Improving text simplification language modeling using unsimplified text data
0 likes459 views












Improving text simplification language modeling using unsimplified text data
- 1. Improving Text Simplification Language Modeling Using Unsimplified Text Data In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, pp.1537‒1546, 2013. Presented by Kodaira Tomonori 1
- 2. 概要 • 研究目的:平易化されていないテキストデータを 用いてテキスト平易化言語モデルの改善 • 実験:普通の英語と平易な英語のテキストで 学習したモデルを比較 • 結果:平易な英語データでの学習より、perplexityが 2種類の英語の共同の言語モデルでは23% モデル学習では、語彙平易化タスクにおいて24%向上 2
- 3. 使用コーパス • English Wikipedia と Simple English Wikipedia *Simple English Wikipediaから60Kの記事 *English Wikipediaから60Kの共通記事を抽出 simple normal sentences 385K 2540K words 7.15M 64.7M vocab size 78K 307K 3
- 6. Language Model Adaptation • 線形補完による領域適応の手法を用いる • 線形補完モデルは2つの言語モデルの 確率を加重和として、合わせた 6
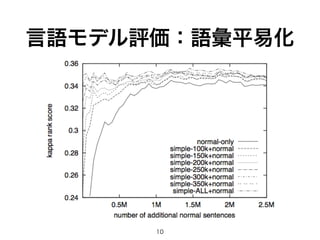
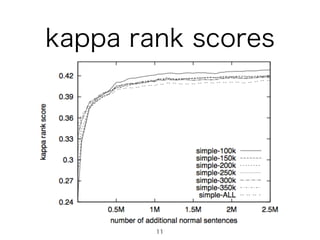
- 8. • 学習した言語モデルを用いて、SemEval2012 のデータセットの候補をランキング • システムが出力したランキングを評価するために Cohen s kappa coefficientを用いた。 8 言語モデル評価:語彙平易化 Word: tight Context: With the physical market as tight as it has been … Candidates: constricted, pressurised, low, high-strung, tight Human ranking: tight, low, constricted, pressurised, high-strung
- 10. 10 言語モデル評価:語彙平易化
- 12. まとめ • perplexyタスクにおいて、混合モデルは23% 語彙平易化タスクに於いては24%向上 • 言語モデル適応において、ノーマルデータの役割は、 部分的なタスクに依存している • 少ないデータしかない英語じゃない言語において、 テキスト平易化やテキスト圧縮などで使える 12
- 13. simple language model に関する研究課題 • 膨大なノーマルデータを使った実験では、 分野外のデータを加える限界を理解する必要性 • wiki以外のソースデータやサイズと分野の影響を 調べなければならない • どのように言語モデルの性能は文レベル、 文平易化章レベルの平易化に影響を与えるかつきとめる • 線形補完言語モデル以外の分野適応技術 より良いものがあるかもしれない。 13