Efficient Clustering from Distributions over Topics
0 likes94 views

This document presents an efficient approach for clustering large document collections based on topic distributions generated by probabilistic topic models like LDA. It proposes three approaches - TDC, RDC, and CRDC - that cluster documents based on variations or rankings of their topic distributions rather than the distributions directly. An evaluation on Apache Commons Math dataset shows CRDC improves over baselines in effectiveness, cost and efficiency metrics. Future work will explore hybrid methods combining these approaches with existing techniques.










![11
Scenario
[ 0.243, 0.145, 0.600, 0.022]
corpus Prob. Topic Model
Topic 1
Topic 2
Topic 3
Dirichlet Distribution
• Exponential family distribution over the simplex,
i.e. positive vectors that sum to one](https://image.slidesharecdn.com/efficientclustering-171215125442/85/Efficient-Clustering-from-Distributions-over-Topics-11-320.jpg)

![13
Approach 2: RDC
Ranking on Dirichlet-based Clustering (RDC)
• Only considering the top n topics from the ranked list of probability distribu7ons [29]
• Based on the assump7on that the highest weighted topics have a high influence in the
rest of topics when calcula7ng distances
0.23 0.18 0.33 0.13 0.13 n=2, P =
2 0 R =
1 0 2 3 4](https://image.slidesharecdn.com/efficientclustering-171215125442/85/Efficient-Clustering-from-Distributions-over-Topics-13-320.jpg)
















Efficient Clustering from Distributions over Topics
- 1. Badenes-Olmedo, Carlos Redondo Garcia, Jose Luís Corcho, Oscar Ontology Engineering Group (OEG) Universidad Politécnica de Madrid (UPM) cbadenes@fi.upm.es @carbadol github.com/librairy oeg-upm.net Efficient Clustering from Distributions over Topics K-CAP 2017 Knowledge Capture December 4th-6th, 2017 Austin, Texas, United States
- 3. 3 Connected Documents in a Collection
- 4. 4 From Sets of Textual documents to Graphs
- 6. 6 Solution: Partition of the Search Space
- 7. 7 Use-Case: Digital Publisher 7,648 Books 68,653 Chapters 4x1.6 Ghz 16GB RAM 4x1.6 Ghz 16GB RAM 2,910,883,150 similarities aprox 8 hours 76,301 Documents All pairwise similarities approx 3.5 days
- 8. 8 Hypothesis Topic 1 Topic 2 Topic 3 Topic 4 LDA LDA for efficient space partition Probabilis)c Topic Models (PTM) and in par)cular, on Latent Dirichlet Alloca-on (LDA) can efficiently divide the search space and speed up the process of finding rela)ons among documents inside big collec)ons.
- 9. 9 • Each topic is a distribution over words • Each document is a mixture of corpus-wide topics • Each word is drawn from one of those topics Probabilistic Topic Models source: David Blei, Probabilistic Topic Models
- 10. 10 Topic Model Similarity Valuetopic0: 0.520, topic1: 0.327 topic2: 0.081 … topic122: 0.182 topic1: 0.573, topic2: 0.172 topic3: 0.136 … topic122: 0.099 0.595 .. Topic0 Topic1 Topic2 Topic122 DOCUMENT ‘A’ DOCUMENT ‘B’ Topic-based Similarity Jensen-Shannon Divergence
- 11. 11 Scenario [ 0.243, 0.145, 0.600, 0.022] corpus Prob. Topic Model Topic 1 Topic 2 Topic 3 Dirichlet Distribution • Exponential family distribution over the simplex, i.e. positive vectors that sum to one
- 12. Approach 1: TDC 12 • Instead of directly relying on the topic distribu5on’s scores, it considers their varia5ons across consecu5ve topics inside a document’s topic distribu5on 0.23 0.18 0.33 0.13 0.13 P = > < = > 2 1 2 0 T = Trends on Dirichlet-based Clustering (TDC)
- 13. 13 Approach 2: RDC Ranking on Dirichlet-based Clustering (RDC) • Only considering the top n topics from the ranked list of probability distribu7ons [29] • Based on the assump7on that the highest weighted topics have a high influence in the rest of topics when calcula7ng distances 0.23 0.18 0.33 0.13 0.13 n=2, P = 2 0 R = 1 0 2 3 4
- 14. 14 Approach 3: CRDC Cumulative Ranking on Dirichlet-based Clustering (CRDC)
- 16. 16 Experiments: Baselines • 1: h%p://commons.apache.org/proper/commons-math/ Similarity Metrics: •Jensen-Shannon Divergence •Hellinger Distance Clustering Algorithms:
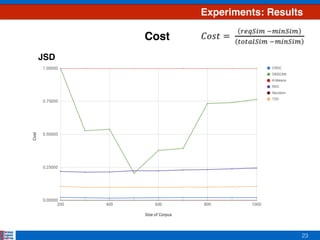
- 20. 20 Experiments: Results Number of Clusters
- 27. 27 Conclusions • Unsupervised clustering algorithms, TDC, RDC and CRDC. • CRDC is a promising approach, which improves the efficiency obtained by other centroid-based and density-based approaches such as K-Means • Hierarchical approach for RDC algorithm was also considered but it did not produce good results
- 28. 28 Future Work • Hybrid methods combining some of these novel approaches with exis8ng techniques will be performed in future work on the same line • Nearest neighbors as baseline
- 29. 29 Use-Case: Digital Publisher 7,648 Books 68,653 Chapters 4x1.6 Ghz 16GB RAM 4x1.6 Ghz 16GB RAM 2,910,883,150 similarities aprox 8 hours 76,301 Documents by using CRDC aprox 2 hours 64,635,080 similarities threshold = 0.9 approx 3.5 days
- 30. K-CAP 2017 Knowledge Capture December 4th-6th, 2017 Austin, Texas, United States Badenes-Olmedo, Carlos Redondo Garcia, Jose Luís Corcho, Oscar Ontology Engineering Group (OEG) Universidad Politécnica de Madrid (UPM) Efficient Clustering from Distributions over Topics cbadenes@fi.upm.es @carbadol github.com/librairy oeg-upm.net