Embracing Failure - AzureDay Rome
Download as PPTX, PDF0 likes25 views

The document discusses the importance of embracing failure in cloud-based application development, highlighting the differences between traditional on-premises applications and modern microservices architectures. It emphasizes the need for a resilient, responsive, and elastic system design that incorporates chaos engineering techniques to enhance reliability and availability while adapting to workload changes. Additionally, it covers architectural patterns and principles for building reliable systems, including the role of continuous integration and continuous delivery tools.


































![Tools don’t create reliability.
Human do.
[But tools can help.]
@CaseyRosenthal
Thank You!!!](https://image.slidesharecdn.com/azureday-rome-embracingfailure-191130080914/85/Embracing-Failure-AzureDay-Rome-36-320.jpg)



Embracing Failure - AzureDay Rome
- 1. Embracing Failure The art of being at the edge
- 2. Thanks to
- 3. Embracing Failure «Failures are given, and everything will eventually fail over time» (Werner Vogels – CTO Amazon)
- 5. The art of being at the edge
- 6. Change Mindset Building a reliable application in the cloud is different than building a reliable application in an enterprise setting A new Mindset is needed.
- 7. Eight Fallacies of Distributed Computing - The network is reliable - Latency is zero - Bandwidth is infinite - The network is secure - Topology doesn’t exist - There is one administrator - Transport cost is zero - The network is homogeneous Peter Deutsch
- 8. Conway's law
- 9. On-premises Application - Before the Cloud, users were connected to our applications through the Company's local network; - A server's downtime was planned and involved stopping production - Conway’s law model
- 10. Modern Application - Now our users connect through the Internet - The workload to which our services are subjected will increase significantly, thanks to the greater spread of the applications themselves. - Many Microservices replace Monolithic
- 11. Microservices: is it really a matter of sizes? We cannot say there is a formal definition of the microservices architectural style, but we can attempt to describe what we see as common characteristics for architectures that fit the label. Common Characteristics Componentisation via services Organised around business capabilities Decentralised data management Products not projects Decentralised governance Smart endpoints and dumb pipes Evolutionary design Infrastructure automation ????????????? (Martin Fowler, James Lewis)
- 12. Microservices: or a question of Business?
- 13. Or is it a matter of paradigms? Sync Communication (e.g. http) Async Communication (e.g. ServiceBus) VS
- 14. Reactive Manifesto (16.01.2014) • (Jones Boner, Dave Farley, Roland Kuhn, Martin Thompson) • The absolute, most import thing is it needs to be responsive. This means that a reactive system needs to remain responsive event when a failure occurs.
- 15. Responsive “The system responds in a timely manner if at all possible. Responsiveness is the cornerstone of usability and utility, but more than that, responsiveness means that problems may be detected quickly and dealt with effectively.” https://www.reactivemanifesto.org/it
- 16. Availability Availability Downtime per year Categories 95% (1-nine) 18 days 6 hours Batch processing, Data extraction, Load jobs 99% (2-nines) 3 days 15 hours Internal Tools, Project Tracking 99.9% (3-nines) 8 hours 45 minutes Online Commerce 99.99% (4-nines) 52 minutes Video Delivery, Broadcast systems 99.999% (5-nines) 5 minutes Telecom Industry (ATM Transactions) 99.9999% (6-nines) 31 seconds Answering to me loved one
- 17. Availability The beauty of Math at work! Component Availability Downtime X 99% (2-nines) 3 days 15 hours Y 99.99% (4-nines) 52 minutes X and Y Combined 98.99% 3 days 16 hours 33 minutes Component Availability Downtime X 99% (2-nines) 3 days 15 hours Two X in parallel 99.99% (4-nines) 52 minutes Three X in parallel 99.9999% (6-nines) 31 seconds
- 18. Reactive Manifesto - Resilient
- 19. Resilient • Resilient systems embrace the idea that failures are normal and that it is perfectly acceptable to run systems in what we call partially failing mode.
- 20. Services resiliency All Azure management services are architected to be resilient from region-level failures. In the spectrum of failures, one or more Availability Zone failures within a region have a smaller failure radius compared to an entire region failure. Azure can recover from a zone-level failure of management services within the region or from another Azure region. Azure performs critical maintenance one zone at a time within a region, to prevent any failures impacting customer resources deployed across Availability Zones within a region. Azure solution • Availability Zones • Zonal services: you pin the resource to a specific zone (for example, virtual machines, managed disks, Standard IP addresses) • Zone-redundant services: platform replicates automatically across zones (for example, zone-redundant storage, SQL Database) What are Availability Zones in Azure?
- 21. Reactive Manifesto - Elastic
- 22. Elastic The degree to which a system is able to adapt to workload changes by provisioning and de-provisioning resources in an autonomic manner, such that at each point in time the available resources match the current demand as closely as possible.
- 23. • In free and shared service plan, you cannot scale the application as only one instance is available. • In basic plan, you can scale the application manually. This means you have to check the metrics manually to see if more instances are needed and then can increase or decrease them from your Azure management portal. • In standard and premium plan, you can choose to auto scale based on few parameters. Azure solution • The code that we use for scripting (PowerShell or bash) … it’s code. So we have to treat him as such.
- 24. Reactive Manifesto – Message Driven
- 25. Guaranteering Delivery - The Two Generals Problem - When we have an unreliable network, which we always do, we cannot guarantee message receipt. - Instead we must be satisfied with either - At Most Once - At Least Once - Exactly Once
- 26. • Event Grid • Event Hubs • Service Bus Azure solution SERVICE PURPOSE TYPE WHEN TO USE Event Grid Reactive programming Event distribution (discrete) React to status changes Event Hubs Big data pipeline Event streaming (series) Telemetry and distributed data streaming Service Bus High-value enterprise messaging Message Order processing and financial transaction
- 27. Chaos Engineering Before starting your journey into chaos engineering, make sure you’ve done your homework and have built resiliency into every level of your organization. Building resilient systems isn’t all about software. It starts at the infrastructure layer, progresses to the network and data, influences application design and extends to people and culture. Adrian Hornsby
- 28. Chaos Engineering - Chaos engineering is a technique to meet the resilience requirement. - Chaos engineering can be use to achieve resilience against - Infrastructure failures - Network failures - Application failures The logo for Chaos Monkey used by Netflix Is the discipline of experimenting on a software system in production in order to build confidence in the system's capability to withstand turbulent and unexpected conditions.
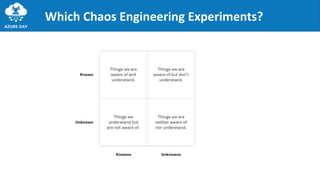
- 29. Which Chaos Engineering Experiments?
- 30. The Phases of Chaos Engineering It’s important to understand that chaos engineering is NOT about letting monkeys loose or allowing them to break things randomly without a purpose. Chaos engineering is about breaking things in a controlled environment, through well-planned experiments in order to build confidence in your application to withstand turbulent conditions. https://medium.com/@adhorn/chaos-engineering-ab0cc9fbd12a
- 31. Canary Deployment Canary deployment: Start small, and slowly build confidence within your team and your organization - How many customers are affected? - What functionality is impaired? - Which locations are imapcted?
- 32. New Tools One of the most efficient methods for uncovering misalignments in software is put the code together and run it. Continuos Integration was promoted heavily as part of XP methodology as a way to achieve this and is now a common industry norm. Continuos Delivery builds on the success of CI by automated the steps of preparing code and deploying it to an environment. CD tools allow engineers to choose a build that passed the CI stage and promote that through the pipeline to run in production. Like CI/CD, Continuos Verification is born out of a need to navigate increasingly complex systems. Modern organizations can’t validate that the internal machinations of the system work as intended, so instead they verify that the output of the system matches expectations.
- 33. Benefits of Chaos Engineering - Customer: the increased availability and durability of service means no outages disrupt their day-to-day lives. - Business: Chaos Engineering can help prevent extremely large losses in revenue and maintenance costs, create happier and more engaged engineers, improve in on-call training for engineering teams - Technical: the insights from chaos experiments can mean a reduction in incidents, reduction in on-call burden, increased understanding of system failure modes, improved system design
- 34. Designed for failure Common Characteristics Componentisation via services Organised around business capabilities Decentralised data management Products not projects Decentralised governance Smart endpoints and dumb pipes Evolutionary design Infrastructure automation designed for failure Chaos Engineering is an experiment to ensure that the impact of failures is mitigated. Adrian Crockcroft
- 35. Tools don’t create reliability. Human do. @CaseyRosenthal Thank You!!!
- 36. Tools don’t create reliability. Human do. [But tools can help.] @CaseyRosenthal Thank You!!!
- 37. • Reactive Manifesto • Asynchronous Message-Based-Communication (Microsoft) • Patterns For Resilient Architecture (Medium) • The Quest for Availability • Chaos Engineering • Availability modes for an Always On availability group • Configure availability group on Azure SQL Server VM manually Resources
- 38. Thanks to