Hoard: A Scalable Memory Allocator for Multithreaded Applications
Download as PPT, PDF4 likes2,611 views

Hoard is a scalable memory allocator designed for multithreaded applications, aimed at addressing bottlenecks in parallel memory allocation. It utilizes a unique approach with local heaps and a global heap to manage memory efficiently while minimizing fragmentation and avoiding false sharing. Experimental results demonstrate that Hoard's performance is on par with uniprocessor allocators, exhibiting excellent speed, scalability, and low memory consumption across various benchmarks.



![Uniprocessor Allocators on Multiprocessors Fragmentation: Excellent Very low for most programs [Wilson & Johnstone] Speed & Scalability: Poor Heap contention a single lock protects the heap Can exacerbate false sharing different processors can share cache lines](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-4-320.jpg)




![Multiprocessor Allocator II: Private Heaps with Ownership Private heaps with ownership: free puts memory back on the originating processor 's heap. Avoids unbounded memory consumption Examples: ptmalloc [Gloger], LKmalloc [Larson & Krishnan] x1= malloc(s) free(x1) free(x2) x2= malloc(s) processor 1 processor 2](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-9-320.jpg)




![Summary of Analytical Results Worst-case memory consumption: O(n log M/m + P ) [instead of O( P n log M/m)] n = memory required M = biggest object size m = smallest object size P = number of processors Best possible: O(n log M/m) [Robson] Provably low synchronization in most cases](https://image.slidesharecdn.com/hoard-a-scalable-memory-allocator-for-multithreaded-applications-13641/85/Hoard-A-Scalable-Memory-Allocator-for-Multithreaded-Applications-14-320.jpg)






Hoard: A Scalable Memory Allocator for Multithreaded Applications
- 1. Hoard: A Scalable Memory Allocator for Multithreaded Applications Emery Berger , Kathryn McKinley * , Robert Blumofe, Paul Wilson Department of Computer Sciences * Department of Computer Science
- 2. Motivation Parallel multithreaded programs becoming prevalent web servers, search engines, database managers, etc. run on SMP’s for high performance often embarrassingly parallel Memory allocation is a bottleneck prevents scaling with number of processors
- 3. Assessment Criteria for Multiprocessor Allocators Speed competitive with uniprocessor allocators on one processor Scalability performance linear with the number of processors Fragmentation (= max allocated / max in use) competitive with uniprocessor allocators worst-case and average-case
- 4. Uniprocessor Allocators on Multiprocessors Fragmentation: Excellent Very low for most programs [Wilson & Johnstone] Speed & Scalability: Poor Heap contention a single lock protects the heap Can exacerbate false sharing different processors can share cache lines
- 5. Allocator-Induced False Sharing Allocators cause false sharing! Cache lines can end up spread across a number of processors Practically all allocators do this processor 1 processor 2 x2 = malloc(s); x1 = malloc(s); A cache line thrash… thrash…
- 6. Existing Multiprocessor Allocators Speed: One concurrent heap (e.g., concurrent B-tree): too expensive too many locks/atomic updates O(log n) cost per memory operation Fast allocators use multiple heaps Scalability: Allocator-induced false sharing and other bottlenecks Fragmentation: P-fold increase or even unbounded
- 7. Multiprocessor Allocator I: Pure Private Heaps Pure private heaps : one heap per processor. malloc gets memory from the processor's heap or the system free puts memory on the processor's heap Avoids heap contention Examples: STL, ad hoc (e.g., Cilk 4.1) x1= malloc(s) free(x1) free(x2) x3= malloc(s) x2= malloc(s) x4= malloc(s) processor 1 processor 2 = allocated by heap 1 = free, on heap 2
- 8. How to Break Pure Private Heaps: Fragmentation Pure private heaps : memory consumption can grow without bound! Producer-consumer: processor 1 allocates processor 2 frees free(x1) x2= malloc(s) free(x2) x1= malloc(s) processor 1 processor 2 x3= malloc(s) free(x3)
- 9. Multiprocessor Allocator II: Private Heaps with Ownership Private heaps with ownership: free puts memory back on the originating processor 's heap. Avoids unbounded memory consumption Examples: ptmalloc [Gloger], LKmalloc [Larson & Krishnan] x1= malloc(s) free(x1) free(x2) x2= malloc(s) processor 1 processor 2
- 10. How to Break Private Heaps with Ownership:Fragmentation Private heaps with ownership: memory consumption can blowup by a factor of P. Round-robin producer-consumer: processor i allocates processor i+1 frees This really happens (NDS). free(x2) free(x1) free(x3) x1= malloc(s) x2= malloc(s) x3=malloc(s) processor 1 processor 2 processor 3
- 11. So What Do We Do Now?
- 12. The Hoard Multiprocessor Memory Allocator Manages memory in page-sized superblocks of same-sized objects - Avoids false sharing by not carving up cache lines - Avoids heap contention - local heaps allocate & free small blocks from their set of superblocks Adds a global heap that is a repository of superblocks When the fraction of free memory exceeds the empty fraction , moves superblocks to the global heap - Avoids blowup in memory consumption
- 13. Hoard Example Hoard : one heap per processor + a global heap malloc gets memory from a superblock on its heap. free returns memory to its superblock . If the heap is “too empty”, it moves a superblock to the global heap. x1= malloc(s) processor 1 global heap free(x7) … some mallocs … some frees Empty fraction = 1/3
- 14. Summary of Analytical Results Worst-case memory consumption: O(n log M/m + P ) [instead of O( P n log M/m)] n = memory required M = biggest object size m = smallest object size P = number of processors Best possible: O(n log M/m) [Robson] Provably low synchronization in most cases
- 15. Experiments Run on a dedicated 14-processor Sun Enterprise 300 MHz UltraSparc, 1 GB of RAM Solaris 2.7 All programs compiled with g++ version 2.95.1 Allocators: Hoard version 2.0.2 Solaris (system allocator) Ptmalloc (GNU libc – private heaps with ownership) mtmalloc (Sun’s “MT-hot” allocator)
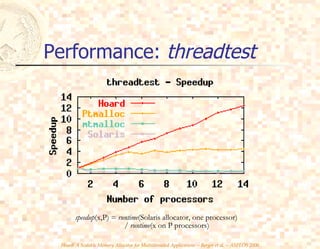
- 16. Performance: threadtest speedup (x,P) = runtime (Solaris allocator, one processor) / runtime (x on P processors)
- 17. Performance: Larson Server-style benchmark with sharing
- 18. Performance: false sharing Each thread reads & writes heap data
- 19. Fragmentation Results On most standard uniprocessor benchmarks, Hoard’s fragmentation was low: p2c (Pascal-to-C): 1.20 espresso: 1.47 LRUsim : 1.05 Ghostscript : 1.15 Within 20% of Lea’s allocator On the multiprocessor benchmarks and other codes: Fragmentation was between 1.02 and 1.24 for all but one anomalous benchmark (shbench : 3.17) .
- 20. Hoard Conclusions Speed: Excellent As fast as a uniprocessor allocator on one processor amortized O(1) cost 1 lock for malloc , 2 for free Scalability: Excellent Scales linearly with the number of processors Avoids false sharing Fragmentation: Very good Worst-case is provably close to ideal Actual observed fragmentation is low
- 21. Hoard Heap Details “ Segregated size class” allocator Size classes are logarithmically-spaced Superblocks hold objects of one size class empty superblocks are “recycled” Approximately radix-sorted: Allocate from mostly-full superblocks Fast removal of mostly-empty superblocks 8 16 24 32 40 48 sizeclass bins radix-sorted superblock lists (emptiest to fullest) superblocks