




























FPGAによる大規模データ処理の高速化
- 1. © Hitachi, Ltd. 2018. All rights reserved. 株式会社 日立製作所 研究開発グループ デジタルテクノロジーイノベーションセンタ 藤本 和久 2018/2/17 FPGAによる大規模データ処理の高速化
- 2. © Hitachi, Ltd. 2018. All rights reserved. 本日の内容 1. ⼤規模データ処理の動向と課題 2. FPGAによるHadoopのデータ処理エンジンの⾼速化 3. FPGAによるアニーリングマシンの実現
- 3. © Hitachi, Ltd. 2018. All rights reserved. 1. ⼤規模データ処理の動向と課題
- 4. © Hitachi, Ltd. 2018. All rights reserved. 1-1 大規模データ処理のアプリ群 BigData解析やAI/MLは、OSSを組合わせて分散並列処理システムで実⾏ データソース Webデータ 売上情報など 構造化データ (業務RDB) センサデータ システムログ 音声 画像 非構造データ データ収集 ビックデータ蓄積 データ分析 Apache Manifold CF Apache Nutch クローラ Apache Sqoop Talend データロード Apache Kafka Apache Flume Fluentd 収集 Apache Spark Streaming Apache Storm Esper Drools Fusion Jubatus CEP Apache Hadoop HDFS Ceph GlusterFS Lustre ElasticSearch データ蓄積ファイルシステム Apache Hadoop MapReduce/YARN Apache Mesos Apache Spark Apache Tez 並列分散処理 TensorFlow Caffe MLib,など 機械学習 MIT Kerberos OpenLDAP セキュリティ/認証 インメモリDG/分散KVS Apache Cassandra Apache Hbase Infinispan MongoDB Redis Riak 定型業務RDB DWH/マートレスDB MySQL PostgreSQL ※商用DB (著名なOSSはない) 分析用データ 解析ツール Python, R言語 統計解析 Pentaho JasperReport BI/BAツール Apache Drill Apache Hive Apache Spark SQL Apache Impala 準リアルタイムクエリ Apache Sqoop データロード 高速化キャッシュ/スケールアウト インメモリDB VoltDB * OSS: Open Source Software
- 5. © Hitachi, Ltd. 2018. All rights reserved. 1-2 大規模データ処理の課題 分析データ量の増大 分析の高速化 サーバ導入コスト 電気代 管理コスト分析スピード 分析データ量 サーバを 増やしたい 現状の システム規模 TCO limit TCOを 減らしたい * TCO: Total Cost of Ownership (ITシステムの導入、維持・管理などにかかる総費用) ユーザニーズ
- 6. © Hitachi, Ltd. 2018. All rights reserved. 2. FPGAによるHadoopのデータ処理エンジン⾼速化
- 7. © Hitachi, Ltd. 2018. All rights reserved. 2-1 データ分析のニーズ ビッグデータを分析し,意思決定に活用するニーズの高まり ① データ規模・種別:大規模化,多様化(構造,半構造,非構造) • Data lakeに格納し,マートレスで分析 ⇒ Hadoop系分散データ処理基盤 ② データ分析の形態:レポーティング(バッチ処理)から、インタラクティブへ • ニアリアルタイムのデータ分析が必要 ⇒ 低レイテンシ,⾼速なデータ処理 ③ データ処理基盤:データベースアクセス(クエリ)の標準I/F活用 • RDBMSと同じI/F ⇒ SQLが⾼利便性
- 8. © Hitachi, Ltd. 2018. All rights reserved. 7 2-2 分散DBエンジン(SQL on Hadoop)の普及 標準SQL I/Fでアクセスし、インタラクティブな分析を提供する 分散DBエンジン(SQL on Hadoop)が普及 出展: DB-Engines Ranking http://db-engines.com/en/ranking_trend 図 DB-Engines Ranking(主要SQL on Hadoopを抜粋) Spark SQL Drill Hive Impala DBランキングスコア Jan2013 Jan2014 Jan2015 Jan2016 Jan2017 SQL onSQL onSQL onSQL on HadoopHadoopHadoopHadoop Jan2018 HDFS Spark YARN Hive Spark SQL MapMap Reduce Drill (MapR) データ 処理層 リソース 管理層 データ ストア層 MapR FS MapR FS クエリ 処理層 Impala SQL onSQL onSQL onSQL on HadoopHadoopHadoopHadoop
- 9. © Hitachi, Ltd. 2018. All rights reserved. 2-3 データ分析システムのボトルネック 8 ストレージ: 磁気ディスク(HDD)に代わり、フラッシュストレージが普及 データベース: テーブルフォーマットが、ローストアからカラムストアに変化 ⇒ データ分析のボトルネックが、ストレージ(I/O)からCPUに移動 CPUネックのため、インメモリDBにおいてもボトルネックは解消不可 *1 カラムストアDBは列単位のデータ操作に最適化した実装.補足1参照 サーバ ストレージ 性能向上 x10 – x100 HDD ローストア DB (分析用DB) データ 読み出し量1/30 ボトルネック CPU メモリ 従来 現在~将来 サーバ ストレージ カラムストアDB*1 (分析用DB) データ圧縮率の向上: 1/3 必要カラムだけの読み出し:1/10 ストレージの トータルの 性能向上 x300 - x3,000 CPU メモリボトルネック Flash SSDSSDSSDSSD
- 10. © Hitachi, Ltd. 2018. All rights reserved. 2-4 FPGAによるデータ分析処理の高速化 9 FPGAはSQL on Hadoop配下で動作し、ユーザからは⾒えない Scan/Filter, Group by, Aggregationを、並列・パイプライン処理して高速化 データ量を1/100〜1/10,000に削減して、ソフトウェア処理に渡す ⇒ リソース(CPU、ネットワーク)利⽤率の緩和 データレイク Hadoop分散ストレージ SQL on Hadoop(分散DBエンジン) ・・・ 分析ツール クエリ(SQL) データ量を1/100 から 1/10,000 に削減 DBテーブル FPGASSD FPGASSD PCIe SSD DBテーブル キーテクノロジー: 並列処理、パイプライン処理 FPGA(DBFPGA(DBFPGA(DBFPGA(DBアクセラレータアクセラレータアクセラレータアクセラレータ)))) DataDataDataData FilterFilterFilterFilter Scan/Scan/Scan/Scan/ FilterFilterFilterFilter AgregationAgregationAgregationAgregation
- 11. © Hitachi, Ltd. 2018. All rights reserved. 2-5 FPGAアクセラレータ効果例: デモ 10 ニューヨーク市のタクシー運⾏データの分析 (データ:256GB 15億⾏のテーブル) アクセラレータの有無による分析時間の比較 (分散DBエンジン: Apache Drill) 分析時間短縮: 数分 ⇒ 数秒 * FHV: For Hire Vehicle(Lyft, etc)
- 12. © Hitachi, Ltd. 2018. All rights reserved. 2-6 SQL on Hadoop-アクセラレータ連携における課題 11 ① OSS毎のアクセラレータ連携機能の作り込み工数大 ② 様々なデータタイプをサポートするOSS-DB標準フォーマットへの対応 データレイク Query(SQL) Impala SparkSQL Drill 要開発部分FPGA連携 FPGA連携FPGA連携FPGA連携 ・・・ ① 毎のアクセラレータ の作り込み工数大 ① OSS毎のアクセラレータ 連携機能の作り込み工数大 分析ツール Hadoop分散ストレージ DBテーブル (Apache Parquet) ② 様々なデータタイプをサポートする OSS の標準フォーマットへの対応 ② 様々なデータタイプをサポートする OSS-DBの標準フォーマットへの対応 *1 Apache Parquet: 標準カラムDBテーブルフォーマット.補足3参照 FPGASSD FPGASSD FPGASSD
- 13. © Hitachi, Ltd. 2018. All rights reserved. 2-7 課題を解決するコア技術 12 ① 連携機能モジュールをプラグイン化 ② 様々なデータ形式をFPGA回路で直接処理 Before クエリ 分散DB エンジン CPU データ SSD ・・・ ・・・ 数100サーバ必要 Hadoop 分散データ処理基盤 分析ツール After 分散DB エンジン ① プラグイン クエリ データ ② 多様なデータ形式 同等性能を数サーバで実現 Hadoop 分散データ処理基盤 分析ツール SSD I/F 2017/11/14ニュースリリース 「OSSベースでのビッグデータ分析を最大100倍に高速化する技術を開発」 http://www.hitachi.co.jp/rd/news/2017/1114.html FPGA データ
- 14. © Hitachi, Ltd. 2018. All rights reserved. Drillのソフトウェアスタック 2-8 OSS連携プラグイン 13 連携機能モジュールのインタフェースをOSSのAPIに合せる CPUに最適化された処理⼿順をFPGA内での並列処理⼿順に変換 After 分散DB エンジン 処理命令 データ 同等性能を数サーバで実現 Hadoop データ処理基盤 分析ツール I/F SQL Parser Query Optimizer Execution Engine Apache Calcite SQL Query クエリプラン 最適化ルール API プラグイン データ処理⼿順変換 FPGA Driver ① プラグイン ② 多様なデータ形式 SSD 処理 手順 データ 処理 手順 FPGA
- 15. © Hitachi, Ltd. 2018. All rights reserved. 2-9 OSS-DB標準フォーマット(Parquet)への対応 14 多種データ形式対応デコーダでデータをデコード デコードされた可変⻑データを、効率的にパッキングして並列処理する回路 After 分散DB エンジン プラグイン データ処理 手順変換 処理命令 データ 同等性能を数サーバで実現 Hadoop データ処理基盤 分析ツール I/F SSD ② 多様なデータ形式 データ 処理 手順 FPGA FPGA回路上の処理 集約回路 検索回路 出⼒回路 Optimized Parallelism データ⼊⼒回路 解析回路 様々なタイプ、サイズのデータ IntegerString DateString Time ・・・
- 16. © Hitachi, Ltd. 2018. All rights reserved. 15 ① プラグインが、Scan(/Filter),Groupby,AggregationをFPGAにオフロード ② データをSSDから直接読み出すことにより、CPUでのScanオーバーヘッドを解消 ③ FPGA内で、上記処理を並列&パイプライン実⾏、結果をDBエンジンに返す 2222----10101010 アーキテクチャアーキテクチャアーキテクチャアーキテクチャ Slave NodeSlave Node Node SQL-on-Hadoop (分散DBエンジン) メインメモリ 分析ツール HDFS on SSD データ (インメモリフォーマット) データ 処理結果 データリクエストデータリクエスト データ 3 - Filter Aggre-Aggre- gation FPGA プラグイン FPGA DriverFPGA Driver クエリ(SQL) 1I/F 2 Scan(/Filter),Groupby,Aggregation クエリ処理⼿順
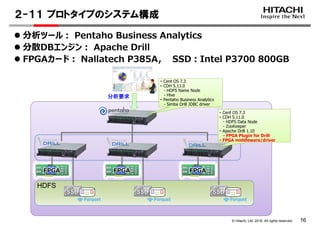
- 17. © Hitachi, Ltd. 2018. All rights reserved. 16 分析ツール: Pentaho Business Analytics 分散DBエンジン: Apache Drill FPGAカード: Nallatech P385A, SSD:Intel P3700 800GB 2-11 プロトタイプのシステム構成 HDFS 分析要求 Cent OS 7.3・ Cent OS 7.3 ・ CDH 5.11.0 - HDFS Name Node - Hive ・ Pentaho Business Analytics - Simba Drill JDBC driver ・・・・ FPGA middleware/driver ・ Cent OS 7.3 ・ CDH 5.11.0 - HDFS Data Node - ZooKeeper ・ Apache Drill 1.10 - FPGA Plugin for Drill ・・・・ FPGA middleware/driver FPGA FPGA FPGA SSD SSD SSD
- 18. © Hitachi, Ltd. 2018. All rights reserved. 2-12 ベンチマーク 17 プロトタイプシステムにて、TPC-Hベンチマークによる性能を比較 FPGAはQ1クエリで最大78倍、Q6クエリで最大19倍。 ⇒Aggregationの多いQ1クエリのほうが、FPGA並列処理の効果が出る 0 20 40 60 80 100 120 140 Q01 Drill SparkSQL Impala FPGA accel. 0 20 40 60 80 100 120 Q06 Drill SparkSQL Impala FPGA accel. 評価条件: ワーカノードサーバのスペック CPU: Xeon E5-2640 v4 2sockets(20cores@2.4GHz) Memory: 128GB NIC: 10GBASE-T CDH 5.11.0 (Hadoop Hadoop 2.6.0, Impala 2.8.0, +Spark 2.1.0)、Drill 1.10 データセットは、SF100(およそ100GB/600M⾏)のlineitem表。 (ただし、impalaはDATE型非サポートのため一部カラムをTIMESTAMP型に変更) クエリを数回実⾏してウォームアップした後に、3回計測した平均値を記載 FPGA FPGA Impala SparkSQL DrillDrill SparkSQL Impala M lines/sec・node M lines/sec・node
- 19. © Hitachi, Ltd. 2018. All rights reserved. 2-13 ユーザメリット: コスト,電力削減効果の一例 18 同等性能を実現するクラスター規模で、コストと消費電⼒を⽐較 FPGAアクセラレータ適用により性能が向上し,必要ノード数が削減 トータルのシステムコストと消費電⼒削減が期待できる 前提条件: • 対象データサイズ毎に、TPC-H/Q1を10秒間で処理するのに必要なクラスター規模で⽐較 • 20core CPU/サーバ、サーバ当たり1FPGAボード、1NVMe-SSD搭載 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 0.0TB 64.0TB 128.0TB 192.0TB 256.0TB システムコスト($M) 分析データサイズあたりシステムコスト 分析データサイズ (TB) TPC-H Q1 実⾏時間:10秒 0 5 10 15 20 25 30 35 40 0.0TB 64.0TB 128.0TB 192.0TB 256.0TB 消費電⼒(KW) 分析データサイズあたり消費電⼒ 分析データサイズ (TB) TPC-H Q1 実⾏時間:10秒
- 20. © Hitachi, Ltd. 2018. All rights reserved. 3. FPGAによるアニーリングマシンの実現
- 21. © Hitachi, Ltd. 2018. All rights reserved. 3-1 最適化の必要性 交通渋滞の解消 物流コスト最小化 エネルギー安定供給 分野 交通システム サプライチェーン 電力送電網 課題 最適化対象 入力パラメータ 制御パラメータ 最適化問題 計算量 交通量、移動コスト 交通状況 各車の目的地 信号、各車 最大フロー・最短経路 2n回: nは制御対象のパラメータ数 総移動コスト 拠点間の移動コスト 移動経路 巡回セールスマン 蓄電量、等 発電・消費電力量 経路容量 発電量、流路 最大フロー 膨大なパラメータ数に対するシステム最適化が必要 「組合せ最適化問題」は計算量が膨⼤となる
- 22. © Hitachi, Ltd. 2018. All rights reserved. 3-2 計算手法の革新による組合せ最適化の加速 問題規模 計算時間・消費電⼒ 指数関数的爆発! 従来型コンピュータ ノイマン型 本提案:アニーリングマシンによる改善 1,000,000パラメータ アニーリングマシン 非ノイマン型 計算手法の革新による 劇的な改善 最適化問題の計算コストは指数関数的に増大 複雑で大規模化する社会システムに従来手法を適用するのは困難
- 23. © Hitachi, Ltd. 2018. All rights reserved. 3-3 アニーリングマシンの原理 組合せ最適化問題をイジングモデルへマッピング イジングモデルでエネルギー最低の状態を探索し、もとの最適化問題 にもどして最適化問題の解を探索 イジングモデル: 個々のスピンの向き(上または下)が、スピン間の相互作用により 安定状態(=エネルギーが低い状態)に遷移するのを計算するモデル σ1 3つの要素で構成 ①スピン①スピン①スピン①スピン (σi) ②②②②相互作用係数相互作用係数相互作用係数相互作用係数 (Jij) ③バイアス係数③バイアス係数③バイアス係数③バイアス係数 (hi) σ2 σ3 σ4 σ5 σ6 σ7 σ8 σ9 エネルギー 最適状態 J12 J14 J47 h2 h3 h7 h4 : 上 : 下 最適化問題の解法に利⽤ スピンの状態 j j j ji jiij hJH σσσ ∑∑ −−= ,
- 24. © Hitachi, Ltd. 2018. All rights reserved. 3-4 さまざまな実装のアニーリングマシン 富士通 D-Wave NTT(ImPACT) ⽇⽴ 方式 シミュレーティド アニーリング(改) 量⼦アニーリン グ 光パラメトロン CMOS アニーリング 実装 FPGA 超伝導量⼦ビッ ト レーザー発振器 半導体CMOS FPGA 消費電⼒ ? × 15kW(冷却) 〇 ◎ 集積度 2017年 1k 2k 2k 20k (大規模化可能) サイズ サーバサイズ 冷凍機 (部屋の規模) サーバサイズ チップ 動作温度 〇室温 ×低温 (-273℃) 〇室温 〇室温 解精度 ? ○ ? △SQA 優位性・特徴 ・製品化済 ・クラウド化済 ・クラウド化済 ・温度変化に弱い ・低価格 ・エッジ・クラウド 対応 半導体/FPGAによる実装でエッジ・クラウドに搭載可能な低電⼒・ スケーラビリティ・小型化・室温動作・低コスト化を実現
- 25. © Hitachi, Ltd. 2018. All rights reserved. 3-5 FPGA版アニーリングマシンを用いたデモ 2. ドローン通信順序最適化1. 無線基地局の周波数割り当て 3. 通信網の堅牢性確保 4. 画像修復 6. 画像ノイズ除去 8. コミュニティのコア検出7. 施設配置 9. 機械学習(ブースティング) 5. 爆発物探知の高速化 検出検出 検出検出 さまざまなアプリ適用に向けたデモを実施
- 26. © Hitachi, Ltd. 2018. All rights reserved. 3-6 第3世代 FPGA版アニーリングマシンの性能 量⼦アニーリングマシンと同等の性能スケーラビリティでさらに大 規模の問題がターゲット 従来手法(Simulated annealing)では計算時間がかかりす ぎて解けない問題規模を狙う 50 問題規模 (スピン数) 5,000 計算時間(s) 500 1µ 1m D-Wave (量⼦アニーリングマシン) (2017) Simulated annealing (ソフト) 解精度 100% 1 1k 1M 1G 50,000 500,000 解精度 99.5% 解精度 100% ⽇⽴ (CMOSアニーリングマシン) 解精度 100%
- 27. © Hitachi, Ltd. 2018. All rights reserved. 3-7 アニーリングマシンの強化学習への適用 ニューラルネットワーク+DQN ボルツマンマシン(アニーリングマシン) +FERL DQN FERL 訓練数 30,000 300 時間 / 訓練 1 100 Back propagation (DQN) 平衡状態の期待値計算 (FERL) ⇒ 複数回サンプリング ニューラルネットワーク: ・ 学習に用いられるネット ワーク ・ 入力層から出力層にむけて 信号が伝播 ・ 訓練回数を2桁削減できる可能性あり 入力層 出力層 入力層 出力層 ボルツマンマシン: ・ 接続されたノードが相互 作用をするネットワーク (イジングモデルと同型) ・ 信号は双方向に伝わる FERL: Free Energy Reinforcement Learning アニーリングマシンをボルツマンマシンとして利⽤してニューラルネッ トワークを置換、強化学習の訓練回数を約2桁削減(1QBit社) 第3世代FPGA版プロトタイプ(32x4層)で同等の効果を確認 A. Levit et al., “Free-Energy-based Reinforcement Learning Using a Quantum Processor,” Theory of Quantum Computation, Communication and Cryptography TCQ 2017. DQN: deep Q-network
- 28. © Hitachi, Ltd. 2018. All rights reserved. Disclaimer 27 • The contents of this presentation are based on early research results. • This presentation does not reflect any product plan or business plan. • All information is provided as is, with no warranties or guarantees.
- 29. © Hitachi, Ltd. 2018. All rights reserved. END 28 MicrosoftおよびSQL Serverは、米国Microsoft Corporationの米国及びその他の国における登録商標または商標です。 Oracle、NySQLは、Oracle Corporation及びその子会社、関連会社の米国及びその他の国における登録商標です。 DB2は、米国International Business Machines Corp.の米国及びその他の国における登録商標です。 PostgreSQLは、PostgreSQLの米国およびその他の国における商標です。 SASは、米国およびその他の国における米国SAS Institute Inc.の登録商標または商標です。 Qlikは、QlikTech International ABの商標または登録商標です。 Tableauは、Tableau Software Inc.の商標または登録商標です。 、Apache、Hadoop、Hadoop MapReduce、Hadoop HDSFは、Apache Software Foundationの 米国及びその他の国における登録商標または商標です。 、HIVE、Spark、 Impala、Drill、Parquetは、Apache Software Foundationの米国及びその他の国に おける登録商標または商標です。