Exact Inference in Bayesian Networks using MapReduce__HadoopSummit2010
14 likes4,499 views

The document discusses exact inference in Bayesian networks using MapReduce, highlighting the importance of Bayesian networks in various fields and applications. It details Cloudera's role in providing an industry-standard platform for processing large datasets and presents the technical aspects of implementing Bayesian network inference with MapReduce, including parallel processing and performance considerations. The conclusions emphasize the capability of Hadoop in transforming complex probabilistic inference tasks into manageable computations.



















Exact Inference in Bayesian Networks using MapReduce__HadoopSummit2010
- 1. Exact Inference in Bayesian Networks using MapReduceAlex KozlovCloudera, Inc.
- 2. About MeAbout ClouderaBayesian (Probabilistic) NetworksBN Inference 101CPCS NetworkWhy BN InferenceInference with MRResultsConclusions2Session Agenda
- 3. Worked on BN Inference in 1995-1998 (for Ph.D.)Published the fastest implementation at the timeWorked on DM/BI field since thenRecently joined Cloudera, Inc.Started looking at how to solve world’s hardest problems3About Me
- 4. Founded in the summer 2008Cloudera helps organizations profit from all of their data. We deliver the industry-standard platform which consolidates, stores and processes any kind of data, from any source, at scale. We make it possible to do more powerful analysis of more kinds of data, at scale, than ever before. With Cloudera, you get better insight into their customers, partners, vendors and businesses.Cloudera’s platform is built on the popular open source Apache Hadoop project. We deliver the innovative work of a global community of contributors in a package that makes it easy for anyone to put the power of Google, Facebook and Yahoo! to work on their own problems.4About Cloudera
- 5. NodesEdgesProbabilities5Bayesian NetworksBayes, Thomas (1763)An essay towards solving a problem in the doctrine of chances, published posthumously by his friendPhilosophical Transactions of the Royal Society of London, 53:370-418
- 6. Computational biology and bioinformatics (gene regulatory networks, protein structure, gene expression analysis)MedicineDocument classification, information retrievalImage processingData fusionGamingLawOn-line advertising!6Applications
- 7. 7A Simple BN NetworkTFRainRainTF0.40.6F0.20.80.10.9TSprinklerSprinkler, RainTF0.010.99F, F0.80.2F, TWet Driveway0.9 0.1T, F0.990.01T, TPr(Rain | Wet Driveway)Pr(Sprinkler Broken | !Wet Driveway & !Rain)
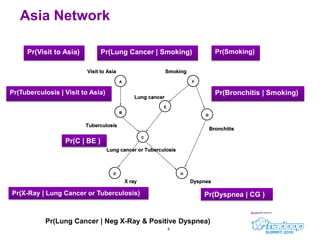
- 8. 8Asia NetworkPr(Visit to Asia)Pr(Smoking)Pr(Lung Cancer | Smoking)Pr(Tuberculosis | Visit to Asia)Pr(Bronchitis | Smoking)Pr(C | BE )Pr(X-Ray | Lung Cancer or Tuberculosis)Pr(Dyspnea | CG )Pr(Lung Cancer | Neg X-Ray & Positive Dyspnea)
- 9. JPD = <product of all probabilities and conditional probabilities in the network> = Pr(A, B, …, H)PAB = SELECT A, B, SUM(PROB) FROM JPD GROUP BY A, B;PB = SELECT B, SUM(PROB) FROM PAB GROUP BY A;Pr(A|B) = Pr(A,B)/Pr(B) – Bayes’ ruleCPCS is 422 nodes, a table of at least 2422 rows!9BN Inference 101 (in Hive)
- 10. 10Junction TreePr(E | F )Pr(Tuberculosis | Visit to Asia)Pr(G | F )ABEFGPr(Visit to Asia)Pr(F)BPr(C | BE )EGPr(H | CG )BCECECEGHCPr(Lung Cancer | Dyspnea) =Pr(E|H)CDPr(D| C)
- 11. 11CPCS Networks422 nodes14 nodes describe diseases33 risk factors375 various findings related to diseases
- 12. 12CPCS Networks
- 13. Choose the right tool for the right job!BN is an abstraction for reasoning and decision making
- 14. Easy to incorporate human insight and intuitions
- 15. Very general, no specific ‘label’ node
- 16. Easy to do ‘what-if’, strength of influence, value of information, analysis
- 17. Immune to Gaussian assumptionsIt’s all just a joint probability distribution13Why Bayesian Network Inference?
- 18. Map & Reduces14B1C1E1KeysMapB1C1E2A1B1B1ReduceB1C2E1A2B1B1C2E2A1B2B2C1E1∑ Pr(B1| A) x ∑ Pr(D| C1)B2B2C1E2A2B2B2C2E1B2C2E2Pr(C| BE) x ∑ Pr(B1| A) x ∑ Pr(D| C1)Aggregation 2 (x)B1C1E1B1C1E2C1D1B1C2E1C1Aggregation 1 (+)C2D1B1C2E2C1D2B2C1E1B2C1E2C2BCEC2D2B2C2E1B2C2E2
- 19. for each clique in depth-first order:MAP:Sum over the variables to get ‘clique message’ (requires state, custom partitioner and input format)Emit factors for the next cliqueREDUCE:Multiply the factors from all childrenInclude probabilities assigned to the cliqueForm the new clique valuesthe MAP is done over all child cliques15MapReduce Implementation
- 20. Topological parallelism: compute branches C2 and C4 in parallel
- 21. Clique parallelism: divide computation of each clique into maps/reducers
- 22. Fall back into optimal factoring if a corresponding subtree is small
- 23. Combine multiple phases together
- 24. Reduce replication level16Cliques, Trees, and ParallelismC6C5C4C3C2C1Cliques may be larger than they appear!
- 25. CPCS:The 360-node subnet has the largest ‘clique’ of 11,739,896 floats (fits into 2GB)The full 422-node version (absent, mild, moderate, severe)3,377,699,720,527,872 floats (or 12 PB of storage, but do not need it for all queries)In most cases do not need to do inference on the full network17CPCS Inference
- 26. 1‘used an SGI Origin 2000 machine with sixteen MIPS R10000 processors (195 MHz clock speed)’ in 19972Macbook Pro 4 GB DDR3 2.53 GHz310 node Linux Xeon cluster 24 GB quad 2-core18Results
- 27. Exact probabilistic inference is finally in sight for the full 422 node CPCS networkHadoop helps to solve the world’s hardest problemsWhat you should know after this talkBN is a DAG and represents a joint probability distribution (JPD)Can compute conditional probabilities by multiplying and summing JPDFor large networks, this may be PBytes of intermediate data, but it’s MR19Conclusions
- 29. BACKUP21
- 30. Conditioning nodes (evidence) – do not need to be summedBare child nodes’ values sum to one (barren node) – can be dropped from the network22Optimizing BN Inference 101Noisy-OR (conditional independence of parents)Context specific independence (based on the specific value of one of the parents)TF0.010.99FF0.80.2FTWet grass0.9 0.1TF0.990.01TT
- 31. 23GeNIe package
- 32. No updates – have to compute clique potentials from all children and assigned probabilitiesTree structure The key encodes full set of variable values (LongWritable or composite)The value encodes partial sums (proportional to probabilities)No need for TotalOrderPartitioning (we know the key distribution)Need custom Partitioner and WritableComparator (next slide)Need to do the aggregation in the Mapper (sum, next slide)24MapReduce Implementation
- 33. Build on top of old 1997 C program with a few modificationsAn interactive command line program for interactive analysisEstimates running time from optimal factory plan andEither executes it locallyShips a jar to a Hadoop cluster to execute25Current implementation
Editor's Notes
- #2: AbstractProbabilistic inference is a way of obtaining values of unobservable variables out of incomplete data. Probabilistic inference is used in robotics, medical diagnostic, image recognition, finance and other fields. One of the tools for inference and a way to represent knowledge is 'Bayesian Network', where nodes represent variables and edges represent probabilistic dependencies between variables. The advantage of exact probabilistic inference using BN is that it does not involve the traditional 'Gaussian distribution' assumptions and the results are immune to Taleb's distributions, or distributions with a high probability of outliers.A typical application of probabilistic inference is to infer the probability of one or several dependent variables, like the probability that a person has a certain disease, given other observations, like presence of abdominal pain. In exact probabilistic inference, variables are clustered in groups, called cliques, and probabilistic inference can be carried out by manipulating more or less complex data structures on top of the cliques, which leads to high computational and space complexity of the inference: the data structures can become very complex and large. The advantage: one can encode arbitrarily complex distributions and dependencies.While a lot of research has been devoted to devising schemes to approximate the solution, Hadoop allows performing exact inference on the whole network. We present an approach for performing large-scale probabilistic inference in probabilistic networks in a Hadoop cluster. Probabilistic inference is reduced to a number of MR jobs over the data structures representing clique potentials. One of the applications is the CPCS BN, one of the biggest models created at Stanford Medical Informatics Center (now The Stanford Center for Biomedical Informatics Research) in 1994, never solved exactly. In this specific network containing 422 nodes representing states of different variables, 14 nodes describe diseases, 33 nodes describe history and risk factors, and the remaining 375 nodes describe various findings related to the diseases.
- #3: Here is what I am going to talk about1. I will not be able to delve into every detail and the implementation is not complete2. BN Inference is not a Cloudera product today, therefore it’s not a product announcement!3. This is not a research paper either!Promise – no formulas or complicated mathI promise there will be at least one photo and an SQL statementCPCS -- (Computer-based Patient Case Study) model [Pradhanet al.1994]Pradhanet al.1994 Malcolm Pradhan, Gregory Provan, Blackford Middleton, and Max Henrion. Knowledge engineering for large belief networks. In Proceedings of the Tenth Annual Conference on Uncertainty in Artificial Intelligence (UAI-94), pages 484-490, San Francisco, CA, 1994. Morgan Kaufmann Publishers.
- #4: I did probabilistic inference since 1994!There is a resurgence of interest in parallel computations, see Yinglong Xia and Viktor K. Prasanna2008-2010 papers
- #5: Interest in Hadoop is surging…Hadoop is: ‘A scalable fault-tolerant distributed system for data storage and processing’Hadoop History2002-2004: Doug Cutting and Mike Cafarella started working on Nutch2003-2004: Google publishes GFS and MapReduce papers 2004: Cutting adds DFS & MapReduce support to Nutch2006: Yahoo! hires Cutting, Hadoop spins out of Nutch2007: NY Times converts 4TB of archives over 100 EC2s2008: Web-scale deployments at Y!, Facebook, Last.fmApril 2008: Yahoo does fastest sort of a TB, 3.5mins over 910 nodesMay 2009:Yahoo does fastest sort of a TB, 62secs over 1460 nodesYahoo sorts a PB in 16.25hours over 3658 nodesJune 2009, Oct 2009:Hadoop Summit, Hadoop WorldSeptember 2009: Doug Cutting joins Cloudera
- #6: A gentle introduction to BNsA Bayesian network, belief network or directed acyclic graphical model is a probabilistic graphical model that represents a set of random variables and their conditional independencies via a directed acyclic graph (DAG)Formally, Bayesian networks are directed acyclic graphs whose nodes represent random variables in the Bayesian sense: they may be observable quantities, latent variables, unknown parameters or hypotheses. Edges represent conditional dependencies; nodes which are not connected represent variables which are conditionally independent of each other. Each node is associated with a probability function that takes as input a particular set of values for the node's parent variables and gives the probability of the variable represented by the node. For example, if the parents are m Boolean variables then the probability function could be represented by a table of 2m entries, one entry for each of the 2m possible combinations of its parents being true or false.Efficient algorithms exist that perform inference and learning in Bayesian networks. Bayesian networks that model infinite sequences of variables (e.g. speech signals or protein sequences) are called markov chains. Generalizations of Bayesian networks that can represent and solve decision problems under uncertainty are called influence diagrams.Bayes never invented the BNs, even didn’t have a publication on probabilities during his lifetime
- #7: As you can notice, BNs are used anywhere were data are a bit more complex (‘unstructured data’ in RDBMS terms)Like Hadoop!Naïve Bayes is the most famous incarnation of a BN (conditional independence of attribute variables given the class label)Let’s look at the examples of BN
- #8: A reasoning tool: People think they are good with probabilitiesOne advantage of Bayesian networks is that it is intuitively easier for a human to understand (a sparse set of) direct dependencies and local distributions than complete joint distribution.Wind blows – trees move?May be extended to ‘causal networks’
- #9: A more complex networkVisit to Asia – predisposing factorsTuberculosis, Lung Cancer, Bronchitis – diseasesX-Ray, Dyspnea – findingsLungCancer or Tuberculosis – hidden node
- #10: CS 221 at StanfordBN Inference in HiveFor example Pr(Lung Cancer|Dyspnea)Can some intelligently: see optimal factoring approach in my Ph.D. thesisThe largest clique size – max width in CSP terms (did I mention it’s NP-hard?)Approximate and sampling algorithms existFormally, it can be represented as `variable elimination` or ‘belief propagation` up and down a join treeLet’s have a look
- #11: Junction tree: Each probability is assigned to one of the cliques in the junction treeWhen we sum, the results is a message (M)When we multiply, the result is a (R)Already looks like MapReduce! MapReduce existed long before it was invented.But before we delve into MR implementation, lets talk about CPCS (Comuter-based Patient Case Study) networkDid I mention BN Inference is NP-hard? It can be mapped to a CSP problem
- #12: A typical query is Pr(diseases|finding, risk factors)One big mess!
- #13: A typical query is Pr(diseases| risk factors, findings)Interactive analysisWhat-if analysisStrength of InfluenceSensitivity AnalysisValue of informationValue of additional evidence (tests)Cost of not taking a specific decisionBy now you are wondering: why inference?
- #14: Let’s have a break and discuss why you should use BN InferenceIf the current tools work for you, continue using themIf you run a company that underestimates risk and looses $1T as a result, you probably need to innovate: There should be some technology that can handle itNow, let’s delve into MapReduce implementation and results
- #15: That’s a bit more complicated slide, but bear with meMap: summation, generate multiple keys/records per 1 original recordReduce: multiplicationThe key encodes full set of variable values (LongWritable or composite)The value encodes partial sums (proportional to probabilities)No need for TotalOrderPartitioning (we know the key distribution)Need custom Partitioner and WritableComparator (next slide)Need to do an aggregation in the Mapper (sum, next slide)By arranging the node order in the cliques we can optimize data localitySorting helps!
- #16: Preserves data locality by specifying node order in a certain way (need for a custom WritableComparator and Partitioner)
- #17: The computation is C6 -> C5 -> C4 -> C3 -> C2 -> C1Topological parallelism is usually limitedMost of the work is done in reducers (indices remapping, summation)Let’s look at the actual clique sizes in CPCS!
- #18: Doing inference on the ‘full’ network has only an academic inferenceHowever, to understand how the simplifications in the network affect results, we need to be able to perform exact inferenceWhat is the scoop?
- #19: The first three are for the ‘full’ propagation up and down the treeRandom A, B are randomly generated BNs used for the 1995 paperCpcs360 is a subset of cpcs422 used for interactive analysisCpcs422 on a 5-node subquery
- #20: Doing inference on the ‘full’ network has only an academic inferenceHowever, to understand how the simplifications in the network affect results, we need to be able to perform exact inference
- #21: git@github.com:alexvk/BN-Inference.gitGoals:Inference is an interesting applicationWe have an interactive program to perform inferenceAll questions to Cloudera, Inc.Need:Implementors (to help)Large cluster (to have 10s of PB of storage)
- #22: Doing inference on the ‘full’ network has only an academic inferenceHowever, to understand how the simplifications in the network affect results, we need to be able to perform exact inference
- #23: Summation: Pure MR+ (M-R-M-R-...-M-R) jobNormalization: Requires update (or a copy) operationEach key can encode the set of values (odometer)No need for PartialOrder (we know the key distribution)Can optimize data locality
- #24: Many tools for interactive analysis:-Sensitivity analysis-Strength of InfluenceValue of Information-Hybrid networks (with some continuous parents)
- #25: As opposed to traditional MR, aggregation is made in the map phase (summation)
- #26: Very few modifications:* In file included from utils.c:12:/usr/lib/gcc/x86_64-redhat-linux/4.1.2/include/varargs.h:4:2: error: #error "GCC no longer implements <varargs.h>."/usr/lib/gcc/x86_64-redhat-linux/4.1.2/include/varargs.h:5:2: error: #error "Revise your code to use <stdarg.h>."* Convert ints to longsImplement MR logic and code generation