una petición de lectura, proporciona el dato solicitado y los tres siguientes. El tiempo de acceso de los tres últimos datos es mucho más corto que el del primero. En escritura hay que proporcionar cuatro datos para ser almacenados en posiciones consecutivas.
- 60. Modo Columna Estática • Idénticas en funcionamiento a las modo de página • No hace falta suministrar la señal CAS# • Interpreta los cambios del bus como una nueva columna
- 61. Modo Síncrono (SDRAM) • Todas las memorias anteriores son asíncronas • CAS# y RAS# se activan con independencia del reloj de la CPU. • En estas memorias, RAS# y CAS# solamente se suministran en sincronía con el reloj del sistema . • Simplifica el diseño del subsistema de memoria • Los sistemas actuales son todos síncronos
- 62. Modo DDR (Double Data Rate) • Son memorias síncronas • Permiten un acceso en flanco de subida y otro en flanco de bajada de la señal del reloj • La velocidad de transferencia es el doble de una SDRAM • Funcionan internamente con 16 bits aunque tienen bus de datos de 8 bits
- 63. Memorias comerciales • FPMDRAM (Fast Page Mode DRAM) : DRAM que permite acceso en modo página. • EDO DRAM (Extended Data Output DRAM ) :Se empieza a leer el siguiente bloque de memoria sin haber finalizado el anterior.(40-66 MHz) • BEDO DRAM (Burst EDO DRAM ) : Puede procesar hasta 4 posiciones de memoria en una ráfaga, pero sólo de forma puntual.(66-75 MHz) • SDRAM (Synchronous DRAM) : Se sincroniza con el bus del sistema para leer/escribir varias posiciones de memoria en una ráfaga, de manera continua. (100 MHz) • DDR SDRAM (Double Data Rate SDRAM) : Transfiere dos datos por ciclo de reloj. Dobla las prestaciones de la SDRAM. Buses AGP. • DR DRAM (Direct Rambus DRAM) : Tecnología distinta de SDRAM. Bus especial de alta velocidad (1.6 Gb/sg). • SL DRAM (Synchronous Link DRAM) : Evolución de las SDRAM. Teóricamente, hasta 3.2Gb/sg. • RAM de tarjetas de vídeo : (RDRAM, VRAM, WRAM, SGRAM, MDRAM): Múltiples puertos de acceso, puertos de lectura y escritura diferenciados y simultáneos,… • RAM alimentada por baterías : Solución intermedia entre RAM y ROM. RAM “normal” alimentada por una pila botón de forma continua. Ej: BIOS PCs.
- 64. Memoria virtual Implementación de la jerarquía de memoria entre el segundo y tercer nivel de memoria Esquema similar al del nivel de cache Estrategia de manejo orientada al SO mas que al rendimiento Terminología: Segmento o página se refieren a un bloque Fallo de segmento o fallo de página se refieren a fallo
- 65. Otras diferencias El reemplazo de los fallos de cache está controlado por hardware mientras que el reemplazo en memoria virtual se controla por el sistema operativo. El tamaño de la dirección del procesador determina el tamaño de la memoria virtual, pero el tamaño de la cache es normalmente independiente de la dirección del procesador. El nivel más bajo de la memoria virtual(discos) se comparte con el sistema de archivos del sistema operativo, con lo cual el tamaño o capacidad de la memoria virtual no es siempre la misma.
- 66. Tipos de memoria virtual Memoria virtual Paginada : bloques fijos tamaño : 512 a 8192 bytes relacionada con aspectos físicos del nivel inferior Segmentada : bloques variables tamaño : 1 a 2 32 bytes relacionada con aspectos de programación
- 67. Ubicación de bloques en memoria principal Penalización de fallos de memoria virtual involucra el acceso a un dispositivo generalmente lento (discos magnéticos) Alternativas: reducir la frecuencia de fallos un algoritmo de ubicación de bloques mas sencillo elección mas adecuada: disminuir la frecuencia de fallos debido al alto costo de un fallo Por tanto los sistemas operativos permiten que un bloque se coloque en cualquier parte de la memoria virtual
- 68. Identificación de un bloque la memoria virtual implementa una estructura de datos indexada por el numero de pagina o segmento La estructura de datos tiene la forma de una tabla de paginas , donde sus entradas se seleccionan mediante una dirección virtual y cada una de las entradas posee datos diversos entre los que se cuentan: dirección física, limite (para segmentación solamente), atributos propios de la pagina/segmento, protecciones, etc. Nº de pág. Virtual desp de página Tabla de páginas Memoria principal
- 69. Estrategias de reemplazo Meta principal : minimizar los fallos de página por su coste elevado en tiempo Algoritmo de sustitución : elección del bloque menos recientemente usado (LRU) (es el que menos, probablemente, se necesitará)
- 70. Estrategia de escritura Una escritura al nivel mas bajo de memoria virtual (el disco) es bastante costosa en tiempo El sistema operativo trata de evitar accesos a disco hasta que el bloque sea reemplazado haciendo todas las escrituras en memoria principal Estrategia de postescritura Inconveniente : Falta de coherencia entre RAM y discos
- 71. Rendimiento del sistema global T CPU = IC * (CPI ejecución + accesos-memoria * FF * PF) * T ciclo instrucción Hasta ahora: Al incorporar el comportamiento de la memoria virtual queda: Penalización de fallos de cache = (1) = FF TLB * tiempo_acceso_RAM * Longitud_entrada_tabla_páginas + (2) + FA RAM * tiempo_acceso_RAM + (3) + (1 - FA RAM ) * Tiempo_acceso_disco * Tamaño_página con: FF TLB : Frecuencia de fallos de la TLB. tiempo_acceso_RAM : Tiempo de acceso a una palabra de la RAM. FA RAM : Frecuencia de aciertos a la RAM