Gender, language, and Twitter: Social theory and computational methods
Download as PPTX, PDF1 like590 views

The document discusses the intersection of gender, language, and social networks, particularly focusing on how computational methods can predict speaker gender based on their language use on Twitter. It outlines the use of logistic regression and clustering techniques on a dataset of Twitter users to analyze gender differences in language, revealing complexities and challenges in understanding gender as a binary construct. The findings highlight that women and men exhibit different linguistic patterns, but also demonstrate that these patterns are not universally applicable and can vary across social contexts.




































![Majority female clusters
Size % fem Top words
c14 1,345 89.60%
hubs blogged bloggers giveaway @klout recipe fabric
recipes blogging tweetup
c7 884 80.40% kidd hubs xo =] xoxoxo muah xoxo darren scotty ttyl
c6 661 80.00% authors pokemon hubs xd author arc xxx ^_^ bloggers d:
c16 200 78.00%
xo blessings -) xoxoxo #music #love #socialmedia slash
:)) xoxo
c8 318 72.30% xxx :') xx tyga youu (: wbu thankyou heyy knoww
c5 539 71.10% (: :') xd (; /: <333 d: <33 </3 -___-
c4 1,376 63.00%
&& hipster #idol #photo #lessambitiousmovies hipsters
#americanidol #oscars totes #goldenglobes
c9 458 60.00%
wyd #oomf lmbo shyt bruh cuzzo #nowfollowing lls
niggas finna](https://image.slidesharecdn.com/twittergenderpresentationchicagoapr2014cleaned-up-140806161841-phpapp02-150731181930-lva1-app6892/85/Gender-language-and-Twitter-Social-theory-and-computational-methods-37-320.jpg)








































![Majority female clusters
Size % fem Top words
c14 1,345 89.60%
hubs blogged bloggers giveaway @klout recipe fabric
recipes blogging tweetup
c7 884 80.40% kidd hubs xo =] xoxoxo muah xoxo darren scotty ttyl
c6 661 80.00% authors pokemon hubs xd author arc xxx ^_^ bloggers d:
c16 200 78.00%
xo blessings -) xoxoxo #music #love #socialmedia slash
:)) xoxo
c8 318 72.30% xxx :') xx tyga youu (: wbu thankyou heyy knoww
c5 539 71.10% (: :') xd (; /: <333 d: <33 </3 -___-
c4 1,376 63.00%
&& hipster #idol #photo #lessambitiousmovies hipsters
#americanidol #oscars totes #goldenglobes
c9 458 60.00%
wyd #oomf lmbo shyt bruh cuzzo #nowfollowing lls
niggas finna](https://image.slidesharecdn.com/twittergenderpresentationchicagoapr2014cleaned-up-140806161841-phpapp02-150731181930-lva1-app6892/85/Gender-language-and-Twitter-Social-theory-and-computational-methods-79-320.jpg)







Gender, language, and Twitter: Social theory and computational methods
- 1. Gender, language and Twitter: Social theory and computational methods Tyler Schnoebelen (including work with David Bamman and Jacob Eisenstein) Tweet this talk! @Tschnoebelen
- 2. Welcome to the slide-u-ment • Hi, you may want to check out the “Notes” fields for additional context.
- 3. At its most basic
- 4. At its most basic • Assumption 1: Men and women use different vocabularies – Hypothesis I: Computational methods can cut through noise and predict speaker gender based on the words they use • Assumption 2: Social networks are typically “homophilous” (birds of a feather flock together) – Hypothesis II: Adding the gender make-up of a user’s social network should get even better prediction
- 6. Let’s say we can predict gender • So what? • Does it license us to connect words/word groups to the social category in question? • This assumes that gender is – Stable – The primary driving force
- 7. Our actual goal • Problematize gender prediction as a task – Define a system where we could just “stop” and call it good – But NOT ACTUALLY STOP • Demonstrate that simple gender binaries aren’t actually descriptively accurate • Show ways to combine social theory and computational methods that expand the questions on both sides
- 9. “Standard” is a keyword
- 10. Typical findings • Women use standard variables more often than men. – In fact, early dialectologists ignored women completely because they wanted “NORMS”—non-mobile, older, rural male speakers, seen as preserving the purest regional (non-standard) forms • See Chambers and Trudgill (1980). – Did they do it for prestige (to acquire social capital)? – To avoid losing status? – Are women actually creating norms, not following them?
- 11. Computational/corpus work • People are fascinated by gender differences • In order to get statistical significance, you have to have enough data where you can detect a signal • In the past, this has led researchers to roll up words into word classes
- 12. The most common distinctions • Men use informative language – Prepositions (to), attributive adjectives (fat), higher word lengths (gargantuan) • Women use involved language – First and second person pronouns (you), present tense verbs (goes), contractions (don’t) • (Argamon, Koppel, Fine, & Shimoni, 2003; Herring & Paolillo, 2006b; Schler, Koppel, Argamon, & Pennebaker, 2006…they are working off of dimensions in Biber 1995 and Chafe 1982)
- 13. Or “contextuality” • Men are formal and explicit – Nouns (floor), adjectives (big), prepositions (to), articles (the) • Women are deictic and contextual – Pronouns (you), verbs (run), adverbs (happily), interjections (oh!) • “Contextuality” decreases when an unambiguous understanding is more important or difficult—when people are physically or socially farther away • (Mukherjee & Liu, 2010; Nowson, Oberlander, & Gill, 2005 building off of Heylighen and Dewaele 2002)
- 14. Are all nouns really the same?
- 15. Are all nouns really the same?
- 16. And what about…
- 17. And what about…
- 18. Our approach also lumps • It’s just at a lower level – instead of “nouns” or “blog words” – we assume all usages of a unigram are identical • Lumping itself isn’t a problem. In fact, you have to. – But ideologies are going to structure your lumpings and divisions, so watch out!
- 19. OUR WORK (WITH DAVID BAMMAN AND JACOB EISENSTEIN)
- 20. Data • Public Twitter messages in same-gender and cross-gender social networks – Word frequencies (unigrams) – Gender (induced from first names using the Social Security Administration data) • 14,464 Twitter users (56% male) – Geolocated in the US – Must use 50 of top 1,000 most frequent words – Between 4 and 100 ties (at least 2 “mutual @’s” separated by 14 days) • Women have 58% female friends • Men have 67% male friends • 9.2M tweets, Jan-Jun 2011
- 21. Twitter has a pretty good swath (Pew) • Nearly identical usage among women and men: – 15% of female internet users are on Twitter – 14% of male internet users • High usage among non-Hispanic Blacks (28%) • Even distribution across income and education levels • Higher usage among young adults (26% for ages 18-29, 4% for ages 65+)
- 22. First names are highly gendered 100 97 86 15 0 0 3 14 85 100 0 20 40 60 80 100 Matt Alex Chris Kelly Sarah % female % male 95% of users have a name 85% associated with one gender Median user name is 99.6% associated with its majority gender
- 23. First step: gender prediction • Logistic regression: – Will you have a heart attack Y/N? – Will you vote for X or Y? – Will your Brazilian Portuguese nouns and modifiers agree in number? • Logistic regression is the statistical technique at the core of variable rule analysis (Tagliamonte 2006) • But we’re going to reverse the direction for what sociolinguists typically do
- 24. First step: gender prediction • The relevant linguistic variables aren’t known beforehand • So the dependent variable—the thing we are trying to predict—is author gender • The independent variables are the 10,000 most frequent lexical items in the tweets
- 25. Preventing overfitting • This involves estimating a lot of parameters. • Which raises the risk of overfitting: learning parameter values that perfectly describe the training data but won’t generalize to new data
- 26. Why regularize? Regularization dampens the effect of an individual variable (Hastie et al 2009). A single regularization parameter controls the tradeoff between perfectly describing the training data and generalizing to unseen data.
- 27. Evaluating accuracy • We use the typical method of cross-validation. 1. Randomly divide the full dataset into 10 parts. 2. Train on 80% of the data 3. Use 10% of the data to tune the regularization parameter 4. Now, use the model to predict the other 10% 5. Compare the predictions to what really happened • Do this 10 times and take the average.
- 28. Gender prediction results • State-of-the-art accuracy: 88.0% – Lexical features strongly predict gender – Ignoring syntax (treating tweets as “bags of words”) does pretty good
- 29. Previous literature In our data Pronouns F F Emotion terms F F Family terms F Mixed results "Blog words" (lol, omg) F F Conjunctions F F (weakly) Articles M No results Numbers M M Quantifiers M No results Technology words M M Prepositions Mixed results F (weakly) Swear words Mixed results M Assent Mixed results Mixed results Negation Mixed results Mixed results Emoticons Mixed results F Hesitation markers Mixed results F Top 500 markers for each gender
- 30. At a corpus level, women use more non-dictionary words and men use more named entities. In a moment we’ll ask how universal this is. Hand classification of most frequent 10k words (90.0% agreement) Female authors Male authors Common words in a standard dictionary 74.2% 74.9% Punctuation 14.6% 14.2% Non-standard, unpronounceable words (e.g., :), lmao) 4.28% 2.99% Non-standard, pronounceable words (e.g., luv) 3.55% 3.35% Named entities 1.94% 2.51% Numbers 0.83% 0.99% Taboo words 0.47% 0.69% Hashtags 0.16% 0.18%
- 31. Involvement • Using traditional definitions, it looks as if our data confirms: – men as more informational (all those named entities) – women as more interactive/involved (pronouns, emoticons, etc.) • Note that most of the named entities for the men are sports figures and teams
- 32. Right. These guys are not “involved”.
- 34. Clustering without regard to gender • We apply probabilistic clustering in order to group authors who are linguistically similar • Each author is represented as a list of word counts across the 10,000 words used in the classification experiment
- 35. Clustering! (Hastie et al 2009) Easy example: 2 clusters “Expectation Maximization” 1. Randomly assign all authors to one of 20 clusters 2. Calculate the center of the cluster from the average word counts of all authors put in it 3. Assign each author to the nearest cluster, based on the distance between their word counts and the average word counts of the cluster center 4. Keep iterating through this moving from random clustering to meaningful clusters 5. Repeat steps 1-4 (25 times) 6. Pick the best
- 36. Some definitions • Style: combinations of linguistic resources • Cluster: a group of authors who use a particular style • Social network: each author has a social network made up of people who they send AND receive messages from • An author’s social network does not have to be a part of that author’s cluster
- 37. Majority female clusters Size % fem Top words c14 1,345 89.60% hubs blogged bloggers giveaway @klout recipe fabric recipes blogging tweetup c7 884 80.40% kidd hubs xo =] xoxoxo muah xoxo darren scotty ttyl c6 661 80.00% authors pokemon hubs xd author arc xxx ^_^ bloggers d: c16 200 78.00% xo blessings -) xoxoxo #music #love #socialmedia slash :)) xoxo c8 318 72.30% xxx :') xx tyga youu (: wbu thankyou heyy knoww c5 539 71.10% (: :') xd (; /: <333 d: <33 </3 -___- c4 1,376 63.00% && hipster #idol #photo #lessambitiousmovies hipsters #americanidol #oscars totes #goldenglobes c9 458 60.00% wyd #oomf lmbo shyt bruh cuzzo #nowfollowing lls niggas finna
- 38. Looks like “women are trying to destroy the English language” Female authors Male authors Common words in a standard dictionary 74.2% 74.9% Punctuation 14.6% 14.2% Non-standard, unpronounceable words (e.g., :), lmao) 4.28% 2.99% Non-standard, pronounceable words (e.g., luv) 3.55% 3.35% Named entities 1.94% 2.51% Numbers 0.83% 0.99% Taboo words 0.47% 0.69% Hashtags 0.16% 0.18%
- 39. Clusters that are majority female • At the population level, women use many non- dictionary words. • But there are clusters of (mostly) women who actually use fewer words like lol, nah, haha than men do Size % fem Top words c14 1,345 89.60% hubs blogged bloggers giveaway @klout recipe fabric recipes blogging tweetup c6 661 80.00% authors pokemon hubs xd author arc xxx ^_^ bloggers d: c4 1,376 63.00% && hipster #idol #photo #lessambitiousmovies hipsters #americanidol #oscars totes #goldenglobes
- 40. Consider xo • A lot more women use xo than men – 11% of all women – 2.5% of all men • But that means that 89% of women aren’t using it at all. • People who use xo are three times more likely to use ttyl (‘talk to you later’) – The style is more commonly adopted by women – But there’s other stuff going on here: age, job, etc. – It’s not clear that gender is even the most important, it’s just that we’re starting with gender-colored glasses
- 41. Shit Girls Say http://www.youtube.com/watch?feature=player_embedded&v=u-yLGIH7W9Y
- 42. Meme-splosion!
- 43. Group Gender Activity/social role Interactions Geography Shit Guys Don't Say Out Loud Shit College Freshmen Say Shit Girlfriends Say Shit Asian Dads Say Shit Redneck Guys Say Shit Girls Say to Gay Guys Say Shit Black Girls Say Say Shit Black Guys Say Say Shit People Say in LA Shit White Girls Say…to Black Girls Shit New Yorkers Say Shit Frat Guys Say Shit Whipped Guys Say Shit Guys Don't Say Say Shit Asian Girls Say Shit Tumblr Girls Say Shit Brides Say Shit Spanish Girls Say Shit Asian Moms Say Shit Vegans Say Shit Hipsters Say Shit Cyclists Say Shit Yogis Say Shit Skiers Say
- 44. Notice • That gender wasn’t really limited to the “gender” column – “Moms” and “dads” are gendered social roles • And that the words “guys” and “girls” aren’t really the same as “male” and “female” – What are the plausible age ranges and social styles for “guys” and “girls”?
- 45. Clusters that are majority male Size % male Top words c13 761 89.40% #nhl #bruins #mlb nhl #knicks qb @darrenrovell inning boozer jimmer c10 1,865 85.40% /cc api ios ui portal developer e3 apple's plugin developers c18 623 81.10% @macmiller niggas flyers cena bosh pacers @wale bruh melo @fucktyler c11 432 73.80% niggas wyd nigga finna shyt lls ctfu #oomf lmaoo lmaooo c20 429 72.50% gop dems senate unions conservative democrats liberal palin republican republicans c15 963 65.30% #photo /cc #fb (@ brewing #sxsw @getglue startup brewery @foursquare
- 46. Looks like “men are Twitter-headed sailor-swearing accountants” Female authors Male authors Common words in a standard dictionary 74.2% 74.9% Punctuation 14.6% 14.2% Non-standard, unpronounceable words (e.g., :), lmao) 4.28% 2.99% Non-standard, pronounceable words (e.g., luv) 3.55% 3.35% Named entities 1.94% 2.51% Numbers 0.83% 0.99% Taboo words 0.47% 0.69% Hashtags 0.16% 0.18%
- 47. Aggregates generally don’t hold Top words Notes c13 #nhl #bruins #mlb nhl #knicks qb @darrenrovell inning boozer jimmer Few Taboo/Hashes Lots of Punc c10 /cc api ios ui portal developer e3 apple's plugin developers Few Taboo/Hashes Lots of Punc c18 @macmiller niggas flyers cena bosh pacers @wale bruh melo @fucktyler c11 niggas wyd nigga finna shyt lls ctfu #oomf lmaoo lmaooo Few Dict words, Lots of unPron and Pron c20 gop dems senate unions conservative democrats liberal palin republican republicans Few Taboo/Hashes Lots of Punc c15 #photo /cc #fb (@ brewing #sxsw @getglue startup brewery @foursquare Few Taboo Lots of Punc
- 48. Small exceptions • At the population level, men use many named entities and numbers • Clusters use these at various rates, but: – No female-skewed clusters use them *more* than the male average – No male-skewed clusters use them *less* than the female average • But again, the other 6 generalizations about gender we might have made at an aggregate aren’t supported once we get to clusters
- 49. Erasure! • Clusters are highly gendered • For example, let’s consider clusters made up of 60% or more of people of the same gender – That covers 82.95% of all the authors – But what about the 1,242 men who are part of female-majority clusters? – The 1,052 women who are part of male-majority clusters? – Are they just noise? Odd-balls? Is there no structure to what they’re doing? – These people are using language to do identity work, even as they construct identities at odds with conventional notions of masculinity and femininity.
- 50. Clusters vs. social networks • The more skewed a cluster is, the more skewed the social networks of its members 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 3 4 5 6 7 8 9 10 11 13 14 15 16 17 18 19 20 percent male percentmalefriends
- 51. Women with female networks use the most female markers 1 2 3 4 5 6 7 8 9 10 0.20.40.60.81.0 female authors percent female social network femalemarkerproportion
- 52. Men with male networks use the most male markers 1 2 3 4 5 6 7 8 9 10 0.00.20.40.60.8 male authors percent male social network malemarkerproportion
- 53. Women with male networks use more male markers (and vice versa)
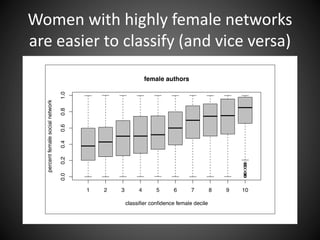
- 54. Women with highly female networks are easier to classify (and vice versa)
- 55. In other words • The classifier is picking up on the fact that if you insist upon a gender binary then people with same-gender networks use language in a more “gender-coherent” way.
- 56. Does social network help prediction? • 88% accuracy with text alone – Logistic regression, 10-fold cross-validation – State-of-the-art accuracy • Add network information… – Still 88% accuracy
- 57. Once we have 1000 words/author, network info doesn’t help Words Accuracy 0.50.60.70.80.91.0 0 10 100 1,000 10,000 all words plus social network words only 0.880
- 58. Wait, why not? • A new feature is only going to improve classification accuracy if it adds new information. • There is strong homophily: 63% of the connections are between same-gender individuals. • But language and social network can’t mutually disambiguate because they aren’t independent views on gender. • Individuals who use linguistic resources from “the other gender” consistently have denser social network connections to the other gender. – Performance, style, accommodation • Gender is not an “A or B” kind of thing
- 59. If we seek only predictive accuracy…
- 60. We’re awesome!
- 61. Not so simple • If we want to understand categories, we should start with people in interactions. – Counting is great but we have to watch our bins and investigate them, too.
- 62. Look at words a different way
- 63. Not markers…
- 65. Positioning
- 66. Positioning and stance • “Stance” is usually seen as an expression of a speaker’s relationship to their talk and their interlocutors – E.g., Kiesling (2009); Du Bois (2007); Bednarek (2008) • But “stance” (and “roles”) seem static • I’d like something with more motion and dynamism
- 67. Positioning and stance • “Stance” is usually seen as an expression of a speaker’s relationship to their talk and their interlocutors – E.g., Kiesling (2009); Du Bois (2007); Bednarek (2008) • But “stance” (and “roles”) seem static • I’d like something with more motion and dynamism • I develop positioning to connect linguistic forms to social structures • (Particularly affect, actually)
- 68. Positioning in a social grid
- 70. Positioning in a social grid • Social structures are created, maintained, and changed by specific interactions • People enter interactions already positioned • Interactions change these positions, people are attentive to changes
- 71. Conventions • Different linguistic resources come to be associated with different positionings • Distributions of experiences are usually maintained • The maintenance and disruption of expectations has (affective) consequences
- 72. A LITTLE BIT OF LITTLE
- 73. CHILDES (MacWhinney, 2000) • 4,676 transcripts of parent-child interactions – American English Observed little Expected little O/E Mothers-to-boys 4,313 4,158 1.037 Fathers-to-boys 1,516 1,381 1.098 Mothers-to-girls 6,312 5,441 1.160 Fathers-to-girls 230 281 0.819 Girls-to-mothers 1,221 1,533 0.796 Girls-to-fathers 4 3 1.482 Boys-to-mothers 875 1,526 0.573 Boys-to-fathers 117 265 0.441
- 74. Gender and little • Women tend to use little more—multiple corpora show significant differences • But this misses the point Buckeye OE CALLHOME OE Female 1.170 1.073 Male 0.855 0.725
- 75. Add interlocutor gender CHILDES Parent- Child OE CHILDES Child- Parent OE Buckeye OE Fisher Am. Eng. OE Fisher Ohioans OE CALLHOME OE Female to female 1.160 0.796 0.936 1.051 1.160 1.088 Female to male 1.037 1.482 1.290 0.887 0.771 1.064 Male to male 1.098 0.441 0.879 1.071 0.830 0.685 Male to female 0.819 0.573 0.908 0.842 0.836 0.727
- 76. Gender and topics • Some topics are more face-threatening than others. – Face-threatening topics get less little. • When topic is held constant, men and women mostly have the same little usage . – Regardless of the gender of the person they’re talking to. • But there are some exceptions, which are connected to issues of masculinity, femininity, and emotional regulation. – Some examples: • Generally, people don’t use little to talk about terrorism. EXCEPT women speaking to women use little to modify emotions (terrified, scared) • Generally, people DO use little to talk about fitness. EXCEPT men talking to men. The men talking to women use little to talk about their pudgy, flabby bodies. The few men talking to men who use little use it to talk about working out a little harder or putting on a little more muscle mass.
- 77. ICSI meeting corpus (Janin et al., 2003) • 75 meetings from Berkeley’s International Computer Science Institute (2000-2002) – 3-10 participants (avg of 6) – 17-103 minutes each (usually an hour) – 72 hours of data # speakers (avg age) Observed little Expected little O/E Undergrad 6 (30 yo) 59 34 1.734 Grad 14 (29 yo) 234 223 1.049 Postdoc 1 (not given) 51 75 0.676 Ph.D. 11 (37 yo) 152 228 0.667 Professor 4 (52 yo) 278 213 1.302
- 78. Gender, genre, topic, style • “Different ways of saying things are intended to signal different ways of being, which includes different potential things to say.” (Eckert 2008)
- 79. Majority female clusters Size % fem Top words c14 1,345 89.60% hubs blogged bloggers giveaway @klout recipe fabric recipes blogging tweetup c7 884 80.40% kidd hubs xo =] xoxoxo muah xoxo darren scotty ttyl c6 661 80.00% authors pokemon hubs xd author arc xxx ^_^ bloggers d: c16 200 78.00% xo blessings -) xoxoxo #music #love #socialmedia slash :)) xoxo c8 318 72.30% xxx :') xx tyga youu (: wbu thankyou heyy knoww c5 539 71.10% (: :') xd (; /: <333 d: <33 </3 -___- c4 1,376 63.00% && hipster #idol #photo #lessambitiousmovies hipsters #americanidol #oscars totes #goldenglobes c9 458 60.00% wyd #oomf lmbo shyt bruh cuzzo #nowfollowing lls niggas finna
- 80. Clusters that are majority male Size % male Top words c13 761 89.40% #nhl #bruins #mlb nhl #knicks qb @darrenrovell inning boozer jimmer c10 1,865 85.40% /cc api ios ui portal developer e3 apple's plugin developers c18 623 81.10% @macmiller niggas flyers cena bosh pacers @wale bruh melo @fucktyler c11 432 73.80% niggas wyd nigga finna shyt lls ctfu #oomf lmaoo lmaooo c20 429 72.50% gop dems senate unions conservative democrats liberal palin republican republicans c15 963 65.30% #photo /cc #fb (@ brewing #sxsw @getglue startup brewery @foursquare
- 81. Gender is not something people have
- 82. It’s something people *do* And there are a lot of ways to “do” gender.
- 84. Gender is binary only with blinders • “My mom doesn’t say that’s lovely or omg!...” – “Nevermind that!” • Problem: Sliding from predictive accuracy to causal stories • Realistic finding: There are lots of ways to do gender
- 85. Big data, big opportunities • Big data offers us the opportunity to let clusters emerge (and test them against our big bins) • We can show how language reflects and creates the social worlds we live in
- 86. THANKS!
Editor's Notes
- #10: E.g., Cheshire (2004), Cameron & Coates (1989), Eckert & McConnell-Ginet (1999), Holmes (1997), or Romaine (2003).
- #13: (Argamon, Koppel, Fine, & Shimoni, 2003; Herring & Paolillo, 2006b; Schler, Koppel, Argamon, & Pennebaker, 2006…they are working off of dimensions in Biber 1995 and Chafe 1982)
- #14: (Mukherjee & Liu, 2010; Nowson, Oberlander, & Gill, 2005 building off of Heylighen and Dewaele 2002)
- #19: We also ran our work with part-of-speech tagged unigrams for one level less lumping—the results are basically the same but not reported here.
- #21: We only select users with first names that occur over 1,000 times in the census data (approximately 9,000 names), the most infrequent of which include Cherylann, Kailin and Zeno. We further filtered our sample to only those individuals who are actively engaging with their social network. Twitter contains an explicit social network in the links between individuals who have chosen to receive each other’s messages. However, Kwak, Lee, Park, and Moon (2010) found that only 22 percent of such links are reciprocal, and that a small number of hubs account for a high proportion of the total number of links. Instead, we define a social network based on direct, mutual interactions. In Twitter, it is possible to address a public message towards another user by prepending the @ symbol before the recipient’s user name. We build an undirected network of these links. To ensure that the network is mutual and as close of a proxy to a real social network as possible, we form a link between two users only if we observe at least two mentions (one in each direction) separated by at least two weeks. This filters spam accounts, unrequited mentions (e.g., users attempting to attract the attention of celebrities), and one-time conversations. We selected only those users with between four and 100 mutual-mention friends. The upper bound helps avoid ‘broadcast-oriented’ Twitter accounts such as news media, corporations, and celebrities. --e.g., The Social Security Administration says: Tyler is a male name 97.36% of the time Annette is a female name 100% of the time Robin is female 87.69% of the time
- #23: Some names are ambiguous by gender, but in our dataset, such ambiguity is rare: the median user has a name that is 99.6% associated with its majority gender; 95% of all users have name that is at least 85% associated with its majority gender. We assume that users tend to self-report their true name; while this may be largely true on aggregate, there are bound to be exceptions. Our analysis therefore focuses on aggregate trends and not individual case studies. A second potential concern is that social categories are not equally relevant in every utterance. But while this is certainly true in some cases, it is not true on aggregate — otherwise, accurate gender prediction from text would not be possible. Later, we address this issue by analyzing the social behavior of individuals whose language is not easily associated with their gender.
- #24: All words were converted to lower-case but no other preprocessing or stopword filtering was performed.
- #26: Basically you train on part of the data but hold out part of it to tune the regularization parameter.
- #27: Example: If a single word, like indubitably were used three times by men and never by women, an overfit model would have high confidence that anyone who uses indubitably is a man, regardless of other words they use That would be dumb. So we use regularization.
- #28: The accuracy in gender prediction by this method is 88.0%, which is state of the art compared with gender prediction on similar datasets (Burger et al. 2011). While more expressive features might perform better still, the high accuracy of lexical features shows that they capture a great deal of language’s predictive power with regard to gender.
- #29: More specifically, we apply the standard machine learning technique of logistic regression (Hastie, Tibshirani, & Friedman, 2009) . The model learns a column vector of weights w to parametrize a conditional distribution over labels (gender) as , where and x represents a column vector of term frequencies. The weights are chosen to maximize the conditional likelihood P(y| x; w) on a training set, using quasi-Newton optimization. To prevent overfitting of the training data, we use standard L2 regularization; this is equivalent to ridge regression in linear regression models. As features, we used a boolean indicator for each of the most frequent 10,000 words in the dataset. Train a statistical model on part of the data. Logistic regression (Hastie, Tibshirani, & Friedman, 2009) Test it on a different part of the data, hiding the gender labels. 10-fold cross-validation: 10 unique training/test splits (so the test is a different 10% of the data)
- #30: Not shown: Clitics: previous lit “F”, our data: weakly “F”
- #31: Because the counts are so high, all differences are statistically significant at p < 0.01. Hand-classified by two authors, disagreements decided by discussion between all three authors.
- #34: But categories are never simply descriptive; they are normative statements that draw lines around who is included and excluded (Butler 1990).
- #35: Expectation-maximizing (EM) algorithm (Dempster et al., 1977); basically k-means with log-linear distributions (Eisenstein, Ahmed, and Xing, ICML 2011) 25 runs with randomly generated Q(zn=k) and select the iteration with the highest joint likelihood. Each author is assigned a distribution over clusters ; each cluster has a probability distribution over word counts and a prior strength . In the EM algorithm, these parameter are iteratively updated until convergence. The probability distribution over words uses the Sparse Additive Generative Model (Eisenstein, Ahmed, and Xing 2011), which is especially well suited to high-dimensional data like text. For simplicity, we perform a hard clustering, sometimes known as hard EM. Since the EM algorithm can find only a local optimum, we make 25 runs with randomly-generated initial assignments, and select the run with the highest likelihood.
- #36: Each cluster is associated with a probability distribution over text and each author is placed in a cluster with the best probabilistic fit for their language. The maximum-likelihood solution is the clustering that assigns the greatest probability to all of the observed text.
- #39: Because the counts are so high, all differences are statistically significant at p < 0.01. Hand-classified by two authors, disagreements decided by discussion between all three authors.
- #40: That is, we’re comparing these clusters’ rates with the aggregated-men’s rates. We’re reporting the clusters that are significantly different. (In other words, women in these three clusters are using lol-like words significantly less than men-on-a-whole do. If women were really non-standard across the board, we wouldn’t expect any clusters to use less than the aggregated MALE number.)
- #44: These are some of the most popular “Shit X Say” videos. Notice that “Gender” is not limited to the “gender” category—e.g., ”girls” does not include “elderly women” and “Moms” doesn’t really include teenagers (even if they are young mothers).
- #47: Because the counts are so high, all differences are statistically significant at p < 0.01. Hand-classified by two authors, disagreements decided by discussion between all three authors.
- #63: Christopher Wool exhibit going on right now!
- #64: Words are social (even when the speaker is alone). Interlocutors aren’t just listening for meaning, they are constructing and imposing it. From the facial analysis literature: “Perceivers are imposing, rather than detecting, categorical distinctions in the facial configurations that they rate” (Barrett 2006: 23).
- #66: On this view, language does not reveal gender as a binary category; rather, linguistic resources are used to position oneself relative to one’s audience. Gender emerges indirectly, and to the extent that a linguistic resource indexes gender, it is pointing to (and creating) the habitual, repeated, multifaceted positionings inherent in every situated use of language.
- #67: A person's expression of their relationship to their talk (their epistemic stance--e.g., how certain they are about their assertions), and a person's expression of their relationship to their interlocutors (their interpersonal stance--e.g., friendly or dominating)
- #68: I developed my ideas about positioning out of the data, but the metaphor is powerful and after I was mostly done, I found that Rom Harré and colleagues had made their own explorations/elaborations of “positioning”. We took different paths to a fairly similar end point. I’m happy to have my work be considered an extension of his.
- #69: “You” and “I” aren’t references to objects independent of time and space They are momentary status updates (Harré, 1983) Even when they aren’t explicitly there, you and I are there—our talk relates us to each other
- #71: 1b:But the structure does impose constraints on interactions (Bourdieu, 1977; Butler, 1999; Giddens 1984) 3: citation (Goffman 1981) 3b: People make use of conversational forms and strategies that are available to them (Harré, 1986; Vygotsky, 1962)
- #72: 2b: Expectations are maintained 2c: People are enabled and constrained by these expectations
- #73: It’s a “female marker” in Twitter.
- #84: But categories are never simply descriptive; they are normative statements that draw lines around who is included and excluded (Butler 1990).
- #85: And we can’t trust the idea that we’ll just figure out each of the independent parts—if we figure out “woman” and “African American” then we’ll understand “African American women”.
- #87: ----- Meeting Notes (4/21/14 10:03) ----- Sports teams and gender, Americanness, "doing sports teams” (not “doing gender”) Online utterances: we can tailor, we can delete, how feed in to this Tried to take into account time of tweet, predictors of spelling out words Apply techniques like LDA or hierarchical model, maybe person is drawing from clusters. Gender or cluster. People are distributions over topics. Fisher topics vs. Twitter topics Statistican asks about using clusters to predict gender, then realizes I’m moving the goalposts