DAシンポジウム2019招待講演「深層学習モデルの高速なTraining/InferenceのためのHW/SW技術」 金子紘也hare
5 likes2,154 views

2019年8月28日に開催されたDAシンポジウムにおける招待講演資料です。 本資料では、深層学習モデルの高速なTraining/Inferenceを行うためのハードウェア及びソフトウェア技術について弊社の取り組みを交えて紹介しています。






![9
ディープラーニング(深層学習)と
● 層が深く、幅も広いニューラルネットワーク
を利用した機械学習手法 一手法
● 2012年 大ブレーク以来、研究コミュニティ
みならず産業界に多く使われてきた
● 画像認識、音声認識、強化学習、自然言語処理
などで劇的な精度向上を果たし、そ 多くが既に実用化されている
2014年 一般画像認識コンテストで優勝した
22層からなる GoogLeNet 例 [Google 2014]
*http://memkite.com/deep-learning-bibliography/](https://image.slidesharecdn.com/dasymposiumhwswfortraininginferenceslideshare-190911111040/85/DA-2019-Training-Inference-HW-SW-hare-7-320.jpg)















































DAシンポジウム2019招待講演「深層学習モデルの高速なTraining/InferenceのためのHW/SW技術」 金子紘也hare
- 1. 2019/08/28 DAシンポジウム 1A招待講演 深層学習モデル 高 な Training/Inference ため HW/SW技術 Hiroya Kaneko @Preferred Networks
- 2. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 3. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 4. 株式会社Preferred Networks (PFN) • 設立:2014年3月 • 本社:東京都千代田区大手町(日本) • Preferred Networks America, Inc.:カリフォルニア州バークレー(米国) • 取締役:西川 徹、岡野原 大輔、奥田 遼介 • 従業員数:約250名(2019年4月時点) • ミッション:IoT時代に向けた新しいコンピュータを創 する あらゆるモノに知能をもたせ、分散知能を実現する • 事業内容:IoT + 分散機械学習 交通システム、製 業、バイオヘルスケア
- 5. 7 @CEATEC JAPAN 2018 Autonomous Tidying-up Robot System https://projects.preferred.jp/tidying-up-robot/ x2
- 6. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 7. 9 ディープラーニング(深層学習)と ● 層が深く、幅も広いニューラルネットワーク を利用した機械学習手法 一手法 ● 2012年 大ブレーク以来、研究コミュニティ みならず産業界に多く使われてきた ● 画像認識、音声認識、強化学習、自然言語処理 などで劇的な精度向上を果たし、そ 多くが既に実用化されている 2014年 一般画像認識コンテストで優勝した 22層からなる GoogLeNet 例 [Google 2014] *http://memkite.com/deep-learning-bibliography/
- 8. 10 深層学習 = 表現学習、一貫学習(end-to-end学習) ● データをど ように表現するか(表現学習) ● 全モジュールを誤差逆伝播法で一貫して学習 — モジュール毎 局所最適化 問題がない — 信用割り当て問題(誰に間違った責任があるか)を自然に解く 特徴設計 ルール ・ プログラム タスク 学習 ルールベース 浅い機械学習 (決定木、RF、SVM、 ロジスティク回帰など) 深層学習 タスク 学習 表現学習 (特徴設計) 人手 データから自動獲得 一貫学習
- 9. 深層学習における代表的なタスク 11 The graph was excerpted from https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/object_localization_and_detection.html
- 10. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 11. 13 ニューラルネットワークモデル ● 入力に対しhidden layer 演算を繰り返して出力を得る 深いレイヤー パーツを組み合わせた 総合的かつ抽象的な情報 図 CS231n講義資料より http://cs231n.github.io/neural-networks-1/
- 12. 14 ディープラーニング 基本計算 ● 下層 入力xを重み付きで足しあわせた後に活性化関数hをかけて出力 – Wi がモデルパラメータであり、重みと呼 れる x1 x2 x3 +1 w1 w2 w3 w4 h = a(x1 w1 +x2 w2 +x3 w3 +w4 ) h a 例 ReLU: h(x) = max(0, x) a : 活性化関数 バイアス項 活性化関数に 、ReLUなど勾配消失問題を 回避できる区分線形関数が多く使われる
- 13. 15 CNN (Convolutional Neural Network) 1 2 3 4 5 6 7 8 9 Input * Nch 1 2 3 4 Weight * N個 1 2 3 4 1 2 3 4 1 2 3 4 Output(Activation) 1 2 3 4 37 47 67 87 1 2 3 4 5 6 7 8 9 * Filterをずらしながら畳み込み演算を行う データ転送に対して演算量が大きい input ch数=1 場合
- 14. 16 アーキテクチャ 例 ● AlexNet — Conv 5層+FC3層というシンプルなモデル Chainerで 実装例 with self.init_scope(): self.conv1 = L.Convolution2D(None, 96, 11, stride=4) self.conv2 = L.Convolution2D(None, 256, 5, pad=2) self.conv3 = L.Convolution2D(None, 384, 3, pad=1) self.conv4 = L.Convolution2D(None, 384, 3, pad=1) self.conv5 = L.Convolution2D(None, 256, 3, pad=1) self.fc6 = L.Linear(None, 4096) self.fc7 = L.Linear(None, 4096) self.fc8 = L.Linear(None, 1000) def forward(self, x, t): h = F.max_pooling_2d(F.local_response_normalization( F.relu(self.conv1(x))), 3, stride=2) h = F.max_pooling_2d(F.local_response_normalization( F.relu(self.conv2(h))), 3, stride=2) h = F.relu(self.conv3(h)) h = F.relu(self.conv4(h)) h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2) h = F.dropout(F.relu(self.fc6(h))) h = F.dropout(F.relu(self.fc7(h))) h = self.fc8(h) The graph was excerpted from https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
- 15. Trainingにおける演算 • 誤差逆伝播を使った勾配 算出とモデル アップデート (これを1iterationと呼ぶ) – Forward時 activation 値が必要 – いくつか 入力をまとめて学習を行う場 合もある(ミニバッチ学習) – 勾配 平均をupdateに利用する – 全て 入力データを一度利用することを 1epochと呼ぶ • 大量 密なFMA演算が必要とされる – 特にCNN 場合Filterを共有するためメ モリアクセスに対して演算量が大きい 図 メディカル AI専門コース オンライン講義資料より https://japan-medical-ai.github.io/medical-ai-course-materials/
- 16. Image Classification 進歩 ● ILSVRC Image classification competition The graph was excerpted from Eunbyung Park (2017). Overview of ILSVRC 2017 2012: AlexNet 2014: GoogLeNet 2016: ResNet 既に人 認識率を 超えつつある
- 17. 19 モデル 探索・改善 ● 新しいネットワークアーキテクチャ 探索(Trained from scratch) — ある意味職人芸 世界 — 各ドメインごとにある程度当たりをつけた上で 様々なアーキテクチャ/ハイパーパラメータ 試行錯誤 を繰り返す — アーキテクチャ 自動探索 (Neural Architecture Search) ● Pre-trained model 活用 (fine-tuning) — 大きなデータセットに対して十分に Trainingされたモデル 良い特徴量抽出器として利用できること が知られている — Pre-trained modelをtrunk networkとして利用し他 タスク向けに再学習 — scratchからtrainingするより 時間が短縮できるが、 結局 試行錯誤 繰り返し
- 18. ● 最適なアーキテクチャを自動的に探 索する仕組み ● 近年hand-craft なネットワーク 精 度をNASが凌駕しつつある ● 試行錯誤 自動化 20 Neural Architecture Search (NAS) The graph was excerpted from Zoph, B., Vasudevan, V., Shlens, J., & Le, Q. V. (2017). Learning Transferable Architectures for Scalable Image Recognition. AAAI-18 Red: NAS, Black: Handcraft Top-1 Acc@ImageNet Better Search Train & Test Neural Network Metrics
- 19. Deep Learningに必要な計算能力 増え続けている ● SoTAな研究において モデルサイズ 依然として増えていく傾向にある — 画像から動画/立体へ、画像 巨大化 — 時間方向/空間方向へ Convolution, HD画像処理など ● NAS (Network Architecture Search) — アーキテクチャ探索 自動化 — 探索時間を減らすため 試みなど 様々行われているが、基本的に 試行錯誤 自動化 — 人がボトルネックにならない ● 計算能力を高めること 競争力 源泉 Train Evaluate Design a new model quicker Train faster Get a better (or equivalent) model
- 20. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 21. PFNにおける深層学習基盤 ● HWからSWまで深層学習 研究開発 加 を目的に整備・運用している — HW ◆ GPU Cluster (MN-1/1b/2) ◆ Custom Processor (MN-Core) — SW ◆ k8s env + job scheduler ◆ Optuna (hyperparameter optimization framework) ◆ Chainer family (Deep learning framework)
- 22. 24 PFNが自社クラスタにこだわる理由 • 大量 計算機を使って誰にも成し遂げられなかったことをしたい(グランドチャレンジ) – や り計算力 競争力 源(クラウドとて無限で ない) – 2017年5月頃、NIPS論文提出 締切直前に、大手クラウドサービス GPUが枯渇 • 息をするように大規模な学習できる環境 – 16 GPU, 32 GPU 学習を日常的に回したい • 高 な通信環境をいつも使いたい – 分散深層学習に 高 な通信環境が必須 • 上から下まで保有すること 重要性 – 様々な技術バックグランドを持つメンバーが集結することによって、新しいも を生み出 していく(クラスタ 調達からアルゴリズムまで)
- 23. Deep Learning 高 化 ● 基本的に 一般的なHPC workload 高 化と考え方 同じ ● Scale-out (分散並列化) – SW的な改善 — 分散深層学習 ◆ データ並列、モデル並列 ◆ 計算と通信 オーバラップ ● Scale-up (専用アクセラレータ) – HW的な改善 — Inference/Training専用アクセラレータ
- 24. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 25. 27 Deep learningにおける分散並列化 Data-parallelism Model-parallelism Synchronous Asynchronous Fine-grained Coarse-grained 一つ モデルを複数 ノードを用い て高 にTrainingする - 全ノードで同一 パラメータ 一つ 大きなモデルを 複数 ノード を用いて分担してTrainingする - 全ノードで異なるパラメータ ● データ並列とモデル並列で目的が異なる — 高 化 観点で データ並列を利用する 高 化 観点で 同期型データ並列が重要
- 26. 28 同期型データ並列による学習 高 化 ● 1iterationで処理する画像 枚数 (バッチサイズ)を大きく取り各GPUで処理を分担 — 複数 GPUに画像を らまき各 GPUで逆伝播を行う — 各GPUで求まった勾配 平均を Allreduceを用いて求める — 各GPUにおいてモデルをアップデートする ● 課題 ● バッチサイズを変更した結果 精度劣化 ● All-reduceによる同期オーバヘッド All-Reduc e Forward Forward Forward Backward Backward Backward Optimize Optimize Optimize Forward Backward Optimizebatchsize=32 batchsize=96 (32*3) 1nodeで 学習 3nodeで 分散学習 ※1nodeあたり batchsize GPUを 効率的に利用可能な値に設定される
- 27. 29 The “large batch” problem From Keskar et al. “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima” “It has been observed in practice that when using a larger batch there is a significant degradation in the quality of the model, as measured by its ability to generalize” 1. Computed gradients in each iteration is an average of larger number of samples → gradients are “less stochastic”, which makes it difficult to escape from local minima 2. Total number of iterations (=updates) is smaller (number of iterations in 1epoch = number of images / batchsize) Local minima Better model
- 28. 30 “Linear scaling rule” for large batch problem “If minibatch-size is k times larger, increase learning rate by k times”
- 29. 31 Data parallel: sync vs. async All-Reduc e Forward Forward Forward Backward Backward Backward Optimize Optimize Optimize Synchronous: Parameter server Asynchronous:
- 30. 32 Reduce communication: use FP16 Compute gradients Convert FP32 to FP16 Allreduce (with NCCL) Convert FP16 to FP32 and update
- 31. 33 Hide communication (by overlapping) Double buffering • Each update uses the gradients from previous iteration (1-step stale grad.)
- 32. 同期型データ並列による学習 高 化 ● 問題設定 ● Dataset: ImageNet ● モデル: ResNet50 ● 90epochをいかに精度を落とさずに高 に学習するか (epoch数自体を減らして いけない ) ● 2年弱で100倍以上高 化している Company Processor Date Training time PFN TITAN X *128 17/1 4h Facebook P100 *256 17/6 1h PFN P100 *1024 17/11 15min SONY V100 *2176 18/11 3.7min Google TPUv3 *1024 18/11 2.2min
- 33. Scale-out (分散並列化)による高 化 ● 同期型データ並列によって、2年弱で100倍以上高 化している — 元々 論文で 8枚 GPUで数週間要していたも 、今や2.2min — バッチサイズを増やせる問題について 、GPU台数に対してほぼリニアに性能向上が達成で きる程度にノウハウがたまりつつある ● 常に適用できる万能な手法で ない — バッチサイズを増やしても精度や学習 安定性に問題が出ないモデル に み適用可能
- 34. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 35. Scale-upによる高 化 - 専用アクセラレータによる高 化- ● 様々な専用アクセラレータを 各社提案している — Inference向け — 精度を維持したまま く、省電力に推論を実 行する(組み込み寄り 世界) — Training向け ◆ 精度を維持したままモ デルを高 に学習す る (HPC寄り 世界) The image was excerpted from https://github.com/basicmi/AI-Chip PFNとして こちら 高 化 需要が大きい
- 36. なぜ今DL専用アクセラレータ開発な か? ● 「大きな計算能力が必要」という需要 観点以外にも、ハードウェア開発を加 さ せる背景がある — Deep Learning 応用範囲が拡大していること — Deep Learningにおいて必要とされる演算精度がこれまで 科学技術計算と異なること — 演算手順が計算グラフによって宣言的に定義されること
- 37. なぜ今DL専用アクセラレータ開発な か? ● 「大きな計算能力が必要」という需要 観点以外にも、ハードウェア開発を加 さ せる背景がある — Deep Learning 応用範囲が拡大していること — Deep Learningにおいて必要とされる演算精度がこれまで 科学技術計算と異なること — 演算手順が計算グラフによって宣言的に定義されること
- 38. 演算精度について(Training) ● Trainingで 混合精度 (fp16乗算+fp32加算) 活用が注目されている — NVIDIA Volta: Tensor Core (4x4 混合積和演算, fp16 matmul, fp32 accumulate) — Google TPU: BFLOAT16 (brain float) ◆ fp16よりもdynamic rangeが広い ◆ 勾配 underflow対策 ● Deep learningに最適な数値表現と なにか?という問題に 答え 出ていない — fp16でもCNN, RNN, GANなど Trainingがある程度うまくいくという報告 — 使う観点で cuDNNなどが対応を始めているが、正しく利用するために ノウハウが必要 ● HPC系学会でも混合精度演算 benchmarkについて議論が始まっている The figure was excerpted from https://cloud.google.com/tpu/docs/bfloat16
- 39. 演算精度について(Inference) ● Inferenceで 、よりAggressiveな最適化が可能 — Int8, Int4, binary ● 学習済みモデルをターゲットアーキテクチャに対して最適化する — モデル 量子化 (Quantization) ◆ モデル N-bit整数化 — モデル 剪定 (Pruning) ◆ 構築済みモデル Sparse化 (主にSpMV Acceleratorと 組み合わせ) — 小さいモデルへ 蒸留 (distillation) ◆ 小さなモデルに教師モデル 分布を学習させる ● Emerging deviceを利用したも も様々提案がある(が、現時点で まだMNIST など Toy Problemが解ける程度という印象)
- 40. なぜ今DL専用アクセラレータ開発な か? ● 「大きな計算能力が必要」という需要 観点以外にも、ハードウェア開発を加 さ せる背景がある — Deep Learning 応用範囲が拡大していること — Deep Learningにおいて必要とされる演算精度がこれまで 科学技術計算と異なること — 演算手順が計算グラフによって宣言的に定義されること
- 41. 計算グラフと中間表現 ● Deep learning モデル 計算グラフとして 表現できる ● 現実的に モデル element-wiseな計算 依存関係で なくオペレータ (レイヤ) 接続関係としてDeep Learning Framework 上で表現される — I/F Frameworkごとに異なっても表現し ているも に大きな違い ない ● 手続き的な表現でなく宣言的な表現 (グラフ IR)が手に入る! — 中間表現 標準化:ONNX, NNEFなど
- 42. 計算グラフが手に入るうれしさ - アーキテクチャ観点から ● 高度なオフラインスケジューリングが可能 — 変数 life-timeが既知 ◆ cache 重要性 低下 (scratchpadで十分) — 演算順序がdeterministicに決定可能 ◆ 分岐予測 重要性 低下 (値に依存して分岐することが少ない) ◆ 並列性が抽出しやすい -> 高度なオフラインスケジューラを前提としたシンプルかつ並列度 高いプ ロセッサアーキテクチャを現実的に利用可能
- 43. 深層学習コンパイラ ● グラフIRを入力に、ターゲット依存 最適化を行うコンパイラ The figure was excerpted from Tianqi Chen et al. TVM: An Automated End-to-End Optimizing Compiler for Deep Learning https://arxiv.org/abs/1802.04799 ● オペレータ単位でプロセッサ専用 高効率カーネルを定義可能 ● 演算 fusionやスケジューリング、メ モリ配置 最適化 ● 演算 スケジューリング /メモリ配置 最適化 ● 再計算 — 計算量を増加させることで、メモリ使用量 を削減する
- 44. Chainer-compiler ● Box: software component / Rounded corner: data ● Yellow: exists / Grey: future work CH2O elichika XCVM runtime Python Chainer ONNX+ inferenc e XCVM IR ONNX Chainer ONNX+ training Compiler code gen Menoh C API @static graph MN-Core? Static graph analysis Visualizers (e.g., netron) native binary (AOT) Compiler middle end
- 45. 今日話す内容 • PFNについて • 深層学習と • 深層学習における計算・ワークフロー • Deep Learning 高 化 – ソフトウェア 視点から – ハードウェア 視点から • MN-Core 開発について • まとめ
- 46. 深層学習用プロセッサ MN-Core 倍精度 単精度 半精度 TFLOP 32.8 131 524 TFLOP/W 0.066 0.26 1.0 開発中 • Deep Learning Trainingに特 化した専用設計 ASIC • 特に計算量 多いConvolution Kernelを高 化するため 専用 設計
- 47. MN-Core • 階層メモリ型SIMDアーキテク チャによって512MABを1chip に集積 – 各階層 メモリ スク ラッチパッドとして利用 可能 – 各階層間で 分配、結 合、放送、縮約といった 複数 転送モードをサ ポート • 倍/単/半精度相当及び混合 精度 行列積演算をサポート • Deep Learningに特化した演 算器を搭載 製 プロセス TSMC 12nm 消費電力 (W、予測値) 500 (4die, 1package合計) ピーク性能 (TFLOPS) 32.8 (倍精度) / 131 (単精度) / 524 (半精度) 電力性能 (TFLOPS / W、予測値) 0.066 (倍精度) / 0.26 (単精度) / 1.0 (半精度)
- 48. MN-Core • PCIe接続 アクセラレータカードとして提供 • ボード及びサーバも開発中 – MN-Coreを搭載したクラスタを2020年に運用開始予定(目標) チップ 1 MN-Core チップ (4die) インターフェース PCI Express Gen3 x16 メモリサイズ 32 GB (ボード当たり) 消費電力 600 W (予測値)
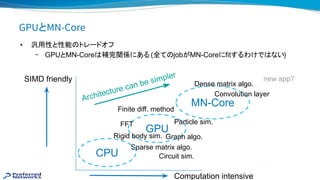
- 49. GPUとMN-Core • 汎用性と性能 トレードオフ – GPUとMN-Core 補完関係にある (全て jobがMN-Coreにfitするわけで ない) Architecture can be simpler GPU MN-Core Computation intensive SIMD friendly Convolution layer Dense matrix algo. Particle sim. Sparse matrix algo. Finite diff. method CPU FFT Graph algo.Rigid body sim. new app? Circuit sim.
- 50. MN-Core開発チーム ● ハードウェア/ソフトウェアエンジニア 垣根なくフレキシブルに働いている — そもそも区分けが会社全体として存在していない ● HDLをソフトウェアエンジニアが読みつつ・・・など よくある 開発メンバー ● 神戸大学 牧野淳一郎教授と共同で アーキテクチャ検討を実施 — ASIC開発に関して 経験豊富な GRAPE開発メンバがリード
- 51. MN-Core 開発 ● 開発プロセスに何か特筆すべき事項があるわけで ない — SystemCベース 検証環境 ◆ 主にデバイスドライバなどと 協調検証に利用 — ソフトウェアエミュレータ ◆ MN-Core 命令レベルエミュレータ ◆ 上位 アプリケーションレベル 記述性 確認 ◆ RTLと 最終的な比較一致検証 — 演算器 精度などについて Chainer側に手を入れ一部モデルで検証を実施
- 52. HWを支えるSWについて • ユーザにとって いつも コードをいつも 方法で動かして、結果 くなるという が理想(使 うために大きなオーバヘッド 避けるべき) • 既存 Chainerからシームレスに、かつ高効率にMN-Coreを利用可能にするため ソフト ウェア 研究開発を行っています – 専用ASICを利用するため ツールチェーン群 – ChainerX • 高 な自動微分 実装、選択可能なbackend – Chainer-compiler • Pythonから拡張ONNXフォーマットへ convert • 拡張ONNX上における計算グラフ 最適化、自動微分
- 53. PFN プロセッサ関連研究へ 取り組み ● 次世代 プロセッサ 開発を並行して実施している (NEDO PJ) ● そ 他、新しい検討など — 新しいアーキテクチャ 検討・評価 — 形式手法を用いたテスト 自動生成 — 高 ・高機能なHPC向けInterconnect 検討 ● 今後重要になりそうなTopic — システム (データセンタ)全体として性能を出すため 仕組み ◆ 既に学習を律 するも がプロセッサで なくなりつつある
- 54. さいごに ● Deep Learning 分野において 計算能力 向上が求められている — 高 化 アプローチ:Scale-out (分散並列化)とScale-up (専用アクセラレータ) — プロセッサ 設計/効率的な利用という観点で 、宣言的に計算が定義されることが重要 ◆ オフラインスケジューリングを前提としたシンプルな並列アーキテクチャ ◆ 深層学習コンパイラ ● Deep learning ため 最適な計算機を構築するために 専用ASIC (MN-Core) から上位ソフトウェアフレームワークまで含めて全体を考え ていく必要がある