Lecture_ASCII and Unicode.ppt
Download as PPT, PDF0 likes1,173 views

Unicode is a character encoding standard that aims to support all languages of the world. It evolved from limitations of earlier standards like ASCII that could only represent English characters. Unicode uses 16-bit or 32-bit encodings to represent over 1 million characters, as opposed to ASCII's 128 characters. Popular Unicode encodings include UTF-8, UTF-16, and UTF-32. The widespread adoption of Unicode has allowed globalization of text and the internet by supporting the simultaneous use of different languages.





































Lecture_ASCII and Unicode.ppt
- 3. Terms
- 4. Outline • ASCII Code • Unicode system – Discuss the Unicode’s main objective within computer processing • Computer processing before development of Unicode • Unicode vs. ASCII • Different kinds of Unicode encodings • Significance of Unicode in the modern world
- 5. From Bit & Bytes to ASCII • Bytes can represent any collection of items using a “look-up table” approach • ASCII is used to represent characters ASCII American Standard Code for Information Interchange http://en.wikipedia.org/wiki/ASCII
- 6. ASCII • It is an acronym for the American Standard Code for Information Interchange. • It is a standard seven-bit code that was first proposed by the American National Standards Institute or ANSI in 1963, and finalized in 1968 as ANSI Standard X3.4. • The purpose of ASCII was to provide a standard to code various symbols ( visible and invisible symbols)
- 7. ASCII • In the ASCII character set, each binary value between 0 and 127 represents a specific character. • Most computers extend the ASCII character set to use the full range of 256 characters available in a byte. The upper 128 characters handle special things like accented characters from common foreign languages.
- 8. • In general, ASCII works by assigning standard numeric values to letters, numbers, punctuation marks and other characters such as control codes. • An uppercase "A," for example, is represented by the decimal number 65."
- 9. Bytes: ASCII • By looking at the ASCII table, you can clearly see a one-to-one correspondence between each character and the ASCII code used. • For example, 32 is the ASCII code for a space. • We could expand these decimal numbers out to binary numbers (so 32 = 00100000), if we wanted to be technically correct -- that is how the computer really deals with things.
- 10. Bytes: ASCII • Computers store text documents, both on disk and in memory, using these ASCII codes. • For example, if you use Notepad in Windows XP/2000 to create a text file containing the words, "Four score and seven years ago," Notepad would use 1 byte of memory per character (including 1 byte for each space character between the words -- ASCII character 32). • When Notepad stores the sentence in a file on disk, the file will also contain 1 byte per character and per space. • Binary number is usually displayed as Hexadecimal to save display space.
- 11. • Take a look at a file size now. • Take a look at the space of your p drive
- 12. Bytes: ASCII • If you were to look at the file as a computer looks at it, you would find that each byte contains not a letter but a number -- the number is the ASCII code corresponding to the character (see below). So on disk, the numbers for the file look like this: • F o u r a n d s e v e n • 70 111 117 114 32 97 110 100 32 115 101 118 101 110
- 13. • Externally, it appears that human beings will use natural languages symbols to communicate with computer. • But internally, computer will convert everything into binary data. • Then process all information in binary world. • Finally, computer will convert binary information to human understandable languages.
- 14. • When you type the letter A, the hardware logic built into the keyboard automatically translates that character into the ASCII code 65, which is then sent to the computer. Similarly, when the computer sends the ASCII code 65 to the screen, the letter A appears.
- 15. ascii ASCII stands for American Standard Code for Information Interchange First published on October 6, 1960 ASCII is a type of binary data
- 16. Ascii part 2 ASCII is a character encoding scheme that encodes 128 different characters into 7 bit integers Computers can only read numbers, so ASCII is a numerical representation of special characters Ex: ‘%’ ‘!’ ‘?’
- 17. Ascii part 3 ASCII code assigns a number for each English character Each letter is assigned a number from 0-127 Ex: An uppercase ‘m’ has the ASCII code of 77 By 2007, ASCII was the most commonly used character encoding program on the internet
- 18. (This is a funny picture) • 01010100 01101000 01101001 01110011 00100000 01101001 01110011 00100000 01100001 00100000 01100110 01110101 01101110 01101110 01111001 00100000 01110000 01101001 01100011 01110100 01110101 01110010 01100101
- 19. Large files Large files can contain several megabytes 1,000,000 bytes are equivalent to one megabyte Some applications on a computer may even take up several thousand megabytes of data
- 20. revisit “char” data type • In C, single characters are represented using the data type char, which is one of the most important scalar data types. char achar; achar=‘A’; achar=65;
- 21. Character and integer • A character and an integer (actually a small integer spanning only 8 bits) are actually indistinguishable on their own. If you want to use it as a char, it will be a char, if you want to use it as an integer, it will be an integer, as long as you know how to use proper C++ statements to express your intentions.
- 22. • General Understanding of the Unicode System • http://www.youtube.com/watch?v=ot3VKnP4 Mz0
- 23. What is Unicode? • A worldwide character-encoding standard • Its main objective is to enable a single, unique character set that is capable of supporting all characters from all scripts, as well as symbols, that are commonly utilized for computer processing throughout the globe • Fun fact: Unicode is capable of encoding about at least 1,110,000 characters!
- 24. Before Unicode Began… • During the 1960s, each letter or character was represented by a number assigned from multiple different encoding schemes used by the ASCII Code • Such schemes included code pages that held as many as 256 characters, with each character requiring about eight bits of storage! • Made it insufficient to manage character sets consisting of thousands of characters such as Chinese and Japanese characters • Basically, character encoding was very limited in how much it was capable of containing • Also did not enable character sets of various languages to integrate
- 25. The ASCII Code • Acronym for the American Standard Code for Information Interchange • A computer processing code that represents English characters as numbers, with each letter assigned a number from 0 to 127 – For instance, the ASCII code for uppercase M is 77 • The standard ASCII character set uses just 7 bits for each character • Some larger character sets in ASCII code incorporate 8 bits, which allow 128 additional characters used to represent non-English characters, graphics symbols, and mathematical symbols • ASCII vs Unicode
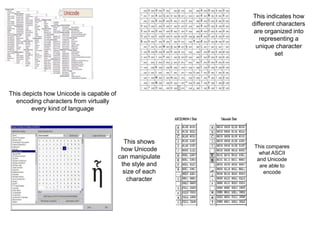
- 26. This depicts how Unicode is capable of encoding characters from virtually every kind of language This indicates how different characters are organized into representing a unique character set This shows how Unicode can manipulate the style and size of each character This compares what ASCII and Unicode are able to encode
- 27. Various Unicode Encodings Name UTF-8 UTF-16 UTF-16BE UTF-16LE UTF-32 UTF-32BE UTF-32LE Smallest code point 0000 0000 0000 0000 0000 0000 0000 Largest code point 10FFFF 10FFFF 10FFFF 10FFFF 10FFFF 10FFFF 10FFFF Code unit size 8 bits 16 bits 16 bits 16 bits 32 bits 32 bits 32 bits Byte order N/A <BOM> big- endian little- endian <BOM> big- endian little- endian Fewest bytes per character 1 2 2 2 4 4 4 Most bytes per character 4 4 4 4 4 4 4 http://www.unicode.org/faq/utf_bom.html
- 28. http://emergent.unpythonic.net/01360162755 Unicode’s Growth Over Time This graph shows the number of defined code points in Unicode from its first release in 1991 to the present
- 29. ASCII vs Unicode -Has 128 code points, 0 through 127 -Can only encode characters in 7 bits -Can only encode characters from the English language -Has about 1,114,112 code positions -Can encode characters in 16- bits and more -Can encode characters from virtually all kinds of languages -It is a superset of ASCII -Both are charact er codes -The 128 first code position s of Unicod e mean the same as ASCII
- 30. Method of Encoding • Unicode Transformation Format (UTF) – An algorithmic mapping from virtually every Unicode code point to a unique byte sequence – Each UTF is reversible, thus every UTF supports lossless round tripping: mapping from any Unicode coded character sequence S to a sequence of bytes and back will produce S again – Most texts in documents and webpages is encoded using some of the various UTF encodings – The conversions between all UTF encodings are algorithmically based, fast and lossless • Makes it easy to support data input or output in multiple formats, while using a particular UTF for internal storage or processing
- 31. Unicode Transformation Format Encodings • UTF-7 – Uses 7 bits for each character. It was designed to represent ASCII characters in email messages that required Unicode encoding – Not really used as often • UTF-8 – The most popular type of Unicode encoding – It uses one byte for standard English letters and symbols, two bytes for additional Latin and Middle Eastern characters, and three bytes for Asian characters – Any additional characters can be represented using four bytes – UTF-8 is backwards compatible with ASCII, since the first 128 characters are mapped to the same values
- 32. UTF Encodings (Cont…) • UTF-16 – An extension of the "UCS-2" Unicode encoding, which uses at least two bytes to represent about 65,536 characters – Used by operating systems such as Java and Qualcomm BREW • UTF-32 – A multi-byte encoding that represents each character with 4 bytes • Makes it space inefficient – Main use is in internal APIs where the data is single code points or glyphs, rather than strings of characters – Used on Unix systems sometimes for storage of information
- 33. What can Unicod e be Used For? Encode text for creation of passwords Encode characters used in email settings Encodes characters to display in all webpages Modify characters used in documents
- 34. Why is Unicode Important? • By providing a unique set for each character, this systemized standard creates a simple, yet efficient and faster way of handling tasks involving computer processing • Makes it possible for a single software product or a single website to be designed for multiple countries, platforms, and languages – Can reduce the cost over using legacy character sets – No need for re-engineering! • Unicode data can be utilized through a wide range of systems without the risk of data corruption • Unicode serves as a common point in the conversion of between other character encoding schemes – It is a superset of all of the other common character encoding schemes • Therefore, it is possible to convert from one encoding scheme to Unicode, and then from Unicode to the other encoding scheme.
- 35. Unicode in the Future… • Unicode may be capable of encoding characters from every language across the globe • Can become the most dominant and resourceful tool in encoding every kind of character and symbol • Integrates all kinds of character encoding schemes into its operations
- 36. Summary Unicode’s ability to create a standard in which virtually every character is represented through its complicated operations has revolutionized the way computer processing is handled today. It has emerged as an effective tool for processing characters within computers, replacing old versions of character encodings, such as the ASCII. Unicode’s capacity has substantially grown since its development, and continues to expand on its capability of encoding all kinds of characters and symbols from every language across the globe. It will become a necessary component of the technological advances that we will inevitably continue to produce in the near future, potentially creating new ways of encoding characters.
- 37. Pop Quiz! 1. What is the main purpose of the Unicode system? -To enable a single, unique character set that is capable of supporting all characters from all scripts and symbols 2. How many code points is Unicode capable of encoding? -About 1,114,112 code points
- 38. References • Cavalleri, Beshar Bahjat & Igor. Unicode 101: An Introduction to the Unicode Standard. 2014. Web. 17 09 2014. <http://www.interproinc.com/articles/unicode-101-introduction-unicode-standard>. • Constable, Peter. Understanding Unicode. 13 06 2001. Web. 17 09 2014. <http://scripts.sil.org/cms/scripts/page.php?item_id=IWS-Chapter04a>. • "UTF." Teach Terms. N.p., 20 Apr. 2012. Web. 13 Nov. 2014. <http%3A%2F%2Fwww.techterms.com%2Fdefinition%2Futf>. • "UTF-8, UTF-16, UTF-32 & BOM." FAQ. N.p., n.d. Web. 13 Nov. 2014. <http://www.unicode.org/faq/utf_bom.html>.