Monitor everything
Download as PPTX, PDF1 like519 views

This document discusses the importance of comprehensive monitoring for containerized applications and infrastructure. It recommends monitoring at multiple levels, from the host and operating system to the network, orchestration layer, and applications themselves. The document outlines common failure models for each of these levels. It also provides an example of how detailed metrics and monitoring could have helped identify issues that caused an e-commerce site outage. The document concludes by recommending best practices for monitoring, such as starting small, avoiding alert fatigue, and testing monitoring systems.




![- [ ] Introduction
- [ ] Operations Overview
- [ ] Failure Models
- [ ] Demo
- [ ] Best Practices & Recap](https://image.slidesharecdn.com/monitoreverything-190317201629/85/Monitor-everything-5-320.jpg)












![- [ X ] Introduction
- [ ] Operations Overview
- [ ] What to Monitor
- [ ] Demo
- [ ] Best Practices & Recap](https://image.slidesharecdn.com/monitoreverything-190317201629/85/Monitor-everything-18-320.jpg)











![- [ X ] Introduction
- [ X ] Operations Overview
- [ ] What to Monitor
- [ ] Demo
- [ ] Best Practices & Recap](https://image.slidesharecdn.com/monitoreverything-190317201629/85/Monitor-everything-30-320.jpg)







![- [ X ] Introduction
- [ X ] Operations Overview
- [ X ] What to Monitor
- [ ] Demo
- [ ] Best Practices & Recap](https://image.slidesharecdn.com/monitoreverything-190317201629/85/Monitor-everything-39-320.jpg)


![- [ X ] Introduction
- [ X ] Operations Overview
- [ X ] What to Monitor
- [ X ] Demo
- [ ] Best Practices & Recap](https://image.slidesharecdn.com/monitoreverything-190317201629/85/Monitor-everything-42-320.jpg)






Monitor everything
- 4. Don’t Limit Monitoring to Infrastructure
- 5. - [ ] Introduction - [ ] Operations Overview - [ ] Failure Models - [ ] Demo - [ ] Best Practices & Recap
- 6. docker run who-is-brian Brian Christner • Co-Founder 56K.Cloud / SRE • Docker Captain • Passionate about Monitoring and anything with .io domains
- 11. OK, give me a business example
- 13. Casinos
- 16. Monitor Early
- 17. www.your-now.com A joint collaboration between BMW & Daimler AG
- 18. - [ X ] Introduction - [ ] Operations Overview - [ ] What to Monitor - [ ] Demo - [ ] Best Practices & Recap
- 19. • Everything is Automated • Reduce Costs • No support calls / support tickets Ops Paradise
- 20. Ops Firefighting
- 22. Users Care about 3 Things • Availability - Is my System Online Yes/No • Latency - Does it take a long time to access applications x, y, z • Reliability - Can the user rely on using the application
- 23. Brain Based Tools • We can track 8 objects on average • 4 Moving Objects • Build Dashboards & Tools accordingly
- 25. SRE
- 26. SRE is treats Operations as if it were a Software Problem “Hope is not a strategy.” Traditional SRE saying www.google.com/sre SRE (Site Reliability Engineering)
- 27. TL;DR - SRE Latency Traffic Errors Saturation 4 Golden Signals
- 28. (Request) Rate: the number of requests, per second, you services are serving. (Request) Errors: the number of failed requests per second. Utilization: the average time that the resource was busy servicing work (Request) Duration: distributions of the amount of time each request takes. R.E.D (Microservice Level)
- 29. Resource: all physical server functional components (CPUs, disks, busses, ...) Utilization: the average time that the resource was busy servicing work Saturation: the degree to which the resource has extra work which it can't service, often queued Errors: the count of error events U.S.E (Low Level / Infrastructure) For every resource, check Utilization, Saturation, and Errors
- 30. - [ X ] Introduction - [ X ] Operations Overview - [ ] What to Monitor - [ ] Demo - [ ] Best Practices & Recap
- 31. Operating Systems Understanding Failure Models Config Mgt Monitoring LoggingCI/CD ..more..Images Networking Volumes PhysicalVirtualizationPublic Cloud Developer Services Registry Services Access Policies App Lifecycle Management Automation & Extensibility Networking Orchestration Storage Container Engine CONTAINER PLATFORM Platform Security
- 32. Operating Systems Host / Hardware Config Mgt Monitoring LoggingCI/CD ..more..Images Networking Volumes PhysicalVirtualizationPublic Cloud Developer Services Registry Services Access Policies App Lifecycle Management Automation & Extensibility Networking Orchestration Storage Container Engine CONTAINER PLATFORM Platform Security CPU Memory Liveness File Descriptors Storage Capacity
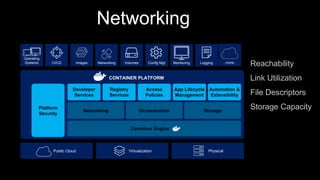
- 33. Operating Systems Networking Config Mgt Monitoring LoggingCI/CD ..more..Images Networking Volumes PhysicalVirtualizationPublic Cloud Developer Services Registry Services Access Policies App Lifecycle Management Automation & Extensibility Networking Orchestration Storage Container Engine CONTAINER PLATFORM Platform Security Reachability Link Utilization File Descriptors Storage Capacity
- 34. Operating Systems Orchestration Config Mgt Monitoring LoggingCI/CD ..more..Images Networking Volumes PhysicalVirtualizationPublic Cloud Developer Services Registry Services Access Policies App Lifecycle Management Automation & Extensibility Networking Orchestration Storage Container Engine CONTAINER PLATFORM Platform Security State Deployment Rates Capacity Scheduling Events
- 35. Operating Systems Applications Config Mgt Monitoring LoggingCI/CD ..more..Images Networking Volumes PhysicalVirtualizationPublic Cloud Developer Services Registry Services Access Policies App Lifecycle Management Automation & Extensibility Networking Orchestration Storage Container Engine CONTAINER PLATFORM Platform Security CPU Memory Liveness File Descriptors Storage Capacity
- 37. • Total Downtime: Just under 4 minutes • 502 error messages total: 12 000 • People affected by the 502 error who did not get their bargain: 400 Website Down?
- 39. - [ X ] Introduction - [ X ] Operations Overview - [ X ] What to Monitor - [ ] Demo - [ ] Best Practices & Recap
- 40. DEMO
- 42. - [ X ] Introduction - [ X ] Operations Overview - [ X ] What to Monitor - [ X ] Demo - [ ] Best Practices & Recap
- 45. Best Practices • Start small & increment • Don’t Overlert yourself • Set Resource Limits • Aim for actionable Information • Run separate from Workload • Test for Failures • Know your Failure Models
- 47. Resources •56K.Cloud - https://56K.Cloud •Prometheus - https://github.com/vegasbrianc/prometheus •Monitoring Labs – github.com/56kcloud/Training/ •Docker Resource Link - https://awesome-docker.netlify.com •GitLab Dashboards - https://monitor.gitlab.net
Editor's Notes
- #15: Air quality Problems in casino Top Players Sporting events weather
- #23: What we won’t hear from customers: - I hope that we have more maintenance windows I really wish my application wasn’t so fast My application is far too stable
- #46: Know-your-Failure Modes Structured Logs Test for Failures Optimize for MTTR and not Uptime Alerts Should be actionable with little digging Catch the Symptom and not the problem