A Structural Engineering Support System using Semantic Computing

This document presents a dissertation submitted by Thiti Vacharasintopchai for the degree of Doctor of Engineering in Structural Engineering. The dissertation proposes developing a support system for structural engineers using semantic computing technologies. It aims to address limitations in available computing tools and access to relevant knowledge that hinder engineer productivity. The dissertation reviews knowledge management and related technologies and outlines the development of two frameworks: 1) a Weblog and Digital Library framework (Blog+DL) for engineering knowledge management and 2) a Semantic Web Services framework (SWSCM) for computational mechanics. Proof of concept prototypes are developed to demonstrate the joint application of Blog+DL and SWSCM in building a support system and facilitating computationally intensive workflows.




















![<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
< rdf:Description
rdf:about="http://ce-res.blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html"
5 dc:title="Reinforced Concrete Design Worksheets">
<dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#rc-design"/>
<dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#working-stress-design"/>
<dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#ultimate-strength-design"/>
<dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#structural-members"/>
10 <dc:language rdf:resource="http://www.iso.org/iso/en/prods-services/iso3166ma/02iso-3166-code-
lists/list-en1.html#TH"/>
</ rdf:Description >
</rdf:RDF>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
15 xmlns:dc="http://purl.org/dc/elements/1.1/">
< rdf:Description
rdf:about="http://ce-res.blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html">
<dc:author rdf:resource="http://stweb.ait.ac.th/~st029284/foaf.rdf#thitiv"/>
</ rdf:Description >
20 </rdf:RDF>
Figure 2.2: Example of RDF Metadata Embedded in Web Page
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:foaf="http://xmlns.com/foaf/0.1/">
5 <foaf:PersonalProfileDocument
rdf:about="http://stweb.ait.ac.th/~st029284/foaf.rdf">
<foaf:maker rdf:resource="#thitiv"/>
<foaf:primaryTopic rdf:resource="#thitiv"/>
</foaf:PersonalProfileDocument>
10
<foaf:Person rdf:ID="thitiv">
<foaf:givenname>Thiti</foaf:givenname>
<foaf:family_name>Vacharasintopchai</foaf:family_name>
<foaf:mbox rdf:resource="mailto:thitiv[at]gmail.com"/>
15 <foaf:homepage rdf:resource="http://thitiv.blogspot.com"/>
</foaf:Person>
</rdf:RDF>
Figure 2.3: Sample RDF Statements about Person
Then he has to go to a search engine, such as Google, and type in the author’s
name and a keyword such as “e-mail” to search for traces of an e-mail address.
If John is lucky enough, he gets the e-mail address after the first search.
Semantic Web Solution. A set of RDF statements that describe the Web page (Fig-
ure 2.2) will usually be published in conjunction with the page content. A Se-
mantic Web-enabled Web browser will recognize the “is authored by” RDF state-
ment (the dc:author and the rdf:resource tags) and will be directed to the
RDF statements about the author. The Web browser can inspect the statements
about the author (Figure 2.3) and extract the author’s e-mail address from the
foaf:mbox statement automatically. This e-mail address will be suggested by
the Web browser as the e-mail address that John is looking for.
14](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-21-320.jpg)















![(a) Account Verification (b) Personalized Bookmarklets
Figure 4.3: User-specific Initialization of Prototype
and federated Search bookmarklets personalized (Figure 4.3b). Bookmarklets must be
dragged and dropped onto the bookmark toolbar of Mozilla Firefox before they can be
used.
Socialization and Externalization
In terms of publication, to externalize his knowledge and socialize, the engineer
logs on to his blog and clicks Manage to enter Blojsom administration console. To
create a new blog entry, he chooses the Add Entry command in the Entry toolbar which
directs him to the Add Blog Entry page. Here, he can start blogging about new findings,
as well as ideas and plans related to a project, in a fashion similar to composing e-
mails (Figure 4.4a). The content of his entry is automatically analyzed for important
keywords as he blogs, thanks to embedded AJAX codes, preregistered ontologies and
the Keyword Suggester. Checkboxes of suggested keywords are presented in real time
in the Smart Keyword Suggestions section where he can pick ones that apply. He may
also add invented keywords into the User’s specified textbox, although such a practice
is discouraged for vocabulary control reasons (Figure 4.4b). The composition of blog
entry completes when the Add Blog Entry button is clicked. New entries are saved into
the server’s database.
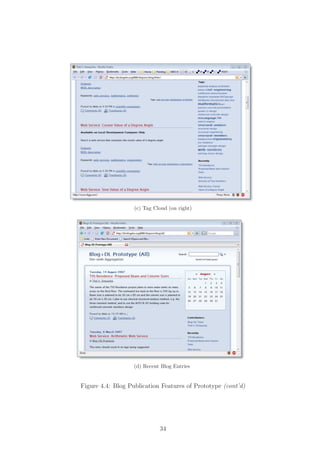
Entries by individual users are listed in a reverse chronological order on their per-
sonal blogs, accessible at the URLs http://http://kb.blogdns.org:8080/blojsom/
blog/[user_name]. Tag clouds, lists of tag names with varying font sizes, which rep-
resent different frequencies of keywords used by particular users, are also provided so
that visitors can easily navigate through various aspects of the authors’ interests (Fig-
ure 4.4c). Recent entries by all users are additionally aggregated on the prototype’s
homepage at the URL http://http://kb.blogdns.org:8080/blojsom (Figure 4.4d)
for quick overview of new contributions from all users.
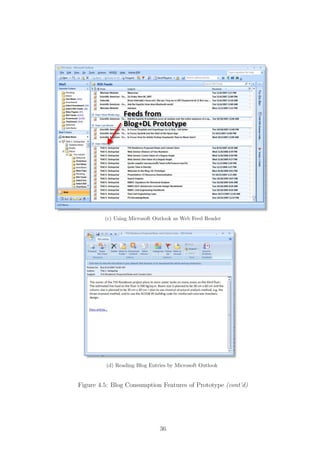
In terms of consumption, the engineer can browse through blog entries by visit-
ing the prototype’s homepage as well as personal ones of acquainted colleagues. He may
check for updates by paying regular visits to respective sites. Such a practice is consid-
ered the “pull” method of blog consumption. He may also choose the “push” method
to subscribe to blogs, as well as aggregated entries on the homepage, by clicking at the
orange Web feed icon at the right end of Web browser address bars, cf. Figures 4.4c, d.
By doing so, he is next presented with a Web feed subscription screen (Figure 4.5a)
where he can allow updated contents to be regularly pushed to him via a blog reader.
Figure 4.5b illustrates how a personal blog is subscribed as a Web feed source in Mi-
crosoft Outlook 2007. Excerpts from recent entries on the blog are regularly pushed
30](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-37-320.jpg)




























![REFERENCES
Al-Ghassani, A. M., Anumba, C. J., Carrillo, P. M., and Robinson, H. S. (2005).
Tools and techniques for knowledge management. In Anumba, C. J., Egbu, C., and
Carrillo, P., editors, Knowledge Management in Construction. Blackwell Publishing,
Oxford, U.K., 2005. ISBN 1-40-512972-7.
ANSYS (2006). ANSYS Finite Element Analysis Software: ANSYS Structural. AN-
SYS, Inc., 2006. Available online: http://www.ansys.com/products/structural.
asp. [Downloaded: April 29, 2006].
Apache (2003a). Apache Axis 1.1. Apache Software Foundation, 2003. Available
online: http://ws.apache.org/axis.
Apache (2003b). Web Services Invocation Framework 2.0. Apache Software Founda-
tion, 2003. Available online: http://ws.apache.org/wsif.
Apache (2007). Apache Lucene. Apache Software Foundation, 2007. Available online:
http://lucene.apache.org/java/docs/index.html. [Downloaded: November 12,
2007].
Barry, W. and Vacharasintopchai, T. (2001). A parallel implementation of the element-
free Galerkin method. In Proceedings of the 8th East Asia-Pacific Conference on
Structural Engineering and Construction (EASEC-8), page Paper No. 1068, Singa-
pore, December 5-7, 2001. Available online: http://stweb.ait.ac.th/~ st029284/
papers/parallel-efgm-easec-8.pdf. [Downloaded: March 20, 2007].
Basha, S., Cable, S., Galbraith, B., Hendricks, M., Irani, R., Milbery, J., Modi, T.,
Tost, A., and Toussaint, A. (2002). Professional Java Web Services. Wrox Press,
Ltd., 2002. ISBN 1-861003-75-7.
Berners-Lee, T., Masinter, L., and McCahill, M. (1994). RFC1738 Uniform Resource
Locators (URL). The Internet Engineering Task Force (IETF), December 1994.
Available online: http://www.ietf.org/rfc/rfc1738.txt. [Downloaded: August
29, 2003].
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The Semantic Web. Scientific
American, 284(5):34–43, May 2001.
Blogger (2007). Blogger homepage, Blogger.com – a Blog Service by Google, 2007.
Available online: http://www.blogger.com. [Downloaded: May 5, 2007].
Boakes, R. (2007). Semantic computing, August 2007. Available online: http://
semanticcomputing.org. [Downloaded: October 4, 2007].
Brown, J. S. and Duguid, P. (2000). The Social Life of Information. Harvard Business
School Press, Boston, MA, U.S.A., 2000.
Burstein, M., Bussler, C., Zaremba, M., Finin, T., Huhns, M. N., Paolucci, M., Sheth,
A. P., and Williams, S. (2005). A Semantic Web Services architecture. IEEE Internet
Computing, 9(5):72–81, September/October 2005. Available online: http://doi.
ieeecomputersociety.org/10.1109/MIC.2005.96.
63](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-70-320.jpg)
![Carrillo, P. and Chinowsky, P. (2006). Exploiting knowledge management: The en-
gineering and construction perspective. Journal of Management in Engineering, 22
(1):2–10, 2006.
Catlett, C. (2002). TeraGrid Primer. The TeraGrid Project, September 2002. Avail-
able online: http://www.teragrid.org/about/TeraGrid-Primer-Sept-02.pdf.
[Downloaded: June 10, 2003].
Chen, H.-M., Lin, Y.-C., and Chao, Y.-F. (2006). Application of web services for
structural engineering systems. Journal of Computing in Civil Engineering, 20(3):
154–164, 2006.
Chew, P., Chrisochoides, N., Gopalsamy, S., Heber, G., Ingraffea, T., Luke, E., Neto,
J., Pingali, K., Shih, A., Soni, B., Stodghill, P., Thompson, D., Vavasis, S., and
Wawrzynek, P. (2003). Computational science simulations based on Web Services.
In Proceedings of International Conference on Computational Science 2003, St. Pe-
tersburg, Russian Federation and Melbourne, Australia, June 2003. Available on-
line: http://www.cs.cornell.edu/stodghil/papers/iccs03.pdf. [Downloaded:
September 3, 2003].
Chiu, K., Govindaraju, M., and Bramley, R. (2002). Investigating the limits of SOAP
performance for scientific computing. In Proceedings of 11th IEEE International
Symposium on High Performance Distributed Computing (HPDC-11), Edinburgh,
Scotland, July 2002. Available online: http://www.extreme.indiana.edu/xgws/
papers/soap-hpdc2002/soap-hpdc2002.pdf. [Downloaded: September 3, 2003].
Cross, R. (1998). Managing for knowledge: Managing for growth. Knowledge Manage-
ment, 1(3):9–13, 1998.
Crystal, D. (2006). Language and the Internet. Cambridge University
Press, Cambridge, U.K., 2 edition, 2006. ISBN 0-52-186859-9. Avail-
able online: http://books.google.com/books?id=cnhnO0AO45AC&pg=PA15&dq=
blogosphere&sig=GTyNVN_DEzaeNCYOiTkZhPU5gUU#PPA15,M1. [Downloaded: May
4, 2007].
Czarnecki, D. (2007). Blojsom – java blog server software, 2007. Available online:
http://www.blojsom.com. [Downloaded: August 22, 2007].
de Geytere, T. (2007). A unified model of dynamic organizational knowledge cre-
ation: Explanation of SECI model of Nonaka and Takeuchi, 12manage B.V., 2007.
Available online: http://www.12manage.com/methods_nonaka_seci.html. [Down-
loaded: April 5, 2007].
Drucker, P. F. (1993). Post-Capitalist Society. HarperCollins, New York, U.S.A., 1993.
ISBN 0-88-730620-9.
DSpace (2007a). Dspace home page, DSpace Federation, 2007. Available online:
http://www.dspace.org. [Downloaded: August 22, 2007].
DSpace (2007b). MIT’s DSpace experience: A case study, MIT Libraries and Hewlett-
Packard Company, 2007. Available online: http://dspace.org/implement/
case-study.pdf. [Downloaded: May 5, 2007].
64](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-71-320.jpg)
![El-Tayeh, A. and Gil, N. (2007). Using digital socialization to support geographically
dispersed aec project teams. Journal of Construction Engineering and Management,
133(6):462–473, June 2007.
Fallside, D. C. (2001). XML Schema Part 0: Primer. World Wide Web Consor-
tium (W3C), May 2001. Available online: http://www.w3.org/TR/xmlschema-0.
[Downloaded: June 23, 2003].
Fielding, R., Gettys, J., Mogul, J., Frystyk, H., Masinter, L., Leach, P., and Berners-
Lee, T. (1999). RFC2616 Hypertext Transfer Protocol – HTTP/1.1. The Internet
Engineering Task Force (IETF), June 1999. Available online: http://www.ietf.
org/rfc/rfc2616.txt. [Downloaded: August 29, 2003].
Foster, I. and Gannon, D. (2003). The Open Grid Services Architecture Platform.
The Global Grid Forum, 2003. Available online: http://www.gridforum.org/
Meetings/ggf7/drafts/draft-ggf-ogsa-platform-2.pdf. [Downloaded: June
16, 2003].
Foster, I., Kesselman, C., and Tuecke, S. (2001). The anatomy of the Grid: En-
abling scalable virtual organizations. International Journal of Supercomputer Appli-
cations, 15(3), 2001. Available online: http://www.globus.org/research/papers/
anatomy.pdf. [Downloaded: June 6, 2003].
Foster, I. (2002). What is the Grid? A three point checklist. July 2002. Avail-
able online: http://www-fp.mcs.anl.gov/~ foster/Articles/WhatIsTheGrid.
pdf. [Downloaded: April 29, 2003].
GGF (2003). The Global Grid Forum website, The Global Grid Forum, 2003. Available
online: http://www.gridforum.org. [Downloaded: June 13, 2003].
Haarslev, V. and Moller, R. (2003). RACER User’s Guide and Reference Manual
(Version 1.7.7), November 2003. Available online: http://www.cs.concordia.ca/
~haarslev/racer/index.shtml. [Downloaded: January 30, 2004].
He, H. (2003). What is service-oriented architecture, September 2003. Available
online: http://webservices.xml.com/pub/a/ws/2003/09/30/soa.html. [Down-
loaded: September 19, 2007].
IPG (2003). What is the IPG? Information Power Grid Project, NASA, October 2003.
Available online: http://www.ipg.nasa.gov/aboutipg/what.html. [Downloaded:
June 11, 2003].
Jakobsen, T. (2006). Bookmarklets - Browser Power, April 2006. Available online:
http://subsimple.com/bookmarklets. [Downloaded: November 12, 2007].
Jena (2007). Jena – a Semantic Web framework for java, Hewlett-Packard Laboratories,
2007. Available online: http://jena.sourceforge.net. [Downloaded: November
12, 2007].
Jonathan Cohen & Associates (2004). Knowledge management for design firms: Case
studies, April 2004. Available online: http://www.jcarchitects.com/KM.html.
[Downloaded: April 27, 2007].
65](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-72-320.jpg)
![Lagoze, C., Van de Sompel, H., Nelson, M., and Warner, S. (2004). The Open
Archives Initiative Protocol for Metadata Harvesting. Open Archives Initiative
(OAI), October 2004. Available online: http://www.openarchives.org/OAI/
openarchivesprotocol.html. [Downloaded: May 11, 2007].
Liu, D., Peng, J., Law, K. H., Wiederhold, G., and Sriram, R. D. (2005). Composition
of engineering web services with distributed data-flows and computations. Advanced
Engineering Informatics, 19:25–42, 2005.
Martin, D., Burstein, M., Hobbs, J., Lassila, O., McDermott, D., McIlraith, S.,
Narayanan, S., Paolucci, M., Parsia, B., Payne, T., Sirin, E., Srinivasan, N., and
Sycara, K. (2004). OWL-S: Semantic Markup for Web Services. World Wide Web
Consortium (W3C), November 2004. Available online: http://www.w3.org/
Submission/OWL-S. [Downloaded: March 15, 2007]. W3C Member Submission.
Metcalfe, V. and Gierth, A. (1998). Programming UNIX Sockets in C - Frequently
Asked Questions, January 1998. Available online: http://www.faqs.org/faqs/
unix-faq/socket. [Downloaded: November 24, 2007].
Mezher, T., Abdul-Malak, M. A., Ghosn, I., and Ajam, M. (2005). Knowledge man-
agement in mechanical and industrial engineering consulting: A case study. Journal
of Management in Engineering, 21(3):138–147, 2005.
Microsoft (1996). DCOM technical overview, November 1996. Available online:
http://msdn2.microsoft.com/en-us/library/ms809340. [Downloaded: March
13, 2007].
Microsoft (2003). Microsoft .NET, Microsoft Corporation, 2003. Available online:
http://www.microsoft.com/net. [Downloaded: November 5, 2003].
MIT Libraries and Hewlett-Packard Company (2007). Introducing DSpace. DSpace
Federation, 2007. Available online: http://dspace.org/introduction/index.
html. [Downloaded: May 11, 2007].
Mozilla (2007). Mozilla firefox home page, Mozilla Corporation, 2007. Available online:
http://www.mozilla.com. [Downloaded: August 22, 2007].
Nardi, D., Brachman, R. J., Baader, F., Nutt, W., Donini, F. M., Sattler, U., Calvanese,
D., Molitor, R., De Giacomo, G., Kusters, R., Wolter, F., McGuinness, D. L., Patel-
Schneider, P. F., Moller, R., Haarslev, V., Horrocks, I., Borgida, A., Welty, C.,
Franconi, A. R. E., Lenzerini, M., and Rosati, R. (2003). The Description Logic
Handbook: Theory, Implementation and Applications. Cambridge University Press,
Cambridge, U.K., 2003. ISBN 0-521-78176-0.
NIST (1999). JAMA: Java Matrix Package. National Institute of Standards and
Technology, 1999. Available online: http://math.nist.gov/javanumerics/jama.
Nonaka, I. and Takeuchi, H. (1995). The Knowledge-Creating Company: How Japanese
Companies Create the Dynamics of Innovation. Oxford University Press, New York,
U.S.A., 1995. ISBN 0-19-509269-4.
66](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-73-320.jpg)
![Nottingham, M. and Sayre, R. (2005). The Atom Syndication Format. The Internet
Engineering Task Force (IETF), December 2005. Available online: http://www.
ietf.org/rfc/rfc4287. [Downloaded: May 8, 2007].
OASIS (2002). Universal Description, Discovery & Integration (UDDI) Specification
Version 2. Organization for the Advancement of Structured Information Stan-
dards (OASIS) Consortium, 2002. Available online: http://www.oasis-open.org/
committees/uddi-spec/tcspecs.shtml#uddiv2.
OMG (2005). The Common Object Request Broker Architecture: Frequently
asked questions, 2005. Available online: http://www.omg.org/gettingstarted/
corbafaq.htm. [Downloaded: March 13, 2007].
OWL–S (2003). OWL-S: Semantic markup for Web Services. Technical report, The
OWL Services Coalition, November 2003. Available online: http://www.daml.org/
services/owl-s/1.0/owl-s.pdf. [Downloaded: April 30, 2004].
Palme, J., Hopmann, A., and Shelness, N. (1999). RFC2557 Multipurpose Internet
Mail Extension (MIME) Encapsulation of Aggregate Documents, such as HTML
(MHTML). The Internet Engineering Task Force (IETF), March 1999. Available
online: http://tools.ietf.org/html/rfc2557. [Downloaded: November 8, 2007].
Palmer, S. B. (2002). RDF in HTML: Approaches, June 2002. Available online:
http://infomesh.net/2002/rdfinhtml. [Downloaded: March 14, 2007].
Paolucci, M., Kawamura, T., Payne, T. R., and Sycara, K. (2002). Semantic match-
ing of web services capabilities. In Proceedings of the First International Seman-
tic Web Conference (ISWC2002), pages 333–347, Sardinia, Italy, 2002. Available
online: http://www-2.cs.cmu.edu/~ softagents/papers/ISWC2002.pdf. [Down-
loaded: October 31, 2003].
Peng, J. and Law, K. H. (2004). Building finite element analysis programs in distributed
services environment. Computers and Structures, 82:1813–1833, 2004.
Pollock, N. (2001). Knowledge management: Next step to competitive advan-
tage. Journal of the Defense Systems Management College, September-October
2001. Available online: http://www.providersedge.com/docs/km_articles/KM_
-_Next_Step_to_Competitive_Advantage.pdf. [Downloaded: April 5, 2007].
Prot´g´ (2005). The Prot´g´ Ontology Editor and Knowledge Acquisition System. Stan-
e e e e
ford Medical Informatics Department, Stanford University, Stanford, CA, U.S.A.,
2005. Available online: http://protege.stanford.edu. [Downloaded: March 20,
2006].
Quintas, P. (2005). The nature and dimensions of knowledge management. In Anumba,
C. J., Egbu, C., and Carrillo, P., editors, Knowledge Management in Construction.
Blackwell Publishing, Oxford, U.K., 2005. ISBN 1-40-512972-7.
Reddy, R., Ager, T., Chellappa, R., Croft, W. B., Davis-Brown, B., Mendel, J. M.,
and Shamos, M. I. (1999). WTEC Panel report on digital information organization
in Japan. Technical report, Loyola College in Maryland, 1999. Available online:
http://www.wtec.org/loyola/digilibs/d_01.htm. [Downloaded: September 11,
2006].
67](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-74-320.jpg)
![Rezgui, Y. (2006). Ontology-centered knowledge management using information re-
trieval techniques. Journal of Computing in Civil Engineering, 20(4):261–270, July
2006.
Roman, D., Keller, U., Lausen, H., de Bruijn, J., Lara, R., Stollberg, M.,
Polleres, A., Feier, C., Bussler, C., and Fensel, D. (2005). Web ser-
vice modeling ontology. Applied Ontology, 1(1):77–106, 2005. Available
online: http://iospress.metapress.com/openurl.asp?genre=article&issn=
1570-5838&volume=1&issue=1&spage=77. [Downloaded: March 15, 2007].
RSS Advisory Board (2006). RSS 2.0 Specification. RSS Advisory Board, August 2006.
Available online: http://www.rssboard.org/rss-specification. [Downloaded:
May 8, 2007].
Sheehan, T., Poole, D., Lyttle, I., and Egbu, C. O. (2005). Strategies and business case
for knowledge management. In Anumba, C. J., Egbu, C., and Carrillo, P., editors,
Knowledge Management in Construction. Blackwell Publishing, Oxford, U.K., 2005.
ISBN 1-40-512972-7.
Sifry, D. (2007). The state of the Live Web, April 2007, Technorati, Inc., April 2007.
Available online: http://www.sifry.com/alerts/archives/000493.html. [Down-
loaded: May 8, 2007].
Sirin, E. (2004). OWL-S API, Maryland Information and Network Dynamics Lab
Semantic Web Agents (MINDSWAP) Project, Institute for Advanced Computer
Studies, University of Maryland, 2004. Available online: http://www.mindswap.
org/2004/owl-s/api. [Downloaded: June 29, 2004].
Sun Microsystems, Inc. (2007). Javamail api, Sun Microsystems, Inc., 2007. Avail-
able online: http://java.sun.com/products/javamail. [Downloaded: November
8, 2007].
Sycara, K., Paolucci, M., Ankolekar, A., and Srinivasan, N. (2003). Automated discov-
ery, interaction and composition of Semantic Web Services. Web Semantics: Science,
Services and Agents on the World Wide Web, 1(1):27–46, December 2003. Avail-
able online: http://dx.doi.org/10.1016/j.websem.2003.07.002. [Downloaded:
March 15, 2007].
Trott, B. and Trott, M. (2002). TrackBack Technical Specification, October 2002.
Available online: http://www.movabletype.org/docs/mttrackback.html. [Down-
loaded: May 8, 2007].
Turban, E. and Aronson, J. (2001). Decision Support Systems and Intelligent Systems.
Prentice Hall, London, U.K., 2001.
Vacharasintopchai, T. (2005). KMITL/SUT: Reinforced Concrete Design Work-
sheets. CE Resources Weblog, October 2005. Available online: http://ce-res.
blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html. [Down-
loaded: March 14, 2007].
Vacharasintopchai, T., Barry, W., Wuwongse, V., and Kanok-Nukulchai, W. (2007a).
Semantic Web Services framework for computational mechanics. Journal of Com-
puting in Civil Engineering, 21(2):65–77, March-April 2007.
68](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-75-320.jpg)
![Vacharasintopchai, T., Wuwongse, V., and Chalermsook, K. (2007b). Weblog, Digital
Library, and Semantic Web Services approach to computer-aided engineering design.
In Proceedings of the 8th Asia Pacific Conference on Industrial Engineering and
Management System (APIEMS2007), Kaohsiung, Taiwan, R.O.C., December 9-13,
2007.
van Engelen, R. A. (2003). Pushing the SOAP envelope with Web Services for scientific
computing. In Proceedings of the International Conference on Web Services (ICWS)
2003, Las Vegas, Nevada, USA, June 2003. Available online: http://www.cs.fsu.
edu/~engelen/icws03.pdf. [Downloaded: September 3, 2003].
W3C (1999a). HyperText Markup Language (HTML) 4.01 Specification.
World Wide Web Consortium (W3C), December 1999. Available online: http:
//www.w3.org/TR/html4.
W3C (1999b). Resource Description Framework (RDF) Model and Syntax Specifi-
cation. World Wide Web Consortium (W3C), February 1999. Available online:
http://www.w3.org/TR/1999/REC-rdf-syntax-19990222. [Downloaded: Septem-
ber 19, 2003].
W3C (2000). Simple Object Access Protocol (SOAP) 1.1. World Wide Web Consortium
(W3C), 2000. Available online: http://www.w3.org/TR/SOAP.
W3C (2001). Web Service Definition Language (WSDL) 1.1. World Wide Web Con-
sortium (W3C), 2001. Available online: http://www.w3.org/TR/wsdl.
W3C (2003). RDF Primer. World Wide Web Consortium (W3C), September
2003. Available online: http://www.w3.org/TR/2003/WD-rdf-primer-20030905.
[Downloaded: September 22, 2003]. W3C Working Draft.
W3C (2004a). OWL Web Ontology Language Overview. World Wide Web Consortium
(W3C), February 2004. Available online: http://www.w3.org/TR/owl-features/.
[Downloaded: March 15, 2004]. W3C Recommendation.
W3C (2004b). OWL Web Ontology Language: Semantics and Abstract Syntax. World
Wide Web Consortium (W3C), February 2004. Available online: http://www.w3.
org/TR/owl-semantics. [Downloaded: March 16, 2007].
W3C (2004c). RDF Semantics. World Wide Web Consortium (W3C), February 2004.
Available online: http://www.w3.org/TR/rdf-mt. [Downloaded: March 14, 2007].
W3C (2004d). Web Services Architecture. World Wide Web Consortium (W3C),
February 2004. Available online: http://www.w3.org/TR/ws-arch. [Downloaded:
March 13, 2007]. W3C Working Group Note.
Wielemaker, J., Schreiber, G., and Wielinga, B. (2003). Prolog-based infrastructure
for RDF: Performance and scalability. In Fensel, D., Sycara, K., and Mylopoulos, J.,
editors, Proceedings of the 2nd International Semantic Web Conference (ISWC’03),
pages 644–658, Sanibel Island, Florida, USA, October 20-23, 2003. Available
online: http://hcs.science.uva.nl/projects/SWI-Prolog/articles/iswc-03.
pdf. [Downloaded: April 25, 2006].
69](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-76-320.jpg)
![Wikipedia (2006a). General packet radio service, Wikipedia, The Free Encyclopedia,
April 13, 2006. Available online: http://en.wikipedia.org/wiki/GPRS. [Down-
loaded: April 30, 2006].
Wikipedia (2006b). Wi-fi, Wikipedia, The Free Encyclopedia, April 30, 2006. Available
online: http://en.wikipedia.org/wiki/WiFi. [Downloaded: April 30, 2006].
Wikipedia (2007a). Application Programming Interface. Wikipedia, The Free En-
cyclopedia, March 2007. Available online: http://en.wikipedia.org/wiki/API.
[Downloaded: March 14, 2007].
Wikipedia (2007b). Blog. Wikipedia, The Free Encyclopedia, May 2007. Available
online: http://en.wikipedia.org/wiki/Blog. [Downloaded: May 2, 2007].
Wikipedia (2007c). Blogosphere. Wikipedia, The Free Encyclopedia, April 2007. Avail-
able online: http://en.wikipedia.org/wiki/Blogosphere. [Downloaded: May 4,
2007].
Wikipedia (2007d). Digital Library. Wikipedia, The Free Encyclopedia, April
2007. Available online: http://en.wikipedia.org/wiki/Digital_library.
[Downloaded: May 2, 2007].
Wikipedia (2007e). Web Feed. Wikipedia, The Free Encyclopedia, May 2007. Available
online: http://en.wikipedia.org/wiki/Web_feed. [Downloaded: May 2, 2007].
Witten, I. H. and Bainbridge, D. (2003). How to Build a Digital Library. Morgan
Kaufmann Publishers, San Francisco, CA, U.S.A., 2003. ISBN 1-55-860790-0.
Witten, I. H., Boddie, S., and Thompson, J. (2006). Greenstone Digital Library User’s
Guide. University of Waikato, New Zealand, March 2006.
WordPress (2007). Wordpress homepage, Automattic, Inc., 2007. Available online:
http://wordpress.com. [Downloaded: May 5, 2007].
WSDL4J (2006). Web Services Description Language for Java (WSDL4J) toolkit,
November 2006. Available online: http://sourceforge.net/projects/wsdl4j.
[Downloaded: November 19, 2007].
70](https://image.slidesharecdn.com/2007bdissertationsemanticcomputingait-120305214825-phpapp02/85/A-Structural-Engineering-Support-System-using-Semantic-Computing-77-320.jpg)
A Structural Engineering Support System using Semantic Computing
- 1. A STRUCTURAL ENGINEERING SUPPORT SYSTEM USING SEMANTIC COMPUTING by Thiti Vacharasintopchai A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Engineering in Structural Engineering Examination Commitee: Professor Vilas Wuwongse (Chairperson) Professor Worsak Kanok-Nukulchai (Co-chairperson) Dr. Pennung Warnitchai Dr. B. H. W. Hadikusumo External Examiner: Professor Kincho H. Law Department of Civil and Environmental Engineering Stanford University Stanford, CA, U.S.A. Nationality: Thai Previous Degrees: B.Eng. (Civil Engineering) Chulalongkorn University Bangkok, Thailand M.Eng. (Structural Engineering) Asian Institute of Technology Bangkok, Thailand Scholarship Donor: RTG Fellowship Asian Institute of Technology School of Engineering and Technology Thailand December 2007 i
- 2. ACKNOWLEDGMENTS I would like to thank the Royal Thai Government for granting me a doctoral research fellowship at the Asian Institute of Technology. My pro- found gratitude is due to Professor Vilas Wuwongse and Professor Worsak Kanok-Nukulchai, my mentors and advisors who invariably gave highly valuable guidance, inspirational suggestions, encouragement and support throughout this research, to Professor Kincho H. Law from Stanford Uni- versity who gave highly valuable suggestions as the external examiner, and to Dr. William Barry, former doctoral advisor, master’s thesis advisor and good friend, who introduced me to the world of scientific computing. I would also like to express sincere appreciation for Dr. Pennung Warnitchai and Dr. B. H. W. Hadikusumo, doctoral committee members, who gave invaluable guidance and suggestions. I am grateful to Dr. Pannapa Her- abat for her unfailingly support and to Dr. Wisit U. Pongsa, my former employer, who gave several opportunities for conferences and professional training which form the basis of the work in this dissertation. Dr. Vo- ratas Kachitvichyanukul provided useful comments during the early stages of this research. Wouter Rosingh was of great help particularly towards the end. I wish to thank my parents, Chavalert Vacharasintopchai and Benjawan Chatnarat, my younger brothers, Nithi and Nipith, family mem- bers, Apsara Narat and Gallissara Agavatpanitch for their love, support and encouragement. Thanks are due to friends, especially Dr. Dussadee Satirasetthavee, Dr. Kannapa Pongponrat, Dr. Pongtawat Chippimolchai, Neelawat Intaraksa and Anisara Pensuk for their selfless care and generos- ity during my study at the Institute. Assistance from colleagues at the Knowledge Representation Laboratory and the School of Engineering and Technology, especially Yupa Soodjitporn and Worranuch Chumchat, are appreciated. I am also grateful to the Asian Development Bank and the Greater Mekong Subregion Academic Network for funding the knowledge management part of this research. ii
- 3. ABSTRACT Practicing structural engineers are often faced with limitations in avail- able computing tools as well as insufficient access to relevant knowledge for design projects and engineering jobs. At the launch of a project the im- mediate tasks invariably involve research, discussions with colleagues and a series of computations. These tasks are repeated over and over again until a final design is arrived at. The degree to which these tasks are well facilitated in an engineering firm helps determine the productivity of its engineers and thus the firm’s competitiveness in the industry. Semantic computing technologies such as Semantic Web Services, Weblog, and Dig- ital Library have substantial, hitherto untapped potential to improve the productivity of structural engineers. This dissertation proposes a support system for structural engineering using these semantic computing technolo- gies. A system architecture and the key software components for it are specified and prototype systems presented. The support system involves two frameworks of software infrastructure: first, the Weblog and Digital Library Framework for Engineering Knowledge Management (Blog+DL), which uses Weblogs and Digital Libraries as core components of a collab- orative structural engineering support system; second, the Semantic Web Services Framework for Computational Mechanics (SWSCM), a method- ology that unifies and utilizes scattered computing resources. Blog+DL and SWSCM are complementary methodologies in the engineering process. Blog+DL relies on SWSCM to integrate computing resources shared by sev- eral parties. SWSCM can use Blog+DL to deploy and discover shared com- puting resources, as well as to educate and exchange knowledge, including peer opinions about underlying theories and user experiences. Two proof of concept prototype systems were developed. The first system illustrates the joint application of Blog+DL and SWSCM to build support systems that facilitate the computationally oriented knowledge management process in structural engineering. The second system illustrates the full potential of SWSCM to facilitate a computationally intensive workflow that involves heterogeneous engineering software components. Blog+DL and SWSCM combine semantic computing technologies to build computer-aided engi- neering tools that improve the productivity of individual engineers and thereby enhance the competitiveness of engineering firms. Keywords: engineering support systems, knowledge management, productivity, software interoperability, Semantic Web Services, Semantic Web, Web Services, Internet, ontologies, artificial intelligence iii
- 4. TABLE OF CONTENTS Chapter Title Page Title Page i Acknowledgments ii Abstract iii Table of Contents iv List of Figures vi List of Tables vii 1 Introduction 1 1.1 Motivation 1 1.2 Problem Statement 1 1.3 Objectives 2 1.4 Scope and Research Approach 2 1.5 Contributions 3 1.6 Organization 3 2 Literature Review 4 2.1 Knowledge Management 4 2.1.1 Definition and Significance 4 2.1.2 Classification of Knowledge 5 2.1.3 Theory of Organizational Knowledge Creation 5 2.1.4 Knowledge Management Process and Tools 6 2.2 Knowledge Management in Engineering Design Firms 6 2.2.1 DAR Knowledge Management System 7 2.2.2 ADD and Arup Intranet Systems 7 2.3 Weblogs and Digital Libraries 8 2.3.1 Weblogs 8 2.3.2 Digital Libraries 9 2.4 Web Services 10 2.5 The Semantic Web 12 2.5.1 Background 12 2.5.2 How the Semantic Web Works 13 2.6 Semantic Web Services 15 2.6.1 Background 15 2.6.2 How Semantic Web Services Work 16 3 Development of a Support System for Structural En- gineering 18 3.1 Structural Engineers and Construction Projects 18 3.2 Design Principles 18 3.3 General System Architecture 20 3.4 Summary 21 4 A Structural Engineering Support System Using Semantic Computing 22 4.1 Introduction 22 iv
- 5. 4.2 Blog+DL Framework for Engineering Knowledge Man- agement 22 4.2.1 Technology Application Framework 22 4.2.2 System Architecture 24 4.3 A Semantic Computing-Based Support System for Struc- tural Engineers 27 4.3.1 Implementation 27 4.3.2 A Proof of Concept Prototype 29 4.4 Summary 31 5 Engineering Software Interoperability 44 5.1 Introduction 44 5.2 A Semantic Web Services Framework for Computa- tional Mechanics 44 5.2.1 SWSCM Model 45 5.2.2 Components of SWSCM Service 46 5.2.3 Communication between SWSCM Services 47 5.2.4 Inference Engine and Reasoning Process 48 5.2.5 Matchmaking Algorithm 50 5.3 Application to Structural Analysis and Design 51 5.3.1 Implementation 51 5.3.2 A Proof of Concept Prototype 53 5.4 Summary 56 6 Conclusions 59 6.1 Conclusion and Discussion 59 6.2 Recommendations for Further Research 61 References 63 v
- 6. LIST OF FIGURES Figure Title Page 2.1 Conceptual Web Services Model 10 2.2 Example of RDF Metadata Embedded in Web Page 14 2.3 Sample RDF Statements about Person 14 2.4 OWL-S Service Profile Description of GetSineValue Web Service 17 3.1 General Architecture of Support Systems 20 4.1 Blog, Digital Library, and Knowledge Conversion Modes 23 4.2 Blog+DL Framework for Computer-Aided Engineering Design 25 4.3 User-specific Initialization of Prototype 30 4.4 Blog Publication Features of Prototype 33 4.5 Blog Consumption Features of Prototype 35 4.6 Blog Socialization Features of Prototype 37 4.7 Knowledge Archiving Features of Prototype 38 4.8 Knowledge Retrieval Features of Prototype 41 5.1 Semantic Web Services Model 45 5.2 Semantic SOAP Message 46 5.3 Components of Semantic Web Service 46 5.4 System Configuration of Prototype 52 5.5 Windows Mobile User Interface 54 5.6 Sample Request Message from PDA Client 55 5.7 OWL Definition of ASTM A36 Steel 56 5.8 OWL Definition of Pinned Node 57 5.9 Output Screen on PDA Client 57 vi
- 7. LIST OF TABLES Table Title Page 6.1 Features Comparison with Existing Work 60 vii
- 8. CHAPTER 1 INTRODUCTION 1.1 Motivation Two obstacles that practicing structural engineers often face in a design project are limitations in available computing tools and limited access to relevant knowledge. Several tasks are involved when a project is launched, in terms of research, discussion with colleagues and computational workflow. These tasks are repeated over and over again until a final design is arrived at. If they are not well facilitated, multiple bottle- necks will occur and an engineering firm suffers low productivity among its engineers. Not all engineering firms can afford expensive design software packages, and the software itself often does not fully address their needs. Some firms may share a commercial software package or use it on a pay-per-use basis; whereas others develop software or subroutines in-house. Some in-house tools may be so well-developed or have such well-developed components that it is more productive for engineers to reuse them rather than to develop new systems from scratch. However, both commercial and in-house tools are typically based on specific assumptions that need to be satisfied beforehand, and their input and output data are usually based on specific conventions and formats that must be strictly followed to obtain sensible results. As the number of shared tools grows, it becomes difficult for users to find appropriate tools that fit their design problems best, and it is tedious for them to manually adapt the potentially incompatible input and output data of the tools to a computational workflow, such as the discretization–analysis–postprocessing process in finite element methods. In terms of knowledge management, on the launch of a new project, file cabi- nets are often searched to retrieve reference documents of similar past projects. For less common projects, significant time is typically invested in research to come up with a solution strategy with the assistance of senior engineers or experts. This process is time consuming and can become a bottleneck if not well facilitated. Many knowl- edge management solutions are available in the literature or as commercial software packages. However, most of them aim single-sidedly to capture tacit knowledge from experts into a knowledge repository, rather than facilitating the sharing, discussing and developing of new knowledge among individuals, which are key practices for the sustainable improvement of knowledge in an organization according to the theory of organizational knowledge creation (Nonaka and Takeuchi, 1995). 1.2 Problem Statement This research aims to create a support system that improves the productivity of structural engineers during the engineering process and, particularly, to alleviate the two obstacles introduced earlier which hinder the performance of practicing engineers. The realization of a support system that alleviates productivity obstacles involves ad- dressing issues in the following areas: 1. Identification of the necessary features for a structural engineering support sys- tem; 2. Knowledge management best practice according to knowledge management the- ory; and 3. Effective methodologies for precise storage and retrieval of knowledge. 1
- 9. 4. Development and sharing of in-house software tools as well as general-purpose software packages; 5. Automated integration and execution of in-house and general-purpose software tools; Knowledge and tools in structural engineering as well as well-established com- puter technologies, research, and standards are integrated in this study. The former are required to ensure that the obstacles specific to structural engineering are addressed and the latter are required to ensure the scalability and sustainability of the proposed solution. 1.3 Objectives The primary objective of this study is to develop a support system that improves the productivity of structural engineers during the engineering process. To fulfill this primary objective, the following secondary objectives are set: 1. To develop a framework and a prototype support system for structural engineers that facilitates the improvement and mutual sharing of knowledge and skills in the form of multimedia documents and computational tools. The framework includes (a) the identification of the features of a good knowledge management system based on knowledge management best practice, (b) a methodology to appropriately apply computing and information technolo- gies in the knowledge management context, and (c) methods and enabling modules that allow knowledge and computational tools to be created, shared and improved by semantic computing technolo- gies. 2. To develop a framework and a prototype system that enables the dissemina- tion and use of intelligently unified computational tools shared in the structural engineering knowledge system. Specifically, these include (a) a procedure for structural engineers to develop and/or disseminate in-house and commercial computational tools, (b) the data model and format requirements for structural engineering compu- tational tools to interoperate, (c) the software services and components necessary to receive, interpret, and process client requests, and (d) the decision processes, knowledge, and rules by which a software agent searches, evaluates, selects, and executes computational tools in a fully au- tomated structural engineering workflow. 1.4 Scope and Research Approach The scope of this study covers both knowledge management and computational interoperability in the structural engineering context. Beyond the literature review 2
- 10. traditional for research of this type, the work is anchored in observations of real world constraints on practicing engineers in engineering consulting firms as experienced by the author. This led to the development of a Web-based proof of concept knowl- edge management prototype as well as a set of software infrastructure for the sharing and interoperability of computational tools. The former facilitates the creating and sharing of knowledge in the form of multimedia files and computational services. It allows users to exchange opinions about posted issues and services and to save some of them to personal knowledge portfolios for later reference. It also allows access to shared computational tools which can be invoked and interoperated by the software infrastructure developed in this study. To demonstrate the full potential of this infras- tructure, a prototype is separately developed to illustrate an intelligent collaboration of many structural analysis software agents located on personal computers and parallel computer clusters on the Internet to solve problems in linear elasticity. The implementation of the system prototypes is based primarily on open-source software tools. Several widely-accepted semantic computing standards, such as XML, Web Services and Semantic Web standards sanctioned by the World Wide Web Con- sortium (W3C), have been used during the development of the frameworks and the prototypes. As the term “semantic” implies, artificial intelligence techniques are used extensively. 1.5 Contributions This study is aimed at improving the productivity of structural engineers in the engineering process by dealing with computational workflow and knowledge man- agement issues using semantic computing. The results of this study are an intelligent structural engineering support system and two underlying frameworks: one which cre- ates a collaborative environment where structural engineers, both novice and expert, can share and sustainably improve their knowledge and another which turns the Inter- net into a large platform for numerical analysis of structures where computational tools individually developed and located on heterogeneous computer platforms intelligently collaborate. It is expected that the application of the frameworks and support system developed and demonstrated in this study can alleviate computational and knowledge management problems in project design and other engineering work and thus improve the productivity of individual engineers and the competitiveness of engineering firms. 1.6 Organization The rest of this dissertation is organized as follows: Chapter 2 gives background information about the theory, technologies and research that pertain to the develop- ment of support systems for the engineering process. Chapter 3 describes common obstacles in the structural engineering process, identifies necessary features and con- ceptualizes the general design for structural engineering support systems. Chapter 4 presents the structural engineering support system using semantic computing and de- scribes the architectural framework on which it is based. Chapter 5 addresses the interoperability of computing resources which enables the sharing of computational tools via support systems. It proposes a framework for the interoperation of structural engineering software modules and demonstrates the framework by a system prototype and a case study. Chapter 6 concludes this dissertation and discusses the benefits and limitations of the presented work, with recommendations for further research. 3
- 11. CHAPTER 2 LITERATURE REVIEW “Semantic Computing encompasses all aspects of computing where data is encoded, processed, stored or transferred using techniques that communicate the meaning of the data in addition to the data itself” (Boakes, 2007). An overview of the theory, technolo- gies and research that pertain to the development of a support system for structural engineering processes using semantic computing is presented in this chapter. First, the theoretical background of knowledge management (KM) and two illustrative KM sys- tems for engineering design firms are presented. Weblogs, a socialization and knowledge sharing enabling technology for the Web, and Digital Libraries, a technology for fast and accurate archiving and retrieval of electronic documents and multimedia content in organizations, are discussed next. Web Services technology, a modern paradigm for distributed computing on the Internet is then presented. Finally, the Semantic Web, an emerging technology that brings artificial intelligence to the Web, and Semantic Web Services, the joint application of Web Services and the Semantic Web, are discussed. 2.1 Knowledge Management 2.1.1 Definition and Significance Knowledge management is a process for optimizing the effective application of intellectual assets to achieve organizational objectives (Pollock, 2001). It is “the disci- pline of creating a thriving work and learning environment that fosters the continuous creation, aggregation, use and re-use of both organizational and personal knowledge in the pursuit of new business value” (Cross, 1998, as cited in Quintas 2005). Knowledge, the sets of processed information in a relevant context ready for understanding and action (Turban and Aronson, 2001, as cited in Mezher et al. 2005), is an organization- specific resource that is indispensable to create value for the organization (de Geytere, 2007). Knowledge differs from data and information in that it is “a function of a particular stance, perspective, or intention” and involves an action “to some end;” whereas information and data are the “necessary medium or materials for eliciting and constructing knowledge.” Knowledge, data, and information however are alike in that they are “context specific” and “relational” (Nonaka and Takeuchi, 1995, p. 58). In decision making terms, knowledge contains the least “noise” whereas data contains the most noise pertaining to a decision making process (Sheehan et al., 2005). Business organizations that manage the creation and the application of knowledge more effec- tively will be more competitive than others. Organizations that better manage and share knowledge from past experiences of their peers will more effectively utilize their resources to fulfill their mission. In the construction industry, which is very competi- tive with low profit margins, although each project is invariably to some extent unique, there are common processes which require engineers to seek out knowledgeable persons “who know what” and to learn the “lessons learned” from them in a timely fashion to minimize cost and stay competitive. This competitive environment has made KM attractive in engineering consultant firms (Carrillo and Chinowsky, 2006; Mezher et al., 2005). KM helps an engineering consulting firm to leverage their technical skills and store them in a manner to speed up the work, and compete with others in such a way that projects are produced with high quality in less time (Mezher et al., 2005). As the world enters the “knowledge society,” the basic economic resource is no longer capital, 4
- 12. natural resources, or labor, but is and will be knowledge; and “knowledge workers” will play an increasingly central role in society (Drucker, 1993; Nonaka and Takeuchi, 1995). 2.1.2 Classification of Knowledge Knowledge can be classified into two kinds, namely, explicit knowledge and tacit knowledge. Explicit knowledge can be articulated in formal language such as grammat- ical statements, mathematical expressions, and manuals, which can be processed by a computer with relative ease. Tacit knowledge on the other hand consists of personal knowledge embedded in individual experience and involves intangible factors such as personal beliefs, perspectives, and value systems, which are difficult to articulate com- pletely in formal language. Because of its subjective and intuitive nature, it is difficult to process or transmit acquired tacit knowledge in a systematic or logical manner (Non- aka and Takeuchi, 1995). A large portion of human knowledge resides in the form of tacit knowledge, and often tacit knowledge is regarded as the more important kind of knowledge (Nonaka and Takeuchi, 1995, p. viii), as may be illustrated by the quotes “If NASA wanted to go to the moon again, it would have to start from scratch, hav- ing lost not the data, but the human expertise that took it there last time” (Brown and Duguid, 2000, as cited in Quintas 2005) and “A master craftsman ... develops a wealth of expertise at his fingertips after years of experience. But he is often unable to articulate the scientific or technical principles behind what he knows” (Nonaka and Takeuchi, 1995, p. 8). 2.1.3 Theory of Organizational Knowledge Creation Knowledge is dynamic in nature. Nonaka and Takeuchi (1995) proposed the theory of organizational knowledge creation which postulates four temporal modes of conversion among tacit and explicit knowledge, namely, (1) socialization from tacit knowledge to tacit knowledge, (2) externalization from tacit knowledge to explicit knowledge, (3) combination from explicit knowledge to explicit knowledge, and (4) in- ternalization from explicit to tacit knowledge, which constitute the “knowledge spiral” that drives innovation in an organization. Socialization, the process of “sharing experiences and thereby creating tacit knowledge” such as shared mental models and technical skills, helps an individual to acquire tacit knowledge directly from others through observation, imitation, and practice in a field of interaction. Externalization, the process of “articulating tacit knowledge into explicit concepts,” is the definitive process through which an individ- ual attempts to conceptualize a mental image linguistically by metaphors, analogies, concepts, hypotheses, or models. It is typically used in the process of concept cre- ations and is “triggered” by meaningful dialog or collective reflection. Combination, the process of “systemizing concepts into a knowledge system,” involves “networking” different bodies of explicit knowledge in media such as documents or computerized communication channels so that they are “crystallized” into a new piece of knowledge, product, service, or methodology. Formal education and training in schools usually takes the combination form of knowledge conversion. Internalization, the process of “embodying explicit knowledge into tacit knowledge,” is the process through which experiences of individuals, obtained through socialization, externalization, and combi- nation, are internalized into their tacit knowledge bases in the form of shared mental models or technical know-how. Internalization is closely related to “learning by do- 5
- 13. ing.” Documentation helps individuals to internalize what they experienced and also facilitates the transfer of explicit knowledge to other people. Each mode of knowledge conversion naturally produces different knowledge types: socialization produces sympathized knowledge; externalization produces con- ceptual knowledge; combination produces systemic knowledge; and internalization pro- duces operational knowledge. These knowledge types interact with each other in a spiral fashion: sympathized knowledge may become explicit conceptual knowledge through socialization and externalization. The conceptual knowledge produced then becomes a guideline for creating systemic knowledge through combination. The systemic knowl- edge is next converted to operational knowledge through internalization. When an individual socializes with colleagues and externalizes his knowledge, his operational knowledge consequently triggers a new cycle of knowledge creation. Knowledge conver- sion is a social process between individuals and is not confined within an individual. As human cognition is the deductive process of an individual, who is never isolated from so- cial interaction when things are perceived, the quality and quantity of tacit and explicit knowledge are constantly “amplified” through shifts between these social conversion processes. The four temporal modes of knowledge conversion among individual staff members, departments, and divisions in an organization therefore constitute a “knowl- edge spiral” that drives innovation in the organization. This knowledge creation model, based on the theory of organizational knowledge creation, is sometimes called the Socialization-Externalization-Combination-Internalization (SECI) model (de Geytere, 2007). 2.1.4 Knowledge Management Process and Tools The KM process has been discovered rather than invented. Human activity is inconceivable without knowledge. Even though the phrase “knowledge management” came into common usage in the mid-1990s, the management of knowledge processes began long before the term was coined, without the KM label (Quintas, 2005). KM is different in each organization. There is no one right way and organizations develop different approaches according to their values and objectives (Sheehan et al., 2005). Some KM processes that function well may not have the KM label affixed. In contrast “many so-called KM initiatives and tools that emerged in the late 1990s were less concerned with addressing real knowledge issues than informal or existing processes that are not so labeled” (Quintas, 2005). The focus of these initiatives and tools was often on capturing explicit knowledge, rather than facilitating the conversion and sharing of tacit and explicit knowledge, as in the SECI model. Their scope can thus more properly be described as limited to “information management.” 2.2 Knowledge Management in Engineering Design Firms Structural engineers often work for engineering design and consultant firms rather than for construction managers or contractors. The nature of their work differs from that in construction management, in which project planning and scheduling, re- source allocation, procurement and document management are of more concern. Multi- ple KM initiatives and tools for engineering design firms are available in the literature, cf. Mezher et al. (2005); Jonathan Cohen & Associates (2004); Al-Ghassani et al. (2005); Carrillo and Chinowsky (2006). Most of them, however, rely on proprietary technologies that do not conform to Internet standards other than basic HTTP and 6
- 14. HTML for Web publication. Cross-system interoperability and advanced applications of Web technologies, such as the Semantic Web (Berners-Lee et al., 2001) and Web feeds (Wikipedia, 2007e) cannot therefore be implemented without major modifications of these approaches. For illustrative purposes, the intranet knowledge management sys- tems at the consultant firms DAR, ADD Inc. and Ove Arup and Partners are presented. Weblogs and Digital Libraries, recent Internet technologies which overcome these diffi- culties and can be integrated to form part of a more effective knowledge management system, are introduced in the next section. 2.2.1 DAR Knowledge Management System Mezher et al. (2005) developed a KM system at the DAR consulting firm. The system was developed based on the KM cycle outlined by Turban and Aronson (2001) which consists of six processes, namely, (1) the creation of knowledge from design procedures prepared by engineers, lessons learned from construction sites and known design hints and shortcuts, (2) the capturing of explicit and tacit knowledge created by the first process, (3) the refining of knowledge through the review and approval by group leaders and directors, (4) the storage of useful knowledge in a repository for access by others in the organization, (5) the management of knowledge to main- tain relevance, accuracy and currency, and (6) the dissemination of knowledge in a format useful to users. The system consists of shared folders on the department’s file server repository at the head office and a Web-based user interface that helps users to access Word, Excel or AutoCAD documents and relevant e-mails in file server hi- erarchies. Folders on the file server include design standards and manuals, archives of completed project drawings and documents, pending project drawings and documents, department-specific software and worksheets, libraries of AutoCAD shortcut menus and programs as well as document templates and forms, all of which go through the six KM cycle processes above. Access to these folders is restricted to relevant personnel. The system is accessible from branch offices through the company’s intranet. The system provides engineers with ready access to proper design templates and procedures, as well as past site lessons. It prevents unnecessary re-work and allows en- gineers to work both faster and more efficiently. Although the knowledge retrieval process is assisted by a Web interface, it is not clear whether the knowledge creation and review workflow and repositorial publication, which are part of the externalization process, are computerized or automated. Metadata, as well as keyword and full-text search features, which are information and tools necessary for precise retrieval of knowl- edge from large knowledge bases or nested folder hierarchies, are not mentioned. The system is therefore likely to not be scalable. Users will also find it difficult to review, publish and precisely locate pieces of knowledge as the size of the knowledge base grows. In addition, the system does not support communication means other than e-mails to enable peer discussion and collaboration, leaving the socialization aspect of the SECI model relatively unfacilitated. 2.2.2 ADD and Arup Intranet Systems Jonathan Cohen & Associates (2004) developed intranet KM systems for ADD Inc. and Ove Arup and Partners. ADD is a medium-sized multidisciplinary design firm with 150 employees and three offices in Cambridge, Massachusetts, San Francisco and Miami; whereas Arup is a very large engineering consultant firm with 5,000 employees in 60 offices and 40 countries. 7
- 15. The ADD intranet is a unified Web portal to internal firm information. ADD staff are directed to a “today” homepage when they enter the site where they are presented with updated events, news and announcements stored on a shared calendar database. From the homepage, they can navigate to information about firm standard procedures, document templates and CAD details. Meetings can be scheduled using the calendar function; and pictures and news items can be shared among colleagues through personal pages assigned to each user. These personal pages help to create a social network across the three offices. A list of experts within the firm is also posted on the intranet so that they can be promptly consulted should the need arise. The Arup intranet is an attempt to create a road map to the knowledge within the firm, which is so large that it is difficult to keep track of all the expertise it possesses. The Arup intranet is a central repository of the firm’s expertise that provides firm- wide access to specifications in Word and PDF formats as well as CAD details with a database that tracks how specific details have been implemented in projects. Arup’s engineers can annotate their experience with the details and specifications, such as how they worked in one project and failed in another, and so capture the feedback loop between design and implementation. These experience records and the feedback loop are invaluable information and practice that help distinguish Arup in the marketplace. Employees of Arup are also allowed to “volunteer” information through personal Web pages where they can quickly and easily share their interests and expertise with the rest of the firm (Sheehan et al., 2005). In this way individuals can socialize and join the SECI knowledge spiral which drives innovation at the firm. The ADD and Arup intranet systems are examples of systems that conform to KM best practice but rely on proprietary techniques. Cross-system interoperability and advanced applications of recent Web technologies, which can further improve the productivity of engineers, cannot thus be implemented easily. 2.3 Weblogs and Digital Libraries 2.3.1 Weblogs A weblog, or a blog, is a Web-based journal publication which consists primarily of periodic articles, normally in reverse chronological order (Wikipedia, 2007b). Each article in a blog is called a blog entry. A person who publishes to a blog is called a blogger . To publish to a blog is called to blog, the gerund form of which is blogging. The totality of all blogs on the Internet is called the blogosphere (Wikipedia, 2007c; Crystal, 2006). A blog entry usually consists of (1) the title, (2) the content, (3) the categories, tag names, or keywords of the content, (4) the date and time of publication, (5) the comment section where readers and the blogger can discuss and exchange experiences and opinions about issues raised in the blog entry, and (6) the trackback (Trott and Trott, 2002) hyperlink where the readers who blog about the blog entry can notify the original blogger about the existence and the content of their blogs. Hyperlinks, comments, trackbacks, and citations in blogs create online social networks and promote the externalization, socialization, and combinations of knowledge among the bloggers, according to the SECI model. Blogging is as easy as composing an e-mail. A blogger can blog about anything, ranging from news items, personal opinions, pictures, hobbies, problems at work, to random thoughts. A blog entry usually contains some hyperlinks to other Web docu- 8
- 16. ments which are the subjects of discussion. To publish a blog entry, a blogger logs on to his account on the blog service provider Website, cf. Blogger (2007) and WordPress (2007), clicks the compose button, types the content into a Web form, enters the title and keywords for the content. Multimedia contents such as pictures, audio/video clips, as well as Word and Excel files can be uploaded and included as attachments. When a publish button is clicked, the blog entry is instantly published to the Internet and can be accessed by friends, colleagues, and the public through regular Web browsers, Web search engines, and dedicated blog reader software which conforms to the Really Sim- ple Syndication (RSS) (RSS Advisory Board, 2006) or Atom (Nottingham and Sayre, 2005) Web syndication (a.k.a. Web feed) standards. A blogger can also send e-mails to a secret e-mail address to publish the contents and picture attachments directly from an e-mail client software on a laptop computer or a mobile phone. Blogging thus allows people to share information on the Internet with very few barriers. Technorati, Inc., a Web tracking company, reported that as of April 2007 there were 70 millions blogs on the Internet, with 120,000 new blogs added each day, and 1.5 million posts per day. The blogosphere grew from 35 to 70 million blogs in 320 days. Japanese, English, Chinese, and Italian are the four major blogging languages—37 percent of the blogs are in Japanese, 33 percent in English, 8 percent in Chinese, and 3 percent in Italian (Sifry, 2007). 2.3.2 Digital Libraries A digital library is an integrated set of services for capturing, cataloging, stor- ing, searching, protecting, and retrieving information (Reddy et al., 1999). It comprises focused collections of digital objects, including text, video, and audio, along with meth- ods for access and retrieval, and for selection, organization, and maintenance of the collections (Witten and Bainbridge, 2003), all of which support life-long learning, re- search, scholarly communication and preservation (Wikipedia, 2007d). Digital libraries were originally used to archive the digitized copies of rare documents, books, and the pictures of historical objects so that they can be studied by people of later generations. They have also recently been used as central repositories to preserve the works of in- dividuals in an organization, so that they do not vanish with time and technological obsolescence (DSpace, 2007b). A digital library system is often developed such that it is accessible on the Web, with the user interface resembling that of a Website. However, not all Websites, even the ones that offer focused collections of well-organized material and appropriate methods of access and retrieval, can be regarded as digital libraries, unless metadata (data about data), which are important information to precisely catalog, locate and retrieve pieces of information, are stored along with each object in the collections, and the access, retrieval, and modification of metadata, as well as the retrieval of objects based on them, are facilitated by the system (Witten and Bainbridge, 2003). The metadata typically used in digital libraries include bibliographic information and subject keywords, much as the indexing information used in physical libraries. The users of a digital library system have one of two roles, namely, the publisher and the reader. In some digital library implementations, such as the Greenstone Dig- ital Library software (Witten et al., 2006), a librarian takes the sole publisher role to capture (e.g., by scanning printed articles or typing in a word-processor), create cata- loging metadata, store, manage, and publish the collections of digital objects; and the general users take the reader role to browse, search, and consume information in the 9
- 17. Service UDDI Description Service WSDL Registry Pu d bli Fin sh Service Service Bind Consumer Provider SOAP Web Service Figure 2.1: Conceptual Web Services Model collections. In other digital library implementations, such as DSpace (MIT Libraries and Hewlett-Packard Company, 2007) which is based on an institutional repository concept, select users may also publish to some collections in the repository, thus taking both the publisher and the reader roles. Computers and users can locate objects across heterogeneous digital library systems by using standard query protocols, such as the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) (Lagoze et al., 2004). When a digital library system is deployed in an organization, it functions as a knowledge base which stores explicit and externalized knowledge from the users. The metadata-rich search feature of the system also allows users to precisely and promptly locate pieces of knowledge which can be used to solve their specific problems in a timely fashion. In this sense, a digital library system can thus promote the combination and internalization of knowledge in the SECI model. 2.4 Web Services Web Services (W3C, 2004d) is a modern paradigm of distributed computing that uses the Internet as the communication medium. Its fundamental concept is to build computer software by making use of remote procedure calls (RPC) over the In- ternet or an intranet. It differs from other distributed computing technologies, for example CORBA (OMG, 2005) and DCOM (Microsoft, 1996), in the use of platform- independent standards, based on HTTP (Fielding et al., 1999) and Extensible Markup Language (XML) (Fallside, 2001), which allows service providers to hide the imple- mentation details from clients. The clients need to know the URLs (Berners-Lee et al., 1994) of the services and the data types for method calls, but not the details of the service implementation in order to use them (Basha et al., 2002). Web Services is dif- ferent from the common term “web services” (spelled in lower case) adopted by some researchers, which simply refers to the “ability to access many services through the Internet” (Chen et al., 2006) via an arbitrary communication protocol without regard to the specific World Wide Web Consortium (W3C) standards that are introduced in this section. The typical architecture of Web Services is shown in Figure 2.1. Three roles, namely, a service provider, a service consumer, and a service registry, and three oper- ations, namely, publishing, finding, and binding, are involved. A service provider is an entity that creates Web services. Typically, it exposes 10
- 18. certain functionality in their organization as a Web service that is made available for any other organization to invoke. To be effective, a Web service needs to perform two tasks. First, it needs to describe the Web service in a standard format that is understandable by all organizations that will be using that Web service. Next it needs to publish the details about its Web service in a central registry that is publicly accessible. A service consumer is any organization that uses Web services provided by a service provider. It knows the functionality of a particular Web service from the description made available by the service provider. To retrieve those details, a service consumer searches the registry where the service provider has published its Web service description. The service consumer can then obtain the description of the required mechanism, bind to the service provider’s Web service and invoke that Web service. A service registry is a central location where service providers list their Web services, and where service consumers search for them. Service providers usually pub- lish their Web service capabilities in the service registry for service consumers to find and later, if interested in the provided service, bind to them. Examples of information typically stored in the service registry include the detailed description of an organiza- tion, the Web services that it provides, and a written description of each Web service as well as the input and output formats for its invocation. Web services take multiple roles on different occasions. A Web service takes the “provider” role when it accepts requests from consumers to be processed. It takes the “consumer” role when it delegates its tasks to other Web services. A Web service provider takes the special role of “service registry” if it helps a service consumer to discover a service provider for later binding. A client program that interacts only with end users takes the consumer role when it requests a service from a Web service provider. The Web Services architecture aims to achieve interapplication communication, irrespective of the programming language that the application is written in or the platform that the application is running on, by three fundamental operations which are “finding,” “binding,” and “publishing.” To make this happen, standards for each of these three operations and a standard way for a service provider to describe their Web services are needed. The Web Service Description Language (WSDL) (W3C, 2001) is such a standard that uses the XML data format to describe Web services. The WSDL document for a Web service defines the methods that are present in the Web service, the input/output parameters for each method, the data types, the network transport protocol used, and the URLs where requests for services are to be submitted and from which the results can be received. The Universal Description, Discovery, and Integration (UDDI) standard (OA- SIS, 2002) provides a way for service providers to publish details about their organi- zation and the Web services that they provide to a central registry. It also provides a standard for service consumers to find service providers and details about their Web services. Publication of the details is the “description” part of UDDI and the location of such details is the “discovery” part of it. Publication of these details is typically achieved by advertising hyperlinks to their WSDL documents on UDDI service reg- istries. Communication between service consumers, service providers and service reg- istries is through the Simple Object Access Protocol (SOAP) (W3C, 2000), which is a 11
- 19. lightweight XML communication mechanism to exchange information between appli- cations, regardless of the operating systems, programming languages, or object models employed in their development. SOAP may be visualized as a “carrier” of data encoded in XML format. Web Services technology has been involved in many areas of scientific comput- ing, ranging from computational infrastructure developments (Chiu et al., 2002; van Engelen, 2003) to finite-element analysis of a coupled fluid, thermal, and mechani- cal fracture problem (Chew et al., 2003). One significant effort in this area is the standardization attempt by the Global Grid Forum (GGF, 2003) to create the Open Grid Service Architecture specification (OGSA) (Foster and Gannon, 2003) which is the global standard for interoperation in the grid computing community (Foster, 2002; Foster et al., 2001) and is the specification in which the SOAP and WSDL standards, two important components of Web Services architecture, have been adopted. As there are already a significant number of scientific computing projects that rely on grid com- puting infrastructure, such as NASA’s Information Power Grid (IPG, 2003) and the TeraGrid (Catlett, 2002), imposition of such a standard is likely to increase the number of scientific computing applications that rely on Web Services technology significantly. 2.5 The Semantic Web 2.5.1 Background The Semantic Web (Berners-Lee et al., 2001) is a vision for the next generation of the Web on which information will be useful and meaningful not only for people but also for computers. Computers will be able to understand pieces of information on Web pages rather than merely presenting them to users, and will thus be able to autonomously assist users in manipulating the information. The Semantic Web is not a separate Web. Rather, it is an evolution of the present Web into one in which information is given well-defined meaning (Berners-Lee et al., 2001). Documents on the present Web can be transformed into Semantic Web documents by augmenting them with metadata aimed at computers. Metadata is data about other data that enables computers to determine the meaning of information in a Web document by following hyperlinks to definitions of key terms and rules for reasoning about them logically. The Semantic Web relies on two existing technologies which are XML and the Resource Description Framework (RDF) (Berners-Lee et al., 2001). XML (Fallside, 2001), a generalization of HTML (W3C, 1999a), has been pro- posed as the language for the publication of Web documents. XML allows Web pub- lishers to add structure to their documents by using tags, which are hidden labels that annotate Web pages or sections of text on a page. Computer programs can make use of these tags in many ways, from rendering XML documents in a human-friendly format on Web browsers, to mapping XML documents as data sources. However, XML tags are not uniformly created and they can be used by different groups of people. There- fore, their intended meaning must be precisely comprehended by the programmers in order to develop programs that properly manipulate the XML tags. The intended meaning of an XML tag will be understood if the name of the tag is drawn from a common dictionary. RDF (W3C, 1999b) is a language for describing information about resources on the Web. Typically encoded in XML format itself, the RDF language allows Web 12
- 20. publishers to assert that particular things (Web pages, videos, etc.) have properties (such as “is authored by” or “is a kind of”) with certain values (such as a thing, a person, etc.), in a grammatical form similar to the subject, verb, and object of an elementary sentence (Berners-Lee et al., 2001). An assertion that the Web page “www.asce.org” “is authored by” “ASCE” is called an RDF statement, or a triple. A set of triples with the same term or concept in a domain forms a definition of the term. A collection of the definitions and the relations among terms in a domain constitutes an ontology of the domain. In the context of the Semantic Web, an ontology is a document or file that formally defines terms and their relations (Berners-Lee et al., 2001). It can serve as a common dictionary from which XML tag names, and RDF property names and values can be drawn. Subjects, verbs, and objects in RDF statements are uniquely identified by Uni- versal Resource Identifiers (URIs). The Uniform Resource Locators (URLs) that link Web pages are the most common type of URI. URIs ensure that terms or concepts are not just words in a document but are tied to a unique definition that anyone can find on the Web (Berners-Lee et al., 2001). In addition, the object of an RDF statement can be another RDF statement, so that complex RDF statements can have other RDF statements nested inside in multiple layers. Figure 2.2 illustrates the RDF statements serving as metadata about the Web page http://ce-res.blogspot.com/2005/10/ kmitlsut-reinforced-concrete-design.html. It asserts that the page “has title” “Reinforced Concrete Design Worksheets,” is categorized in the “subjects” “RC De- sign,” “Working Stress Design,” etc., and “is authored by” the person identified by the URI http://stweb.ait.ac.th/~ st029284/foaf.rdf#thitiv. Ontologies and RDF statements are typically stored on Web servers for later retrieval by other parties in the same way as the publication of traditional Web doc- uments. The statements about the author of the Reinforced Concrete Design Work- sheet can be retrieved for display on a Web browser by accessing the URI http: //stweb.ait.ac.th/~ st029284/foaf.rdf#thitiv. It is also possible to embed an RDF statement that employs terms from specific ontologies inside hidden tags of Web documents themselves (Palmer, 2002). Software tools such as the Jena Semantic Web Framework (Jena, 2007) provide a means to retrieve ontologies and RDF statements from Web sources and store them in a local knowledge base. The set of inference rules that correspond to the semantics of the RDF constructs (W3C, 2004c) is prebuilt into Jena. Answers to queries such as “give me a list of Web pages authored by http://stweb.ait.ac.th/~ st029284/foaf.rdf#thitiv” can be obtained through Jena’s Application Programming Interfaces (APIs) (Wikipedia, 2007a). 2.5.2 How the Semantic Web Works The following examples illustrate how Web documents, XML, ontologies, and RDF statements work on the Semantic Web. Example 1 John Doe is at the Reinforced Concrete Design Worksheet Web page on the CE Resources Website (Vacharasintopchai, 2005). He is interested in the link mentioned on the page and wants to contact the author for more information about it. The author’s e-mail address or contact information is not given on the Web page. How can John find the author’s e-mail address? Traditional Solution. On the Web page, John has to find the name of the author. 13
- 21. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> < rdf:Description rdf:about="http://ce-res.blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html" 5 dc:title="Reinforced Concrete Design Worksheets"> <dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#rc-design"/> <dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#working-stress-design"/> <dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#ultimate-strength-design"/> <dc:subject rdf:resource="http://thitiv.blogspot.com/semblog/terms.owl#structural-members"/> 10 <dc:language rdf:resource="http://www.iso.org/iso/en/prods-services/iso3166ma/02iso-3166-code- lists/list-en1.html#TH"/> </ rdf:Description > </rdf:RDF> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 15 xmlns:dc="http://purl.org/dc/elements/1.1/"> < rdf:Description rdf:about="http://ce-res.blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html"> <dc:author rdf:resource="http://stweb.ait.ac.th/~st029284/foaf.rdf#thitiv"/> </ rdf:Description > 20 </rdf:RDF> Figure 2.2: Example of RDF Metadata Embedded in Web Page <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:foaf="http://xmlns.com/foaf/0.1/"> 5 <foaf:PersonalProfileDocument rdf:about="http://stweb.ait.ac.th/~st029284/foaf.rdf"> <foaf:maker rdf:resource="#thitiv"/> <foaf:primaryTopic rdf:resource="#thitiv"/> </foaf:PersonalProfileDocument> 10 <foaf:Person rdf:ID="thitiv"> <foaf:givenname>Thiti</foaf:givenname> <foaf:family_name>Vacharasintopchai</foaf:family_name> <foaf:mbox rdf:resource="mailto:thitiv[at]gmail.com"/> 15 <foaf:homepage rdf:resource="http://thitiv.blogspot.com"/> </foaf:Person> </rdf:RDF> Figure 2.3: Sample RDF Statements about Person Then he has to go to a search engine, such as Google, and type in the author’s name and a keyword such as “e-mail” to search for traces of an e-mail address. If John is lucky enough, he gets the e-mail address after the first search. Semantic Web Solution. A set of RDF statements that describe the Web page (Fig- ure 2.2) will usually be published in conjunction with the page content. A Se- mantic Web-enabled Web browser will recognize the “is authored by” RDF state- ment (the dc:author and the rdf:resource tags) and will be directed to the RDF statements about the author. The Web browser can inspect the statements about the author (Figure 2.3) and extract the author’s e-mail address from the foaf:mbox statement automatically. This e-mail address will be suggested by the Web browser as the e-mail address that John is looking for. 14
- 22. Example 2 The RC design Web page is categorized on the Website under a keyword “struc- tural members.” If John wants to see more articles about “structural members” from the same author, how would he do it? Traditional Solution. On the Web page, the author provides a link to an index of articles in the “structural members” category. If John clicks on the “structural members” link, he is directed to a list of articles about “structural members.” Had the author not provided such an index, John would have to search for a list of articles with “structural members” and the author’s name as the keywords. However, John is not likely to encounter an article about “beams,” although obviously it is a kind of structural member, unless “beams” is also explicitly added to the keyword list. Semantic Web Solution. The Web browser will recognize the “subject” statements (the dc:subject tag) in the set of RDF statements about the RC design Web page (Figure 2.2). When requested to find more Web pages whose dc:subject property is http://thitiv.blogspot.com/semblog/terms.owl#structural-members and whose dc:author property is http://stweb.ait.ac.th/~ st029284/foaf. rdf#thitiv, the Web browser can browse through a list of RDF statements, then select the Web pages whose dc:author and dc:subject are the same as, or related to, the given ones, and then present the result accordingly. If the Web browser finds an RDF statement which asserts that http://thitiv.blogspot. com/semblog/terms.owl#beams is a “subclass of” (W3C, 2003) http://thitiv. blogspot.com/semblog/terms.owl#structural-members, it will also include the article about “beams” in the results, as it can be deduced by an inference engine that beams are a type of structural member. In technical terms, we say that the concept “structural members” subsumes the concept “beams.” It should be noted here that the term “RDF statement,” used earlier, collectively refers to the statements that are represented by the RDF language (W3C, 2003) as well as the Web Ontology Language (OWL) (W3C, 2004a), which is an extension of the RDF language for more comprehensive representation of knowledge on the Semantic Web. OWL provides several additional constructs, such as “equivalent class,” “intersection of,” “union of,” “inverse of,” and “disjoint with,” that more precisely capture bodies of knowledge over those available in the RDF language. Henceforth, the term “OWL statement” may be used when it is desirable to emphasize the employment of OWL’s additional constructs in the statement. 2.6 Semantic Web Services 2.6.1 Background Web Services introduced a new model of distributed computing that uses the Internet as the communication platform. The present technology based on WSDL, SOAP, and UDDI allows automatic publication, discovery, and execution of services at the syntactic level. However, WSDL documents, which play a key role in the interop- eration of Web services, are XML documents and therefore inherit the same semantic problem of XML discussed earlier. To make proper use of the Web services advertised by WSDL documents, programmers have to know in advance the intended meaning 15
- 23. of the custom tags that specify the input and output schemas as well as the names of services that a Web service provides. Like other XML documents, WSDL documents are usually created and used by different groups of people. Unless supported by on- tologies, it would be difficult for a computer program looking for a GetSineValue Web service that calculates the sine of a “degree” angle to autonomously execute and get the correct sine value from an advertised TrigonometricSine Web service that takes “radian” angles as the input, even though both of them are described as Web services that calculate the sine values of angles. Semantic Web Services, the idea of augmenting Web service descriptions using Semantic Web technology (Burstein et al., 2005), were introduced to address this kind of problem and to facilitate the autonomous publication, discovery, and execution of services at the semantic level. Semantic Web service description languages, such as OWL-S (OWL–S, 2003) and Web Service Modeling Ontology (WSMO) (Roman et al., 2005), were proposed as abstractions of syntactic Web service description languages such as WSDL, which are used in current Web Services technology. They are meant to be used with semantic matchmakers, which are the software agents that accept and keep track of the descriptions of available services from providers and match them against the requirements from service consumers (Burstein et al., 2005). Matchmakers enhance the role of UDDI service registries in the Semantic Web Services architecture. OWL-S is among the most widely used semantic Web service description lan- guages and was submitted to W3C for possible standardization (Martin et al., 2004). It describes the categories, the inputs, the outputs, and the consequences of Web ser- vices in terms of concepts defined in OWL ontologies. It also provides the grounding constructs for specialization into WSDL constructs for compatibility with existing Web services, which are described by WSDL documents. OWL-S is used as the semantic Web service description language in this research. 2.6.2 How Semantic Web Services Work To illustrate how Semantic Web Services can help a program looking for the GetSineValue Web service to get the correct value of sine from the TrigonometricSine Web service, consider the OWL-S description of GetSineValue in Figure 2.4. The “service profile” description, which is the proposed information for use by matchmakers (Sycara et al., 2003), is presented. Figure 2.4 shows that: 1. The GetSineValueService (which is the service that the program is looking for) is a kind of SineFunctionEvaluator defined in the profileHierarchy taxon- omy; 2. The service takes one input parameter “Angular Degree” the definition of which is available at http://std.swscm.org/200407/quantities.owl#AngularDegree, and gives one output the definition of which is available at http://std.swscm. org/200407/quantities.owl#UnaryConstantFunctionQuantity; and 3. The effect of this service is defined by http://std.swscm.org/200407/Math- OperationEffects.owl#TrigonometricFunctionValueEffect. In the Semantic Web Services architecture, when a service consumer needs a service from a provider, it creates an ideal service profile, such as the one in Figure 2.4, and submits it to a matchmaker as a request for recommendation (Sycara et al., 2003). 16
- 24. <rdf:RDF> <service:Service rdf:ID="GetSineValueService"> <service:presents rdf:resource="#GetSineValueServiceProfile"/> </service:Service> 5 <profileHierarchy:SineFunctionEvaluator rdf:ID="GetSineValueServiceProfile"> <service:isPresentedBy rdf:resource="#GetSineValueService"/> <profile:hasInput> 10 <process:Input> <process:parameterType rdf:resource ="http://std.swscm.org/200407/quantities.owl#AngularDegree"/> </process:Input> </profile:hasInput> 15 <profile:hasEffect rdf:resource= "http://std.swscm.org/200407/MathOperationEffects.owl#TrigonometricFunctionValueEffect"/> <profile:hasOutput> 20 <process:UnConditionalOutput> <process:parameterType rdf:resource ="http://std.swscm.org/200407/quantities.owl#UnaryConstantFunctionQuantity "/> </process:UnConditionalOutput > </profile:hasOutput> 25 </profileHierarchy:SineFunctionEvaluator > </rdf:RDF> Figure 2.4: OWL-S Service Profile Description of GetSineValue Web Service From the profiles registered by various service providers, the matchmaker selects the one that most closely matches the ideal profile requested, and recommends it to the consumer for further binding between the two parties. As the matchmaker processes the request, suppose that it had searched the list of service profiles advertised by service providers but could not find any service that matched perfectly. However, there is a TrigonometricSine Web service that advertises itself as a kind of SineFunctionEvaluator which gives a UnaryConstantFunction- Quantity output and the TrigonometricFunctionValueEffect effect. The service takes the input parameter defined by http://www.math.org/terms.owl#RadianAngle rather than the http://std.swscm.org/200407/quantities.owl#AngularDegree. If there are some assertions that the “radian angle” and the “angular degree” concepts are related in some ways, for example: 1. Both “radian angle” and “angular degree” are subclasses of http://www.math. org/terms.owl#PlaneAngle; and 2. The “angular degree” “has conversion factor” of π/180 and ”has reference unit of measurement” of http://www.math.org/terms.owl#RadianAngle, by populating these assertions into the knowledge base of an inference engine, and by querying whether the pairs of service types, input parameters, output parameters, and effects, subsume each other (Sycara et al., 2003), the matchmaker will be able to determine that the two Web services near perfectly match, and could thus recommend this TrigonometricSine Web service to the consumer. The consumer will be able to use the “has conversion factor” assertion to convert its angular degree into the radian angle unit expected by the service provider, and will be able to initiate a request to the TrigonometricSine Web service and finally get the correct sine function value. 17
- 25. CHAPTER 3 DEVELOPMENT OF A SUPPORT SYSTEM FOR STRUCTURAL ENGINEERING 3.1 Structural Engineers and Construction Projects Construction projects start when owners decide to have buildings constructed to satisfy their needs. Through bidding processes or fast track approaches, an architect is contracted, the owner’s requirements collected and a preliminary design agreed upon. A series of drawings and specifications which consist primarily of architectural and structural work are indispensable for the materialization of a project. Tender drawings and specifications are required for bidding to select a general contractor for the project. Detailed drawings from designers and shop drawings from field engineers are necessary for work at the construction site to proceed. Structural engineers play a critical role in all these construction project phases. At the outset, architects need a structural engineers’ opinion about viable structural systems that are appropriate for preliminary designs. Structural engineers are con- sulted for the estimated size of columns, beams and slabs before architectural drawings are developed for tender. Detailed foundation designs are often the first construction drawings requested from structural engineers, even though the information for them is last obtained in the analysis and design process. In addition, field engineers need prompt advice from structural designers when unexpected difficulties occur at the con- struction site to minimize expenses from work delays. Sound structural analysis and design is central to the safety and economy of a construction project; yet structural engineers are often on the critical path with tight schedules and are allocated very limited time for their tasks. Two obstacles that hinder the productivity of structural engineers in dealing with their tasks are limitations in available computing tools and limited access to relevant knowledge. A support system that improves the productivity of structural engineers during the engineering process is therefore highly advantageous, as postulated in the first chapter. 3.2 Design Principles Structural engineering departments typically have both senior engineers with extensive practical experience and junior engineers (or fresh graduates) with little pro- fessional experience. Many kinds of tools are used in the engineering process. Junior engineers are often more acquainted with relatively new technologies, whereas senior engineers have a wealth of practical insight and often know useful shortcuts. Some commercial software packages are licensed and many departments have special-purpose software tools that have been individually developed in-house. Commercial software and in-house tools are usually shared among engineers in the department. The output from structural engineers is commonly in the form of hand sketches or CAD drawings, supported by calculation sheets. On completion of projects, relevant documents are collected on file servers or in cabinets for future reference. To improve the productivity of structural engineers in dealing with their tasks, good support systems should at least have the following features: 1. References and Premises Engineering is an applied science by nature. It deals with the application of pure scientific knowledge to solve practical problems. When structural engineers are assigned tasks at the launch of new projects, ref- 18
- 26. erence documents, such as design manuals, theoretical notes and data sheets, as well as examples from similar past projects, are the first information needed to come up with solution strategies. Good support systems for structural engineers should thus facilitate the efficient storage, as well as fast and precise retrieval, of reference documents and premises to minimize the engineers’ start-up time. 2. Knowledge and Tools Sharing Engineers study project requirements and pre- dict assumptions to simulate the behavior of structures under critical usage con- ditions. Based on the mechanical properties of construction materials, structural members are designed such that they can withstand severe conditions at reason- able levels of safety. To maximize the safety and economy of structural engineer- ing products and arrive at proper rather than over- or under-designs engineers should have access to the best possible set of knowledge and tools relevant to their tasks. Methodologies, tips and techniques, as well as software tools licensed from commercial vendors or developed in-house, should be accessible to as many fel- low colleagues as possible. Good support systems for structural engineers should second facilitate the creating, sharing and disseminating of knowledge and tools among structural engineers so that they are well equipped for their work. 3. Computational Workflow Commercial and in-house software tools are typically based on specific assumptions that need to be satisfied. Their input and output data are usually based on specific conventions, formats and units of measurement that must be strictly followed to obtain sensible results. Such software is often chained into a computational workflow to address specific requirements unsup- ported by general-purposes software packages. It is tedious and error-prone for the engineers to adapt the potentially incompatible input and output data of tools in the chain manually. It is also difficult for users in workplaces where nu- merous software tools are shared to find the tools that fit their specific problem best. Good support systems for structural engineers should thus thirdly facilitate the interoperation of software tools and allow them to be chained such that the least possible user intervention is required to use them effectively and prevent blunders. 4. Discussion and Collaboration Engineering is collaborative in nature. Senior engineers in structural engineering departments have a wealth of practical insight and experience, whereas junior engineers have fewer but are more acquainted with modern technologies and design techniques. In general, the two exchange knowledge and learn from each other. Senior engineers give guidelines and opin- ions about approaches to a solution. Colleagues give suggestions about tools and techniques appropriate for specific project types. Although members of en- gineering teams usually meet and discuss formally on a regular basis, human knowledge is amplified during informal socialization, as postulated by the theory of organizational knowledge creation in Chapter 2. To assist structural engineers in exchanging and amplifying their knowledge in other than lunch and hallway meetings, good support systems for structural engineers should fourthly facilitate informal discussion and collaboration among peers. The systems should allow ex- changes of audio/video clips, worksheets, pictures and drawings for effective peer communication. To encourage user participation, the tool for discussion and col- laboration should be easy to use. The systems should also have an archiving 19
- 27. Figure 3.1: General Architecture of Support Systems feature to make both past projects and the group thinking processes behind the solutions arrived at, accessible to colleague engineers in the future. 5. Accessibility and Interoperability Support systems are not useful if they are difficult to access. They will not wide gain acceptance and adoption in the industry if they lack interoperability with other systems. In addition to the four features above, good support systems for structural engineers should therefore follow open standards and be platform neutral for cross-system interoperability and accessibility. Users on different computing platforms (such as Windows, Mac OS and Linux) should be able to access the systems indifferently. Ubiquitous access to the systems, especially from remote construction sites, would also be advantageous for timely access to knowledge and tools to assist with unforeseen problems on-site. 3.3 General System Architecture The semantic computing technologies reviewed in Chapter 2 provide various functionalities which can be combined to meet the five requirements for good struc- tural engineering support systems. This section proposes a general system architecture which utilizes semantic computing technologies to build such a system. The system architecture consists of five components as depicted in Figure 3.1. Each component is labeled with numbers (1), (2), . . . , (5), which correspond to item numbers of the design principles. For example, (1) refers to References and Premises and (2) refers to Knowl- edge and Tools Sharing. The relationships between these components and the design principles can be explained as follows: Digital Library The need for support systems to facilitate efficient storage and fast, precise retrieval of premises and reference documents matches well with the meta- data rich content archiving and retrieval features of digital libraries. Digital li- braries are specifically developed to store large amounts of electronic documents for archival purposes and to allow them to be precisely located and retrieved with relative ease. Digital Library technology is therefore appropriate for the References and Premises requirement. The Web access and conformance to stan- dard query protocols of digital library systems make them appropriate for the Accessibility and Interoperability requirement. 20
- 28. Weblogs The need for support systems to facilitate the creating, sharing, and dis- seminating of knowledge and tools matches well with the publication and social networking features of Weblogs. Blogging allows engineers to instantly document and disseminate among peers new ideas, software tools and techniques, and to conveniently receive focused feedback on particular topics in the form of com- ments and trackbacks. Engineers can also blog about work plans and difficulties arising in particular projects to solicit comments and suggestions from colleagues. Weblogs, in this regard, are therefore appropriate both for the Knowledge and Tools Sharing and the Discussion and Collaboration requirements. The confor- mance of Weblog servers to Web feed standards and the convenient means of publication offered by Weblogs make the technology especially appropriate for support systems, from the Accessibility and Interoperability point of view. In addition, the bibliographic information of blog entries is important metadata which contributes to the fast and precise retrieval of knowledge in blog content, according to the References and Premises principle. Web Services The need for support systems to facilitate with the least user inter- vention the interoperation and chaining of software tools matches well with the capability of Web Services and Semantic Web Services to help unify and utilize scattered computing resources. Web service providers and consumers include, but are not limited to, software tools on parallel computer clusters, personal computers, laptops and smartphone devices. With premises from service meta- data (i.e. service descriptions) and ontologies, the artificial intelligence inherent in Semantic Web Services technology also helps to intelligently discover and unify heterogeneous computational services and to reduce the necessity for user inter- vention during workflow processes. Web Services and Semantic Web Services technologies, in this regard, are thus particularly appropriate for structural engi- neering support systems, in terms of Computational Workflow, Accessibility and Interoperability, as well as Reference and Premises. 3.4 Summary This chapter has described common obstacles in the structural engineering pro- cess and proposed five principles for the design of support systems to assist engineers in dealing with their tasks more productively. Semantic computing technologies were identified as enabling tools for such systems and a general architecture for the develop- ment of structural engineering support systems has been proposed. The methodology to create support systems from these technologies are presented in the next two chap- ters, along with proof of concept prototypes. Metadata and ontologies as well as their annotation in data and knowledge are central to all aspects of the development, hence the term “semantic computing.” Their importance is illustrated throughout. 21
- 29. CHAPTER 4 A STRUCTURAL ENGINEERING SUPPORT SYSTEM USING SEMANTIC COMPUTING 4.1 Introduction Weblogs (a.k.a. Blogs) and Digital Libraries, information technologies deploy- able on the Internet or an intranet, can be combined to build a new generation of knowledge management (KM) systems, which can enhance the access to knowledge and expertise of engineers, as previously postulated. Such systems assist them in sharing tacit knowledge, developing concepts from many pieces of tacit knowledge, combining various elements of explicit knowledge, and storing new knowledge in the knowledge bases of individuals and the organization. In such a KM system, an engineer is assigned a personal blog where he/she can store work in progress, including collec- tions of random thoughts, ideas, documents, spreadsheets, or audio-video recordings. Through the dynamic social networking facilities of blogs, exchanges of comments and discussions among colleagues are electronically facilitated and individual blog entries and discussions can be cross-referenced. After a work-in-progress is completed, related blog entries and discussions, as well as a project summary document, can be archived to a digital library for future reference. This chapter builds on the general design for structural engineering support systems described in Chapter 3 to propose a methodology by which blogs and digital libraries can be combined into a structural engineering support system based on three enabling modules which will be described and specified. A framework for this applica- tion is proposed and the prototype that facilitates the management and sharing of both personal knowledge and computing tools is developed, with the objective of improving the overall efficiency and productivity of engineering design processes.1 4.2 Blog+DL Framework for Engineering Knowledge Management Based on the SECI model, this section identifies the features of a KM system that promote the conversion and interaction of tacit and explicit knowledge among individuals. A framework for the use of Weblogs and Digital Libraries as building blocks for a KM system is presented. 4.2.1 Technology Application Framework Socialization and Externalization As depicted in the top left-hand quadrant of Figure 4.1, the first part of the spiral of knowledge creation is interpersonal. It starts when people that share the same interest gather to interact, socialize and externalize their tacit knowledge by sharing experiences. A good KM system should help such people to discover each other and provide them a convenient means for socialization and externalization. The statistics about blogs in Section 2.3 indicate that blogs can be used as an effective KM tool in this regard. Blog publication and the social networking features help people to discover each other and create online social networks of bloggers on which issues of common interest are expressed and personal opinions, as well as experiences, are exchanged. When Blogs is used as an engineering KM tool, an engineer may blog 1 The content of this chapter has been published in Vacharasintopchai et al. (2007b). 22
- 30. Figure 4.1: Blog, Digital Library, and Knowledge Conversion Modes (adapted from Nonaka and Takeuchi 1995) about a design problem that he is trying to solve, e.g., how to setup a proper design criterion for a construction project. The blog entry may describe the engineer’s view of the problem as well as the available approaches, and may also contain initial research work, such as hyperlinks to other blog entries about “lessons learned” from similar projects. When published to the Internet or a corporate intranet, the blog entry can be read by many other people, some of which may share the same interest or have experienced the same problem. A reader may assist the engineer in finding a solution by posting his opinion or experience, such as the limitation of a selected approach, as a comment to the blog entry. Another reader may view the problem differently and may not agree with the first reader’s opinion. He may express his opinion on a personal blog and notify the original blogger in the form of a trackback. The original blogger can participate in the discussion thread created by this series of comments and trackbacks and be able to find a more appropriate design criterion for his project. This blog discussion thread may also benefit a public audience who may have had a similar problem and comes across this discussion thread on a Web search engine. In this way, a group of people who share the same interest is gathered; a field of interaction is constituted; and the participants are equipped with a tool to socialize and exchange experiences, i.e., pieces of tacit knowledge, in blog discussion threads. Combination and Internalization The second part of the spiral of knowledge creation is intrapersonal. It contin- ues from the interpersonal part when a person synthesizes new explicit knowledge— combining different bodies of explicit knowledge to solve an unfamiliar problem. Once 23
- 31. the new knowledge is put into practice, it becomes valuable know-how that is internal- ized into the person’s tacit knowledge base and becomes part of his skills. An effective KM system should help people to easily build up repositories of explicit knowledge and allow relevant pieces of knowledge in the repositories to be conveniently and precisely retrieved so that a more complete set of knowledge is accessible and can be combined into the best possible new knowledge. A desirable KM system should also facilitate internalization, i.e., help people put new knowledge into practice by, for example, pro- viding them convenient access to relevant computational software tools to shorten the time required for a design workflow. Keyword tagging and the selective tag browsing features of Blogs complement the metadata rich content archiving and retrieval features of Digital Libraries and make them suitable as effective KM tools in this regard. Blog entries created during socialization and externalization are typically tagged with keywords when they are published. In addition to conventional keyword and full text searches, the blog owner and readers can use the selective tag browsing feature available in most blog service providers to filter and browse only through relevant blog entries, allowing them to stay focused on the topics of most interest to them. An engineer can also archive the content and metadata of mature blog discussion threads, which contain pieces of externalized tacit knowledge and reflects the group thinking processes by which solutions to important problems are arrived at, into the collections of the institutional- repository digital library of which he has a membership. He can also archive interesting Web pages, such as product data sheets, and digital content, such as Excel, PowerPoint, PDF, Word, and MP3 files, into the collections. In this way, the engineer builds up a personal portfolio of knowledge that can be shared across the organization. A digital library, with its extensive metadata browsing and search features, as well as full-text indexing capability, becomes a human-filtered search engine (Takeda, personal communication, February 26, 2007) which portfolio owners and peers can use to access a focused set of relevant knowledge without “noise.” With all the mentioned features, Blogs and Digital Libraries can thereby enhance the efficiency and effectiveness of the combination and internalization processes of individuals. 4.2.2 System Architecture A system architecture that corresponds to the proposed technology application framework is presented in Figure 4.2. Seven components, namely, the Web Browser, the Blog Server, the Digital Library Server, the World Wide Web, the Archiver, the Keyword Suggester, and the Web Service (WS) Portfolio Manager, are involved. The latter three are the key components that, together with Weblog and Digital Library technologies, enable the constitution of an effective knowledge management system. The Web Browser is proposed as the primary user interface for convenient and ubiquitous access to the system and also because Blogs and Digital Libraries are them- selves Web-based. An engineer can use a Web browser to create an account on a blog server and a digital library, and use it to log on to the blog server to socialize and externalize his knowledge by publishing blog entries or joining blog discussion threads. The Archiver is a special-purpose component that monitors requests from a Web browser to take a “snapshot” of a blog discussion thread or a Web page and archive it to a specific collection in a digital library. It is the primary component that assists in building up personal knowledge portfolios. When a blog discussion thread has matured, the blog owner may summarize the discussion and use a Web browser to take 24
- 32. Figure 4.2: Blog+DL Framework for Computer-Aided Engineering Design 25
- 33. a snapshot of the thread. The Web browser would prompt him to enter appropriate metadata, such as the title, the author’s name, keywords, and a brief description of the thread, as well as his digital library account name and the name of the collection, i.e., knowledge portfolio, to which he is authorized to submit. It would then submit the collected information along with the URL of the thread to the archiver and request that a snapshot of the thread be taken and processed accordingly. In addition, an engineer may use the Web browser and the archiver to take snapshots of interesting Web pages, such as discussion threads, product datasheets, or design tips, into his portfolio. During the combination and internalization processes, when explicit knowledge from various sources is crystallized into new explicit knowledge and put into practice, the engineer then uses the Web browser to access relevant discussion threads in blogs and pieces of knowledge collected in personal portfolios in the digital library. The Keyword Suggester is a second essential component in the KM system proposed here. Since the Blog and Digital Library are independent technologies that do not naturally interoperate; the use of common metadata is necessary to enable such interoperation, i.e., the keywords assigned to blog entries and digital library items should be from the same controlled set and the bibliographic information assigned to them should conform to the same data format (e.g., DD-MM-YYYY for dates) so that relevant knowledge in blogs and the digital library can be retrieved simultaneously with a common search query. The Keyword Suggester is the component that ensures the enforcement of common metadata. Besides exchanging and commenting on traditional documents and multimedia content, an engineer can participate in the SECI modes of knowledge conversion by exchanging and commenting on computational tools, such as mathematical routines, numerical analysis modules, and design shortcuts. An engineer can develop these computational tools as subroutines (or methods, in the object-oriented programming paradigm) in his preferred programming languages, such as Java or VB.NET, and al- low them to be remotely executed by other computers as Web services on the Internet. To “publish” a Web service, i.e., to make a subroutine available for remote access, an engineer places the code of the subroutine onto a Web service server, such as Apache Axis for Java or Microsoft Internet Information Server for VB.NET. The server au- tomatically generates a “Web service description document” that corresponds to the subroutine. This document contains the instruction for computers and people on how to execute the service. The engineer can post the Web service description document in a blog entry, along with a brief description of the service, its theoretical explanation, and a user’s guide. In this way, the service is advertised and made accessible to the public. Discussions about the service, such as user experiences, can be exchanged as blog comments and trackbacks as in the ordinary socialization and externalization use of blogs. The Web services published through blog entries are discovered primarily when the service advertisement entries are visited by fellow bloggers. They may also be discovered secondarily when referred to in other discussion threads. Besides reading the contents, e.g., descriptions and explanations, blog readers can execute the service or build up a portfolio of computational tools, i.e., Web services. This availability of the portfolio of Web services necessitates the third compo- nent being suggested in the framework, namely, the Web Service Portfolio Manager. This third key component turns the proposed framework into a fully-functioning KM system by enabling the sharing and execution of Web services published in blog discus- sion threads. This add-on component to the blog server detects whether the content 26
- 34. of a blog entry includes a hyperlink to the description document of a Web service. If it does so, the Web Service Portfolio Manager will provide an “execute” button and a “save” button in the Web page that displays the blog entry, so that the readers can choose to execute the service or save it to their portfolio for later use. In the latter case, the user will be asked to provide the description of the desired Web service when a computational service is needed. The Web service portfolio manager would search the user’s portfolio and retrieve a list of Web services that best match the request. Once a Web service is selected by the user, the user can execute the Web service by entering the input data and clicking the execute button. The selection of Web services from portfolios and the execution of Web services are performed intelligently according to the Semantic Web Services Framework for Computational Mechanics (SWSCM), which is proposed and explained in the next chapter. The Web service portfolio man- ager performs the consumer and the matchmaker roles in the SWSCM. Readers are referred to the mentioned reference for in-depth information about the Semantic Web Services technology and its application in engineering design. 4.3 A Semantic Computing-Based Support System for Structural Engi- neers 4.3.1 Implementation Based on the proposed Blog+DL framework for computer-aided engineering design, a prototype system has been developed to assist engineers in socializing and externalizing their knowledge, as well as in building up personal portfolios of knowl- edge and computational tools. The knowledge and tools in such portfolios can be combined and crystallized into new knowledge and can also be shared with colleagues of the engineers to form a larger organizational KM system. The prototype system contains structural design aids, such as properties of steel sections from various in- dustrial standards, as well as Web services and worksheets for structural analyses and designs. It also includes articles and discussion threads about general sciences and applications of information and communication technologies in structural engineering. The implementation of the prototype system follows the system architecture presented previously which consists of six components, namely the Web Browser, the Blog server, the Digital Library server, and the three KM enabling components: the Archiver, the Keyword Suggester, and the Web Service (WS) Portfolio Manager. A federated search agent was additionally introduced for even improved productivity. The prototype system was implemented in Java and JavaScript and utilized platform neutral open-source software tools. The server components were deployed on a Windows XP Professional Web server at http://kb.blogdns.org:8080/blojsom. Web Browser Mozilla Firefox (Mozilla, 2007), a standards conformant Web browser available on major computer platforms, such as Windows, Linux and Mac OS X, was chosen as the Web Browser component. Firefox is highly extensible and fully supports bookmarklets—JavaScript codes embedded in Web browser bookmarks— which are useful as custom user interface components. Blog Server Blojsom (Czarnecki, 2007), a blog server developed in Java with ex- tensive support for third-party add-on modules, was chosen as the Blog server. Optional features useful for KM, such as site-wide article aggregation, selective tag browsing and keyword tagging, as well as full-text searches, were installed 27
- 35. and customized. Digital Library Server DSpace (DSpace, 2007a), a widely accepted large-scale Java digital library server based on the institutional repository concept, with an exten- sive documented set of application programming interfaces (APIs), was chosen as the Digital Library server. Several collections, such as general “Structural Engineering,” “Steel Design,” “Reference,” “News,” and “Tips and Techniques” were created to store user contributed contents. Archiver The Archiver was developed as a Java servlet that monitors requests to archive documents at particular URLs along with the provided sets of metadata into specific DSpace collections. An archive bookmarklet was developed as a bridging user interface between Mozilla Firefox and the Archiver (Figures 4.7a, b). The bookmarklet was deployed as a Save to DSpace button in the Mozilla Firefox bookmarks toolbar. Once clicked it prompts the user to enter a brief descrip- tion and the metadata of a Web page and forwards the request to the Archiver. The Archiver utilizes DSpace APIs, such as the methods of classes Item and Collection in the org.dspace.content package, and the JavaMail APIs (Sun Microsystems, Inc., 2007) to create and store standard compliant MHTML doc- ument archives (Palme et al., 1999) into the DSpace repository. By adopting the MHTML Internet standard, document archives generated by the Archiver can be readily processed by the built-in full-text indexer of DSpace and are displayable on major Web browsers, such as Microsoft Internet Explorer, Mozilla Firefox and Opera. Keyword Suggester The Keyword Suggester was implemented as a servlet that pro- vides ontology-assisted keyword suggestions. It takes input strings from HTTP POST requests and consults a predefined set of ontologies to extract relevant key- words from Web contents at specific URLs by using APIs from Jena (Jena, 2007), an open-source Semantic Web programming toolkit originated from Hewlett- Packard Laboratories, and Apache Lucene (Apache, 2007), a high-performance text search engine toolkit from Apache Software Foundation. The bookmarklet uses Asynchronous JavaScript and XML (AJAX) programming techniques to consult the Keyword Suggester and retrieve a list of suggested keywords for the Web page being saved. JavaScript codes in the bookmarklet prepopulate these keywords into the keywords textbox to assist users in entering proper metadata. Ontology-assisted keyword suggestion is helpful to enforce a controlled set of key- words, which is necessary for the interoperation of Blog and Digital Library and the effective retrieval of content in large digital library collections. The same func- tionality is also provided in the blog entry editing module of Blojsom to suggest proper keyword tags when entries are created or modified (Figure 4.4b). Read- ers are referred to Jakobsen (2006) for an in-depth explanation on bookmarklet programming. Federated Search Agent A federated search function which allows users to locate pieces of knowledge across blog entries and digital library collections is provided for increased productivity. Like the Archiver, the federated search agent was developed as a Java servlet that monitors requests to search for keywords or metadata. A search bookmarklet was developed as a bridging user interface between Mozilla Firefox and the Federated Search agent (Figure 4.8c). The 28
- 36. bookmarklet was deployed as a Search button in the Mozilla Firefox bookmarks toolbar. Once clicked it prompts users to enter search keywords or metadata and forwards requests to the Federated Search agent. The agent utilizes APIs such as methods of classes SimpleSearchServlet and AdvancedSearchServlet in the org.dspace.app.webui.servlet package of DSpace, methods of class BlojsomFetcher in the org.blojsom.fetcher package of Blojsom and full-text search functions of Apache Lucene, the underlying search engine used by Blojsom and DSpace, to locate relevant pieces of knowledge and consolidate them into a single Web page for convenient access by users (Figure 4.8d). Web Service Portfolio Manager The Web service portfolio manager consists of two important subcomponents: the Blojsom plug-in and the Web service port- folio management servlet. The Blojsom plug-in implements the BlojsomPlugin interface class in the org.blojsom.plugin package of Blojsom to preprocess the contents of blog entries before they are displayed on Web browsers. By using the regular expression string matching technique, the plug-in detects whether blog entries contain links to Web service descriptions, such as WSDL or OWL-S files. If they do so, (1) Save buttons are inserted into the HTML codes of blog entries such that, once clicked, users’ log-in names and URLs of Web service de- scriptions are forwarded to the Web service portfolio management servlet, which maintains the registration of Web services in users’ portfolios; and (2) user inter- face components such as input boxes and submit buttons are inserted into the HTML codes of blog entries for immediate execution of Web services, with the assistance of the OWL-S API (Sirin, 2004), WSDL4J (WSDL4J, 2006) toolkit and Apache Web Service Invocation Framework (WSIF) (Apache, 2003b). The Web service portfolio management servlet handles the registration, unregistration and selection of services in users’ portfolios. It was developed as a Java servlet that monitors requests to add, update or delete services in particular portfolios, identified by log-in names. It also acts as a proxy to the Matchmaker service described in Section 5.3 on page 51, which implements the matchmaking algo- rithm in Section 5.2 to help users select appropriate services from many they have collected. Java hash tables and property files were used as building blocks for service registration databases. OWL-S API and WSDL4J toolkits were used to extract information from Web service descriptions. WSIF was used for the execu- tion of Web services. Jena Semantic Web toolkit and RACER Description Logic reasoner (Haarslev and Moller, 2003) were used to provide intelligence assistance to the matchmaker. Intelligent interoperability of Web services are explained in detail in the next chapter. 4.3.2 A Proof of Concept Prototype Figures 4.3 through 4.8 illustrate a typical application of the prototype, a walk- through example of which is demonstrated as follows: Installation Initially, an engineer needs to create an account on the system by visiting the homepage of the Blog and the Digital Library server. An instruction on the homepage will direct him to the services page where his user name is verified (Figure 4.3a), URL to personal blog assigned, membership of DSpace collections granted, and Save to DSpace 29
- 37. (a) Account Verification (b) Personalized Bookmarklets Figure 4.3: User-specific Initialization of Prototype and federated Search bookmarklets personalized (Figure 4.3b). Bookmarklets must be dragged and dropped onto the bookmark toolbar of Mozilla Firefox before they can be used. Socialization and Externalization In terms of publication, to externalize his knowledge and socialize, the engineer logs on to his blog and clicks Manage to enter Blojsom administration console. To create a new blog entry, he chooses the Add Entry command in the Entry toolbar which directs him to the Add Blog Entry page. Here, he can start blogging about new findings, as well as ideas and plans related to a project, in a fashion similar to composing e- mails (Figure 4.4a). The content of his entry is automatically analyzed for important keywords as he blogs, thanks to embedded AJAX codes, preregistered ontologies and the Keyword Suggester. Checkboxes of suggested keywords are presented in real time in the Smart Keyword Suggestions section where he can pick ones that apply. He may also add invented keywords into the User’s specified textbox, although such a practice is discouraged for vocabulary control reasons (Figure 4.4b). The composition of blog entry completes when the Add Blog Entry button is clicked. New entries are saved into the server’s database. Entries by individual users are listed in a reverse chronological order on their per- sonal blogs, accessible at the URLs http://http://kb.blogdns.org:8080/blojsom/ blog/[user_name]. Tag clouds, lists of tag names with varying font sizes, which rep- resent different frequencies of keywords used by particular users, are also provided so that visitors can easily navigate through various aspects of the authors’ interests (Fig- ure 4.4c). Recent entries by all users are additionally aggregated on the prototype’s homepage at the URL http://http://kb.blogdns.org:8080/blojsom (Figure 4.4d) for quick overview of new contributions from all users. In terms of consumption, the engineer can browse through blog entries by visit- ing the prototype’s homepage as well as personal ones of acquainted colleagues. He may check for updates by paying regular visits to respective sites. Such a practice is consid- ered the “pull” method of blog consumption. He may also choose the “push” method to subscribe to blogs, as well as aggregated entries on the homepage, by clicking at the orange Web feed icon at the right end of Web browser address bars, cf. Figures 4.4c, d. By doing so, he is next presented with a Web feed subscription screen (Figure 4.5a) where he can allow updated contents to be regularly pushed to him via a blog reader. Figure 4.5b illustrates how a personal blog is subscribed as a Web feed source in Mi- crosoft Outlook 2007. Excerpts from recent entries on the blog are regularly pushed 30
- 38. into the engineer’s Inbox, along with other e-mail items (Figure 4.5c). Interesting blog entries can be opened and read in a fashion similar to that for e-mails (Figure 4.5d). The engineer can click the View article button to visit original blog entry pages to read full articles and participate in discussion threads with his peers (Figure 4.6a). Combination and Internalization During day-to-day tasks, engineers often come across new knowledge that are sometimes not related to present tasks but may be useful in the future. The engineer can log on to his DSpace portfolios (collections) and collect pieces of knowledge, as well as their metadata, into the knowledge repository. For improved productivity, Web contents such as blog discussion threads, datasheets and design aids can be directly archived into DSpace collections by clicking at the Save to DSpace button on Mozilla Firefox’s bookmark toolbar. The engineer will be prompted to enter bibliographic metadata, i.e., title, authors, keywords and brief descriptions, and to select a DSpace collection most appropriate for the new knowledge piece (Figures 4.7a, b). Non-Web contents such as printed documents can be digitized into electronic forms, such as PDF and JPEG files, and are archived into the repository through DSpace’s standard Web interface (Figure 4.7c). Figure 4.7d illustrates a personal knowledge portfolio built upon the accumulation of knowledge pieces into DSpace collections. Knowledge shared in blog entries as well as those accumulated in personal port- folios are invaluable resources to promptly solve the engineer’s problems at hand. He can also use these knowledge to help others by providing suggestions and URLs to knowledge pieces in colleagues’ discussion threads. When working on a project simi- lar to some in the past, archived documents in the repository can be readily accessed thanks to DSpace’s metadata and full-text search facilities (Figure 4.8a). If he feels he had seen design tips related to this type of projects in a colleague’s Web feed, he can use Blojsom’s keyword and full-text search features to locate that particular blog entry (Figure 4.8b). For improved convenience, the engineer can also use the fed- erated Search bookmarklet to simultaneously search through discussion threads and knowledge portfolios contributed by him and colleagues (Figure 4.8c). Search results are summarized in single Web pages where articles are readily accessed by one mouse clicks (Figure 4.8d). Web services published through blog entries can also be executed right away from results pages with the assistance of the Web Service Portfolio Manager described earlier (Figure 4.8e). In this way, the engineer and fellow staff members are equipped with an inte- grated set of tools to better share knowledge and experience. 4.4 Summary This chapter has proposed a framework for the application of Weblog, Digital Library, and Semantic Web Services technologies to support structural engineers dur- ing the engineering process. The framework is based on the theory of organizational knowledge management which postulates that knowledge is created by the interactions between tacit knowledge and explicit knowledge among individuals in an organization. In contrast to the KM initiatives in the late 1990s, the focus of this framework is on facilitating the conversion, interaction, and sharing of tacit and explicit knowledge, which are the bases for creating knowledge, rather than on capturing the individual pieces of explicit knowledge. The proposed framework also differs from many modern KM tools for engineering design firms in the literature because it is based on several 31
- 39. Internet standards beyond HTTP and HTML and therefore promotes cross-system in- teroperability and advanced applications of such Web technologies as Web feeds and Web Services, which are enabling technologies for Web 2.0 (a.k.a. the social Web) and Internet-based multiplatform distributed computing. The introduction of Semantic Web Services technologies and the application of ontology, as a fundamental compo- nent of the Semantic Web, further open KM systems that conform to the proposed framework to a wide variety of Internet-based artificial intelligence technologies. The proposed framework can improve the knowledge and productivity of engineers in to- day’s ever more globalized and competitive world. 32
- 40. (a) Creating New Blog Entry (b) Ontology-assisted Keyword Suggestion Figure 4.4: Blog Publication Features of Prototype 33
- 41. (c) Tag Cloud (on right) (d) Recent Blog Entries Figure 4.4: Blog Publication Features of Prototype (cont’d) 34
- 42. (a) Subscribing to Web Feed (b) Subscribed Web Feeds in Microsoft Outlook Figure 4.5: Blog Consumption Features of Prototype 35
- 43. (c) Using Microsoft Outlook as Web Feed Reader (d) Reading Blog Entries by Microsoft Outlook Figure 4.5: Blog Consumption Features of Prototype (cont’d) 36
- 44. (a) Discussion among Colleagues Figure 4.6: Blog Socialization Features of Prototype 37
- 45. (a) Archiving Discussion Thread to DSpace (b) Archiving Webpage to DSpace Figure 4.7: Knowledge Archiving Features of Prototype 38
- 46. (c) Archiving Non-Web Content Figure 4.7: Knowledge Archiving Features of Prototype (cont’d) 39
- 47. (d) Personal Portfolio of Knowledge Figure 4.7: Knowledge Archiving Features of Prototype (cont’d) 40
- 48. (a) Digital Library Search (b) Blog Search Figure 4.8: Knowledge Retrieval Features of Prototype 41
- 49. (c) Federated Search (d) Search Results Figure 4.8: Knowledge Retrieval Features of Prototype (cont’d) 42
- 50. (e) Web Service Execution Figure 4.8: Knowledge Retrieval Features of Prototype (cont’d) 43
- 51. CHAPTER 5 ENGINEERING SOFTWARE INTEROPERABILITY 5.1 Introduction Computers performing structural analysis using numerical methods require close guidance from human users. Consider the case of finite element analysis, in which it is first necessary to examine a real world problem and construct a computer model of the problem including the problem domain, material behaviors, and boundary conditions. It may also be necessary to consult many design codes or previously obtained experi- mental results to assemble the proper input data for the analysis. Next, the problem domain must be discretized, either manually or through the help of automatic meshing software, before the element stiffness matrices can be computed and assembled, the boundary conditions applied and a solution for nodal unknowns found. Experience and judgment are required by the analyst to select the element types and the consti- tutive models for the materials and physical processes being simulated, to examine the accuracy of the analysis results and, if necessary, to repeat the entire process to study solution convergence. For large and complex analyses, running an entire process may take hours or days and visualization techniques, including animations or virtual real- ity, may be needed to effectively interpret the analysis results. Such situations may be even more complicated when incompatibilities between input and output data formats of the software components employed exist, and are likely to be tedious and lead to inaccurate solutions, especially if performed by inexperienced users. Web Services (W3C, 2004d) and the Semantic Web (Berners-Lee et al., 2001), two Internet technologies, have the potential to help unify and utilize scattered re- sources, such as personal computers, computer clusters, supercomputers, databases and knowledge bases to enable numerical structural or mechanical analyses to be done in a fast, accurate and automated manner. These technologies potentially reduce the need for analysts to be actively involved in providing all the required data and detailed instructions. Rather, analysts can initiate the solution process by giving simple in- structions, monitoring the computers as they work on obtaining solutions, and making a final decision on the acceptability of the results. With today’s ubiquitous access, the Internet is not simply a hyper-library for information searches, nor only a communica- tion tool for sending e-mail messages. It may, in fact, be utilized as a large platform for scientific computation with the help of intelligent software agents that collaborate to accomplish a given task. A framework for the joint application of Web Services, the Semantic Web and Semantic Web Services to address software interoperability problems in structural en- gineering is proposed in this chapter, a proof of concept prototype presented and its potential illustrated by a case study which involves the solution of a typical problem in structural analysis and design.1 5.2 A Semantic Web Services Framework for Computational Mechanics As discussed earlier, Semantic Web Services have the potential to help unify computing resources and knowledge scattered on the Internet into a large platform for scientific computing. In this section, an architectural framework is proposed, from a system development point of view, for the development of computational mechanics 1 The content of this chapter has been published in Vacharasintopchai et al. (2007a). 44
- 52. Service Description Matchmaker APP LOGIC, OWL-S KB, DB Pu d bli Fi n sh Service Service Consumer Provider Bind APP LOGIC, APP LOGIC, KB, DB SOAP KB, DB (XML+RDF) Figure 5.1: Semantic Web Services Model software based on Semantic Web Services. To prevent ambiguity with terms in the general Semantic Web Services architecture, the proposed framework is called Semantic Web Services for Computational Mechanics (SWSCM), and a semantic Web service in the SWSCM architectural framework is called an SWSCM Service. 5.2.1 SWSCM Model The proposed SWSCM is an extended version of the standard Web Services model presented in Figure 2.1 on page 10. The model of the SWSCM architecture is illustrated in Figure 5.1. The goal in the development of the SWSCM framework is to make it as compatible with the prevalent Web Services technology as possible, i.e., we try to make SWSCM the semantic “shell” of Web Services. By adopting such a shell principle, we will have access not only to a variety of software development tools for Web Services technology, which are available in several programming languages, but also the many Web services deployed on the Internet. To facilitate the publication and discovery of relevant semantic Web services, the UDDI service registry is replaced by the matchmaker service, and the WSDL service description is replaced by the OWL-S semantic Web service description (Figures 2.1 and 5.1). Access to WSDL documents on the Internet is still necessary for service consumers to properly ground and bind to service providers. However, the matchmaker does not need to store the copies (or URL to the copies) of such documents locally because only the semantic Web services description from OWL-S documents is used in the matching process. SOAP messages, which are used for communication between Web services, are augmented with RDF statements so that XML data transmitted from a sender will be meaningful to the recipient. Each parameter of the request and response mes- sages between service consumers and providers consists of the serialized XML data (as required by the SOAP specification) and its corresponding RDF statements which explain the meaning of such data, as shown in Figure 5.2. RDF statements are typi- cally encoded in XML format and the format is termed RDF/XML according to the RDF specification. As RDF/XML can naturally be included as extra attachments in SOAP messages, RDF-augmented SOAP messages will not cause a compatibility issue 45
- 53. SOAP Envelope SOAP Body REQUEST / RESPONSE MESSAGE CONSUMER PROVIDER Parameter 1 XML RDF DATA ... Parameter n XML RDF DATA Figure 5.2: Semantic SOAP Message KNOWLEDGE BASE APP LOGIC DATABASE Concepts Objects Table A Processor Inference Engine Query Assertions - fields Table B - methods ... Instances Table n Figure 5.3: Components of Semantic Web Service with non-SWSCM aware recipients because the recipients can ignore the part of an attachment that they do not recognize. 5.2.2 Components of SWSCM Service Each SWSCM service comprises three components, which are the application logic component, the knowledge base component, and the optional database component, as illustrated in Figure 5.3. The application logic is the primary component of a SWSCM service. It per- forms the functions advertised in its service description. It handles and processes requests initiated by service consumers, and delegates tasks to the others by sending out request messages. The application logic is the same component found in typical services on the Web Services architecture. The knowledge base provides intelligent assistance to the application logic. It consists of an inference engine and copies of ontologies and RDF (or OWL) state- ments downloaded from the Semantic Web. Multiple domain ontologies, e.g., a units- of-measurement ontology, a material property ontology, and a structural engineering ontology, are downloaded and stored locally on the knowledge base during the initial- ization process of an SWSCM service. The knowledge base uses its inference engine and the premises from RDF (or OWL) statements to answer queries initiated from the application logic. The database component provides information processing assistance to the ap- plication logic. It is an optional component which contains a dedicated database man- agement system. The database component is useful when an SWSCM service has to deal with a large amount of raw data and complicated database queries, as in the 46
- 54. case of postprocessing the results from a large-scale finite-element analysis which can involve several million degrees of freedom. 5.2.3 Communication between SWSCM Services In standard Web Services architecture, to send a request to a service provider, a service consumer first serializes its respective input parameters—“objects” in the object-oriented programming paradigm or “structures” in the procedural programming paradigm—into a structured XML representation (shown as XML data in Figure 5.2). According to the WSDL standard by W3C, the structure of the XML representation (termed XML schema) is agreed upon in the “Types” section of the WSDL document published by the service provider. Next, the service consumer consecutively wraps the input parameters with the SOAP Body and SOAP Envelope XML elements, and finally uses the HyperText Transfer Protocol (HTTP) to transmit the SOAP envelope to the service provider at the “rendezvous URL,” which is also specified in the WSDL document. Once the service provider receives the SOAP message from the consumer, it does the reverse procedure to extract the input parameters and deserialize them into objects or structures, depending on its programming paradigm. Later, it processes the input data, serializes the output into XML format, constructs the SOAP message, and finally transmits the result back to the service consumer at the rendezvous. SWSCM services communicate in the same fashion as standard Web services do, i.e., through SOAP messages. The WSDL grounding section of an OWL-S description grounds the generic input parameters, output parameters, and atomic processes to specific sections of a WSDL document that specify the XML schema of the input parameters and output parameters, and the rendezvous URL for actual invocation of the Web service. At the syntactic level, SWSCM services refer to the XML schema and rendezvous URL for the serialization of objects or structures and the transmission of SOAP envelopes, respectively. In addition, at the semantic level, the communication between SWSCM ser- vices extends the standard SOAP messaging protocol by embedding the RDF state- ments relevant to the objects or structures carried by SOAP messages (Figure 5.2). It is proposed that the application logic component of each SWSCM service assigns each object or structure a unique URI at runtime and that it populates its associated knowledge base component with a set of assertions about the object or structure. For example, a floating-point object Width 01 with the value of 2.00, which represents the inch width of a rectangle, could be given the URI of http://ws.example.com/ object_ids#Width_01. If we refer to this URI as URI W01, its corresponding set of assertions would be the RDF statements: URI W01 “is an instance of” http://std.swscm.org/geometry.owl#Width; and URI W01 “has unit” http://std.swscm.org/units.owl#Inch. A pair of an object (or a structure) in the application logic and its assertions in the knowledge base is termed a Semantic Object. During the serialization process, when an SWSCM service consumer sends a request message to the provider, the application logic component not only serializes an input parameter (an object or a structure) into the XML Data, but also provides an accompanying set of RDF/XML assertions (shown as the RDF block in Figure 5.2). Having received and deserialized the SOAP message, the SWSCM service provider will be able to not only reconstruct the data set of input parameters but also replicate the 47
- 55. assertions about each input parameter into its own knowledge base. In addition to the semantic matching of Web service description profiles, which is discussed in the section on “Semantic Web Services”, the proposed RDF-augmented SOAP messages provides an extra cross-checking means to address the incompatibility issue between the input and output parameters. RDF-augmented SOAP messages would help prevent the kind of problem that causes mishandlings of physical quantities in the mission- critical calculations, which occurs, for example, just because one service expects the input parameters in metric units of measurement and another service provides the input parameters in English units, and the two services by chance refer to their input parameters by the same ontological concept. The RDF augmented SOAP messaging in the SWSCM framework is termed the Semantic SOAP. 5.2.4 Inference Engine and Reasoning Process The proposed SWSCM framework is independent of an inference engine. Any inference engine can be used provided that they are equipped with the basic rules for processing RDF and OWL statements. As discussed in the sections on “Semantic Web” and “Semantic Web Services”, reasoning on RDF and OWL statements relies heavily on concept subsumption, which is the determination of whether one concept is more general than another. For instance, term X subsumes term Y if term X is more general than term Y, and term X is the same as term Y if term X and term Y subsume each other. Therefore, the inference engine for the knowledge base component of an SWSCM service must satisfy the following requirements: 1. It must be capable of parsing the statements encoded in RDF and OWL lan- guages; 2. It must natively understand or be equipped with the set of rules to understand the semantics of RDF and OWL constructs as specified by W3C (W3C, 2004c,b); and 3. It must at least be able to answer concept subsumption problems. An inference engine that understands the semantics of RDF and OWL will be able to answer queries similar to the following examples, with terms in the quotation marks referring to standard constructs in the RDF and OWL specifications. Example 1 Given the premise RDF statements: term X is an “instance of” class X; class X is a “subclass of” class Y; and class Y is a “subclass of” class Z, then Query: Does class Z subsume class X? Answer : Yes, by transitivity. Query: Is term X an “instance of” class Z? Answer : Yes, because term X is an instance of class X which is subsumed by class Z. 48
- 56. Example 2 Given the premise RDF statements: Triangle is a “subclass of” PlaneShape; Triangle is a “subclass of” ClosedShape; Triangle “has side” of Line only; and The “number of” “has side” properties that Triangle has is 3, then, if an object is defined by the following assertions: The object is a “subclass of” PlaneShape; The object is a “subclass of” ClosedShape; The object is a “subclass of” EquilateralShape; The object “has side” of Line A, which is an “instance of” Line; The object “has side” of Line B, which is an “instance of” Line; The object “has side” of Line C, which is an “instance of” Line; and The “number of” “has side” properties that this object has is 3. Query: Is the object a Triangle? Answer : Yes, because based on the given premises, Triangle subsumes the definition of the object; therefore, the object is a kind of Triangle. Examples of inference engines that can be used in SWSCM knowledge base compo- nents are RACER (Haarslev and Moller, 2003) and the SWI-Prolog Semantic Web package (Wielemaker et al., 2003), which are based on Description Logics (Nardi et al., 2003) and Prolog, respectively. RACER is an example of an inference engine that na- tively understands the semantics of RDF and OWL constructs because its underlying Description Logics framework was used as the basis to design the OWL language. SWI- Prolog with its Semantic Web package is an example of an inference engine equipped with a set of rules that enables it to understand the semantics of the RDF and OWL constructs. It should be noted that RDF and OWL are knowledge “representation” lan- guages. The RDF and OWL specifications do not mandate the use of Description Logics as the only logical framework for the Semantic Web. The knowledge inferred by an inference engine, or the answer that it provides, is limited by its underlying logical framework. 49
- 57. 5.2.5 Matchmaking Algorithm One of the most important operations in the Semantic Web Services architecture is the matching of the ideal service profile of a service consumer against the service pro- files registered by several service providers. In this section, the service profile matching algorithm proposed for use by matchmakers in the SWSCM architecture is discussed. The algorithm is inspired by the one proposed by Semantic Web Services researchers at Carnegie Mellon University (Paolucci et al., 2002; Sycara et al., 2003). An OWL-S profile description is a set of OWL-S statements that semantically describes a service, which is either needed by a service consumer or offered from a service provider. From the section on “Service Profiles” in the OWL-S specification (OWL–S, 2003), the elements of a profile description that are relevant to the interoperation of SWSCM services are the taxonomic type of profile (i.e., whether a service belongs to a certain class) and the “has input,” “has effect,” and “has output” properties. Examples of such elements are the <profileHierarchy:SineFunctionEvaluator>, the <profile:hasInput>, the <profile:hasEffect>, and the <profile:hasOutput> in Figure 2.4 on page 17, respectively. For each pair of the service profiles, the degree of match is calculated by using the weighted average of the matching scores between the pairs of the profile types, the input parameters, the effects of service, and the output parameters. Mathematically, the degree of match between a pair of service profiles is i wi di p DS = (5.1) i wi where DS = degree of match between two service profiles; and wi and di p = respective weight and the matching scores between the profile types, the input parameters, the effects of services, and the output parameters. By default, equal weights are assigned to the matching scores in typical matchmaking operations. Service consumers may request higher weights to certain pairs of the profile description if compatibility between those pairs is more important. For each pair of the ideal concept CR and the advertised concept CA , the match- ing score between CR and CA with respect to CR , d(CR , CA ), is defined as 1.00 if CR is the same as CA , 0.75 if C subsumes C , A R d(CR , CA ) = (5.2) 0.50 if CR subsumes CA , 0 otherwise. If we collectively call the profile types, the input parameters, the effects of service, and the output parameters “parameters,” the value of d(CR , CA ) = 1.00 signifies that the ideal parameter perfectly matches the advertised parameter. The value of 0.75 signifies that the advertised parameter is more general than the ideal parameter, and that the advertised service is not specifically made for the consumer. The value of 0.50 signifies that the ideal parameter is more general than the advertised parameter, and that the advertised service may not completely fulfill the consumer’s request. The value of 0 signifies that the two parameters are incompatible and the advertised service is not recommended for the consumer (Paolucci et al., 2002). SWSCM services often take several input parameters. In this case the matching score between the two sets of input parameters is the unweighted average of the match- 50
- 58. ing scores between each sequential pair of the input parameters. Mathematically, it is defined as jdj I dI p = (5.3) N where dI p = matching score between two sets of input parameters; dj I = degree of match between the jth pair of input parameters; and N is the total number of input parameters. To eliminate the case of strong incompatibilities between certain pairs of input parameters, dI p must be taken as zero if any of dj I equals zero. 5.3 Application to Structural Analysis and Design 5.3.1 Implementation A prototype system was developed to determine the maximum stress in a rect- angular solid object of various configurations. The object, made of a material selected by the user, was to be loaded uniformly under a user-given load specification and subjected to user-given support conditions. The dimensions of the object were to be specified in different units of measurement. The specific objectives in developing the prototype were: 1. to demonstrate the interoperability of heterogeneous software components, as offered by ontologies, OWL statements, semantic Web service descriptions, and the matchmaking concepts; and 2. to demonstrate the role of OWL statements, published on the Semantic Web, as dynamic and external data sources for structural analysis software components. The following open source and public-domain software tools were used in the implementation: 1. Apache Axis Web Services toolkit (Apache, 2003a), 2. Apache Web Service Invocation Framework (WSIF) (Apache, 2003b), 3. JAMA matrix library (NIST, 1999), 4. Jena Semantic Web Framework (Jena, 2007), 5. University of Maryland’s OWL-S API project (OWL-S API) (Sirin, 2004), 6. Prot´g´ ontology development tool (Prot´g´, 2005), and e e e e 7. RACER Description Logic reasoner (Haarslev and Moller, 2003). All Java Web services utilized the APIs provided by Apache Axis and WSIF to initiate and process SOAP requests and responses during the execution of Web services. Custom serializer and deserializer modules were developed in Java to allow Apache Axis to recognize and process Semantic SOAP messages. Matrix operations in Java Web services employed the APIs by JAMA matrix library. Java software development kit version 1.4.1 and Microsoft Visual Studio .NET 2003 were used as the compilers for Java and C# codes. All SWSCM services employed the inference 51
- 59. ParEFG WS USER-INTERFACE (PDA/Smartphone) Mesher WS Match maker Structural Analysis WS FEM WS Max Value WS Figure 5.4: System Configuration of Prototype engine and RDF knowledge base query and management APIs provided by Jena. The Matchmaker employed the inference engine and RDF knowledge base APIs provided by RACER, a dedicated Description Logic reasoner, for more powerful reasoning on complicated ontologies. The Matchmaker utilized OWL-S API to extract concepts represented in OWL-S service profiles. SWSCM services used OWL-S API to extract service grounding information for binding to service providers. Grounded services were executed by means of the APIs in WSIF. The Prot´g´ ontology development tool by e e Stanford University was used in the development of ontologies. The prototype system consisted of five SWSCM services, one Matchmaker ser- vice and one User Interface, as shown in Figure 5.4. The SWSCM services consist of the Structural Analysis (SA) service, the Mesher service, the Parallel Element-Free Garlerkin Method (ParEFG) service, the Finite-Element Method (FEM) service and the Max Value service. WSDL documents and OWL-S documents, as well as ontologies and OWL statements, were published on a Web server to facilitate the operation of SWSCM services and the Matchmaker. WSDL documents describe the syntactic oper- ations of SWSCM services, e.g., the schemas of XML Data and the rendezvous URLs where SOAP messages are expected. OWL-S counterparts provide semantic profile descriptions with grounding references to specific parts of the WSDL documents. Ideal service profiles desired by SWSCM consumers were published as nongrounded OWL-S documents. Ontologies developed and published on the Web server include: 1. the Quantities ontology that defines physical quantities and various types of num- bers; 2. the Material ontology that defines materials and their mechanical properties; 3. the Units ontology that defines relations between units of measurement (e.g., “an angular degree is a subclass of plane angle, has conversion factor of π/180 with radian angle as the reference unit of measurement”); and 4. the Structural Engineering ontology that defines general knowledge in structural engineering (e.g. the pinned support condition). 52
- 60. The prototype system was deliberately designed to consist of modules devel- oped on potentially incompatible platforms. As postulated in Section 5.2.1, OWL-S, WSDL and SOAP are the common languages that SWSCM services “speak.” Ser- vices on different computing platforms were developed in appropriate programming languages such that they speak the same dialects and communicate by the methodol- ogy in Section 5.2.3. Key characteristics of modules in the prototype are presented as follows: Java Web Services The Matchmaker, the SA service, and the Max Value service were developed as Web services in Java. The Matchmaker employed the service profile matching algorithm in Section 5.2.5 to handle requests for service recom- mendation. The SA service assisted the User Interface in numerical analyses of structures. The Max Value service employed the Quicksort algorithm to identify maximum values from lists of double-precision numbers. Commercial Software Package The Mesher and the FEM services were developed in Java as Web service frontends to the ANSYS commercial FEM software (AN- SYS, 2006). The Mesher, upon receiving Semantic SOAP request messages, de- serializes input parameters then generates and executes ANSYS input files which discretizes problem domains into eight-noded brick meshes. The FEM service, in a similar manner, takes Semantic SOAP request messages then generates and executes ANSYS input files to solve particular problems correspondingly. Results from these services are serialized and returned to service consumers at respective rendezvous URLs. Parallel Cluster Computing The ParEFG service, programmed in Java, allowed other SWSCM services to access the Element-Free Garlerkin Method (EFGM) meshless analysis engine developed in C and deployed on a Linux parallel com- puter cluster (Barry and Vacharasintopchai, 2001). It acts as a proxy for SWSCM services to access the functionality of the EFGM engine which per se takes inputs, receives commands and delivers outputs through UNIX socket communication (Metcalfe and Gierth, 1998). Mobile Computing The User Interface was developed for Windows Mobile personal digital assistants (PDAs) or smartphones, using the C# programming language and Microsoft .NET Web Services client APIs (Microsoft, 2003). It relies on the SA service which acts as a proxy, allowing devices with lower computing power to access the more powerful computing power provided by ParEFG, FEM and Max Value services. Ubiquitous Access The User-Interface was designed to communicate with the SA service via the General Packet Radio Service (GPRS) on mobile phones (Wikipedia, 2006a) or Wi-Fi Internet connections (Wikipedia, 2006b). In this regard, the sys- tem prototype illustrates not only the interoperability between .NET and Java Web services but also the ubiquitous access to computational facilities made pos- sible by Web Services technology. 5.3.2 A Proof of Concept Prototype The following describes an example workflow of components in the system pro- totype to solve a particular problem of finding “the maximum service stresses in an 53
- 61. Figure 5.5: Windows Mobile User Interface ASTM A36 steel plate with the dimensions of 1.00–m wide by 200–cm long with 0.25–in thickness, cantilever-supported along the longer edge, and subjected to the floor load for libraries specified in the Thai Building Code.” The workflow started when the user entered the input data into the User In- terface shown in Figure 5.5. From the left of the figure, the geometry of the problem was entered at the Geometry screen, and the “Generic ASTM A36 Steel” material, the “Library Floor” load condition, the “TH-2527” building code, the “Service Load” load factor, and the “Longer-edge Cantilever” support condition were selected at the Parameter screen. The Summary screen allowed the user to verify the input data, and to submit the request to the SA service. Except for the numerical values, the input parameters were selected through the “Select a Resource” screen which retrieved pa- rameter choices from an external XML data file. The preferred unit of stress can be selected on the configuration menu and in this example the unit of stress was set to pascals (Pa). The content of the SOAP body submitted by the User Interface is shown in Figure 5.6. The width, length, and thickness of the object are accompanied by re- spective URIs to the units of measurement. The material type, the support condition, the building code, the loading condition, and the load factors were specified as URIs of concepts. The preferred unit of stress was specified as the URI to the concept “Pa.” The input parameters were deserialized by the SA service into semantic objects as soon as the request message arrived. Preconfigured to work in the SI units, e.g., lengths in meters and stresses in pascals, the application logic of the SA service queried the knowledge base for conversion factors, and the width, length, and thickness of ob- jects are converted into the meters unit at the time they were constructed. The seman- tic objects that represented the modulus of elasticity, density, Poisson’s ratio, tensile proportional limit, and ultimate strength of the ASTM A36 steel were created using the assertions about http://www.swscm.net/material-properties.owl#ASTM A36 queried from the knowledge base. Inside the knowledge base component, the material- properties.owl file, shown in Figure 5.7, was downloaded from www.swscm.net and OWL statements with the “hasTensileModulusOfElasticity,” “hasDensity,” “hasPoissons- Ratio,” “hasTensileProportionalLimit,” and “hasTensileStrength” as verbs were re- trieved. All material property objects were normalized into the SI units in the same fashion as the length objects. The SA service next requested the Matchmaker for a service that matches its ideal mesher profile. The URI to the OWL-S description of the Mesher service was suggested. The SA service then retrieved the WSDL grounding information from the OWL-S description. The Semantic SOAP message that contained the problem geom- 54
- 62. <analysisRequest xmlns="uri:ppc-client" xml:base="uri:ppc-client"> <getMaxStress> <geometry> 5 <width unit="http://std.swscm.org/units.owl#m"> 1.00</width> <length unit="http://std.swscm.org/units.owl#cm"> 200</length> <thickness unit="http://std.swscm.org/units.owl# 10 inch">0.25</thickness> </geometry> <material>http://www.swscm.net/material- properties.owl#ASTM_A36</material> <support> 15 <condition>http://std.swscm.org/structures.owl# LongerEdgeCantileverSupport</condition> </support> <loading> <code>http://std.swscm.org/structures.owl# 20 TH2527</code> <condition>http://std.swscm.org/structures.owl# LibraryFloor</condition> <loadFactor>http://std.swscm.org/structures.owl# ServiceLF</loadFactor> 25 </loading> <resultUnit> http://std.swscm.org/units.owl#Pa</resultUnit> </getMaxStress> </analysisRequest> Figure 5.6: Sample Request Message from PDA Client etry was transmitted to the rendezvous URL of Mesher, and the eight-noded brick element mesh was constructed. After this, the SA service handled the boundary conditions (BCs). For displace- ment BCs, it created a semantic array object of prescribed displacements using asser- tions from the definition of the concept http://std.swscm.org/structures.owl#- LongerEdgeCantileverSupport, which specified nodal displacements in terms of a set of nodes at a specific location (e.g., the set of nodes that “has X coordinate equal to zero”) using the “pinned” node and the “locked” displacement concepts. The OWL statements that define such concepts are presented in Figure 5.8. The definition of the pinned node asserted that the displacements ux , uy , and uz for each node be specified as locked. The locked displacement was asserted as the “Scalar” that “has value” of 0.00 and “has unit” of meters. The force BCs were handled similarly. Later, the SA service requested the Matchmaker for a service that matches its ideal structural analysis profile. The ideal input parameters comprised a mesh, the force and displacement boundary conditions, and the material properties. The ideal output parameter was an array of stress tensors. Each parameter was supported by an onto- logical concept. The ideal effect of service was http://std.swscm.org/Structural- AnalysisEffects.owl#SmoothStressAtIntegrationPoints. The same input and output parameters that match the ideal sets were described in the ParEFG and FEM service. However, the FEM service gave the http://std.swscm.org/Structural- AnalysisEffects.owl#StressAtIntegrationPoints effect, whereas the SmoothStress- AtIntegrationPoints, a subclass of StressAtIntegrationPoints, was given in the ParEFG case. The matchmaking algorithm thus recommended the ParEFG service. The Semantic SOAP message was submitted to the rendezvous URL and the array of stress tensors at integration points were computed. The Von Mises stresses at the 55
- 63. <rdf:RDF> ... <mat:DuctileMaterial rdf:ID="ASTM_A36"> <rdfs:label>ASTM A36 steel</rdfs:label> 5 <mat:hasDensity rdf:resource="#Steel_Density"/> <mat:hasPoissonsRatio rdf:resource ="#Steel_PoissonsRatio"/> <mat:hasTensileModulusOfElasticity 10 rdf:resource ="#Steel_TensileModulusOfElasticity"/> <mat:hasTensileProportionalLimit> <mat:TensileProportionalLimit rdf:ID="ASTM_A36_TensileProportionalLimit"> 15 <mat:representedBy> <mat:Scalar> <mat:hasValue rdf:datatype="&double;">36.0 </mat:hasValue> </mat:Scalar> 20 </mat:representedBy> <mat:hasUnit rdf:resource="&unit;#ksi"/> </mat:TensileProportionalLimit> </mat:hasTensileProportionalLimit> 25 <mat:hasTensileStrength> <mat:TensileStrength rdf:ID="ASTM_A36_UltimateStrength "> <mat:representedBy> <mat:Scalar> 30 <mat:hasValue rdf:datatype="&double;">58.0 </mat:hasValue> </mat:Scalar> </mat:representedBy> <mat:hasUnit rdf:resource="&unit;#ksi"/> 35 </mat:TensileStrength> </mat:hasTensileStrength > </mat:DuctileMaterial> ... 40 </rdf:RDF> Figure 5.7: OWL Definition of ASTM A36 Steel integration points were calculated by the application logic of the SA and the Max Value service was consulted to find the maximum stress. Finally, the SA service identified the point where the maximum stress occurred, and the stress value and the location was returned to the User Interface for presentation to the user, as shown in Figure 5.9. From the analysis, the maximum Von Mises stress in the plate was 0.254 × 109 Pa. It exceeded the yield stress of the specified ASTM A36 material, which, according to Figure 5.7, equals 36 ksi (0.249 × 109 Pa). Therefore, the configuration of the structure needed to be revised for improved safety. 5.4 Summary This chapter has presented an architecture framework, from the system devel- opment point of view, for the application of Semantic Web Services technology to address software interoperability problems in structural engineering. It provides the implementational details which were identified but not yet addressed by general re- searchers that are necessary for the practical application of Semantic Web Services in scientific computing, particularly in computational mechanics. Based on several software tools, which are products from ongoing research on 56
- 64. <rdf:RDF> <swscm:DisplacementSpecification rdf:ID="Locked"> <mat:representedBy> 5 <mat:Scalar> <mat:hasValue rdf:datatype ="&double;">0.00</mat:hasValue> </mat:Scalar> </mat:representedBy> 10 <mat:hasUnit rdf:resource="&unit;#m"/> </swscm:DisplacementSpecification > <swscm:Support rdf:ID="Pinned"> <rdfs:label>Simple support condition</rdfs:label> 15 <swscm:hasDisplacementSpecification > <swscm:onComponent rdf:resource="#ux"/> <swscm:hasSpecification rdf:resource="#Locked"/> </swscm:hasDisplacementSpecification> 20 <swscm:hasDisplacementSpecification > <swscm:onComponent rdf:resource="#uy"/> <swscm:hasSpecification rdf:resouce="#Locked"/> </swscm:hasDisplacementSpecification> 25 <swscm:hasDisplacementSpecification > <swscm:onComponent rdf:resource="#uz"/> <swscm:hasSpecification rdf:resouce="#Locked"/> </swscm:hasDisplacementSpecification> 30 </swscm:Support> </rdf:RDF> Figure 5.8: OWL Definition of Pinned Node Figure 5.9: Output Screen on PDA Client 57
- 65. the Semantic Web and Semantic Web Services, a system prototype was developed to demonstrate how the proposed framework can help integrate multiple structural engineering software modules—potentially developed by various groups of programmers and deployed on heterogeneous platforms—with the element-free Garlerkin method software on a parallel computer cluster and the ANSYS finite element analysis software package on a Windows PC as particular examples. In addition, the system prototype also demonstrates how ubiquitous access to computational facilities can be achieved through personal digital assistant and smartphone devices that support Web Services technology. In this aspect, the proposed framework could be especially useful for engineers at construction sites. The proposed framework will become more useful as Web Services technol- ogy advances. As a platform-independent technology, Web Services allows convenient access to commercial software and potentially is an effective means both to reduce practitioners’ cost (through a pay-per-use model) and to prevent software piracy (as executable codes of Web services are located on remote servers and so are hidden from users). Thus, it is envisaged that general computational mechanics and structural engineering software developers will gradually adopt Web Services as their architec- tural platform, and the proposed framework will be a practical tool to assist in the integration of Web service software components. Despite the advantages of the proposed framework and the example implemen- tation, there are some issues that have not been addressed. In particular, issues related to trust and security have not been taken into account explicitly. More research work is also required to ensure that premises from ontological sources and results from ser- vice providers are credible and can be used in mission-critical environments. Financial aspects, such as the potential implementation of a pay-per-use model, were not specifi- cally implemented. However, concepts from e-commerce can be adopted and integrated into the framework. Last but not least, as the framework depends primarily on on- tologies, a more complete body of knowledge related to computational mechanics and structural engineering needs to be captured and published on the Web, and the wide adoption of such ontologies from software developers are essential for the framework to work at its full potential. 58
- 66. CHAPTER 6 CONCLUSIONS 6.1 Conclusion and Discussion This dissertation has proposed a structural engineering support system and two frameworks for the application of semantic computing—by means of metadata and ontologies—to improve the productivity of structural engineers on engineering design projects. The first system architecture framework, the Blog and Digital Library Frame- work for Engineering Knowledge Management (Blog+DL), is based on three software components that enable a methodology which uses Weblogs and Digital Libraries as building blocks for a collaborative engineering knowledge management system to assist engineers in sharing, exchanging, and improving their knowledge, skills and computing resources. The second system architecture framework proposed is the Semantic Web Services Framework for Computational Mechanics (SWSCM). The software compo- nents required for it are specified and the methodology by which they interact to unify and utilize the scattered wealth of computing resources available is described. The Blog+DL and SWSCM complement each other in the engineering process. Blog+DL relies on SWSCM to integrate computing resources shared by individual engineers. SWSCM can use Blog+DL to disseminate and discover shared computing resources, as well as to educate and exchange peer opinions about their underlying the- ories and user experiences. Two prototype systems were developed to demonstrate the proposed frameworks. The first system illustrates the joint application of Blog+DL and SWSCM to build support systems that facilitate the computationally oriented KM process in structural engineering, and the second system illustrates the full po- tential of SWSCM in facilitating a computationally intensive workflow that involves heterogeneous software components. To the best of the author’s knowledge, there have been no attempts to simultane- ously address the computational and knowledge management aspects of the engineering process. Existing work in engineering literature that is closely related to this research consists of Liu et al. (2005), Peng and Law (2004), El-Tayeh and Gil (2007), Mezher et al. (2005), and Rezgui (2006). The first two address computational aspects of the engineering process and the latter three address knowledge management. A summary comparison of their features with the ones of SWSCM and Blog+DL is provided in Table 6.1. Peng and Law (2004) propose an Internet-based framework which facilitates the composition of distributed Web services into a finite-element analysis (FEA) program. By adopting a service-oriented system architecture (He, 2003), as SWSCM does, the framework allows new and legacy codes from heterogeneous sites to be dynamically discovered, bound, and executed by the FEA program, and support for mobile device clients, such as Palm OS and Windows Mobile PDAs or smartphones, is technically possible. Their approach differs from the one in this research in that it is based on the Java Remote Method Invocation (RMI) interoperation technology which predates the World Wide Web Consortium (W3C) Web Services standard; limiting interoper- ability with Web services on the Internet, and restricting the supported programming language to Java. The dynamic service composition and data interoperability issues were addressed by Liu et al. (2005), a group affiliated with Peng and Law, when they proposed the Flow-based Infrastructure for Composing Autonomous Services (FICAS), an infrastructure for the composition of loosely coupled software components with an 59
- 67. Table 6.1: Features Comparison with Existing Work Peng Liu El-Tayeh Mezher Blog+DL & and Rezgui et al. and Gil et al. SWSCM Law (2006) (2005) (2007) (2005) (2004) KNOWLEDGE SHARING Documents1 Y – – Y2 Y Y Computing tools - Worksheets Y – – – Y – - Individual software Y – – – Y – - Subroutines Y – – – – – Multimedia content Y – – – Y3 Y3 Socialization Y – – Y – – KNOWLEDGE ARCHIVING Documents1 Y – – Y2 Y Y Individual software Y – – – Y – Multimedia contents Y – – – Y3 – Web content Y – – – – – Repository Y – – Y Y Y Automated review workflow Y – – – – – KNOWLEDGE RETRIEVAL Ontology-assisted Y – – Y – Y Keyword tagging Y – – Y – Y Smart keyword suggestion Y – – – – Y Metadata search Y – – – – – Full-text search Y – – – – Y Categorized browsing Y – – Y Y Y USER INTERFACE & INTEROPERABILITY User interface Web – – Web Web Web Support for Social Network Analysis Y – – Y – – URL, Windows Web System interoperability standard(s) RSS/Atom, – – Proprietary files Services4 OAI-MHP sharing COMPUTATIONAL FEATURES Support for mobile device clients Y Y Y3 – – – Service-oriented architecture Y Y Y – – – Support for legacy codes Y Y3 Y – – – Heterogeneous platform interoperability Y Y Y – – – Dynamic service discovery and binding Y Y Y – – – Dynamic service composition Y Y – – – – Dynamic data interoperability Y Y – – – – OWL Knowledge-base data source – – – – – ontologies Web Services Java Interoperability standards & Semantic Proprietary – – – RMI Web5 Java & major Supported programming language Java Java – – – languages6 Compatible with existing Web Services Y – – – – – technology 1 including AutoCAD, Excel, PDF, PowerPoint, and Word 2 plain-text only 3 technically possible, although not explicitly discussed by the authors 4 SOAP, WSDL, UDDI 5 HTTP, SOAP, WSDL, RDF, OWL, and OWL-S 6 including C++, C#, Perl, PHP, Python, and VB.NET 60
- 68. active data mediation facility. Despite the reported superior performance over SOAP in high data volume engineering applications, the communication protocol and the ser- vice description scheme in FICAS are proprietary and not compatible with the W3C standards, making them incompatible with the emerging development tools in many programming languages that conform to the W3C specifications. Ontologies and se- mantic descriptions of terms and Web services were not taken into account in these proposals, so that Internet-based artificial intelligence technologies that allow more seamless integration of software components from the Web, cannot be readily incorpo- rated. Mezher et al. (2005) present a methodology to build a knowledge management system in an international engineering consultant firm by using the Microsoft Windows file-sharing system on the company’s intranet, covering three main offices in different countries. Each office hosts a file-repository server that stores standard design pro- cedures, templates, forms, and computer programs, as well as lessons from sites and project documents. The documents include Word and Excel files as well as AutoCAD drawings. Using the Internet Explorer Web browser as a front-end user interface, users can retrieve pieces of knowledge from the repository by browsing through hierarchies of folders to which they are granted access privileges. Knowledge and computer programs are exchanged among users in different offices through e-mail but need to be autho- rized by a superior engineer before they can be stored on a file server. Their approach differs from the one in this research in that it lacks an integrated set of socializa- tion tools which facilitate the sharing and developing of tacit knowledge among users. The hierarchical browsing through explicit knowledge, without support from advanced metadata and full-text search facilities, will make it difficult for users to precisely re- trieve relevant knowledge as the size of the repository grows. The system also lacks automated support for the review workflow which increases the time required for criti- cal pieces of knowledge to gain approval for publication in the repository. The sharing of computational software tools in the form of Web Services is also not supported. An advanced ontology-assisted knowledge retrieval technique for the construc- tion industry, with document summarization and full-text search capabilities, is pro- posed in Rezgui (2006); however, review workflow, metadata search, and socialization techniques are not included in this study. Digital socialization in a construction team was addressed in El-Tayeh and Gil (2007); nevertheless, the sharing, archiving, and retrieval of knowledge are limited to plain-text documents. Like Blog+DL, Rezgui (2006) is based on widely-accepted system interoperabil- ity standards. Their developments were however aimed at different applications. The W3C standard compliant Web services adopted in Rezgui (2006) support interoper- ability at the application programming interface level, which is intended specifically for software developers; whereas the RSS/Atom and the OAI-MHP features in Blog+DL support interoperability at the information exchange and consumption level, which is intended both for developers and general users. 6.2 Recommendations for Further Research The support system as well as the SWSCM and Blog+DL frameworks proposed in this dissertation can potentially be applied not only to structural engineering but also to other computationally-oriented application areas. The implementation of the prototype systems has spawned many interesting research topics worth further inves- tigation. 61
- 69. In particular, this dissertation has focused on methodologies to more seamlessly integrate computational services owned or developed by different groups of people on heterogeneous computing platforms via the Internet or an intranet. One assumption for such integration is that all services are trustworthy and a second is that they are accessible free of charge. Issues related to trust, security, and tariffs have not been addressed by this research. Such conditions, however, are not easily achieved when a large number of services are deployed and consumed via the Internet, as is clear from current concerns about malicious software and Web phishing incidences. The trust, security, and tariff issues of Web services therefore need to be further investigated, in addition to the refinement of the matchmaking and composition algorithms. As the framework depends primarily on ontologies, more complete bodies of knowledge in the target application domains of computational mechanics and structural engineering need to be captured and published on the Web. The wide adoption of such ontologies by software developers is essential for the proposed frameworks to be exploited to their full potential. The Blog+DL framework features an ontology-assisted keyword suggestion component which assists users in providing proper metadata for the effective and convergent retrieval of knowledge. A relatively simple keyword detection algorithm has been implemented in the prototype system for illustrative purposes. More advanced keyword detection techniques however, are available in the natural language processing literature. Such techniques should be further explored to improve the performance of metadata enforcement and knowledge retrieval. Last but not least, the social networking feature of Weblogs opens Blog+DL to research in social network analysis which holds the potential to further enrich the capabilities of the Blog+DL- based knowledge management systems. 62
- 70. REFERENCES Al-Ghassani, A. M., Anumba, C. J., Carrillo, P. M., and Robinson, H. S. (2005). Tools and techniques for knowledge management. In Anumba, C. J., Egbu, C., and Carrillo, P., editors, Knowledge Management in Construction. Blackwell Publishing, Oxford, U.K., 2005. ISBN 1-40-512972-7. ANSYS (2006). ANSYS Finite Element Analysis Software: ANSYS Structural. AN- SYS, Inc., 2006. Available online: http://www.ansys.com/products/structural. asp. [Downloaded: April 29, 2006]. Apache (2003a). Apache Axis 1.1. Apache Software Foundation, 2003. Available online: http://ws.apache.org/axis. Apache (2003b). Web Services Invocation Framework 2.0. Apache Software Founda- tion, 2003. Available online: http://ws.apache.org/wsif. Apache (2007). Apache Lucene. Apache Software Foundation, 2007. Available online: http://lucene.apache.org/java/docs/index.html. [Downloaded: November 12, 2007]. Barry, W. and Vacharasintopchai, T. (2001). A parallel implementation of the element- free Galerkin method. In Proceedings of the 8th East Asia-Pacific Conference on Structural Engineering and Construction (EASEC-8), page Paper No. 1068, Singa- pore, December 5-7, 2001. Available online: http://stweb.ait.ac.th/~ st029284/ papers/parallel-efgm-easec-8.pdf. [Downloaded: March 20, 2007]. Basha, S., Cable, S., Galbraith, B., Hendricks, M., Irani, R., Milbery, J., Modi, T., Tost, A., and Toussaint, A. (2002). Professional Java Web Services. Wrox Press, Ltd., 2002. ISBN 1-861003-75-7. Berners-Lee, T., Masinter, L., and McCahill, M. (1994). RFC1738 Uniform Resource Locators (URL). The Internet Engineering Task Force (IETF), December 1994. Available online: http://www.ietf.org/rfc/rfc1738.txt. [Downloaded: August 29, 2003]. Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The Semantic Web. Scientific American, 284(5):34–43, May 2001. Blogger (2007). Blogger homepage, Blogger.com – a Blog Service by Google, 2007. Available online: http://www.blogger.com. [Downloaded: May 5, 2007]. Boakes, R. (2007). Semantic computing, August 2007. Available online: http:// semanticcomputing.org. [Downloaded: October 4, 2007]. Brown, J. S. and Duguid, P. (2000). The Social Life of Information. Harvard Business School Press, Boston, MA, U.S.A., 2000. Burstein, M., Bussler, C., Zaremba, M., Finin, T., Huhns, M. N., Paolucci, M., Sheth, A. P., and Williams, S. (2005). A Semantic Web Services architecture. IEEE Internet Computing, 9(5):72–81, September/October 2005. Available online: http://doi. ieeecomputersociety.org/10.1109/MIC.2005.96. 63
- 71. Carrillo, P. and Chinowsky, P. (2006). Exploiting knowledge management: The en- gineering and construction perspective. Journal of Management in Engineering, 22 (1):2–10, 2006. Catlett, C. (2002). TeraGrid Primer. The TeraGrid Project, September 2002. Avail- able online: http://www.teragrid.org/about/TeraGrid-Primer-Sept-02.pdf. [Downloaded: June 10, 2003]. Chen, H.-M., Lin, Y.-C., and Chao, Y.-F. (2006). Application of web services for structural engineering systems. Journal of Computing in Civil Engineering, 20(3): 154–164, 2006. Chew, P., Chrisochoides, N., Gopalsamy, S., Heber, G., Ingraffea, T., Luke, E., Neto, J., Pingali, K., Shih, A., Soni, B., Stodghill, P., Thompson, D., Vavasis, S., and Wawrzynek, P. (2003). Computational science simulations based on Web Services. In Proceedings of International Conference on Computational Science 2003, St. Pe- tersburg, Russian Federation and Melbourne, Australia, June 2003. Available on- line: http://www.cs.cornell.edu/stodghil/papers/iccs03.pdf. [Downloaded: September 3, 2003]. Chiu, K., Govindaraju, M., and Bramley, R. (2002). Investigating the limits of SOAP performance for scientific computing. In Proceedings of 11th IEEE International Symposium on High Performance Distributed Computing (HPDC-11), Edinburgh, Scotland, July 2002. Available online: http://www.extreme.indiana.edu/xgws/ papers/soap-hpdc2002/soap-hpdc2002.pdf. [Downloaded: September 3, 2003]. Cross, R. (1998). Managing for knowledge: Managing for growth. Knowledge Manage- ment, 1(3):9–13, 1998. Crystal, D. (2006). Language and the Internet. Cambridge University Press, Cambridge, U.K., 2 edition, 2006. ISBN 0-52-186859-9. Avail- able online: http://books.google.com/books?id=cnhnO0AO45AC&pg=PA15&dq= blogosphere&sig=GTyNVN_DEzaeNCYOiTkZhPU5gUU#PPA15,M1. [Downloaded: May 4, 2007]. Czarnecki, D. (2007). Blojsom – java blog server software, 2007. Available online: http://www.blojsom.com. [Downloaded: August 22, 2007]. de Geytere, T. (2007). A unified model of dynamic organizational knowledge cre- ation: Explanation of SECI model of Nonaka and Takeuchi, 12manage B.V., 2007. Available online: http://www.12manage.com/methods_nonaka_seci.html. [Down- loaded: April 5, 2007]. Drucker, P. F. (1993). Post-Capitalist Society. HarperCollins, New York, U.S.A., 1993. ISBN 0-88-730620-9. DSpace (2007a). Dspace home page, DSpace Federation, 2007. Available online: http://www.dspace.org. [Downloaded: August 22, 2007]. DSpace (2007b). MIT’s DSpace experience: A case study, MIT Libraries and Hewlett- Packard Company, 2007. Available online: http://dspace.org/implement/ case-study.pdf. [Downloaded: May 5, 2007]. 64
- 72. El-Tayeh, A. and Gil, N. (2007). Using digital socialization to support geographically dispersed aec project teams. Journal of Construction Engineering and Management, 133(6):462–473, June 2007. Fallside, D. C. (2001). XML Schema Part 0: Primer. World Wide Web Consor- tium (W3C), May 2001. Available online: http://www.w3.org/TR/xmlschema-0. [Downloaded: June 23, 2003]. Fielding, R., Gettys, J., Mogul, J., Frystyk, H., Masinter, L., Leach, P., and Berners- Lee, T. (1999). RFC2616 Hypertext Transfer Protocol – HTTP/1.1. The Internet Engineering Task Force (IETF), June 1999. Available online: http://www.ietf. org/rfc/rfc2616.txt. [Downloaded: August 29, 2003]. Foster, I. and Gannon, D. (2003). The Open Grid Services Architecture Platform. The Global Grid Forum, 2003. Available online: http://www.gridforum.org/ Meetings/ggf7/drafts/draft-ggf-ogsa-platform-2.pdf. [Downloaded: June 16, 2003]. Foster, I., Kesselman, C., and Tuecke, S. (2001). The anatomy of the Grid: En- abling scalable virtual organizations. International Journal of Supercomputer Appli- cations, 15(3), 2001. Available online: http://www.globus.org/research/papers/ anatomy.pdf. [Downloaded: June 6, 2003]. Foster, I. (2002). What is the Grid? A three point checklist. July 2002. Avail- able online: http://www-fp.mcs.anl.gov/~ foster/Articles/WhatIsTheGrid. pdf. [Downloaded: April 29, 2003]. GGF (2003). The Global Grid Forum website, The Global Grid Forum, 2003. Available online: http://www.gridforum.org. [Downloaded: June 13, 2003]. Haarslev, V. and Moller, R. (2003). RACER User’s Guide and Reference Manual (Version 1.7.7), November 2003. Available online: http://www.cs.concordia.ca/ ~haarslev/racer/index.shtml. [Downloaded: January 30, 2004]. He, H. (2003). What is service-oriented architecture, September 2003. Available online: http://webservices.xml.com/pub/a/ws/2003/09/30/soa.html. [Down- loaded: September 19, 2007]. IPG (2003). What is the IPG? Information Power Grid Project, NASA, October 2003. Available online: http://www.ipg.nasa.gov/aboutipg/what.html. [Downloaded: June 11, 2003]. Jakobsen, T. (2006). Bookmarklets - Browser Power, April 2006. Available online: http://subsimple.com/bookmarklets. [Downloaded: November 12, 2007]. Jena (2007). Jena – a Semantic Web framework for java, Hewlett-Packard Laboratories, 2007. Available online: http://jena.sourceforge.net. [Downloaded: November 12, 2007]. Jonathan Cohen & Associates (2004). Knowledge management for design firms: Case studies, April 2004. Available online: http://www.jcarchitects.com/KM.html. [Downloaded: April 27, 2007]. 65
- 73. Lagoze, C., Van de Sompel, H., Nelson, M., and Warner, S. (2004). The Open Archives Initiative Protocol for Metadata Harvesting. Open Archives Initiative (OAI), October 2004. Available online: http://www.openarchives.org/OAI/ openarchivesprotocol.html. [Downloaded: May 11, 2007]. Liu, D., Peng, J., Law, K. H., Wiederhold, G., and Sriram, R. D. (2005). Composition of engineering web services with distributed data-flows and computations. Advanced Engineering Informatics, 19:25–42, 2005. Martin, D., Burstein, M., Hobbs, J., Lassila, O., McDermott, D., McIlraith, S., Narayanan, S., Paolucci, M., Parsia, B., Payne, T., Sirin, E., Srinivasan, N., and Sycara, K. (2004). OWL-S: Semantic Markup for Web Services. World Wide Web Consortium (W3C), November 2004. Available online: http://www.w3.org/ Submission/OWL-S. [Downloaded: March 15, 2007]. W3C Member Submission. Metcalfe, V. and Gierth, A. (1998). Programming UNIX Sockets in C - Frequently Asked Questions, January 1998. Available online: http://www.faqs.org/faqs/ unix-faq/socket. [Downloaded: November 24, 2007]. Mezher, T., Abdul-Malak, M. A., Ghosn, I., and Ajam, M. (2005). Knowledge man- agement in mechanical and industrial engineering consulting: A case study. Journal of Management in Engineering, 21(3):138–147, 2005. Microsoft (1996). DCOM technical overview, November 1996. Available online: http://msdn2.microsoft.com/en-us/library/ms809340. [Downloaded: March 13, 2007]. Microsoft (2003). Microsoft .NET, Microsoft Corporation, 2003. Available online: http://www.microsoft.com/net. [Downloaded: November 5, 2003]. MIT Libraries and Hewlett-Packard Company (2007). Introducing DSpace. DSpace Federation, 2007. Available online: http://dspace.org/introduction/index. html. [Downloaded: May 11, 2007]. Mozilla (2007). Mozilla firefox home page, Mozilla Corporation, 2007. Available online: http://www.mozilla.com. [Downloaded: August 22, 2007]. Nardi, D., Brachman, R. J., Baader, F., Nutt, W., Donini, F. M., Sattler, U., Calvanese, D., Molitor, R., De Giacomo, G., Kusters, R., Wolter, F., McGuinness, D. L., Patel- Schneider, P. F., Moller, R., Haarslev, V., Horrocks, I., Borgida, A., Welty, C., Franconi, A. R. E., Lenzerini, M., and Rosati, R. (2003). The Description Logic Handbook: Theory, Implementation and Applications. Cambridge University Press, Cambridge, U.K., 2003. ISBN 0-521-78176-0. NIST (1999). JAMA: Java Matrix Package. National Institute of Standards and Technology, 1999. Available online: http://math.nist.gov/javanumerics/jama. Nonaka, I. and Takeuchi, H. (1995). The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation. Oxford University Press, New York, U.S.A., 1995. ISBN 0-19-509269-4. 66
- 74. Nottingham, M. and Sayre, R. (2005). The Atom Syndication Format. The Internet Engineering Task Force (IETF), December 2005. Available online: http://www. ietf.org/rfc/rfc4287. [Downloaded: May 8, 2007]. OASIS (2002). Universal Description, Discovery & Integration (UDDI) Specification Version 2. Organization for the Advancement of Structured Information Stan- dards (OASIS) Consortium, 2002. Available online: http://www.oasis-open.org/ committees/uddi-spec/tcspecs.shtml#uddiv2. OMG (2005). The Common Object Request Broker Architecture: Frequently asked questions, 2005. Available online: http://www.omg.org/gettingstarted/ corbafaq.htm. [Downloaded: March 13, 2007]. OWL–S (2003). OWL-S: Semantic markup for Web Services. Technical report, The OWL Services Coalition, November 2003. Available online: http://www.daml.org/ services/owl-s/1.0/owl-s.pdf. [Downloaded: April 30, 2004]. Palme, J., Hopmann, A., and Shelness, N. (1999). RFC2557 Multipurpose Internet Mail Extension (MIME) Encapsulation of Aggregate Documents, such as HTML (MHTML). The Internet Engineering Task Force (IETF), March 1999. Available online: http://tools.ietf.org/html/rfc2557. [Downloaded: November 8, 2007]. Palmer, S. B. (2002). RDF in HTML: Approaches, June 2002. Available online: http://infomesh.net/2002/rdfinhtml. [Downloaded: March 14, 2007]. Paolucci, M., Kawamura, T., Payne, T. R., and Sycara, K. (2002). Semantic match- ing of web services capabilities. In Proceedings of the First International Seman- tic Web Conference (ISWC2002), pages 333–347, Sardinia, Italy, 2002. Available online: http://www-2.cs.cmu.edu/~ softagents/papers/ISWC2002.pdf. [Down- loaded: October 31, 2003]. Peng, J. and Law, K. H. (2004). Building finite element analysis programs in distributed services environment. Computers and Structures, 82:1813–1833, 2004. Pollock, N. (2001). Knowledge management: Next step to competitive advan- tage. Journal of the Defense Systems Management College, September-October 2001. Available online: http://www.providersedge.com/docs/km_articles/KM_ -_Next_Step_to_Competitive_Advantage.pdf. [Downloaded: April 5, 2007]. Prot´g´ (2005). The Prot´g´ Ontology Editor and Knowledge Acquisition System. Stan- e e e e ford Medical Informatics Department, Stanford University, Stanford, CA, U.S.A., 2005. Available online: http://protege.stanford.edu. [Downloaded: March 20, 2006]. Quintas, P. (2005). The nature and dimensions of knowledge management. In Anumba, C. J., Egbu, C., and Carrillo, P., editors, Knowledge Management in Construction. Blackwell Publishing, Oxford, U.K., 2005. ISBN 1-40-512972-7. Reddy, R., Ager, T., Chellappa, R., Croft, W. B., Davis-Brown, B., Mendel, J. M., and Shamos, M. I. (1999). WTEC Panel report on digital information organization in Japan. Technical report, Loyola College in Maryland, 1999. Available online: http://www.wtec.org/loyola/digilibs/d_01.htm. [Downloaded: September 11, 2006]. 67
- 75. Rezgui, Y. (2006). Ontology-centered knowledge management using information re- trieval techniques. Journal of Computing in Civil Engineering, 20(4):261–270, July 2006. Roman, D., Keller, U., Lausen, H., de Bruijn, J., Lara, R., Stollberg, M., Polleres, A., Feier, C., Bussler, C., and Fensel, D. (2005). Web ser- vice modeling ontology. Applied Ontology, 1(1):77–106, 2005. Available online: http://iospress.metapress.com/openurl.asp?genre=article&issn= 1570-5838&volume=1&issue=1&spage=77. [Downloaded: March 15, 2007]. RSS Advisory Board (2006). RSS 2.0 Specification. RSS Advisory Board, August 2006. Available online: http://www.rssboard.org/rss-specification. [Downloaded: May 8, 2007]. Sheehan, T., Poole, D., Lyttle, I., and Egbu, C. O. (2005). Strategies and business case for knowledge management. In Anumba, C. J., Egbu, C., and Carrillo, P., editors, Knowledge Management in Construction. Blackwell Publishing, Oxford, U.K., 2005. ISBN 1-40-512972-7. Sifry, D. (2007). The state of the Live Web, April 2007, Technorati, Inc., April 2007. Available online: http://www.sifry.com/alerts/archives/000493.html. [Down- loaded: May 8, 2007]. Sirin, E. (2004). OWL-S API, Maryland Information and Network Dynamics Lab Semantic Web Agents (MINDSWAP) Project, Institute for Advanced Computer Studies, University of Maryland, 2004. Available online: http://www.mindswap. org/2004/owl-s/api. [Downloaded: June 29, 2004]. Sun Microsystems, Inc. (2007). Javamail api, Sun Microsystems, Inc., 2007. Avail- able online: http://java.sun.com/products/javamail. [Downloaded: November 8, 2007]. Sycara, K., Paolucci, M., Ankolekar, A., and Srinivasan, N. (2003). Automated discov- ery, interaction and composition of Semantic Web Services. Web Semantics: Science, Services and Agents on the World Wide Web, 1(1):27–46, December 2003. Avail- able online: http://dx.doi.org/10.1016/j.websem.2003.07.002. [Downloaded: March 15, 2007]. Trott, B. and Trott, M. (2002). TrackBack Technical Specification, October 2002. Available online: http://www.movabletype.org/docs/mttrackback.html. [Down- loaded: May 8, 2007]. Turban, E. and Aronson, J. (2001). Decision Support Systems and Intelligent Systems. Prentice Hall, London, U.K., 2001. Vacharasintopchai, T. (2005). KMITL/SUT: Reinforced Concrete Design Work- sheets. CE Resources Weblog, October 2005. Available online: http://ce-res. blogspot.com/2005/10/kmitlsut-reinforced-concrete-design.html. [Down- loaded: March 14, 2007]. Vacharasintopchai, T., Barry, W., Wuwongse, V., and Kanok-Nukulchai, W. (2007a). Semantic Web Services framework for computational mechanics. Journal of Com- puting in Civil Engineering, 21(2):65–77, March-April 2007. 68
- 76. Vacharasintopchai, T., Wuwongse, V., and Chalermsook, K. (2007b). Weblog, Digital Library, and Semantic Web Services approach to computer-aided engineering design. In Proceedings of the 8th Asia Pacific Conference on Industrial Engineering and Management System (APIEMS2007), Kaohsiung, Taiwan, R.O.C., December 9-13, 2007. van Engelen, R. A. (2003). Pushing the SOAP envelope with Web Services for scientific computing. In Proceedings of the International Conference on Web Services (ICWS) 2003, Las Vegas, Nevada, USA, June 2003. Available online: http://www.cs.fsu. edu/~engelen/icws03.pdf. [Downloaded: September 3, 2003]. W3C (1999a). HyperText Markup Language (HTML) 4.01 Specification. World Wide Web Consortium (W3C), December 1999. Available online: http: //www.w3.org/TR/html4. W3C (1999b). Resource Description Framework (RDF) Model and Syntax Specifi- cation. World Wide Web Consortium (W3C), February 1999. Available online: http://www.w3.org/TR/1999/REC-rdf-syntax-19990222. [Downloaded: Septem- ber 19, 2003]. W3C (2000). Simple Object Access Protocol (SOAP) 1.1. World Wide Web Consortium (W3C), 2000. Available online: http://www.w3.org/TR/SOAP. W3C (2001). Web Service Definition Language (WSDL) 1.1. World Wide Web Con- sortium (W3C), 2001. Available online: http://www.w3.org/TR/wsdl. W3C (2003). RDF Primer. World Wide Web Consortium (W3C), September 2003. Available online: http://www.w3.org/TR/2003/WD-rdf-primer-20030905. [Downloaded: September 22, 2003]. W3C Working Draft. W3C (2004a). OWL Web Ontology Language Overview. World Wide Web Consortium (W3C), February 2004. Available online: http://www.w3.org/TR/owl-features/. [Downloaded: March 15, 2004]. W3C Recommendation. W3C (2004b). OWL Web Ontology Language: Semantics and Abstract Syntax. World Wide Web Consortium (W3C), February 2004. Available online: http://www.w3. org/TR/owl-semantics. [Downloaded: March 16, 2007]. W3C (2004c). RDF Semantics. World Wide Web Consortium (W3C), February 2004. Available online: http://www.w3.org/TR/rdf-mt. [Downloaded: March 14, 2007]. W3C (2004d). Web Services Architecture. World Wide Web Consortium (W3C), February 2004. Available online: http://www.w3.org/TR/ws-arch. [Downloaded: March 13, 2007]. W3C Working Group Note. Wielemaker, J., Schreiber, G., and Wielinga, B. (2003). Prolog-based infrastructure for RDF: Performance and scalability. In Fensel, D., Sycara, K., and Mylopoulos, J., editors, Proceedings of the 2nd International Semantic Web Conference (ISWC’03), pages 644–658, Sanibel Island, Florida, USA, October 20-23, 2003. Available online: http://hcs.science.uva.nl/projects/SWI-Prolog/articles/iswc-03. pdf. [Downloaded: April 25, 2006]. 69
- 77. Wikipedia (2006a). General packet radio service, Wikipedia, The Free Encyclopedia, April 13, 2006. Available online: http://en.wikipedia.org/wiki/GPRS. [Down- loaded: April 30, 2006]. Wikipedia (2006b). Wi-fi, Wikipedia, The Free Encyclopedia, April 30, 2006. Available online: http://en.wikipedia.org/wiki/WiFi. [Downloaded: April 30, 2006]. Wikipedia (2007a). Application Programming Interface. Wikipedia, The Free En- cyclopedia, March 2007. Available online: http://en.wikipedia.org/wiki/API. [Downloaded: March 14, 2007]. Wikipedia (2007b). Blog. Wikipedia, The Free Encyclopedia, May 2007. Available online: http://en.wikipedia.org/wiki/Blog. [Downloaded: May 2, 2007]. Wikipedia (2007c). Blogosphere. Wikipedia, The Free Encyclopedia, April 2007. Avail- able online: http://en.wikipedia.org/wiki/Blogosphere. [Downloaded: May 4, 2007]. Wikipedia (2007d). Digital Library. Wikipedia, The Free Encyclopedia, April 2007. Available online: http://en.wikipedia.org/wiki/Digital_library. [Downloaded: May 2, 2007]. Wikipedia (2007e). Web Feed. Wikipedia, The Free Encyclopedia, May 2007. Available online: http://en.wikipedia.org/wiki/Web_feed. [Downloaded: May 2, 2007]. Witten, I. H. and Bainbridge, D. (2003). How to Build a Digital Library. Morgan Kaufmann Publishers, San Francisco, CA, U.S.A., 2003. ISBN 1-55-860790-0. Witten, I. H., Boddie, S., and Thompson, J. (2006). Greenstone Digital Library User’s Guide. University of Waikato, New Zealand, March 2006. WordPress (2007). Wordpress homepage, Automattic, Inc., 2007. Available online: http://wordpress.com. [Downloaded: May 5, 2007]. WSDL4J (2006). Web Services Description Language for Java (WSDL4J) toolkit, November 2006. Available online: http://sourceforge.net/projects/wsdl4j. [Downloaded: November 19, 2007]. 70