






A hierarchical neural autoencoder for paragraphs and documents
- 1. A Hierarchical Neural Autoencoder for Paragraphs and Documents Jiwei Li, Minh-Thang Luong and Dan Jurafsky ACL 2015
- 2. Introduction ● Generating the coherent text (document/paragraph) ● Using the 2 stacked LSTM per encoder/decoder ○ Lower: word sequence is compressed into one vector ○ Upper: sentence sequence is compressed into one vector ● Evaluating the coherence of the output from autoencoder.
- 3. Paragraph autoencoder, Model 1: Standard LSTM ● Input and output is the same D = {s1 , s2 , …, sND , endD } ● each s = {w1 , w2 , …, wNs } ○ ND, Ns means the each length. ● e represents the embedding ● Standard: all sentences concatenated into one sequence.
- 4. Model 2: Hierarchical LSTM ● Encoder ● Decoder (I think the lower one is LSTMword ) ● After generating </s> at each sentence, last hidden state is used as a input of the sentence decoder.
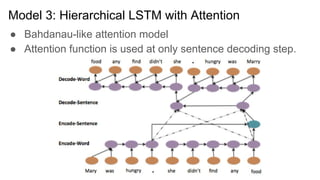
- 5. Model 3: Hierarchical LSTM with Attention ● Bahdanau-like attention model ● Attention function is used at only sentence decoding step.
- 6. Experiment ● LSTM: 4-layer (in total), 1000 dim ● SGD: Learning rate = 0.1, 7 epoch, batch_size = 32 doc. They used crawled documents ● Hotel Review (from TripAdvisor’s page) ○ Train: 340,000 reviews (included at most 250 words in each reviews) ○ Test: 40,000 reviews ● Wikipedia (it is not domain-specific data) ○ Train: 500,000 paragraphs ○ Test: 50,000 paragraphs
- 7. Evaluation ● ROUGE, BLEU (it doesn’t use the log function) ● Following L-value (Lapata and Barzily 2005) “Based on the assumption that human-generated texts are coherent.” a. Make the feature vector consisting of verbs and nouns b. Align the input and output sentences based on F1 score using this vector. ■ ROUGE and BLEU is used as the precision and recall value c. Calculate the L-value i denotes the position index, i’ denotes the position index at input side
- 8. Result and Conclusion ● Hotel Review task is easier than Wikipedia task ○ Open domain documents are difficult to generate ? ○ The sentences on Wikipedia are written in the fixed format ? ● Proposed method is useful to auto-encode the document.