Active learning with efficient feature weighting methods for improving data quality and classification accuracy
3 likes1,716 views

社内輪読会で紹介した「Active learning with efficient feature weighting methods for improving data quality and classification accuracy」の資料



















Active learning with efficient feature weighting methods for improving data quality and classification accuracy
- 1. Active Learning with Efficient Feature Weighting Methods for Improving Data Quality and Classification Accuracy Justin Martineau1, Lu Chen, Doreen Cheng, and Amit Sheth ACL2014 id:skozawa 論文輪読会
- 2. Supervised Algorithm and Data ● 教師あり学習にはアノテーションデータが必須 ● アノテーションデータの収集方法は2種類 1. 少数の専門家 ○ 時間がかかる、高コスト ○ 高品質なデータ 2. クラウドソーシング (eg. Amazon’s Mechanical Turk) ○ 時間が早い、低コスト ○ 低品質なデータ ■ 分類モデルの性能低下 大規模だが、低品質なアノテーションデータが与えられたとき、 いかにしてデータの品質を改善し、分類器の性能を向上させるか
- 3. Error Correction with Active Learning ● データ改善のアプローチ ○ 再アノテーション ■ コストが高い ● アノテーションの軽減 ○ 最も誤っていそうな事例を選択するアルゴリズムが必要 ○ 誤り事例の選択と再アノテーションを繰り返し実行 ● この戦略は能動学習と類似
- 4. Active Learning ● 能動学習 ○ 教師データを作成する際に最大の効果を発揮するように教師とす るデータを選択する方法についての研究分野 ● 少量のラベル付きデータを利用して、大量のラベルなしデータ の中からアノテーションすべきデータを見つける ● アノテーションすべきデータの選択には 主に2種類の戦略がある 1. サンプリングの乏しい領域を選択 2. モデルに対する影響が大きいデータを選択
- 5. Error Correction with Active Learning ● データ改善のアプローチ ○ 再アノテーション ■ コストが高い ● アノテーションの軽減 ○ 最も誤っていそうな事例を選択するアルゴリズムが必要 ○ 誤り事例の選択と再アノテーションを繰り返し実行 ● この戦略は能動学習と類似 ○ 少ない学習データを利用して高精度な分類器を学習 ○ 少数のアノテーションデータを利用し、大量の非アノテーションデー タから最も情報量の多い事例を選択 繰り返し、かつ、相互にアノテーションエラーを 訂正するために能動学習のアイデアを利用
- 6. Proposed Method ● 効率的、かつ、効果的に誤っていそうな事例を 見つけることが重要 ○ 事例を分類し、信頼性順にランキング ○ 信頼性は高いが、事前のラベルと異なる事例は誤りである可能性 が高い ● 非線形分布拡散アルゴリズムを提案 ○ Delta IDFを利用し特徴を重み付け ○ Delta IDFのスコア分布を利用し識別的な特徴を認識 ● Twitterの感情分析 ○ より高精度な感情分類器の学習 ○ より低いコストでのアノテーション品質の向上
- 7. Related Works 1. ノイズ許容 (Noise Tolerance) ○ 誤りラベルが原因の過学習を避けるように学習アルゴリズムを改善 し、ノイズを許容可能な分類器を構築 ○ デメリット:学習するアルゴリズムに依存 2. ノイズ除去 (Noise Elimination) ○ 分類器を構築する前処理としてデータセットから誤りラベル を識別し削除する ○ デメリット ■ 曖昧な事例の削除 ■ ノイズが多い場合には十分なデータが残らない 3. ノイズ訂正 (Noise Correction) ○ 専門家が介入するアプローチとしないアプローチ ○ 自動訂正は誤った訂正をすると新たなノイズを生む
- 8. Active Learning for Data Cleaning ● 専門家によるラベル訂正 ○ コミュニティで再利用されうる高品質なデータの獲得 ○ 高コストだが、価値はある ● Active Label Correction (Rebbapragada et. al (2012)) ○ 専門家に少量の誤っていそうなデータを繰り返し提示 ○ 提案手法は同様のフレームワークを利用 ● 伝統的な能動学習との相違点 ○ 低品質なラベルを持つデータ ○ 従来はラベルなし ● ラベルの違いを利用 ○ 付与されている低品質なラベル ○ 低品質なデータに基づき学習器を利用して付与したラベル
- 9. Active Learning Framework for Label Correction D = {(x1, y1), … , (xn, yn)} : 誤ったラベルを含むデータ xi: 事例, yi: ラベル {-1, +1} ● 目的 ○ 高品質なデータDの取得 ○ 高精度な分類器Cの学習 ● 定義 ○ T:対象のデータ ○ S:再アノテーション対象の データ集合 ○ Sr:再アノテーション済み のデータ集合 ^
- 10. Active Learning Framework for Label Correction ● アルゴリズム 1. データTを利用し分類器Cを構築 2. 分類器Cを利用しTから誤っていそうな事例を m個(S)取得 3. 専門家が事例(S-(Sr∧S))を 再アノテーション 4. データTを更新 ● 上記を繰り返し実行 ○ 1,2は交差検定 ○ アノテーションに対する 報酬が小さくなったら終了
- 11. Feature Weighting Methods ● 誤っていそうな事例を発見する分類器Cの構築が能動学習にお いて最も重要 (1) 最もありそうな誤りを効率的に発見 ● 高精度に事例を予測し、予測の信頼度に基づきランキング (2) 短い学習時間 ■ 削減した時間はより多くの誤りを訂正するのに利用 ● 特徴の重み付け手法 ○ 識別的な特徴の重みを大きくする ○ 計算量が少ない ● 非線形分布拡散アルゴリズムを提案 ○ Delta-IDFを利用
- 12. Delta IDF Weigting Scheme ● Delta IDF ○ TFやTF.IDFとは異なる ○ 正例と負例を別のコーパスとして扱う ○ 1つのクラスに含まれるほど、単語の重みは大きくなる ■ 特定のクラスに関連しやすい単語の重要性が大きくなる ■ 他のクラスから識別するのに効果的な特徴 ● 単語 j のDelta IDF ● データの不均衡への対処 ○ Delta IDFを計算する前に多数派のクラスのサンプルを減らす ● 単語 j の重み (負例数) (単語jを含む負例数) (単語jを含む正例数) (正例数)
- 13. A Non-linear Distribution Spreading Algorithm ● 複数クラスにわたる素性の重み(Delta IDF)分布を利用 ○ 複数の感情カテゴリ(funny, happy, sad, exciting, boring, etc.) ● クラスuに属する単語 j の拡散スコア ○ L: クラスの集合、 |L|: クラス数 ● 拡散スコアが高い クラスuとそれ以外のクラスのDelta IDFの差異 ○ あるクラスに識別的な単語のスコアが高い クラス数 - 1 クラスu,単語jに対するDelta IDF ×
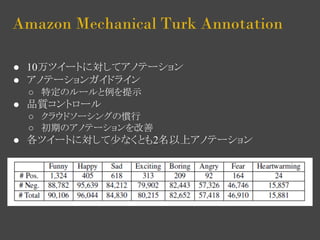
- 14. Experiments ● 提案手法を評価 ○ 感情分類モデルの有効性 ○ 手法の計算時間 ○ アノテーションの品質の改善 ● タスク:感情分析 ○ 8の感情(funny, happy, sad, exciting, boring, angry, fear, heartwarming) ○ アノテーションは簡単ではない i. 複数の感情がアノテーションされる ii. 感情表現は分かりづらく、曖昧なため、見落としやすい iii. データのバランスが悪い ● 少数の感情は見落とされやすい
- 15. Experimental Setup ● テレビ番組や映画に関するツイートデータを利用 ○ テレビ番組や映画をクエリとして20億ツイートを収集 ○ よく言及される60のテレビ番組や映画の10万ツイートを選択 ■ 各番組に対しては同じツイート数 ● データ生成 ○ Amazon Mechanical Turk ○ 専門家
- 16. Amazon Mechanical Turk Annotation ● 10万ツイートに対してアノテーション ● アノテーションガイドライン ○ 特定のルールと例を提示 ● 品質コントロール ○ クラウドソーシングの慣行 ○ 初期のアノテーションを改善 ● 各ツイートに対して少なくとも2名以上アノテーション
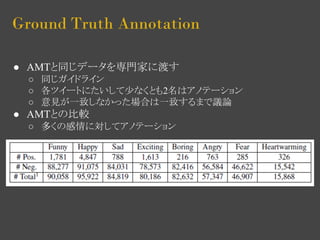
- 17. Ground Truth Annotation ● AMTと同じデータを専門家に渡す ○ 同じガイドライン ○ 各ツイートにたいして少なくとも2名はアノテーション ○ 意見が一致しなかった場合は一致するまで議論 ● AMTとの比較 ○ 多くの感情に対してアノテーション
- 18. Methods For Evaluation ● Delta-IDF ○ Delta IDF 重みベクトルとDFベクトルの内積 ● Spread ○ 分布拡散重みベクトル(s=2)とDFの内積 ● SVM-TF ○ BOW(TF)のSVM ● SVM-Delta-IDF ○ BOW(TF.Delta-IDF)のSVM ● 分類器Cとして利用 ○ トップmのツイートを選択 ○ 再アノテーションには ground truthを利用
- 19. Experimental Results (MAP/F1) ● 再アノテーション数とMAP/F値 ○ 序盤 : SVM-Delta-IDF > SVM-TF > Spread ○ 終盤 : SVM-Delta-IDF > Spread > SVM-TF
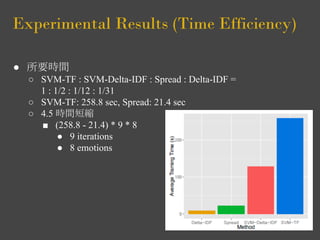
- 20. Experimental Results (Time Efficiency) ● 所要時間 ○ SVM-TF : SVM-Delta-IDF : Spread : Delta-IDF = 1 : 1/2 : 1/12 : 1/31 ○ SVM-TF: 258.8 sec, Spread: 21.4 sec ○ 4.5 時間短縮 ■ (258.8 - 21.4) * 9 * 8 ● 9 iterations ● 8 emotions
- 21. Experimenta Results (Queality) ● よい手法は少ないイテレーションで多くのラベルを修正 ● Random: ランダムに事例を選択
- 22. Conclusion ● アノテーションの品質改善手法としての能動学習を調査 ● 計算機コストが高いSVMの代わりに non-linear distribution spreading アルゴリズムを利用 ● 評価で以下を示した (1)誤りである可能性が高いデータをランキングし、 その精度は計算機コストの高いベースライン(SVM-TF)と同等 (2)SVM-TFより早く学習・実行 (3)アノテーションプロセスは分類器の性能に陽に影響を与え、データ の品質を改善