

![6%
36%
1%5% 12%
41%
Entity (“1978 cj5 jeep”)
Type (“doctors in barcelona”)
Attribute (“zip code waterville Maine”)
Relation (“tom cruise katie holmes”)
Other (“nightlife in Barcelona”)
Uninterpretable
Distribution of web search
queries [Pound et al. 2010]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-3-320.jpg)
![28%
15%
10% 4%
14%
29% Entity
Entity+refiner
Category
Category+refiner
Other
Website
Distribution of web search
queries [Lin et al. 2011]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-4-320.jpg)








![Semantic web (2)
and calculate their ranking. Yet, at the heart of all sc
methods lies a mechanism for capturing the co-occur
between source and target entities. A common take o
task was to first gather snippets for the input entity
then extract co-occurring entities from these snippets
a named entity recognizer. Several submissions built he
on Wikipedia, for example by exploiting outgoing links
the entity’s Wikipedia page, by using it to improve n
entity recognition, or by making use of Wikipedia categ
for entity type detection [5].
The number of entities with a Wikipedia page tha
found by any of the 41 TREC runs submitted by partic
ing groups, is shown in Table 1 (#rel). This result set
not be complete, as only the top 10 entities per topi
submission were pooled for assessment, and some Wiki
pages were not included in the ClueWeb crawl.
4.2 Semantic Web
In order to answer the information needs using sem
web technologies, we follow two approaches. The fi
straightforward and transforms each query into a SPA
query, by instantiating E and T in a template query
example, for topic #5 “Products of Medimmune, Inc.,
following SPARQL query is issued (the namespaces
been removed to improve readability):
SELECT DISTINCT ?m ?r
WHERE {
?m rdf:type dbpedia-owl:Drug .
{ ?m ?r dbpedia:MedImmune }
UNION
{ dbpedia:MedImmune ?r ?m }
}
This query returns all items that are of type T and
appear as either the predicate or object of a relation
E. Table 2 shows the results of this example query
the LOD SPARQL endpoint. There is no support w](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-13-320.jpg)













![dbpedia:Audi_A4
foaf:name Audi A4
rdfs:label Audi A4
rdfs:comment The Audi A4 is a compact executive car
produced since late 1994 by the German car
manufacturer Audi, a subsidiary of the
Volkswagen Group. The A4 has been built [...]
dbpprop:production 1994
2001
2005
2008
rdf:type dbpedia-owl:MeanOfTransportation
dbpedia-owl:Automobile
dbpedia-owl:manufacturer dbpedia:Audi
dbpedia-owl:class dbpedia:Compact_executive_car
owl:sameAs freebase:Audi A4
is dbpedia-owl:predecessor of dbpedia:Audi_A5
is dbpprop:similar of dbpedia:Cadillac_BLS](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-27-320.jpg)
![Mixture of Language Models
[Ogilvie & Callan 2003]
- Build a separate language model for each field
- Take a linear combination of them
mX
j=1
µj = 1
Field language model
Smoothed with a collection model built
from all document representations of the
same type in the collectionField weights
P(t|✓d) =
mX
j=1
µjP(t|✓dj )](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-28-320.jpg)


![Predicate folding
- Idea: reduce the number of fields by grouping
them together
- Grouping based on (BM25F and)
- type [Pérez-Agüera et al. 2010]
- manually determined importance [Blanco et al. 2011]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-31-320.jpg)
![Hierarchical Entity Model
[Neumayer et al. 2012]
- Organize fields into a 2-level hierarchy
- Field types (4) on the top level
- Individual fields of that type on the bottom level
- Estimate field weights
- Using training data for field types
- Using heuristics for bottom-level types](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-32-320.jpg)
![Two-level hierarchy
[Neumayer et al. 2012]
foaf:name Audi A4
rdfs:label Audi A4
rdfs:comment The Audi A4 is a compact executive car
produced since late 1994 by the German car
manufacturer Audi, a subsidiary of the
Volkswagen Group. The A4 has been built [...]
dbpprop:production 1994
2001
2005
2008
rdf:type dbpedia-owl:MeanOfTransportation
dbpedia-owl:Automobile
dbpedia-owl:manufacturer dbpedia:Audi
dbpedia-owl:class dbpedia:Compact_executive_car
owl:sameAs freebase:Audi A4
is dbpedia-owl:predecessor of dbpedia:Audi_A5
is dbpprop:similar of dbpedia:Cadillac_BLS
Name
Attributes
Out-relations
In-relations](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-33-320.jpg)

![Probabilistic Retrieval Model
for Semistructured data
[Kim et al. 2009]
- Extension to the Mixture of Language Models
- Find which document field each query term
may be associated with
Mapping probability
Estimated for each query term
P(t|✓d) =
mX
j=1
µjP(t|✓dj )
P(t|✓d) =
mX
j=1
P(dj|t)P(t|✓dj )](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-35-320.jpg)










![Generative probabilistic
models
- Candidate generation models (P(e|q))
- Two-stage language model
- Topic generation models (P(q|e))
- Candidate model, a.k.a. Model 1
- Document model, a.k.a. Model 2
- Proximity-based variations
- Both families of models can be derived from the
Probability Ranking Principle [Fang & Zhai 2007]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-46-320.jpg)
![Candidate models (“Model 1”)
[Balog et al. 2006]
P(q|✓e) =
Y
t2q
P(t|✓e)n(t,q)
Smoothing
With collection-wide background model
(1 )P(t|e) + P(t)
X
d
P(t|d, e)P(d|e)
Document-entity
association
Term-candidate
co-occurrence
In a particular document.
In the simplest case:P(t|d)](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-47-320.jpg)
![Document models (“Model 2”)
[Balog et al. 2006]
P(q|e) =
X
d
P(q|d, e)P(d|e)
Document-entity
association
Document relevance
How well document d
supports the claim that e
is relevant to q
Y
t2q
P(t|d, e)n(t,q)
Simplifying assumption
(t and e are conditionally
independent given d)
P(t|✓d)](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-48-320.jpg)


![Using proximity kernels
[Petkova & Croft 2007]
P(t|d, e) =
1
Z
NX
i=1
d(i, t)k(t, e)
Indicator function
1 if the term at position i is t,
0 otherwise
Normalizing
contant
Proximity-based kernel
- constant function
- triangle kernel
- Gaussian kernel
- step function](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-51-320.jpg)



![Arithmetic Mean
Discriminative (AMD) model
[Yang et al. 2010]
P✓(r = 1|e, q) =
X
d
P(r1 = 1|q, d)P(r2 = 1|e, d)P(d)
Document
prior
Query-document
relevance
Document-entity
relevance
logistic function
over a linear
combination of features
⇣ Ng
X
j=1
jgj(e, dt)
⌘⇣ Nf
X
i=1
↵ifi(q, dt)
⌘
standard logistic
function
weight
parameters
(learned)
features](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-55-320.jpg)
![Learning to rank && entity
retrieval
- Pointwise
- AMD, GMD [Yang et al. 2010]
- Multilayer perceptrons, logistic regression [Sorg &
Cimiano 2011]
- Additive Groves [Moreira et al. 2011]
- Pairwise
- Ranking SVM [Yang et al. 2009]
- RankBoost, RankNet [Moreira et al. 2011]
- Listwise
- AdaRank, Coordinate Ascent [Moreira et al. 2011]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-56-320.jpg)
![Voting models
[Macdonald & Ounis 2006]
- Inspired by techniques from data fusion
- Combining evidence from different sources
- Documents ranked w.r.t. the query are seen as
“votes” for the entity](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-57-320.jpg)

![Graph-based models
[Serdyukov et al. 2008]
- One particular way of constructing graphs
- Vertices are documents and entities
- Only document-entity edges
- Search can be approached as a random walk
on this graph
- Pick a random document or entity
- Follow links to entities or other documents
- Repeat it a number of times](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-59-320.jpg)
![Infinite random walk
[Serdyukov et al. 2008]
Pi(d) = PJ (d) + (1 )
X
e!d
P(d|e)Pi 1(e),
Pi(e) =
X
d!e
P(e|d)Pi 1(d),
PJ (d) = P(d|q),
ee e
d d
e
d d](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-60-320.jpg)


![If target type is not provided
Rely on techniques from...
- Federated search
- Obtain a separate ranking for each type of entity,
then merge [Kim & Croft 2010]
- Aggregated search
- Return top ranked entities from each type [Lalmas
2011]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-63-320.jpg)







![Modeling terms and categories
[Balog et al. 2011]
Term-based representation
Query model
p(t|✓T
e )p(t|✓T
q ) p(c|✓C
q ) p(c|✓C
e )
Entity model Query model Entity model
Category-based representation
KL(✓T
q ||✓T
e ) KL(✓C
q ||✓C
e )
P(e|q) / P(q|e)P(e)
P(q|e) = (1 )P(✓T
q |✓T
e ) + P(✓C
q |✓C
e )](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-71-320.jpg)
![Identifying target types for
queries
- Types of top ranked entities [Vallet & Zaragoza
2008]
- Direct term-based vs. indirect entity-based
representations [Balog & Neumayer 2012]
- Hierarchical case is difficult... [Sawant &
Chakrabarti 2013]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-72-320.jpg)






![Modeling related entity finding
[Bron et al. 2010]
- Three-component model
p(e|E, T, R) / p(e|E) · p(T|e) · p(R|E, e)
Context model
Type filtering
Co-occurrence
model](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-80-320.jpg)

![The usual suspects from
document retrieval...
- Priors
- HITS, PageRank
- Document link indegree [Kamps & Koolen 2008]
- Pseudo relevance feedback
- Document-centric vs. entity-centric [Macdonald &
Ounis 2007; Serdyukov et al. 2007]
- sampling expansion terms from top ranked documents
and/or (profiles of) top ranked candidates
- Field-based [Kim & Croft 2011]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-82-320.jpg)
![Query understanding
- Structuring and segmentation [Bendersky et al.
2010, Bendersky et al. 2011]
- Aiding the user with context-sensitive
suggestions [Bast et al. 2012]
- Query interpretation with the help of
knowledge bases [Pound et al. 2012]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-83-320.jpg)
![Specialized interfaces
[Bast et al. 2012]
Figure taken from Bast et al. Broccoli: Semantic Full-Text Search at your Fingertips.
http://arxiv.org/abs/1207.2615/](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-84-320.jpg)

![Joint query interpretation and
response ranking
[Sawant & Chakrabarti 2013]](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-86-320.jpg)







![Test collections (2)
- Entity search as Question Answering
- TREC QA track
- QALD-2 challenge
- INEX-LD Jeopardy task
- DBpedia entity search [Balog & Neumayer 2013]
- synthesized queries and assessments, distilled from
previous campaigns
- from short keyword queries to natural language
questions
- 485 queries in total; mapped to DBpedia](https://image.slidesharecdn.com/sigir2013-entityretrieval-130728102445-phpapp01/85/Entity-Retrieval-SIGIR-2013-tutorial-94-320.jpg)





Entity Retrieval (SIGIR 2013 tutorial)
- 1. Part II Entity Retrieval Krisztian Balog University of Stavanger Full-day tutorial at the SIGIR’13 conference | Dublin, Ireland, 2013
- 2. Entity retrieval Addressing information needs that are better answered by returning specific objects instead of just any type of documents.
- 3. 6% 36% 1%5% 12% 41% Entity (“1978 cj5 jeep”) Type (“doctors in barcelona”) Attribute (“zip code waterville Maine”) Relation (“tom cruise katie holmes”) Other (“nightlife in Barcelona”) Uninterpretable Distribution of web search queries [Pound et al. 2010]
- 4. 28% 15% 10% 4% 14% 29% Entity Entity+refiner Category Category+refiner Other Website Distribution of web search queries [Lin et al. 2011]
- 5. What’s so special here? - Entities are not always directly represented - Recognize and disambiguate entities in text (that is, entity linking) - Collect and aggregate information about a given entity from multiple documents and even multiple data collections - More structure than in document-based IR - Types (from some taxonomy) - Attributes (from some ontology) - Relationships to other entities (“typed links”)
- 6. In this part - Look at a number of entity ranking tasks - Motivating real-world use-cases - Abstractions at evaluation benchmarking campaigns (TREC, INEX) - Methods and approaches - In all cases - Input: (semi-structured) query - Output: ranked list of entities - Evaluation: standard IR metrics
- 7. Outline 1.Ranking based on entity descriptions 2.Incorporating entity types 3.Entity relationships Attributes (/Descriptions) Type(s) Relationships
- 9. We are IR people ... - ... but that doesn’t mean that we are the only ones who thought about this - Entity retrieval is an active research area in neighbouring communities - Databases - Semantic web - Natural language processing
- 10. Databases - Keyword search in DBs - Return tuples with matching keywords, minimally joined through primary-foreign key relationships
- 11. Databases (2)
- 12. Semantic web - Indexing - Retrieval - Querying - Inference
- 13. Semantic web (2) and calculate their ranking. Yet, at the heart of all sc methods lies a mechanism for capturing the co-occur between source and target entities. A common take o task was to first gather snippets for the input entity then extract co-occurring entities from these snippets a named entity recognizer. Several submissions built he on Wikipedia, for example by exploiting outgoing links the entity’s Wikipedia page, by using it to improve n entity recognition, or by making use of Wikipedia categ for entity type detection [5]. The number of entities with a Wikipedia page tha found by any of the 41 TREC runs submitted by partic ing groups, is shown in Table 1 (#rel). This result set not be complete, as only the top 10 entities per topi submission were pooled for assessment, and some Wiki pages were not included in the ClueWeb crawl. 4.2 Semantic Web In order to answer the information needs using sem web technologies, we follow two approaches. The fi straightforward and transforms each query into a SPA query, by instantiating E and T in a template query example, for topic #5 “Products of Medimmune, Inc., following SPARQL query is issued (the namespaces been removed to improve readability): SELECT DISTINCT ?m ?r WHERE { ?m rdf:type dbpedia-owl:Drug . { ?m ?r dbpedia:MedImmune } UNION { dbpedia:MedImmune ?r ?m } } This query returns all items that are of type T and appear as either the predicate or object of a relation E. Table 2 shows the results of this example query the LOD SPARQL endpoint. There is no support w
- 14. Natural language processing - Question answering - “Who invented the paper clip?” - “What museums have displayed Chanel clothing?” - Relationship extraction
- 15. Ranking based on entity descriptions Attributes (/Descriptions) Type(s) Relationships
- 16. Task: ad-hoc entity retrieval - Input: unconstrained natural language query - “telegraphic” queries (neither well-formed nor grammatically correct sentences or questions) - Output: ranked list of entities - Collection: unstructured and/or semi- structured documents
- 17. Example information needs meg ryan war american embassy nairobi ben franklin Chernobyl Worst actor century Sweden Iceland currency
- 18. Two settings 1.With ready-made entity descriptions 2.Without explicit entity representations xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx e xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx e xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx e xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx
- 19. Ranking with ready-made entity descriptions
- 20. This is not unrealistic...
- 21. Document-based entity representations - Most entities have a “home page” - I.e., each entity is described by a document - In this scenario, ranking entities is much like ranking documents - unstructured - semi-structured
- 22. Evaluation initiatives - INEX Entity Ranking track (2007-09) - Collection is the (English) Wikipedia - Entities are represented by Wikipedia articles - Semantic Search Challenge (2010-11) - Collection is a Semantic Web crawl (BTC2009) - ~1 billion RDF triples - Entities are represented by URIs - INEX Linked Data track (2012-13) - Wikipedia enriched with RDF properties from DBpedia and YAGO
- 23. Standard Language Modeling approach - Rank documents d according to their likelihood of being relevant given a query q: P(d|q) P(d|q) = P(q|d)P(d) P(q) / P(q|d)P(d) Document prior Probability of the document being relevant to any query Query likelihood Probability that query q was “produced” by document d P(q|d) = Y t2q P(t|✓d)n(t,q)
- 24. Standard Language Modeling approach (2) Number of times t appears in q Empirical document model Collection model Smoothing parameter Maximum likelihood estimates P(q|d) = Y t2q P(t|✓d)n(t,q) Document language model Multinomial probability distribution over the vocabulary of terms P(t|✓d) = (1 )P(t|d) + P(t|C) n(t, d) |d| P d n(t, d) P d |d|
- 25. Here, documents==entities, so P(e|q) / P(e)P(q|✓e) = P(e) Y t2q P(t|✓e)n(t,q) Entity prior Probability of the entity being relevant to any query Entity language model Multinomial probability distribution over the vocabulary of terms
- 26. Semi-structured entity representation - Entity description documents are rarely unstructured - Representing entities as - Fielded documents – the IR approach - Graphs – the DB/SW approach
- 27. dbpedia:Audi_A4 foaf:name Audi A4 rdfs:label Audi A4 rdfs:comment The Audi A4 is a compact executive car produced since late 1994 by the German car manufacturer Audi, a subsidiary of the Volkswagen Group. The A4 has been built [...] dbpprop:production 1994 2001 2005 2008 rdf:type dbpedia-owl:MeanOfTransportation dbpedia-owl:Automobile dbpedia-owl:manufacturer dbpedia:Audi dbpedia-owl:class dbpedia:Compact_executive_car owl:sameAs freebase:Audi A4 is dbpedia-owl:predecessor of dbpedia:Audi_A5 is dbpprop:similar of dbpedia:Cadillac_BLS
- 28. Mixture of Language Models [Ogilvie & Callan 2003] - Build a separate language model for each field - Take a linear combination of them mX j=1 µj = 1 Field language model Smoothed with a collection model built from all document representations of the same type in the collectionField weights P(t|✓d) = mX j=1 µjP(t|✓dj )
- 29. Comparison of models d dfF ... t dfF t ... ...d tdf ... tdf ...d t ... t Unstructured document model Fielded document model Hierarchical document model
- 30. Setting field weights - Heuristically - Proportional to the length of text content in that field, to the field’s individual performance, etc. - Empirically (using training queries) - Problems - Number of possible fields is huge - It is not possible to optimise their weights directly - Entities are sparse w.r.t. different fields - Most entities have only a handful of predicates
- 31. Predicate folding - Idea: reduce the number of fields by grouping them together - Grouping based on (BM25F and) - type [Pérez-Agüera et al. 2010] - manually determined importance [Blanco et al. 2011]
- 32. Hierarchical Entity Model [Neumayer et al. 2012] - Organize fields into a 2-level hierarchy - Field types (4) on the top level - Individual fields of that type on the bottom level - Estimate field weights - Using training data for field types - Using heuristics for bottom-level types
- 33. Two-level hierarchy [Neumayer et al. 2012] foaf:name Audi A4 rdfs:label Audi A4 rdfs:comment The Audi A4 is a compact executive car produced since late 1994 by the German car manufacturer Audi, a subsidiary of the Volkswagen Group. The A4 has been built [...] dbpprop:production 1994 2001 2005 2008 rdf:type dbpedia-owl:MeanOfTransportation dbpedia-owl:Automobile dbpedia-owl:manufacturer dbpedia:Audi dbpedia-owl:class dbpedia:Compact_executive_car owl:sameAs freebase:Audi A4 is dbpedia-owl:predecessor of dbpedia:Audi_A5 is dbpprop:similar of dbpedia:Cadillac_BLS Name Attributes Out-relations In-relations
- 34. Comparison of models d dfF ... t dfF t ... ...d tdf ... tdf ...d t ... t Unstructured document model Fielded document model Hierarchical document model
- 35. Probabilistic Retrieval Model for Semistructured data [Kim et al. 2009] - Extension to the Mixture of Language Models - Find which document field each query term may be associated with Mapping probability Estimated for each query term P(t|✓d) = mX j=1 µjP(t|✓dj ) P(t|✓d) = mX j=1 P(dj|t)P(t|✓dj )
- 36. Estimating the mapping probability Term likelihood Probability of a query term occurring in a given field type Prior field probability Probability of mapping the query term to this field before observing collection statistics P(dj|t) = P(t|dj)P(dj) P(t) X dk P(t|dk)P(dk) P(t|Cj) = P d n(t, dj) P d |dj|
- 37. Example cast 0.407 team 0.382 title 0.187 genre 0.927 title 0.070 location 0.002 cast 0.601 team 0.381 title 0.017 dj dj djP(t|dj) P(t|dj) P(t|dj) meg ryan war
- 38. Ranking without explicit entity representations
- 39. Scenario - Entity descriptions are not readily available - Entity occurrences are annotated - manually - automatically (~entity linking)
- 40. TREC Enterprise track - Expert finding task (2005-08) - Enterprise setting (intranet of a large organization) - Given a query, return people who are experts on the query topic - List of potential experts is provided - We assume that the collection has been annotated with <person>...</person> tokens
- 41. The basic idea Use documents to go from queries to entities e xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x q xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx Query-document association the document’s relevance Document-entity association how well the document characterises the entity
- 42. Two principal approaches - Profile-based methods - Create a textual profile for entities, then rank them (by adapting document retrieval techniques) - Document-based methods - Indirect representation based on mentions identified in documents - First ranking documents (or snippets) and then aggregating evidence for associated entities
- 43. Profile-based methods q xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx e xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx e e
- 44. Document-based methods q xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx xx x xxxx x xxx xx xxxx x xxx xx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxxx xxxxxx xx x xxx xx x xxxx xx xxx x xxxxx xx x xxx xx xxxx xx xxx xx x xxxxx xxx X e X X e e
- 45. Many possibilities in terms of modeling - Generative (probabilistic) models - Discriminative (probabilistic) models - Voting models - Graph-based models
- 46. Generative probabilistic models - Candidate generation models (P(e|q)) - Two-stage language model - Topic generation models (P(q|e)) - Candidate model, a.k.a. Model 1 - Document model, a.k.a. Model 2 - Proximity-based variations - Both families of models can be derived from the Probability Ranking Principle [Fang & Zhai 2007]
- 47. Candidate models (“Model 1”) [Balog et al. 2006] P(q|✓e) = Y t2q P(t|✓e)n(t,q) Smoothing With collection-wide background model (1 )P(t|e) + P(t) X d P(t|d, e)P(d|e) Document-entity association Term-candidate co-occurrence In a particular document. In the simplest case:P(t|d)
- 48. Document models (“Model 2”) [Balog et al. 2006] P(q|e) = X d P(q|d, e)P(d|e) Document-entity association Document relevance How well document d supports the claim that e is relevant to q Y t2q P(t|d, e)n(t,q) Simplifying assumption (t and e are conditionally independent given d) P(t|✓d)
- 49. Document-entity associations - Boolean (or set-based) approach - Weighted by the confidence in entity linking - Consider other entities mentioned in the document
- 50. Proximity-based variations - So far, conditional independence assumption between candidates and terms when computing the probability P(t|d,e) - Relationship between terms and entities that in the same document is ignored - Entity is equally strongly associated with everything discussed in that document - Let’s capture the dependence between entities and terms - Use their distance in the document
- 51. Using proximity kernels [Petkova & Croft 2007] P(t|d, e) = 1 Z NX i=1 d(i, t)k(t, e) Indicator function 1 if the term at position i is t, 0 otherwise Normalizing contant Proximity-based kernel - constant function - triangle kernel - Gaussian kernel - step function
- 52. Figure taken from D. Petkova and W.B. Croft. Proximity-based document representation for named entity retrieval. CIKM'07.
- 53. Many possibilities in terms of modeling - Generative probabilistic models - Discriminative probabilistic models - Voting models - Graph-based models
- 54. Discriminative models - Vs. generative models: - Fewer assumptions (e.g., term independence) - “Let the data speak” - Sufficient amounts of training data required - Incorporating more document features, multiple signals for document-entity associations - Estimating P(r=1|e,q) directly (instead of P(e,q|r=1)) - Optimization can get trapped in a local maximum/ minimum
- 55. Arithmetic Mean Discriminative (AMD) model [Yang et al. 2010] P✓(r = 1|e, q) = X d P(r1 = 1|q, d)P(r2 = 1|e, d)P(d) Document prior Query-document relevance Document-entity relevance logistic function over a linear combination of features ⇣ Ng X j=1 jgj(e, dt) ⌘⇣ Nf X i=1 ↵ifi(q, dt) ⌘ standard logistic function weight parameters (learned) features
- 56. Learning to rank && entity retrieval - Pointwise - AMD, GMD [Yang et al. 2010] - Multilayer perceptrons, logistic regression [Sorg & Cimiano 2011] - Additive Groves [Moreira et al. 2011] - Pairwise - Ranking SVM [Yang et al. 2009] - RankBoost, RankNet [Moreira et al. 2011] - Listwise - AdaRank, Coordinate Ascent [Moreira et al. 2011]
- 57. Voting models [Macdonald & Ounis 2006] - Inspired by techniques from data fusion - Combining evidence from different sources - Documents ranked w.r.t. the query are seen as “votes” for the entity
- 58. Voting models Many different variants, including... - Votes - Number of documents mentioning the entity - Reciprocal Rank - Sum of inverse ranks of documents - CombSUM - Sum of scores of documents Score(e, q) = |{M(e) R(q)}| X {M(e)R(q)} s(d, q) Score(e, q) = X {M(e)R(q)} 1 rank(d, q) Score(e, q) = |M(e) R(q)|
- 59. Graph-based models [Serdyukov et al. 2008] - One particular way of constructing graphs - Vertices are documents and entities - Only document-entity edges - Search can be approached as a random walk on this graph - Pick a random document or entity - Follow links to entities or other documents - Repeat it a number of times
- 60. Infinite random walk [Serdyukov et al. 2008] Pi(d) = PJ (d) + (1 ) X e!d P(d|e)Pi 1(e), Pi(e) = X d!e P(e|d)Pi 1(d), PJ (d) = P(d|q), ee e d d e d d
- 63. If target type is not provided Rely on techniques from... - Federated search - Obtain a separate ranking for each type of entity, then merge [Kim & Croft 2010] - Aggregated search - Return top ranked entities from each type [Lalmas 2011]
- 64. Example (1) Mixing all types together (“federated search”)
- 65. Example (2) Grouping results by entity type (“aggregated search”)
- 66. Often, users provide target types explicitly
- 67. Type-aware entity ranking - Assume that the user provides target type(s) - Challenges - Target type information is imperfect - Users are not familiar with the classification system - Categorisation of entities is imperfect - Entity might belong to multiple categories - E.g. is King Arthur “British royalty”, “fictional character”, or “military person”? - Types can be hierarchically organised - Although it may not be a strict “is-a” hierarchy
- 68. INEX Entity Ranking track - Entities are represented by Wikipedia articles - Topic definition includes target categories Movies with eight or more Academy Awards best picture oscar british films american films
- 70. Using target type information - Constraining results - Soft/hard filtering - Different ways to measure type similarity (between target types and the types associated with the entity) - Set-based - Content-based - Lexical similarity of type labels - Query expansion - Adding terms from type names to the query - Entity expansion - Categories as a separate metadata field
- 71. Modeling terms and categories [Balog et al. 2011] Term-based representation Query model p(t|✓T e )p(t|✓T q ) p(c|✓C q ) p(c|✓C e ) Entity model Query model Entity model Category-based representation KL(✓T q ||✓T e ) KL(✓C q ||✓C e ) P(e|q) / P(q|e)P(e) P(q|e) = (1 )P(✓T q |✓T e ) + P(✓C q |✓C e )
- 72. Identifying target types for queries - Types of top ranked entities [Vallet & Zaragoza 2008] - Direct term-based vs. indirect entity-based representations [Balog & Neumayer 2012] - Hierarchical case is difficult... [Sawant & Chakrabarti 2013]
- 73. Expanding target types - Pseudo relevance feedback - Based on hierarchical structure - Using lexical similarity of type labels
- 75. Related entities
- 77. TREC Entity track - Related Entity Finding task - Given - Input entity (defined by name and homepage) - Type of the target entity (PER/ORG/LOC) - Narrative (describing the nature of the relation in free text) - Return (homepages of) related entities
- 78. Example information needs airlines that currently use Boeing 747 planes ORG Boeing 747 Members of The Beaux Arts Trio PER The Beaux Arts Trio What countries does Eurail operate in? LOC Eurail
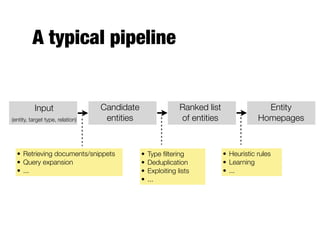
- 79. A typical pipeline Input (entity, target type, relation) Ranked list of entities Entity Homepages Candidate entities • Retrieving documents/snippets • Query expansion • ... • Type filtering • Deduplication • Exploiting lists • ... • Heuristic rules • Learning • ...
- 80. Modeling related entity finding [Bron et al. 2010] - Three-component model p(e|E, T, R) / p(e|E) · p(T|e) · p(R|E, e) Context model Type filtering Co-occurrence model
- 81. Anything else?
- 82. The usual suspects from document retrieval... - Priors - HITS, PageRank - Document link indegree [Kamps & Koolen 2008] - Pseudo relevance feedback - Document-centric vs. entity-centric [Macdonald & Ounis 2007; Serdyukov et al. 2007] - sampling expansion terms from top ranked documents and/or (profiles of) top ranked candidates - Field-based [Kim & Croft 2011]
- 83. Query understanding - Structuring and segmentation [Bendersky et al. 2010, Bendersky et al. 2011] - Aiding the user with context-sensitive suggestions [Bast et al. 2012] - Query interpretation with the help of knowledge bases [Pound et al. 2012]
- 84. Specialized interfaces [Bast et al. 2012] Figure taken from Bast et al. Broccoli: Semantic Full-Text Search at your Fingertips. http://arxiv.org/abs/1207.2615/
- 85. Semantic query understanding songs by jimi hendrix dbpedia:Jimi_Hendrixdbpedia-owl:Song dbpedia-owl:artist
- 86. Joint query interpretation and response ranking [Sawant & Chakrabarti 2013]
- 87. Tools & services
- 88. Public Toolkits and Web Services for Entity Retrieval - EARS - Sindice & SIREn - Sig.ma
- 89. EARS - Entity and Association Retrieval System - open source, built on top of Lemur in C++ - not actively maintained anymore (but still works) - Entity-topic association finding models - suited for other tasks, e.g. blog distillation - focuses on two entity-related tasks: - finding entities: - "Which entities are associated with topic X?" - profiling entities: - "What topics is an entity associated with?" - See https://code.google.com/p/ears/
- 90. Sindice/SIREn - Handling of semi-structured data - efficient, large scale - typically based on DBMS backends - uses Lucene for semi-structured search - Open source - Online demo, local install - See http://siren.sindice.com/
- 91. Sig.ma - Search, aggregate, and visualize LOD data - Powered by Sindice - See http://sig.ma/
- 92. Test collections
- 93. Test collections Campaign Task Collection Entity repr. #Topics TREC Enterprise (2005-08) Expert finding Enterprise intranets (W3C, CSIRO) Indirect 99 (W3C) 127 (CSIRO) TREC Entity (2009-11) Rel. entity finding Web crawl (ClueWeb09) Indirect 120TREC Entity (2009-11) List completion Web crawl (ClueWeb09) Indirect 70 INEX Entity Ranking (2007-09) Entity search Wikipedia Direct 55 INEX Entity Ranking (2007-09) List completion Wikipedia Direct 55 SemSearch Chall. (2010-11) Entity search Semantic Web crawl (BTC2009) Direct 142SemSearch Chall. (2010-11) List search Semantic Web crawl (BTC2009) Direct 50 INEX Linked Data (2012-13) Ad-hoc search Wikipedia + RDF (Wikipedia-LOD) Direct 100 (’12) 144 (’13)
- 94. Test collections (2) - Entity search as Question Answering - TREC QA track - QALD-2 challenge - INEX-LD Jeopardy task - DBpedia entity search [Balog & Neumayer 2013] - synthesized queries and assessments, distilled from previous campaigns - from short keyword queries to natural language questions - 485 queries in total; mapped to DBpedia
- 95. Open challenges
- 96. Open challenges - Combining text and structure - Knowledge bases and unstructured Web documents - Query understanding and modeling - UI/UX/Result presentation - How to interact with entities - Hyperlocal - Siri/Google Now/... - Recommendations
- 97. Open challenges (2) - There is more to types than currently exploited - Multiple category systems, hierarchy, ... - Entity retrieval is typically part of some more complex task - Buying a product, planning a vacation, etc.
- 98. Follow-up reading K. Balog, Y. Fang, M. de Rijke, P. Serdyukov, and L. Si. Expertise Retrieval. FnTIR'12.