2. Merge Sort 2
Divide-and-Conquer
• Divide-and conquer is a
general algorithm design
paradigm:
• Divide: divide the input
data S in two disjoint
subsets S1 and S2
• Recur: solve the
subproblems associated
with S1 and S2
• Conquer: combine the
solutions for S1 and S2 into
a solution for S
• The base case for the
recursion are subproblems
of size 0 or 1
3. Merge Sort 3
Merge-Sort
• Merge-sort is a sorting algorithm based on the divide-and-
conquer paradigm
• Like heap-sort
• It has O(n log n) running time
• Unlike heap-sort
• It does not use an auxiliary priority queue
• It accesses data in a sequential manner (suitable to sort data on a
disk)
4. Merge Sort 4
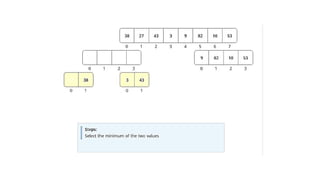
The Merge-Sort Algorithm
• Merge-sort on an input
sequence S with n
elements consists of
three steps:
• Divide: partition S into
two sequences S1 and S2
of about n/2 elements
each
• Recur: recursively sort S1
and S2
• Conquer: merge S1 and
S2 into a unique sorted
sequence
Algorithm mergeSort(S)
Input sequence S with n
elements
Output sequence S sorted
according to C
if S.size() > 1
(S1, S2) partition(S,
n/2)
mergeSort(S1)
mergeSort(S2)
S merge(S1, S2)
5. Algorithm
void mergeSort(vector<T>& arr, int left, int right) {
if (left >= right)
return;
int mid = (left + right) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
104. Merge Sort 104
Analysis of Merge-Sort
• The height h of the merge-sort tree is O(log n)
• at each recursive call we divide in half the sequence,
• The overall amount or work done at the nodes of depth i is
O(n)
• we partition and merge 2i
sequences of size n/2i
• we make 2i+1
recursive calls
• Thus, the total running time of merge-sort is O(n log n)
depth #seqs size
0 1 n
1 2 n/2
i 2i
n/2i
… … …
105. Merge Sort 105
Summary of Sorting
Algorithms
Algorithm Time Notes
selection-sort O(n2
)
slow
in-place
for small data sets (< 1K)
insertion-sort O(n2
)
slow
in-place
for small data sets (< 1K)
heap-sort O(n log n)
fast
in-place
for large data sets (1K — 1M)
merge-sort O(n log n)
fast
sequential data access
for huge data sets (> 1M)