Advanced Apache Spark Meetup Spark SQL + DataFrames + Catalyst Optimizer + Data Sources API
Download as PPTX, PDF12 likes5,191 views

The document details a meetup presentation about advanced Apache Spark, focusing on Spark SQL, DataFrames, and the Catalyst optimizer, delivered by Chris Fregly from IBM. It covers the structure, functionality, and performance tuning of DataFrames and introduces custom data sources, partitioning, and optimization techniques. Additionally, it outlines upcoming meetups and future topics related to Spark technology.






















![IBM | spark.tc
Parquet Data Source
Configuration
spark.sql.parquet.filterPushdown=true
spark.sql.parquet.mergeSchema=true
spark.sql.parquet.cacheMetadata=true
spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo]
DataFrames
val gendersDF = sqlContext.read.format("parquet")
.load("file:/root/pipeline/datasets/dating/genders.parquet")
gendersDF.write.format("parquet").partitionBy("gender")
.save("file:/root/pipeline/datasets/dating/genders.parquet")
SQL
CREATE TABLE genders USING parquet
OPTIONS
(path "file:/root/pipeline/datasets/dating/genders.parquet")](https://image.slidesharecdn.com/advancedapachesparkmeetupdatasourcesapicassandrasparkconnectorsept212015-150922225610-lva1-app6891/85/Advanced-Apache-Spark-Meetup-Spark-SQL-DataFrames-Catalyst-Optimizer-Data-Sources-API-27-320.jpg)













Advanced Apache Spark Meetup Spark SQL + DataFrames + Catalyst Optimizer + Data Sources API
- 1. IBM | spark.tc Advanced Apache Spark Meetup Spark SQL + DataFrames + Catalyst + Data Sources API Chris Fregly, Principal Data Solutions Engineer IBM Spark Technology Center Sept 21, 2015 Power of data. Simplicity of design. Speed of innovation.
- 3. IBM | spark.tc Announcements Patrick McFadin, Evangelist DataStax Steve Beier, Boss Man IBM Spark Tech Center
- 4. IBM | spark.tc Who am I? Streaming Platform Engineer Not a Photographer or Model Streaming Data Engineer Netflix Open Source Committer Data Solutions Engineer Apache Contributor Principal Data Solutions Engineer IBM Technology Center
- 5. IBM | spark.tc Last Meetup (Spark Wins 100 TB Daytona GraySort) On-disk only, in-memory caching disabled!sortbenchmark.org/ApacheSpark2014.pdf
- 6. IBM | spark.tc Meetup Metrics Total Spark Experts: ~1000 (+20%) Mean RSVPs per Meetup: ~300 Mean Attendance: ~50-60% of RSVPs Donations: $0 (-100%) This is good! “Your money is no good here.” Lloyd from The Shining <--- eek!
- 7. IBM | spark.tc Meetup Updates Talking with other Spark Meetup Groups Potential mergers and/or hostile takeovers! New Sponsors!! Looking for more South Bay/Peninsula Hosts Required: Food, Beer/Soda/Water, Air Conditioning Optional: A/V Recording and Live Stream We’re trying out new PowerPoint Animations Please be patient!
- 8. IBM | spark.tc Constructive Criticism from Previous Attendees “Chris, you’re like a fat version of an already-fat Erlich from Silicon Valley - except not funny.” “Chris, your voice is so annoying that it actually woke me from the sleep induced by your boring content.”
- 9. IBM | spark.tc Freg-a-palooza Upcoming World Tour ① New York Strata (Sept 29th – Oct 1st) ② London Spark Meetup (Oct 12th) ③ Scotland Data Science Meetup (Oct 13th) ④ Dublin Spark Meetup (Oct 15th) ⑤ Barcelona Spark Meetup (Oct 20th) ⑥ Madrid Spark Meetup (Oct 22nd) ⑦ Amsterdam Spark Summit (Oct 27th – Oct 29th) ⑧ Delft Dutch Data Science Meetup (Oct 29th) ⑨ Brussels Spark Meetup (Oct 30th) ⑩ Zurich Big Data Developers Meetup (Nov 2nd) High probability I’ll end up in jail
- 10. IBM | spark.tc Topics of this Talk ①DataFrames ②Catalyst Optimizer and Query Plans ③Data Sources API ④Creating and Contributing Custom Data Source ①Partitions, Pruning, Pushdowns ①Native + Third-Party Data Source Impls ①Spark SQL Performance Tuning
- 11. IBM | spark.tc DataFrames Inspired by R and Pandas DataFrames Cross language support SQL, Python, Scala, Java, R Levels performance of Python, Scala, Java, and R Generates JVM bytecode vs serialize/pickle objects to Python DataFrame is Container for Logical Plan Transformations are lazy and represented as a tree Catalyst Optimizer creates physical plan DataFrame.rdd returns the underlying RDD if needed Custom UDF using registerFunction() New, experimental UDAF support Use DataFrames instead of RDDs!!
- 12. IBM | spark.tc Catalyst Optimizer Converts logical plan to physical plan Manipulate & optimize DataFrame transformation tree Subquery elimination – use aliases to collapse subqueries Constant folding – replace expression with constant Simplify filters – remove unnecessary filters Predicate/filter pushdowns – avoid unnecessary data load Projection collapsing – avoid unnecessary projections Hooks for custom rules Rules = Scala Case Classes val newPlan = MyFilterRule(analyzedPlan) Implements oas.sql.catalyst.rules.Rule Apply to any plan stage
- 13. IBM | spark.tc Plan Debugging gendersCsvDF.select($"id", $"gender").filter("gender != 'F'").filter("gender != 'M'").explain(true) Requires explain(true) DataFrame.queryExecution.logical DataFrame.queryExecution.analyzed DataFrame.queryExecution.optimizedPlan DataFrame.queryExecution.executedPlan
- 14. IBM | spark.tc Plan Visualization & Join/Aggregation Metrics Effectiveness of Filter Cost-based Optimization is Applied Peak Memory for Joins and Aggs Optimized CPU-cache-aware Binary Format Minimizes GC & Improves Join Perf (Project Tungsten) New in Spark 1.5!
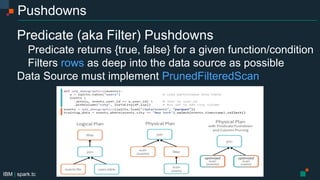
- 15. IBM | spark.tc Data Sources API Execution (o.a.s.sql.execution.commands.scala) RunnableCommand (trait/interface) ExplainCommand(impl: case class) CacheTableCommand(impl: case class) Relations (o.a.s.sql.sources.interfaces.scala) BaseRelation (abstract class) TableScan (impl: returns all rows) PrunedFilteredScan (impl: column pruning and predicate pushdown) InsertableRelation (impl: insert or overwrite data using SaveMode) Filters (o.a.s.sql.sources.filters.scala) Filter (abstract class for all filter pushdowns for this data source) EqualTo GreaterThan StringStartsWith
- 16. IBM | spark.tc Creating a Custom Data Source Study Existing Native and Third-Party Data Source Impls Native: JDBC (o.a.s.sql.execution.datasources.jdbc) class JDBCRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation Third-Party: Cassandra (o.a.s.sql.cassandra) class CassandraSourceRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation
- 17. IBM | spark.tc Contributing a Custom Data Source spark-packages.org Managed by Contains links to externally-managed github projects Ratings and comments Spark version requirements of each package Examples https://github.com/databricks/spark-csv https://github.com/databricks/spark-avro https://github.com/databricks/spark-redshift
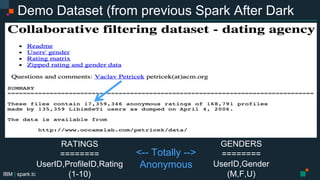
- 19. IBM | spark.tc Demo Dataset (from previous Spark After Dark talks) RATINGS ======== UserID,ProfileID,Rating (1-10) GENDERS ======== UserID,Gender (M,F,U) <-- Totally --> Anonymous
- 20. IBM | spark.tc Partitions Partition based on data usage patterns /root/gender=M/… /gender=F/… <-- Use case: access users by gender /gender=U/… Partition Discovery On read, infer partitions from organization of data (ie. gender=F) Dynamic Partitions Upon insert, dynamically create partitions Specify field to use for each partition (ie. gender) SQL: INSERT TABLE genders PARTITION (gender) SELECT … DF: gendersDF.write.format(”parquet").partitionBy(”gender”).save(…)
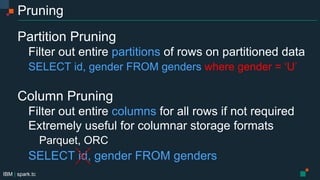
- 21. IBM | spark.tc Pruning Partition Pruning Filter out entire partitions of rows on partitioned data SELECT id, gender FROM genders where gender = ‘U’ Column Pruning Filter out entire columns for all rows if not required Extremely useful for columnar storage formats Parquet, ORC SELECT id, gender FROM genders
- 22. IBM | spark.tc Pushdowns Predicate (aka Filter) Pushdowns Predicate returns {true, false} for a given function/condition Filters rows as deep into the data source as possible Data Source must implement PrunedFilteredScan
- 23. Native Spark SQL Data Sources
- 24. IBM | spark.tc Spark SQL Native Data Sources - Source Code
- 25. IBM | spark.tc JSON Data Source DataFrame val ratingsDF = sqlContext.read.format("json") .load("file:/root/pipeline/datasets/dating/ratings.json.bz2") -- or -- val ratingsDF = sqlContext.read.json ("file:/root/pipeline/datasets/dating/ratings.json.bz2") SQL Code CREATE TABLE genders USING json OPTIONS (path "file:/root/pipeline/datasets/dating/genders.json.bz2") Convenience Method
- 26. IBM | spark.tc JDBC Data Source Add Driver to Spark JVM System Classpath $ export SPARK_CLASSPATH=<jdbc-driver.jar> DataFrame val jdbcConfig = Map("driver" -> "org.postgresql.Driver", "url" -> "jdbc:postgresql:hostname:port/database", "dbtable" -> ”schema.tablename") df.read.format("jdbc").options(jdbcConfig).load() SQL CREATE TABLE genders USING jdbc OPTIONS (url, dbtable, driver, …)
- 27. IBM | spark.tc Parquet Data Source Configuration spark.sql.parquet.filterPushdown=true spark.sql.parquet.mergeSchema=true spark.sql.parquet.cacheMetadata=true spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo] DataFrames val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet") gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet") SQL CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")
- 28. IBM | spark.tc ORC Data Source Configuration spark.sql.orc.filterPushdown=true DataFrames val gendersDF = sqlContext.read.format("orc") .load("file:/root/pipeline/datasets/dating/genders") gendersDF.write.format("orc").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders") SQL CREATE TABLE genders USING orc OPTIONS (path "file:/root/pipeline/datasets/dating/genders")
- 30. IBM | spark.tc CSV Data Source (Databricks) Github https://github.com/databricks/spark-csv Maven com.databricks:spark-csv_2.10:1.2.0 Code val gendersCsvDF = sqlContext.read .format("com.databricks.spark.csv") .load("file:/root/pipeline/datasets/dating/gender.csv.bz2") .toDF("id", "gender") toDF() defines column names
- 31. IBM | spark.tc Avro Data Source (Databricks) Github https://github.com/databricks/spark-avro Maven com.databricks:spark-avro_2.10:2.0.1 Code val df = sqlContext.read .format("com.databricks.spark.avro") .load("file:/root/pipeline/datasets/dating/gender.avro")
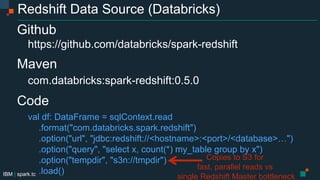
- 32. IBM | spark.tc Redshift Data Source (Databricks) Github https://github.com/databricks/spark-redshift Maven com.databricks:spark-redshift:0.5.0 Code val df: DataFrame = sqlContext.read .format("com.databricks.spark.redshift") .option("url", "jdbc:redshift://<hostname>:<port>/<database>…") .option("query", "select x, count(*) my_table group by x") .option("tempdir", "s3n://tmpdir") .load() Copies to S3 for fast, parallel reads vs single Redshift Master bottleneck
- 33. IBM | spark.tc ElasticSearch Data Source (Elastic.co) Github https://github.com/elastic/elasticsearch-hadoop Maven org.elasticsearch:elasticsearch-spark_2.10:2.1.0 Code val esConfig = Map("pushdown" -> "true", "es.nodes" -> "<hostname>", "es.port" -> "<port>") df.write.format("org.elasticsearch.spark.sql”).mode(SaveMode.Overwrite) .options(esConfig).save("<index>/<document>")
- 34. IBM | spark.tc Cassandra Data Source (DataStax) Github https://github.com/datastax/spark-cassandra-connector Maven com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M1 Code ratingsDF.write.format("org.apache.spark.sql.cassandra") .mode(SaveMode.Append) .options(Map("keyspace"->"dating","table"->"ratings")) .save()
- 35. IBM | spark.tc REST Data Source (Databricks) Coming Soon! https://github.com/databricks/spark-rest? Michael Armbrust Spark SQL Lead @ Databricks
- 36. IBM | spark.tc DynamoDB Data Source (IBM Spark Tech Center) Coming Soon! https://github.com/cfregly/spark-dynamodb Me Erlich
- 37. IBM | spark.tc SparkSQL Performance Tuning (oas.sql.SQLConf) spark.sql.inMemoryColumnarStorage.compressed=true Automatically selects column codec based on data spark.sql.inMemoryColumnarStorage.batchSize Increase as much as possible without OOM – improves compression and GC spark.sql.inMemoryPartitionPruning=true Enable partition pruning for in-memory partitions spark.sql.tungsten.enabled=true Code Gen for CPU and Memory Optimizations (Tungsten aka Unsafe Mode) spark.sql.shuffle.partitions Increase from default 200 for large joins and aggregations spark.sql.autoBroadcastJoinThreshold Increase to tune this cost-based, physical plan optimization spark.sql.hive.metastorePartitionPruning Predicate pushdown into the metastore to prune partitions early spark.sql.planner.sortMergeJoin Prefer sort-merge (vs. hash join) for large joins spark.sql.sources.partitionDiscovery.enabled & spark.sql.sources.parallelPartitionDiscovery.threshold
- 38. IBM | spark.tc Related Links https://github.com/datastax/spark-cassandra-connector http://blog.madhukaraphatak.com/anatomy-of-spark-dataframe-api/ https://github.com/phatek-dev/anatomy_of_spark_dataframe_api/ https://databricks.com/blog/…
- 39. IBM | spark.tc Upcoming Advanced Apache Spark Meetups Project Tungsten Data Structs & Algos for CPU & Memory Optimization Nov 12th, 2015 Text-based Advanced Analytics and Machine Learning Jan 14th, 2016 ElasticSearch-Spark Connector w/ Costin Leau (Elastic.co) & Me Feb 16th, 2016 Spark Internals Deep Dive Mar 24th, 2016 Spark SQL Catalyst Optimizer Deep Dive Apr 21st, 2016
- 40. Special Thanks to DataStax!! IBM Spark Tech Center is Hiring! Only Fun, Collaborative People - No Erlichs! IBM | spark.tc Sign up for our newsletter at Thank You! Power of data. Simplicity of design. Speed of innovation.
- 41. Power of data. Simplicity of design. Speed of innovation. IBM Spark